Reinforcement deep learning not working yet
- Transfer
About the author . Alex Irpan is a developer from the Brain Robotics group at Google, before that he worked in the Berkeley Artificial Intelligence Research (BAIR) laboratory.
It mainly cites articles from Berkeley, Google Brain, DeepMind, and OpenAI over the past few years, because their work is most visible from my point of view. I almost certainly missed something from older literature and from other organizations, so I apologize - I'm just one person, after all.

Once on Facebook I stated the following.
Unfortunately, in reality this thing does not work yet.
But I believe that she will shoot. If I didn’t believe, I wouldn’t cook in this topic. But there are a lot of problems ahead, many of which are fundamentally complex. Beautiful demos of trained agents hide all the blood, sweat and tears that spilled during their creation.
Several times I saw people seduced by recent results. They first tried deep RL and always underestimated the difficulties. Without a doubt, this “model task" is not as simple as it seems. And without a doubt, this area broke them several times before they learned to set realistic expectations in their research.
There is no one's personal mistake. This is a system problem. It's easy to draw a story around a positive outcome. Try to do this with a negative. The problem is that researchers most often get exactly a negative result. In a sense, such results are even more important than positive ones.
In this article, I will explain why deep RL does not work. I will give examples when it still works and how to achieve more reliable work in the future, in my opinion. I do this not to stop people working on deep RL, but because it’s easier to make progress if everyone understands the problems. It is easier to reach agreement if you really talk about problems, and not again and again stumble upon the same rake separately from each other.
I would like to see more research on the topic of deep RL. So that new people come here. And so that they know what they are getting involved in.
Before proceeding, let me make a few remarks.
Without further ado, here are some of the cases where deep RL crashes.
The most famous benchmark for deep learning with reinforcements is Atari games. As shown in the well-known article Deep Q-Networks (DQN), if you combine Q-Learning with neural networks of a reasonable size and some optimization tricks, you can achieve human performance in several Atari games or surpass them.
Games Atari games run at 60 frames per second. Can you immediately figure out how many frames you need to process the best DQN to show the result as a person?
The answer depends on the game, so take a look at a recent Deepmind article - Rainbow DQN (Hessel et al, 2017). It shows how some of the consecutive enhancements to the original DQN architecture improve the outcome, and combining all the improvements is most effective. The neural network surpasses the human result in more than 40 of 57 Atari games. The results are shown in this convenient chart.
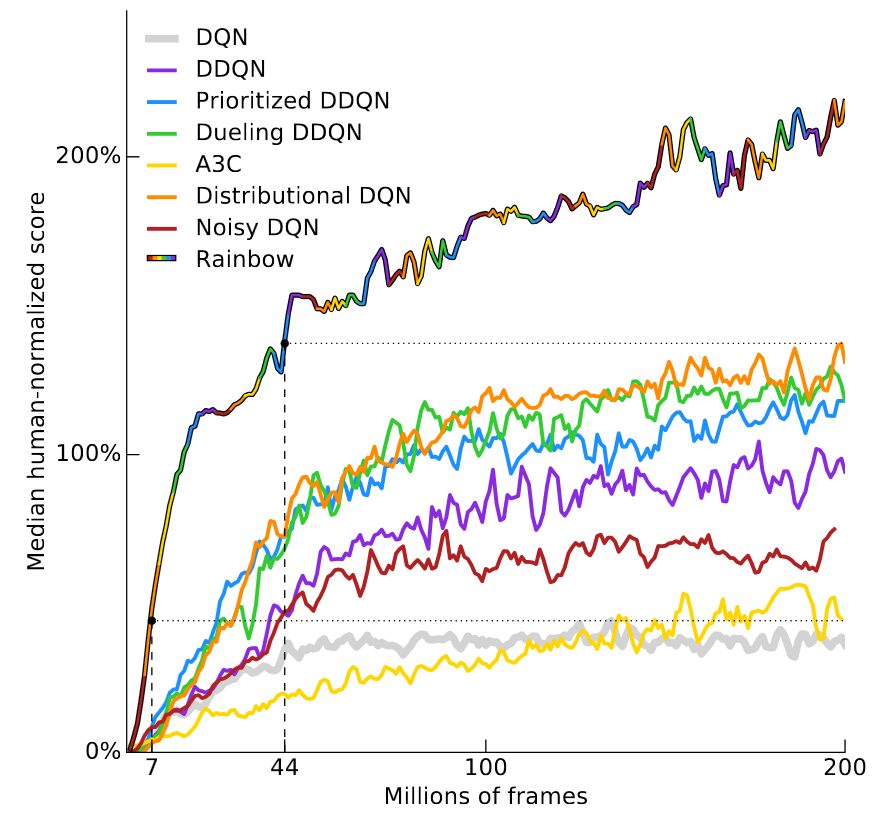
The vertical axis shows the “median average result normalized to human”. it is calculated by training 57 DQN neural networks, one for each Atari game, with normalizing the result of each agent when the human result is taken as 100%, and then calculating the average median result for 57 games. RainbowDQN exceeds 100% after processing 18 millionframes. This corresponds to approximately 83 hours of play, plus time to learn, no matter how long it takes. This is a lot of time for the simple Atari games that most people grab in a couple of minutes.
Keep in mind that 18 million frames is actually a very good result, because the previous record belonged to the Distributional DQN system (Bellemare et al, 2017) , which required 70 million frames to achieve a 100% result, i.e. about four times as much time. As for Nature DQN (Mnih et al, 2015) , it generally never reaches 100% median result, even after 200 million frames.
The cognitive bias of the “planning error” says that completing a task usually takes longer than you expected. Reinforcement learning has its own planning mistake - training usually requires more samples than you thought.
The problem is not limited to Atari games. The second most popular test is the MuJoCo benchmarks, a set of tasks in the MuJoCo physics engine. In these tasks, the position and speed of each hinge in a simulation of a robot are usually given at the input. Although there is no need to solve the problem of vision, RL systems are required for training from before
before  steps, depending on the task. This is incredible for control in such a simple environment.
steps, depending on the task. This is incredible for control in such a simple environment.
A Parkour DeepMind article (Heess et al, 2017) , illustrated below, has been trained using 64 workers for over 100 hours. The article does not specify what a worker is, but I assume that this means a single processor.
This is a super result . When he first came out, I was surprised that the deep RL was generally able to learn such gait on the run.
But it took 6400 hours of processor time, which is a bit disappointing. Not that I expected less time ... it’s just sad that in simple skills the deep RL is still an order of magnitude inferior to the level of training that could be useful in practice.
There is an obvious counterargument here: what if you simply ignore the effectiveness of the training? There are certain environments that make it easy to generate experience. For example, games. But for any environment where this is not possible , RL faces enormous challenges. Unfortunately, most environments fall into this category.
When searching for solutions to any problem, you usually have to find a compromise in achieving different goals. You can focus on a really good solution to this particular problem, or you can focus on the maximum contribution to the overall research. The best problems are those where a good contribution to research is required to get a good solution. But in reality, it is difficult to find problems that meet these criteria.
Purely in demonstrating maximum efficiency, the deep RL does not show very impressive results, because it is constantly superior to other methods. Here's a video of MuJoCo robots that are controlled by interactive path optimization. Correct actions are calculated almost in real time, interactively, without offline learning. Yes, and everything works on the equipment of 2012 (Tassa et al, IROS 2012 ).
I think this work can be compared with a DeepMind article on parkour. What is the difference?
The difference is that here the authors apply control with predictive models, working with a real model of the earth’s world (physical engine). There are no such models in RL, which greatly complicates the work. On the other hand, if model-based action planning improves the outcome so much, then why bother with tricked out RL training?
Similarly, you can easily outperform the Atari DQN neural networks with the Monte Carlo (MCTS) turnkey tree search solution. Here are the key metrics from Guo et al, NIPS 2014 . The authors compare the results of trained DQNs with the results of the UCT agent (this is a standard version of modern MCTS).


Again, this is an unfair comparison, because the DQN does not search, and the MCTS does exactly the search using a real model of terrestrial physics (Atari emulator). But in some situations, you don’t care, here is an honest or dishonest comparison. Sometimes you just need it to work (if you need a full UCT assessment, see the appendix in the original scientific article Arcade Learning Environment (Bellemare et al, JAIR 2013 ).
Reinforced learning is theoretically suitable for everything, including environments with an unknown model of the world. However, such versatility is expensive: it is difficult to use any specific information that could help in learning. Because of this, you have to use a lot of samples to learn things that could just be hard-coded from the very beginning.
Experience has shown that, with the exception of rare cases, algorithms tailored to specific tasks work faster and better than reinforced learning. It’s not a problem if you are developing deep-seated RL for the sake of deep-seated RL, but I personally find it frustrating to compare the effectiveness of RL c ... well, with anything else. One of the reasons why I liked AlphaGo so much is because it was a definite victory for the deep RL, and this does not happen very often.
Because of all this, it’s more difficult to explain to people why my tasks are so cool, complex and interesting, because often they don’t have context or experience to evaluate whythey are so complicated. There is a definite difference between what people think about the capabilities of deep RL - and its real capabilities. Now I work in the field of robotics. Consider a company that comes to the minds of most people if you mention robotics: Boston Dynamics.
This thing does not use reinforcement training. Several times I met people who thought that RL was used here, but no. If you look for published scientific papers from a group of developers, you will find articles mentioning time-varying linear-quadratic regulators, solvers of quadratic programming problems and convex optimization . In other words, they mainly apply the classical methods of robotics. It turns out that these classic techniques work fine if properly applied.
Reinforced learning implies the existence of a reward function. Usually it is either there initially, or manually configured in offline mode and remains unchanged during training. I say “usually” because there are exceptions, such as simulation training or the opposite of RL (when the reward function is restored ex post), but in most cases RL uses reward as an oracle.
It’s important to note that for RL to work properly, the reward function must cover exactly what we need. And I mean exactly. RL is annoyingly prone to overfit, which leads to unexpected consequences. That's why Atari is such a good benchmark. It’s not only easy to get a lot of samples there, but every game has a clear goal - the number of points, so you never have to worry about finding a reward function. And you know that everyone else has the same function.
The popularity of MuJoCo tasks is due to the same reasons. Since they work in simulation, you have complete information about the state of the object, which greatly simplifies the creation of the reward function.
In the Reacher task, you control a two-segmented arm that is connected to a center point, and the goal is to move the end of the arm to a given target. See below for an example of successful learning.
