What does YouTube mean
- Tutorial
At the dawn of machine learning, most of the solutions looked very strange, isolated and unusual. Today, many ML algorithms are already lining up in the usual for the programmer set of frameworks and toolkits, with which you can work without going into details of their implementation.
By the way, I am an opponent of such a superficial approach, but for my colleagues I would like to show that this industry is moving by leaps and bounds and there is nothing difficult to apply its achievements in production projects.
For example, I will show how you can help a user find the right video among hundreds of others in our workflow service.
In my project, users create and exchange hundreds of different materials: text, pictures, videos, articles, documents in various formats.
Search for documents is quite simple. But what to do with the search for multimedia content? For a full-fledged user service, you must be obliged to fill out a description, give the name of a video or a picture, several tags will not hurt. Unfortunately, not everyone wants to spend time on such content improvements. Typically, the user uploads a link to youtube, reports that this is a new video and presses save. What can the service do with such “gray” content? The first idea is to ask YouTube? But YouTube is also filled with users (often the same user). Often the video may not be from the Youtube service.
So I got the idea to teach our service to “listen” to the video and independently “understand” what it is about.
I admit, this idea is not new, but today for its implementation it is not necessary to have a staff of ten Data Scientists, two days are enough and some hardware resources.
Formulation of the problem
Our microservice, let's call it Summarizer , should:
- Download video from media service;
- Extract audio track;
- Listen to the audio track, actually Speech to text;
- Find 20 keywords;
- Select one sentence from the text that would maximally reveal the essence of the video;
- All results are sent to the content service;
We will entrust the implementation of Python , so there is no need to integrate with ready-made ML solutions.
Step one: audio to text.
First, install all the necessary components.
pip3 install wave numpy tensorflow youtube_dl ffmpeg-python deepspeech nltk networkx
brew install ffmpeg wget
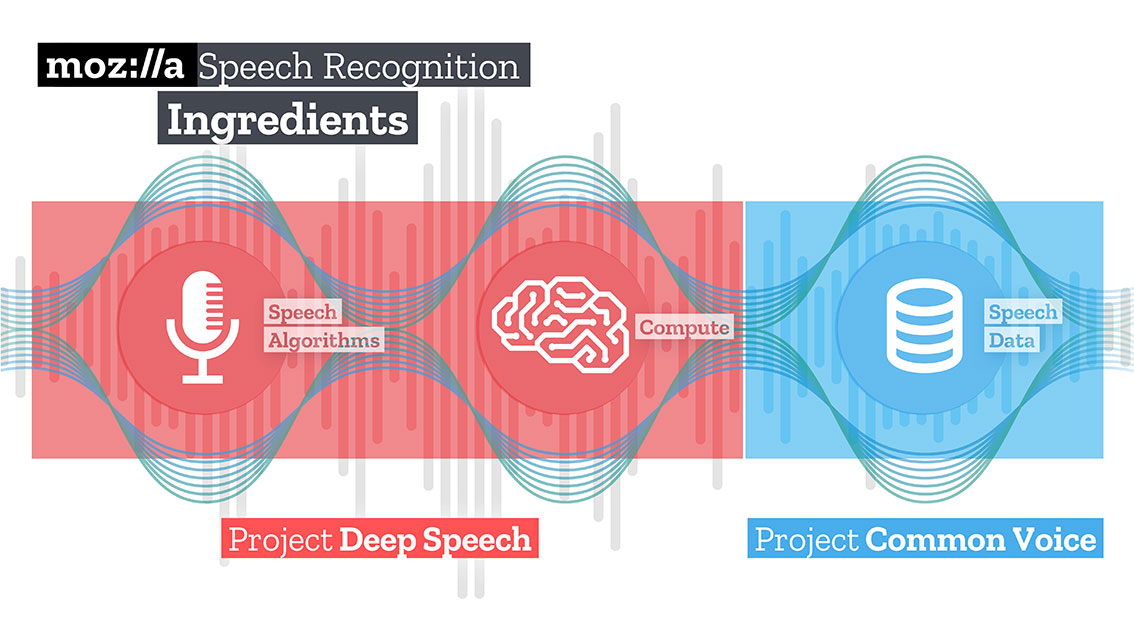
Next, download and unpack the trained model for Speech to text solutions from Mozilla - Deepspeech.
mkdir /Users/Volodymyr/Projects/deepspeech/
cd /Users/Volodymyr/Projects/deepspeech/
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.3.0/deepspeech-0.3.0-models.tar.gz
tar zxvf deepspeech-0.3.0-models.tar.gz
The Mozilla team created and trained a fairly good solution that, using TensorFlow, can turn long audio clips into large pieces of text with high quality. Also, TensorFlow allows you to work out of the box on both the CPU and the GPU.
