50 shades of celery
You are here if you want to know how to tame a widely known framework called Pylery in Python-developer circles. And even if in your project Celery confidently performs the basic commands, then Fintech experience can open up uncharted sides to you. Because fintech is always Big Data, and with it the need for background tasks, batch processing, asynchronous API, etc.

The beauty of Oleg Churkin's story about Celery at Moscow Python Conf ++ in addition to detailed instructions on how to configure Celery under load and how to monitor it, is that you can borrow useful ideas.
About speaker and project: Oleg Churkin ( Bahusss ) has been developing Python-projects of various complexity for 8 years, he worked in many well-known companies: Yandex, Rambler, RBC, Kaspersky Labs. Now technid in fintech-stapard StatusMoney.
The project works with a large amount of financial user data (1.5 terabytes): accounts, transactions, merchants, etc. It runs up to a million tasks every day. Maybe someone will not find this number really large, but for a small startup on modest capacities this is a significant amount of data, and the developers had to face various problems on the way to a stable process.
Oleg told about the key points of the work:
And he shared a pair of project utilities that implement the missing functionality in Celery. As it turned out, in 2018 this could happen. Further, the text version of the report from the first person.
Problematics
It was necessary to solve the following tasks:
For background tasks include any types of notifications: email, push, desktop - all of this is sent to the background tasks the trigger. In the same way, a periodic update of financial data is launched.
In the background, various specific checks are performed, for example, checking a user for fraud. In financial startups, a lot of effort and attention is paid to data security , because we allow users to add their bank accounts to our system, and we can see all their transactions. Fraudsters can try to use our service for something bad, for example, to check the balance of a stolen account.
The last category of background tasks is maintenance tasks.: twist something, look, fix, zamonitory, etc.
To send notifications, only mass, batch processing is used . The large amount of data we receive from our users has to be calculated and processed in a certain way, incl. in batch mode.
The same concept includes the classic Extract, Transform, Load :
It's no secret that the asynchronous API can be done using simple polling requests: the frontend initiates the process on the backend, the backend runs the task, which periodically launches itself, pollit the results and updates the state in the database. The frontend shows the user this interactivity - the state is changing. This allows:
In our service, this is still enough, but in the future most likely it will be necessary to rewrite something else.
Requirements for tools
To realize these tasks, we had the following requirements for the tools:
Which tool to choose?
What are the options on the market in 2018 to solve these problems?
Once upon a time for less ambitious tasks, I wrote a convenient library that is still used in some projects. It is easy to operate and performs tasks in the background. But at the same time no brokers are needed (neither Celery, nor others), only the uwsgi application server , which has a spooler, is such a thing that runs as a separate worker. This is a very simple solution - all tasks are stored conditionally in files. For simple projects, this is enough, but for ours it was not enough.
Anyway, we looked at:
Promising Candidate 2018
Now I would draw your attention to Dramatiq . This is a library from the Celery adept, who learned all the disadvantages of Celery and decided to rewrite everything, only very beautifully. Advantages of Dramatiq:
Some time ago Dramatiq had problems with licenses: at first it was AGPL, then it was replaced with LGPL. But now you can try.
But in 2016, apart from Celery, there was nothing special to take. We liked its rich functionality, and then it ideally suited our tasks, because even then it was mature and functional:
Project Features
I'll tell you about our context so that the following story is clearer.
We use Redis as a message broker . I have heard many stories and rumors that Redis is losing messages, that he is not fit to be a message broker. This is not confirmed for the production experience, and as it turns out, Redis now works more efficiently than RabbitMQ (it is with Celery, at least, apparently, the problem is in the integration code with brokers). In version 4, the Redis broker was repaired, it really stopped losing tasks during restarts and works quite stably. In 2016, Celery was going to abandon Redis and concentrate on integration with RabbitMQ, but, fortunately, this did not happen.
In case of problems with Redis, if we need serious high availability, we will switch to Amazon SQS or Amazon MQ because we are using Amazon power.
We do not use result backend to store the results , because we prefer to store the results ourselves where we want, and check them as we want. We don't want Celery to do this for us.
We use the pefork pool , that is, process-workers, which create separate forks of processes for additional concurrency.
Unit of work
We will discuss the basic elements to bring up to date those who have not tried Celery, but are only going to. Unit of work for Celery is a challenge . I will give an example of a simple task that sends email.
Simple function and decorator:
The task launch is simple: either we call the function and the task is executed at runtime (send_email (email = "python@example.com")), or in a worker, that is, the same effect of the task in the background:
During two years of work with Celery under high loads, we derived good tone rules. There were a lot of rakes, we learned to bypass them, and I will share how.