Since all coordinates are known, the reward can be defined as the distance from the end of the hand to the target, plus a short time to move. In principle, in the real world you can do the same experiment if you have enough sensors to accurately measure the coordinates. But depending on what the system needs to do, it can be difficult to determine a reasonable reward.
The reward function itself would not be a big problem if it weren't for ...
Making the reward function is not so difficult. Difficulties arise when you try to create a function that will encourage proper behavior, and at the same time, the system will retain learning.
In HalfCheetah, we have a two-legged robot bounded by a vertical plane, which means that it can only move forward or backward. The goal is to learn to jog. The reward is the speed of HalfCheetah ( video ). This is a smooth or shaped (shaped) reward, that is, it increases with approach to the ultimate goal. Unlike sparse

(sparse) remuneration, which is given only upon reaching the final state of the goal, and in other states is absent. The smooth growth of remuneration is often much easier to learn, because it provides positive feedback, even if training did not provide a complete solution to the problem.
Unfortunately, rewards with smooth growth can be biased. As already mentioned, because of this, unexpected and undesirable behavior is manifested. A good example is boat racing from an OpenAI blog article . The intended goal is to reach the finish line. You can imagine a reward as +1 for the end of the race at a given time, and a reward of 0 otherwise.
The reward function gives points for crossing checkpoints and for collecting bonuses that allow you to quickly reach the finish line. As it turned out, collecting bonuses gives more points than the completion of the race.
To be honest, this publication was a little annoying at first. Not because she is wrong! But because it seemed to me that she was demonstrating obvious things. Of course, reinforced learning will give a strange result when the reward is incorrectly defined! It seemed to me that the publication attached unjustifiably great importance to this particular case.
But then I started writing this article and realized that the most convincing example of an incorrectly defined reward is just this very video with boat races. Since then, it has been used in several presentations on this topic, which attracted attention to the problem. So all right, I reluctantly admit that it was a good blog post.
RL algorithms fall into a black hole if they have to more or less guess about the world around them. The most versatile category of modelless RLs is almost like black box optimization. Such systems are only allowed to assume that they are in the MDP (Markov decision-making process) - and nothing more. The agent is simply told that this is what you get +1 for, but you don’t get it for this, and you should find out the rest yourself. As with the optimization of the black box, the problem is that any behavior that gives +1 is considered good, even if the reward is received in the wrong way.
A classic example is not from the sphere of RL - when someone applied genetic algorithms for the design of microcircuits and received a scheme in whichthe final design needed one unconnected logic gate .
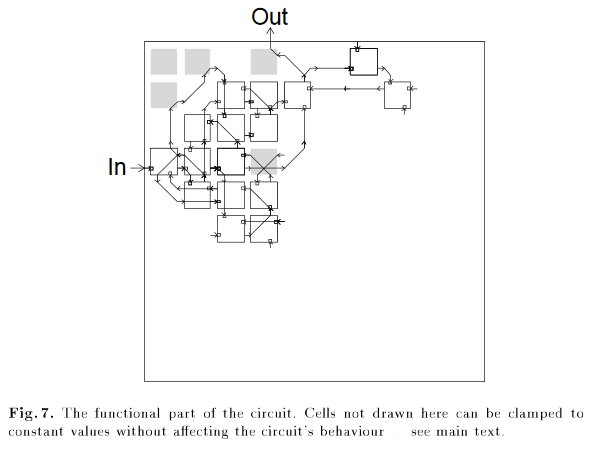
Gray elements are necessary for the correct operation of the circuit, including the element in the upper left corner, although it is not connected to anything. From the article “An Evolved Circuit, Intrinsic in Silicon, Entwined with Physics”
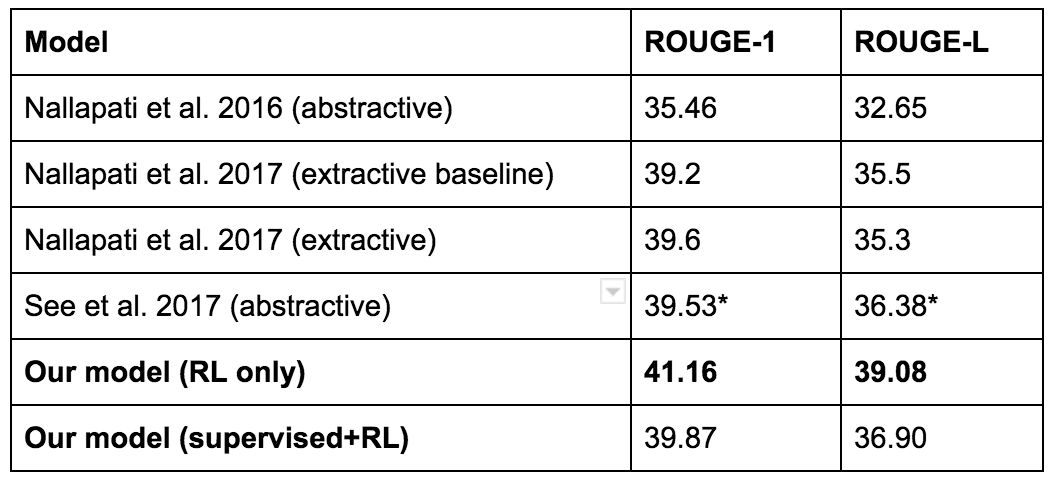
Or a more recent example, here's a 2017 Salesforce blog post . Their goal was to compose a summary for the text. The basic model was taught with a teacher, then it was evaluated by an automated metric called ROUGE. ROUGE is an undifferentiated reward, but RL can work with such. So they tried to apply RL to optimize ROUGE directly. This gives a high ROUGE (cheers!), But not really good lyrics. Here is an example.
And although the RL model showed the maximum ROUGE result ...
... they eventually decided to use another model for compiling a resume.
Another fun example. This is from an article by Popov et al, 2017 , also known as an “article on folding Lego constructor.” The authors use a distributed version of DDPG to teach capture rules. The goal is to grab the red cube and put it on the blue.
They made her work, but faced an interesting case of failure. The initial lifting movement is rewarded based on the lifting height of the red block. This is determined by the z-coordinate of the bottom face of the cube. In one of the failure options, the model learned to turn the red cube with the bottom face up, and not raise it.
Clearly, this behavior was not intended. But RL doesn't care. In terms of reinforcement training, she received a reward for turning the cube - so she will continue to turn the cube.
One way to solve this problem is to make the reward sparse, giving it only after connecting the cubes. Sometimes this works because a rare reward lends itself to learning. But often this is not so, since the lack of positive reinforcement makes things all too complicated.
Another solution to the problem is the careful formation of remuneration, the addition of new remuneration conditions and the adjustment of coefficients for existing conditions until the RL algorithm begins to demonstrate the desired learning behavior. Yes maybefight RL on this front, but such a struggle is not satisfying. Sometimes it is necessary, but I never felt that I had learned something in the process.
For reference, here is one of the reward functions from an article on folding Lego constructor.
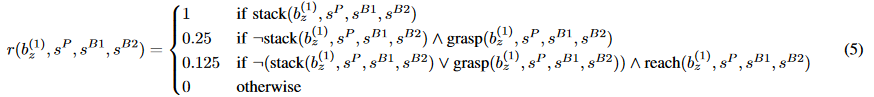
I don’t know how much time the guys spent on developing this feature, but I would say “a lot” by the number of members and different coefficients.
In conversations with other RL researchers, I heard several stories about the original behavior of models with incorrectly set rewards.
True, all this is stories from the wrong lips, personally, I have not seen videos with this behavior. But not one of these stories seems impossible to me. I got burned on RL too many times to believe otherwise.
I know people who like to tell stories about paper optimizers . Okay, I understand honestly. But in truth, I'm tired of listening to these stories, because they always speak of some superhuman disoriented, strong AI as a real story. Why invent it if there are so many real stories around that happen every day.
Previous RL examples are often referred to as "reward hacks." As for me, this is a smart, non-standard solution that brings more reward than the expected solution from the task designer.
Hacking rewards are exceptions. Much more common are cases of incorrect local optima that result from the wrong compromise between exploration and exploitation.
Here is one of my favorite videos . It implements the normalized benefit feature that is trained in HalfCheetah. From the perspective of an outsider, this is very, very
stupid. But we call it stupid only because we look from the side and have a lot of knowledge that moving on your feet is better than lying on your back. RL does not know this! He sees a state vector, sends action vectors and sees that he is receiving some positive reward. That's all.
Here is the most plausible explanation that I can come up with about what happened during the training.
This is very funny, but obviously not what we want from the robot.
Here is another unsuccessful example, this time surrounded by Reacher ( video ) In this run, random initial weights, as a rule, gave out strongly positive or very negative values for actions. Because of this, most of the actions were performed with the maximum or minimum possible acceleration. In fact, it is very easy to spin up a model very much: just give a high amount of force to each hinge. When the robot spins, it is already difficult to get out of this state in some understandable way: in order to stop the rampant rotation, several reconnaissance steps should be taken. Of course, this is possible. But this did not happen in this run.

In both cases, we see the classic reconnaissance / exploitation problem, which, from time immemorial, has pursued reinforced learning. Your data is derived from current rules. If the current rules provide for extensive intelligence, you will receive unnecessary data and learn nothing. Exploit too much - and “sew” non-optimal behavior.
There are several intuitively pleasant ideas on this subject - internal motives and curiosity, intelligence based on counting, etc. Many of these approaches were first proposed in the 80s or earlier, and some were later revised for deep learning models. But as far as I know, no approach works stably in all environments. Sometimes it helps, sometimes not. It would be nice for some kind of intelligence trick to work everywhere, but I doubt that in the foreseeable future they will find a silver bullet of this caliber. Not because no one is trying, but because exploration-exploitation is a very, very, very, very complicated matter. Quote from the Wikipedia multi-armed bandit article :
I present the deep RL as a demon who deliberately misunderstands your reward and is actively looking for the laziest way to achieve a local optimum. A bit ridiculous, but it turned out to be really productive thinking.
positive side of reinforcement training is that if you want to achieve a good result in a particular environment, you can retrain as a madman. The disadvantage is that if you need to extend the model to any other environment, it will probably work poorly due to crazy retraining.
DQN networks cope with many Atari games, because all the training of each model is focused on a single goal - to achieve maximum results in one game. The final model cannot be expanded to other games because it wasn’t taught that way. You can configure the trained DQN for the new Atari game (see Progressive Neural Networks (Rusu et al, 2016)), but there is no guarantee that such a transfer will take place, and usually no one expects this. This is not the wild success that people see on the pre-trained features of ImageNet.
