Jira against chaos in development: how not to lose tasks

In a previous article, I told you what add-ons for Jira we made so that the working flow becomes as convenient as possible, and the ticket is exhaustively informative. In today's article, we will solve another problem.
Given:
- You develop and support a complex software product that runs on multiple clients.
- you have several engineering teams (backend, IT Ops, iOS, Android, web, etc.) that work independently from each other with separate backlogs;
- you have several product lines, that is, roughly speaking, one product manager leads several projects in his own direction, another manager - in his own way;
- your engineering teams are functional, that is, they are not allocated to separate product areas, but solve the tasks of all units at once, serving a certain part of the technological stack;
- and of course you use Jira!
Problems:
- process participants do not understand what engineering pieces the feature consists of and what else needs to be done on the project at the moment;
- engineering teams work on the same project asynchronously: one team can finish its part a month ago, and the second can not even start its own, because they forgot about its piece in the stream of more important tasks.
There is an obvious problem with the transparency of the development process. When there are a lot of projects and directions, the need for some kind of magical instrument that eliminates chaos and gives a clear picture is especially acute. Unfortunately, our experience shows that the standard features of Jira do not fully cope with this.
Is that familiar? Let's think about what we can do about it.
Project structure
I will analyze the problem using the development example in Badoo. So how is the project work? What stages does the project go through? What pieces does a typical new feature consist of requiring the participation of several teams?
Idea and design
The product manager (PM), having come up with what can be improved in the product, creates a PROD ticket with the type Project in Jira. The description of this ticket consists of a single link to a page in Confluence (an analogue of the Atlassian Wiki that integrates with Jira). This page we call PRD (Product Requirements Document). It is a key element of development. In fact, this is a detailed description of what remains to be done in the framework of the project.
Typical PRD Structure
- Goals.
It briefly describes what we want to achieve by implementing the project (increasing profits, expanding coverage, other metrics that we plan to influence, etc.). - Description.
This is the largest part of PRD. The whole business logic of the feature is described here, all possible cases are considered. Design elements are also placed here (how the user should see the feature at each stage of interaction with it). It also describes all tokens that can be shown to the user. - A / B test requirements.
We launch almost all new features after the A / B test in order to be able to check the impact of the new functionality on a small group of users (after all, it can be negative). This section describes all the possible test groups and the differences in their logic for the user. - Statistics requirements.
Here it is recorded which user actions and business indicators should be monitored (button presses, promo screen impressions, etc.).
When creating this document, PM works closely with the designer. For this, another PROD ticket with the Design type is created. In it, the designer places layouts, icon sets, etc. These elements are then inserted into the PRD for clarity, and are also used by engineering teams in development.
Having written the document, PM submits it for public discussion. Usually other PMs as well as leads from engineering teams participate in the conversation. The discussion is directly in the comments on PRD. This is convenient, because the correspondence history remains, and all interested participants receive notifications when new comments appear. Based on the discussion, agreed changes are made to the original PRD.
When all the nuances are clarified, the initial PROD ticket is translated into the backlog of pending development. After that, once a week, the product team sorts this backlog according to priority in accordance with the goals of the company, the estimated exhaust and the complexity of the implementation. The projects recognized as the most promising, move on to the next stage - decomposition. For this, a special MAPI ticket (Mobile API) is created for the team of system architects.
It is important to note here that in order to more quickly create tickets related to the project, as well as to eliminate the human factor (they forgot something, incorrectly linked or marked it up), we automated this process. So, for example, the root ticket of the project in the header has two additional buttons.
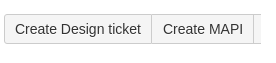
The first creates a ticket for designers, the second for system architects. In this case, new tickets are automatically filled with the necessary attributes: the correct labels, a link to PRD, a description template, and most importantly - are linked to each other.
This flow optimization is implemented based on the Jira ScriptRunner plugin , which I wrote about in a previous article .
Decomposition
Having received a new MAPI ticket with a PRD attached to it, system architects decide:
- which part of the logic should be implemented on the server side, and which part on the client side;
- what commands the client should send and what responses it should receive from the server;
- which tokens should be “wired” to the client, and which should come from the server side.
