What is inside HR? (There will be no anatomy)
Hello, Habr! We recently shared an interview with a representative of Vera’s robot, the first robot recruiter in the world developed by the Stafory team in Russia. And then the technical details of the project arrived, because we asked the guys to tell us how Vera works.

I give the floor to the author.
Robot Vera was invented a little over a year ago, but in such a short time she managed to do quite a lot. The world's first robot recruiter saves 60% of the working time for recruitment specialists in 300 companies not only in Russia but also abroad. In just a year, Vera managed to select more than 95,000 candidates for companies, conduct 2,300 video interviews and make more than 1,000,000 calls, and in October 2017 she also won the HR Tech World startup competition.

A lot of work - Vera is looking for suitable resumes for job seekers among tens of millions of entries on job sites, at the same time makes tens of thousands of calls to job seekers to offer them vacancies, conducts video interviews, recognizes the emotions of candidates and the question “What about the money?” will answer no worse than the standard “What kind of salary is offered?”.
Faith is managed in a personal account on robotvera.com, and Microsoft solutions helped to quickly launch a recruiting robot and ensure smooth operation. The first thing that was deployed in the Azure cloud was a web server on Django. Due to the fact that there is a ready-made solution with very simple and clear documentation on the marketplace, everyone set up very quickly. In total, less than an hour has passed from the start of work to the moment when the site was deployed.
Over time, we switched to standard instances with Ubuntu, but in the early stages, the ability to deploy the site as a cloud service, spending only a few minutes, was very useful for us. The availability of instances in the marketplace already with Django turned out to be very useful. For example, there is an assembly of a virtual machine from Bitnami, and if you use it, then you no longer need to install Django and the server - everything is already there. As a result, you just need to create and run your website application.
Of course, one cannot ignore that Bitnami has its own characteristics, for example, an additional firewall - because of it, the port must be opened not only on Azure, but also on the virtual machine in Bitnami. But it is also not difficult and does not take much time, especially with the help of the Azure marketplace, we have already saved it pretty much.
The web server, of course, is not the most difficult task that we solve when working with our product. Since Vera takes on the task of phoning the candidates and talking to them, she should talk like a person.
We want our robot recruiter to not only ask the employer questions according to the script and mechanically record the answers, but also be able to tell the candidate the information that interests him, coping with any complexity of formulations. This challenge lies in the field of machine learning. It was practically impossible to program all options of possible questions from applicants hardcore, because there are thousands of variations. The standard question is “What is the salary?” can sound in a dozen options, for example, “What's for the money?”, “What is the salary?” or “How much money do they give?”
It is impossible to foresee all the options, and in order to find the closest answer to the candidate’s question, we decided to use the word2vec library . If someone suddenly forgot or do not know, this is a technology that processes huge arrays of text information and calculates the vector representation of words. The latter is based on proximity in context: words that appear in the text next to identical words are defined as having a similar meaning. In the vector representation, they will have close coordinates of the word vectors.
Let's see how the model is trained on a pair of sentences, in this case these are words related to income.

In the code above, we initialize the array with sentences, then create the word2vec model and pass our array to it as an argument. We get all the vectors from the model to the variable X. Next, we create a two-dimensional PCA model (principal component method) using the scikit-learn library, call the fit_transform method and transfer our vectors to it.
After that, our words can be displayed in vector space using pyplot:
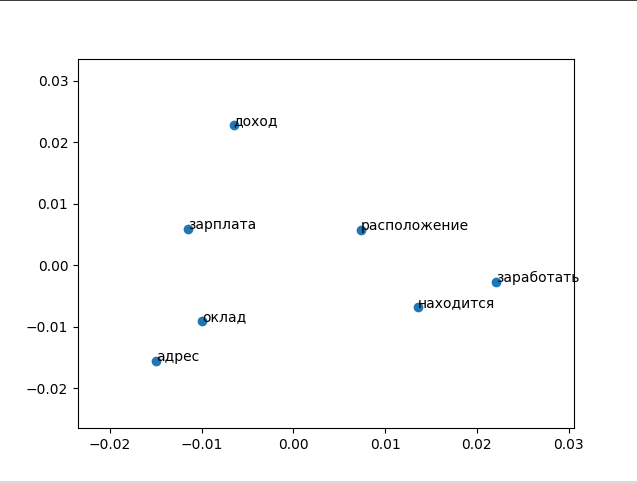
It can be seen that at this stage the words are so far scattered, and there is no explicit correlation of meaning and their location. This is because the model is not yet fully trained, since we have only passed a couple of sentences to it.
