Machine learning to find errors in the code: how I trained at JetBrains Research
We recently talked about how to get an internship at Google. In addition to Google, our students try their hand at JetBrains, Yandex, Acronis and other companies.
In this article, I will share my experience in internships at JetBrains Research , talk about the tasks that are being solved there, and elaborate on how to find bugs in the program code using machine learning.

My name is Egor Bogomolov, I am a 4th year student of the Bachelor degree in St. Petersburg Higher School of Science in Applied Mathematics and Computer Science. The first 3 years I, like my classmates, studied at the Academic University, and from this September we moved to the Higher School of Economics with the whole department.
After the 2nd year, I went to a summer internship at Google Zurich. I worked there for three months on the Android Calendar team, most of the time doing frontend and a bit of UX-research. The most interesting part of my work was researching how calendar interfaces might look in the future. It was pleasant that almost all the work I had done by the end of the internship got into the main version of the application. But the topic of internship at Google is very well covered in the previous post, so I’ll talk about what I did this summer.
JetBrains Research is a set of laboratories working in various fields: programming languages, applied mathematics, machine learning, robotics, and others. Within each direction there are several scientific groups. I, by virtue of my direction, are best acquainted with the activities of groups in the field of machine learning. Each of them hosts weekly seminars where members of the group or invited guests talk about their work or interesting articles in their field. Many students from HSE come to these seminars, since they pass through the road from the main building of the St. Petersburg Higher School of Economics campus.
On our bachelor program, we are surely engaged in research work (R & D) and present the results of research twice a year. Often this work smoothly develops into summer internships. This happened with my research work: this summer I had an internship in the laboratory “Methods of machine learning in software engineering” with my supervisor Timofei Bryksin. The tasks that are being worked on in this laboratory include the automatic suggestion of refactorings, the analysis of the code style of programmers, the autocompletion of the code, the search for errors in the program code.