To prevent some obvious comments: yes, in principle, training on a wide range of environments can solve some problems. In some cases, such an extension of the action of the model occurs by itself. An example is navigation, where you can try random locations of targets and use universal functions to generalize. (see Universal Value Function Approximators, Schaul et al, ICML 2015) I consider this work very promising, and later I will give more examples from this work. But I think that the possibilities of generalizing deep RL are not so great as to cope with a diverse set of tasks. The perception has become much better, but the deep RL is still ahead of the moment when “ImageNet for management” appears. The OpenAI Universe tried to light this bonfire, but from what I heard, the task was too complicated, so they did little.
While there is no such moment for generalizing models, we are stuck with surprisingly narrow models in scope. As an example (and as an excuse to laugh at my own work), look at the Can Deep RL Solve Erdos-Selfridge-Spencer Games article ? (Raghu et al, 2017). We studied a combinatorial game for two players, where there is a solution in an analytical form for an optimal game. In one of the first experiments, we recorded the behavior of player 1, and then trained player 2 using RL. In this case, you can consider the actions of player 1 as part of the environment. Teaching player 2 against optimal player 1, we have shown that RL is able to show high results. But when we applied the same rules against non-optimal player 1, then the effectiveness of player 2 fell because it did not apply to non-optimal opponents.
Authors of the article Lanctot et al, NIPS 2017got a similar result. Here two agents are playing laser tag. Agents are trained using multi-agent reinforcement training. To test the generalization, training was launched with five random starting points (sids). Here is a video of agents who were trained to play against each other.
As you can see, they learned to get close and shoot at each other. Then the authors took player 1 from one experiment - and brought him together with player 2 from another experiment. If the learned rules are generalized, then we should see a similar behavior.
Spoiler: we will not see him.
This seems to be a common multi-agent RL problem. When agents are trained against each other, a kind of joint evolution takes place. Agents are trained to really fight each other really well, but when they are directed against a player whom they have not met before, their effectiveness decreases. I want to note that the only difference between these videos is random seed. The same learning algorithm, the same hyperparameters. The difference in behavior is purely due to the random nature of the initial conditions.
Nevertheless, there are some impressive results obtained in an environment with independent play against each other - they seem to contradict the general thesis. The OpenAI Blog has a good post about some of their work in this area.. Do-it-yourself play is also an important part of AlphaGo and AlphaZero. My intuitive hunch is that if agents learn at the same pace, they can constantly compete and speed up each other’s learning, but if one of them learns much faster than the other, then he uses the weak player’s vulnerabilities too much and retrains. As you move from a symmetrical stand-alone game to common multi-agent settings, it becomes much more difficult to make sure that the training is at the same speed.
Almost every machine learning algorithm has hyperparameters that affect the behavior of the learning system. Often they are selected manually or by random search.
Teacher training is stable. Fixed dataset, checking with true data. If you slightly change the hyperparameters, the functioning will not change too much. Not all hyperparameters work well, but many empirical tricks have been found over the years, so many hyperparameters show signs of life during training. These signs of life are very important: they say that you are on the right track, doing something reasonable - and you need to devote more time.
Currently, deep RL is not at all stable, which is very annoying in the research process.
When I started working in Google Brain, I almost immediately began to implement the algorithm from the above article Normalized Advantage Function (NAF). I thought it would only take two to three weeks. I had a few trump cards: a certain acquaintance with Teano (which is well ported to TensorFlow), some experience with deep RL, and the lead author of the NAF article interned in Brain, so I could pester him with questions.
In the end, it took me six weeks to reproduce the results, due to several bugs in the software. The question is, why did these bugs hide for so long?
To answer this question, consider the simplest continuous management task in OpenAI Gym: the Pendulum task. In this problem, the pendulum is fixed at a certain point and gravity acts on it. The input is a three-dimensional state. The space of action is one-dimensional: it is a moment of force that is applied to the pendulum. The goal is to balance the pendulum in exactly vertical position.
This is a small problem, and it becomes even easier thanks to well-defined remuneration. The reward depends on the angle of the pendulum. Actions that bring the pendulum to a vertical position, not only give a reward, they increase it.
Here is a video of a model that is almostworks. Although it does not bring the pendulum into an exactly vertical position, it provides an exact moment of force to compensate for gravity. And here is a performance graph after fixing all the errors. Each line is a reward curve from one of ten independent runs. The same hyperparameters, the difference is only in a random starting point. Seven out of ten runs worked well. Three did not pass. A 30% failure rate is considered operational . Here is another graph from Variational Information Maximizing Exploration (Houthooft et al, NIPS 2016) . Wednesday - HalfCheetah. The award was made sparse, although the details are not too important. The y-axis is episodic reward, the x-axis is the number of time slices, and the algorithm used is TRPO.


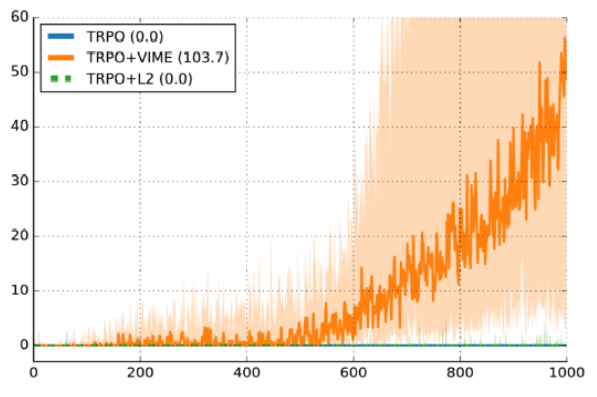
The dark line is the median performance for ten random sids, and the shaded area is coverage from the 25th to the 75th percentile. Don't get me wrong, this graph seems like a good argument for VIME. But on the other hand, the line of the 25th percentile is really close to zero. This means that about 25% do not work simply because of a random starting point.
Look, in teaching with a teacher there is also variance, but not so bad. If my training code did not cope with a teacher in 30% of runs with random sids, then I would be absolutely sure that some kind of error occurred while loading data or training. If my training code with reinforcements copes no better than randomness, then I have no idea whether it is a bug, or bad hyperparameters, or I’m just out of luck.
This is an illustration from the article “Why is machine learning so“ difficult ”to work with?” The main point is that machine learning adds extra dimensions to the crash space, which exponentially increases the number of crash options. Deep RL adds another dimension: randomness. And the only way to solve the problem of randomness is to clean out the noise.
If your learning algorithm has inefficient sampling and is not stable at the same time, then it greatly reduces the productivity of your research. Maybe he will need only 1 million steps. But when you multiply this by five random input values, and then multiply by the spread of the hyperparameters, you will see an exponential increase in the calculations needed to effectively test the hypothesis.
The instability of random seeds is like a canary in a coal mine. If a simple coincidence leads to such a strong difference between runs, then imagine what the difference would be with a real code change.
Fortunately, we do not need to conduct this thought experiment because it has already been carried out and described in the article “Deep Reinforcement Learning That Matters” (Henderson et al, AAAI 2018) . Here are some conclusions:
My theory is that RL is very sensitive to both initialization and the dynamics of the educational process, because data is always collected on the Internet and the only parameter that is controlled is the size of the reward. Models that randomly encounter good training examples work much better. If the model does not see good examples, then it may not learn anything at all, as it is increasingly becoming convinced that any deviations are inconclusive.
Of course, in-depth reinforcement learning has achieved some excellent results. DQN is no longer a novelty, but at one time it was an absolutely crazy discovery. The same model is studied directly by pixels, without adjusting for each game individually. Both AlphaGo and AlphaZero also remain very impressive achievements.
But besides these successes, it is difficult to find cases where deep RL has practical value for the real world.
I tried to think about how you can use deep RL in the real world for practical tasks - and this is surprisingly difficult. I thought that I would find some use in recommendation systems, but in my opinion collaborative filtering and contextual bandits still dominate there .
The best thing that I finally found was two Google projects: reducing energy consumption in data centers and the recently announced AutoML Vision project . Jack Clark of OpenAI tweeted a similar question to readers - and came to the same conclusion . (Tweet last year, before the announcement of AutoML).
I know that Audi is doing something interesting with deep RL, because on NIPS they showed a small model of an unmanned racing car and said that they had developed a deep RL system. I know that skillful work is underway with optimizing the placement of devices for large tensor graphs (Mirhoseini et al, ICML 2017). Salesforce has a text-summarization model that works if you use RL fairly carefully. Financial companies are probably experimenting with RL while you read this article, but there is no evidence for this yet. (Of course, financial companies have reasons to hide their methods of playing in the market, so we can never get solid evidence). Facebook works great with deep RL for chatbots and speech. Every Internet company in history has probably ever thought about introducing RL into its advertising model, but if someone actually implemented RL, then it is silent about it.
So, in my opinion, either deep RL is still the topic of academic research, not a reliable technology for widespread use, or it can really be made to work effectively - and the people who succeeded do not disclose the information. I think the first option is more likely.
If you came to me with the problem of classifying images, I would advise pre-trained ImageNet models - they will probably do the job well. We live in a world where filmmakers from the Silicon Valley series jokingly make a real AI application for recognizing hot dogs . I can not say about the same success of deep RL.
This is a priori difficult question. The problem is that you are trying to apply the same RL approach to different environments. It is only natural that it will not always work.
Based on the foregoing, some conclusions can be drawn from the existing achievements of reinforced learning. These are projects where the deep RL either learns some kind of qualitatively impressive behavior, or learns better than previous systems in this area (although these are very subjective criteria).
Here is my list at the moment.
(Brief digression: machine learning recently beat professional unlimited Texas Hold'em players. The program uses both Libratus (Brown et al, IJCAI 2017) and DeepStack (Moravčík et al, 2017) . I spoke with several people who thought they worked here deep RL. Both systems are very cool, but they don’t use deep learning with reinforcement. It uses an algorithm of counterfactual minimization of regret and a competent iterative solution to subgames).
From this list, you can isolate common properties that facilitate learning. None of these properties, listed below, are required for training, but the more they are present, the better the result will definitely be.
You can combine several principles and analyze the success of Neural Architecture Search. According to the original version of ICLR 2017 , after 12,800 samples, deep RL is able to design the best-of-its-kind neural network architectures. Admittedly, in each example, it was necessary to train the neural network to convergence, but it is still very effective in the number of samples.
