Modern CSS for dinosaurs
- Transfer
- Moving pixels in CSS was already difficult! And now they tell me how cool it is to use non-semantic class names, inline styles in HTML, and even write CSS styles in JavaScript!
[Insert here a GIF from Family Guy] - Ha!
Illustrations from Dinosaur Comics by Ryan North
Oddly enough, CSS is considered one of the simplest and one of the most complex languages for a web developer. Definitely, it is quite simple at the beginning - you define the properties of the style, the values for specific elements, and ... that’s practically all you need to know! However, in large projects, the situation becomes quite confusing and complicated in order to organize CSS in some meaningful way. Changing any CSS line to style an element on one page often leads to unforeseen consequences for elements on other pages.
To understand the intrinsic complexity of CSS, a variety of best practices have been created. The problem is that there is still no consensus on which of them are the best, and many of them completely contradict each other. If this is your first time trying to learn CSS, then this situation is disorienting, to say the least.
The purpose of this article is to show the historical context of how CSS techniques and tools evolved to their current state in 2018. By understanding this story, it will be easier to understand each approach and how to use it profitably. So, let's begin!
Using CSS for basic styles
Let's start with a simple website using only a simple file
index.htmlthat links to a separate file index.css:Modern CSS This is the header. This is the main content.
...
While we do not use any classes or id in HTML, only semantic tags . Without CSS at all, a website would look like this (with placeholder text):
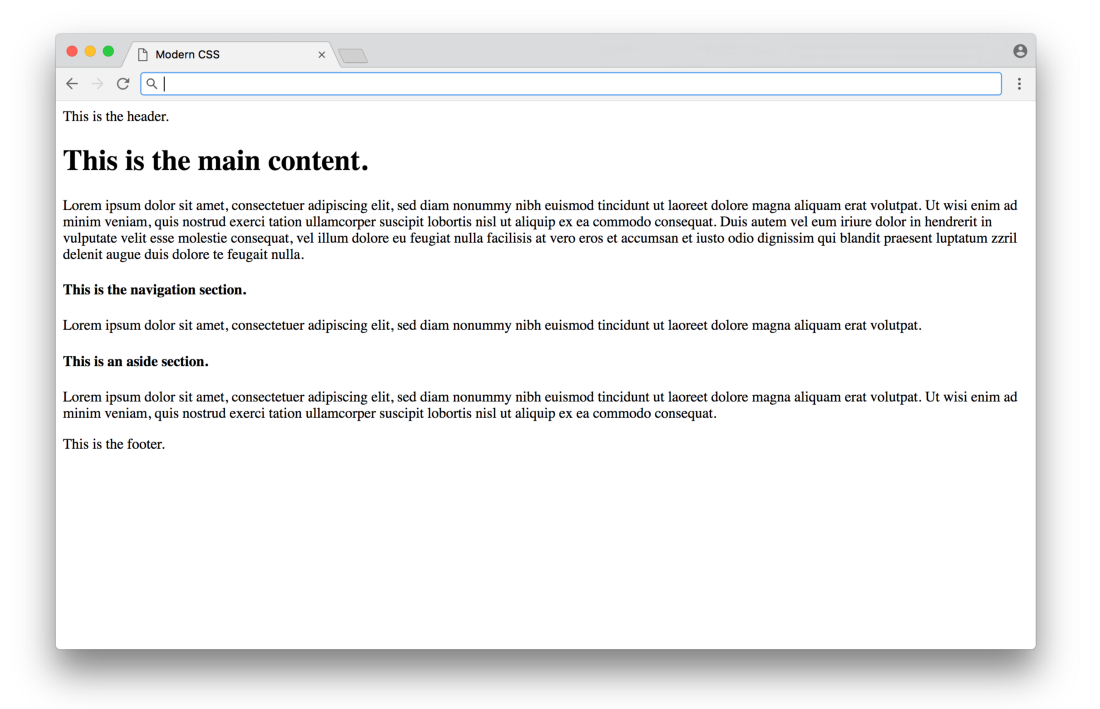
Click here for a real-life example
Functionally, but not very pretty. We can add CSS to improve the basic design in
index.css:/* BASIC TYPOGRAPHY */
/* from https://github.com/oxalorg/sakura */
html {
font-size: 62.5%;
font-family: serif;
}
body {
font-size: 1.8rem;
line-height: 1.618;
max-width: 38em;
margin: auto;
color: #4a4a4a;
background-color: #f9f9f9;
padding: 13px;
}
@media (max-width: 684px) {
body {
font-size: 1.53rem;
}
}
@media (max-width: 382px) {
body {
font-size: 1.35rem;
}
}
h1, h2, h3, h4, h5, h6 {
line-height: 1.1;
