Application Performance Analysis Practical Guide
You probably already know that a few months after the conferences we post videos of all the reports . And for the very best, as in the case of Sasha Goldshtn Goldshtein’s keynote , we are also preparing transcripts - so those who don’t like video format can join.
Sasha talks about methods and tools for analyzing application performance, including those developed by himself.
The article is based on Sasha's speech at the DotNext 2017 Piter conference. Sasha works as the technical director of the Israeli training and consulting company Sela and knows firsthand how to conduct a performance analysis. How to start it better than finish, what tools should be used, and which ones to avoid, read under the cut.
Let's start with the performance analysis framework. The following plan is used by developers, system administrators, any technical specialists:
Getting an accurate description of the problem from the client is much more difficult than it seems at first glance.
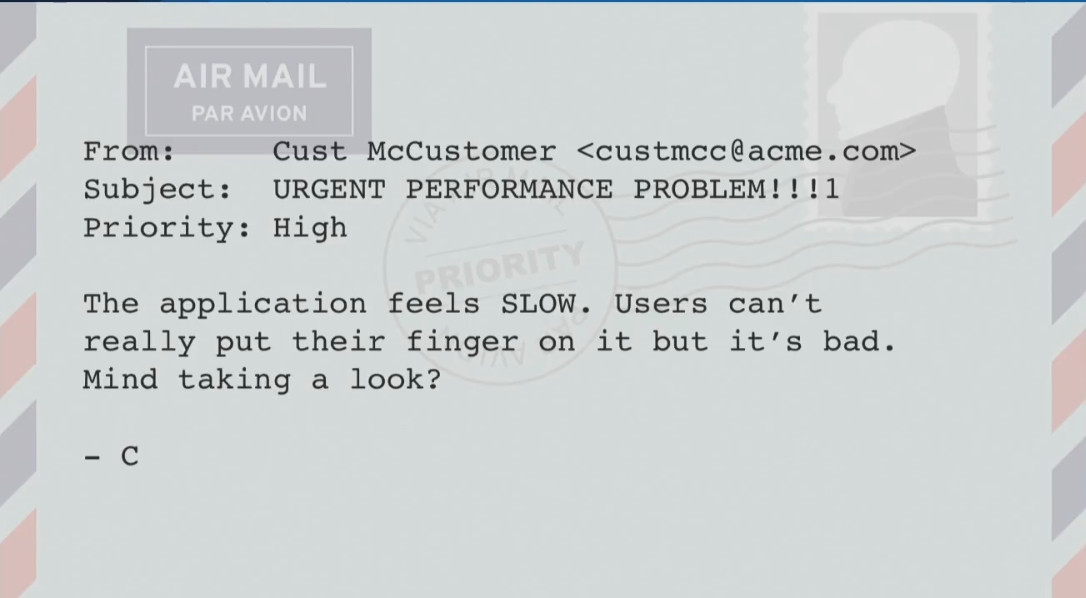
A client may have a problem like:
“The application is too SLOW. Users cannot say exactly when this happens, but it’s bad. Can you see? ”
Or
“We have a budget for work to improve productivity, can you look at our work environment and find a problem for two days?”
Of course, you can try, but it is unlikely to be a very good use of the allocated budget. The problem formulated more accurately may look like this:
“Starting at 4:25 in the morning, when accessing the ASP.NET site in 95% of cases, a delay of 1400 ms is observed (the usual response time is 60 ms). The delay is observed regardless of geographical location and does not decrease. We turned on automatic scaling, but that didn't help. ”
Such a description of the problem is already much more accurate, because I see the symptoms and understand where to look, and I know what can be considered a solution to the problem (reducing the delay to 60 ms).
Sometimes it is much more difficult to find out what exactly is required for a client than it seems at first glance.

Each company has its own performance requirements, which, unfortunately, are not always formulated. For example, they can be like this:
When such requirements exist, it remains only to test the system for compliance with them and understand how to solve the problem. But it’s important to understand that requirements do not come from nowhere; they must always be consistent with business goals. Having clearly defined requirements, you can always track statistics in the APM solution or in other ways and receive notifications when something goes wrong.
Before diving into the analysis methods that produce the result, I want to talk a bit about how the problem should not be analyzed. So you should definitely not:
I will give an example of one unsuccessful analysis, which was never completed. My task was to understand why sometimes, when saving and loading documents in the project management system, clients encounter significant delays. The system was connected to NetApp via SMB on the local network, and my task was to find out the network latency and latencies that might occur when working with the data warehouse.
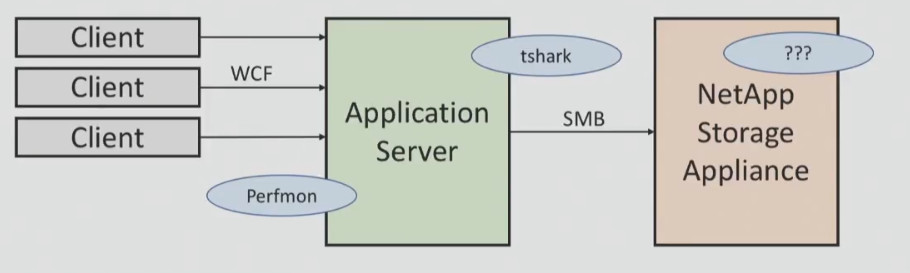
I had tools to track WCF and application server performance, I had a sniffer for network traffic, but I did not have access to the NetApp storage system. After a series of tests, I found out that the average response speed was 11 ms, however, some cases of a delay of 1200 ms were observed within 24 hours. I did not have enough information about what was happening on the part of NetApp, and it was necessary to get performance testing data.
From the client I was able to get only information that the response speed of the storage system can in no way be less than 5 ms. To my question about what this figure is: average or peak delay, I got the answer: this is the maximum average value for 60 seconds.I still don’t know what this value is, and I believe that you are not in the know either. He could take the average value every second and then take the maximum value from all means or maybe take the maximum value every second and then take the average from maximum ...

After that I found performance counters in the documentation for NetApp that are considered valid for this storage system . This is the average data per second, not per minute. I asked the client to provide me with this data, but was refused. This attempt to conduct the analysis ended.
For me, this is a classic case of how performance analysis cannot be done. I tried my best to get as much information as possible and not rely on assumptionsHowever, I did not succeed due to the lack of mutual understanding with the client. And this is a good example of why one cannot rely on assumptions and absurd beliefs.
Now about the unsuccessful use of tools.
Sometimes experts think that if they bought an expensive tool, then they simply must use it for all analysis options. I will give a classic example of using the wrong tool for analysis.
Run Visual Studio profiling tools in CPU fetch mode to test the performance of the search robot. The robot can do some things that do not load the processor, and if we conduct such a test, we can get something like this:
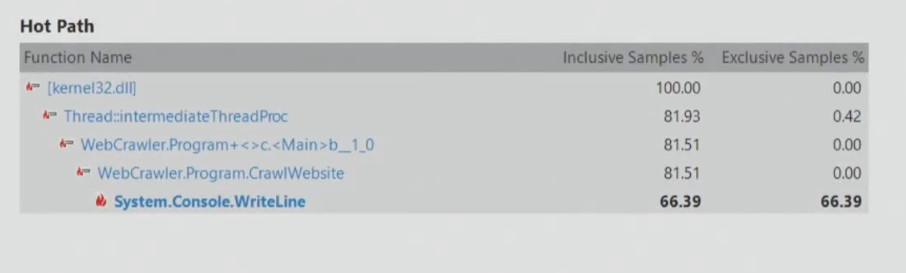
It follows that it is necessary to improve the performance of System.Console.WriteLine, since this method slows down the application. However, the search robot can simply wait for the arrival of network data, this is not connected with the processor. Therefore, you can never choose a tool for analysis on the principle of "simply because we bought it, and we need to recapture its value."