My internship lasted two months (July and August), and in the fall I continued to work on the assigned tasks within the framework of R & D. I worked in several directions, the most interesting of them, in my opinion, was the automatic search for bugs in the code, and I want to tell you about it. The starting point was an article by Michael Pradel .
Why search for bugs is more or less clear. Let's see how they do it now. Modern bug detectors are mainly based on static code analysis. For each type of error, pre-noticed patterns are sought by which it can be determined. Then, to reduce the number of false positives, heuristics are added that were invented for each individual case. Patterns can be searched for both in an abstract syntax tree (AST), built by code, and in control flow or data flow graphs.
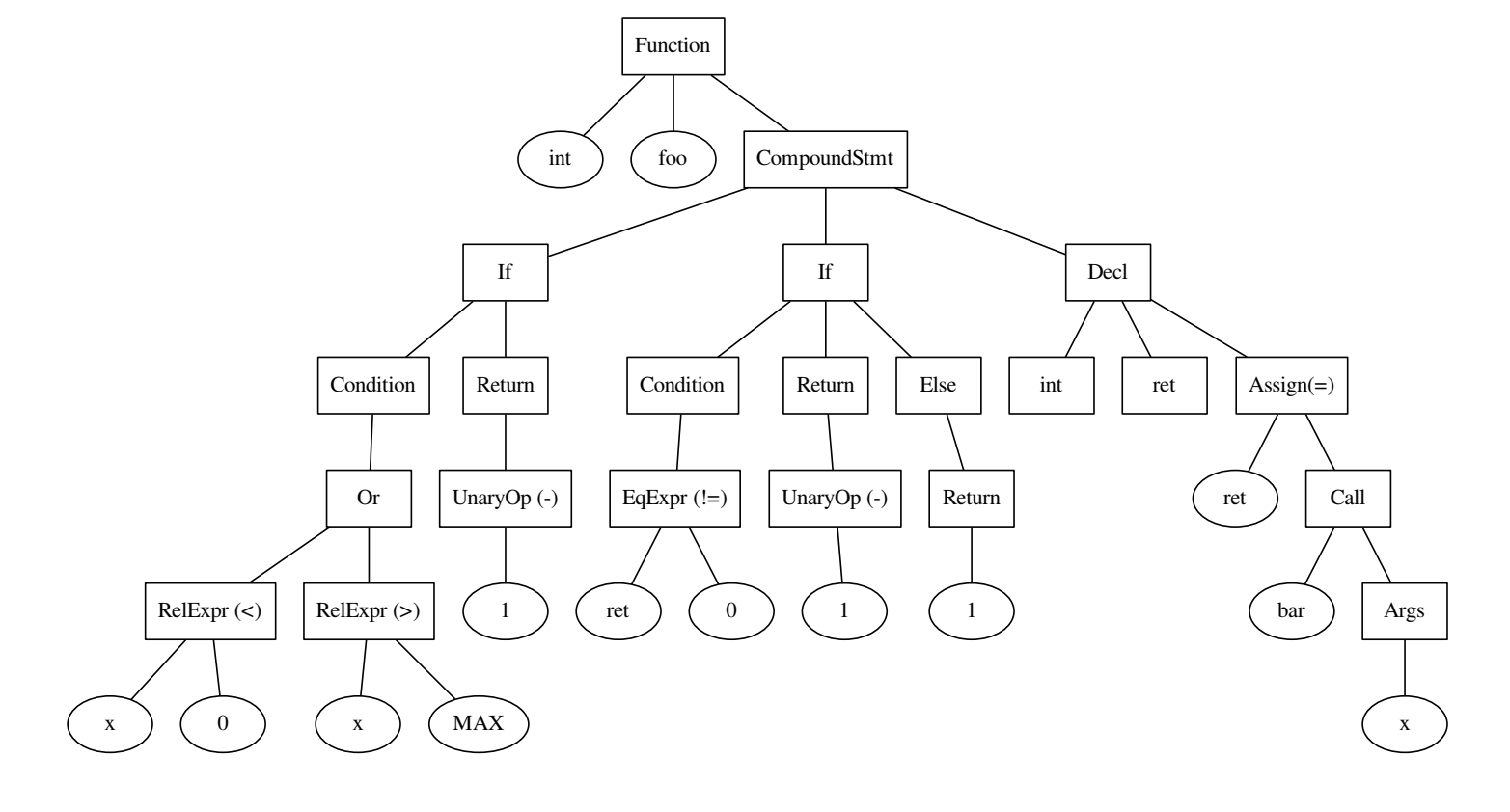
The code and the tree that was built on it.
To understand how this works, consider an example. The kind of bugs can be using = instead of == in C ++. Let's look at the following piece of code:
It contains an error in the conditional expression, while the first = in assigning the value of a variable is correct. Hence the pattern: if an assignment is used inside a condition in an if, this is a potential bug. Looking for such a pattern in AST, we can detect the error and correct it.
In the more general case, we will not be able to find a way to describe the error so easily. Suppose we want to determine the correct order of the operands. Again, look at the code snippets:
In the first case, the use of 1-i was erroneous, and in the second it was completely correct, which is clear from the context. But how to describe it in the form of a pattern? With the complication of the type of errors, it is necessary to consider a larger part of the code and parse more and more cases.
The last motivating example: useful information is also contained in the names of methods and variables. It is even harder to express it with some manually defined conditions.
It is clear to the person that, most likely, the arguments in the function call are confused, because we have an understanding that x looks more like xDim than yDim. But how to report this to the detector? You can add some heuristics of the form “the variable name is the prefix of the argument name”, but let's say that x is more often the width than the height, so no longer express it.
Total: the problem of the modern approach to the search for errors is that a lot of work has to be done by hand: to determine the patterns, add heuristics, because of this, adding support for a new type of errors to the detector becomes time-consuming. In addition, it is difficult to use an important piece of information that the developer left in the code: the names of variables and methods.
