Automating the process of quality control of corporate data storage
In Rostelecom, as in any large company, there is a corporate data storage (CDR). Our CDW is constantly expanding and expanding, we build on it useful storefronts, reports and data cubes. At some point we were faced with the fact that poor-quality data prevent us from building storefronts, the resulting aggregates do not converge with the aggregates of the source systems and cause misunderstanding of the business. For example, data with Null values in foreign keys (foreign key) are not connected to data from other tables.
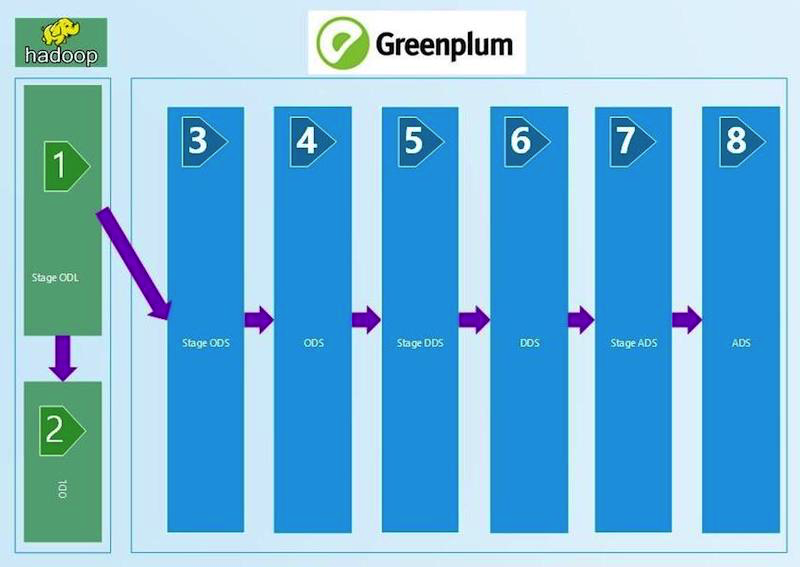
Brief scheme of CDW:
We understood that we needed a regular reconciliation process to ensure data quality. Of course, automated and allowing each of the technological levels to be confident in the quality of data and their convergence, both vertically and horizontally. As a result, we simultaneously reviewed three ready-made platforms for managing reconciliations from various vendors and wrote our own. Share experiences in this post.
The disadvantages of ready-made platforms are well known to everyone: price, limited flexibility, the inability to add and fix functionality. Pluses - parts of mdm (gold data, etc.), training and support are also closed. After evaluating this, we quickly forgot about the purchase and concentrated on developing our solution.
The core of our system is written in Python, and the database of metadata for storing, logging and storing the results is on Oracle. Libraries for Python are written a lot, we use the necessary minimum for Hive (pyhive), GreenPlum (pgdb), Oracle (cx_Oracle) connections. Connecting another type of source should also not be a problem.
We add the resulting data sets (result set) to the resulting Oracle tables, evaluating the status of the matching checkout (SUCCESS / ERROR) as we go. The resulting tables are configured with APEX in which the visualization of the results is built, which is convenient for both maintenance and management.
To run the checks in the Vault, the Informatica orchestrator is used, which loads data. When you receive the status of the successful download of this data automatically begin to verify. The use of query parameterization and CDW metadata allows the use of matching query templates for sets of tables.
Now about the reconciliations implemented on this platform.
We started with technical reconciliations that compare the amount of data at the input and the layers of the CDW with the imposition of certain filters. We take the ctl file with the data entered at the CDW, read the number of records from it and compare it with the table on the Stage ODL and / or Stage ODS (1, 2, 3 in the diagram). The matching criterion is defined in the equality of the number of records (count). If the amount converges, the result is SUCCESS, no - ERROR and manual error analysis.
This chain of technical reconciliations compared the number of records stretches to the ADS layer (8 in the diagram). Filters are changed between layers, which depend on the type of loading — DIM (reference book), HDIM (historical reference book), FACT (actual charge tables), etc. — as well as on the versionality of SCD and the layer. The closer to the showcase layer, the more complex filtering algorithms we use.