As mentioned above, the reward is validation accuracy. This is a very rich reward signal - if a change in the structure of the neural network improves accuracy from just 70% to 71%, RL will still benefit from it. In addition, there is evidence that hyperparameters in deep learning are close to linearly independent. (This has been empirically shown in the workHyperparameter Optimization: A Spectral Approach (Hazan et al, 2017) - my resume here , if interested). NAS does not specifically configure hyperparameters, but I think it’s quite reasonable that neural network design decisions are made in this way. This is good news for learning, given the strong correlations between solution and performance. Finally, here is not only a rich reward, but here is exactly what is important to us when teaching models.
Together, these reasons make it clear why the NAS requires “only” about 12,800 trained networks to determine the best neural network compared to the millions of examples needed in other environments. From different sides, everything plays in favor of RL.
In general, such success stories are still the exception, not the rule. Many pieces of the puzzle must be correctly folded so that reinforced learning works convincingly, and even then it will be difficult.
In general, now deep RL cannot be called a technology that works right out of the box.
There is an old saying - every researcher learns over time how to hate his field of research. The joke is that researchers still continue to do this because they like the problems too much.
This is about how I feel about reinforced deep learning. Despite all of the above, I am absolutely sure that we need to try to use RL on various problems, including those where it is most likely to be ineffective. But how else can we improve RL?
I see no reason why deep RL will not work in the future, if technology is given time for improvement. Some very interesting things will begin to happen when the deep RL becomes reliable enough for widespread use. The question is how to achieve this.
Below I have listed some plausible future development options. If further research is needed to develop in this direction, then links to relevant scientific articles in these areas are indicated.
Local optima are good enough . It would be arrogance to say that people themselves are globally optimal in everything. I would say that we are slightly better than other species optimized to create civilization. In the same vein, the RL solution does not have to strive for global optima if its local optima exceed the basic level of a person.
Iron will solve everything. I know people who believe that the most important thing for creating AI is simply to increase the speed of iron. Personally, I am skeptical that iron will solve all problems, but it certainly will make an important contribution. The faster everything works, the less you are concerned about the inefficiency of the samples and the easier it is to break through brute force through intelligence problems.
Add more training signals . Sparse rewards are difficult to learn, because there is very little information about what exactly gives the effect. It is possible that we will either generate positive rewards in the form of hallucinations ( Hindsight Experience Replay, Andrychowicz et al, NIPS 2017 ), or define supporting tasks ( UNREAL, Jaderberg et al, NIPS 2016), or we will build a good model of the world, starting with self-controlled learning. Add the cherry on the cake, so to speak.
Model-based training will increase sample efficiency . Here's how I describe RL based on the model: "Everyone wants to do it, but few know how." In principle, a good model fixes a bunch of problems. As can be seen in the example of AlphaGo, the presence of a model in principle greatly facilitates the search for a good solution. Good models of the world are well transferred to new tasks, and the introduction of a model of the world allows us to imagine new experiences. In my experience, model-based solutions also require fewer samples.
But training a good model is a difficult thing. I got the impression that low-dimensional state models sometimes work, but image models are usually too difficult. But if they become easier, some interesting things can happen.
Dyna (Sutton, 1991) and Dyna-2 (Silver et al., ICML 2008) are classic works in this area. As examples of work where model-based learning is combined with deep-seated networks, I would recommend several recent articles from the Berkeley Robotics Laboratory:
Using reinforcement learning is easy as a tweak . The first AlphaGo article began with teacher training and fine-tuning RL. This is a good option because it speeds up initial training using a faster, but less powerful way. This method also worked in a different context - see Sequence Tutor (Jaques et al, ICML 2017) . You can consider it as the beginning of the RL process with a reasonable, rather than random, prior distribution of probabilities (prior), where another system is involved in creating this “prior”.
Reward Functions Can Be Learnable. Machine learning promises that on the basis of data, you can learn to build things better than those designed by man. If it is so difficult to choose a reward function, then why not use machine learning for this task? Simulation learning and the reverse of RL - these rich areas have shown that reward functions can be implicitly determined by confirmations or ratings from a person.
The most famous scientific papers on reverse RL and simulation training are Algorithms for Inverse Reinforcement Learning (Ng and Russell, ICML 2000) , Apprenticeship Learning via Inverse Reinforcement Learning (Abbeel and Ng, ICML 2004) and DAgger (Ross, Gordon, and Bagnell, AISTATS 2011) .
Recent works that expand these ideas into the field of deep learning include Guided Cost Learning (Finn et al, ICML 2016) , Time-Constrastive Networks (Sermanet et al, 2017) and Learning From Human Preferences (Christiano et al, NIPS 2017) . In particular, the last of the listed articles shows that the remuneration derived from the ratings put by people actually turned out to be better (better-shaped) for training than the original hard-coded remuneration - and this is a good practical result.
Of the long-term jobs that do not use in-depth training, I liked the articles by Inverse Reward Design (Hadfield-Menell et al, NIPS 2017) andLearning Robot Objectives from Physical Human Interaction (Bajcsy et al, CoRL 2017) .
Learning transfer . Learning transfer promises that you can use the knowledge from previous tasks to speed up learning new tasks. I am absolutely sure that this is the future, when training will become reliable enough to solve disparate tasks. It is difficult to transfer training if you cannot study at all, and if there are tasks A and B, it is difficult to predict whether the transfer of training from task A to task B will occur. In my experience, here is either a very obvious answer or completely incomprehensible. And even in the most obvious cases, a non-trivial approach is required.
Recent work in this area is the Universal Value Function Approximators (Schaul et al, ICML 2015) ,Distral (Whye Teh et al, NIPS 2017) and Overcoming Catastrophic Forgetting (Kirkpatrick et al, PNAS 2017) . For older works, see Horde (Sutton et al, AAMAS 2011) .
For example, robotics shows good progress in transferring training from simulators to the real world (from simulating a task to a real task). See Domain Randomization (Tobin et al, IROS 2017) , Sim-to-Real Robot Learning with Progressive Nets (Rusu et al, CoRL 2017) and GraspGAN (Bousmalis et al, 2017) . (Disclaimer: I worked on GraspGAN).
Good priors can greatly reduce training time.. This is closely related to some of the previous points. On the one hand, the transfer of learning is to use past experience to create good a priori probability distributions (priors) for other tasks. RL algorithms are designed to work on any Markov decision-making process - and here there is a problem with generalization. If we believe that our solutions work well only in a narrow sector of environments, then we should be able to use a common structure to effectively solve these environments.
In her speeches, Pieter Ebbill likes to note that the deep RL needs to be asked only the tasks that we solve in the real world. I agree that this makes a lot of sense. There must be some real-world prior, which allows us to quickly learn new real tasks through slower learning of unrealistic tasks, and this is a perfectly acceptable compromise.
The difficulty is that such a real-world prior is very difficult to design. However, I think there is a good chance that this is still possible. Personally, I am delighted with recent work on meta-training, because it provides a way to generate reasonable priors from data. For example, if I want to use RL to navigate a warehouse, it would be interesting to first use meta-training to teach good navigation in general, and then fine-tune this prior for a specific warehouse where the robot will move. This is very similar to the future, and the question is whether meta-training will get there or not.
For a summary of the latest learning-to-learn work, see this publication from BAIR (Berkeley AI Research) .
More complex environments can paradoxically be easier. One of the main conclusions of the DeepMind article on parkour-bot is that if you complicate the task very much by adding several variations of the tasks, then in reality you simplify the training, because the rules cannot retrain in one setting without losing performance in all other parameters . We saw something similar in articles on domain randomization and even in ImageNet: models trained in ImageNet can expand to other environments much better than those trained on CIFAR-100. As I said, perhaps we only need to create some “ImageNet for management” in order to move to a much more universal RL.
There are many options. OpenAI Gym is the most popular environment, but there is also the Arcade Learning Environment ,Roboschool , DeepMind Lab , DeepMind Control Suite, and ELF .
Finally, although this is insulting from an academic point of view, the empirical problems of deep RL may not matter from a practical point of view. As a hypothetical example, imagine that a financial company uses deep RL. They train a sales agent on past US stock market data using three random sids. In real A / B testing, the first seed brings 2% less income, the second works with average profitability, and the third brings 2% more. In this hypothetical version, reproducibility does not matter - you simply deploy a model whose profitability is 2% higher and rejoice. Similarly, it does not matter that a sales agent can work well only in the United States: if it does not expand well in the world market - just do not use it there. There is a big difference between an extraordinary system and a reproducible extraordinary system. Perhaps you should focus on the first.
In many ways, the current state of deep RL annoys me. Nevertheless, it attracts such strong interest among researchers, which I have not seen in any other field. My feelings are best expressed by the phrase Andrew Eun mentioned in his talk with Nuts and Bolts of Applying Deep Learning : strong pessimism in the short term, balanced by even stronger long-term optimism. Now deep RL is a bit chaotic, but I still believe in the future.
However, if someone again asks me if reinforcement learning (RL) can solve their problem, I will still immediately answer that no, I won’t. But I will ask you to repeat this question in a few years. By then, perhaps everything will work out.
It mainly cites articles from Berkeley, Google Brain, DeepMind, and OpenAI over the past few years, because their work is most visible from my point of view. I almost certainly missed something from older literature and from other organizations, so I apologize - I'm just one person, after all.
Introduction
Once on Facebook I stated the following.
When someone asks if reinforcement learning (RL) can solve their problem, I immediately answer that I can’t. I think that this is true in at least 70% of cases.Deep learning with reinforcement is accompanied by a mass of hype. And there are good reasons! Reinforced Learning (RL) is an incredibly common paradigm. In principle, a reliable and high-performance RL system should be perfect in everything. The fusion of this paradigm with the empirical power of deep learning is self-evident. Deep RL is what looks most like a strong AI, and it's a kind of dream that fuels billions of dollars of funding.
Unfortunately, in reality this thing does not work yet.
But I believe that she will shoot. If I didn’t believe, I wouldn’t cook in this topic. But there are a lot of problems ahead, many of which are fundamentally complex. Beautiful demos of trained agents hide all the blood, sweat and tears that spilled during their creation.
Several times I saw people seduced by recent results. They first tried deep RL and always underestimated the difficulties. Without a doubt, this “model task" is not as simple as it seems. And without a doubt, this area broke them several times before they learned to set realistic expectations in their research.
There is no one's personal mistake. This is a system problem. It's easy to draw a story around a positive outcome. Try to do this with a negative. The problem is that researchers most often get exactly a negative result. In a sense, such results are even more important than positive ones.
