Kubernetes success stories in production. Part 3: GitHub
We continue to talk about successful examples of using Kubernetes in production. The new case is completely fresh. Detailed information about him appeared only yesterday. And what is even more significant, we will talk about a major online service that every reader of the Habra probably works with in one way or another - GitHub.
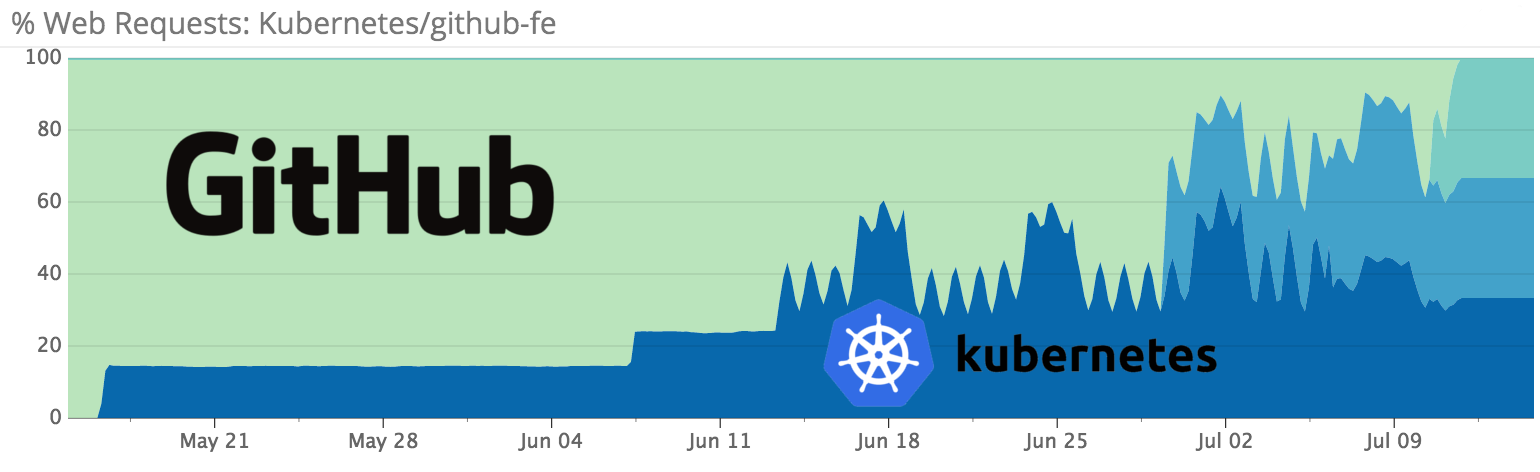
The fact that GitHub is engaged in the implementation of Kubernetes in its production became publicly known for the first time a month ago from the Twitter account of ARE’s SRE engineer at Aaron Brown. Then he briefly reported:
That is: "if you go on the pages of GitHub today, then you may be interested in the fact that from this day all web content is delivered using Kubernetes." Subsequent responses clarified that traffic to Kubernetes-managed Docker containers was switched for the web frontend and Gist service, and the API applications were in the process of migration. Containerization in GitHub affected only stateless applications, because things are more complicated with stateful products and "[for maintenance] MySQL, Redis and Git, we [already have extensive automation in GitHub]." The choice for Kubernetes was called optimal for GitHub employees with a note that “Mesos / Nomad is neither worse nor better - they are just different.”
There was little information, but GitHub engineers promised to talk about the details soon. And yesterday Jesse Newland, the senior SRE in the company, published the long-awaited note “ Kubernetes at GitHub ”, and just 8 hours before this publication on the hub, the already mentioned Aaron Brown spoke at the belated celebration of Kubernetes’s 2nd anniversary in Apprenda with the corresponding report:

Quote from Aaron’s report: ““ I dream of spending more time setting up hosts ”- no engineer, ever”
Until recent events, the main GitHub application written in Ruby on Rails has changed little over the past 8 years since its creation:
As GitHub (employees, number of features and services, user requests) grew, difficulties arose, and in particular:
Engineers and developers began a joint project to solve these problems, which led to the study and comparison of existing container orchestration platforms. When evaluating Kubernetes, they identified several benefits:
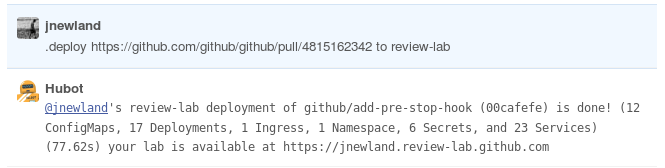
To organize the deployment of the main GitHub Ruby application using the Kubernetes-based infrastructure, the so-called Review Lab was created. It consisted of the following projects:
The bottom line is the chat-based interface for deploying the GitHub application for any pull request:
The laboratory implementation proved to be excellent, and by early June, the entire GitHub deployment had switched to a new scheme.