The input data also made a technical reconciliation in Python, which detects duplicates in key fields. In GreenPlum, the key fields (PK) are not protected from duplicates by the database system tools. So we wrote a Python script that reads the fields of the loaded table from the PK metadata and generates a SQL script that checks for duplicates. The flexibility of the approach allows us to use PK consisting of one or more fields, which is extremely convenient. This reconciliation stretches to the STG ADS layer.
An example of python-code verification of uniqueness. Calling, passing connection parameters and putting the results into the resulting table is performed by the control module in Python.
Verification for the absence of NULL values is built similarly to the previous one and also in Python. We read fields from the metadata of the load, which cannot have empty (NULL) values and check their fullness. Verification is used up to the DDS layer (6 in the first diagram).
A trend analysis of incoming data packets is also implemented at the entrance to the repository. The amount of incoming data upon receipt of a new package is recorded in the history table. With a significant change in the amount of data, the person responsible for the table and the SI (source system) receives a notification to the mail (in the plans), sees the APEX error before the dubious data packet reaches the Storage and finds out the reason for this with the SI.
Between STG (STAGE) _ODS and ODS (operational data layer) (3 and 4 in the diagram) technical deletion fields appear (deletion indicator = deleted_ind), the correctness of which we also fill in using SQL queries. Missing input data must be marked as deleted in the ODS.
The result of the reconciliation script we expect to see zero number of errors. In the presented example of verification, the parameters ~ # PKG_ID # ~ are passed through the Python control block, and parameters like ~ P_JOIN_CONDITION ~ and ~ PERIOD_COL ~ are filled from the table metadata, the very name of the table ~ TABLE ~ from the launch parameters.
Below is the parameterized reconciliation. Sample SQL reconciliation code between STG_ODS and ODS for HDIM type:
Example of SQL reconciliation code between STG_ODS and ODS for HDIM type with substituted parameters:
Beginning with ODS, history is kept in reference books, therefore, it should be checked for the absence of intersections and gaps. This is done by counting the number of incorrect values in the history and writing the resulting number of errors in the resulting table. If there are errors in the history of the history, they will have to search manually. Reconciliation depends on the type of download - HDIM (reference with history) in the first place. We carry out reconciliations of the correctness of the history for reference books up to the ADS layer.
On the DDS layer (6 in the first diagram), different SI (source systems) are connected into one table, HUB surrogate key generation tables appear for data bundles from different source systems. We check them for the uniqueness of the python-check, similar to the stage layer.
On the DDS layer, it is necessary to check that after merging with the HUB-table, in the key fields, no values of the type 0, -1, -2 appear, meaning incorrect merging of the tables, lack of data. They could appear in the absence of the necessary data in the HUB-table. And this is a mistake for manual analysis.