Code design
There can be different logic in the task. In general, Celery helps you keep your puzzles in files or packages, or import them from somewhere. Sometimes it turns out a jumble of business logic in one module. In our opinion, here the correct approach from the point of view of the modularity of the application is to keep the minimum of logic in the task . We use puzzles only as “starters” of the code. That is, the task does not carry logic, but triggers the launch of code on the Background.
We extend all code to external classes that use some other classes. All tasks essentially consist of two lines.
Simple objects in the parameters
In the example above, a certain id is passed to the task. In all the tasks that we use, we transmit only small scalar data , id. We do not serialize Django models to transmit them. Even in ETL, when it comes from the external service of a large data blob, we first save it and then run a task that reads the entire blob by id and processes it.
If you do not do this, then we have seen very large spikes of consumed memory from Redis. The message starts to occupy more memory, the network is heavily loaded, the number of processed tasks (performance) drops. While the object reaches execution, the tasks become irrelevant, the object is already deleted. The data needed to be serialized - not everything is well serialized in JSON in Python. When we needed to retry tasks, we needed to quickly decide what to do with this data, receive them again, and run some checks on them.
Idempotent tasks
This approach is recommended by the Celery developers themselves. When re-running the code segment, no side-effects should occur, the result should be the same. This is not always easy to achieve, especially if there is interaction with many services, or two-phase commits.
But when you do everything locally, you can always check that the incoming data exists and is relevant, you really can do work on it, and use transactions. If a single task has a lot of queries into the database and something can go wrong at runtime - use transactions to roll back unnecessary changes.
backward compatibility
We had several interesting side effects with a deploe application. It doesn't matter what type of deployment you use (blue + green or rolling update), there will always be a situation when the old service code creates messages for the new worker code, and vice versa, the old worker receives messages from the new service code because it rolls out "first" and there the traffic went.
We caught mistakes and lost tasks until we learned how to maintain backward compatibility between releases.. Backward compatibility is that tasks should work safely between releases, no matter what parameters come into this task. Therefore, in all tasks we are now doing a "rubber" signature (** kwargs). When in the next release you need to add a new parameter, you will take it from ** kwargs in the new release, and in the old one you will not take it - nothing will break. As soon as the signature changes, but Celery does not know about it, it falls and gives an error that there is no such parameter in the task.
A more rigorous way to avoid such problems is the versioning of task queues between releases, but it is quite difficult to implement and we have left it in the backlog so far.
Timeouts
Problems may occur due to insufficient or incorrect timeouts.
Therefore, all our tasks are hung with timeouts, including global ones for all tasks, and timeouts are also set for each specific task.
Be sure to include: soft_limit_timeout and expires.
Expires is how much a task can live in a queue. It is necessary that tasks do not accumulate in queues in case of problems. For example, if we now want to report something to the user, but something has happened, and the task can be completed only tomorrow - this makes no sense, tomorrow the message will be irrelevant. Therefore, on the notice we have quite a small expires.
Note the use of eta (countdown) + visibility _timeout. The FAQ describes such a problem with Redis - the so-called visibility timeout at the Redis broker. By default, its value is one hour: if after an hour the worker doesn’t take the task to execution, then re-adds it to the queue. Thus, if the countdown is equal to two hours, after an hour the broker will find out that this task has not yet been completed, and will create another one the same. And in two hours two identical tasks will be executed.
Retry policy
For those tasks that can be repeated, or that can be performed with errors, we use the Retry policy. But we use it carefully so as not to overwhelm external services. If you quickly repeat the task without specifying the exponential backoff, then the external service, and maybe the internal one, can simply not withstand.
The parameters retry_backoff , retry_jitter and max_retries would be nice to specify explicitly, especially max_retries. retry_jitter is a parameter that allows you to add a little chaos so that tasks do not start repeating at the same time.
Memory leaks
In general, working with memory in Python is very controversial. You will spend a lot of time and nerves to understand why a leak occurs, and then it turns out that it is not even in your code. Therefore, always starting a project, put a memory limit on the worker : worker_max_memory_per_child.
This ensures that OOM Killer does not come one day, does not kill all workers, and you do not lose all tasks. Celery will restart the workers when needed.
The priority of the tasks
There are always tasks that need to be performed before everyone, faster than all - they must be completed right now! There are tasks that are not so important - let them be executed during the day. To do this, the task has a priority parameter . It works quite interestingly in Redis - a new queue is created with the name to which priority is added.
We use a different approach - separate workers for priorities , i.e. in the old manner, we create workers for Celery with different “importance”:
Celery multi start is a helper that helps to run the entire Celery configuration on one machine and from one command line. In this example, we create nodes (or workers): high_priority and low_priority, 2 and 6 - this is concurrency.
Two high_priority workers constantly process the urgent_notifications queue. No one else will take these workers, they will only read important tasks from the urgent_notifications lineup.