Quite often, at this stage, a change in PRD occurs. Architects delve deeper into implementation details than they did when discussing PRD. Therefore, it may turn out that in order to achieve the business goals of the project, it is possible, by abandoning part of the initial requirements, to significantly simplify development. We really appreciate this initiative.
You can learn more about how our team of architects works and see our API description from the report .
The results of the work of system architects are:
- The appearance of full technical documentation for the project (a description of the client-server interaction protocol with reference to the business logic cases described in PRD). Screenshot of part of the documentation of one of our currently inactive features
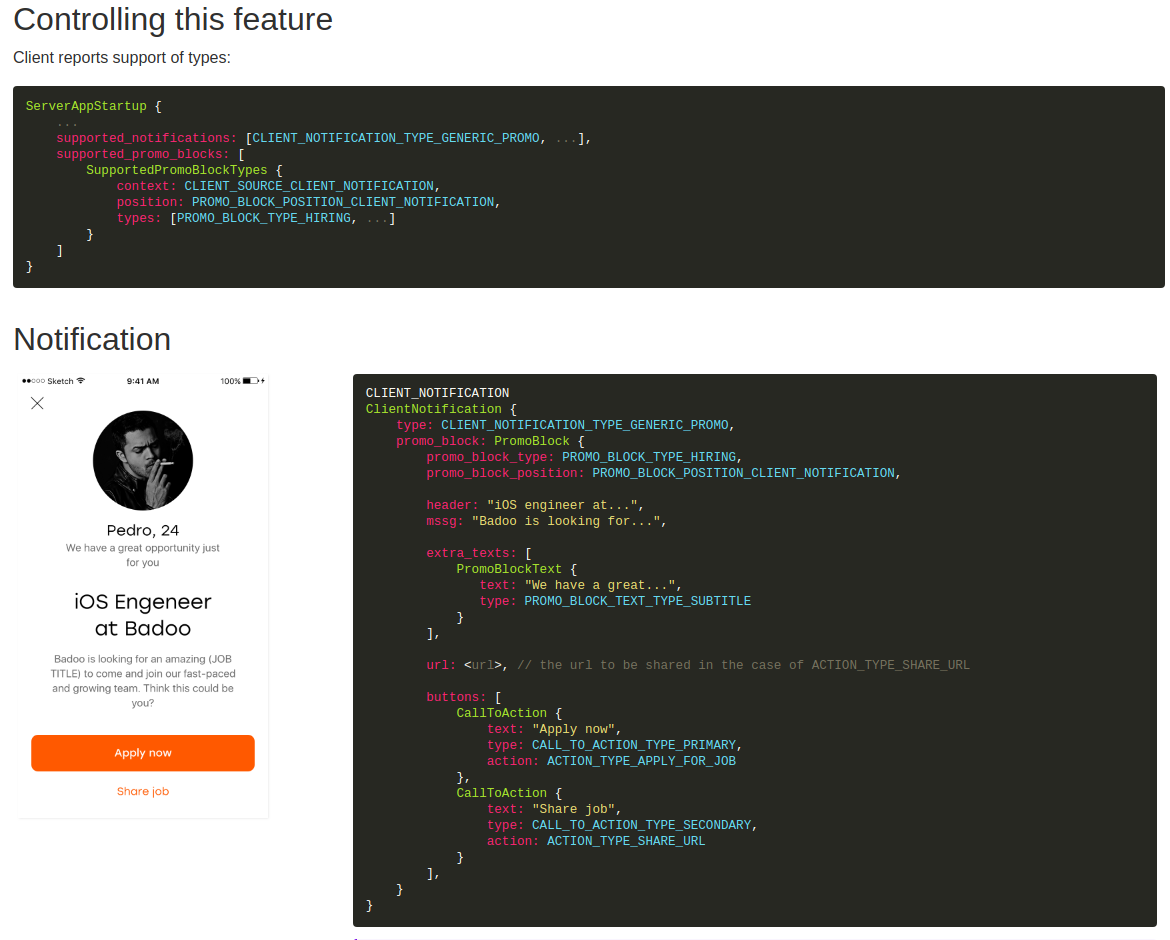
- Modified protocol (file in Google Protocol Buffers format) in the repositories. If new features or changes to old ones are needed to implement features, they will be available to developers of all teams.
