Consul.io Part 1
When developing applications, special attention must be paid to architecture. If this is not done initially, scaling problems may appear suddenly (and sometimes they may not have a solution). Scaling the application and efficient use of resources at the initial stage are the saved months of work in the future.
To prevent such problems, a distributed architecture is often used, that is, an architecture with the ability to scale all components horizontally. But unfortunately, when implementing SOA, new problems arise, namely: the connectivity and complexity of service configuration.

In this article, we will talk about one of the discovery services called Consul, with which you can solve the above problems and make the architecture more transparent and understandable.
Designing an application as a set of loosely coupled components, we initially get the ability to scale any component.
SOA ( Service Oriented Architecture ) is an architectural pattern that describes the application architecture in the form of stand-alone components with weak connectivity, communicating with each other using standard protocols (for example, REST). The logical continuation (or subset) of SOA is a microservice architecture. It is based on increasing the number of services instead of increasing the functionality of a particular service (a reflection of the principle of Single Responsibility in architecture) and deep integration with continuous processes.
If we are engaged in the implementation of microservice architecture, then, undoubtedly, the responsibility for the interaction of our services goes to the infrastructure solution of our application. Services that comply with the principle of Single Responsibility can only accept a request and return a response. In this case, it is necessary to balance the traffic between the system nodes, it is necessary to connect, albeit weakly, but still dependent on each other services to each other. And of course, we need to respond to configuration changes in our system:
In any system, this is a continuous and complex process, but with the help of the discovery service we can control it and make it more transparent.
Discovery is a tool (or toolkit) for providing communication between components of an architecture. Using discovery, we provide connectivity between application components, but not connectivity . Discovery can be considered as a kind of register of meta-information about a distributed architecture, which stores all the data about the components. This allows the interaction of components with minimal manual intervention (i.e. in accordance with the ZeroConf principle ).
The Discovery service provides three main functions on which connectivity is based within a distributed architecture:
We will reveal the values of each item in detail:
Consistency A
distributed architecture implies that components can be scaled horizontally, while they must have up-to-date information about the state of the cluster. The Discovery service provides (de) centralized storage and access to it for any node. Components can save their data and information will be delivered to all interested members of the cluster.
Registration and monitoring
Newly added services should report about themselves, and already launched services must undergo a constant check for availability. This is a prerequisite for automatic cluster configuration. Traffic balancers and dependent nodes must have information about the current cluster configuration for efficient use of resources.
Discovery Discovery
refers to a mechanism for finding services, for example, by the roles they perform. We can request a location for all services of a certain role, not knowing their exact number and specific addresses, but only knowing the address of the discovery service.
This article discusses a Consul-based discovery implementation.
Consul is a decentralized fault-tolerant discovery service from HashiCorp (which develops products such as Vagrant, TerraForm, Otto, Atlas and others).
Consul is a decentralized service, that is, the Consul agent is installed on each host and is a full member of the cluster. Thus, services do not need to know the discovery address in our network, all requests to discovery are made to the local address 127.0.0.1.
For the dissemination of information uses algorithms that are based on the eventual consistency model .
Agents use the gossip protocol to disseminate information .
The servers use the Raft algorithm to select a leader .
A leader is a server that accepts all requests for information changes. If we draw an analogy with the database, then this is master in the context of master / slave replication. All other servers replicate data from the leader. The key difference from DB replication is that in the event of a leader failure, all other servers start the election mechanism for the new leader and automatically begin to replicate from it after the election. The switching mechanism is fully automatic and does not require administrator intervention.
Each instance can work in two modes: agent and server. The difference is that the agent is the distribution point of information, and the server is the registration point. Those. agents accept read-only requests, and the server can make changes to existing information (registration and removal of services). In fact, in any case, we execute the request to the local address, the only difference is that the read request will be processed by the agent on the local host, and the request for data change will be redirected to the leader, who will save and distribute the data across the cluster. If our local agent is not a leader at the moment, then our change request will be fully processed locally and distributed across the cluster.
A consul cluster is a network of connected nodes that run services registered in discovery. Consul guarantees that cluster information will be distributed to all cluster members and available upon request. It also supports not only peer-to-peer, but also multi-peer, zone-separated clusters, which in Consul terminology are called data centers. Using Consul, you can work with a specific data center or perform actions on any other. Data centers are not isolated from each other as part of discovery. An agent in one DC can receive information from another DC, which can help in building an effective solution for a distributed system.