The next step in the implementation of Kubernetes was the construction of a very demanding infrastructure performance and reliability infrastructure for the company's main service in production - github.com.
The basic infrastructure of GitHub is the so-called metal cloud (a cloud running on physical servers in its own data centers). Of course, Kubernetes needed to be run taking into account the specifics. For this, the company's engineers again implemented a number of supporting projects:
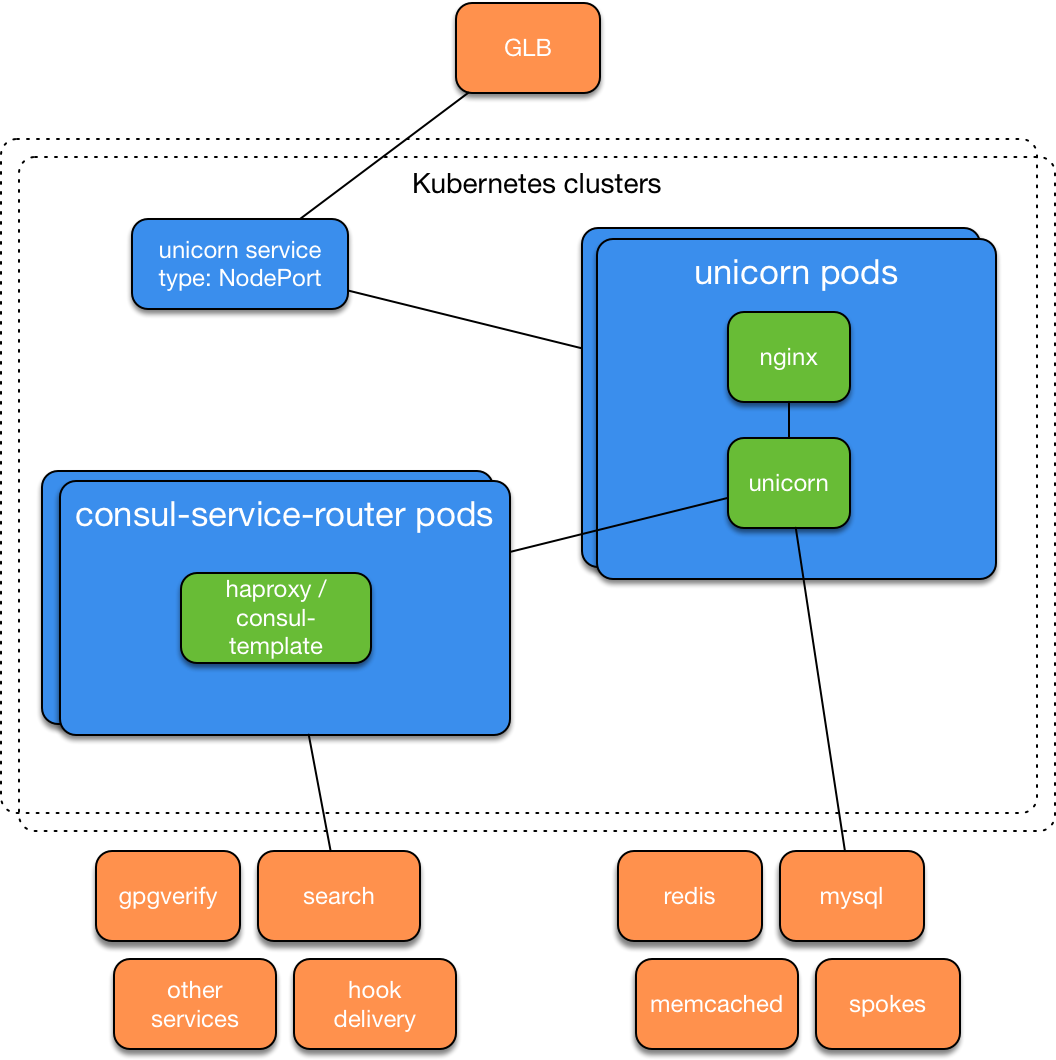
The result is a Kubernetes cluster on iron servers, which passed internal tests and in less than a week began to be used for migration from AWS. After creating additional such clusters, GitHub engineers launched a copy of the combat github.com on Kubernetes and (using GLB) offered their employees a button to switch between the original installation of the application and the version in Kubernetes. The architecture of the services was as follows:
After fixing the problems discovered by the employees, the user traffic began to gradually switch to new clusters: first, 100 requests per second, and then 10% of all requests to github.com and api.github.com.