- Tickets for development and localization teams. For this, we have a special interface that allows you to create the necessary tickets for all involved teams at once. It opens by a link from a MAPI ticket.
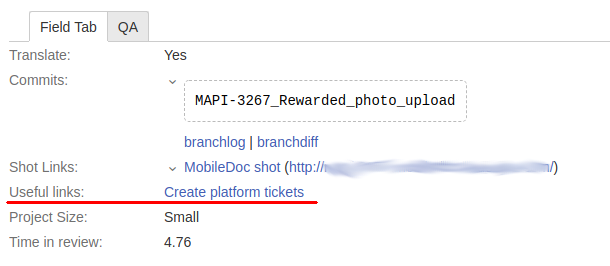
By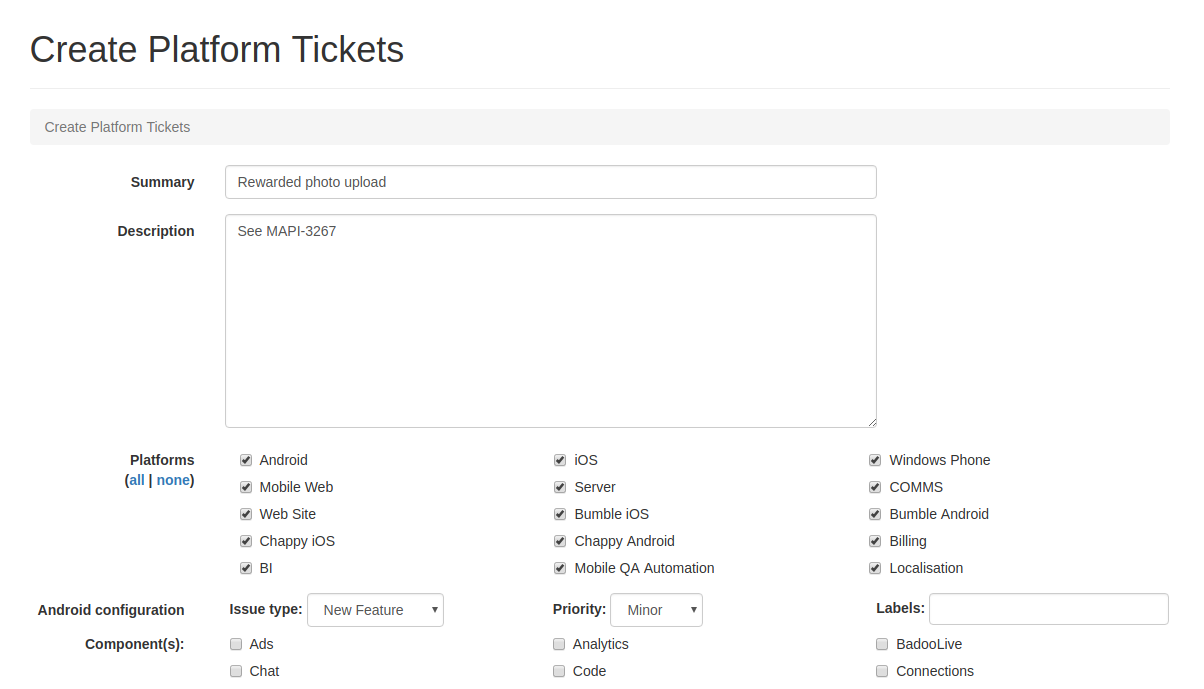
clicking on the button, the interface we created here opens: By clicking the button at the bottom of the form (it is not visible in the screenshot), the necessary tickets will appear that will be automatically linked to the original MAPI ticket. It is worth noting that all development teams work in our own Jira space (project): the backend team is in SRV, the Android team is in AND, the web team is on the Web, etc.
