Using various metrics to cluster key queries
- Tutorial
Technology determines the result. Calltouch has long accepted this truth.
Our senior product manager Fedor Ivanov mthmtcn wrote about using various metrics to cluster key queries.
To date, conversion optimization tools in contextual advertising are widely used by both direct advertisers and agencies. For more than a year now, at Calltouch, we have been developing our tool for optimizing bids in contextual advertising. The main goal of optimizers is to calculate such bids for keywords, setting them would allow to achieve those desired key indicators( K P I ) that are set as the optimization goal. A classic example of such a statement of the problem is optimization byC P A( C o s tP e rA c t i o n ) . In this case, the main goal of the optimizer is to get as many conversions (target actions) as possible so that the average cost of this action does not exceed the established target limitC P A . There are also optimization strategies such as maximizationR O I( R e t u r no fI n v e s t m e n t ) , attracting maximum conversions for a given budget for advertising campaigns, etc.
Today on the market there are a significant number of systems that are engaged in bid management. Each tool has its own characteristics in terms of initial configuration, functionality, additional options, etc. In particular, Calltouch optimizer specializes in optimizing contextual advertising in calling topics (although its capabilities are not limited to optimizing only for calls). Context optimization systems as a whole successfully cope with the tasks that advertisers set for them. However, a significant effect of optimization is achieved mainly by those customers who have large advertising budgets. To understand this dependence is quite simple. All conversion optimizers in one way or another are repelled from the data collected over some reference period. The larger the budget for the advertising account, the more statistics, necessary to calculate the optimal bids, manages to collect. In addition, the size of the budget for the context directly affects the speed of data collection, and hence the speed with which optimizers “accelerate”. The above is clearly illustrated by Yandex.Direct help on the automatic bidding strategy for the campaign:
Obviously, only a very small number of advertising campaigns fit the “filter” discussed above. For advertisers with small budgets, as well as for newly created advertising campaigns, the launch of this kind of optimizer is impossible. Of course, “third-party” optimizers are not so demanding on the volume of traffic (in particular, we set a minimum threshold of 1 target visit and 10 clicks per day on the “folder” - a package of optimized campaigns with singleK P I and the optimization strategy), but they are somehow forced to exist in conditions of a significant deficit of accumulated statistics. Consider the problem of lack of data in more detail.
The Pareto principle is widely known, which can be formulated as: “20% of efforts yield 80% of the result”:
Based on our observations, this principle also takes place in contextual advertising, but the proportion is slightly different: “95% of traffic falls to 5% of key phrases ( statistics) ”:

Since the conversion optimizers decide on the optimal bid for each key phrase separately, an informed decision can only be made for about 5% of the phrases. If we examine this picture in more detail, then all key phrases can be divided into 3 groups according to the volume of statistics (for a certain period of its collection, which is also called a reference):

Of course, the question of the adequacy of statistics should be consistent with some criterion for assessing the amount of data. The calculation of this criterion is based on the methods of probability theory and mathematical statistics associated with assessing the adequacy of the sample size of a certain distribution.
Thus, all key phrases of a phrase can be divided into 3 main groups:
Before you start discussing various approaches to calculating bids under conditions of insufficient data, you need to understand how this data is converted to the optimal bid. This conversion can be divided into 2 main blocks:
First, consider the second block. We assume that we predicted the conversion rateWith R for the phrase. If the client has set the targetTo R I and the phrase has accumulated some statisticsS T according to the required key metrics, then the optimal rateB i d is calculated as a function of the above parameters:
The key point in calculating the bid is to predict the conversion rate as accurately as possible, which is done before the bid calculation. By definition, a keyword’s conversion rate is the likelihood that a click on that phrase will result in a conversion. With enough clicksC L and conversionsC V , this coefficient can be calculated as:
For example, suppose a phraseX for some period there were 2 clicks and 1 conversion. In this case, the formula will give the valueC R = 0.5 . Let the optimization strategy be “maximum conversions forC P A = 2000 rubles. ", ThenB i d = 200 ∗ 0.5 = 1000 rub. It remains to hope that the phraseX does not refer to the YAN campaign ...
The opposite is the case. Let the phraseY had 2 clicks and 0 conversions. In this case, the formula will give the valueC R = 0 . Let the optimization strategy be “maximum conversions forC P A = 2000 rubles ", thenrub. In this case, the minimum bid for the currency of this account will be sent. Impressions for the phrase will practically stop, and it will never bring a conversion in the future.
If the phrase had 0 clicks and 0 conversions, then the calculation“Directly” is impossible in principle due to the uncertainty of the expression “0/0”.
Thus, the "simple" calculation formulacan be used only for key phrases with a sufficient amount of statistics (as we recall, about 5% of such phrases), and we cannot make a “weighted” decision on the remaining 95% of phrases.
In order to get out of this situation, various techniques can be used, for example:
Methods 2 and 5 are actively used in our tool, in the near future we also plan to add the ability to flexibly configure the reference period. On how to do this, we will write a separate article. And in this paper we will consider the “pooling” method, which has shown the greatest efficiency and is widely used in contextual advertising optimization systems.