The most complex reconciliations for the data of the ADS storefront (8 in the first diagram). For complete confidence in the convergence of the result obtained, a verification with the source system on the aggregation of the amount of charges is deployed here. On the one hand, there is a class of indicators, which include aggregated charges. We collect them in a month from the display of the CCD. On the other hand, we take the units of the same charges from the source system. A discrepancy of no more than 1% or a definite and agreed absolute value is acceptable. The result sets obtained by checking are placed in the specially created resulting data sets, the resulting Oracle tables. Data comparison is done in the Oracle view. Visualization of the obtained results in APEX. The presence of a whole data set (result set) allows us
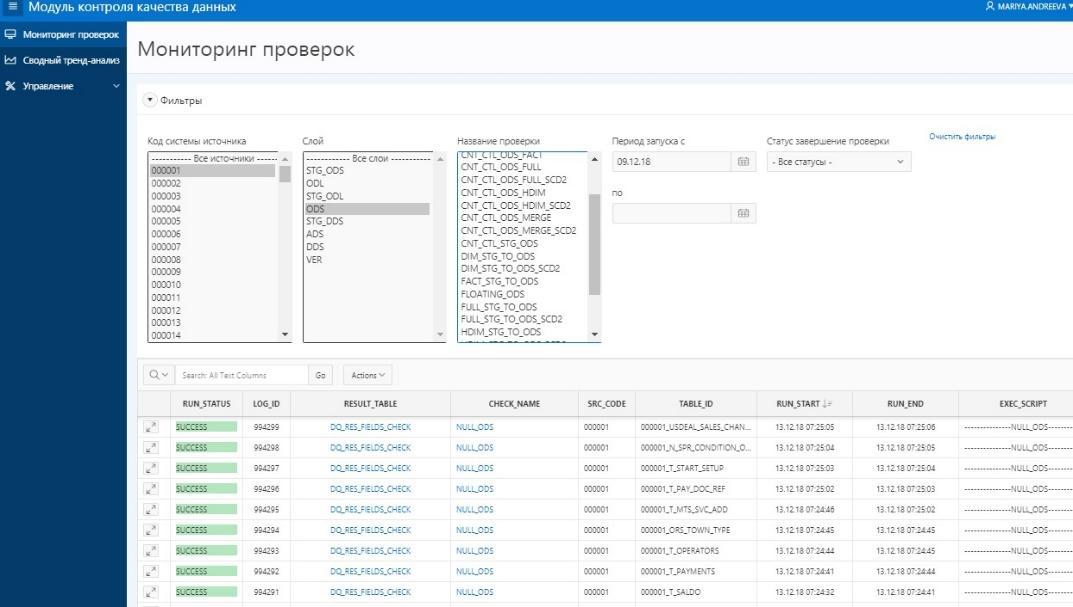
Presentation of the results of reconciliations for users in APEX
At the moment we have a workable and actively used application for reconciliation of data. Of course, we have plans to further develop both the quantity and quality of the reconciliations, and the development of the platform itself. Own development allows us to change and modify the functionality quickly enough.
The article was prepared by the data management team of Rostelecom.
Brief scheme of CDW:
We understood that we needed a regular reconciliation process to ensure data quality. Of course, automated and allowing each of the technological levels to be confident in the quality of data and their convergence, both vertically and horizontally. As a result, we simultaneously reviewed three ready-made platforms for managing reconciliations from various vendors and wrote our own. Share experiences in this post.
The disadvantages of ready-made platforms are well known to everyone: price, limited flexibility, the inability to add and fix functionality. Pluses - parts of mdm (gold data, etc.), training and support are also closed. After evaluating this, we quickly forgot about the purchase and concentrated on developing our solution.
The core of our system is written in Python, and the database of metadata for storing, logging and storing the results is on Oracle. Libraries for Python are written a lot, we use the necessary minimum for Hive (pyhive), GreenPlum (pgdb), Oracle (cx_Oracle) connections. Connecting another type of source should also not be a problem.
We add the resulting data sets (result set) to the resulting Oracle tables, evaluating the status of the matching checkout (SUCCESS / ERROR) as we go. The resulting tables are configured with APEX in which the visualization of the results is built, which is convenient for both maintenance and management.
To run the checks in the Vault, the Informatica orchestrator is used, which loads data. When you receive the status of the successful download of this data automatically begin to verify. The use of query parameterization and CDW metadata allows the use of matching query templates for sets of tables.
Now about the reconciliations implemented on this platform.
We started with technical reconciliations that compare the amount of data at the input and the layers of the CDW with the imposition of certain filters. We take the ctl file with the data entered at the CDW, read the number of records from it and compare it with the table on the Stage ODL and / or Stage ODS (1, 2, 3 in the diagram). The matching criterion is defined in the equality of the number of records (count). If the amount converges, the result is SUCCESS, no - ERROR and manual error analysis.
This chain of technical reconciliations compared the number of records stretches to the ADS layer (8 in the diagram). Filters are changed between layers, which depend on the type of loading — DIM (reference book), HDIM (historical reference book), FACT (actual charge tables), etc. — as well as on the versionality of SCD and the layer. The closer to the showcase layer, the more complex filtering algorithms we use.