For unimportant tasks, there is a low_priority queue. There are 6 workers who receive messages from all other queues. We also subscribe to urgent_notifications low_priority workers so they can help if the high_priority workers do not cope.
We use this classic scheme to prioritize tasks.
Extract, Transform, Load
Most often, ETL looks like a chain of tasks, each of which receives input from the previous task.
In the example, three tasks. Celery has an approach to distributed processing and several useful utilities, including the chain function , which makes one such pipeline out of three such tasks:
Celery will disassemble the pipeline itself, perform the first task in order first, then transmit the received data to the second, the data that the second task returns, transfer to the third. So we implement simple ETL pipelines.
For more complex chains, you have to connect additional logic. But it is important to keep in mind that if this chain has a problem in one task, then the whole chain will fall apart . If you do not want this behavior, handle exception and continue execution, or stop the entire exception chain.
In fact, this chain inside looks like one big task, which contains all the tasks with all the parameters. Therefore, if you abuse the number of tasks in the chain, you get a very high memory consumption and slowing down the overall process.Creating chains of thousands of tasks is a bad idea.
Batch processing tasks
Now the most interesting thing: what happens when you need to send an email to two million users.
You write this function to bypass all users:
True, more often than not, the function will receive not only user id, but also flush the entire users table in general. For each user will run their own task.
There are several problems with this task:
I called it Task flood, on the chart it looks like this.
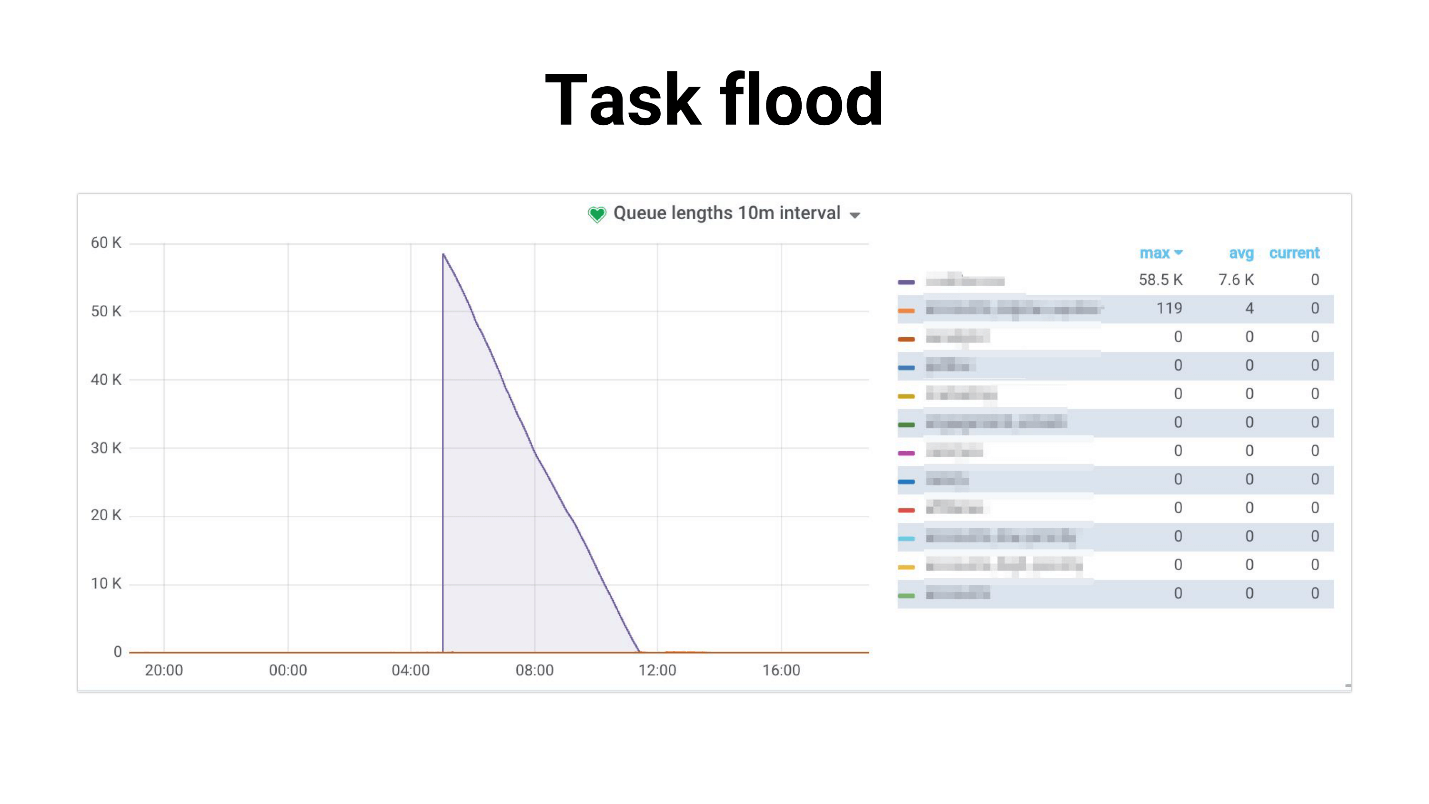
There is an influx of tasks that workers quietly begin to handle. The following happens if tasks use a master-replica, the whole project starts to just pop - nothing works. Below is an example from our practice, where DB CPU Usage was 100% several hours, we, frankly, managed to get scared.

