Implement fast 2D shadows in Unity with 1D shadow mapping
- Transfer

Introduction
I recently started implementing a 2D shadow system in Unity, which could be used in a real game. As is known to professional developers, there is a big difference between what can be achieved in a technical demo and what is applicable for integration into a full game, where the implemented opportunity is only one of many. The effect on the CPU, video processor and memory must be in balance with everything else in the game. In practice, different projects have different limitations, but I decided to create a system that takes no more than a couple of milliseconds of processing time and no more than a few megabytes in memory.
With this restriction, I discarded many existing methods for calculating the shadows that I managed to find. A couple of techniques were popular. One used ray tracing implemented on the CPU, which defines the boundaries of the silhouettes of light-blocking geometry. In another, all the obstacles to the light were rendered into a texture, and then an algorithm like ray-stepping with several passes was performed for it to create a shadow map. These techniques are usually used with no more than a couple of light sources and would definitely not allow me to work with dozens of light sources in accordance with the restrictions I have chosen.
Shadow overlay
Therefore, I decided to create a 2D analogue of the method of calculating shadows, which is used in most modern 3D games: rendering geometry from the point of view of the light source and creating a depth buffer that will allow us to determine when rendering each pixel whether it is visible from the light source. This technique is called shadow mapping. In 3D, it creates a two-dimensional texture, that is, in 2D it will create a one-dimensional texture. The screenshot below shows my finished lighting map in Unity resource view; but actually it’s not for one light source, but for 64: each line of pixels in the texture is a shadow map for a separate source.

This method uses polar coordinates to convert a 2D position to an angle and distance (or depth) relative to another object.
inline float2 CartesianToPolar(float2 point, float2 origin)
{
float2 d = point - origin;
// x - угол в радианах, y - расстояние
return float2(atan2(d.y, d.x), length(d));
}That is, each line in the shadow map represents 360 degrees around the light source, and each pixel represents the distance from the light source to the nearest opaque geometry in this direction. The higher the horizontal resolution of the texture, the greater the accuracy of the resulting shadows.
Opaque geometry casting shadows, which I will call blocking geometry below, passed as a list of lines. Each pair of vertices creates a pair of positions in the polar space, after which the pixel shader fills the corresponding segment in the lighting map. In each pixel, using the standard z-buffer test, only the pixel closest to the geometry is saved. It would be wrong to simply interpolate the polar depth in the pixel shader to obtain the z-coordinate, because this is how we get curved shadows for straight edges. Instead, we need to calculate the intersection point between the line segment and the ray of light at the current angle, but this is a matter of just a couple of scalar products and division, which is not very expensive for modern video processors.
Difficulties
All this would be very simple if it were not for one fly in the ointment - a serious problem when using polar coordinates arises when we get a straight line segment in polar coordinates, which is 360 degrees on both sides of the border. A common solution would be to split the line segment into two separate parts: the first part would end at 360 degrees, and the other (the remainder of the segment) would start at 0. However, the vertex shader gets only one vertex and produces one result, and there is no way to output two separate segment. The main difficulty of this approach is to solve this problem.
You can solve it this way: present the original lines of the shadow map not in 360 degrees, but add an additional 180 degrees, that is, from 0 to 540. A line segment in the polar space takes no more than 180 degrees, so this is enough to accommodate any segment that is nearby with a point of 360. This means that each line segment still creates one line segment at the output for the pixel shader, as needed.
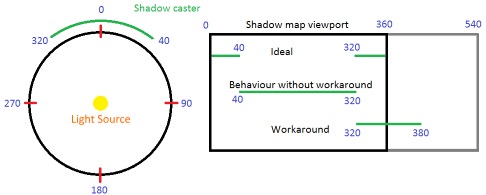
The disadvantage of this method is that. that the first part of the line (from 0 to 180) and the last part (from 360 to 540) are actually one area in the polar space. To check the pixel relative to the shadow map, we need to determine whether the polar angle falls in this area, and if so, then take samples from two places and select at least two depths. This is not exactly what I was aiming for - branching and additional sampling will have a terrible effect on performance, especially when performing multiple texture sampling for Percentage Closest Filtering (PCF) (this technique is widely used to create smooth shadows based on shadow maps). My solution (after filling in all the lines of the shadow map) is as follows: performing another pass of the video processor on the shadow map, its resampling and combinability of the first 180 degrees with the last 180 degrees. By the usual frame buffer standards, the texture of shadow cards is very small, so it takes a little video processor time. As a result, we get a ready-made shadow map texture in which one sample is enough to determine whether the current pixel is illuminated by a specific light source.
The main disadvantage of this system is that for the recognition and processing of borderline cases, the blocking geometry must have a special format. Each vertex of each line segment itself resembles a line segment, because it stores the position of the other end of the line segment. This means that we will have to either build the geometry in this format during the execution of the application, or previously. We cannot just convey the geometry that is used for rendering. However, this has a good side: after constructing this special geometry, we at least do not transmit any unnecessary data, that is, the efficiency is higher.
Another great feature of this system is that the finished shadow map can be written back to the video processor, and this allows you to perform visibility requests through the CPU without the need for ray tracing. Copying the texture back to the video processor can be quite a costly task, and despite the fact that in Unity 2018 we are waiting for the long-awaited implementation of asynchronous gpu read-backs of the video processor, this function should not be used without real need.
Algorithm
In essence, the algorithm works as follows.
- Create a mesh of line segments for the shadow casting geometry. If the geometry does not change, then there is no need to rebuild it in each frame. You can also use two meshes, one for static geometry and one for dynamic to avoid unnecessary rebuilding.
- Render this blocking geometry for each shadow casting light source. In the demo, separate rendering calls are used for this, but this is a great opportunity to use instancing so that the mesh is transferred to the video processor only once. Each light source is assigned a line in the shadow map, and this data is transmitted to the shader through the shader constants, which allows you to create a suitable Y coordinate to which you want to record.
- In the vertex shader, line segments are converted to polar space.
- The video processor shades the line segments in the current line with the shadow texture, performing a z-test to store only the nearest pixels.
- We re-sample the finished shadow map into another texture to eliminate the parts belonging to the same polar region.
- For each light source we render a quadrangle covering the maximum range of the source (for example, the radius of a point light source). For each pixel, calculate the polar coordinate in accordance with the light source, and use it to sample the shadow map. If the polar distance is greater than the value read from the shadow map, then the pixel is not illuminated by the light source, that is, lighting is not applied to it.
And here are the finished results. For the stress test, I set 64 movable shadow-casting point light sources with random-sized lighting cones moving between several rotating opaque objects.