Our code will start by downloading content. This will help him a great library youtube-dl , which has a built-in postprocessor that can convert video to the desired format. Unfortunately, the postprocessor code is a bit limited, it does not know how to do resampling, so we will help it.
At the entrance of Deepspeech you need to submit an audio file with a mono track and 16K sample rate. To do this, you need to re-process our received file.
_ = ffmpeg.input(youtube_id + '.wav').output(output_file_name, ac=1, t=crop_time, ar='16k').overwrite_output().run(capture_stdout=False)
In the same operation, we can limit the duration of our file by passing the additional parameter “t”.
Download deepspeech model.
deepspeech = Model(args.model, N_FEATURES, N_CONTEXT, args.alphabet, BEAM_WIDTH)
Using the wave library, we extract frames in the np.array format and transfer them to the input of the deepspeech library.
fin = wave.open(file_name, 'rb')
framerate_sample = fin.getframerate()
if framerate_sample != 16000:
print('Warning: original sample rate ({}) is different than 16kHz. Resampling might produce erratic speech recognition.'.format(framerate_sample), file=sys.stderr)
fin.close()
returnelse:
audio = np.frombuffer(fin.readframes(fin.getnframes()), np.int16)
audio_length = fin.getnframes() * (1/16000)
fin.close()
print('Running inference.', file=sys.stderr)
inference_start = timer()
result = deepspeech.stt(audio, framerate_sample)
After a while, proportional to your hardware resources, you get the text.
Step Two: Search for “Meaning”
To search for words describing the resulting text, I will use the method of graphs. This method is based on the distance between the sequences. First we find all the “unique” words, imagine that these are the vertices of our graph. After, going through the text "window" of a given length, we find the distance between the words, they will be the edges of our gaf. Vertices added to a graph can be limited to syntax filters that select only lexical units of a specific part of speech. For example, only nouns and verbs to be added to a graph can be considered. Therefore, we will build potential edges based only on the relationship that can be established between nouns and verbs.
The score associated with each vertex is set to the initial value of 1, and the ranking algorithm is launched. The ranking algorithm is “voting” or “recommendation.” When one vertex is connected with another, it “votes” for this (connected) vertex. The higher the number of votes cast for the top, the higher the importance of this top. Moreover, the importance of a top for voting determines how important voting itself is, and this information is also taken into account by the ranking model. Consequently, the assessment associated with the peak is determined on the basis of the votes cast for it, and the evaluation of the peaks giving these votes.
Suppose we have a graph G = (V, E), described by vertices V and edges E. For a given vertex V, let there be a set of vertices E that are connected with it. For each vertex Vi, there are In (Vi) vertices associated with it, and Out (Vi) vertices with which the vertex Vi is associated. Thus, the weight of a vertex Vi can be represented by the formula.
S ( V i ) = ( 1 - d ) + d ∗ ∑ j ∈ I n ( V i ) 1∣ O u t ( V j ) ∣ ∗S(Vj)
Where d is the attenuation / suppression factor, taking values from 1 to 0.
The algorithm must iterate the graph several times to get approximate estimates.
After obtaining a rough estimate for each vertex in the graph, the vertices are sorted in order of decreasing grade. Vertices that appear at the top of the list will be our searched keywords.