In this article, I will explain why deep RL does not work. I will give examples when it still works and how to achieve more reliable work in the future, in my opinion. I do this not to stop people working on deep RL, but because it’s easier to make progress if everyone understands the problems. It is easier to reach agreement if you really talk about problems, and not again and again stumble upon the same rake separately from each other.
I would like to see more research on the topic of deep RL. So that new people come here. And so that they know what they are getting involved in.
Before proceeding, let me make a few remarks.
- Several scientific articles are cited here. Usually I give convincing negative examples and I am silent about the positive ones. This does not mean that I do not like scientific work . They are all good - worth a read if you have the time.
- I use the terms “reinforcement learning” and “deep reinforcement learning” as synonyms because in my daily work RL always implies deep RL. It criticizes the empirical behavior of deep learning with reinforcement rather than learning with reinforcement in general . The cited articles usually describe the work of an agent with a deep neural network. Although empirically criticism may also apply to linear RL (linear RL) or tabular RL (tabular RL), I'm not sure that this criticism can be extended to smaller tasks. The hype surrounding deep RL is due to the fact that RL is presented as a solution for large, complex, multidimensional environments where a good approximating function is needed. It is with this hype, in particular, that we need to sort it out.
- The article is structured to move from pessimism to optimism. I know that it is a bit long, but I will be very grateful if you take the time to read it in its entirety before answering.
Without further ado, here are some of the cases where deep RL crashes.
Reinforced deep learning can be terribly ineffective
The most famous benchmark for deep learning with reinforcements is Atari games. As shown in the well-known article Deep Q-Networks (DQN), if you combine Q-Learning with neural networks of a reasonable size and some optimization tricks, you can achieve human performance in several Atari games or surpass them.
Games Atari games run at 60 frames per second. Can you immediately figure out how many frames you need to process the best DQN to show the result as a person?
The answer depends on the game, so take a look at a recent Deepmind article - Rainbow DQN (Hessel et al, 2017). It shows how some of the consecutive enhancements to the original DQN architecture improve the outcome, and combining all the improvements is most effective. The neural network surpasses the human result in more than 40 of 57 Atari games. The results are shown in this convenient chart.
The vertical axis shows the “median average result normalized to human”. it is calculated by training 57 DQN neural networks, one for each Atari game, with normalizing the result of each agent when the human result is taken as 100%, and then calculating the average median result for 57 games. RainbowDQN exceeds 100% after processing 18 millionframes. This corresponds to approximately 83 hours of play, plus time to learn, no matter how long it takes. This is a lot of time for the simple Atari games that most people grab in a couple of minutes.
Keep in mind that 18 million frames is actually a very good result, because the previous record belonged to the Distributional DQN system (Bellemare et al, 2017) , which required 70 million frames to achieve a 100% result, i.e. about four times as much time. As for Nature DQN (Mnih et al, 2015) , it generally never reaches 100% median result, even after 200 million frames.
The cognitive bias of the “planning error” says that completing a task usually takes longer than you expected. Reinforcement learning has its own planning mistake - training usually requires more samples than you thought.
The problem is not limited to Atari games. The second most popular test is the MuJoCo benchmarks, a set of tasks in the MuJoCo physics engine. In these tasks, the position and speed of each hinge in a simulation of a robot are usually given at the input. Although there is no need to solve the problem of vision, RL systems are required for training from
before steps, depending on the task. This is incredible for control in such a simple environment. A Parkour DeepMind article (Heess et al, 2017) , illustrated below, has been trained using 64 workers for over 100 hours. The article does not specify what a worker is, but I assume that this means a single processor.
This is a super result . When he first came out, I was surprised that the deep RL was generally able to learn such gait on the run.
But it took 6400 hours of processor time, which is a bit disappointing. Not that I expected less time ... it’s just sad that in simple skills the deep RL is still an order of magnitude inferior to the level of training that could be useful in practice.
There is an obvious counterargument here: what if you simply ignore the effectiveness of the training? There are certain environments that make it easy to generate experience. For example, games. But for any environment where this is not possible , RL faces enormous challenges. Unfortunately, most environments fall into this category.
If you care only about the final performance, then many problems are better solved by other methods.
When searching for solutions to any problem, you usually have to find a compromise in achieving different goals. You can focus on a really good solution to this particular problem, or you can focus on the maximum contribution to the overall research. The best problems are those where a good contribution to research is required to get a good solution. But in reality, it is difficult to find problems that meet these criteria.
Purely in demonstrating maximum efficiency, the deep RL does not show very impressive results, because it is constantly superior to other methods. Here's a video of MuJoCo robots that are controlled by interactive path optimization. Correct actions are calculated almost in real time, interactively, without offline learning. Yes, and everything works on the equipment of 2012 (Tassa et al, IROS 2012 ).
I think this work can be compared with a DeepMind article on parkour. What is the difference?
The difference is that here the authors apply control with predictive models, working with a real model of the earth’s world (physical engine). There are no such models in RL, which greatly complicates the work. On the other hand, if model-based action planning improves the outcome so much, then why bother with tricked out RL training?
Similarly, you can easily outperform the Atari DQN neural networks with the Monte Carlo (MCTS) turnkey tree search solution. Here are the key metrics from Guo et al, NIPS 2014 . The authors compare the results of trained DQNs with the results of the UCT agent (this is a standard version of modern MCTS).
Again, this is an unfair comparison, because the DQN does not search, and the MCTS does exactly the search using a real model of terrestrial physics (Atari emulator). But in some situations, you don’t care, here is an honest or dishonest comparison. Sometimes you just need it to work (if you need a full UCT assessment, see the appendix in the original scientific article Arcade Learning Environment (Bellemare et al, JAIR 2013 ).
Reinforced learning is theoretically suitable for everything, including environments with an unknown model of the world. However, such versatility is expensive: it is difficult to use any specific information that could help in learning. Because of this, you have to use a lot of samples to learn things that could just be hard-coded from the very beginning.
Experience has shown that, with the exception of rare cases, algorithms tailored to specific tasks work faster and better than reinforced learning. It’s not a problem if you are developing deep-seated RL for the sake of deep-seated RL, but I personally find it frustrating to compare the effectiveness of RL c ... well, with anything else. One of the reasons why I liked AlphaGo so much is because it was a definite victory for the deep RL, and this does not happen very often.
Because of all this, it’s more difficult to explain to people why my tasks are so cool, complex and interesting, because often they don’t have context or experience to evaluate whythey are so complicated. There is a definite difference between what people think about the capabilities of deep RL - and its real capabilities. Now I work in the field of robotics. Consider a company that comes to the minds of most people if you mention robotics: Boston Dynamics.
This thing does not use reinforcement training. Several times I met people who thought that RL was used here, but no. If you look for published scientific papers from a group of developers, you will find articles mentioning time-varying linear-quadratic regulators, solvers of quadratic programming problems and convex optimization . In other words, they mainly apply the classical methods of robotics. It turns out that these classic techniques work fine if properly applied.
Reinforcement training usually requires a reward function
Reinforced learning implies the existence of a reward function. Usually it is either there initially, or manually configured in offline mode and remains unchanged during training. I say “usually” because there are exceptions, such as simulation training or the opposite of RL (when the reward function is restored ex post), but in most cases RL uses reward as an oracle.
It’s important to note that for RL to work properly, the reward function must cover exactly what we need. And I mean exactly. RL is annoyingly prone to overfit, which leads to unexpected consequences. That's why Atari is such a good benchmark. It’s not only easy to get a lot of samples there, but every game has a clear goal - the number of points, so you never have to worry about finding a reward function. And you know that everyone else has the same function.
The popularity of MuJoCo tasks is due to the same reasons. Since they work in simulation, you have complete information about the state of the object, which greatly simplifies the creation of the reward function.
In the Reacher task, you control a two-segmented arm that is connected to a center point, and the goal is to move the end of the arm to a given target. See below for an example of successful learning.
Since all coordinates are known, the reward can be defined as the distance from the end of the hand to the target, plus a short time to move. In principle, in the real world you can do the same experiment if you have enough sensors to accurately measure the coordinates. But depending on what the system needs to do, it can be difficult to determine a reasonable reward.
The reward function itself would not be a big problem if it weren't for ...
The complexity of developing a reward function
Making the reward function is not so difficult. Difficulties arise when you try to create a function that will encourage proper behavior, and at the same time, the system will retain learning.
In HalfCheetah, we have a two-legged robot bounded by a vertical plane, which means that it can only move forward or backward. The goal is to learn to jog. The reward is the speed of HalfCheetah ( video ). This is a smooth or shaped (shaped) reward, that is, it increases with approach to the ultimate goal. Unlike sparse
(sparse) remuneration, which is given only upon reaching the final state of the goal, and in other states is absent. The smooth growth of remuneration is often much easier to learn, because it provides positive feedback, even if training did not provide a complete solution to the problem.
Unfortunately, rewards with smooth growth can be biased. As already mentioned, because of this, unexpected and undesirable behavior is manifested. A good example is boat racing from an OpenAI blog article . The intended goal is to reach the finish line. You can imagine a reward as +1 for the end of the race at a given time, and a reward of 0 otherwise.
The reward function gives points for crossing checkpoints and for collecting bonuses that allow you to quickly reach the finish line. As it turned out, collecting bonuses gives more points than the completion of the race.
To be honest, this publication was a little annoying at first. Not because she is wrong! But because it seemed to me that she was demonstrating obvious things. Of course, reinforced learning will give a strange result when the reward is incorrectly defined! It seemed to me that the publication attached unjustifiably great importance to this particular case.
But then I started writing this article and realized that the most convincing example of an incorrectly defined reward is just this very video with boat races. Since then, it has been used in several presentations on this topic, which attracted attention to the problem. So all right, I reluctantly admit that it was a good blog post.
RL algorithms fall into a black hole if they have to more or less guess about the world around them. The most versatile category of modelless RLs is almost like black box optimization. Such systems are only allowed to assume that they are in the MDP (Markov decision-making process) - and nothing more. The agent is simply told that this is what you get +1 for, but you don’t get it for this, and you should find out the rest yourself. As with the optimization of the black box, the problem is that any behavior that gives +1 is considered good, even if the reward is received in the wrong way.
A classic example is not from the sphere of RL - when someone applied genetic algorithms for the design of microcircuits and received a scheme in whichthe final design needed one unconnected logic gate .