font-family: Verdana, Geneva, sans-serif;
font-weight: 700;
overflow-wrap: break-word;
word-wrap: break-word;
-ms-word-break: break-all;
word-break: break-word;
-ms-hyphens: auto;
-moz-hyphens: auto;
-webkit-hyphens: auto;
hyphens: auto;
}
h1 {
font-size: 2.35em;
}
h2 {
font-size: 2em;
}
h3 {
font-size: 1.75em;
}
h4 {
font-size: 1.5em;
}
h5 {
font-size: 1.25em;
}
h6 {
font-size: 1em;
}Here, most of the CSS is design styles (font sizes, line heights, etc.), with some color styles and a centered layout. You would have to study the design to find out the good values of these parameters (here are the styles from sakura.css ), but the CSS code itself is not too complicated to read here. The result looks something like this:
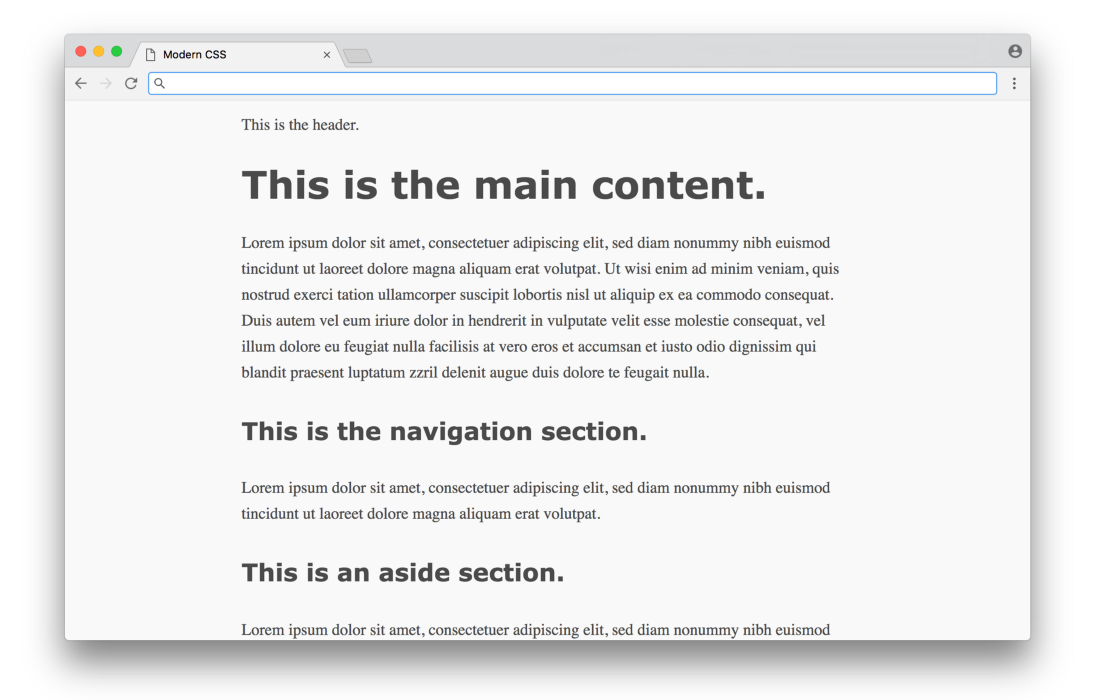
Click here for a real example
What a difference! This CSS message is an easy way to add styles to your document, without programming or complex logic. Unfortunately, things get a little more complicated when we start using CSS for something more than just layout and colors (we'll figure it out later).
Using CSS for markup
In the 1990s, before CSS was widely adopted, there were few options for marking up content on a page. HTML was originally designed as a language for creating simple documents, not dynamic websites with side menus, columns, etc. In those days, markup was often done with HTML tables - the entire page was entirely placed in a table, which was used to organize the content into columns and rows. This approach worked, but the reverse side was the close linking of content and presentation - if you wanted to change the markup on the site, sometimes you had to rewrite a significant amount of HTML.
CSS gave a strong impetus to the separation of content (written in HTML) and presentation (written in CSS). There was a way to extract all the markup from HTML (no more tables) in CSS. It is important to note that CSS, like HTML, was also not originally designed for page layout, so the first layout attempts can hardly be called elegant.
Let's see how this works in practice with our example above. Before defining any CSS markup, we first reset all the margins and indents (which affect the calculation of the markup), and mark the sections in different colors (not for beauty, but for distinguishing them visually when testing different layouts).