What were the costs? If we assume that the blocking geometry is static, and that we use instancing of the geometry, then a complete shadow map for any number of sources (subject to texture size restrictions) can be transferred to the video processor for a single draw call. The amount of redrawing in the shadow map is determined by the complexity of the geometry blocking the lighting, but since the texture is very small compared to modern frame buffers, the performance of the video processor cache should be fantastic. Similarly, when we come to sampling the shadow map, it is no different from shadow mapping in 3D, except that the shadow map will be much smaller.
Our game consists of a single large environment and we have 64 constantly active and shadow casting light sources, so I used the texture of a shadow map of size 1024x64. The costs within the overall budget of the frame calculations were minimal.
Additional features
If you want to expand this system, then I can offer a couple of interesting features. When processing a shadow map to eliminate two overlapping areas, you can take the opportunity to convert the values to create an exponential shadow map and then blur it (do not forget that you need to blur only in the horizontal direction, otherwise it will affect sources unrelated to each other! ) This will allow us to create smooth shadows without multisampling the shadow map. Second: as I mentioned earlier, the demo is now making a separate draw call to transfer the shading geometry of each source, but if we pack the position of the light source and other parameters into the matrix, this can be trivially done in one draw call using instancing.
Moreover, I believe that with almost no additional work on the part of the CPU, radiosity lighting with single reflection can be implemented as an extension of the system. To do this, you can use the following principle: the video processor can use the shadow map from the last frame to calculate the reflections of light rays in the scene. So far I can’t say anything more detailed, because I have not yet implemented this system. If it works, it will be much more efficient than the usual Virtual Point Light implementations, which use ray tracing performed by the CPU.
In addition, you can use this system in many interesting ways. For example, if you replace light sources with sound emitters, then this system can be used to calculate sound absorption. Or it can be used to determine the field of view in AI procedures. In general, it is possible to turn ray tracing into a texture search.
Completion
This concludes my account of the details of the implementation of my one-dimensional shadowing system. If you have any questions, then ask them in the comments to the original article .
Demo source code
https://www.double11.com/misc/uploads/1DShadowMapDemo.zip