"Make beautiful." Google Tensorboard Training Visualization
- Tutorial

Beauty, as you know, requires sacrifice, but the world promises to save. A fairly fresh (2015) visualizer from Google is designed to help deal with the processes taking place in deep learning networks. Sounds tempting.
A colorful interface and loud promises dragged on the analysis of this designer shaitan, with unintuitively debugging glitches. The API is unusually meager and often updated, the examples on the network are the same (the eyes can no longer look at the hackneyed MNIST ).
So that the experiment would not go in vain, I decided to share the simplest possible description of insights with the Habrachians, because there are few Russian-speaking guides, and English-speaking ones are all the same. Maybe this introduction will help you reduce the time you need to get acquainted with Tensorboard and the number of abusive words at the start. I will also be glad to know what results he gave in your project and whether he helped in the real task.
In order not to repeat myself once again, I will not raise the topic of working with Tensorflow as such, you can read about it here , for example , and here at the end even look at an example of using Tensorboard. You will be narrated with the assumption that the concept of the operation graph used in Tensorflow is familiar to you.
Official Guide TensorboardIt contains, in fact, everything that is required, so if you are used to working with a brief description and picking up ideas on the fly, you can follow the link and use the instructions of the developers. I was not able to recognize and apply them immediately.
General principle of logging
It is very difficult to get the parameters of the network built in TensorFlow (TF). TensorBoard (TB) acts as a tool in this task.
TF can collect, one might say, in “boxes” - summary , data that TB displays to us. Moreover, there are several types of these "boxes" for different types of data.