Sometimes you just don’t know what to look for, in which case I propose a methodology that is often used by engineers around the world. This is the USE (Utilization, Saturation, Errors) method, which works in several stages:
Here's what the USE method might look like for hardware and software resources:
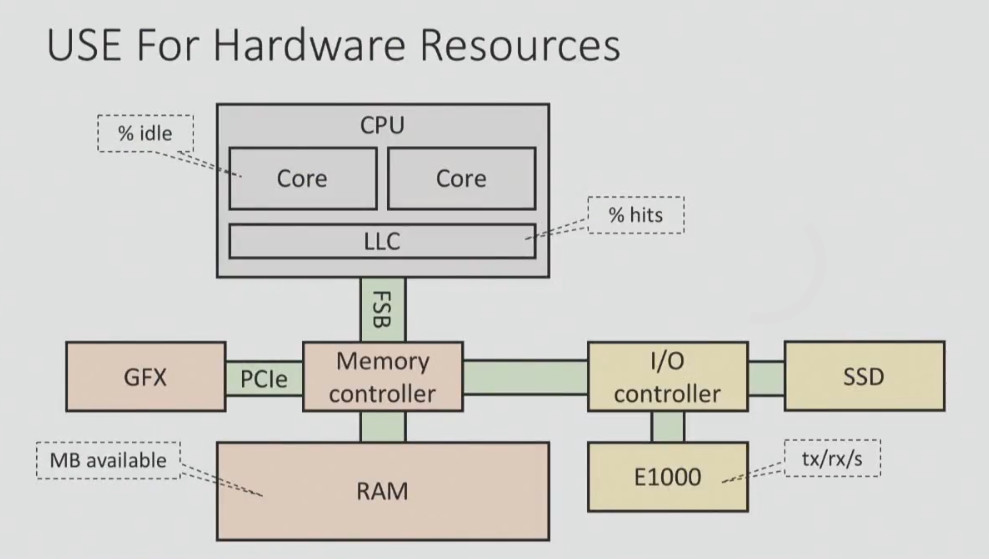
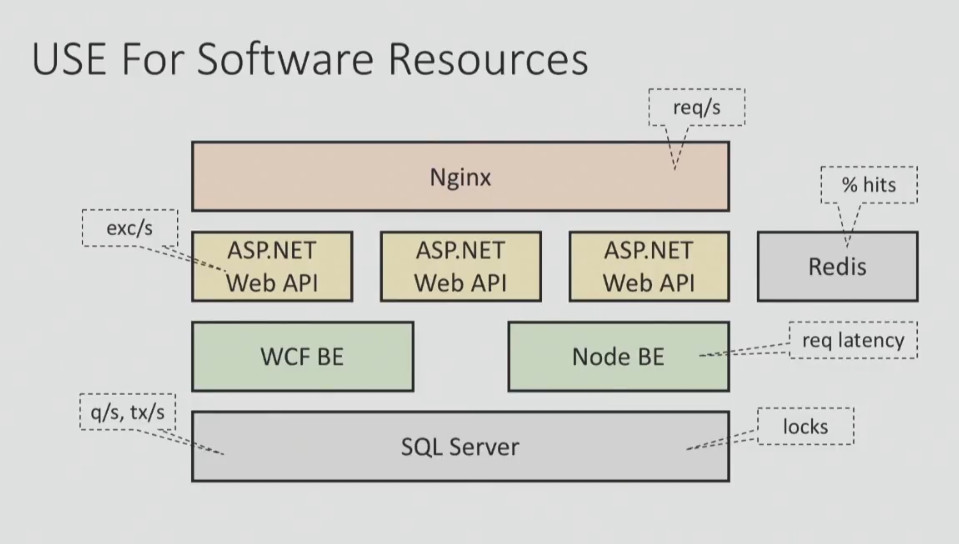
You should have a checklist according to which you systematically test each component to get the big picture.
Here's what the checklist for Windows systems looks like:
Most of this data can be obtained using the built-in Windows performance counters. This test can be done very quickly, but it saves a lot of time, then focus on analyzing the problems found.
A variety of solutions can be used to automate this process:
Performance analysis tools can be divided into three categories:
As a rule, the tools of the first category give a small overhead, when using tools to determine the waiting time, it is longer, and the funds of the third category lead to a significant overhead. And this is not surprising, because the latter provide much more information.
When choosing tools, it is important to pay attention to five points:
Any observation can affect the state of the system, but some tools are more powerful than others. Therefore, before using any tool, it is best to consult the documentation. As a rule, it indicates what can be expected from the use of the tool (for example, increasing the load on the processor by 5-10% under certain circumstances).

If the documentation for the tool that you are going to use does not say anything about the overhead, then you will have to test it yourself. This should be done on the test system, measuring how much performance drops.
Perhaps for those who do not work with Java, this will be news, but most of the Java CPU profilers used by the developers produce incorrect data (VisualVM, jstack, YourKit, JProfiler ...). They use GetAllStackTraces, a documented JVMTI API. It produces a sample of what each thread in the system does when you call the GetAllStackTraces function.
The advantage of its use is cross-platform, but there is a significant drawback. You get a thread sample only when all threads are in safe states. That is, if you request a stack trace, you get it not from the current moment, but from some point later, when the thread decides that it wants to transfer its stack trace. As a result, you get results that have nothing to do with the real situation.
In the screenshot below, you can see the data from a scientific report on the accuracy of Java profilers.
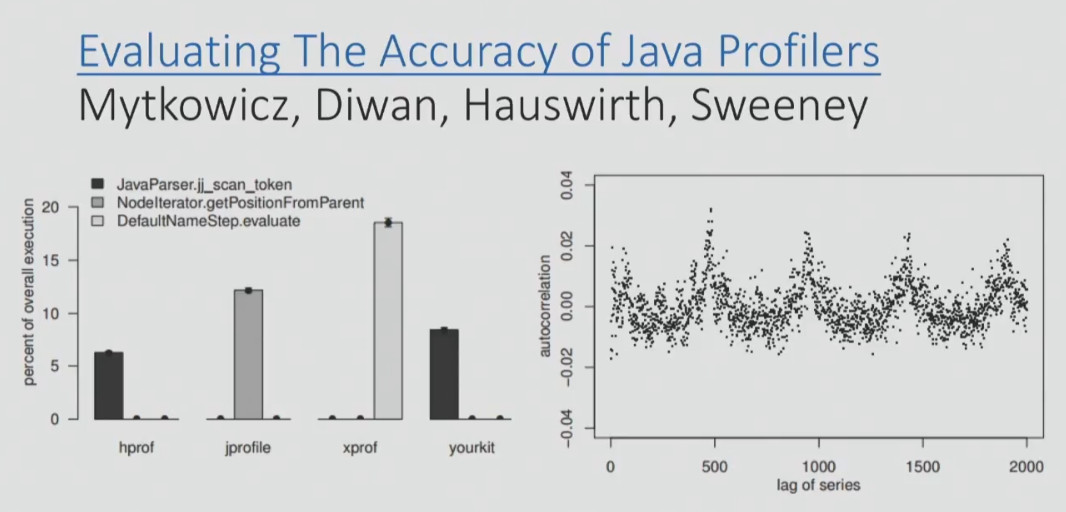
On the graph you can see the data of four profilers about which of the methods on a particular benchmark was the “hottest”. Two of the four profilers (left and right) determined that it was the jj_scan_token method, the third profiler determined that it was the getPositionFromParent method, and the fourth one DefaultNameStep.evaluate. That is, four profilers gave completely different readings and completely different methods. And here it is not the profilers, but the APIs that they use to get the results from the target process.
That is why if you are using a new tool, you must definitely test it under different conditions (when the processor is actively working, is at rest, or data is being read from the disk). And you need to make sure that the profiler provides the correct data, and then look at the overhead. If the data is incorrect, then this profiler, of course, should not be used.