Pooling Methods
Pooling is essentially a “reasonable” increase in statistics for a keyword by borrowing statistics for other phrases. In order to understand the principle of classic pooling, we turn to the structure of an advertising account (for example, Yandex Direct):
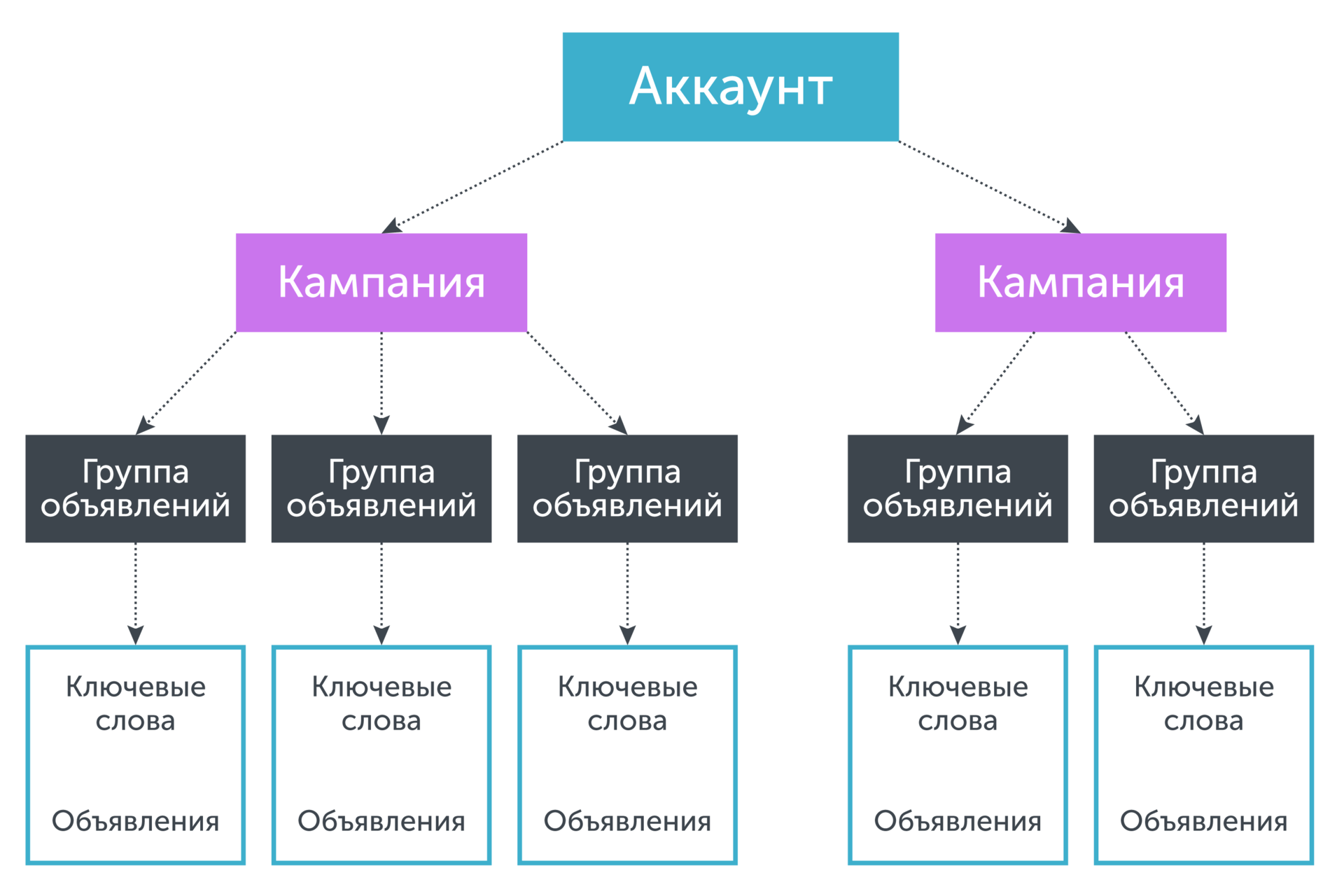
An account has a tree structure, where the "root" is the account itself, and the "leaves" are key phrases. Key phrases are related in a certain way to the ads that they trigger. Ads, in turn, are collected in ad groups, which in turn are combined as part of an advertising campaign. If we need to predict the conversion rate for a keyword, whose own statistics are not enough, then we combine the statistics for the keyword and ads, the ad group to which this phrase belongs, the campaign to which this ad group belongs, and so on, until thus, the statistics will not be enough to decide on the value of the predicted parameter. Graphically, this is equivalent to “moving down” the tree from “leaves” to “root”:
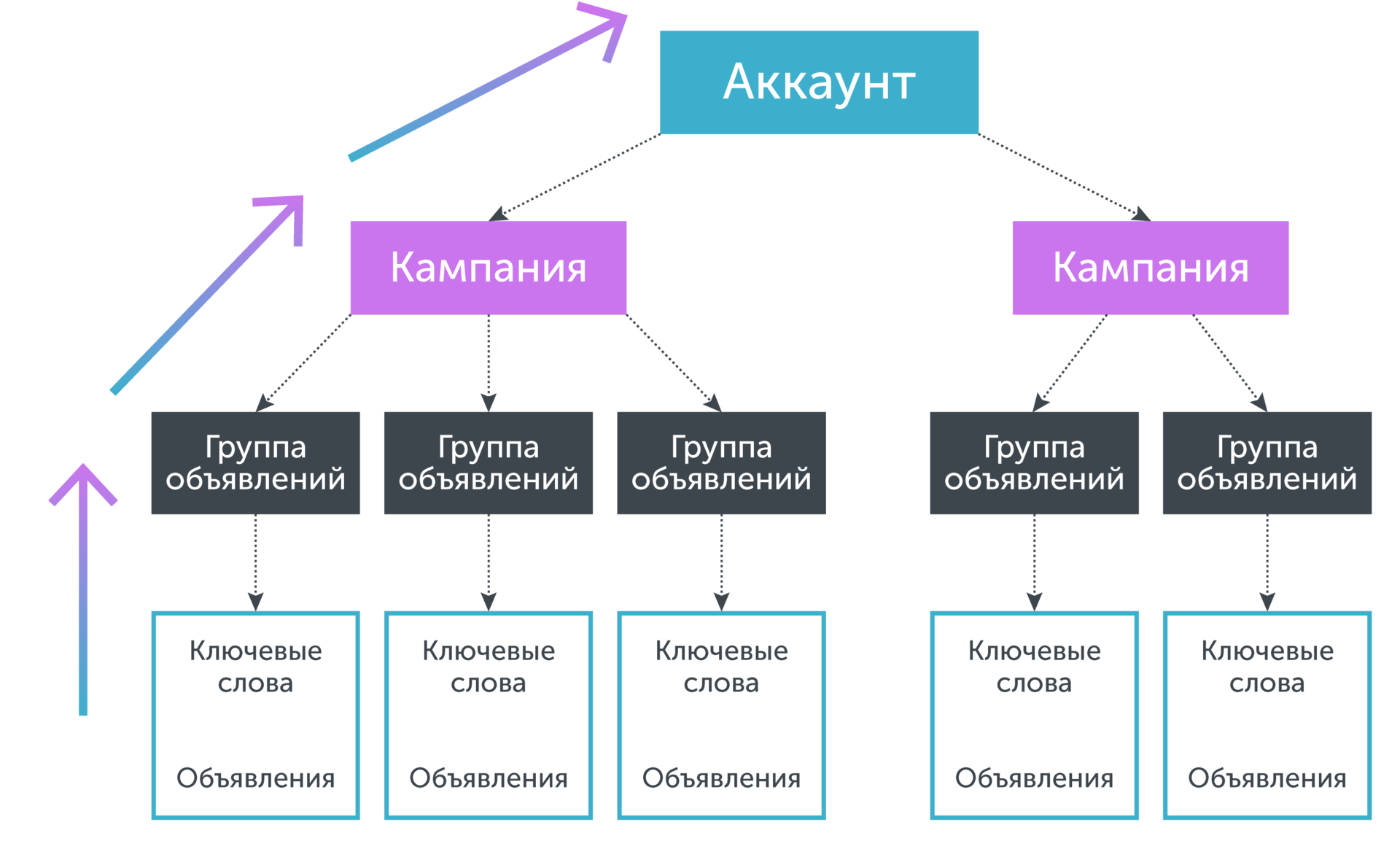
The simplest pooling formula is:Where - projected key phrase - the number of conversions for the keyword, - number of clicks on a keyword phrase, - the value of the conversion rate for the next pooling level (for example, the value of the conversion rate of the campaign). Thus, this model predicts how many phrases will require additional clicks to get another conversion, assuming that on average all phrases have close to. In turn, it can be calculated directly, provided that at this level there is enough statistical data, otherwise it can be calculated using pooling of a higher level. In this case, a complex nested model is obtained.
We give an example. Let the phrase had 5 clicks and 1 conversion, and for the ad group in which it’s located , got 100 clicks and 5 conversions. If we assume that a hundred clicks are enough to make a decision on the optimal bid, we get:The pooling method and its various generalizations are widely used in contextual advertising automation systems. For example, Marin Software, the world's most popular advertising management platform on the Internet, has patented its model (patent US PTO 60948670):
Where - the average value of the conversion probability for the next pooling level, - variance (measure of spread) of the conversion probability values of the next pooling level.
Obviously, the larger the variance, the less, which means that the next level of pooling in predicting the conversion rate has less influence. Valuedetermined by how close conversion rates are to each other. With the classic pooling modelwill directly depend on how well the advertising account is developed, which means the quality of forecasting directly depends on the human factor.
In addition, hierarchical pooling only takes into account statistics for phrases, leaving aside its structure.
In connection with the foregoing, the Calltouch team developed a different approach to forecasting conversion rates.
The main idea of our approach is to abandon the hierarchical structure when pulling. Instead, a special metric is introduced.(a measure of distance), allowing to evaluate the similarity of the texts of key phrases among themselves.