In order for the robot to fully communicate, we loaded 13 billion words (25,000 books and television scripts, or 150 GB of texts) into the model and a description of 100,000 vacancies. This is a huge array of data, but only after that the model begins to calculate the distance between sentences quite well and allows you to correctly select the answers to user questions.
To calculate the distance, we use the wmdistance () method. If we take our example with a couple of sentences that we use as arguments, in this case, the model should calculate the distance between these sentences. The listing below shows how this works: the candidate’s question “how much do you pay?” has a shorter distance with respect to the word “salary” than, for example, with the word “address”.

Considering how much information we have downloaded so that the robot can communicate fully and the distances between sentences are calculated correctly, our model weighs more than 19 GB in RAM, plus a case for training - another 41 GB. Again, using Azure, we easily picked up a suitable machine. It took several minutes to expand it, after that we made an API on this instance for using this model in our product.
And here's another story when Azure helped quickly pick the right instance. When we conducted the pre-ICO, we needed to train the chat bot overnight to answer questions about cryptocurrency and blockchain. We took the dialogue from this forum. There are not so many full-fledged dialogs, but still enough for the machine to start saying something more or less coherent.
For example, we got such dialogs:
- Is mining illegal?
- That depends per view.
- Chinese government banned all of ICOs.
- Please don't panic, just calm for your mother.
- What is your favorite trading exchange?
- I use coinbase.
We taught the bot using the Sequence-to-Sequence model of the TensorFlow library, which translates text from French into English. A GPU machine was needed for training, so we used the Azure N-Series instance. All training took place in the cloud. Of course, it can be seen from the examples that the bot made mistakes, and we did not achieve 100% coincidence of questions and answers at that time. But given that we spent only one day and one night on development and training, while the bot also managed to joke, we assume that we have achieved the goals.
And here you will find an interview with Alexei Kostarev, one of the creators of the Vera Robot.
 Vladimir Sveshnikov is a former founder of a staffing company from the CIS countries. Then the partners created the Veru robot. In the fall of 2017, Robot Vera became the first Russian startup to win the global pitch competition at the HR Tech World 2017 conference in Amsterdam.
Vladimir Sveshnikov is a former founder of a staffing company from the CIS countries. Then the partners created the Veru robot. In the fall of 2017, Robot Vera became the first Russian startup to win the global pitch competition at the HR Tech World 2017 conference in Amsterdam.
Interview about the robot Vera.
I give the floor to the author.
Robot Vera was invented a little over a year ago, but in such a short time she managed to do quite a lot. The world's first robot recruiter saves 60% of the working time for recruitment specialists in 300 companies not only in Russia but also abroad. In just a year, Vera managed to select more than 95,000 candidates for companies, conduct 2,300 video interviews and make more than 1,000,000 calls, and in October 2017 she also won the HR Tech World startup competition.
A lot of work - Vera is looking for suitable resumes for job seekers among tens of millions of entries on job sites, at the same time makes tens of thousands of calls to job seekers to offer them vacancies, conducts video interviews, recognizes the emotions of candidates and the question “What about the money?” will answer no worse than the standard “What kind of salary is offered?”.
Vera Web Side
Faith is managed in a personal account on robotvera.com, and Microsoft solutions helped to quickly launch a recruiting robot and ensure smooth operation. The first thing that was deployed in the Azure cloud was a web server on Django. Due to the fact that there is a ready-made solution with very simple and clear documentation on the marketplace, everyone set up very quickly. In total, less than an hour has passed from the start of work to the moment when the site was deployed.
Over time, we switched to standard instances with Ubuntu, but in the early stages, the ability to deploy the site as a cloud service, spending only a few minutes, was very useful for us. The availability of instances in the marketplace already with Django turned out to be very useful. For example, there is an assembly of a virtual machine from Bitnami, and if you use it, then you no longer need to install Django and the server - everything is already there. As a result, you just need to create and run your website application.