Here I want to give an example of instructions for profiling .NET Core on Linux.
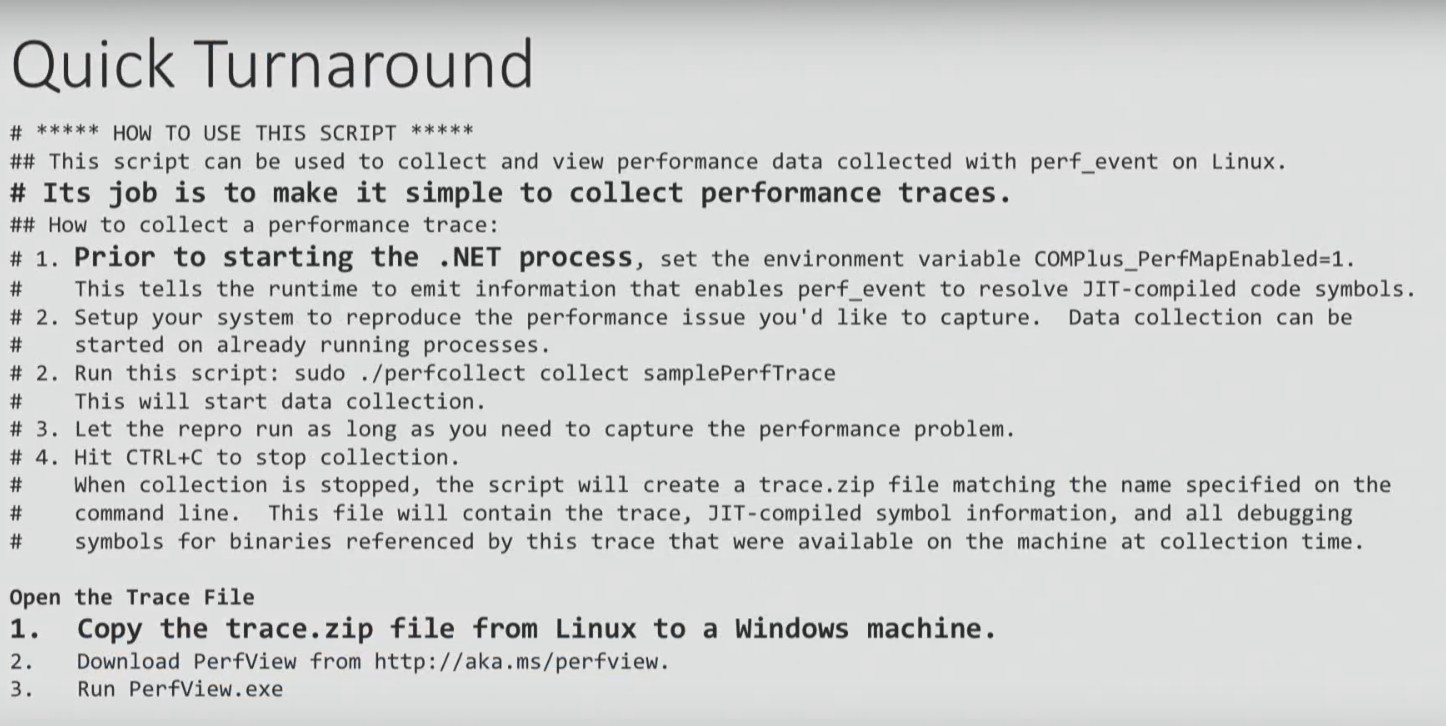
We will not consider it in detail, we will address only some points. It starts with the need to configure an environment variable, with which I, for example, have problems. Well, let's say you did it. The instruction ends with the need to take the ZIP file generated as a result of all these steps, copy it to the Windows machine and open it using PerfView. And only then can you analyze the data. Sounds ridiculous, doesn't it? Perform an analysis on Linux and then open it on Windows ...
Here is an alternative solution to the same problem. These scripts do not work too well, but they at least make it possible to get the result on Linux.
$ ./dotnet-mapgen.py generate 4118
$ ./dotnet-mapgen.py merge 4118
# perf record -p 4118 -F 97 -g
# perf script | ./stackcollapse-perf.pl> stacks
$ ./flamegraph.pl stacks> stacks.svg
As a result, you get a visualization called a flame graph. I will dwell on it in more detail, since many Windows and .NET developers are not familiar with it yet.
This method allows you to visualize different stack traces, for example, where the application often accesses the disk when the processor is heavily loaded, etc. When you have many different stacks, a flame graph is a good way to visualize them instead of reading a lot of text. A flame graph turns thousands of stack trace pages into one interactive graph.
Each rectangle in the chart is a function. Colors are randomly selected, so you can ignore them. The Y axis is the depth of the stack, that is, if one function called another, it will be located above it, and will be shown above in the graph. The X axis is sorted stacks (not time). Having such a schedule, it is very easy to zoom in exactly the area that interests you.
Invasive profilers can adversely affect system performance, reliability, and responsiveness because they are too heavy. For example, when using the Visual Studio profiler in instrumentation mode and IntelliTrace, the application is recompiled and launched with additional markers. Such a tool cannot be used in a production environment.
Another example is the CLR Profiling API, which is still used in some tools. It is based on the implementation of a DLL in the target process. Perhaps this is acceptable during development, but in a production environment, introducing a library into a running process can be problematic.
An extreme example on Linux is the Linux tracing frameworks SystemTap, LTTng, and SysDig, which require the installation of a custom kernel module in the system. Yes, you can trust these guys, but it's still a little suspicious that you need to load something new into the kernel to run the performance measurement tool.
Fortunately, Windows has a fairly lightweight Event Tracing (Windows) trace framework that you may have heard about. Using this framework, you can profile the processor, determine where the garbage collections are located, which files the application accesses, where it accesses the disk, etc.

But despite the fact that ETW is not too invasive, the speed of getting results from it can sometimes be a problem. Below I give an example from a log file generated using PerfView:

As you can see, I collected information on processor usage for 10 seconds, and a total of 15 MB of data was obtained. Therefore, it is unlikely that you can test the system using Event Tracing for hours - the amount of data will be too large. In addition, it took 12.7 seconds to complete the CLR Rundown, then it took some time to convert and open the data (I highlighted the time in red). That is, to get the data collected within 10 seconds, you need to spend half a minute to process and open it.
Despite the fact that this is considered a fairly good result, I do not really like it. Therefore, I’d better tell you about the tools that I wrote myself and without which I simply can’t live.
Etrace (https://github.com/goldshtn/etrace) is the open source command line interface for ETW. You can tell him what events you want to see, and he will give out information about them in real time. As soon as an event occurs, it can be seen on the command line. > etrace --help ... Examples: etrace --clr GC --event GC / AllocationTick etrace --kernel Process, Thread, FileIO, FileIOInit --event File / Create etrace --file trace.etl --stats etrace --clr GC --event GC / Start --field PID, TID, Reason [12], Type
etrace --kernel Process --event Process / start --where ImageFileName =
myapp etrace --clr GC --event GC / Start --duration 60
etrace --other Microsoft-Windows-Win32k --event QueuePostMessage
etrace --list CLR , Kernel
For example, you run etrace and say: I want GC events. As soon as such an event is fired, I want to see its type, reason, process, etc.

Another tool I wrote myself and want to introduce you is LiveStacks.. It is also related to ETW. LiveStacks collects stack traces for interesting events (where are the garbage collections, where is the load on the processor, what files does the application access, where does it access the disk, etc.). The main difference between LiveStacks and other similar tools is the output of information in real time. You do not need to wait until the data processing is completed to find out what processes are happening.
Here is an example of the default processor profiling mode. LiveStacks looks at the process in Visual Studio and shows the call stack in the process that takes the most CPU time.