/* RESET LAYOUT AND ADD COLORS */
body {
margin: 0;
padding: 0;
max-width: inherit;
background: #fff;
color: #4a4a4a;
}
header, footer {
font-size: large;
text-align: center;
padding: 0.3em 0;
background-color: #4a4a4a;
color: #f9f9f9;
}
nav {
background: #eee;
}
main {
background: #f9f9f9;
}
aside {
background: #eee;
}Now the website will temporarily look like this:
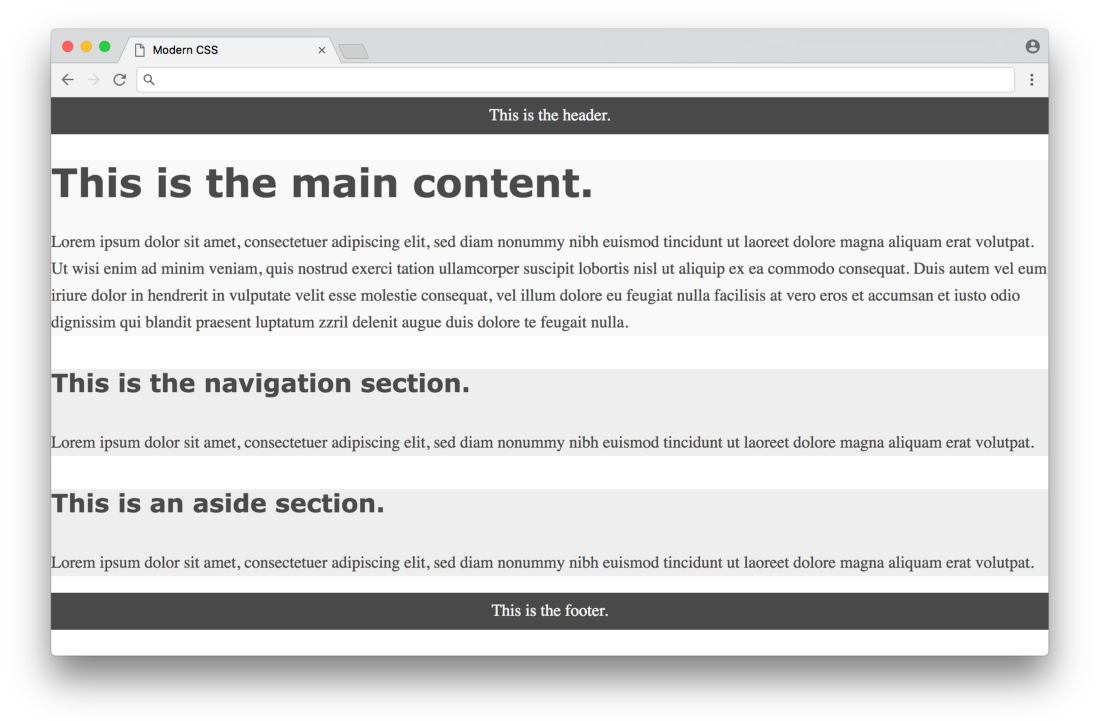
Click here for a real example.
Now we are ready to use CSS to mark up the content on the page. Let's evaluate three different approaches in chronological order, starting with classic float layouts.
Float based layout
The CSS float property was originally introduced to place the image inside a column of text on the left or right (which you often saw in newspapers). Web developers of the early 2000s took advantage of the fact that you can assign the float property not only to images, but to any element, that is, you can create the illusion of rows and columns by assigning a float to entire divs of content. But then again, float is not intended for this purpose, so such an illusion is difficult to implement in a consistent way.
In 2006, A List Apart published a popular article, “In Search of the Holy Grail”, which outlined a detailed and thorough approach to creating a layout known as the Holy Grail - a headline, three columns and a footer. Now it seems crazy that such a fairly simple layout was called the Holy Grail, but it was so difficult to create a robust layout in pure CSS.
Below is a layout based on float for our example based on the technique described in the article:
/* FLOAT-BASED LAYOUT */
body {
padding-left: 200px;
padding-right: 190px;
min-width: 240px;
}
header, footer {
margin-left: -200px;
margin-right: -190px;
}
main, nav, aside {
position: relative;
float: left;
}
main {
padding: 0 20px;
width: 100%;
}
nav {
width: 180px;
padding: 0 10px;
right: 240px;
margin-left: -100%;
}
aside {
width: 130px;
padding: 0 10px;
margin-right: -100%;
}
footer {
clear: both;
}
* html nav {
left: 150px;
}Looking at CSS, you can see several hacks necessary for the layout to work (negative borders, property
clear: both, hard-coded width calculations, etc.) - the article explains in detail the need for each of these hacks. Here's what the result looks like: 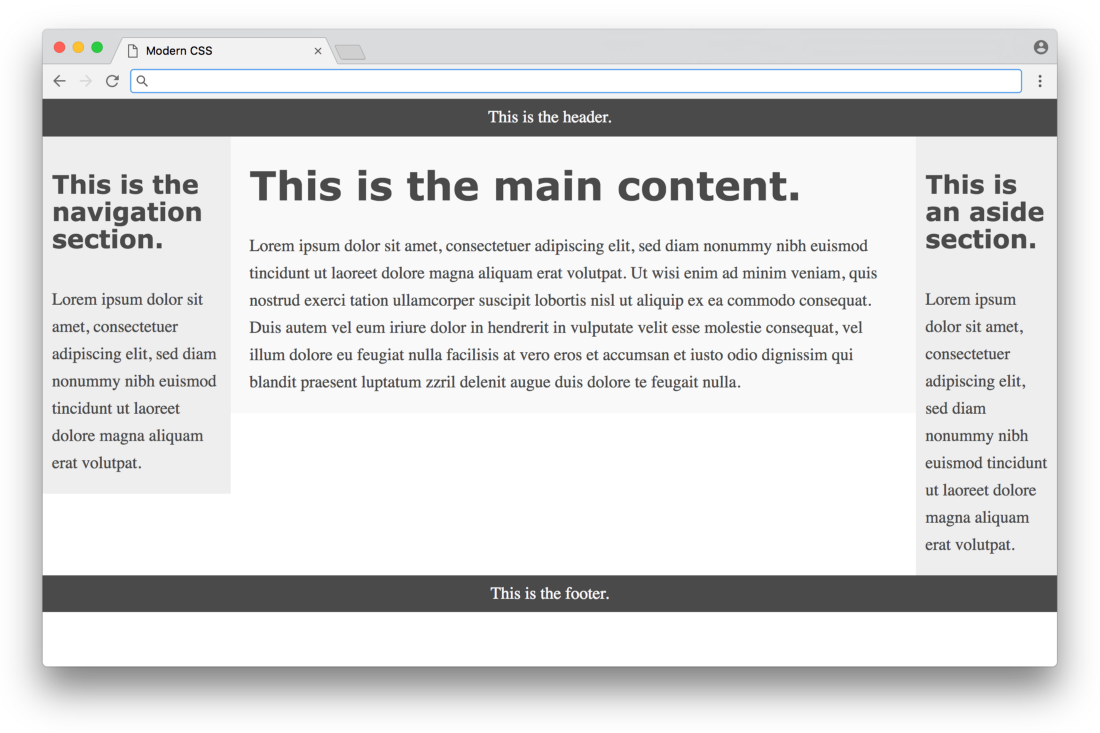
Click here for a real example
Not bad, but the three colors show that the columns have different heights and the page does not fill the entire height of the screen. These are unavoidable problems when using the float approach. All that a float can do is push the content to the left or right border of the section - there is no way in CSS to affect the height of the content in other sections. For years, the problem lacked a simple solution until flexbox-based layouts appeared.