They were in no hurry to switch from 10% to 100% of the traffic. Partial load tests showed unexpected results: the failure of one Kubernetes apiserver host had a negative impact on the availability of available resources in general - the reason, “apparently”, was related to the interaction between different clients connecting to the apiserver (calico-agent, kubelet, kube -proxy, kube-controller-manager), and the behavior of the internal load balancer during the fall of the apiserver node. Therefore, GitHub decided to run the main application on several clusters in different places and redirect requests from problem clusters to working ones.
By mid-July of this year, 100% of GitHub's production traffic was redirected to Kubernetes-based infrastructure.
One of the remaining problems, according to the company's engineer, is that sometimes during heavy loads on some Kubernetes nodes a kernel panic occurs, after which they reboot. Although outwardly this is not noticeable to users, the SRE-team has a high priority in finding out the reasons for this behavior and eliminating them, and the kernel panic (through
First information
The fact that GitHub is engaged in the implementation of Kubernetes in its production became publicly known for the first time a month ago from the Twitter account of ARE’s SRE engineer at Aaron Brown. Then he briefly reported:
That is: "if you go on the pages of GitHub today, then you may be interested in the fact that from this day all web content is delivered using Kubernetes." Subsequent responses clarified that traffic to Kubernetes-managed Docker containers was switched for the web frontend and Gist service, and the API applications were in the process of migration. Containerization in GitHub affected only stateless applications, because things are more complicated with stateful products and "[for maintenance] MySQL, Redis and Git, we [already have extensive automation in GitHub]." The choice for Kubernetes was called optimal for GitHub employees with a note that “Mesos / Nomad is neither worse nor better - they are just different.”
There was little information, but GitHub engineers promised to talk about the details soon. And yesterday Jesse Newland, the senior SRE in the company, published the long-awaited note “ Kubernetes at GitHub ”, and just 8 hours before this publication on the hub, the already mentioned Aaron Brown spoke at the belated celebration of Kubernetes’s 2nd anniversary in Apprenda with the corresponding report:
Quote from Aaron’s report: ““ I dream of spending more time setting up hosts ”- no engineer, ever”
Why do Kubernetes on GitHub?
Until recent events, the main GitHub application written in Ruby on Rails has changed little over the past 8 years since its creation:
- On servers with Ubuntu configured with Puppet, the God process manager launched the Unicorn web server.
- For the deployment, Capistrano was used, which connected via SSH to each front-end server, updated the code and restarted the processes.
- When peak load exceeded available capacities, SRE engineers added new front-end servers using gPanel, IPMI, iPXE, Puppet Facter and Ubuntu PX-image in their workflow (read more about this here ) .
As GitHub (employees, number of features and services, user requests) grew, difficulties arose, and in particular:
- some teams needed to “extract” from large services a small part of their functionality for a separate launch / deployment;
- the growth in the number of services led to the need to support many similar configurations for dozens of applications (more time was spent on server support and provisioning);
- Deployment of new services (depending on their complexity) took days, weeks or even months.
Over time, it became apparent that this approach does not provide our engineers with the flexibility that was necessary to create a world-class service. Our engineers needed a self-service platform that they could use to experiment with new services, deploy and scale them. In addition, it was necessary for the same platform to meet the requirements of the main Ruby on Rails application, so that engineers and / or robots could respond to changes in the load, allocating additional computing resources in seconds, rather than hours, days, or longer.
Engineers and developers began a joint project to solve these problems, which led to the study and comparison of existing container orchestration platforms. When evaluating Kubernetes, they identified several benefits:
- Active Open Source community supporting the project;
- positive experience of the first launch (the first deployment of the application in a small cluster took only a few hours);
- extensive information on the experience of the authors of Kubernetes, which led them to the existing architecture.
Deployment with Kubernetes
To organize the deployment of the main GitHub Ruby application using the Kubernetes-based infrastructure, the so-called Review Lab was created. It consisted of the following projects:
- Kubernetes cluster running in the AWS VPC cloud and managed with Terraform and kops.