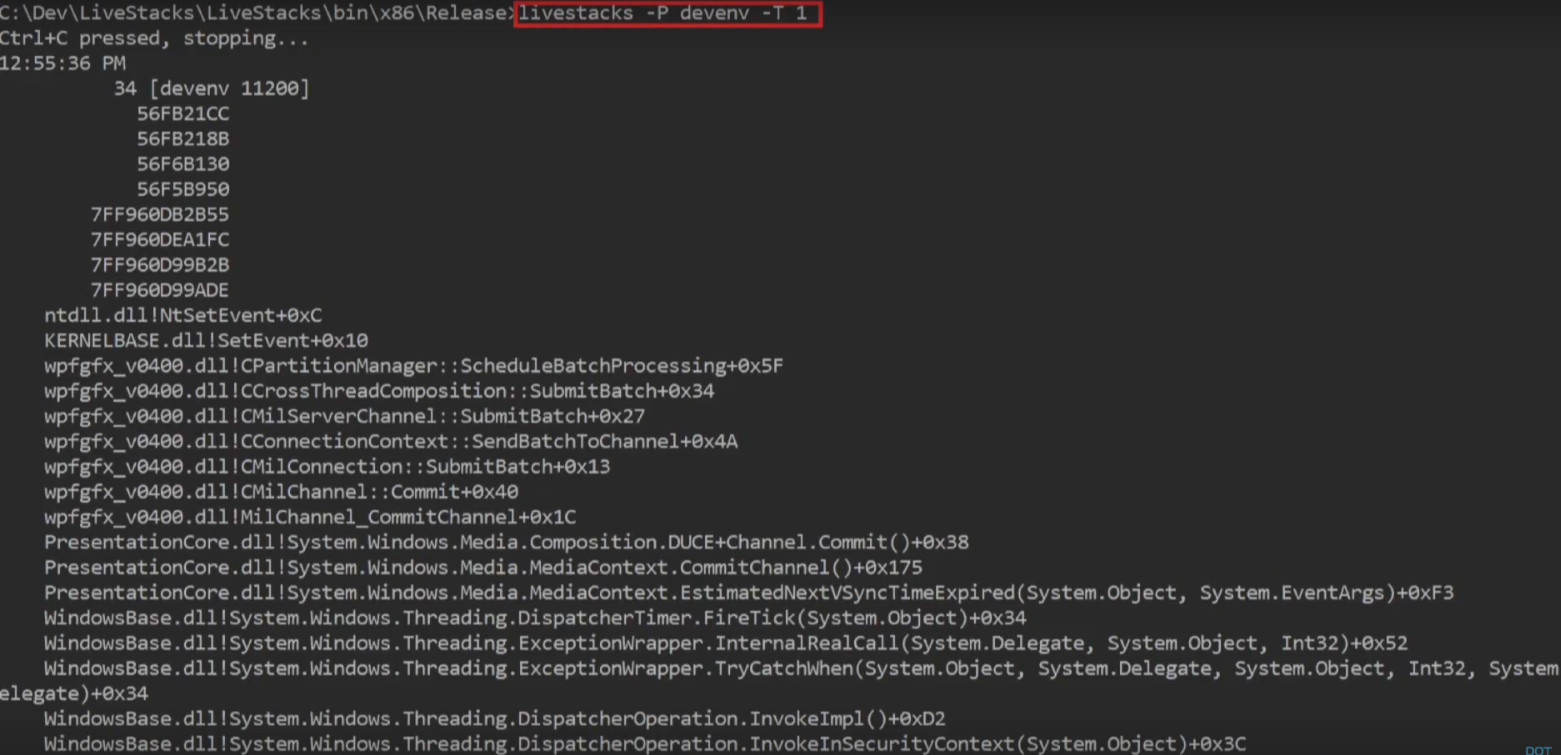
Another example: on the request “show me where the garbage collection starts, which call stack caused the garbage collection to start in a certain process or in the whole system »LiveStacks in real time gives a call stack with information about where the garbage collection takes place:

LiveStacks can generate flame graphs from the results by visualizing call stacks that were displayed in the console.
> LiveStacks -P JackCompiler -f> stacks.txt
ˆC
> perl flamegraph.pl stacks.txt> stacks.svg
I use these tools because they give me the opportunity to get results quickly, without waiting for data processing.
When you build a system, library, architecture for your new project, you should think about some things in advance that will simplify the performance analysis in the future:
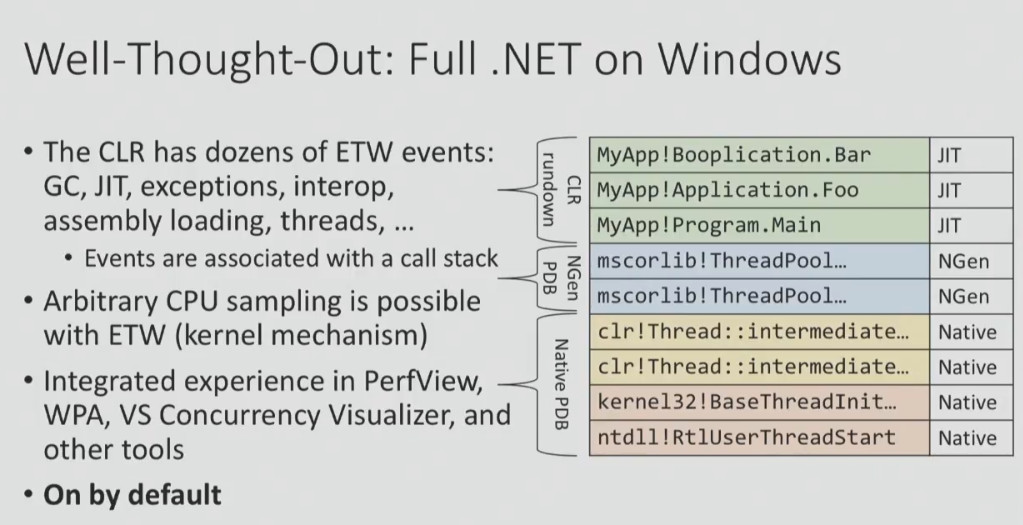
An example project with very good instrumentation tools is .NET on Windows, which has been used by many people for over 10 years. There are ETW events, which I spoke about above, there is an opportunity to capture call stacks of interesting events and convert them into function names. And all this is included by default!
To make a project with such instrumentation tools is not easy. Say, if you look at .NET Core 2.0 for Linux, everything is not so rosy here. And it’s not at all because Linux does not have good tools for analyzing performance, but because it’s rather difficult to build a platform that would be easy to profile and debug.
You want to know what is wrong with .NET Core 1.0 for Linux? The platform has events, but it is impossible to get call stacks, you can only find out that the event happened (which is much less informative). Another example: to convert call stacks to get function names, you need to do a lot of preliminary steps. That is why the documentation suggests taking a ZIP file and opening it on Windows (I gave this example above).
It's all about priorities. If you think that the ability to conduct a performance analysis is an important requirement for the system you are developing, you will not be releasing something like this. Although, of course, this is just my point of view.
Statistics and tools often deceive us. Here are some things to keep in mind in this regard:
For example, someone tells you that "the average response time of the system is 29 ms." What does this mean? For example, the fact that with an average response time of 29 ms, the worst value is 50 ms or 60 ms, and the best is close to zero. Or this may mean that for most cases the response time is 10 ms, but there is a mode in which the system works much slower (with a response time of up to 250 ms), and the average value is also 29 ms.