The most relevant sentence in the text is found by finding the average of the addition of the estimates of all words in the sentence. That is, we add up all the estimates and divide by the number of words in the sentence.
iMac:YoutubeSummarizer $ cd /Users/Volodymyr/Projects/YoutubeSummarizer ; env "PYTHONIOENCODING=UTF-8""PYTHONUNBUFFERED=1" /usr/local/bin/python3 /Users/Volodymyr/.vscode/extensions/ms-python.python-2018.11.0/pythonFiles/experimental/ptvsd_launcher.py --default --client --host localhost --port 53730 /Users/Volodymyr/Projects/YoutubeSummarizer/summarizer.py --youtube-id yA-FCxFQNHg --model /Users/Volodymyr/Projects/deepspeech/models/output_graph.pb --alphabet /Users/Volodymyr/Projects/deepspeech/models/alphabet.txt --lm /Users/Volodymyr/Projects/deepspeech/models/lm.binary --trie /Users/Volodymyr/Projects/deepspeech/models/trie --crop-time 900
Done downloading, now converting ...
ffmpeg version 4.1 Copyright (c) 2000-2018 the FFmpeg developers
built with Apple LLVM version 10.0.0 (clang-1000.11.45.5)
configuration: --prefix=/usr/local/Cellar/ffmpeg/4.1 --enable-shared --enable-pthreads --enable-version3 --enable-hardcoded-tables --enable-avresample --cc=clang --host-cflags= --host-ldflags= --enable-ffplay --enable-gpl --enable-libmp3lame --enable-libopus --enable-libsnappy --enable-libtheora --enable-libvorbis --enable-libvpx --enable-libx264 --enable-libx265 --enable-libxvid --enable-lzma --enable-opencl --enable-videotoolbox
libavutil 56. 22.100 / 56. 22.100
libavcodec 58. 35.100 / 58. 35.100
libavformat 58. 20.100 / 58. 20.100
libavdevice 58. 5.100 / 58. 5.100
libavfilter 7. 40.101 / 7. 40.101
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 3.100 / 5. 3.100
libswresample 3. 3.100 / 3. 3.100
libpostproc 55. 3.100 / 55. 3.100
Guessed Channel Layout for Input Stream #0.0 : stereo
Input #0, wav, from 'yA-FCxFQNHg.wav':
Metadata:
encoder : Lavf58.20.100
Duration: 00:17:27.06, bitrate: 1536 kb/s
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 48000 Hz, stereo, s16, 1536 kb/s
Stream mapping:
Stream #0:0 -> #0:0 (pcm_s16le (native) -> pcm_s16le (native))
Press [q] to stop, [?] forhelp
Output #0, wav, to 'result-yA-FCxFQNHg.wav':
Metadata:
ISFT : Lavf58.20.100
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 16000 Hz, mono, s16, 256 kb/s
Metadata:
encoder : Lavc58.35.100 pcm_s16le
size= 28125kB time=00:15:00.00 bitrate= 256.0kbits/s speed=1.02e+03x
video:0kB audio:28125kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.000271%
Loading model from file /Users/Volodymyr/Projects/deepspeech/models/output_graph.pb
TensorFlow: v1.11.0-9-g97d851f04e
DeepSpeech: unknown
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-12-14 17:42:03.121170: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Loaded model in 0.5s.
Loading language model from files /Users/Volodymyr/Projects/deepspeech/models/lm.binary /Users/Volodymyr/Projects/deepspeech/models/trie
Loaded language model in 3.17s.
Running inference.
Building top 20 keywords...
{'communicate', 'government', 'repetition', 'terrorism', 'technology', 'thinteeneighty', 'incentive', 'ponsibility', 'experience', 'upsetting', 'democracy', 'infection', 'difference', 'evidesrisia', 'legislature', 'metriamatrei', 'believing', 'administration', 'antagethetruth', 'information', 'conspiracy'}
Building summary sentence...
intellectually antagethetruth administration thinteeneighty understanding metriamatrei shareholders evidesrisia recognizing ponsibility communicate information legislature abaddoryis technology difference conspiracy repetition experience government protecting categories mankyuses democracy campaigns primarily attackers terrorism believing happening infection seriously incentive upsetting testified fortunate questions president companies prominent actually platform massacre powerful building poblanas thinking supposed accounts murdered function unsolved perverse recently fighting opposite motional election children watching traction speaking measured nineteen repeated coverage imagined positive designed together countess greatest fourteen attacks publish brought through explain russian opinion winking somehow welcome trithis problem looking college gaining feoryhe talking ighting believe happens connect further working ational mistake diverse between ferring
Inference took 76.729s for 900.000s audio file.
Results
The ideas that come to your mind today can be implemented much faster than three or four years ago. Try, experiment! I think that artificial intelligence is first of all the intelligence engineers who work with it.
The code is available in my Github repository .