We work with long APIs in ASP.NET Core correctly or the subtleties of moving to a new platform
Microsoft worked hard to create a new platform for web development. The new ASP.NET Core is similar to the old ASP.NET MVC only, perhaps, by the MVC architecture itself. Difficulties and familiar things from the old platform have gone, the built-in DI and lightweight view components have appeared, HTTP modules and handlers have given way to middleware, etc. Together with cross-platform and good performance, all this makes the platform very attractive for choice. In this article I will tell you how I managed to solve the specific problem of logging long-term requests to third-party APIs to increase the convenience of incident analysis.
In diplomas and dissertations, somewhere in the beginning, the problem should usually be formulated. But what I will describe below is probably not even a problem, but the desire to make the application more usable and the world around us is a bit more beautiful. This is one of those moments in my life where I ask myself, can I do better? And after that I’m trying to find ways to do this. Sometimes I do it, sometimes I understand that it’s either impossible to do better, or it’s worth the effort so much that it ultimately makes no sense. In the end, itwill not change the world and solve the problem of poverty on the planet.not worth the waste of your time and energy. But anyway, I get from this some experience that cannot but come in handy in the future. In this article I will describe what I think I managed to do better.
To begin with, the company where I work is engaged in the development of highly loaded sites. The applications that I have managed to work on at the moment, for the most part, are a kind of authorization-based interface for accessing the customer’s internal API. There is not much logic there and it is distributed in approximately equal proportions between the frontend and backend. Most of the key business logic lies in these APIs, and the sites that are visible to the end customer are their consumiers.
Sometimes it turns out that third-party APIs in relation to the site respond to user requests for a very long time. Sometimes this is a temporary effect, sometimes permanent. Since the applications are highly loaded by nature, it is impossible to allow user requests to remain in a suspended state for a long time, otherwise it may threaten us with an ever-increasing number of open sockets, a rapidly replenishing queue of unresponsive requests on the server, and also a large number of clients who are worried and worried why their favorite site has been opening for so long. We can’t do anything with the API. And in this regard, from a very long time ago, a balancer introduced a restriction on the duration of the request, equal to 5 seconds. This primarily imposes limitations on the application architecture, since it implies even more asynchronous interaction, as a result of which it solves the problem described above. The site itself opens quickly, and already on the open page, loading indicators spin, which in the end will give some result to the user. It will be what the user expects to see, or the error no longer plays a big role, and this will be a completely different story ...
An attentive reader will notice: but if the restriction is on all requests, then it applies to AJAX requests too. All is correct. I don’t know at all a way to distinguish an AJAX request from a normal page transition that works 100% in all cases. Therefore, long AJAX requests are implemented according to the following principle: we make a request to the server from the client, the server creates a Task and associates a specific GUID with it, then returns this GUID to the client, and the client receives the result for this GUID when it arrives at the server from the API. At this stage, we almost got to the bottom of myfar-fetched problem problem.
We should log and store all requests and answers to these APIs for debriefing, and from the logs we should get the maximum of useful information: called action / controller, IP, URI, user login, etc. etc. When I for the first time using NLog secured my request / response in my ASP.NET Core application, in principle, I was not surprised to see something like this in ElasticSearch:
At the same time, everything looked quite correctly in the NLog configuration and the following was set as layout:
The problem here is that the response from the API comes after the client completes the request (it returns only a GUID to it). And then I started thinking about possible solutions to this problem ...
Of course, any problem can be fixed in several ways. And to score on it is also one of the tricks that sometimes should not be neglected. But let’s talk about real solutions and their consequences.
This is probably the first thing that can only come to mind. We generate a GUID, log this GUID before exiting the action, and pass it to the API service.
The problems with this approach are obvious. We must pass this ID to absolutely all methods of accessing third-party APIs. At the same time, if we want to reuse this piece somewhere else, where such functionality is not required, then this will greatly interfere with us.
The situation is aggravated if we want to process, simplify or aggregate them in some way before giving the data to the client. This applies to business logic and should be taken out in a separate piece. It turns out that this piece, which should remain as independent as possible, will also work with this identifier! So things are not done, so consider other ways.