Gray elements are necessary for the correct operation of the circuit, including the element in the upper left corner, although it is not connected to anything. From the article “An Evolved Circuit, Intrinsic in Silicon, Entwined with Physics”
Or a more recent example, here's a 2017 Salesforce blog post . Their goal was to compose a summary for the text. The basic model was taught with a teacher, then it was evaluated by an automated metric called ROUGE. ROUGE is an undifferentiated reward, but RL can work with such. So they tried to apply RL to optimize ROUGE directly. This gives a high ROUGE (cheers!), But not really good lyrics. Here is an example.
Button deprived him of the 100th race for McLaren after the ERS did not let him start. So ended a bad weekend for the Briton. Button ahead of qualifications. Finished ahead of Nico Rosberg in Bahrain. Lewis Hamilton. In 11 races .. Race. To lead 2000 laps .. In ... I. - Paulus et al, 2017
And although the RL model showed the maximum ROUGE result ...
... they eventually decided to use another model for compiling a resume.
Another fun example. This is from an article by Popov et al, 2017 , also known as an “article on folding Lego constructor.” The authors use a distributed version of DDPG to teach capture rules. The goal is to grab the red cube and put it on the blue.
They made her work, but faced an interesting case of failure. The initial lifting movement is rewarded based on the lifting height of the red block. This is determined by the z-coordinate of the bottom face of the cube. In one of the failure options, the model learned to turn the red cube with the bottom face up, and not raise it.
Clearly, this behavior was not intended. But RL doesn't care. In terms of reinforcement training, she received a reward for turning the cube - so she will continue to turn the cube.
One way to solve this problem is to make the reward sparse, giving it only after connecting the cubes. Sometimes this works because a rare reward lends itself to learning. But often this is not so, since the lack of positive reinforcement makes things all too complicated.
Another solution to the problem is the careful formation of remuneration, the addition of new remuneration conditions and the adjustment of coefficients for existing conditions until the RL algorithm begins to demonstrate the desired learning behavior. Yes maybefight RL on this front, but such a struggle is not satisfying. Sometimes it is necessary, but I never felt that I had learned something in the process.
For reference, here is one of the reward functions from an article on folding Lego constructor.
I don’t know how much time the guys spent on developing this feature, but I would say “a lot” by the number of members and different coefficients.
In conversations with other RL researchers, I heard several stories about the original behavior of models with incorrectly set rewards.
- A colleague teaches an agent to navigate in a room. The episode ends if the agent goes beyond the borders, but in this case a fine is not imposed. At the end of the training, the agent adopted suicidal behavior because negative rewards were very easy to obtain and positive rewards too difficult, so a quick death with a result of 0 was preferable to a long life with a high risk of a negative result.
- A friend trained a robot arm simulator to move toward a specific point above a table. It turns out that the point was defined relative to the table , and the table was not attached to anything. The model learned to knock on the table very hard, causing it to fall, which moved the target point - and she was next to the hand.
- The researcher talked about the use of RL for training a simulator of a robotic arm to take a hammer and hammer a nail. The reward was originally determined by how far the nail went into the hole. Instead of picking up a hammer, the robot hammered a nail with its own limbs. Then they added rewards to encourage the robot to pick up the hammer. As a result, the learned strategy for the robot was to take a hammer ... and throw the tool into the nail, and not use it in a normal way.
True, all this is stories from the wrong lips, personally, I have not seen videos with this behavior. But not one of these stories seems impossible to me. I got burned on RL too many times to believe otherwise.
I know people who like to tell stories about paper optimizers . Okay, I understand honestly. But in truth, I'm tired of listening to these stories, because they always speak of some superhuman disoriented, strong AI as a real story. Why invent it if there are so many real stories around that happen every day.
Even with good rewards, it is difficult to avoid a local optimum.
Previous RL examples are often referred to as "reward hacks." As for me, this is a smart, non-standard solution that brings more reward than the expected solution from the task designer.
Hacking rewards are exceptions. Much more common are cases of incorrect local optima that result from the wrong compromise between exploration and exploitation.
Here is one of my favorite videos . It implements the normalized benefit feature that is trained in HalfCheetah. From the perspective of an outsider, this is very, very
stupid. But we call it stupid only because we look from the side and have a lot of knowledge that moving on your feet is better than lying on your back. RL does not know this! He sees a state vector, sends action vectors and sees that he is receiving some positive reward. That's all.
Here is the most plausible explanation that I can come up with about what happened during the training.
- In a random research process, the model found that falling forward is more profitable than staying motionless.
- The model has done this often enough to “flash” this behavior and begin to fall continuously.
- After falling forward, the model found out that if you apply enough force, you can do a back flip, which gives a little more reward.
- The model often did a backflip - and made sure that it was a good idea, so now the reverse backflip is “flashed” into constant behavior.
- With the condition of constant backward flips, what is easier for the model to learn corrected behavior and follow the “standard path” or learn how to move forward while lying on your back? I would put on the second option.
This is very funny, but obviously not what we want from the robot.
Here is another unsuccessful example, this time surrounded by Reacher ( video ) In this run, random initial weights, as a rule, gave out strongly positive or very negative values for actions. Because of this, most of the actions were performed with the maximum or minimum possible acceleration. In fact, it is very easy to spin up a model very much: just give a high amount of force to each hinge. When the robot spins, it is already difficult to get out of this state in some understandable way: in order to stop the rampant rotation, several reconnaissance steps should be taken. Of course, this is possible. But this did not happen in this run.
In both cases, we see the classic reconnaissance / exploitation problem, which, from time immemorial, has pursued reinforced learning. Your data is derived from current rules. If the current rules provide for extensive intelligence, you will receive unnecessary data and learn nothing. Exploit too much - and “sew” non-optimal behavior.
There are several intuitively pleasant ideas on this subject - internal motives and curiosity, intelligence based on counting, etc. Many of these approaches were first proposed in the 80s or earlier, and some were later revised for deep learning models. But as far as I know, no approach works stably in all environments. Sometimes it helps, sometimes not. It would be nice for some kind of intelligence trick to work everywhere, but I doubt that in the foreseeable future they will find a silver bullet of this caliber. Not because no one is trying, but because exploration-exploitation is a very, very, very, very complicated matter. Quote from the Wikipedia multi-armed bandit article :
For the first time in history, this problem was studied by scientists of the Allied countries of World War II. It turned out to be so intractable that, according to Peter Whittle, it was suggested that they be thrown to the Germans so that German scientists would also spend their time on it.(Source: Q-Learning for Bandit Problems, Duff 1995 )
I present the deep RL as a demon who deliberately misunderstands your reward and is actively looking for the laziest way to achieve a local optimum. A bit ridiculous, but it turned out to be really productive thinking.
Even if deep RL works, it can retrain to strange behavior
Deep learning is popular because it is the only area of machine learning where it is socially acceptable to learn on a test suite.( Source ) The
positive side of reinforcement training is that if you want to achieve a good result in a particular environment, you can retrain as a madman. The disadvantage is that if you need to extend the model to any other environment, it will probably work poorly due to crazy retraining.
DQN networks cope with many Atari games, because all the training of each model is focused on a single goal - to achieve maximum results in one game. The final model cannot be expanded to other games because it wasn’t taught that way. You can configure the trained DQN for the new Atari game (see Progressive Neural Networks (Rusu et al, 2016)), but there is no guarantee that such a transfer will take place, and usually no one expects this. This is not the wild success that people see on the pre-trained features of ImageNet.
To prevent some obvious comments: yes, in principle, training on a wide range of environments can solve some problems. In some cases, such an extension of the action of the model occurs by itself. An example is navigation, where you can try random locations of targets and use universal functions to generalize. (see Universal Value Function Approximators, Schaul et al, ICML 2015) I consider this work very promising, and later I will give more examples from this work. But I think that the possibilities of generalizing deep RL are not so great as to cope with a diverse set of tasks. The perception has become much better, but the deep RL is still ahead of the moment when “ImageNet for management” appears. The OpenAI Universe tried to light this bonfire, but from what I heard, the task was too complicated, so they did little.
While there is no such moment for generalizing models, we are stuck with surprisingly narrow models in scope. As an example (and as an excuse to laugh at my own work), look at the Can Deep RL Solve Erdos-Selfridge-Spencer Games article ? (Raghu et al, 2017). We studied a combinatorial game for two players, where there is a solution in an analytical form for an optimal game. In one of the first experiments, we recorded the behavior of player 1, and then trained player 2 using RL. In this case, you can consider the actions of player 1 as part of the environment. Teaching player 2 against optimal player 1, we have shown that RL is able to show high results. But when we applied the same rules against non-optimal player 1, then the effectiveness of player 2 fell because it did not apply to non-optimal opponents.
Authors of the article Lanctot et al, NIPS 2017got a similar result. Here two agents are playing laser tag. Agents are trained using multi-agent reinforcement training. To test the generalization, training was launched with five random starting points (sids). Here is a video of agents who were trained to play against each other.
As you can see, they learned to get close and shoot at each other. Then the authors took player 1 from one experiment - and brought him together with player 2 from another experiment. If the learned rules are generalized, then we should see a similar behavior.
Spoiler: we will not see him.
This seems to be a common multi-agent RL problem. When agents are trained against each other, a kind of joint evolution takes place. Agents are trained to really fight each other really well, but when they are directed against a player whom they have not met before, their effectiveness decreases. I want to note that the only difference between these videos is random seed. The same learning algorithm, the same hyperparameters. The difference in behavior is purely due to the random nature of the initial conditions.
Nevertheless, there are some impressive results obtained in an environment with independent play against each other - they seem to contradict the general thesis. The OpenAI Blog has a good post about some of their work in this area.. Do-it-yourself play is also an important part of AlphaGo and AlphaZero. My intuitive hunch is that if agents learn at the same pace, they can constantly compete and speed up each other’s learning, but if one of them learns much faster than the other, then he uses the weak player’s vulnerabilities too much and retrains. As you move from a symmetrical stand-alone game to common multi-agent settings, it becomes much more difficult to make sure that the training is at the same speed.
Even without taking into account generalization, it may turn out that the final results are unstable and difficult to reproduce.
Almost every machine learning algorithm has hyperparameters that affect the behavior of the learning system. Often they are selected manually or by random search.
Teacher training is stable. Fixed dataset, checking with true data. If you slightly change the hyperparameters, the functioning will not change too much. Not all hyperparameters work well, but many empirical tricks have been found over the years, so many hyperparameters show signs of life during training. These signs of life are very important: they say that you are on the right track, doing something reasonable - and you need to devote more time.
Currently, deep RL is not at all stable, which is very annoying in the research process.