For a given keyword phrase we will select such elements from a variety of phrases with sufficient statistics (which we will call the clustering core) so that the distance between the text and selected elements did not exceed some predetermined number : If for a given the cluster does not contain enough statistics, then increases by a certain step : until in you won’t get enough statistics to predict the phrase’s conversion rate . Once the cluster is composed, the average value of the conversion rate of phrases within the cluster is selected as the value. Graphically, this process can be represented in the following form:

Now we will consider the cluster structure in more detail:
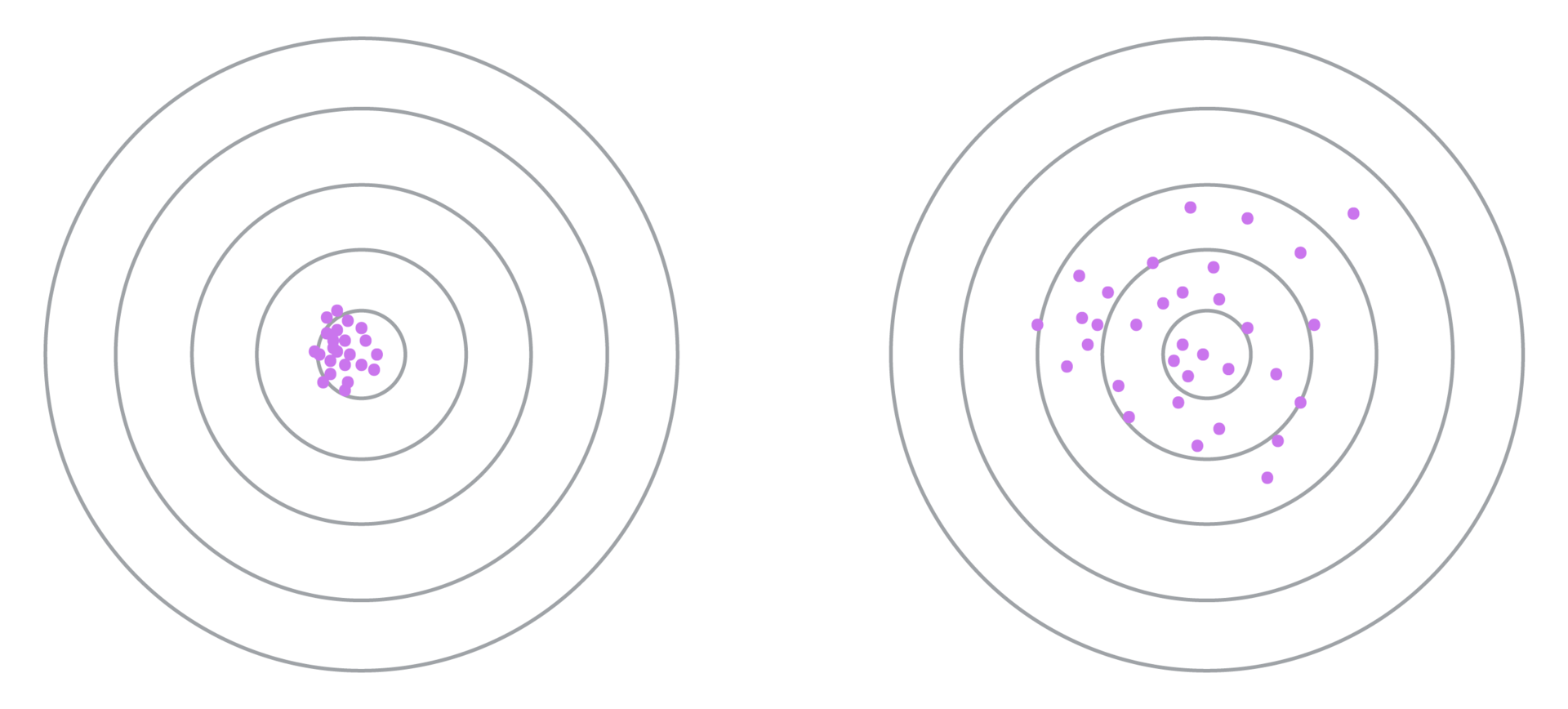
Key phrases with a small dispersion of the conversion coefficient are selected in the left figure, while with a large dispersion in the right one. It can be seen that in the case of large dispersion, the algorithm converges more slowly (it is necessary to increase the threshold several times, and the forecast itself is less accurate. Therefore, it is required to pre-select a phrase similarity metric that minimizes variance.
There are many different metrics to calculate the similarity of two texts (key phrases in our case). Each of these metrics has both its advantages and disadvantages, which narrow the scope of their possible application. In a study conducted by our team, the following types of distances were considered:
We consider each of the metrics in more detail.
Levenshtein distance is defined as the minimum number of operations to insert one character, delete one character and replace one character with another, necessary to turn one line into another. Denote this line spacing and as . Clear that the morethe smaller the line and look alike.
Here are some examples.
Let be and then to turn at , it is required to replace “t” with “o”, “p” with “b” and “o” with “a”, which means .
If a'this is one phrase' and "and this is a completely different phrase," then .