If we think about what tools the framework provides for these purposes, then the first thing we will remember is CallContext with its LogicalSetData / LogicalGetData. Using these methods, you can save the task ID in CallContext'e, and .NET (better to say, .NET 4.5) will make sure that new threads automatically get access to the same data. Inside the framework, this is implemented using a pattern somewhat reminiscent of Memento, which all methods for starting a new thread / task should use:
Now that we know how to save the ID, and then get it in our task, we can include this identifier in each of our logged messages. You can do this directly by calling the logging method. Or, in order not to clog the data access layer, you can use the capabilities of your logger. NLog, for example, has Layout Renderers .
Also, as a last resort, you can write your own logger. In ASP.NET Core, all logging is done using special interfaces located in the Microsoft.Extensions.Logging namespace, which are embedded in the class through DI. Therefore, it is enough for us to implement two interfaces: ILogger and ILoggerProvider. I think this option may be useful if your logger does not support extensions.
And so that everything works out as it should, I recommend that you read Stephen Cleary's article . There is no binding to .NET Core in it (in 2013 it simply did not exist yet), but something useful for yourself can definitely be emphasized there.
The disadvantage of this approach is that messages with an identifier will be logged and in order to get the full picture, you will need to look for an HTTP request with the same ID. I will not say anything about performance, because even if there is some sort of drawdown, compared to other things, this will seem to be a disproportionately small value.
As I already said, messages like:
Ie. everything related to IHttpContext is simply nullified. It seems to be understandable: the query execution has ended, so NLog cannot receive data, i.e. there is no longer a link to the HttpContext.
Finally, I decided to see how NLog actually gets a link to the HttpContext outside the controller. Since the SynchronizationContext and HttpContext.Current in .NET Core were over (yes, this is Stephen Cleary again), there must be some other way to do this.

Digging into the source of NLog, I found a certain IHttpContextAccessor. The thirst to understand what is happening here all the same made me climb into GitHub again and see what this magic thing with one property is all about. It turned out that this is just an abstraction over AsyncLocal , which is essentially a new version of LogicalCallContext (the very methods of LogicalSetData / LogicalGetData). By the way, this was not always the case for the .NET Framework .
After that, I asked myself the question: why then, actually, does this not work? We start Task in the standard way, there is no unmanaged code here ... Running the debugger to see what happens with the HttpContext at the time the logging method was called, I saw that the HttpContext is there, but the properties in it are all reset except Request.Scheme, which at the moment The call is "http". So it turns out that in the log I have a strange "
So, it turns out that in order to improve performance, ASP.NET Core somewhere inside itself resets HttpContexts and reuses them. Apparently, such subtleties coupled and allow you to achieve significant advantages over the old ASP.NET MVC.
What could I do about it? Yes, just keep the current state of the HttpContext! I wrote a simple service with the only CloneCurrentContext method that I registered in a DI container.
I did not use deep cloner, as this would add heavy reflection to the project. And I need this in just one single place. Therefore, I simply create a new HttpContext based on the existing one and copy into it only what will be useful to see in the log when analyzing incidents (action | controller, url, ip, etc.). Not all information is copied .
Now starting the application, I saw about the following happy lines:
And this meant for me a small victory, which I am sharing here with you. Who is thinking about this?
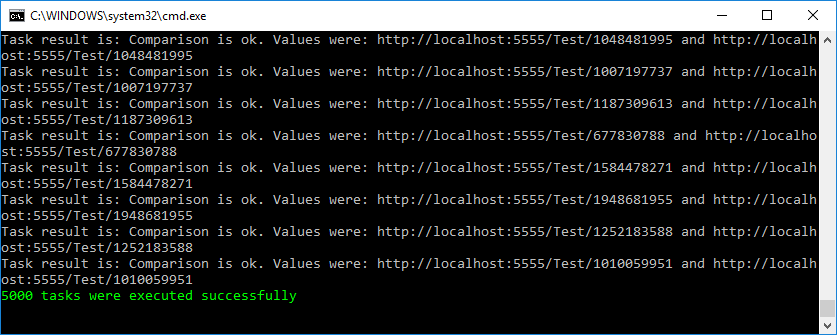
To make sure that I didn’t think up anything false, I wrote a small functional load test, which can be found in my github repository along with the service. When starting 5000 simultaneous tasks, the test was successful.