As you can see, in many examples, errors are visible to a person, but they are hard to describe formally. In such situations, machine learning techniques can often help. Let's look at finding permuted arguments in the function call and understand what we need to look for them using machine learning:
We can hope that in most of the code laid out in open access, the arguments in the function calls are in the correct order. Therefore, for code samples without bugs, you can take some big dataset. In the case of the author of the original article, this was JS 150K (150 thousand files in Javascript), in our case, a similar dataset for Python.
Finding code with bugs is much more difficult. But we can not look for someone's mistakes, but make them ourselves! For the type of errors, you need to specify a function that, on the correct piece of code, will do a spoiled one. In our case, rearrange the arguments in the function call.
Armed with a lot of good and bad code, we are almost ready to teach anyone anything. Before that, we still need to answer the question: how to represent code fragments?
The function call can be represented as a tuple from the name of the method, the name of the one whose method is, the names and types of arguments passed to the variables. If we learn to vectorize individual tokens (the names of variables and methods, all the “words” found in the code), then we can take the concatenation of the vectors of the tokens we are interested in and get the desired vector for the fragment.
To vectorize tokens, let's take a look at how words in ordinary texts are vectorized. One of the most successful and popular ways is the word2vec proposed in 2013.
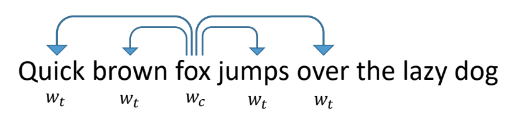
It works in the following way: we teach the network to predict other words that are found next to it in the texts. At the same time, the network looks like an input layer of the size equal to the dictionary, a hidden layer of the vectorization size, which we want to receive, and an output layer, also of the size of the dictionary. In the course of training, the networks feed into the input a vector with one unit at the place of the word under consideration (fox), and at the output we want to receive words that are found within the window around this word (quick, brown, jumps, over). In this case, the network first translates all words into a vector on a hidden layer, and then makes a prediction.
The resulting vectors for individual words have good properties. For example, word vectors with similar meanings are close to each other, and the sum and difference of vectors are the addition and difference of the “meanings” of words.
To make a similar vectorization of tokens in the code, you need to somehow define the environment that will be predicted. They can be information from AST: types of vertices around, occurring tokens, position in the tree.
After receiving the vectorization, you can see which tokens are similar to each other. For this we calculate the cosine distance between them. As a result, the following neighboring vectors (number - cosine distance) are obtained for Javascript:
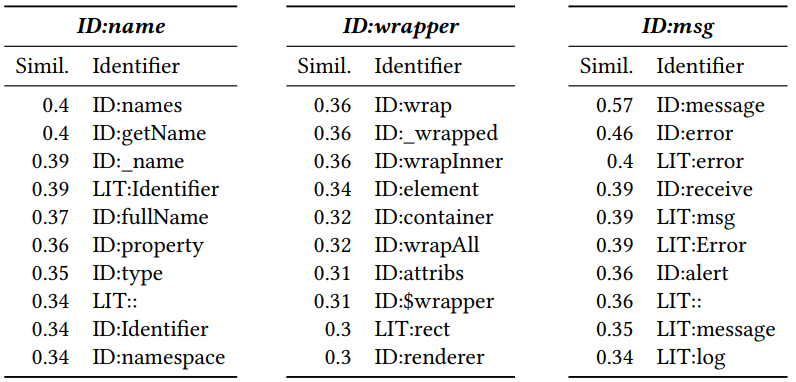
ID and LIT added at the beginning indicate whether the token is an identifier (the name of a variable, method) or a literal (constant). It can be seen that proximity is meaningful.