The main advantages of Levenshtein's distance are its weak dependence on the word forms in the text as well as ease of implementation, and the main disadvantage is the dependence on the word order.
The main idea underlying the calculation of the N-gram distance is to split the lines into substrings of length N and count the number of matching substrings.
For example, if N = 2 (division into bigrams) and'once keyword,' but 'two keywords' then corresponds to the following set of bigrams: 'ra', 'az', 'ke', 'her', ..., 'rd', and the line : 'dv', 'va', 'ke', 'her', ..., 'rd'.
If N = 3 (partition into trigrams), then for the same and we get:
: 'times', 'azk', 'zke', 'kay', 'neur', ..., 'hordes'
: 'two', 'vak', 'ake', 'kay', 'neur', ..., 'hordes'
N-gram distance itself calculated by the following formula: Where - the number of N-grams in , - the number of N-grams in and - the number of total N-grams and .
In our case: and .
The main advantage of this approach to calculating the similarity of key phrases is that it weakly depends on the forms of words in the text. The main drawback is the dependence on the free parameter N, the choice of which can have a strong effect on the dispersion inside the cluster.
The main idea on which the calculation of the cosine distance is based is that a string of characters can be converted to a numerical vector. If we perform this procedure with two compared strings, then the measure of their similarity can be estimated through the cosine between two numerical vectors. From the course of school mathematics, it is known that if the angle between the vectors is 0 (that is, the vectors completely coincide), then the cosine is 1. And vice versa: if the angle between the vectors is 90 degrees (the vectors are orthogonal - that is, they do not completely coincide), then the cosine between equal to 0.
Before introducing the formal definition of the cosine distance, it is necessary to determine the method of mapping the string to a numerical vector. As such a display, we used the conversion of a text string into a vector of indicators.
Consider an example. Let be
'buy plastic windows at a discount',
'buy inexpensive plastic windows with free delivery in Moscow'
Let 's make a table:

The first row of the table shows all the different words that appear in the texts and , the second and third lines are indicators that the given word appears in the line or respectively. Thus, if we replace each of the lines and to vectors from indicators (we call them, respectively and ), then we can calculate the cosine between the lines using the formula:
For our example:
Distance between and we will consider by the formula:
Then in our case:
The main advantage of the cosine distance is that this metric works well on sparse data (real texts of key phrases can be very long, contain significant amounts of overhead information, such as negative keywords, stop words, etc.) A key disadvantage of cosine distance is his very strong dependence on the forms of the word.
We illustrate this with a case in point. Let be,
'buy plastic windows'
'buy a window made of plastic'
It is easy to see that all the words in two seemingly very similar texts are used in different forms. If we calculate the cosine distance between such lines, we get. This means that between and there is generally nothing in common that does not agree with common sense.
To correct the situation allows preliminary preprocessing of the text (lemmatization).
Here is a quick reference from Wikipedia.
In our case, from “Buy plastic windows” we get “buy plastic windows”, and from “Buy a window made of plastic” - “buy a window made of plastic”. Then for normalized texts we have:Thus, the cosine distance should be calculated after preliminary processing of the text.
The optimizer development team and I tested the metrics discussed above on the statistics collected in our clients' advertising accounts. Various topics were considered, such as: real estate, automobiles, medicine, etc. Since the Calltouch service database contains data on more than 10,000 customers, we had more than enough data to conduct reliable tests with metrics. The table shows the averaged variance metrics calculated by clustering key phrases using various metrics.
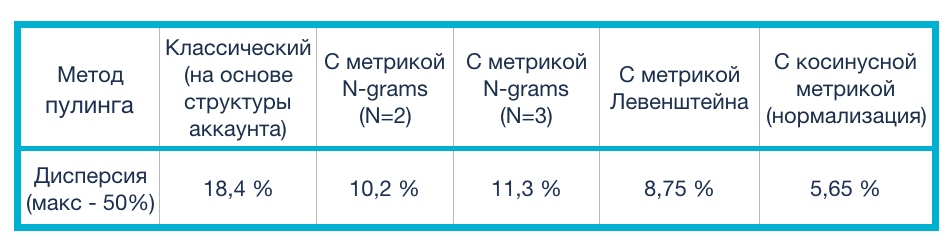
These key phrases were selected as the clustering core for which there was at least one conversion and the number of clicks in the last 28 dayswhich satisfies the ratio:Where - The conversion rate of the campaign to which the keyword phrase belongs.
It can be seen from the table that the classical pooling method has the greatest dispersion (which means its use leads to the least accurate forecast), while the use of any of the metrics for the similarity of phrases among themselves significantly reduces this indicator. The best metric for clustering was the cosine distance.
This article discusses a new approach to clustering key phrases based on text similarity. It is shown that this method significantly reduces the intra-cluster dispersion of the conversion coefficient, which significantly improves the accuracy of the conversion forecasting by keyword. The methods described in the article can be used to optimize even those phrases whose own statistics are not enough to make a decision on the optimal bid. The above methods for calculating the conversion rate are elements of the Calltouch conversion optimizer, which in practice shows high efficiency both on large projects and on accounts with a relatively small advertising budget.