When I started working in Google Brain, I almost immediately began to implement the algorithm from the above article Normalized Advantage Function (NAF). I thought it would only take two to three weeks. I had a few trump cards: a certain acquaintance with Teano (which is well ported to TensorFlow), some experience with deep RL, and the lead author of the NAF article interned in Brain, so I could pester him with questions.
In the end, it took me six weeks to reproduce the results, due to several bugs in the software. The question is, why did these bugs hide for so long?
To answer this question, consider the simplest continuous management task in OpenAI Gym: the Pendulum task. In this problem, the pendulum is fixed at a certain point and gravity acts on it. The input is a three-dimensional state. The space of action is one-dimensional: it is a moment of force that is applied to the pendulum. The goal is to balance the pendulum in exactly vertical position.
This is a small problem, and it becomes even easier thanks to well-defined remuneration. The reward depends on the angle of the pendulum. Actions that bring the pendulum to a vertical position, not only give a reward, they increase it.
Here is a video of a model that is almostworks. Although it does not bring the pendulum into an exactly vertical position, it provides an exact moment of force to compensate for gravity. And here is a performance graph after fixing all the errors. Each line is a reward curve from one of ten independent runs. The same hyperparameters, the difference is only in a random starting point. Seven out of ten runs worked well. Three did not pass. A 30% failure rate is considered operational . Here is another graph from Variational Information Maximizing Exploration (Houthooft et al, NIPS 2016) . Wednesday - HalfCheetah. The award was made sparse, although the details are not too important. The y-axis is episodic reward, the x-axis is the number of time slices, and the algorithm used is TRPO.
The dark line is the median performance for ten random sids, and the shaded area is coverage from the 25th to the 75th percentile. Don't get me wrong, this graph seems like a good argument for VIME. But on the other hand, the line of the 25th percentile is really close to zero. This means that about 25% do not work simply because of a random starting point.
Look, in teaching with a teacher there is also variance, but not so bad. If my training code did not cope with a teacher in 30% of runs with random sids, then I would be absolutely sure that some kind of error occurred while loading data or training. If my training code with reinforcements copes no better than randomness, then I have no idea whether it is a bug, or bad hyperparameters, or I’m just out of luck.
This is an illustration from the article “Why is machine learning so“ difficult ”to work with?” The main point is that machine learning adds extra dimensions to the crash space, which exponentially increases the number of crash options. Deep RL adds another dimension: randomness. And the only way to solve the problem of randomness is to clean out the noise.
If your learning algorithm has inefficient sampling and is not stable at the same time, then it greatly reduces the productivity of your research. Maybe he will need only 1 million steps. But when you multiply this by five random input values, and then multiply by the spread of the hyperparameters, you will see an exponential increase in the calculations needed to effectively test the hypothesis.
If it becomes easier for you, then I have been doing this for some time - and spent about 6 last weeks to get the model gradients from scratch, which work in 50% of cases on a bunch of RL tasks. And I have a GPU cluster and some friends with whom I have lunch every day - and they have been working in this area for the past few years.
In addition, the information received from the field of training with the teacher about the correct design of convolutional neural networks does not seem to extend to the field of training with reinforcement, because the main limitations are credit distribution / bitrate control, and not the lack of effective presentation. Your ResNet, batchnorm and very deep networks do not work here.
[Teacher training] wants to work. Even if you ruin something, you usually get some kind of nonrandom result. RL needs to be made to work. If you ruin something or don’t configure something well enough, you will almost certainly get rules that are worse than random ones. And even if everything is perfectly tuned, then bad results will be in 30% of cases. Why? Just because.
In short, your problems are more likely due to the complexity of the deep RL than the complexity of "designing neural networks." - Comment on Hacker News by Andrej Karpathy when he worked at OpenAI
The instability of random seeds is like a canary in a coal mine. If a simple coincidence leads to such a strong difference between runs, then imagine what the difference would be with a real code change.
Fortunately, we do not need to conduct this thought experiment because it has already been carried out and described in the article “Deep Reinforcement Learning That Matters” (Henderson et al, AAAI 2018) . Here are some conclusions:
- Multiplying rewards by a constant can lead to a significant difference in performance.
- Five random seeds (the general metric in the reports) may not be enough to demonstrate significant results, since careful selection can result in non-overlapping confidence intervals.
- Different implementations of the same algorithm have different performance for the same task, even with the same hyperparameters.
My theory is that RL is very sensitive to both initialization and the dynamics of the educational process, because data is always collected on the Internet and the only parameter that is controlled is the size of the reward. Models that randomly encounter good training examples work much better. If the model does not see good examples, then it may not learn anything at all, as it is increasingly becoming convinced that any deviations are inconclusive.
But what about all the great achievements of deep RL?
Of course, in-depth reinforcement learning has achieved some excellent results. DQN is no longer a novelty, but at one time it was an absolutely crazy discovery. The same model is studied directly by pixels, without adjusting for each game individually. Both AlphaGo and AlphaZero also remain very impressive achievements.
But besides these successes, it is difficult to find cases where deep RL has practical value for the real world.
I tried to think about how you can use deep RL in the real world for practical tasks - and this is surprisingly difficult. I thought that I would find some use in recommendation systems, but in my opinion collaborative filtering and contextual bandits still dominate there .
The best thing that I finally found was two Google projects: reducing energy consumption in data centers and the recently announced AutoML Vision project . Jack Clark of OpenAI tweeted a similar question to readers - and came to the same conclusion . (Tweet last year, before the announcement of AutoML).
I know that Audi is doing something interesting with deep RL, because on NIPS they showed a small model of an unmanned racing car and said that they had developed a deep RL system. I know that skillful work is underway with optimizing the placement of devices for large tensor graphs (Mirhoseini et al, ICML 2017). Salesforce has a text-summarization model that works if you use RL fairly carefully. Financial companies are probably experimenting with RL while you read this article, but there is no evidence for this yet. (Of course, financial companies have reasons to hide their methods of playing in the market, so we can never get solid evidence). Facebook works great with deep RL for chatbots and speech. Every Internet company in history has probably ever thought about introducing RL into its advertising model, but if someone actually implemented RL, then it is silent about it.
So, in my opinion, either deep RL is still the topic of academic research, not a reliable technology for widespread use, or it can really be made to work effectively - and the people who succeeded do not disclose the information. I think the first option is more likely.
If you came to me with the problem of classifying images, I would advise pre-trained ImageNet models - they will probably do the job well. We live in a world where filmmakers from the Silicon Valley series jokingly make a real AI application for recognizing hot dogs . I can not say about the same success of deep RL.
Given these limitations, when to use deep RL?
This is a priori difficult question. The problem is that you are trying to apply the same RL approach to different environments. It is only natural that it will not always work.
Based on the foregoing, some conclusions can be drawn from the existing achievements of reinforced learning. These are projects where the deep RL either learns some kind of qualitatively impressive behavior, or learns better than previous systems in this area (although these are very subjective criteria).
Here is my list at the moment.
- Projects mentioned in previous sections: DQN, AlphaGo, AlphaZero, parkour-bot, reducing energy consumption in data centers and AutoML with Neural Architecture Search.
- The OpenAI Dota 2 1v1 Shadow Fiend bot, which beat the best professionals with simplified battle settings .
- Бот Super Smash Brothers Melee, способный обыграть профессиональных игроков в 1v1 Falcon таким же образом. (Firoiu et al, 2017).
(Brief digression: machine learning recently beat professional unlimited Texas Hold'em players. The program uses both Libratus (Brown et al, IJCAI 2017) and DeepStack (Moravčík et al, 2017) . I spoke with several people who thought they worked here deep RL. Both systems are very cool, but they don’t use deep learning with reinforcement. It uses an algorithm of counterfactual minimization of regret and a competent iterative solution to subgames).
From this list, you can isolate common properties that facilitate learning. None of these properties, listed below, are required for training, but the more they are present, the better the result will definitely be.
- Лёгкая генерация практически неограниченного опыта. Здесь польза очевидна. Чем больше у вас данных, тем проще обучение. Это относится к Atari, го, шахматам, сёги и моделируемым средам паркур-бота. Вероятно, это относится и к проекту электропитания дата-центра, потому что в предыдущей работе (Gao, 2014) было показано, что нейросети способны с высокой точностью прогнозировать энергоэффективность. Именно такую имитационную модель вы бы взяли для обучения системы RL.
Возможно, принцип применим к работам по Dota 2 и SSBM, но это зависит от максимальной скорости игры и количества процессоров. - Задача упрощается до более простой формы. Одна из самых распространённых ошибок в глубинном RL — слишком амбициозные планы и мечты. Обучение с подкреплением способно на всё! Но это не значит, что нужно браться за всё сразу.
Бот OpenAI Dota 2 работает только в начале игры, только Shadow Fiend против Shadow Fiend, только 1х1, с определёнными настройками, с фиксированным положением и типом зданий, а также вероятно обращается к Dota 2 API, чтобы не решать задачи обработки графики. Бот SSBM показывает сверхчеловеческую производительность, но только в игре 1х1, только с Captain Falcon, только на Battlefield с бесконечным временем матча.
Это не издевательство над каким-то из ботов. В самом деле, зачем решать сложную проблему если вы даже не знаете, решается ли простая? Общий подход в этой области — сначала добиться минимального доказательства концепции, а позже обобщить его. OpenAI расширяет свою работу по Dota 2. Продолжается и работа по расширению бота SSBM на других персонажей. - Есть способ обучаться в самостоятельной игре. Так действуют AlphaGo, AlphaZero, боты Dota 2 Shadow Fiend и SSBM Falcon. Должен отметить, что под самостоятельной игрой я имею в виду именно конкурентную игру, хотя оба игрока могут управляться одним агентом. Судя по всему, такая настройка даёт наиболее стабильный результат.
- Есть ясный способ определить подходящее для обучения, неподдельное вознаграждение. В играх для двух игроков это +1 за победу и −1 за проигрыш. В оригинальной статье по Neural Architecture Search от Zoph et al, ICLR 2017 была точность валидации обученной модели. Каждый раз, когда вы задаёте плавное вознаграждение, то вводите шанс изучения неоптимальной политики, которая оптимизирует модель для неправильной цели.
Если хотите почитать больше о том, как сделать правильное вознаграждение, попробуйте поискать по фразе [правильное правило подсчёта очков]. Эта публикация в блоге Терренса Тао приводит доступный пример.