Having obtained vectorization for individual tokens, it is quite simple to get an idea for a piece of code with potential error: it is a concatenation of vectors important for the classification of tokens. A two-layer perceptron with a ReLU as an activation function and a dropout to reduce retraining is learned by pieces of code. Learning converges quickly, the resulting model is small and can make predictions for hundreds of examples per second. This allows you to use it in real time, which will be discussed later.
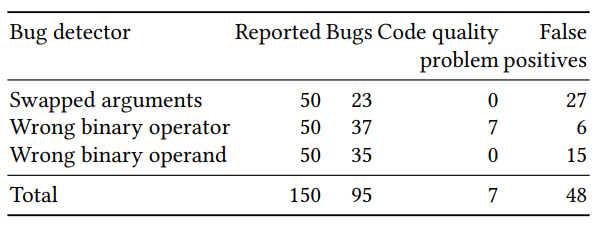
The quality assessment of the classifier obtained was divided into two parts: evaluation of a large number of artificially generated examples and manual testing of a small number (50 for each detector) of examples with the highest predicted probability. The results for the three detectors (rearranged arguments, the correctness of the binary operator and the binary operand) were as follows:
Some of the predicted errors would be hard to find with the classical search methods. An example with res and err swapped in a p.done call:
There were also examples in which errors are not contained, but it would be worthwhile to rename variables in order not to introduce a person who is trying to understand the code into a confusion. For example, the addition of width and each does not seem like a good idea, although it turned out not to be a bug:
I was involved in transferring the work of Michael Pradel from js to python, and then creating a plugin for PyCharm that implements inspections based on the method described above. At the same time, Python 150K dataset was used (150 thousand Python files available on GitHub).
First, it turned out that there are more different tokens in Python than in javascript. For js, the 10,000 most popular tokens accounted for more than 90% of all those encountered, while for Python it was necessary to use about 40,000. This led to an increase in the size of the display of tokens in the vector, which complicated porting to the plugin.
Secondly, by implementing the search for invalid arguments in function calls for Python and looking at the results manually, I received an error rate of more than 90%, which differed from the results for js. Having understood the reasons, it turned out that in javascript more functions are declared in the same file as their calls. I, following the example of the author of the article, at first did not allow the declaration of functions from other files, which led to poor results.
By the end of August, I completed the implementation for Python and wrote the basis for the plugin. The plugin continues to be developed, now this student is engaged in Anastasia Tuchina from our laboratory.
Steps to try out how the plugin works can be found on the wiki repository.
Links to github:
Repository with Python implementation
Plugin repository
In this article, I will share my experience in internships at JetBrains Research , talk about the tasks that are being solved there, and elaborate on how to find bugs in the program code using machine learning.
About myself
My name is Egor Bogomolov, I am a 4th year student of the Bachelor degree in St. Petersburg Higher School of Science in Applied Mathematics and Computer Science. The first 3 years I, like my classmates, studied at the Academic University, and from this September we moved to the Higher School of Economics with the whole department.
After the 2nd year, I went to a summer internship at Google Zurich. I worked there for three months on the Android Calendar team, most of the time doing frontend and a bit of UX-research. The most interesting part of my work was researching how calendar interfaces might look in the future. It was pleasant that almost all the work I had done by the end of the internship got into the main version of the application. But the topic of internship at Google is very well covered in the previous post, so I’ll talk about what I did this summer.
What is JB Research?
JetBrains Research is a set of laboratories working in various fields: programming languages, applied mathematics, machine learning, robotics, and others. Within each direction there are several scientific groups. I, by virtue of my direction, are best acquainted with the activities of groups in the field of machine learning. Each of them hosts weekly seminars where members of the group or invited guests talk about their work or interesting articles in their field. Many students from HSE come to these seminars, since they pass through the road from the main building of the St. Petersburg Higher School of Economics campus.