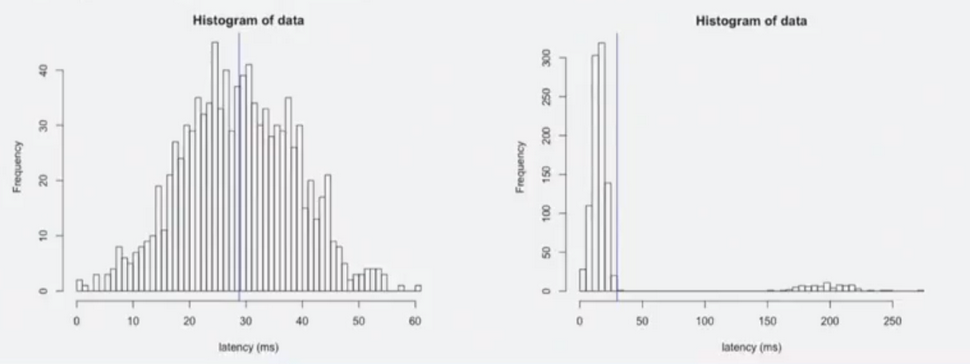
You see that the two graphs showing these two cases with the same average response time are completely different. In order to understand the real picture of what is happening, it is not enough to look at the numbers; you need to look at the real distribution.
Have a great studyI found on the web. It demonstrates why you can never trust only summary statistics and you always need to visualize the data.

The authors visualized 13 data sets with the same summary statistics (the same average x / y, one standard deviation x / y and the same cross-correlation). However, these datasets look completely different. That is, when you look only at numbers, it does not mean anything. You do not see the “form” of your data when you look only at numbers.
Benchmark dotnetIs a library that many of you use. It is simply gorgeous, but does not show the “shape” of your data (at least by default). When you run it in the console, it gives out a lot of numbers: average values, standard deviations, confidence intervals, quartiles, but not the "form" of the data. And this is very important. For some types of analysis, the inability to see the “form” of the data means that you will miss important things.
Here is an example of what you can skip by relying on averages. This graph shows the delay time. In 99% of cases, the response time is slightly less than 200 ms, but periodic stuttering can be observed - too long delays (even up to 10 ms) that occur during a short period of time.
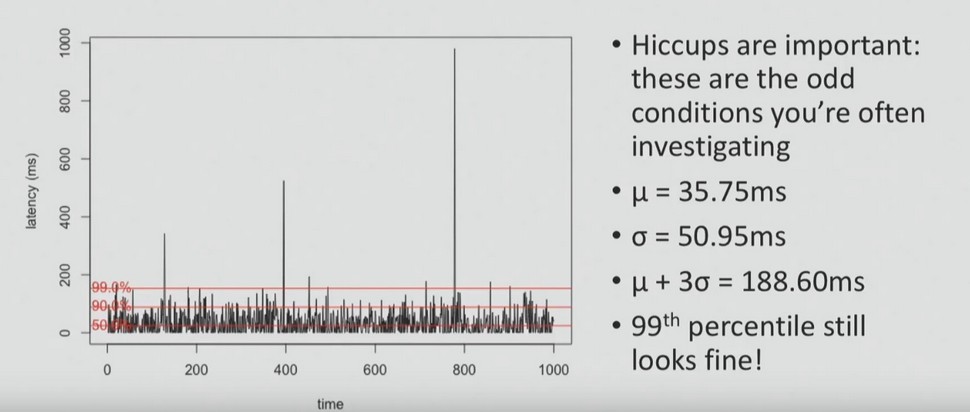
And in most cases, when performing a performance analysis, they are asked to pay attention to stuttering — that is higher than average, and problems that users sometimes encounter. In order to identify them, it is necessary to visualize all data points, as in the graph above, or to build the distribution, as in the graph below.
Another common mistake people make with percentiles is to make mathematical operations with them. For example, you cannot average percentiles, as my client did, whose letter you can read below.

Imagine you have two servers. For server A, the delay time is 90 ms for 90% of the time; for server B, the delay time is 22 ms for 90% of the time.
It is important to understand that you cannot average these values. It is not true that in 90% of requests, the answer comes in less than 57 ms. In fact, 90% of requests respond faster than in 68 ms.
Therefore, you can never average interest, quartiles, etc. You should always look at the data and its dissemination.
Sometimes you can hear something like: “Who cares about the 99th percentile? None of my users even see this! ” I’ll explain why this is important using the Amazon.com website page as an example. She made 328 requests. Assuming all queries are independent, what is the likelihood that at least one of them was in the 99th percentile?
P = 1 - 0.99 328 ~ 96%
The answer is 96%. Therefore, it is very likely that when you go to the Amazon.com page, you will receive at least one request in the 99th percentile. And if your users get access to a system that is relatively complex, then the likelihood that the worst-case scenario will happen to them is very high.
The last thing I would like to mention in the framework of this article is the need to use special tools for systems consisting of a large number of machines. Here's what such tools should be able to do:
There are a lot of such tools. One example of a tool for monitoring application performance is Vector by Netflix. You can see summary statistics on the information panel, but at the same time, you can click on a specific instance at any time and, say, view the processor flame graph for that instance or use disk resources.
Another example is the New Relic AMP solution , which also works with .NET. It shows you the requests in the system and where you spend time serving those requests. And if you want, you can switch to a specific request, to a specific user session.
After the performance analysis is complete, do not neglect the opportunity to sit down and document what has been done. What exactly is worth doing?
Sasha Goldstein is a .NET expert, a productivity guru and a constant speaker of our conferences. At the two-day DotNext, which will be held November 12-13 in Moscow, he will give a hardcore report Debugging and Profiling .NET Core Apps on Linux . And on the eve of the conference, he will conduct a separate training on Production Performance and Troubleshooting of .NET Applications.
Of the other reports, these three will probably also seem interesting to you:
You can view the entire conference program, virtually meet the speakers and purchase tickets on the event website .
Sasha talks about methods and tools for analyzing application performance, including those developed by himself.
The article is based on Sasha's speech at the DotNext 2017 Piter conference. Sasha works as the technical director of the Israeli training and consulting company Sela and knows firsthand how to conduct a performance analysis. How to start it better than finish, what tools should be used, and which ones to avoid, read under the cut.
Performance Analysis: Step-by-Step Plan
Let's start with the performance analysis framework. The following plan is used by developers, system administrators, any technical specialists:
- Getting a description of the problem. This sounds simpler than it actually is, because often customers describe the problems very poorly.
- Building a system diagram. This makes it possible to realize what parts the problem consists of.
- Quick performance check. This allows you to understand what is working in the system, what is overloaded, etc.
- Understanding which component is causing the problem. At this stage, we do not yet know what the problem is, but we already understand where it is, so that there is already progress.
- Detailed analysis. This stage requires the most time.
- Finding the root of the problem.
- Fix a problem.
- Verification At this stage, you need to check whether the problem is fixed and now the system is working correctly.
- Documenting the entire analysis process. This is necessary in order to know exactly what exactly you did, which tools worked for you and which didn’t. This makes it possible not to repeat the same mistakes in the future.
Description of the problem: why is it sometimes so difficult to obtain?
Getting an accurate description of the problem from the client is much more difficult than it seems at first glance.
A client may have a problem like:
“The application is too SLOW. Users cannot say exactly when this happens, but it’s bad. Can you see? ”
Or
“We have a budget for work to improve productivity, can you look at our work environment and find a problem for two days?”
Of course, you can try, but it is unlikely to be a very good use of the allocated budget. The problem formulated more accurately may look like this:
“Starting at 4:25 in the morning, when accessing the ASP.NET site in 95% of cases, a delay of 1400 ms is observed (the usual response time is 60 ms). The delay is observed regardless of geographical location and does not decrease. We turned on automatic scaling, but that didn't help. ”
Such a description of the problem is already much more accurate, because I see the symptoms and understand where to look, and I know what can be considered a solution to the problem (reducing the delay to 60 ms).
Sometimes it is much more difficult to find out what exactly is required for a client than it seems at first glance.
Each company has its own performance requirements, which, unfortunately, are not always formulated. For example, they can be like this:
- 90% of all full-text requests should be completed no later than 200 ms;
- 99% of all full-text requests should be completed no later than 600 ms;
- 100% of all full-text requests should complete no later than 2000 ms.