The interface is based on the Jira REST API.
Thus, the structure of the project can be depicted as the following diagram:
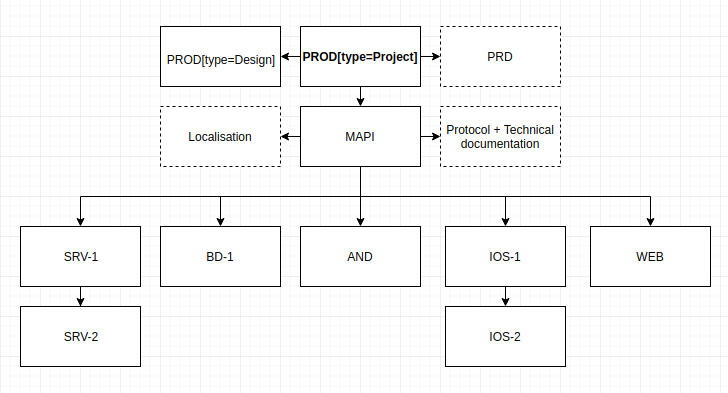
Development and launch
In the general case, all teams can work on a project in parallel, touching only at the final stage of integration, that is, client teams do not have to wait for a finished server to do their part. Since the interaction protocol is described in detail, during development, you can safely emulate the expected server response and debug client logic. Moreover, the server does not need a client during development - the server programmer simply implements the protocol and covers it with tests, emulating client requests.
Typically, a feature is launched in the following scenario:
- The server is the first to lay out its part of the functionality, covered by the feature-flag, in production. Thus, this logic remains idle until one of the clients starts sending this feature-flag.
- Client teams before release in production test their part of the functionality already on the “battle” server.
- As soon as ready, different clients are released, start sending the desired feature-flag and receiving a new server response.
The possibility of synchronous work on the project is a huge plus, which can significantly increase the development efficiency. But here lies the risk: some teams can “write to the table,” that is, do their part of the work, which will never be in demand by other project participants. There may be several reasons:
- different priorities for development teams; problems usually do not arise when working on projects that are super important for the company (they are all well-known and difficult to forget about), but less important ones can be placed in the local backlog of a separate team in the last places;
- project management error: the manager can simply forget to correctly prioritize the tasks of the development team, that is, its participants will not even know that the ticket should be taken into development as soon as possible.
How to level these problems? How to make sure that the pieces of the project are not lost, and the teams pay due attention to priority projects?
Jira Standard Features
What can the standard Jira functionality offer the project manager to solve these problems? Not so much:
- Filters
- kanban boards.
Filters
The filter allows you to see a linear list of tickets received for an arbitrary JQL query. This tool is very convenient for servicing the backlog of one team, but I don’t know how to use it for high-quality project management, distributed across different teams. The maximum that a manager can do is to display a prioritized list of root PROD tickets, and then you need to go into each one, looking at the linked tickets. But this is extremely inconvenient and long, especially considering that the hierarchy of links can be multi-story. Moreover, the development team can create several additional tickets to solve the initial task, and their status must also be monitored.
Kanban boards
For those who do not know how this works in Jira, I’ll explain. In general, this is a list of tasks based on a specific filter, grouped into three columns: “Backlog”, “Tasks in development”, “Completed tasks”. The interface allows you to increase the priority of tasks by simply dragging a ticket in the list with the mouse. At the same time, the Rank property changes , by which you can then sort tickets in your filters.
Here we already have much more room for using the tool in the context of the task at hand. PM can create a filter that selects all the tasks of all departments in the desired direction. This can be done, for example, by automatically placing tickets with the corresponding labels. I remind you that all the key project tickets for our project are created using the appropriate tools. Therefore, automatically copying the necessary labels of the root PROD-ticket to all derivative tickets is a trivial technical task.
We use kanban boards to form and control backlogs of engineering teams. Using the Swimlanes tool, a board can be grouped into projects that correspond to engineering teams. Thus, using this tool, PM can monitor the progress of its projects in the context of different teams, as well as prioritize team tickets.