The problem is that the system greatly degrades with the increase in the number of users. Task that deals with dispatching:
Task flooding occurs: tasks accumulate in queues and create a large load not only on internal services, but also on external ones.
We tried to reduce the competition of workers , it helps in some sense - reducing the load on the service. Or you can scale internal services . But this does not solve the problem of the generator problem, which still takes a lot on itself. And does not affect the dependence on the performance of external services.
Task generation
We decided to go the other way. Most often, we do not need to run all 2 million tasks right now. It is normal that sending notifications to all users will take, for example, 4 hours, if these letters are not so important.
We first tried using Celery.chunks :
This did not change the situation, because, despite the iterator, all user_id will be loaded into memory. And all workers receive chains of tasks, and although workers will have a little rest, we were not satisfied with this decision as a result.
We tried to set rate_limit on workers so that they process only a certain number of tasks per second, and find out that in fact the rate_limit specified for the task is rate_limit for a worker. That is, if you specify rate_limit for a task, this does not mean that the task will be executed 70 times per second. This means that the worker will perform it 70 times per second, and depending on what you have with the workers, this limit may change dynamically, i.e. real limit rate_limit * len (workers).
If the worker starts or stops, the total rate_limit changes. Moreover, if your tasks are slow, then the entire prefetch in the queue that the worker fills in will be clogged with these slow tasks. The worker looks like: “Oh, I have this task in rate_limit, I can’t do it anymore. And all the following tasks in the queue are exactly the same - let them hang! ”- and waits.
Chunkificator
In the end, we decided that we would write our own, and made a small library, which we called Chunkificator.
She accepts sleep_timeout and initial_chunk, and calls herself with a new chunk. Chunk is an abstraction either over integer lists, or over date or datetime lists. We pass chunk to a function that gets users only with that chunk, and runs tasks for that chunk only.
Thus, the task generator runs only the number of tasks that is needed, and does not consume a lot of memory. The picture has become so.

The highlight is the fact that we use sparse chunk, that is, we use instances in the database as a chunk id (some of them can be skipped, so there may be fewer tasks). As a result, the load turned out to be more uniform, the process became longer, but everyone is alive and well, the base is not strained.
Libraryimplemented for Python 3.6+ and available on GitHub. There is a nuance that I plan to fix, but for now, a pickle serializer is needed for a datetime chunk - many will not be able to do this.
A couple of rhetorical questions - where did all this information come from? How do we know that we had problems? How to find out that the problem will soon become critical and it is already necessary to begin to solve it?
The answer is, of course, monitoring.
Monitoring
I really like monitoring, I like to monitor everything and keep my finger on the pulse. If you do not keep your finger on the pulse, then you will constantly step on the rake.
Standard monitoring issues:
We tried several options. Celery has a CLI interface , it is rich enough and gives:
But it’s difficult to really monitor something. It is better suited for local delights, or if you want to change some rate_limit at runtime.
NB: you need access to a production broker to use the CLI interface.
Celery Flower allows you to do the same thing as the CLI, only through a web interface, and then not all. But it builds some simple graphics and allows you to change settings on the fly.
In general, Celery Flower is suitable in order to just see how everything works, in small setups. In addition, it supports the HTTP API, that is, it is convenient if you are writing automation.
But we stopped at Prometheus. Took the current exporter: fixed memory leaks in it; added metrics for exception types; added metrics for the number of messages in the queues; integrated with alerts in Grafana and rejoice. It is also posted on GitHub, you can see here .
Examples in Grafana

The above statistics on all exceptions: what exceptions for which tasks. Below is the time to complete tasks.

What is missing in Celery?
This is a spreading framework, it has a lot of things, but we are missing! There are not enough small features, such as:
findings
Despite the fact that Celery is a framework that many people use in production, it consists of 3 libraries - Celery, Kombu and Billiard. All three of these libraries are being developed by the developers, and they can release one dependency and break your build.
Therefore, I hope that you have somehow figured out and made your assemblies deterministic.
In fact, the findings are not so sad. Celery copes with its tasks in our fintech project under our load. We have gained experience that I have shared with you, and you can apply our solutions or refine them and also overcome all of your difficulties.