Что касается обучаемости, у меня нет советов, кроме как попробовать и смотреть, что работает, а что нет. - Если нужно определить непрерывное вознаграждение, то по крайней мере оно должно быть богатым. В Dota 2 вознаграждение может присуждаться за последние хиты (за каждого убитого монстра любым игроком) и здоровье (срабатывает после каждой точного атаки или применения скилла). Эти сигналы поступают быстро и часто. Боту SSBM вознаграждение можно давать за нанесённый и полученный урон, с сигналом после каждой успешной атаки. Чем короче задержка между действием и следствием, тем быстрее замыкается цикл обратной связи — и тем легче системе подкрепления найти путь к максимальному вознаграждению.
Пример: Neural Architecture Search
You can combine several principles and analyze the success of Neural Architecture Search. According to the original version of ICLR 2017 , after 12,800 samples, deep RL is able to design the best-of-its-kind neural network architectures. Admittedly, in each example, it was necessary to train the neural network to convergence, but it is still very effective in the number of samples.
As mentioned above, the reward is validation accuracy. This is a very rich reward signal - if a change in the structure of the neural network improves accuracy from just 70% to 71%, RL will still benefit from it. In addition, there is evidence that hyperparameters in deep learning are close to linearly independent. (This has been empirically shown in the workHyperparameter Optimization: A Spectral Approach (Hazan et al, 2017) - my resume here , if interested). NAS does not specifically configure hyperparameters, but I think it’s quite reasonable that neural network design decisions are made in this way. This is good news for learning, given the strong correlations between solution and performance. Finally, here is not only a rich reward, but here is exactly what is important to us when teaching models.
Together, these reasons make it clear why the NAS requires “only” about 12,800 trained networks to determine the best neural network compared to the millions of examples needed in other environments. From different sides, everything plays in favor of RL.
In general, such success stories are still the exception, not the rule. Many pieces of the puzzle must be correctly folded so that reinforced learning works convincingly, and even then it will be difficult.
In general, now deep RL cannot be called a technology that works right out of the box.
A look into the future
There is an old saying - every researcher learns over time how to hate his field of research. The joke is that researchers still continue to do this because they like the problems too much.
This is about how I feel about reinforced deep learning. Despite all of the above, I am absolutely sure that we need to try to use RL on various problems, including those where it is most likely to be ineffective. But how else can we improve RL?
I see no reason why deep RL will not work in the future, if technology is given time for improvement. Some very interesting things will begin to happen when the deep RL becomes reliable enough for widespread use. The question is how to achieve this.
Below I have listed some plausible future development options. If further research is needed to develop in this direction, then links to relevant scientific articles in these areas are indicated.
Local optima are good enough . It would be arrogance to say that people themselves are globally optimal in everything. I would say that we are slightly better than other species optimized to create civilization. In the same vein, the RL solution does not have to strive for global optima if its local optima exceed the basic level of a person.
Iron will solve everything. I know people who believe that the most important thing for creating AI is simply to increase the speed of iron. Personally, I am skeptical that iron will solve all problems, but it certainly will make an important contribution. The faster everything works, the less you are concerned about the inefficiency of the samples and the easier it is to break through brute force through intelligence problems.
Add more training signals . Sparse rewards are difficult to learn, because there is very little information about what exactly gives the effect. It is possible that we will either generate positive rewards in the form of hallucinations ( Hindsight Experience Replay, Andrychowicz et al, NIPS 2017 ), or define supporting tasks ( UNREAL, Jaderberg et al, NIPS 2016), or we will build a good model of the world, starting with self-controlled learning. Add the cherry on the cake, so to speak.
Model-based training will increase sample efficiency . Here's how I describe RL based on the model: "Everyone wants to do it, but few know how." In principle, a good model fixes a bunch of problems. As can be seen in the example of AlphaGo, the presence of a model in principle greatly facilitates the search for a good solution. Good models of the world are well transferred to new tasks, and the introduction of a model of the world allows us to imagine new experiences. In my experience, model-based solutions also require fewer samples.
But training a good model is a difficult thing. I got the impression that low-dimensional state models sometimes work, but image models are usually too difficult. But if they become easier, some interesting things can happen.
Dyna (Sutton, 1991) and Dyna-2 (Silver et al., ICML 2008) are classic works in this area. As examples of work where model-based learning is combined with deep-seated networks, I would recommend several recent articles from the Berkeley Robotics Laboratory:
- Neural Network Dynamics for Model-Based Deep RL with Model-Free Fine-Tuning (Nagabandi et al, 2017 ;
- Self-Supervised Visual Planning with Temporal Skip Connections (Ebert et al, CoRL 2017) ;
- Combining Model-Based and Model-Free Updates for Trajectory-Centric Reinforcement Learning (Chebotar et al, ICML 2017);
- Deep Spatial Autoencoders for Visuomotor Learning (Finn et al, ICRA 2016);
- Guided Policy Search (Levine et al, JMLR 2016).
Using reinforcement learning is easy as a tweak . The first AlphaGo article began with teacher training and fine-tuning RL. This is a good option because it speeds up initial training using a faster, but less powerful way. This method also worked in a different context - see Sequence Tutor (Jaques et al, ICML 2017) . You can consider it as the beginning of the RL process with a reasonable, rather than random, prior distribution of probabilities (prior), where another system is involved in creating this “prior”.
Reward Functions Can Be Learnable. Machine learning promises that on the basis of data, you can learn to build things better than those designed by man. If it is so difficult to choose a reward function, then why not use machine learning for this task? Simulation learning and the reverse of RL - these rich areas have shown that reward functions can be implicitly determined by confirmations or ratings from a person.
The most famous scientific papers on reverse RL and simulation training are Algorithms for Inverse Reinforcement Learning (Ng and Russell, ICML 2000) , Apprenticeship Learning via Inverse Reinforcement Learning (Abbeel and Ng, ICML 2004) and DAgger (Ross, Gordon, and Bagnell, AISTATS 2011) .
Recent works that expand these ideas into the field of deep learning include Guided Cost Learning (Finn et al, ICML 2016) , Time-Constrastive Networks (Sermanet et al, 2017) and Learning From Human Preferences (Christiano et al, NIPS 2017) . In particular, the last of the listed articles shows that the remuneration derived from the ratings put by people actually turned out to be better (better-shaped) for training than the original hard-coded remuneration - and this is a good practical result.
Of the long-term jobs that do not use in-depth training, I liked the articles by Inverse Reward Design (Hadfield-Menell et al, NIPS 2017) andLearning Robot Objectives from Physical Human Interaction (Bajcsy et al, CoRL 2017) .
Learning transfer . Learning transfer promises that you can use the knowledge from previous tasks to speed up learning new tasks. I am absolutely sure that this is the future, when training will become reliable enough to solve disparate tasks. It is difficult to transfer training if you cannot study at all, and if there are tasks A and B, it is difficult to predict whether the transfer of training from task A to task B will occur. In my experience, here is either a very obvious answer or completely incomprehensible. And even in the most obvious cases, a non-trivial approach is required.
Recent work in this area is the Universal Value Function Approximators (Schaul et al, ICML 2015) ,Distral (Whye Teh et al, NIPS 2017) and Overcoming Catastrophic Forgetting (Kirkpatrick et al, PNAS 2017) . For older works, see Horde (Sutton et al, AAMAS 2011) .
For example, robotics shows good progress in transferring training from simulators to the real world (from simulating a task to a real task). See Domain Randomization (Tobin et al, IROS 2017) , Sim-to-Real Robot Learning with Progressive Nets (Rusu et al, CoRL 2017) and GraspGAN (Bousmalis et al, 2017) . (Disclaimer: I worked on GraspGAN).
Good priors can greatly reduce training time.. This is closely related to some of the previous points. On the one hand, the transfer of learning is to use past experience to create good a priori probability distributions (priors) for other tasks. RL algorithms are designed to work on any Markov decision-making process - and here there is a problem with generalization. If we believe that our solutions work well only in a narrow sector of environments, then we should be able to use a common structure to effectively solve these environments.
In her speeches, Pieter Ebbill likes to note that the deep RL needs to be asked only the tasks that we solve in the real world. I agree that this makes a lot of sense. There must be some real-world prior, which allows us to quickly learn new real tasks through slower learning of unrealistic tasks, and this is a perfectly acceptable compromise.
The difficulty is that such a real-world prior is very difficult to design. However, I think there is a good chance that this is still possible. Personally, I am delighted with recent work on meta-training, because it provides a way to generate reasonable priors from data. For example, if I want to use RL to navigate a warehouse, it would be interesting to first use meta-training to teach good navigation in general, and then fine-tune this prior for a specific warehouse where the robot will move. This is very similar to the future, and the question is whether meta-training will get there or not.
For a summary of the latest learning-to-learn work, see this publication from BAIR (Berkeley AI Research) .
More complex environments can paradoxically be easier. One of the main conclusions of the DeepMind article on parkour-bot is that if you complicate the task very much by adding several variations of the tasks, then in reality you simplify the training, because the rules cannot retrain in one setting without losing performance in all other parameters . We saw something similar in articles on domain randomization and even in ImageNet: models trained in ImageNet can expand to other environments much better than those trained on CIFAR-100. As I said, perhaps we only need to create some “ImageNet for management” in order to move to a much more universal RL.
There are many options. OpenAI Gym is the most popular environment, but there is also the Arcade Learning Environment ,Roboschool , DeepMind Lab , DeepMind Control Suite, and ELF .
Finally, although this is insulting from an academic point of view, the empirical problems of deep RL may not matter from a practical point of view. As a hypothetical example, imagine that a financial company uses deep RL. They train a sales agent on past US stock market data using three random sids. In real A / B testing, the first seed brings 2% less income, the second works with average profitability, and the third brings 2% more. In this hypothetical version, reproducibility does not matter - you simply deploy a model whose profitability is 2% higher and rejoice. Similarly, it does not matter that a sales agent can work well only in the United States: if it does not expand well in the world market - just do not use it there. There is a big difference between an extraordinary system and a reproducible extraordinary system. Perhaps you should focus on the first.
Where are we now
In many ways, the current state of deep RL annoys me. Nevertheless, it attracts such strong interest among researchers, which I have not seen in any other field. My feelings are best expressed by the phrase Andrew Eun mentioned in his talk with Nuts and Bolts of Applying Deep Learning : strong pessimism in the short term, balanced by even stronger long-term optimism. Now deep RL is a bit chaotic, but I still believe in the future.
However, if someone again asks me if reinforcement learning (RL) can solve their problem, I will still immediately answer that no, I won’t. But I will ask you to repeat this question in a few years. By then, perhaps everything will work out.