- A set of integration tests on Bash, carrying out checks on BP e variables clusters Kubernetes, which are actively used at the beginning of the project.
Dockerfilefor the application.- Improvements to the internal continuous integration platform (CI) to support the assembly of containers and their publication in the registry.
- YAML views of 50+ resources used by Kubernetes.
- Improvements in the internal deployment application for “forwarding” Kubernetes resources from the repository to the Kubernetes namespace and creating Kubernetes secrets (from the internal storage).
- A service based on HAProxy and consul-template for redirecting traffic from Unicorn hearths to existing services.
- A service that forwards alarm events from Kubernetes to an internal error management system.
- The kube-me service, which is compatible with chatops-rpc and provides chat users with limited access to kubectl commands.
The bottom line is the chat-based interface for deploying the GitHub application for any pull request:
The laboratory implementation proved to be excellent, and by early June, the entire GitHub deployment had switched to a new scheme.
Kubernetes for infrastructure
The next step in the implementation of Kubernetes was the construction of a very demanding infrastructure performance and reliability infrastructure for the company's main service in production - github.com.
The basic infrastructure of GitHub is the so-called metal cloud (a cloud running on physical servers in its own data centers). Of course, Kubernetes needed to be run taking into account the specifics. For this, the company's engineers again implemented a number of supporting projects:
- As a network provider, we chose Calico, which "out of the box provided the necessary functionality for quickly deploying a cluster in mode
ipip." - Repeated ("at least a dozen times") reading of Kubernetes the hard way helped to assemble several manually maintained servers into a temporary Kubernetes cluster, which successfully passed the integration tests used for existing AWS clusters.
- Create a small utility that generates CA and configuration for each cluster in a format recognized by the Puppet and secret storage systems used.
- Puppetization of the configuration of two roles (Kubernetes node and Kubernetes apiserver).
- Creating a service (in Go language) that collects container logs, adds metadata in key-value format to each line and sends them to the syslog for the host.
- Adding Kubernetes NodePort Services support to load balancing ( GLB ).
The result is a Kubernetes cluster on iron servers, which passed internal tests and in less than a week began to be used for migration from AWS. After creating additional such clusters, GitHub engineers launched a copy of the combat github.com on Kubernetes and (using GLB) offered their employees a button to switch between the original installation of the application and the version in Kubernetes. The architecture of the services was as follows:
After fixing the problems discovered by the employees, the user traffic began to gradually switch to new clusters: first, 100 requests per second, and then 10% of all requests to github.com and api.github.com.
They were in no hurry to switch from 10% to 100% of the traffic. Partial load tests showed unexpected results: the failure of one Kubernetes apiserver host had a negative impact on the availability of available resources in general - the reason, “apparently”, was related to the interaction between different clients connecting to the apiserver (calico-agent, kubelet, kube -proxy, kube-controller-manager), and the behavior of the internal load balancer during the fall of the apiserver node. Therefore, GitHub decided to run the main application on several clusters in different places and redirect requests from problem clusters to working ones.
By mid-July of this year, 100% of GitHub's production traffic was redirected to Kubernetes-based infrastructure.
One of the remaining problems, according to the company's engineer, is that sometimes during heavy loads on some Kubernetes nodes a kernel panic occurs, after which they reboot. Although outwardly this is not noticeable to users, the SRE-team has a high priority in finding out the reasons for this behavior and eliminating them, and the kernel panic (through
echo c > /proc/sysrq-trigger) call has already been specifically added to tests that test fault tolerance . Despite this, the authors are generally satisfied with the experience gained and are going to conduct more migrations to such an architecture, as well as begin experiments with the launch of stateful services in Kubernetes.Other articles from the cycle
- “ Kubernetes success stories in production. Part 1: 4,200 hearths and TessMaster on eBay . ”
- “ Kubernetes success stories in production. Part 2: Concur and SAP . "
- “ Kubernetes success stories in production. Part 4: SoundCloud (authors Prometheus) . "
- “ Kubernetes success stories in production. Part 5: Monzo Digital Bank. ”
- “ Kubernetes success stories in production. Part 6: BlaBlaCar . "
- “ Kubernetes success stories in production. Part 7: BlackRock . "
- “ Kubernetes success stories in production. Part 8: Huawei . "
- “ Kubernetes success stories in production. Part 9: CERN and 210 K8s clusters. ”
- “ Kubernetes success stories in production. Part 10: Reddit . "