Flexbox based layout
The flexbox property in CSS was first proposed in 2009, but it did not receive widespread support in browsers until around 2015. The property is designed to determine how space is distributed in one column or row, which makes it a more appropriate layout method than float. Thus, after ten years of using layouts based on float, web developers have finally been able to use CSS for layout without the hacks inherent in layouts on float.
The following is a flexbox-based layout for our example. It is based on the technique described on the Solved by Flexbox website (a popular resource that publishes various examples on flexbox). Please note that flexbox requires an additional wrapper div around three columns in HTML:
Modern CSS This is the header. This is the main content.
...
Here is the flexbox code in CSS:
/* FLEXBOX-BASED LAYOUT */
body {
min-height: 100vh;
display: flex;
flex-direction: column;
}
.container {
display: flex;
flex: 1;
}
main {
flex: 1;
padding: 0 20px;
}
nav {
flex: 0 0 180px;
padding: 0 10px;
order: -1;
}
aside {
flex: 0 0 130px;
padding: 0 10px;
}This is much more compact code compared to float based layout! The properties and values of flexbox are a little confusing at first glance, but they eliminate the need for a large number of hacks like negative boundaries - a huge victory. Here is the result:
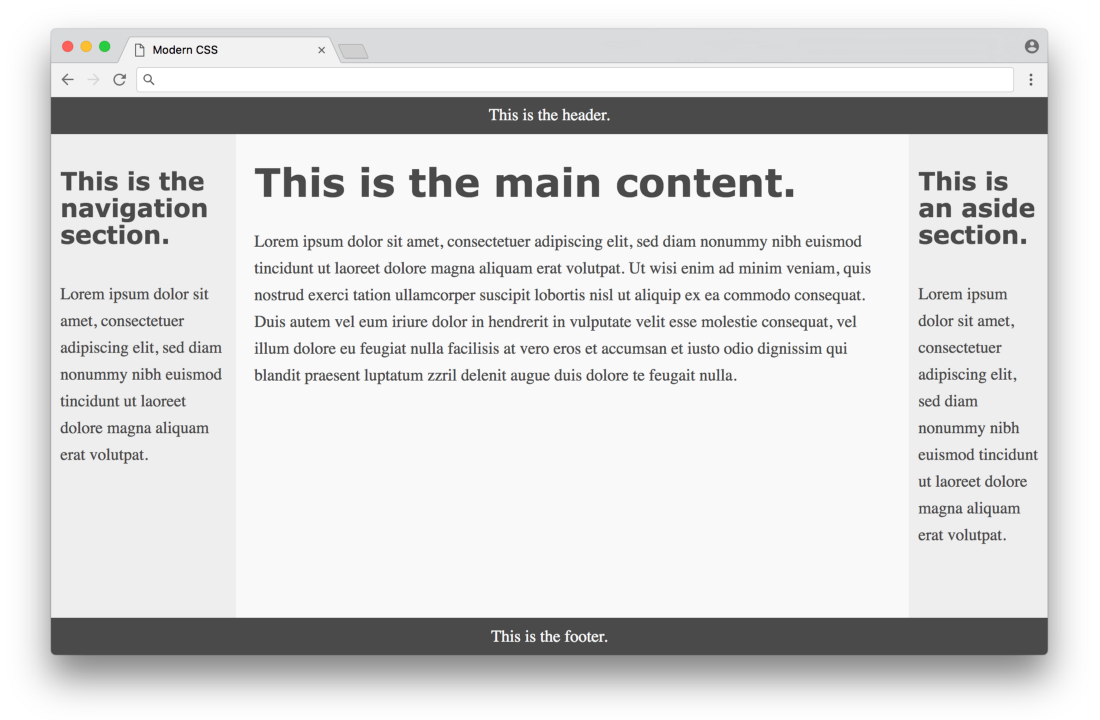
Click here for a real example.