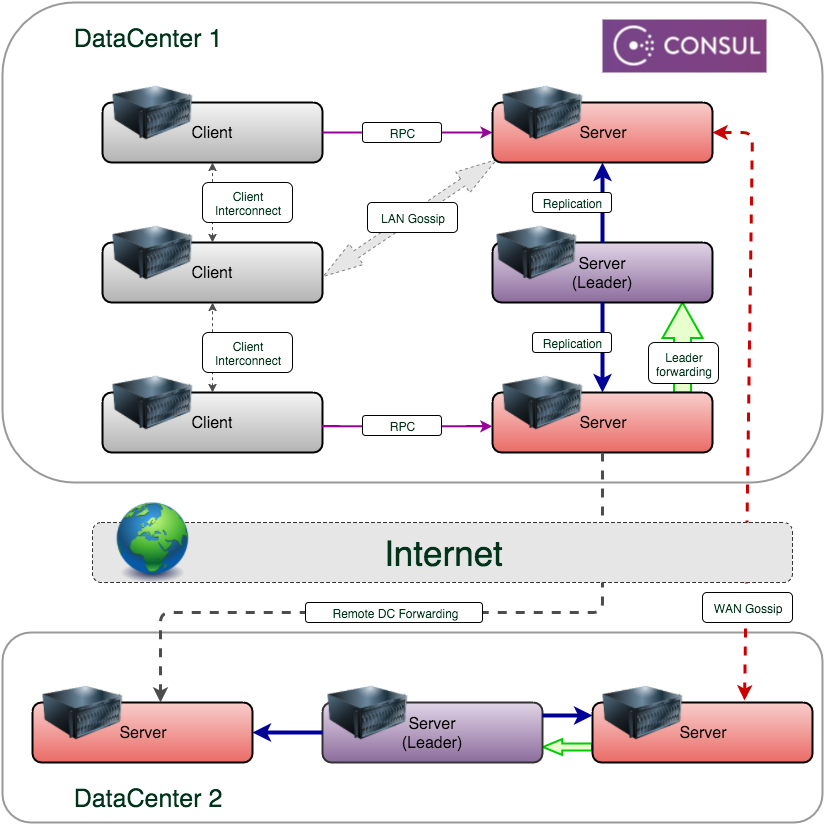
Consul agents running in server mode, in addition to their primary role, also receive the role of a potential cluster leader. It is recommended that you use at least three server-mode agents in the cluster to provide fault tolerance. Using server mode does not impose any restrictions on the basic functionality of the agent.
When entering a new node into the cluster, we need to know the address of any node in the cluster. Having executed the command:
we register a new node in the cluster and, after a short time, information about the state of the entire cluster will be available to this node. Accordingly, the new node will be available for requests from other nodes.
At Consul, we can register our service in two ways:
We consider both cases in more detail.
Using the HTTP API provided by Consul, it is possible to correctly register the component and delete the service in discovery. In addition to these two states, you can use the state
Consider an example of a component registration request (JSON must be passed in a PUT request):
An example of a request to remove a component from the catalog: An example of a request to transfer a service to maintenance mode: Using the enable flag, we can switch the state and add an optional reason parameter that contains a textual description of the reason for the component to switch to maintenance mode. If we need to register any external service and we don’t have the opportunity to “teach” it to register with Consul ourselves, then we can register it not as a service provider, but as an external service. After registration, we will be able to obtain data about the external service through DNS:
In addition to the HTTP API, you can use agent configuration files with the description of services.
In the second part, we will complete the story about the Consul service, namely, we will talk about its following functions:
And of course we’ll summarize the work with Consul.
To prevent such problems, a distributed architecture is often used, that is, an architecture with the ability to scale all components horizontally. But unfortunately, when implementing SOA, new problems arise, namely: the connectivity and complexity of service configuration.
In this article, we will talk about one of the discovery services called Consul, with which you can solve the above problems and make the architecture more transparent and understandable.
Distributed architectures (SOA) and the problems of their construction
Designing an application as a set of loosely coupled components, we initially get the ability to scale any component.
SOA ( Service Oriented Architecture ) is an architectural pattern that describes the application architecture in the form of stand-alone components with weak connectivity, communicating with each other using standard protocols (for example, REST). The logical continuation (or subset) of SOA is a microservice architecture. It is based on increasing the number of services instead of increasing the functionality of a particular service (a reflection of the principle of Single Responsibility in architecture) and deep integration with continuous processes.
If we are engaged in the implementation of microservice architecture, then, undoubtedly, the responsibility for the interaction of our services goes to the infrastructure solution of our application. Services that comply with the principle of Single Responsibility can only accept a request and return a response. In this case, it is necessary to balance the traffic between the system nodes, it is necessary to connect, albeit weakly, but still dependent on each other services to each other. And of course, we need to respond to configuration changes in our system:
- Services are constantly being added.
- Some services no longer respond to healthcheck.
- New components appear in the system and it is necessary to disseminate information about them as efficiently as possible.
- The versions of individual components are updated - backward compatibility breaks.
In any system, this is a continuous and complex process, but with the help of the discovery service we can control it and make it more transparent.
What is discovery?
Discovery is a tool (or toolkit) for providing communication between components of an architecture. Using discovery, we provide connectivity between application components, but not connectivity . Discovery can be considered as a kind of register of meta-information about a distributed architecture, which stores all the data about the components. This allows the interaction of components with minimal manual intervention (i.e. in accordance with the ZeroConf principle ).
The role of discovery in building a distributed architecture
The Discovery service provides three main functions on which connectivity is based within a distributed architecture:
- Consistency of meta-information about services within a cluster.
- A mechanism for recording and monitoring component availability.
- A mechanism for detecting components.