Do not forget that monitoring should be the main part of your project.. Only with the help of monitoring you will be able to find out where is something wrong with you that needs to be corrected, added, corrected.
Contact speaker Oleg Churkin : Bahusss , facebook and github .
The beauty of Oleg Churkin's story about Celery at Moscow Python Conf ++ in addition to detailed instructions on how to configure Celery under load and how to monitor it, is that you can borrow useful ideas.
About speaker and project: Oleg Churkin ( Bahusss ) has been developing Python-projects of various complexity for 8 years, he worked in many well-known companies: Yandex, Rambler, RBC, Kaspersky Labs. Now technid in fintech-stapard StatusMoney.
The project works with a large amount of financial user data (1.5 terabytes): accounts, transactions, merchants, etc. It runs up to a million tasks every day. Maybe someone will not find this number really large, but for a small startup on modest capacities this is a significant amount of data, and the developers had to face various problems on the way to a stable process.
Oleg told about the key points of the work:
- What tasks they wanted to solve with the help of the framework, why they chose Celery.
- How helped Celery.
- How to configure Celery under load.
- How to monitor the status of Celery.
And he shared a pair of project utilities that implement the missing functionality in Celery. As it turned out, in 2018 this could happen. Further, the text version of the report from the first person.
Problematics
It was necessary to solve the following tasks:
- Run separate background tasks .
- To do batch processing of tasks , that is, to run many tasks at once.
- Embed the process of Extract, Transform, Load .
- Implement an asynchronous API . It turns out that the asynchronous API can be implemented not only with the help of asynchronous frameworks, but also quite synchronous ones;
- Perform periodic tasks . No project can do without periodic tasks, for some, you can do Cron, but there are more convenient tools.
- Build a trigger architecture : to trigger the trigger, run a task that updates the data. This is done to compensate for the lack of runtime capacity by pre-calculating data in the background.
For background tasks include any types of notifications: email, push, desktop - all of this is sent to the background tasks the trigger. In the same way, a periodic update of financial data is launched.
In the background, various specific checks are performed, for example, checking a user for fraud. In financial startups, a lot of effort and attention is paid to data security , because we allow users to add their bank accounts to our system, and we can see all their transactions. Fraudsters can try to use our service for something bad, for example, to check the balance of a stolen account.
The last category of background tasks is maintenance tasks.: twist something, look, fix, zamonitory, etc.
To send notifications, only mass, batch processing is used . The large amount of data we receive from our users has to be calculated and processed in a certain way, incl. in batch mode.
The same concept includes the classic Extract, Transform, Load :
- load data from external sources (external API);
- keep untreated;
- run tasks that read and process data;
- We save the processed data in the right place in the right format, so that it is then convenient to use it in the UI, for example.
It's no secret that the asynchronous API can be done using simple polling requests: the frontend initiates the process on the backend, the backend runs the task, which periodically launches itself, pollit the results and updates the state in the database. The frontend shows the user this interactivity - the state is changing. This allows:
- start polling tasks from other tasks;
- run different tasks depending on conditions.
In our service, this is still enough, but in the future most likely it will be necessary to rewrite something else.
Requirements for tools
To realize these tasks, we had the following requirements for the tools:
- The functionality necessary to fulfill our ambitions.
- Scalability without crutches.
- Monitoring the system in order to understand how it works. We use error reporting, so integration with Sentry is not superfluous, with Django too.
- Productivity , because we have a lot of tasks.
- Maturity, reliability and active development are obvious things. We were looking for a tool that would be supported and developed.
- The adequacy of the documentation - without documentation anywhere .
Which tool to choose?
What are the options on the market in 2018 to solve these problems?
Once upon a time for less ambitious tasks, I wrote a convenient library that is still used in some projects. It is easy to operate and performs tasks in the background. But at the same time no brokers are needed (neither Celery, nor others), only the uwsgi application server , which has a spooler, is such a thing that runs as a separate worker. This is a very simple solution - all tasks are stored conditionally in files. For simple projects, this is enough, but for ours it was not enough.
Anyway, we looked at:
- Celery (10K stars on GitHub);
- RQ (5K stars on GitHub);
- Huey (2K stars on GitHub);
- Dramatiq (1K stars on GitHub);
- Tasktiger (0.5K stars on GitHub);
- Airflow? Luigi?
Promising Candidate 2018
Now I would draw your attention to Dramatiq . This is a library from the Celery adept, who learned all the disadvantages of Celery and decided to rewrite everything, only very beautifully. Advantages of Dramatiq:
- A set of all the necessary features.
- Clearance for performance.
- Sentry and metrics support for Prometheus out of the box
- Small and clearly written codebase, code autoreload.