Much better! All columns are the same height and occupy the entire height of the page. In a way, this looks perfect, but there are a couple of minor flaws with this approach. Firstly, browser support - now all modern browsers support flexbox, but some older browsers will never support it. Fortunately, browser developers are taking significant steps to end the life cycle of older versions, which will make the development environment for web designers more stable. Another drawback is the fact that we need to add to the markup
But the biggest flaw is in the CSS code itself. Flexbox eliminates many float hacks, but the code is not as expressive as it could be for describing the layout. Flexbox CSS is hard to read and get a visual understanding of how all the elements will fall on the page. Because of this, you are trying to guess the correct parameters - and check what happened.
It is important to emphasize once again that flexbox is designed to place elements in one column or row - it is not designed to layout an entire page! Even though he copes with it properly (much better than the float approach), other specifications were specially developed for layout in several columns or rows. They are called CSS grid.
Grid based layout
CSS grid was first proposed in 2011 (not much later than flexbox), but a long time passed before browsers began to support it. At the beginning of 2018, the CSS grid is supported by most modern browsers (a huge step forward compared to the situation a year or two ago).
Below is a grid based layout for our example. It is based on the first method described in this article on CSS tricks . Please note that in this example we can get rid of
/* GRID-BASED LAYOUT */
body {
display: grid;
min-height: 100vh;
grid-template-columns: 200px 1fr 150px;
grid-template-rows: min-content 1fr min-content;
}
header {
grid-row: 1;
grid-column: 1 / 4;
}
nav {
grid-row: 2;
grid-column: 1 / 2;
padding: 0 10px;
}
main {
grid-row: 2;
grid-column: 2 / 3;
padding: 0 20px;
}
aside {
grid-row: 2;
grid-column: 3 / 4;
padding: 0 10px;
}
footer {
grid-row: 3;
grid-column: 1 / 4;
}The result is visually identical to the flexbox-based layout. However, here the CSS code is much better in the sense that it clearly shows the desired layout. The size and shape of the columns and rows are defined in the body selector, and each grid element is directly determined by its position.
The only thing that can be confusing is a property
grid-columnthat determines the starting and ending positions of a column. It can be confusing, because in this example there are three columns, but numbers from 1 to 4 are used. The situation becomes clearer if you look at the illustration: 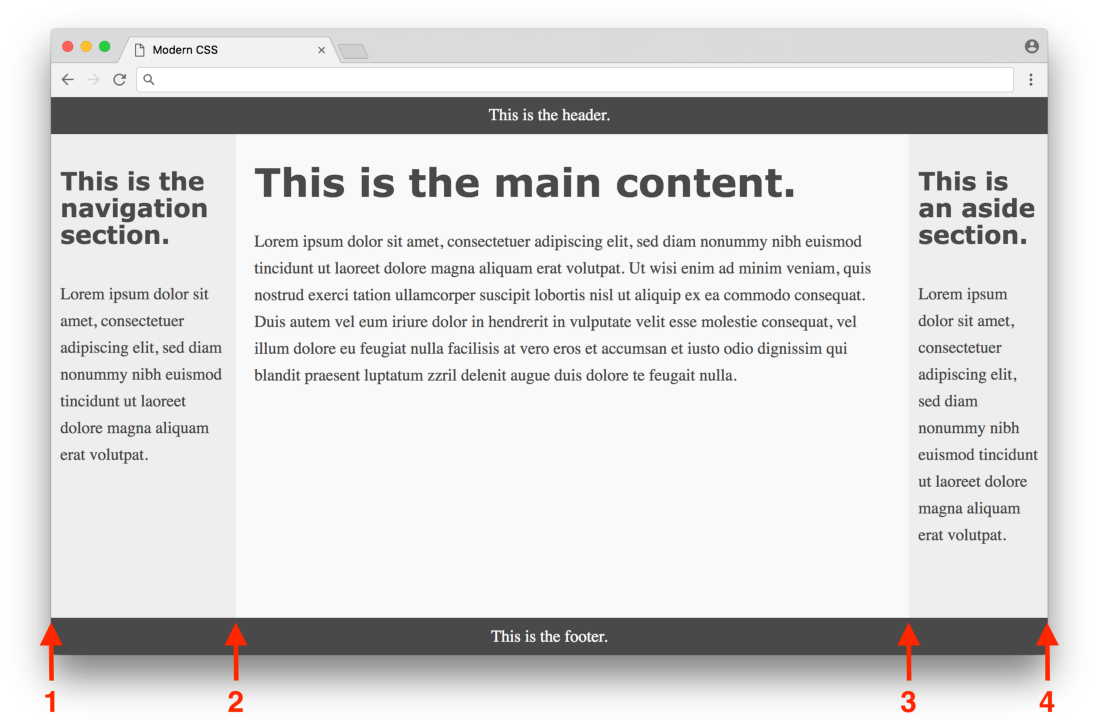
Click here for a real example
The first column starts at position 1 and ends at position 2, the second column starts at 2 and ends at 3, and the third column starts at position 3 and ends at position 4. The heading indicates a property
grid-columnwith a value 1 / 4for expanding to the entire page, in nav indicated grid-columnwith a value 1 / 2for expansion to the first column, etc.When you get used to the grid syntax, it will become clear that this is an ideal way to implement layout in CSS. The only real drawback is that support is not available in all browsers. But again, the situation has improved significantly over the past year. It is difficult to overestimate the value of CSS grid as the first real tool in CSS, which was really originally created for layout, that is, for layout of the entire page. In a sense, web designers have always had to be very conservative when creating creative layouts, because until recently the tools remained very fragile, requiring a variety of hacks and non-standard loopholes. Now with the advent of CSS grid, there is the potential for a new wave of creative design layouts that could never have been created before - wonderful times!