When such requirements exist, it remains only to test the system for compliance with them and understand how to solve the problem. But it’s important to understand that requirements do not come from nowhere; they must always be consistent with business goals. Having clearly defined requirements, you can always track statistics in the APM solution or in other ways and receive notifications when something goes wrong.
Antipatterns: How No Analysis Is Necessary
Before diving into the analysis methods that produce the result, I want to talk a bit about how the problem should not be analyzed. So you should definitely not:
- Make assumptions;
- Trusting “instincts” and absurd beliefs;
- Look for a solution to the problem only where it is easiest to find (this behavior is also called the “street lamp effect.” He was shown by a drunkard from a famous joke who looked for keys not where he lost them, but where it was light);
- Use random tools;
- Shifting responsibility to tools.
I will give an example of one unsuccessful analysis, which was never completed. My task was to understand why sometimes, when saving and loading documents in the project management system, clients encounter significant delays. The system was connected to NetApp via SMB on the local network, and my task was to find out the network latency and latencies that might occur when working with the data warehouse.
I had tools to track WCF and application server performance, I had a sniffer for network traffic, but I did not have access to the NetApp storage system. After a series of tests, I found out that the average response speed was 11 ms, however, some cases of a delay of 1200 ms were observed within 24 hours. I did not have enough information about what was happening on the part of NetApp, and it was necessary to get performance testing data.
From the client I was able to get only information that the response speed of the storage system can in no way be less than 5 ms. To my question about what this figure is: average or peak delay, I got the answer: this is the maximum average value for 60 seconds.I still don’t know what this value is, and I believe that you are not in the know either. He could take the average value every second and then take the maximum value from all means or maybe take the maximum value every second and then take the average from maximum ...
After that I found performance counters in the documentation for NetApp that are considered valid for this storage system . This is the average data per second, not per minute. I asked the client to provide me with this data, but was refused. This attempt to conduct the analysis ended.
For me, this is a classic case of how performance analysis cannot be done. I tried my best to get as much information as possible and not rely on assumptionsHowever, I did not succeed due to the lack of mutual understanding with the client. And this is a good example of why one cannot rely on assumptions and absurd beliefs.
Now about the unsuccessful use of tools.
Sometimes experts think that if they bought an expensive tool, then they simply must use it for all analysis options. I will give a classic example of using the wrong tool for analysis.
Run Visual Studio profiling tools in CPU fetch mode to test the performance of the search robot. The robot can do some things that do not load the processor, and if we conduct such a test, we can get something like this:
It follows that it is necessary to improve the performance of System.Console.WriteLine, since this method slows down the application. However, the search robot can simply wait for the arrival of network data, this is not connected with the processor. Therefore, you can never choose a tool for analysis on the principle of "simply because we bought it, and we need to recapture its value."
Finding the Problem Source: USE Method
Sometimes you just don’t know what to look for, in which case I propose a methodology that is often used by engineers around the world. This is the USE (Utilization, Saturation, Errors) method, which works in several stages:
- At the first, it is necessary to build a diagram of the system, including all hardware and software resources and the connections between them;
- Then, for each resource and each connection, you need to determine three parameters: Utilization - use (how busy the resource is), Saturation - saturation (is there a queue for using this resource) and Errors - if errors occur.
- If problems are associated with a parameter, they must be resolved.
Here's what the USE method might look like for hardware and software resources:
You should have a checklist according to which you systematically test each component to get the big picture.
Here's what the checklist for Windows systems looks like:
| Analysis Tools or Tracked Parameters | ||
| Processor (_Total) \% ProcessorTime,% User Time Process (My App) \% ProcessorTime | ||
| System \ Processor Queue Length | ||
| Intel Processor Diagnostic Tool (and others) | ||
| Memory \ Available Mbytes Process \ Virtual Size, Private Bytes, Working Set .NET CLR Memory \ #Bytes in all Heaps VMMap, RAMMap | ||
| Memory \ Pages / sec | ||
| Windows Memory Diagnostic Utility (and others) | ||
| Network Interface \ Bytes Received / sec, Bytes Sent / sec | ||
| Network Interface \ Output Queue Length, Packets Outbound Discarded, Packets Received Discarded | ||
| Network Interface \ Packets Outbound Errors, Packets Received Errors | ||
| Physical Disc \% Disc Time,% Idle Time, Disc Reds / sec, Disk Writes / sec | ||
| Physical Disc \ Current Disk Queue Length | ||
| Chkdisk (and other tools) | ||
| .NET CLR Exceptions \ # of Excepts Thrown / sec ASP.Net \ Error Events Raised |
Most of this data can be obtained using the built-in Windows performance counters. This test can be done very quickly, but it saves a lot of time, then focus on analyzing the problems found.
A variety of solutions can be used to automate this process:
- Windows System Monitor (Perfmon) - can collect logs of performance counters constantly or only when certain conditions are met.
- Typeperf - can generate a CSV file every second with the values of performance counters that are specified by the user.
- Third Party Solutions. For example, if you are working with a cloud solution, then the provider most likely should provide access to the tool to monitor the activity of the processor, disk, network activity, etc.
Performance Analysis: Which Tools to Use
Performance analysis tools can be divided into three categories:
- Those that help determine how often this happens (counting). For example, how many requests per second we get
- Those that help determine how long it takes (wait time). For example, how long do my ASP.NET requests take, how much time does it take to switch between windows, etc.
- Those that help determine why this is happening (stacks). For example, where a certain condition occurs in the application source code
As a rule, the tools of the first category give a small overhead, when using tools to determine the waiting time, it is longer, and the funds of the third category lead to a significant overhead. And this is not surprising, because the latter provide much more information.
When choosing tools, it is important to pay attention to five points:
- Small overhead
- Accuracy (how much can you trust the results)
- Quick results (when you don’t have to wait for hours to analyze the data)
- Invasiveness (Ability to run on running systems)
- Ability to focus on a specific area (class, function, etc.)
Remember the overhead!
Any observation can affect the state of the system, but some tools are more powerful than others. Therefore, before using any tool, it is best to consult the documentation. As a rule, it indicates what can be expected from the use of the tool (for example, increasing the load on the processor by 5-10% under certain circumstances).
If the documentation for the tool that you are going to use does not say anything about the overhead, then you will have to test it yourself. This should be done on the test system, measuring how much performance drops.
Accuracy: a story with safe conditions
Perhaps for those who do not work with Java, this will be news, but most of the Java CPU profilers used by the developers produce incorrect data (VisualVM, jstack, YourKit, JProfiler ...). They use GetAllStackTraces, a documented JVMTI API. It produces a sample of what each thread in the system does when you call the GetAllStackTraces function.
The advantage of its use is cross-platform, but there is a significant drawback. You get a thread sample only when all threads are in safe states. That is, if you request a stack trace, you get it not from the current moment, but from some point later, when the thread decides that it wants to transfer its stack trace. As a result, you get results that have nothing to do with the real situation.
In the screenshot below, you can see the data from a scientific report on the accuracy of Java profilers.
On the graph you can see the data of four profilers about which of the methods on a particular benchmark was the “hottest”. Two of the four profilers (left and right) determined that it was the jj_scan_token method, the third profiler determined that it was the getPositionFromParent method, and the fourth one DefaultNameStep.evaluate. That is, four profilers gave completely different readings and completely different methods. And here it is not the profilers, but the APIs that they use to get the results from the target process.
That is why if you are using a new tool, you must definitely test it under different conditions (when the processor is actively working, is at rest, or data is being read from the disk). And you need to make sure that the profiler provides the correct data, and then look at the overhead. If the data is incorrect, then this profiler, of course, should not be used.
Results: how fast do you get them?
Here I want to give an example of instructions for profiling .NET Core on Linux.