We will reveal the values of each item in detail:
Consistency A
distributed architecture implies that components can be scaled horizontally, while they must have up-to-date information about the state of the cluster. The Discovery service provides (de) centralized storage and access to it for any node. Components can save their data and information will be delivered to all interested members of the cluster.
Registration and monitoring
Newly added services should report about themselves, and already launched services must undergo a constant check for availability. This is a prerequisite for automatic cluster configuration. Traffic balancers and dependent nodes must have information about the current cluster configuration for efficient use of resources.
Discovery Discovery
refers to a mechanism for finding services, for example, by the roles they perform. We can request a location for all services of a certain role, not knowing their exact number and specific addresses, but only knowing the address of the discovery service.
Consul.io as an implementation of discovery
This article discusses a Consul-based discovery implementation.
Consul is a decentralized fault-tolerant discovery service from HashiCorp (which develops products such as Vagrant, TerraForm, Otto, Atlas and others).
Consul is a decentralized service, that is, the Consul agent is installed on each host and is a full member of the cluster. Thus, services do not need to know the discovery address in our network, all requests to discovery are made to the local address 127.0.0.1.
What else you need to know about Consul:
For the dissemination of information uses algorithms that are based on the eventual consistency model .
Agents use the gossip protocol to disseminate information .
The servers use the Raft algorithm to select a leader .
A leader is a server that accepts all requests for information changes. If we draw an analogy with the database, then this is master in the context of master / slave replication. All other servers replicate data from the leader. The key difference from DB replication is that in the event of a leader failure, all other servers start the election mechanism for the new leader and automatically begin to replicate from it after the election. The switching mechanism is fully automatic and does not require administrator intervention.
Each instance can work in two modes: agent and server. The difference is that the agent is the distribution point of information, and the server is the registration point. Those. agents accept read-only requests, and the server can make changes to existing information (registration and removal of services). In fact, in any case, we execute the request to the local address, the only difference is that the read request will be processed by the agent on the local host, and the request for data change will be redirected to the leader, who will save and distribute the data across the cluster. If our local agent is not a leader at the moment, then our change request will be fully processed locally and distributed across the cluster.
Using Consul in a Cluster
A consul cluster is a network of connected nodes that run services registered in discovery. Consul guarantees that cluster information will be distributed to all cluster members and available upon request. It also supports not only peer-to-peer, but also multi-peer, zone-separated clusters, which in Consul terminology are called data centers. Using Consul, you can work with a specific data center or perform actions on any other. Data centers are not isolated from each other as part of discovery. An agent in one DC can receive information from another DC, which can help in building an effective solution for a distributed system.
Consul agents running in server mode, in addition to their primary role, also receive the role of a potential cluster leader. It is recommended that you use at least three server-mode agents in the cluster to provide fault tolerance. Using server mode does not impose any restrictions on the basic functionality of the agent.
When entering a new node into the cluster, we need to know the address of any node in the cluster. Having executed the command:
consul join node_ip_addresswe register a new node in the cluster and, after a short time, information about the state of the entire cluster will be available to this node. Accordingly, the new node will be available for requests from other nodes.
Types of nodes: internal, external
At Consul, we can register our service in two ways:
- Use the HTTP API or agent configuration file, but only if your service can communicate with Consul independently.
- Register the service as a 3d-party component in case the service cannot communicate with Consul.
We consider both cases in more detail.
Using the HTTP API provided by Consul, it is possible to correctly register the component and delete the service in discovery. In addition to these two states, you can use the state
maintenance. In this mode, the service is marked as unavailable and ceases to appear in DNS and API requests. Consider an example of a component registration request (JSON must be passed in a PUT request):
http://localhost:8500/v1/agent/service/register
{
"ID": "redis1",
"Name": "redis",
"Tags": [
"master",
"v1"
],
"Address": "127.0.0.1",
"Port": 8000,
"Check": {
"Script": "/usr/local/bin/check_redis.py",
"HTTP": "http://localhost:5000/health",
"Interval": "10s",
"TTL": "15s"
}
}
An example of a request to remove a component from the catalog: An example of a request to transfer a service to maintenance mode: Using the enable flag, we can switch the state and add an optional reason parameter that contains a textual description of the reason for the component to switch to maintenance mode. If we need to register any external service and we don’t have the opportunity to “teach” it to register with Consul ourselves, then we can register it not as a service provider, but as an external service. After registration, we will be able to obtain data about the external service through DNS:
http://localhost:8500/v1/agent/service/deregister/[ServiceID]
http://localhost:8500/v1/agent/service/maintenanse/[ServiceID]?enable=true|false
$ curl -X PUT -d '{"Datacenter": "dc1", "Node": "google",
"Address": "www.google.com",
"Service": {"Service": "search", "Port": 80}}'
http://127.0.0.1:8500/v1/catalog/register
In addition to the HTTP API, you can use agent configuration files with the description of services.
In the second part, we will complete the story about the Consul service, namely, we will talk about its following functions:
- DNS interface.
- HTTP API
- Health Checks.
- K / V storage.
And of course we’ll summarize the work with Consul.