- Got? It's funny that when you change something in CSS, it breaks something else!
“Maybe, but with new specs like flexbox and grid, things got a lot better!”
- Ha! CSS has more difficulties, not just layout!
Using CSS preprocessor for new syntax
So far, we have looked at using CSS for simple styles and layouts. Now we’ll explore tools that help you work with the CSS language itself. Let's start with CSS preprocessors.
The CSS preprocessor allows you to write styles in other languages, which are then converted to CSS so that the browser understands them. This was extremely important at a time when browsers too slowly introduced support for new features. The first popular CSS Sass preprocessor was released in 2006. It implemented a new short syntax (indentation instead of brackets, the absence of semicolons, etc.) and added advanced functions that are not available in CSS, such as variables, auxiliary functions, and calculations. Here's what the color section from our previous example looks like when using Sass with variables:
$dark-color: #4a4a4a
$light-color: #f9f9f9
$side-color: #eee
body
color: $dark-color
header, footer
background-color: $dark-color
color: $light-color
main
background: $light-color
nav, aside
background: $side-colorNotice how the symbol
$denotes reusable variables. There are no braces or semicolons, which makes the syntax cleaner. Pure syntax is nice, but functions like variables made a real revolution at the time, as they opened up new possibilities for writing clean and maintainable CSS. To use Sass, you need to install Ruby . This programming language is used to compile Sass code into regular CSS. Then you need to install Sass gem , then run the command on the command line to convert your .sass files to .css files. Here is an example of what the command looks like:
sass --watch index.sass index.cssThis command converts Sass code from a file
index.sassto regular CSS in a file index.css(argument--watchindicates a launch every time the input changes after saving, which is convenient). Such a process is known as the assembly phase, and in 2006 it was a pretty significant barrier to entry. If you are short with programming languages like Ruby, then everything is simple for you. But many front-end developers at that time worked only with HTML and CSS, where such tools were not required. So this is a considerable requirement for the developer - to study the whole ecosystem in order to use the CSS preprocessor functions. Less
released CSS preprocessor in 2009. It is also written in Ruby and has similar functionality with Sass. The key difference was the syntax, which was made as similar as possible to CSS. This means that any CSS code is also a valid Less code. Here is the same example with Less syntax:
@dark-color: #4a4a4a;
@light-color: #f9f9f9;
@side-color: #eee;
body {
color: @dark-color;
}
header, footer {
background-color: @dark-color;
color: @light-color;
}
main {
background: @light-color;
}
nav, aside {
background: @side-color;
}It is almost no different (only a prefix
@instead $for variables), but it doesn’t look as pretty as the Sass example. Here we see the same curly braces and semicolons, as in CSS. But the fact of being close to CSS has made it easier for web designers to master this preprocessor. In 2012, Less was rewritten to use JavaScript (specifically Node.js ) instead of Ruby when compiling. After that Less began to work faster than its competitors in Ruby, and the preprocessor itself became more attractive for developers who already use Node.js in their work. To convert the above code to regular CSS, you first need to install Node.js , then install Less and run the command:
lessc index.less index.cssThe command converts the Less code from the file
index.lessinto plain CSS in a file index.css. Note that lesscthere is no way for a command to monitor file changes as it does sass. So you have to use some other tool to automatically track and compile files .less, which complicates the process a bit. Again, there is nothing complicated for programmers who are used to using command line tools, but this is a significant barrier for ordinary designers who simply want to use a CSS preprocessor. When Less gained popularity, Sass developers added a new SCSS syntax to their preprocessor in 2010 (a superset of CSS similar to Less). They also released LibSass, port of the Ruby Sass engine in C / C ++, which accelerated its work and made it available for programming in various languages.
Another alternative CSS Stylus preprocessor was released in 2010. It is written in Node.js and has a cleaner syntax than Sass or Less. Typically, in a discussion of CSS preprocessors, these three programs are mentioned as the most popular (Sass, Less, and Stylus). In the end, they are all very similar in functionality, so you won’t be mistaken choosing any of them.
However, some believe that CSS preprocessors have recently declined in value because browsers have finally begun to implement some of their functions (such as variables and calculations). Moreover, there is the opposite approach - CSS post-processing, because of which CSS preprocessors can become completely outdated (obviously this is a moot point). CSS postprocessors we will now consider.