By the way, thanks to the architecture of ASP.NET Core, such tests can be written easily and naturally. You just need to run a full server inside the test and access it through a real socket:
Another reason to use ASP.NET Core in your projects.
I really liked ASP.NET Core in all aspects of its implementation. It has great flexibility and at the same time lightness of the entire platform. Due to abstractions for absolutely all functionality, you can do any things and customize the entire platform for yourself, your team and your development methods. Cross-platform is not yet perfected, but Microsoft is striving for this, and someday (though maybe not soon) they should succeed.
Github link
Instead of joining ...
In diplomas and dissertations, somewhere in the beginning, the problem should usually be formulated. But what I will describe below is probably not even a problem, but the desire to make the application more usable and the world around us is a bit more beautiful. This is one of those moments in my life where I ask myself, can I do better? And after that I’m trying to find ways to do this. Sometimes I do it, sometimes I understand that it’s either impossible to do better, or it’s worth the effort so much that it ultimately makes no sense. In the end, it
Task statement
To begin with, the company where I work is engaged in the development of highly loaded sites. The applications that I have managed to work on at the moment, for the most part, are a kind of authorization-based interface for accessing the customer’s internal API. There is not much logic there and it is distributed in approximately equal proportions between the frontend and backend. Most of the key business logic lies in these APIs, and the sites that are visible to the end customer are their consumiers.
Sometimes it turns out that third-party APIs in relation to the site respond to user requests for a very long time. Sometimes this is a temporary effect, sometimes permanent. Since the applications are highly loaded by nature, it is impossible to allow user requests to remain in a suspended state for a long time, otherwise it may threaten us with an ever-increasing number of open sockets, a rapidly replenishing queue of unresponsive requests on the server, and also a large number of clients who are worried and worried why their favorite site has been opening for so long. We can’t do anything with the API. And in this regard, from a very long time ago, a balancer introduced a restriction on the duration of the request, equal to 5 seconds. This primarily imposes limitations on the application architecture, since it implies even more asynchronous interaction, as a result of which it solves the problem described above. The site itself opens quickly, and already on the open page, loading indicators spin, which in the end will give some result to the user. It will be what the user expects to see, or the error no longer plays a big role, and this will be a completely different story ...
A completely different story
An attentive reader will notice: but if the restriction is on all requests, then it applies to AJAX requests too. All is correct. I don’t know at all a way to distinguish an AJAX request from a normal page transition that works 100% in all cases. Therefore, long AJAX requests are implemented according to the following principle: we make a request to the server from the client, the server creates a Task and associates a specific GUID with it, then returns this GUID to the client, and the client receives the result for this GUID when it arrives at the server from the API. At this stage, we almost got to the bottom of my
We should log and store all requests and answers to these APIs for debriefing, and from the logs we should get the maximum of useful information: called action / controller, IP, URI, user login, etc. etc. When I for the first time using NLog secured my request / response in my ASP.NET Core application, in principle, I was not surprised to see something like this in ElasticSearch:
2017-09-23 23:15:53.4287|0|AspNetCoreApp.Services.LongRespondingService|TRACE|/| DoJob method is starting (AspNetCoreApp.Services.LongRespondingService.DoJob:0)| url:http:///At the same time, everything looked quite correctly in the NLog configuration and the following was set as layout:
${longdate}|${event-properties:item=EventId.Id}|${logger}|${uppercase:${level}}|${aspnet-mvc-controller}/${aspnet-mvc-action}| ${message} (${callsite}:${callsite-linenumber})| url:${aspnet-request-url}The problem here is that the response from the API comes after the client completes the request (it returns only a GUID to it). And then I started thinking about possible solutions to this problem ...
Possible solutions to the problem
Of course, any problem can be fixed in several ways. And to score on it is also one of the tricks that sometimes should not be neglected. But let’s talk about real solutions and their consequences.
Pass task ID to API call method
This is probably the first thing that can only come to mind. We generate a GUID, log this GUID before exiting the action, and pass it to the API service.