Some time ago Dramatiq had problems with licenses: at first it was AGPL, then it was replaced with LGPL. But now you can try.
But in 2016, apart from Celery, there was nothing special to take. We liked its rich functionality, and then it ideally suited our tasks, because even then it was mature and functional:
- had periodic tasks out of the box;
- supported several brokers;
- integrated with Django and Sentry.
Project Features
I'll tell you about our context so that the following story is clearer.
We use Redis as a message broker . I have heard many stories and rumors that Redis is losing messages, that he is not fit to be a message broker. This is not confirmed for the production experience, and as it turns out, Redis now works more efficiently than RabbitMQ (it is with Celery, at least, apparently, the problem is in the integration code with brokers). In version 4, the Redis broker was repaired, it really stopped losing tasks during restarts and works quite stably. In 2016, Celery was going to abandon Redis and concentrate on integration with RabbitMQ, but, fortunately, this did not happen.
In case of problems with Redis, if we need serious high availability, we will switch to Amazon SQS or Amazon MQ because we are using Amazon power.
We do not use result backend to store the results , because we prefer to store the results ourselves where we want, and check them as we want. We don't want Celery to do this for us.
We use the pefork pool , that is, process-workers, which create separate forks of processes for additional concurrency.
Unit of work
We will discuss the basic elements to bring up to date those who have not tried Celery, but are only going to. Unit of work for Celery is a challenge . I will give an example of a simple task that sends email.
Simple function and decorator:
@current_app.taskdefsend_email(email: str):
print(f'Sending email to email={email}')
The task launch is simple: either we call the function and the task is executed at runtime (send_email (email = "python@example.com")), or in a worker, that is, the same effect of the task in the background:
send_email.delay(email="python@example.com")
send_email.apply_async(
kwargs={email: "python@example.com"}
)
During two years of work with Celery under high loads, we derived good tone rules. There were a lot of rakes, we learned to bypass them, and I will share how.
Code design
There can be different logic in the task. In general, Celery helps you keep your puzzles in files or packages, or import them from somewhere. Sometimes it turns out a jumble of business logic in one module. In our opinion, here the correct approach from the point of view of the modularity of the application is to keep the minimum of logic in the task . We use puzzles only as “starters” of the code. That is, the task does not carry logic, but triggers the launch of code on the Background.
@celery_app.task(queue='...')defrun_regular_update(provider_account_id, *args, **kwargs):"""..."""
flow = flows.RegularSyncProviderAccountFlow(provider_account_id)
return flow.run(*args, **kwargs)
We extend all code to external classes that use some other classes. All tasks essentially consist of two lines.
Simple objects in the parameters
In the example above, a certain id is passed to the task. In all the tasks that we use, we transmit only small scalar data , id. We do not serialize Django models to transmit them. Even in ETL, when it comes from the external service of a large data blob, we first save it and then run a task that reads the entire blob by id and processes it.
If you do not do this, then we have seen very large spikes of consumed memory from Redis. The message starts to occupy more memory, the network is heavily loaded, the number of processed tasks (performance) drops. While the object reaches execution, the tasks become irrelevant, the object is already deleted. The data needed to be serialized - not everything is well serialized in JSON in Python. When we needed to retry tasks, we needed to quickly decide what to do with this data, receive them again, and run some checks on them.
If you pass big data in the parameters, think again! It is better to transfer a small scalar with a small amount of information in the task, and get all the necessary information for this information in the task.
Idempotent tasks
This approach is recommended by the Celery developers themselves. When re-running the code segment, no side-effects should occur, the result should be the same. This is not always easy to achieve, especially if there is interaction with many services, or two-phase commits.
But when you do everything locally, you can always check that the incoming data exists and is relevant, you really can do work on it, and use transactions. If a single task has a lot of queries into the database and something can go wrong at runtime - use transactions to roll back unnecessary changes.
backward compatibility
We had several interesting side effects with a deploe application. It doesn't matter what type of deployment you use (blue + green or rolling update), there will always be a situation when the old service code creates messages for the new worker code, and vice versa, the old worker receives messages from the new service code because it rolls out "first" and there the traffic went.
We caught mistakes and lost tasks until we learned how to maintain backward compatibility between releases.. Backward compatibility is that tasks should work safely between releases, no matter what parameters come into this task. Therefore, in all tasks we are now doing a "rubber" signature (** kwargs). When in the next release you need to add a new parameter, you will take it from ** kwargs in the new release, and in the old one you will not take it - nothing will break. As soon as the signature changes, but Celery does not know about it, it falls and gives an error that there is no such parameter in the task.
A more rigorous way to avoid such problems is the versioning of task queues between releases, but it is quite difficult to implement and we have left it in the backlog so far.
Timeouts
Problems may occur due to insufficient or incorrect timeouts.