On our bachelor program, we are surely engaged in research work (R & D) and present the results of research twice a year. Often this work smoothly develops into summer internships. This happened with my research work: this summer I had an internship in the laboratory “Methods of machine learning in software engineering” with my supervisor Timofei Bryksin. The tasks that are being worked on in this laboratory include the automatic suggestion of refactorings, the analysis of the code style of programmers, the autocompletion of the code, the search for errors in the program code.
My internship lasted two months (July and August), and in the fall I continued to work on the assigned tasks within the framework of R & D. I worked in several directions, the most interesting of them, in my opinion, was the automatic search for bugs in the code, and I want to tell you about it. The starting point was an article by Michael Pradel .
Automatic bugs search
How to find bugs now?
Why search for bugs is more or less clear. Let's see how they do it now. Modern bug detectors are mainly based on static code analysis. For each type of error, pre-noticed patterns are sought by which it can be determined. Then, to reduce the number of false positives, heuristics are added that were invented for each individual case. Patterns can be searched for both in an abstract syntax tree (AST), built by code, and in control flow or data flow graphs.
intfoo(){
if ((x < 0) || x > MAX) {
return -1;
}
int ret = bar(x);
if (ret != 0) {
return -1;
} else {
return1;
}
}
The code and the tree that was built on it.
To understand how this works, consider an example. The kind of bugs can be using = instead of == in C ++. Let's look at the following piece of code:
int value = 0;
…
if (value = 1) {
...
} else { … }
It contains an error in the conditional expression, while the first = in assigning the value of a variable is correct. Hence the pattern: if an assignment is used inside a condition in an if, this is a potential bug. Looking for such a pattern in AST, we can detect the error and correct it.
int value = 0;
…
if (value == 1) {
...
} else { … }
In the more general case, we will not be able to find a way to describe the error so easily. Suppose we want to determine the correct order of the operands. Again, look at the code snippets:
for (int i = 2; i < n; i++) {
a[i] = a[1 - i] + a[i - 2];
}
intbitReverse(int i){
return1 - i;
}
In the first case, the use of 1-i was erroneous, and in the second it was completely correct, which is clear from the context. But how to describe it in the form of a pattern? With the complication of the type of errors, it is necessary to consider a larger part of the code and parse more and more cases.
The last motivating example: useful information is also contained in the names of methods and variables. It is even harder to express it with some manually defined conditions.
intgetSquare(int xDim, int yDim){ … }
int x = 3, y = 4;
int s = getSquare(y, x);
It is clear to the person that, most likely, the arguments in the function call are confused, because we have an understanding that x looks more like xDim than yDim. But how to report this to the detector? You can add some heuristics of the form “the variable name is the prefix of the argument name”, but let's say that x is more often the width than the height, so no longer express it.
Total: the problem of the modern approach to the search for errors is that a lot of work has to be done by hand: to determine the patterns, add heuristics, because of this, adding support for a new type of errors to the detector becomes time-consuming. In addition, it is difficult to use an important piece of information that the developer left in the code: the names of variables and methods.
How can machine learning help?
As you can see, in many examples, errors are visible to a person, but they are hard to describe formally. In such situations, machine learning techniques can often help. Let's look at finding permuted arguments in the function call and understand what we need to look for them using machine learning:
- A large number of code examples without bugs
- A large number of code with errors of a given type
- Method of vectorization of code fragments
- A model that we will teach to distinguish code with errors and without
We can hope that in most of the code laid out in open access, the arguments in the function calls are in the correct order. Therefore, for code samples without bugs, you can take some big dataset. In the case of the author of the original article, this was JS 150K (150 thousand files in Javascript), in our case, a similar dataset for Python.
Finding code with bugs is much more difficult. But we can not look for someone's mistakes, but make them ourselves! For the type of errors, you need to specify a function that, on the correct piece of code, will do a spoiled one. In our case, rearrange the arguments in the function call.
How to vectorize code?
Armed with a lot of good and bad code, we are almost ready to teach anyone anything. Before that, we still need to answer the question: how to represent code fragments?