The input data also made a technical reconciliation in Python, which detects duplicates in key fields. In GreenPlum, the key fields (PK) are not protected from duplicates by the database system tools. So we wrote a Python script that reads the fields of the loaded table from the PK metadata and generates a SQL script that checks for duplicates. The flexibility of the approach allows us to use PK consisting of one or more fields, which is extremely convenient. This reconciliation stretches to the STG ADS layer.
unique_check
import sys
import os
from datetime import datetime
log_tmstmp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
defdo_check(args, context):
tab = args[0]
data = []
fld_str = ""try:
sql = """SELECT 't_'||lower(table_id) as tn, lower(column_name) as cn
FROM src_column@meta_data
WHERE table_id = '%s' and is_primary_key = 'Y'""" % (tab,)
for fld in context['ora_get_data'](context['ora_con'], sql):
fld_str = fld_str + (fld_str and",") + fld[1]
if fld_str:
config = context['script_config']
con_gp = context['pg_open_con'](config['user'], config['pwd'], config['host'], config['port'], config['dbname'])
sql = """select %s as pkg_id, 't_%s' as table_name, 'PK fields' as column_name, coalesce(sum(cnt), 0) as NOT_UNIQUE_PK, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS') as sys_creation from (select 1 as cnt from edw_%s.t_%s where %s group by %s having count(*) > 1 ) sq;
""" % (context["package"] or'0',tab.lower(), args[1], tab.lower(), (context["package"] and ("package_id = " + context["package"]) or"1=1"), fld_str )
data.extend(context['pg_get_data'](con_gp, sql))
con_gp.close()
except Exception as e:
raisereturn data or [[(context["package"] or0),'t_'+tab.lower(), None, 0, log_tmstmp]]
if __name__ == '__main__':
sys.exit(do_check([sys.argv[1], sys.argv[2]], {}))An example of python-code verification of uniqueness. Calling, passing connection parameters and putting the results into the resulting table is performed by the control module in Python.
Verification for the absence of NULL values is built similarly to the previous one and also in Python. We read fields from the metadata of the load, which cannot have empty (NULL) values and check their fullness. Verification is used up to the DDS layer (6 in the first diagram).
A trend analysis of incoming data packets is also implemented at the entrance to the repository. The amount of incoming data upon receipt of a new package is recorded in the history table. With a significant change in the amount of data, the person responsible for the table and the SI (source system) receives a notification to the mail (in the plans), sees the APEX error before the dubious data packet reaches the Storage and finds out the reason for this with the SI.
Between STG (STAGE) _ODS and ODS (operational data layer) (3 and 4 in the diagram) technical deletion fields appear (deletion indicator = deleted_ind), the correctness of which we also fill in using SQL queries. Missing input data must be marked as deleted in the ODS.
The result of the reconciliation script we expect to see zero number of errors. In the presented example of verification, the parameters ~ # PKG_ID # ~ are passed through the Python control block, and parameters like ~ P_JOIN_CONDITION ~ and ~ PERIOD_COL ~ are filled from the table metadata, the very name of the table ~ TABLE ~ from the launch parameters.
Below is the parameterized reconciliation. Sample SQL reconciliation code between STG_ODS and ODS for HDIM type:
select
package_id as pkg_id,
'T_~TABLE~'as table_name,
to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'),
coalesce(empty_in_ods, 0) as empty_in_ods,
coalesce(not_equal_md5, 0) as not_equal_md5,
coalesce(deleted_in_ods, 0) as deleted_in_ods,
coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods,
max_load_dttm
from
(select
max (src.package_id) as package_id,
sum (casewhen tgt.md5 isnullthen1else0end) as empty_in_ods,
sum (casewhen src.md5<>tgt.md5 and tgt.~PK~ isnotnulland tgt.deleted_ind = 0then1else0end) as not_equal_md5,
sum (casewhen tgt.deleted_ind = 1and src.md5=tgt.md5 then1else0end) as deleted_in_ods
from EDW_STG_ODS.T_~TABLE~ src
leftjoin EDW_ODS.T_~TABLE~ tgt
on ~P_JOIN_CONDITION~ and tgt.active_ind ='Y'where ~#PKG_ID#~ = 0
or src.package_id = ~#PKG_ID#~
) aa,