Our senior product manager Fedor Ivanov mthmtcn wrote about using various metrics to cluster key queries.
Introduction
To date, conversion optimization tools in contextual advertising are widely used by both direct advertisers and agencies. For more than a year now, at Calltouch, we have been developing our tool for optimizing bids in contextual advertising. The main goal of optimizers is to calculate such bids for keywords, setting them would allow to achieve those desired key indicators( K P I ) that are set as the optimization goal. A classic example of such a statement of the problem is optimization byC P A( C o s tP e rA c t i o n ) . In this case, the main goal of the optimizer is to get as many conversions (target actions) as possible so that the average cost of this action does not exceed the established target limitC P A . There are also optimization strategies such as maximizationR O I( R e t u r no fI n v e s t m e n t ) , attracting maximum conversions for a given budget for advertising campaigns, etc.
Today on the market there are a significant number of systems that are engaged in bid management. Each tool has its own characteristics in terms of initial configuration, functionality, additional options, etc. In particular, Calltouch optimizer specializes in optimizing contextual advertising in calling topics (although its capabilities are not limited to optimizing only for calls). Context optimization systems as a whole successfully cope with the tasks that advertisers set for them. However, a significant effect of optimization is achieved mainly by those customers who have large advertising budgets. To understand this dependence is quite simple. All conversion optimizers in one way or another are repelled from the data collected over some reference period. The larger the budget for the advertising account, the more statistics, necessary to calculate the optimal bids, manages to collect. In addition, the size of the budget for the context directly affects the speed of data collection, and hence the speed with which optimizers “accelerate”. The above is clearly illustrated by Yandex.Direct help on the automatic bidding strategy for the campaign:
28 days targeted visits + 0.01 x 28 days clicks ≥ 40- This is the optimization threshold for an automatic CPA strategy (for 1 campaign).
The strategy is effective for campaigns with more than 200 clicks per week and more than 10 targeted visits per week.- and this is a criterion that guarantees the effectiveness of optimization.
Obviously, only a very small number of advertising campaigns fit the “filter” discussed above. For advertisers with small budgets, as well as for newly created advertising campaigns, the launch of this kind of optimizer is impossible. Of course, “third-party” optimizers are not so demanding on the volume of traffic (in particular, we set a minimum threshold of 1 target visit and 10 clicks per day on the “folder” - a package of optimized campaigns with singleK P I and the optimization strategy), but they are somehow forced to exist in conditions of a significant deficit of accumulated statistics. Consider the problem of lack of data in more detail.
Keyword Statistics
The Pareto principle is widely known, which can be formulated as: “20% of efforts yield 80% of the result”:
Based on our observations, this principle also takes place in contextual advertising, but the proportion is slightly different: “95% of traffic falls to 5% of key phrases ( statistics) ”:
Since the conversion optimizers decide on the optimal bid for each key phrase separately, an informed decision can only be made for about 5% of the phrases. If we examine this picture in more detail, then all key phrases can be divided into 3 groups according to the volume of statistics (for a certain period of its collection, which is also called a reference):
Of course, the question of the adequacy of statistics should be consistent with some criterion for assessing the amount of data. The calculation of this criterion is based on the methods of probability theory and mathematical statistics associated with assessing the adequacy of the sample size of a certain distribution.
Thus, all key phrases of a phrase can be divided into 3 main groups:
- Phrases with sufficient statistics for the reference period
- Phrases with statistics that are not enough to make a decision
- Phrases without statistics for the reference period
Before you start discussing various approaches to calculating bids under conditions of insufficient data, you need to understand how this data is converted to the optimal bid. This conversion can be divided into 2 main blocks:
- Calculation of the predicted coefficient C R Keyword Conversions
- Calculation of the optimal bid for the calculated C R and establishedK P I
First, consider the second block. We assume that we predicted the conversion rateWith R for the phrase. If the client has set the targetTo R I and the phrase has accumulated some statisticsS T according to the required key metrics, then the optimal rateB i d is calculated as a function of the above parameters:
B i d = f ( C R , K P I , S T )
. It is obvious that the conversion rate itself also depends on the accumulated statistics, but does not depend on K P I :C R = C R ( S T )
Therefore, the final formula for calculating the optimal rate is:B i d = f ( C R ( S T ) , K P I , S T )
Specific type of function f depends both on the metrics used, which are contained inS T , and from the optimization strategy andK P I . For example, for an optimization strategy forC P A the simplest formula for calculating the rate is:B i d = C P A ∗ C R
For other strategies, more complex formulas for calculating bets are used.The key point in calculating the bid is to predict the conversion rate as accurately as possible, which is done before the bid calculation. By definition, a keyword’s conversion rate is the likelihood that a click on that phrase will result in a conversion. With enough clicksC L and conversionsC V , this coefficient can be calculated as:
C R = C VC l
However, applying this formula “head-on” with a small amount of statistics can lead to a deliberately inaccurate forecast of the conversion rate.For example, suppose a phraseX for some period there were 2 clicks and 1 conversion. In this case, the formula will give the valueC R = 0.5 . Let the optimization strategy be “maximum conversions forC P A = 2000 rubles. ", ThenB i d = 200 ∗ 0.5 = 1000 rub. It remains to hope that the phraseX does not refer to the YAN campaign ...