The function call can be represented as a tuple from the name of the method, the name of the one whose method is, the names and types of arguments passed to the variables. If we learn to vectorize individual tokens (the names of variables and methods, all the “words” found in the code), then we can take the concatenation of the vectors of the tokens we are interested in and get the desired vector for the fragment.
To vectorize tokens, let's take a look at how words in ordinary texts are vectorized. One of the most successful and popular ways is the word2vec proposed in 2013.
It works in the following way: we teach the network to predict other words that are found next to it in the texts. At the same time, the network looks like an input layer of the size equal to the dictionary, a hidden layer of the vectorization size, which we want to receive, and an output layer, also of the size of the dictionary. In the course of training, the networks feed into the input a vector with one unit at the place of the word under consideration (fox), and at the output we want to receive words that are found within the window around this word (quick, brown, jumps, over). In this case, the network first translates all words into a vector on a hidden layer, and then makes a prediction.
The resulting vectors for individual words have good properties. For example, word vectors with similar meanings are close to each other, and the sum and difference of vectors are the addition and difference of the “meanings” of words.
To make a similar vectorization of tokens in the code, you need to somehow define the environment that will be predicted. They can be information from AST: types of vertices around, occurring tokens, position in the tree.
After receiving the vectorization, you can see which tokens are similar to each other. For this we calculate the cosine distance between them. As a result, the following neighboring vectors (number - cosine distance) are obtained for Javascript:
ID and LIT added at the beginning indicate whether the token is an identifier (the name of a variable, method) or a literal (constant). It can be seen that proximity is meaningful.
Training classifier
Having obtained vectorization for individual tokens, it is quite simple to get an idea for a piece of code with potential error: it is a concatenation of vectors important for the classification of tokens. A two-layer perceptron with a ReLU as an activation function and a dropout to reduce retraining is learned by pieces of code. Learning converges quickly, the resulting model is small and can make predictions for hundreds of examples per second. This allows you to use it in real time, which will be discussed later.
results
The quality assessment of the classifier obtained was divided into two parts: evaluation of a large number of artificially generated examples and manual testing of a small number (50 for each detector) of examples with the highest predicted probability. The results for the three detectors (rearranged arguments, the correctness of the binary operator and the binary operand) were as follows:
Some of the predicted errors would be hard to find with the classical search methods. An example with res and err swapped in a p.done call:
var p = newPromise ();
if ( promises === null || promises . length === 0) {
p. done (error , result )
} else {
promises [0](error, result).then( function(res, err) {
p.done(res, err);
});
}
There were also examples in which errors are not contained, but it would be worthwhile to rename variables in order not to introduce a person who is trying to understand the code into a confusion. For example, the addition of width and each does not seem like a good idea, although it turned out not to be a bug:
var cw = cs[i].width + each;
Python transfer
I was involved in transferring the work of Michael Pradel from js to python, and then creating a plugin for PyCharm that implements inspections based on the method described above. At the same time, Python 150K dataset was used (150 thousand Python files available on GitHub).
First, it turned out that there are more different tokens in Python than in javascript. For js, the 10,000 most popular tokens accounted for more than 90% of all those encountered, while for Python it was necessary to use about 40,000. This led to an increase in the size of the display of tokens in the vector, which complicated porting to the plugin.
Secondly, by implementing the search for invalid arguments in function calls for Python and looking at the results manually, I received an error rate of more than 90%, which differed from the results for js. Having understood the reasons, it turned out that in javascript more functions are declared in the same file as their calls. I, following the example of the author of the article, at first did not allow the declaration of functions from other files, which led to poor results.
By the end of August, I completed the implementation for Python and wrote the basis for the plugin. The plugin continues to be developed, now this student is engaged in Anastasia Tuchina from our laboratory.
Steps to try out how the plugin works can be found on the wiki repository.
Links to github:
Repository with Python implementation
Plugin repository