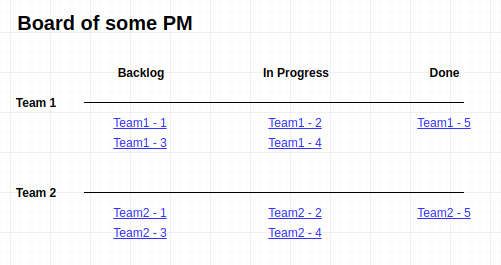
The scheme of a product kanban board on which tickets for PM projects are grouped by teams.
The problem is that the tool does not provide an easy way to group tickets by source PROD tickets, that is, by features: I want to monitor the progress of each project individually in all engineering teams .
Excel
The most obvious solution is to use spreadsheets. After all, you can do everything as you like: convenient, beautiful, informative. Something like this:
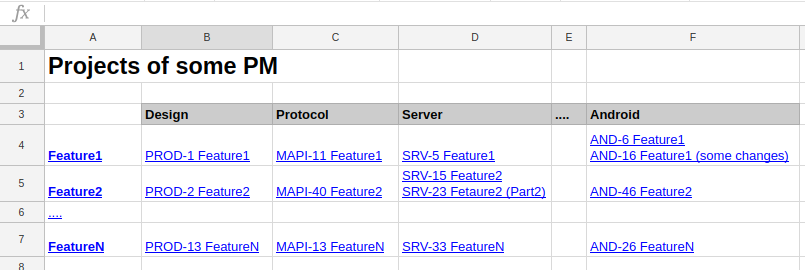
You can see the general scope of work for each project in one place. You can make various notes, cross out completed tickets, etc. Everything is good here, except for one bold but: maintaining the relevance of such tables is extremely difficult. Ticket statuses are constantly changing, new ones are being created. Manually make all changes? You can spend it all day. But we are for efficiency, right?
“And let's cross!”
Why do not we use the convenience and clarity of spreadsheets by adding automatic synchronization with Jira? We have all the possibilities for this! So we decided to create an additional tool based on the Jira REST API, which automatically maintains the current state of information and has a convenient interface for us.
Tool requirements were as follows:
- the ability to create lists of projects and tickets derived from them according to arbitrary JQL queries (this is necessary so that any PM can create its own space (unit) in which it will only see its projects and manage them);
- new projects in Jira should automatically appear in the interface;
- new tickets in the project should automatically appear in the interface (that is, if the development team decides that more tickets are needed to implement the feature, then the PM will immediately see this in the interface);
- depending on the status of tickets, the colors of the cells of the table should change (for quick understanding by the participants of the project status)
- the ability to sort projects (to properly prioritize them);
- automatic hiding of completed projects two weeks after completion.
The PM starts working with the tool, creating its own space (unit), indicating its name and JQL query:
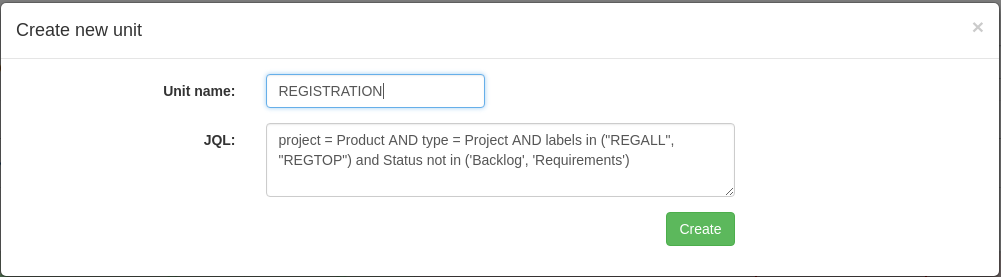