Not setting a timeout for a task is evil. This means that you do not understand what is happening in the task, how business logic should work.
Therefore, all our tasks are hung with timeouts, including global ones for all tasks, and timeouts are also set for each specific task.
Be sure to include: soft_limit_timeout and expires.
Expires is how much a task can live in a queue. It is necessary that tasks do not accumulate in queues in case of problems. For example, if we now want to report something to the user, but something has happened, and the task can be completed only tomorrow - this makes no sense, tomorrow the message will be irrelevant. Therefore, on the notice we have quite a small expires.
Note the use of eta (countdown) + visibility _timeout. The FAQ describes such a problem with Redis - the so-called visibility timeout at the Redis broker. By default, its value is one hour: if after an hour the worker doesn’t take the task to execution, then re-adds it to the queue. Thus, if the countdown is equal to two hours, after an hour the broker will find out that this task has not yet been completed, and will create another one the same. And in two hours two identical tasks will be executed.
If the estimation time or countdown exceeds 1 hour, then most likely, using Redis will result in duplication of tasks, if you, of course, have not changed the visibility_timeout value in the settings of the connection with the broker.
Retry policy
For those tasks that can be repeated, or that can be performed with errors, we use the Retry policy. But we use it carefully so as not to overwhelm external services. If you quickly repeat the task without specifying the exponential backoff, then the external service, and maybe the internal one, can simply not withstand.
The parameters retry_backoff , retry_jitter and max_retries would be nice to specify explicitly, especially max_retries. retry_jitter is a parameter that allows you to add a little chaos so that tasks do not start repeating at the same time.
Memory leaks
Unfortunately, memory leaks arise very easily, and it is difficult to find and fix them.
In general, working with memory in Python is very controversial. You will spend a lot of time and nerves to understand why a leak occurs, and then it turns out that it is not even in your code. Therefore, always starting a project, put a memory limit on the worker : worker_max_memory_per_child.
This ensures that OOM Killer does not come one day, does not kill all workers, and you do not lose all tasks. Celery will restart the workers when needed.
The priority of the tasks
There are always tasks that need to be performed before everyone, faster than all - they must be completed right now! There are tasks that are not so important - let them be executed during the day. To do this, the task has a priority parameter . It works quite interestingly in Redis - a new queue is created with the name to which priority is added.
We use a different approach - separate workers for priorities , i.e. in the old manner, we create workers for Celery with different “importance”:
celery multi start
high_priority low_priority
-c:high_priority 2 -c:low_priority 6
-Q:high_priority urgent_notifications
-Q:low_priority emails,urgent_notifications
Celery multi start is a helper that helps to run the entire Celery configuration on one machine and from one command line. In this example, we create nodes (or workers): high_priority and low_priority, 2 and 6 - this is concurrency.
Two high_priority workers constantly process the urgent_notifications queue. No one else will take these workers, they will only read important tasks from the urgent_notifications lineup.
For unimportant tasks, there is a low_priority queue. There are 6 workers who receive messages from all other queues. We also subscribe to urgent_notifications low_priority workers so they can help if the high_priority workers do not cope.
We use this classic scheme to prioritize tasks.
Extract, Transform, Load
Most often, ETL looks like a chain of tasks, each of which receives input from the previous task.
@taskdefdownload_account_data(account_id)
…
returnaccount_id
@taskdefprocess_account_data(account_id, processing_type)
…
returnaccount_data
@taskdefstore_account_data(account_data)
…
In the example, three tasks. Celery has an approach to distributed processing and several useful utilities, including the chain function , which makes one such pipeline out of three such tasks:
chain(
download_account_data.s(account_id),
process_account_data.s(processing_type='fast'),
store_account_data.s()
).delay()
Celery will disassemble the pipeline itself, perform the first task in order first, then transmit the received data to the second, the data that the second task returns, transfer to the third. So we implement simple ETL pipelines.
For more complex chains, you have to connect additional logic. But it is important to keep in mind that if this chain has a problem in one task, then the whole chain will fall apart . If you do not want this behavior, handle exception and continue execution, or stop the entire exception chain.
In fact, this chain inside looks like one big task, which contains all the tasks with all the parameters. Therefore, if you abuse the number of tasks in the chain, you get a very high memory consumption and slowing down the overall process.Creating chains of thousands of tasks is a bad idea.
Batch processing tasks
Now the most interesting thing: what happens when you need to send an email to two million users.
You write this function to bypass all users:
@taskdefsend_report_emails_to_users():for user_id in User.get_active_ids():
send_report_email.delay(user_id=user_id)
True, more often than not, the function will receive not only user id, but also flush the entire users table in general. For each user will run their own task.
There are several problems with this task:
- Tasks are launched sequentially, that is, the last task (two millionth user) will start in 20 minutes and maybe by this time the timeout will work.