- tf.summary.scalar Here you can put any numerical values, for example, loss functions at each (or not every) era of training. The display in TB will be in the form of the usual graph x (n) .
- tf.summary.image Collects images.
- tf.summary.audio Collects any audio files.
- tf.summary.text Collects text data.
- tf.summary.histogram Collects a set of values and displays in the TB “layered” histograms of the distribution of these values for each recording step. Good for storing weights data, you can track changes in their values for each era of training.
The name of the “box” and the variable from which the value will be taken are set as an argument. For instance:
tf.summary.scalar('loss_op', loss_op)In my task, scalar and histogram types were relevant.
What does scalar and histogram look like
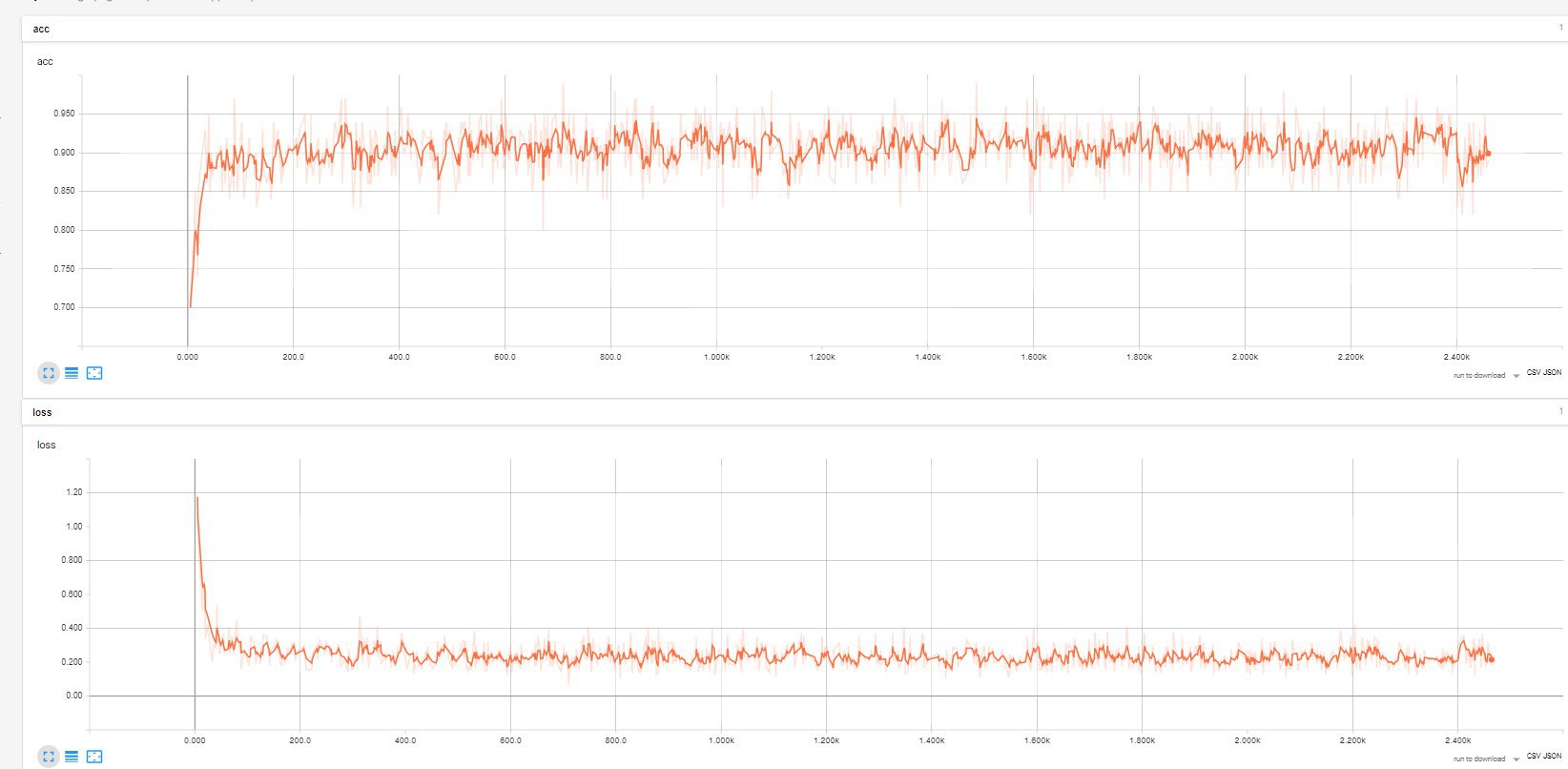
Accuracy in the training set and loss function. A smoothed chart is drawn in bold (the degree of smoothing is set by the user with the slider), pale - original data.
Histograms of the weights of three layers, for two Learning rate values (0.001 and 0.0001).
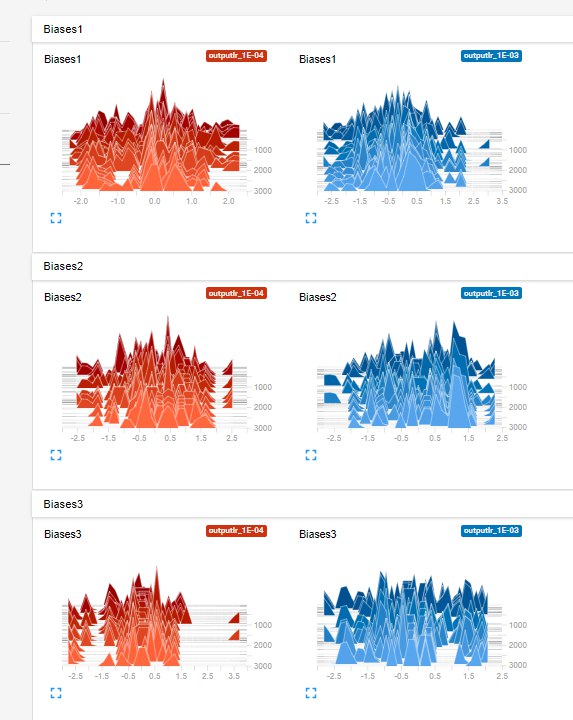
Histograms of the weights of three layers, for two Learning rate values (0.001 and 0.0001).
In order not to explicitly replenish each "box" individually, use merge_all () , collecting them in this way in one heap and getting the necessary data for all the "boxes" at a time.
tf.summary.scalar('loss_op', loss_op) #делаем "коробку" под функцию потерь.
tf.summary.scalar('accuracy', accuracy) #под точность
tf.summary.histogram('Biases1',biases['h1']) #под смещения первого слоя(они берутся из словаря по ключу h1)
tf.summary.histogram('Weights1',weights['h1']) #под веса первого слоя
"""
...
в общем,задаем все необходимые summaries
...
"""
merged_summary_op = tf.summary.merge_all() #и сливаем в единый набор "коробок" Naturally, the mentioned accuracy , loss_op , biases and weights are declared separately as participants in the current graph of operations.