Using CSS post processor for conversion functions
The CSS post processor uses JavaScript to parse and convert your CSS into valid CSS. In this sense, it is quite similar to the CSS preprocessor - it can be considered as another way to solve the same problem. The key difference is that the CSS preprocessor uses special syntax to define the transformation object, and the CSS post processor can parse the original CSS code and transform it without any special syntax. It is best to show this with an example. Let's look at the CSS part from the above example, where we defined the style of the header tags:
h1, h2, h3, h4, h5, h6 {
-ms-hyphens: auto;
-moz-hyphens: auto;
-webkit-hyphens: auto;
hyphens: auto;
}Lines two through four are called vendor prefixes. Browsers use vendor prefixes when testing new CSS features or using them in experimental mode. In this way, developers can test these features before their final implementation in the browser. Here is the prefix
-msfor the Microsoft Internet Explorer browser, the prefix -mozfor Mozilla Firefox and the prefix -webkitfor Webkit browsers (such as Google Chrome, Safari and the latest versions of Opera). It’s rather inconvenient to embed these different vendor prefixes to use CSS properties. It would be nice if some tool automatically did this for us if necessary. This can be done using CSS preprocessors. For example, in the SCSS syntax:
@mixin hyphens($value) {
-ms-hyphens: $value;
-moz-hyphens: $value;
-webkit-hyphens: $value;
hyphens: $value;
}
h1, h2, h3, h4, h5, h6 {
@include hyphens(auto);
}Here we use the mixin function in Sass , which once defines a piece of CSS - and then reuses it everywhere. When this file is compiled into regular CSS, any operator
@includewill be replaced with CSS code from the corresponding one @mixin. This is generally a good solution, but you are responsible for defining a mixin for each CSS property that requires vendor prefixes. These mixin definitions require support: when browsers officially implement some CSS features, you might want to remove unnecessary vendor prefixes. Instead of mixin, I’d just like to write normal CSS so that the tool automatically finds properties that need prefixes and adds them where necessary. CSS postprocessor can work this way. For example, if you usePostCSS with the autoprefixer plugin , you can write completely ordinary CSS without any vendor prefixes, and the post processor will do the job:
h1, h2, h3, h4, h5, h6 {
hyphens: auto;
}If you run the CSS post-processor on this code, then
hyphens: auto;all the relevant vendor prefixes will appear instead of the line (in accordance with the autocorrect rules from the autoprefixer plugin, which do not need to be manually changed). That is, you can just write plain CSS without worrying about any kind of compatibility or special syntax, which is great! In addition to autoprefixer, there are other plugins for PostCSS that allow you to do really cool things. The cssnext plugin allows you to apply experimental CSS features. The CSS modules plugin automatically changes classes to avoid name conflicts. Stylelint pluginfinds errors and conflicting conditions in your CSS. These tools really started in the last year or two, demonstrating features of the developer’s workflow that were never available before!
However, progress has to be paid. Installing and using a CSS post processor such as PostCSS requires more effort than a CSS preprocessor. You will not only have to install and run the tools from the command line, but also install and configure individual plugins and define a more complex set of rules (such as which browsers to take into account, etc.). Instead of launching PostCSS directly from the command line, many developers integrate it into configurable build systems like Grunt , Gulp, or webpack. This makes it easier to manage all the different build tools that you can use for the frontend.
Note : If you have never used modern build systems for the frontend, then it might seem that you need to learn too much information. If you want to start from scratch, read my article “Modern JavaScript for dinosaurs” , which explains all the necessary JavaScript tools necessary for using these modern functions in front-end development.
It is worth noting that controversy has unfolded around CSS post-processors. Some say that the terminology is too confusing ( some say that all these tools should be called CSS preprocessors; others say that they should be called simply CSS processors, etc.). Someone believes that CSS postprocessors will completely eliminate the need for CSS preprocessors, someone believes that they should be used together. In any case, you need to learn CSS postprocessors if you want to squeeze everything you can out of CSS.
- Ha! It seems to me that CSS is changing too quickly for its own good.
- Well, not all at once!
- Ha! Wait, I mean?
- You complain that CSS is difficult, and at the same time complain that people are making tools to improve it!
- Maybe! But with some tools you won’t fix CSS!
- And here CSS methodology will help you!
Using CSS Methodologies for Reliable Maintenance
Tools like CSS preprocessors and CSS postprocessors have come a long way toward improving CSS usability. But these tools alone are not enough to solve the problem of supporting large CSS codebases. To solve this problem, they began to create different guidelines on how to write CSS - they are usually called CSS methodologies.
Before delving into a specific CSS methodology, it’s important to understand why long-term CSS support is so complex. The key issue is the global nature of CSS. Each style you set is globally applied to all parts of the page. You are entrusted with the job of either introducing a detailed naming convention to support unique class names, or introducing CSS specificity rulesto determine which style should be applied to each element. CSS methodologies offer an organized way to write CSS to avoid these pain points in large codebases. Consider some popular methodologies in chronological order.
Oocss
OOCSS (Object Oriented CSS) was first introduced in 2009 as a methodology, on two main principles. The first principle is to separate the structure from the shell . This means that CSS with the definition of the structure (as a layout) should not be mixed with CSS, which defines the shell (like colors, fonts, etc.). It’s easier to redo the shell, that is, the appearance of the application. The second principle is to separate the content from the container . This means representing elements as reusable objects with the key idea that the object should look the same regardless of its position on the page.