The opposite is the case. Let the phraseY had 2 clicks and 0 conversions. In this case, the formula will give the valueC R = 0 . Let the optimization strategy be “maximum conversions forC P A = 2000 rubles ", thenrub. In this case, the minimum bid for the currency of this account will be sent. Impressions for the phrase will practically stop, and it will never bring a conversion in the future.
If the phrase had 0 clicks and 0 conversions, then the calculation“Directly” is impossible in principle due to the uncertainty of the expression “0/0”.
Thus, the "simple" calculation formulacan be used only for key phrases with a sufficient amount of statistics (as we recall, about 5% of such phrases), and we cannot make a “weighted” decision on the remaining 95% of phrases.
In order to get out of this situation, various techniques can be used, for example:
- Setting Single Bids at the Campaign Level
- Analysis of metrics correlating with (e.g. bounce rate)
- Raising bids until phrases start collecting statistics
- Reference period extension
- The use of "pooling" (smart inheritance and averaging statistics)
Methods 2 and 5 are actively used in our tool, in the near future we also plan to add the ability to flexibly configure the reference period. On how to do this, we will write a separate article. And in this paper we will consider the “pooling” method, which has shown the greatest efficiency and is widely used in contextual advertising optimization systems.
Pooling Methods
Pooling is essentially a “reasonable” increase in statistics for a keyword by borrowing statistics for other phrases. In order to understand the principle of classic pooling, we turn to the structure of an advertising account (for example, Yandex Direct):
An account has a tree structure, where the "root" is the account itself, and the "leaves" are key phrases. Key phrases are related in a certain way to the ads that they trigger. Ads, in turn, are collected in ad groups, which in turn are combined as part of an advertising campaign. If we need to predict the conversion rate for a keyword, whose own statistics are not enough, then we combine the statistics for the keyword and ads, the ad group to which this phrase belongs, the campaign to which this ad group belongs, and so on, until thus, the statistics will not be enough to decide on the value of the predicted parameter. Graphically, this is equivalent to “moving down” the tree from “leaves” to “root”:
The simplest pooling formula is:Where - projected key phrase - the number of conversions for the keyword, - number of clicks on a keyword phrase, - the value of the conversion rate for the next pooling level (for example, the value of the conversion rate of the campaign). Thus, this model predicts how many phrases will require additional clicks to get another conversion, assuming that on average all phrases have close to. In turn, it can be calculated directly, provided that at this level there is enough statistical data, otherwise it can be calculated using pooling of a higher level. In this case, a complex nested model is obtained.
We give an example. Let the phrase had 5 clicks and 1 conversion, and for the ad group in which it’s located , got 100 clicks and 5 conversions. If we assume that a hundred clicks are enough to make a decision on the optimal bid, we get:The pooling method and its various generalizations are widely used in contextual advertising automation systems. For example, Marin Software, the world's most popular advertising management platform on the Internet, has patented its model (patent US PTO 60948670):
Where - the average value of the conversion probability for the next pooling level, - variance (measure of spread) of the conversion probability values of the next pooling level.
Obviously, the larger the variance, the less, which means that the next level of pooling in predicting the conversion rate has less influence. Valuedetermined by how close conversion rates are to each other. With the classic pooling modelwill directly depend on how well the advertising account is developed, which means the quality of forecasting directly depends on the human factor.
In addition, hierarchical pooling only takes into account statistics for phrases, leaving aside its structure.
In connection with the foregoing, the Calltouch team developed a different approach to forecasting conversion rates.
Key ideas of our approach
The main idea of our approach is to abandon the hierarchical structure when pulling. Instead, a special metric is introduced.(a measure of distance), allowing to evaluate the similarity of the texts of key phrases among themselves.
For a given keyword phrase we will select such elements from a variety of phrases with sufficient statistics (which we will call the clustering core) so that the distance between the text and selected elements did not exceed some predetermined number : If for a given the cluster does not contain enough statistics, then increases by a certain step : until in you won’t get enough statistics to predict the phrase’s conversion rate . Once the cluster is composed, the average value of the conversion rate of phrases within the cluster is selected as the value. Graphically, this process can be represented in the following form:
Now we will consider the cluster structure in more detail:
Key phrases with a small dispersion of the conversion coefficient are selected in the left figure, while with a large dispersion in the right one. It can be seen that in the case of large dispersion, the algorithm converges more slowly (it is necessary to increase the threshold several times, and the forecast itself is less accurate. Therefore, it is required to pre-select a phrase similarity metric that minimizes variance.
Affinity metrics
There are many different metrics to calculate the similarity of two texts (key phrases in our case). Each of these metrics has both its advantages and disadvantages, which narrow the scope of their possible application. In a study conducted by our team, the following types of distances were considered:
- Levenshtein distance
- N gram distance
- Cosine distance
We consider each of the metrics in more detail.