We will not consider it in detail, we will address only some points. It starts with the need to configure an environment variable, with which I, for example, have problems. Well, let's say you did it. The instruction ends with the need to take the ZIP file generated as a result of all these steps, copy it to the Windows machine and open it using PerfView. And only then can you analyze the data. Sounds ridiculous, doesn't it? Perform an analysis on Linux and then open it on Windows ...
Here is an alternative solution to the same problem. These scripts do not work too well, but they at least make it possible to get the result on Linux.
$ ./dotnet-mapgen.py generate 4118
$ ./dotnet-mapgen.py merge 4118
# perf record -p 4118 -F 97 -g
# perf script | ./stackcollapse-perf.pl> stacks
$ ./flamegraph.pl stacks> stacks.svg
As a result, you get a visualization called a flame graph. I will dwell on it in more detail, since many Windows and .NET developers are not familiar with it yet.
This method allows you to visualize different stack traces, for example, where the application often accesses the disk when the processor is heavily loaded, etc. When you have many different stacks, a flame graph is a good way to visualize them instead of reading a lot of text. A flame graph turns thousands of stack trace pages into one interactive graph.
Each rectangle in the chart is a function. Colors are randomly selected, so you can ignore them. The Y axis is the depth of the stack, that is, if one function called another, it will be located above it, and will be shown above in the graph. The X axis is sorted stacks (not time). Having such a schedule, it is very easy to zoom in exactly the area that interests you.
Invasiveness: how not to harm
Invasive profilers can adversely affect system performance, reliability, and responsiveness because they are too heavy. For example, when using the Visual Studio profiler in instrumentation mode and IntelliTrace, the application is recompiled and launched with additional markers. Such a tool cannot be used in a production environment.
Another example is the CLR Profiling API, which is still used in some tools. It is based on the implementation of a DLL in the target process. Perhaps this is acceptable during development, but in a production environment, introducing a library into a running process can be problematic.
An extreme example on Linux is the Linux tracing frameworks SystemTap, LTTng, and SysDig, which require the installation of a custom kernel module in the system. Yes, you can trust these guys, but it's still a little suspicious that you need to load something new into the kernel to run the performance measurement tool.
Fortunately, Windows has a fairly lightweight Event Tracing (Windows) trace framework that you may have heard about. Using this framework, you can profile the processor, determine where the garbage collections are located, which files the application accesses, where it accesses the disk, etc.
But despite the fact that ETW is not too invasive, the speed of getting results from it can sometimes be a problem. Below I give an example from a log file generated using PerfView:
As you can see, I collected information on processor usage for 10 seconds, and a total of 15 MB of data was obtained. Therefore, it is unlikely that you can test the system using Event Tracing for hours - the amount of data will be too large. In addition, it took 12.7 seconds to complete the CLR Rundown, then it took some time to convert and open the data (I highlighted the time in red). That is, to get the data collected within 10 seconds, you need to spend half a minute to process and open it.
Despite the fact that this is considered a fairly good result, I do not really like it. Therefore, I’d better tell you about the tools that I wrote myself and without which I simply can’t live.
Etrace (https://github.com/goldshtn/etrace) is the open source command line interface for ETW. You can tell him what events you want to see, and he will give out information about them in real time. As soon as an event occurs, it can be seen on the command line. > etrace --help ... Examples: etrace --clr GC --event GC / AllocationTick etrace --kernel Process, Thread, FileIO, FileIOInit --event File / Create etrace --file trace.etl --stats etrace --clr GC --event GC / Start --field PID, TID, Reason [12], Type
etrace --kernel Process --event Process / start --where ImageFileName =
myapp etrace --clr GC --event GC / Start --duration 60
etrace --other Microsoft-Windows-Win32k --event QueuePostMessage
etrace --list CLR , Kernel
For example, you run etrace and say: I want GC events. As soon as such an event is fired, I want to see its type, reason, process, etc.
Another tool I wrote myself and want to introduce you is LiveStacks.. It is also related to ETW. LiveStacks collects stack traces for interesting events (where are the garbage collections, where is the load on the processor, what files does the application access, where does it access the disk, etc.). The main difference between LiveStacks and other similar tools is the output of information in real time. You do not need to wait until the data processing is completed to find out what processes are happening.
Here is an example of the default processor profiling mode. LiveStacks looks at the process in Visual Studio and shows the call stack in the process that takes the most CPU time.
Another example: on the request “show me where the garbage collection starts, which call stack caused the garbage collection to start in a certain process or in the whole system »LiveStacks in real time gives a call stack with information about where the garbage collection takes place:
LiveStacks can generate flame graphs from the results by visualizing call stacks that were displayed in the console.
> LiveStacks -P JackCompiler -f> stacks.txt
ˆC
> perl flamegraph.pl stacks.txt> stacks.svg
I use these tools because they give me the opportunity to get results quickly, without waiting for data processing.
How to build systems for effective instrumentation
When you build a system, library, architecture for your new project, you should think about some things in advance that will simplify the performance analysis in the future:
- Make sure that the call stack for interesting events (disk access, garbage collection, etc.) is easy to get;
- Implement static code instrumentation (tracepoints) so that people can get real-time information about processes;
- Make sure that important processes can be enabled without an overhead, without the need to restart the system, but simply by configuring at the log level;
- Add debug points (probes) for dynamic instrumentation;
- Compose examples and a documentation file so that people performing performance analysis do not need to spend too much time understanding how your system works.
An example project with very good instrumentation tools is .NET on Windows, which has been used by many people for over 10 years. There are ETW events, which I spoke about above, there is an opportunity to capture call stacks of interesting events and convert them into function names. And all this is included by default!
To make a project with such instrumentation tools is not easy. Say, if you look at .NET Core 2.0 for Linux, everything is not so rosy here. And it’s not at all because Linux does not have good tools for analyzing performance, but because it’s rather difficult to build a platform that would be easy to profile and debug.
You want to know what is wrong with .NET Core 1.0 for Linux? The platform has events, but it is impossible to get call stacks, you can only find out that the event happened (which is much less informative). Another example: to convert call stacks to get function names, you need to do a lot of preliminary steps. That is why the documentation suggests taking a ZIP file and opening it on Windows (I gave this example above).
It's all about priorities. If you think that the ability to conduct a performance analysis is an important requirement for the system you are developing, you will not be releasing something like this. Although, of course, this is just my point of view.
Be careful with the statistics!
Statistics and tools often deceive us. Here are some things to keep in mind in this regard:
- Усредненные значения бессмысленны.
- Медианы бессмысленны.
- Перцентили и распределения полезны только в том случае, если вы точно знаете, что делаете.
- Используйте хорошую визуализацию для своих данных.
- Остерегайтесь феномена coordinated omission.
For example, someone tells you that "the average response time of the system is 29 ms." What does this mean? For example, the fact that with an average response time of 29 ms, the worst value is 50 ms or 60 ms, and the best is close to zero. Or this may mean that for most cases the response time is 10 ms, but there is a mode in which the system works much slower (with a response time of up to 250 ms), and the average value is also 29 ms.
You see that the two graphs showing these two cases with the same average response time are completely different. In order to understand the real picture of what is happening, it is not enough to look at the numbers; you need to look at the real distribution.
Have a great studyI found on the web. It demonstrates why you can never trust only summary statistics and you always need to visualize the data.
The authors visualized 13 data sets with the same summary statistics (the same average x / y, one standard deviation x / y and the same cross-correlation). However, these datasets look completely different. That is, when you look only at numbers, it does not mean anything. You do not see the “form” of your data when you look only at numbers.
Benchmark dotnetIs a library that many of you use. It is simply gorgeous, but does not show the “shape” of your data (at least by default). When you run it in the console, it gives out a lot of numbers: average values, standard deviations, confidence intervals, quartiles, but not the "form" of the data. And this is very important. For some types of analysis, the inability to see the “form” of the data means that you will miss important things.