OOCSS offers well-thought-out guidelines, but it does not very accurately describe the specifics of this approach. Subsequent methodologies like SMACSS took key concepts and added more details to make them easier to work with.
SMACSS
SMACSS (Scalable and Modular Architecture for CSS) appeared in 2011 as a methodology that recommends writing CSS in five separate categories: basic rules, layout rules, modules, state rules, and topic rules . The SMACSS methodology also recommends a specific naming convention. For example, in layout rules, class names should be prefixed with
l-or layout-. In state rules, class names must be prefixed with prefixes that describe the state, for example, is-hiddenor is-collapsed.SMACSS has much more specificity than OOCSS, but this methodology still requires careful consideration of which CSS rules should be categorized. Subsequent approaches like BEM partly take decisions, so they are easier to put into practice.
Bem
Introduced in 2010, the BEM (Block, Element, Modifier) methodology is based on dividing the user interface into independent blocks. A block is a reusable component (an example would be a search form defined as
The BEM methodology is easy to understand, with a specific naming convention, which allows beginners to apply it without having to make any complex decisions. The flip side of the coin is that some class names are rather verbose and do not correspond to the traditional rules for specifying semantic names . Subsequently, new methodologies appeared, such as Atomic CSS, where this unconventional approach reached a whole new level!
Atomic css
The Atomic CSS methodology (also known as Functional CSS) appeared in 2014. It is based on the idea of creating small, highly specialized classes with names that are based on a visual function. This approach is completely opposite to the aforementioned OOCSS, SMACSS, and BEM: instead of treating the elements on the page as reusable objects, Atomic CSS generally ignores these objects and applies reusable highly specialized utility classes to style each element. So instead
If your first reaction to this example is to recoil in horror, you are not alone. Many see this methodology as an absolute violation of established CSS best practices. However, there have been many substantive discussions that question the effectiveness of these practices in some cases. This article places emphasis on how the traditional separation of tasks leads to the creation of CSS that depends on HTML (even when using methodologies like BEM), while the “atomic” or functional approach forces you to create HTML that depends on CSS. Both options are acceptable, but upon closer inspection you will find that a complete separation of CSS and HTML is not possible in principle!
Other CSS methodologies like CSS in JS actually include the understanding that CSS and HTML will always depend on each other. This recognition led to the creation of one of the most controversial methodologies to date ...
CSS in JS
CSS methodology in JS introduced in 2014. It is based on defining CSS styles not in a separate stylesheet, but right inside each component. This methodology was developed for the React JavaScript framework (which itself chose the ambiguous approach of defining HTML for a component directly in JavaScript instead of a separate HTML file). Initially, the methodology used nested styles, but in later implementations JavaScript generated CSS code (with unique class names by component) and inserted it into the document along with the style tag.
The CSS methodology in JS is also completely contrary to established CSS best practices for content sharing. The fact is that over time, our ways of using the web have changed dramatically. Initially, the web consisted mainly of static sites - there, separating the HTML content from the CSS presentation made perfect sense. Nowadays, the Web is used for dynamic web applications - here reusable components make sense.
The goal of the CSS methodology in JS is to allow the definition of hard-bound components that consist of their own encapsulated HTML / CSS / JS, so that CSS from one component has no way to affect other components. React was one of the first popular frameworks that promoted these components with tight boundaries. Under his influence, the same components were introduced in other popular frameworks such as Angular, Ember and Vue.js. It is important to note that the CSS methodology in JS is relatively new, so there is a lot of experimentation going on - developers are trying to establish new best practices for CSS in the era of web application components.
It's easy to get confused in so many different CSS methodologies, but it’s important to remember that there is no one right approach — you should present them as different accessible tools that you can use when you have a fairly complex CSS code base. It is convenient to have a choice of different thoughtful approaches, so that all the latest experiments in this area will benefit every developer in the long run!
Conclusion
This is what modern CSS looks like in a nutshell. We discussed the use of CSS for basic styles with styling properties, the use of CSS for layout using float, flexbox and grid, the use of a CSS preprocessor for new syntax such as variables and mixins, the use of a CSS post processor for transformation functions such as adding vendor prefixes, as well as CSS methodology for reliable maintenanceand overcoming the global nature of CSS styles. We had no chance to understand in detail many other CSS functions, such as advanced selectors, transitions, animations, forms, dynamic variables - the list goes on and on. There is much to discuss in CSS — if someone says it's simple, then he probably doesn't know half!
Modern CSS can definitely be awkward to work with because it continues to change and evolve rapidly. But it’s important to remember the historical context of how the Network evolved over the years - and it's nice to know that a lot of smart people work on specific tools and methodologies so that the best CSS practices evolve along with the web. Now is an exciting time to be a web developer, and I hope this information serves as a map on your journey!

- Ha! But all the tough guys still hate CSS, right?
- As I said, not all at once!
-… okay. Let me at least enjoy CSS memes, because CSS is cool [label goes beyond borders]