Next, a request is made to Jira to get a list of projects for the specified JQL query. Also using links in Jira are all derived tickets of engineering teams. The result is something like this table:
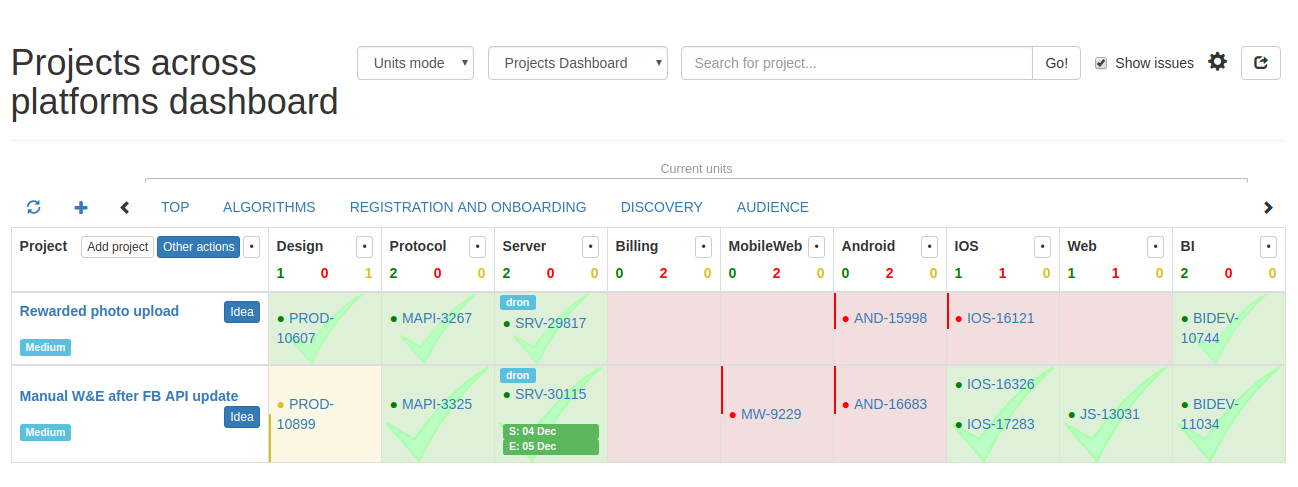
Above are links for switching between units.
Table rows are the unit's root PROD tickets. In the cells we see the tasks of the project for specific engineering departments. Filling takes place automatically subject to the rules for linking project tickets to each other. Completed stages are marked in green, unstarted in red, and current in yellow.
Links lead to tickets to Jira. You can also get brief information about the ticket by hovering over the link:
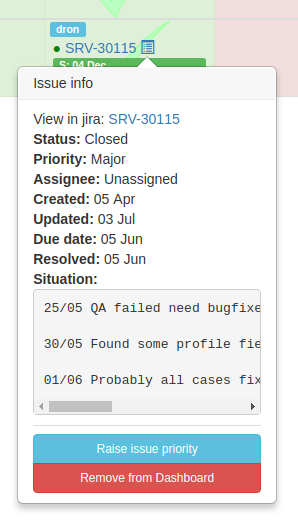
With a frequency of once every few minutes, a request is made to the Jira API to obtain an up-to-date list of projects for all units, to synchronize the list of derivatives of tickets, as well as their current statuses.
Sorting is carried out by simply dragging and dropping the desired project into the desired place in the list:

It is important to note that not only product managers, but also leads of engineering teams work with this tool in Badoo. After all, it is important for everyone to understand what is happening in the product areas, which teams have advanced in implementing important projects for the company more than others, and which are behind.
conclusions
Jira "out of the box" provides powerful functionality for managing the project structure and the relationship between tickets. There are also plugins that significantly expand the capabilities of JQL (for example, they allow you to use links between tickets and their types to filter tickets). In our case, we lacked only the ability to visualize everything as we needed.
Fortunately, Jira allows creating additional convenient tools based on its API, adapted to the company's business processes. So, for example, we were able to solve the problem that arose with the transparency of conducting projects in a dozen product areas, with a little effort and using the additional features of this task tracker. It would be interesting to read in the comments if you tried to make such add-ons at your place or found other solutions for your tasks.
Thank you all for your attention!