Of course, one cannot ignore that Bitnami has its own characteristics, for example, an additional firewall - because of it, the port must be opened not only on Azure, but also on the virtual machine in Bitnami. But it is also not difficult and does not take much time, especially with the help of the Azure marketplace, we have already saved it pretty much.
Teaching Faith
The web server, of course, is not the most difficult task that we solve when working with our product. Since Vera takes on the task of phoning the candidates and talking to them, she should talk like a person.
We want our robot recruiter to not only ask the employer questions according to the script and mechanically record the answers, but also be able to tell the candidate the information that interests him, coping with any complexity of formulations. This challenge lies in the field of machine learning. It was practically impossible to program all options of possible questions from applicants hardcore, because there are thousands of variations. The standard question is “What is the salary?” can sound in a dozen options, for example, “What's for the money?”, “What is the salary?” or “How much money do they give?”
It is impossible to foresee all the options, and in order to find the closest answer to the candidate’s question, we decided to use the word2vec library . If someone suddenly forgot or do not know, this is a technology that processes huge arrays of text information and calculates the vector representation of words. The latter is based on proximity in context: words that appear in the text next to identical words are defined as having a similar meaning. In the vector representation, they will have close coordinates of the word vectors.
Let's see how the model is trained on a pair of sentences, in this case these are words related to income.
In the code above, we initialize the array with sentences, then create the word2vec model and pass our array to it as an argument. We get all the vectors from the model to the variable X. Next, we create a two-dimensional PCA model (principal component method) using the scikit-learn library, call the fit_transform method and transfer our vectors to it.
After that, our words can be displayed in vector space using pyplot:
It can be seen that at this stage the words are so far scattered, and there is no explicit correlation of meaning and their location. This is because the model is not yet fully trained, since we have only passed a couple of sentences to it.
In order for the robot to fully communicate, we loaded 13 billion words (25,000 books and television scripts, or 150 GB of texts) into the model and a description of 100,000 vacancies. This is a huge array of data, but only after that the model begins to calculate the distance between sentences quite well and allows you to correctly select the answers to user questions.
To calculate the distance, we use the wmdistance () method. If we take our example with a couple of sentences that we use as arguments, in this case, the model should calculate the distance between these sentences. The listing below shows how this works: the candidate’s question “how much do you pay?” has a shorter distance with respect to the word “salary” than, for example, with the word “address”.
Considering how much information we have downloaded so that the robot can communicate fully and the distances between sentences are calculated correctly, our model weighs more than 19 GB in RAM, plus a case for training - another 41 GB. Again, using Azure, we easily picked up a suitable machine. It took several minutes to expand it, after that we made an API on this instance for using this model in our product.
We teach Vera in 1 night
And here's another story when Azure helped quickly pick the right instance. When we conducted the pre-ICO, we needed to train the chat bot overnight to answer questions about cryptocurrency and blockchain. We took the dialogue from this forum. There are not so many full-fledged dialogs, but still enough for the machine to start saying something more or less coherent.
For example, we got such dialogs:
- Is mining illegal?
- That depends per view.
- Chinese government banned all of ICOs.
- Please don't panic, just calm for your mother.
- What is your favorite trading exchange?
- I use coinbase.
We taught the bot using the Sequence-to-Sequence model of the TensorFlow library, which translates text from French into English. A GPU machine was needed for training, so we used the Azure N-Series instance. All training took place in the cloud. Of course, it can be seen from the examples that the bot made mistakes, and we did not achieve 100% coincidence of questions and answers at that time. But given that we spent only one day and one night on development and training, while the bot also managed to joke, we assume that we have achieved the goals.
And here you will find an interview with Alexei Kostarev, one of the creators of the Vera Robot.
about the author
Vladimir Sveshnikov is a former founder of a staffing company from the CIS countries. Then the partners created the Veru robot. In the fall of 2017, Robot Vera became the first Russian startup to win the global pitch competition at the HR Tech World 2017 conference in Amsterdam.