The problems with this approach are obvious. We must pass this ID to absolutely all methods of accessing third-party APIs. At the same time, if we want to reuse this piece somewhere else, where such functionality is not required, then this will greatly interfere with us.
The situation is aggravated if we want to process, simplify or aggregate them in some way before giving the data to the client. This applies to business logic and should be taken out in a separate piece. It turns out that this piece, which should remain as independent as possible, will also work with this identifier! So things are not done, so consider other ways.
Save Task ID in CallContext
If we think about what tools the framework provides for these purposes, then the first thing we will remember is CallContext with its LogicalSetData / LogicalGetData. Using these methods, you can save the task ID in CallContext'e, and .NET (better to say, .NET 4.5) will make sure that new threads automatically get access to the same data. Inside the framework, this is implemented using a pattern somewhat reminiscent of Memento, which all methods for starting a new thread / task should use:
// Перед запуском задачи делаем snapshot текущего состояния
var ec = ExecutionContext.Capture();
...
// Разворачиваем сохраненный snapshot в новом потоке
ExecutionContext.Run(ec, obj =>
{
// snapshot на этом этапе уже развернут, поэтому здесь вызывается уже пользовательский код
}, state);
Now that we know how to save the ID, and then get it in our task, we can include this identifier in each of our logged messages. You can do this directly by calling the logging method. Or, in order not to clog the data access layer, you can use the capabilities of your logger. NLog, for example, has Layout Renderers .
Also, as a last resort, you can write your own logger. In ASP.NET Core, all logging is done using special interfaces located in the Microsoft.Extensions.Logging namespace, which are embedded in the class through DI. Therefore, it is enough for us to implement two interfaces: ILogger and ILoggerProvider. I think this option may be useful if your logger does not support extensions.
And so that everything works out as it should, I recommend that you read Stephen Cleary's article . There is no binding to .NET Core in it (in 2013 it simply did not exist yet), but something useful for yourself can definitely be emphasized there.
The disadvantage of this approach is that messages with an identifier will be logged and in order to get the full picture, you will need to look for an HTTP request with the same ID. I will not say anything about performance, because even if there is some sort of drawdown, compared to other things, this will seem to be a disproportionately small value.
But what if you think about why this does not work?
As I already said, messages like:
2017-09-23 23:15:53.4287|0|AspNetCoreApp.Services.LongRespondingService|TRACE|/| DoJob method is starting (AspNetCoreApp.Services.LongRespondingService.DoJob:0)| url:http:///Ie. everything related to IHttpContext is simply nullified. It seems to be understandable: the query execution has ended, so NLog cannot receive data, i.e. there is no longer a link to the HttpContext.
Finally, I decided to see how NLog actually gets a link to the HttpContext outside the controller. Since the SynchronizationContext and HttpContext.Current in .NET Core were over (yes, this is Stephen Cleary again), there must be some other way to do this.
Digging into the source of NLog, I found a certain IHttpContextAccessor. The thirst to understand what is happening here all the same made me climb into GitHub again and see what this magic thing with one property is all about. It turned out that this is just an abstraction over AsyncLocal , which is essentially a new version of LogicalCallContext (the very methods of LogicalSetData / LogicalGetData). By the way, this was not always the case for the .NET Framework .
After that, I asked myself the question: why then, actually, does this not work? We start Task in the standard way, there is no unmanaged code here ... Running the debugger to see what happens with the HttpContext at the time the logging method was called, I saw that the HttpContext is there, but the properties in it are all reset except Request.Scheme, which at the moment The call is "http". So it turns out that in the log I have a strange "
http:///" instead of url . So, it turns out that in order to improve performance, ASP.NET Core somewhere inside itself resets HttpContexts and reuses them. Apparently, such subtleties coupled and allow you to achieve significant advantages over the old ASP.NET MVC.
What could I do about it? Yes, just keep the current state of the HttpContext! I wrote a simple service with the only CloneCurrentContext method that I registered in a DI container.