Here is an example of what you can skip by relying on averages. This graph shows the delay time. In 99% of cases, the response time is slightly less than 200 ms, but periodic stuttering can be observed - too long delays (even up to 10 ms) that occur during a short period of time.
And in most cases, when performing a performance analysis, they are asked to pay attention to stuttering — that is higher than average, and problems that users sometimes encounter. In order to identify them, it is necessary to visualize all data points, as in the graph above, or to build the distribution, as in the graph below.
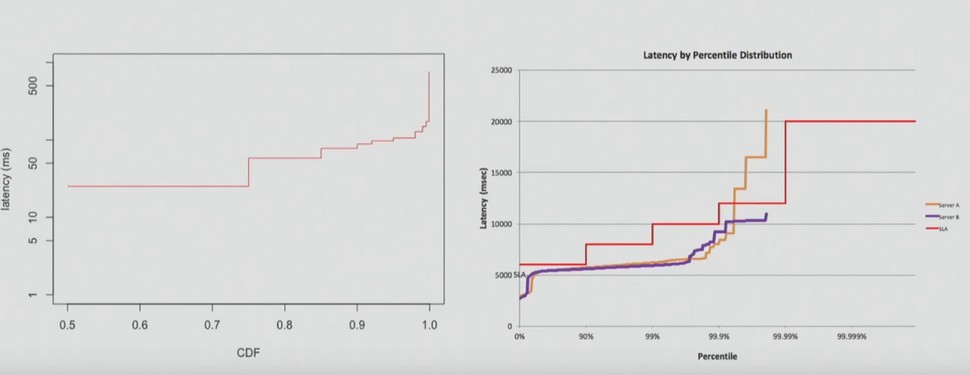
Another common mistake people make with percentiles is to make mathematical operations with them. For example, you cannot average percentiles, as my client did, whose letter you can read below.
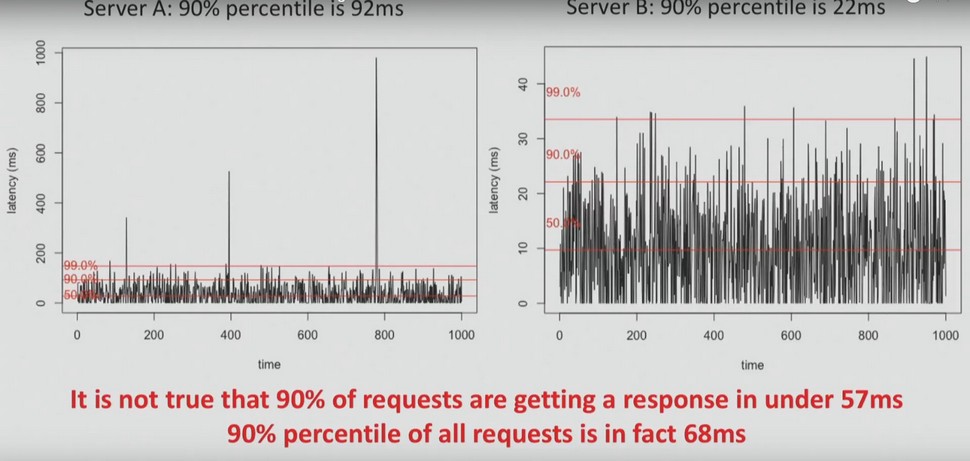
Imagine you have two servers. For server A, the delay time is 90 ms for 90% of the time; for server B, the delay time is 22 ms for 90% of the time.
It is important to understand that you cannot average these values. It is not true that in 90% of requests, the answer comes in less than 57 ms. In fact, 90% of requests respond faster than in 68 ms.
Therefore, you can never average interest, quartiles, etc. You should always look at the data and its dissemination.
Sometimes you can hear something like: “Who cares about the 99th percentile? None of my users even see this! ” I’ll explain why this is important using the Amazon.com website page as an example. She made 328 requests. Assuming all queries are independent, what is the likelihood that at least one of them was in the 99th percentile?
P = 1 - 0.99 328 ~ 96%
The answer is 96%. Therefore, it is very likely that when you go to the Amazon.com page, you will receive at least one request in the 99th percentile. And if your users get access to a system that is relatively complex, then the likelihood that the worst-case scenario will happen to them is very high.
Use serious tools for large systems!
The last thing I would like to mention in the framework of this article is the need to use special tools for systems consisting of a large number of machines. Here's what such tools should be able to do:
- Collect performance data from a large number of machines;
- Associate user actions with a session or transaction ID;
- Visualize data in the information panel;
- Give the ability to focus on a specific user, request, computer with one click.
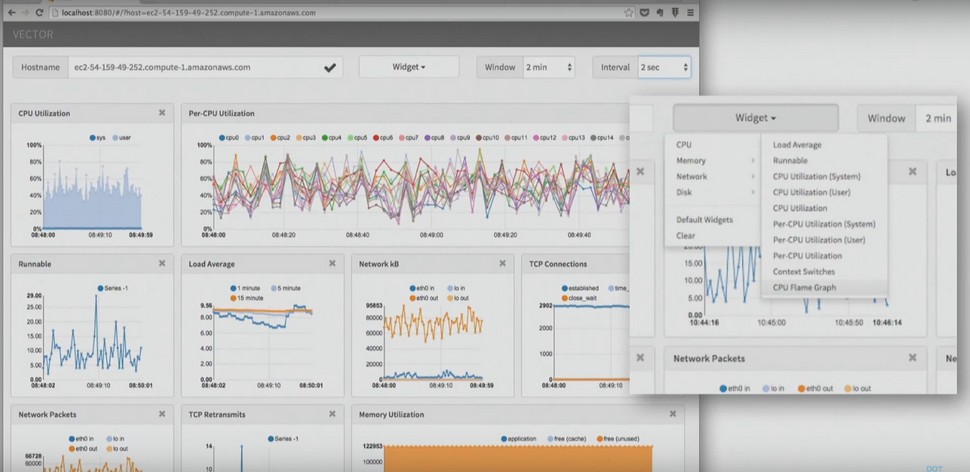
There are a lot of such tools. One example of a tool for monitoring application performance is Vector by Netflix. You can see summary statistics on the information panel, but at the same time, you can click on a specific instance at any time and, say, view the processor flame graph for that instance or use disk resources.
Another example is the New Relic AMP solution , which also works with .NET. It shows you the requests in the system and where you spend time serving those requests. And if you want, you can switch to a specific request, to a specific user session.
When the work is completed: do not forget to document!
After the performance analysis is complete, do not neglect the opportunity to sit down and document what has been done. What exactly is worth doing?
- Document the steps that were taken to find, diagnose, solve, and verify the problem.
- What tools did you use? How can they be improved? What didn’t work?
- What prevented you from doing research?
- Can you add monitoring tools for system administrators?
- Can you add tools for those who will analyze the system after you?
- If this problem arises again, how can it be automated?
- Documenting the process will help you and the whole team avoid the same mistakes in the future, and possibly automate repetitive tasks.
Sasha Goldstein is a .NET expert, a productivity guru and a constant speaker of our conferences. At the two-day DotNext, which will be held November 12-13 in Moscow, he will give a hardcore report Debugging and Profiling .NET Core Apps on Linux . And on the eve of the conference, he will conduct a separate training on Production Performance and Troubleshooting of .NET Applications.
Of the other reports, these three will probably also seem interesting to you:
- another hardcore about performance from Karel Zikmund of Microsoft ( High performance Networking in .NET Core )
- typical problems of performance testing and possible approaches to their solution in a speech by Andrei Akinshin from JetBrains ( Let's talk about performance testing)
- serious talk about high-performance code in a presentation by Federico Lois from Corvalius ( Patterns for high-performance C #: from algorithm optimization to low-level techniques)
You can view the entire conference program, virtually meet the speakers and purchase tickets on the event website .