(selectsum (casewhen src.~PK~ isnullthen1else0end) as not_deleted_in_ods,
max (tgt.load_dttm) as max_load_dttm
from EDW_STG_ODS.T_~TABLE~ src
rightjoin EDW_ODS.T_~TABLE~ tgt
on ~P_JOIN_CONDITION~
where tgt.deleted_ind = 0and tgt.active_ind ='Y'
and tgt.~PERIOD_COL~ between (selectmin(~PERIOD_COL~) from EDW_STG_ODS.T_~TABLE~ where ~#PKG_ID#~ = 0 or package_id = ~#PKG_ID#~)
and (selectmax(~PERIOD_COL~) from EDW_STG_ODS.T_~TABLE~ where ~#PKG_ID#~ = 0 or package_id = ~#PKG_ID#~)
) bb
where1=1Example of SQL reconciliation code between STG_ODS and ODS for HDIM type with substituted parameters:
--------------HDIM_CHECKS---------------select
package_id as pkg_id,
'TABLE_NAME'as table_name,
to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'),
coalesce(empty_in_ods, 0) as empty_in_ods,
coalesce(not_equal_md5, 0) as not_equal_md5,
coalesce(deleted_in_ods, 0) as deleted_in_ods,
coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods,
max_load_dttm
from
(select
max (src.package_id) as package_id,
sum (casewhen tgt.md5 isnullthen1else0end) as empty_in_ods,
sum (casewhen src.md5<>tgt.md5 and tgt.ACTION_ID isnotnulland tgt.deleted_ind = 0then1else0end) as not_equal_md5,
sum (casewhen tgt.deleted_ind = 1and src.md5=tgt.md5 then1else0end) as deleted_in_ods
from EDW_STG_ODS.TABLE_NAME src
leftjoin EDW_ODS.TABLE_NAME tgt
on SRC.PK_ID=TGT.PK_ID and tgt.active_ind ='Y'where709083887 = 0
or src.package_id = 709083887
) aa,
(selectsum (casewhen src.PK_ID isnullthen1else0end) as not_deleted_in_ods,
max (tgt.load_dttm) as max_load_dttm
from EDW_STG_ODS.TABLE_NAME src
rightjoin EDW_ODS.TABLE_NAME tgt
on SRC.PK_ID =TGT.PK_ID
where tgt.del_ind = 0and tgt.active_ind ='Y'
and tgt.DATE_SYS between (selectmin(DATE_SYS) from EDW_STG_ODS.TABLE_NAME where70908 = 0or package_id = 70908)
and (selectmax(DATE_SYS) from EDW_STG_ODS.TABLE_NAME where70908 = 0or package_id = 70908)
) bb
where1=1Beginning with ODS, history is kept in reference books, therefore, it should be checked for the absence of intersections and gaps. This is done by counting the number of incorrect values in the history and writing the resulting number of errors in the resulting table. If there are errors in the history of the history, they will have to search manually. Reconciliation depends on the type of download - HDIM (reference with history) in the first place. We carry out reconciliations of the correctness of the history for reference books up to the ADS layer.
On the DDS layer (6 in the first diagram), different SI (source systems) are connected into one table, HUB surrogate key generation tables appear for data bundles from different source systems. We check them for the uniqueness of the python-check, similar to the stage layer.
On the DDS layer, it is necessary to check that after merging with the HUB-table, in the key fields, no values of the type 0, -1, -2 appear, meaning incorrect merging of the tables, lack of data. They could appear in the absence of the necessary data in the HUB-table. And this is a mistake for manual analysis.
The most complex reconciliations for the data of the ADS storefront (8 in the first diagram). For complete confidence in the convergence of the result obtained, a verification with the source system on the aggregation of the amount of charges is deployed here. On the one hand, there is a class of indicators, which include aggregated charges. We collect them in a month from the display of the CCD. On the other hand, we take the units of the same charges from the source system. A discrepancy of no more than 1% or a definite and agreed absolute value is acceptable. The result sets obtained by checking are placed in the specially created resulting data sets, the resulting Oracle tables. Data comparison is done in the Oracle view. Visualization of the obtained results in APEX. The presence of a whole data set (result set) allows us
Presentation of the results of reconciliations for users in APEX
At the moment we have a workable and actively used application for reconciliation of data. Of course, we have plans to further develop both the quantity and quality of the reconciliations, and the development of the platform itself. Own development allows us to change and modify the functionality quickly enough.
The article was prepared by the data management team of Rostelecom.