HttpContextPreserver
public class HttpContextPreserver : IHttpContextPreserver
{
private readonly IHttpContextAccessor _httpContextAccessor;
ILogger _logger;
public HttpContextPreserver(IHttpContextAccessor httpContextAccessor, ILogger logger)
{
_httpContextAccessor = httpContextAccessor;
_logger = logger;
}
public void CloneCurrentContext()
{
var httpContext = _httpContextAccessor.HttpContext;
var feature = httpContext.Features.Get();
feature = new HttpRequestFeature()
{
Scheme = feature.Scheme,
Body = feature.Body,
Headers = new HeaderDictionary(feature.Headers.ToDictionary(kvp => kvp.Key, kvp => kvp.Value)),
Method = feature.Method,
Path = feature.Path,
PathBase = feature.PathBase,
Protocol = feature.Protocol,
QueryString = feature.QueryString,
RawTarget = feature.RawTarget
};
var itemsFeature = httpContext.Features.Get();
itemsFeature = new ItemsFeature()
{
Items = itemsFeature?.Items.ToDictionary(kvp => kvp.Key, kvp => kvp.Value)
};
var routingFeature = httpContext.Features.Get();
routingFeature = new RoutingFeature()
{
RouteData = routingFeature.RouteData
};
var connectionFeature = httpContext.Features.Get();
connectionFeature = new HttpConnectionFeature()
{
ConnectionId = connectionFeature?.ConnectionId,
LocalIpAddress = connectionFeature?.LocalIpAddress,
RemoteIpAddress = connectionFeature?.RemoteIpAddress,
};
var collection = new FeatureCollection();
collection.Set(feature);
collection.Set(itemsFeature);
collection.Set(connectionFeature);
collection.Set(routingFeature);
var newContext = new DefaultHttpContext(collection);
_httpContextAccessor.HttpContext = newContext;
}
}
public interface IHttpContextPreserver
{
void CloneCurrentContext();
}
I did not use deep cloner, as this would add heavy reflection to the project. And I need this in just one single place. Therefore, I simply create a new HttpContext based on the existing one and copy into it only what will be useful to see in the log when analyzing incidents (action | controller, url, ip, etc.). Not all information is copied .
Now starting the application, I saw about the following happy lines:
2017-10-08 20:29:25.3015|0|AspNetCoreApp.Services.LongRespondingService|TRACE|Home/Test| DoJob method is starting (AspNetCoreApp.Services.LongRespondingService.DoJob:0)| url:http://localhost/Test/1
2017-10-08 20:29:34.3322|0|AspNetCoreApp.Services.LongRespondingService|TRACE|Home/Test| DoJob method is ending (AspNetCoreApp.Services.LongRespondingService+d__3.MoveNext:0)| url:http://localhost/Test/1
And this meant for me a small victory, which I am sharing here with you. Who is thinking about this?
To make sure that I didn’t think up anything false, I wrote a small functional load test, which can be found in my github repository along with the service. When starting 5000 simultaneous tasks, the test was successful.
By the way, thanks to the architecture of ASP.NET Core, such tests can be written easily and naturally. You just need to run a full server inside the test and access it through a real socket:
Server Initialization by URL
protected TestFixture(bool fixHttpContext, string solutionRelativeTargetProjectParentDir)
{
var startupAssembly = typeof(TStartup).Assembly;
var contentRoot = GetProjectPath(solutionRelativeTargetProjectParentDir, startupAssembly);
Console.WriteLine($"Content root: {contentRoot}");
var builder = new WebHostBuilder()
.UseKestrel()
.UseContentRoot(contentRoot)
.ConfigureServices(InitializeServices)
.UseEnvironment(fixHttpContext ? "Good" : "Bad")
.UseStartup(typeof(TStartup))
.UseUrls(BaseAddress);
_host = builder.Build();
_host.Start();
}Another reason to use ASP.NET Core in your projects.
Summary
I really liked ASP.NET Core in all aspects of its implementation. It has great flexibility and at the same time lightness of the entire platform. Due to abstractions for absolutely all functionality, you can do any things and customize the entire platform for yourself, your team and your development methods. Cross-platform is not yet perfected, but Microsoft is striving for this, and someday (though maybe not soon) they should succeed.
Github link