Levenshtein distance
Levenshtein distance is defined as the minimum number of operations to insert one character, delete one character and replace one character with another, necessary to turn one line into another. Denote this line spacing and as . Clear that the morethe smaller the line and look alike.
Here are some examples.
Let be and then to turn at , it is required to replace “t” with “o”, “p” with “b” and “o” with “a”, which means .
If a'this is one phrase' and "and this is a completely different phrase," then .
The main advantages of Levenshtein's distance are its weak dependence on the word forms in the text as well as ease of implementation, and the main disadvantage is the dependence on the word order.
N gram distance
The main idea underlying the calculation of the N-gram distance is to split the lines into substrings of length N and count the number of matching substrings.
For example, if N = 2 (division into bigrams) and'once keyword,' but 'two keywords' then corresponds to the following set of bigrams: 'ra', 'az', 'ke', 'her', ..., 'rd', and the line : 'dv', 'va', 'ke', 'her', ..., 'rd'.
If N = 3 (partition into trigrams), then for the same and we get:
: 'times', 'azk', 'zke', 'kay', 'neur', ..., 'hordes'
: 'two', 'vak', 'ake', 'kay', 'neur', ..., 'hordes'
N-gram distance itself calculated by the following formula: Where - the number of N-grams in , - the number of N-grams in and - the number of total N-grams and .
In our case: and .
The main advantage of this approach to calculating the similarity of key phrases is that it weakly depends on the forms of words in the text. The main drawback is the dependence on the free parameter N, the choice of which can have a strong effect on the dispersion inside the cluster.
Cosine distance
The main idea on which the calculation of the cosine distance is based is that a string of characters can be converted to a numerical vector. If we perform this procedure with two compared strings, then the measure of their similarity can be estimated through the cosine between two numerical vectors. From the course of school mathematics, it is known that if the angle between the vectors is 0 (that is, the vectors completely coincide), then the cosine is 1. And vice versa: if the angle between the vectors is 90 degrees (the vectors are orthogonal - that is, they do not completely coincide), then the cosine between equal to 0.
Before introducing the formal definition of the cosine distance, it is necessary to determine the method of mapping the string to a numerical vector. As such a display, we used the conversion of a text string into a vector of indicators.
Consider an example. Let be
'buy plastic windows at a discount',
'buy inexpensive plastic windows with free delivery in Moscow'
Let 's make a table:
The first row of the table shows all the different words that appear in the texts and , the second and third lines are indicators that the given word appears in the line or respectively. Thus, if we replace each of the lines and to vectors from indicators (we call them, respectively and ), then we can calculate the cosine between the lines using the formula:
For our example:
Distance between and we will consider by the formula:
Then in our case:
The main advantage of the cosine distance is that this metric works well on sparse data (real texts of key phrases can be very long, contain significant amounts of overhead information, such as negative keywords, stop words, etc.) A key disadvantage of cosine distance is his very strong dependence on the forms of the word.
We illustrate this with a case in point. Let be,
'buy plastic windows'
'buy a window made of plastic'
It is easy to see that all the words in two seemingly very similar texts are used in different forms. If we calculate the cosine distance between such lines, we get. This means that between and there is generally nothing in common that does not agree with common sense.
To correct the situation allows preliminary preprocessing of the text (lemmatization).
Here is a quick reference from Wikipedia.
Lemmatization (normalization) is the process of reducing a word form to a lemma - its normal (vocabulary) form.
In Russian, the following morphological forms are considered normal:
- for nouns, the nominative case, singular;
- for adjectives - nominative case, singular, masculine;
- for verbs, participles, participles - a verb in the infinitive.
In addition, lemmatization removes from the text all official words - prepositions, conjunctions, particles, etc.
In our case, from “Buy plastic windows” we get “buy plastic windows”, and from “Buy a window made of plastic” - “buy a window made of plastic”. Then for normalized texts we have:Thus, the cosine distance should be calculated after preliminary processing of the text.
results
The optimizer development team and I tested the metrics discussed above on the statistics collected in our clients' advertising accounts. Various topics were considered, such as: real estate, automobiles, medicine, etc. Since the Calltouch service database contains data on more than 10,000 customers, we had more than enough data to conduct reliable tests with metrics. The table shows the averaged variance metrics calculated by clustering key phrases using various metrics.
These key phrases were selected as the clustering core for which there was at least one conversion and the number of clicks in the last 28 dayswhich satisfies the ratio:Where - The conversion rate of the campaign to which the keyword phrase belongs.
It can be seen from the table that the classical pooling method has the greatest dispersion (which means its use leads to the least accurate forecast), while the use of any of the metrics for the similarity of phrases among themselves significantly reduces this indicator. The best metric for clustering was the cosine distance.
Conclusion
This article discusses a new approach to clustering key phrases based on text similarity. It is shown that this method significantly reduces the intra-cluster dispersion of the conversion coefficient, which significantly improves the accuracy of the conversion forecasting by keyword. The methods described in the article can be used to optimize even those phrases whose own statistics are not enough to make a decision on the optimal bid. The above methods for calculating the conversion rate are elements of the Calltouch conversion optimizer, which in practice shows high efficiency both on large projects and on accounts with a relatively small advertising budget.