Further, merged_summary_op is simply activated at the right moments during session execution. For example, when starting training:
[_, _, sum_result] = sess.run([train_op, loss_op,merged_summary_op], feed_dict={X: batch_x_norm, Y: batch_y}) #запускаем обучение, на выходе нас ничего не интересует, кроме содержимого для "коробок", которое отдается в sum_result
summary_writer.add_summary(sum_result, i) #записываем результат в логи, i-номер степа обучения As you noticed, the result is written to the file using (sorry for the diminutive, but I couldn’t come up with an alternative) the “recorder” summary_writer and its add_summary function . "Recorder" is declared in advance, the path to the folder with the logs is indicated in the arguments. It is convenient to use the creation of several writers for posting results on test and training samples; more about this in the next article. In addition, you can add the values of the used hyperparameters (such as the learning rate, the type of activation function, the number of layers, etc., to the logs. More details on how to set hyperparameters and can be viewed here ), short ones will also be displayed in TB.
Log_Dir="logs/outputNew/myNet" #директория к логам в рабочей папке
hparam= "LR_%s,h1_%s,h2_%s,h3_%s" % (learning_rate,n_hidden_1,n_hidden_2,n_hidden_3) #при отображение графика будет выведено название с указанными гиперпараметрами
summary_writer= tf.summary.FileWriter(Log_Dir+hparam)
summary_writer_train.add_graph(sess.graph)#и обязательно добавляем в наш writer граф операций текущей сессии для отображения в TB структуры графа The TB visualizer is launched using the command (of course, through the console):
tensorboard --logdir='Log_Dir'So after running the session, training the network and collecting all the necessary data in the logs, you can finally see them in the browser by going to localhost: 6006. I think you yourself will deal with different display formats: at least this is really intuitive for TB. And about how convenient it is to display graphs in groups (hyperparameters, for example), use tags, I will tell in the next article.
So, in general, the process of preparing the soil for TB (omitting the features of constructing a graph of operations with TF, of course, is not about that now) looks something like this:
- We form the graph of operations , following the principles of working with TF
- We create “boxes” -summary for the data that we want to collect in the logs
- Merge all the boxes with merge_all ()
- We set the “record” summary_writer , in which we indicate the path for the logs and immediately add our graph
- During the session, call the contiguous boxes in run-e and write the result using summary_writer
- We look at the result in TB, fingers crossed
Three issues that may come up
TB does not see the logs
Check the path indicated to them! If you do not see again, double-check again! And so on until it works. If there are files in the log folder, then TB cannot see them only if the directory is incorrect.
Heavily inhibited schedule update
In order for the schedule to appear in TB, you have to wait up to 15 minutes. At first, I thought that these were some problems with logging, but even restarting TB did not help to solve the problem of late loading of new data. I had to work in the "write logs - wait 10 minutes - see what loaded TB" mode. The computer has never had to blame the brakes, so the root of the problem is somewhere else. It will be interesting to hear if someone else has encountered this glitch.
Duplication of names and data
Periodically, data duplication popped up. For example, several types of accuracy or weights could arise. Or something like this , and this problem could not be resolved, since the origin of the duplicates is not clear. I urge you to be more careful with naming - this sometimes helps (in the graph of operations and in the summary) and analysis of the final graphs. Sometimes there is not what we would like.
Next, I plan to highlight the issue of separating writers for test and training samples, as well as what are the options for displaying the generated heap of logs.
In a working draft on the classification of sections of the time series, the result is better than a simple log. Regression, the neurons did not give, no matter how I tried to try different configurations. But the tool is mastered, which means it can bear fruit in the future.
Stay tuned!
PS In our company "Inkart" there are open vacancies for brave programmers and electronic engineers, and there is also a cook, cool corporate parties and an office on the lake. We design and manufacture cardiorespiratory monitors, which are used by most cardiologists in Russia. We are constantly improving processing algorithms and the iron part of the matter. Free minds from Petersburg - write in private messages for details.
Only registered users can participate in the survey. Please come in.
Useful information in practice?
- 39.2% Yes 11
- 7.1% No 2
- 50% Not yet, but I plan to use in the future 14
- 3.5% No, the information is not in the scope of my interests 1