- All user IDs are loaded first into the application's memory, and then into the queue - delay () will perform 2 million tasks.
I called it Task flood, on the chart it looks like this.
There is an influx of tasks that workers quietly begin to handle. The following happens if tasks use a master-replica, the whole project starts to just pop - nothing works. Below is an example from our practice, where DB CPU Usage was 100% several hours, we, frankly, managed to get scared.
The problem is that the system greatly degrades with the increase in the number of users. Task that deals with dispatching:
- requires more and more memory;
- longer and can be "killed" by timeout.
Task flooding occurs: tasks accumulate in queues and create a large load not only on internal services, but also on external ones.
We tried to reduce the competition of workers , it helps in some sense - reducing the load on the service. Or you can scale internal services . But this does not solve the problem of the generator problem, which still takes a lot on itself. And does not affect the dependence on the performance of external services.
Task generation
We decided to go the other way. Most often, we do not need to run all 2 million tasks right now. It is normal that sending notifications to all users will take, for example, 4 hours, if these letters are not so important.
We first tried using Celery.chunks :
send_report_email.chunks(
({'user_id': user.id} for user in User.objects.active()),
n=100
).apply_async()
This did not change the situation, because, despite the iterator, all user_id will be loaded into memory. And all workers receive chains of tasks, and although workers will have a little rest, we were not satisfied with this decision as a result.
We tried to set rate_limit on workers so that they process only a certain number of tasks per second, and find out that in fact the rate_limit specified for the task is rate_limit for a worker. That is, if you specify rate_limit for a task, this does not mean that the task will be executed 70 times per second. This means that the worker will perform it 70 times per second, and depending on what you have with the workers, this limit may change dynamically, i.e. real limit rate_limit * len (workers).
If the worker starts or stops, the total rate_limit changes. Moreover, if your tasks are slow, then the entire prefetch in the queue that the worker fills in will be clogged with these slow tasks. The worker looks like: “Oh, I have this task in rate_limit, I can’t do it anymore. And all the following tasks in the queue are exactly the same - let them hang! ”- and waits.
Chunkificator
In the end, we decided that we would write our own, and made a small library, which we called Chunkificator.
@task@chunkify_task(sleep_timeout=...l initial_chunk=...) defsend_report_emails_to_users(chunk: Chunk):for user_id in User.get_active_ids(chunk=chunk):
send_report_email.delay(user_id=user_id)
She accepts sleep_timeout and initial_chunk, and calls herself with a new chunk. Chunk is an abstraction either over integer lists, or over date or datetime lists. We pass chunk to a function that gets users only with that chunk, and runs tasks for that chunk only.
Thus, the task generator runs only the number of tasks that is needed, and does not consume a lot of memory. The picture has become so.
The highlight is the fact that we use sparse chunk, that is, we use instances in the database as a chunk id (some of them can be skipped, so there may be fewer tasks). As a result, the load turned out to be more uniform, the process became longer, but everyone is alive and well, the base is not strained.
Libraryimplemented for Python 3.6+ and available on GitHub. There is a nuance that I plan to fix, but for now, a pickle serializer is needed for a datetime chunk - many will not be able to do this.
A couple of rhetorical questions - where did all this information come from? How do we know that we had problems? How to find out that the problem will soon become critical and it is already necessary to begin to solve it?
The answer is, of course, monitoring.
Monitoring
I really like monitoring, I like to monitor everything and keep my finger on the pulse. If you do not keep your finger on the pulse, then you will constantly step on the rake.
Standard monitoring issues:
- Does the current worker / concurrency configuration handle the load?
- What is the degradation of task execution time?
- How long do tasks hang in the queue? Suddenly the line is already full?
We tried several options. Celery has a CLI interface , it is rich enough and gives:
- inspect - information about the system;
- control - manage system settings;
- purge - clear the queues (force majeure);
- events - a console UI to display information about the tasks performed.
But it’s difficult to really monitor something. It is better suited for local delights, or if you want to change some rate_limit at runtime.
NB: you need access to a production broker to use the CLI interface.
Celery Flower allows you to do the same thing as the CLI, only through a web interface, and then not all. But it builds some simple graphics and allows you to change settings on the fly.
In general, Celery Flower is suitable in order to just see how everything works, in small setups. In addition, it supports the HTTP API, that is, it is convenient if you are writing automation.
But we stopped at Prometheus. Took the current exporter: fixed memory leaks in it; added metrics for exception types; added metrics for the number of messages in the queues; integrated with alerts in Grafana and rejoice. It is also posted on GitHub, you can see here .
Examples in Grafana
The above statistics on all exceptions: what exceptions for which tasks. Below is the time to complete tasks.
What is missing in Celery?
This is a spreading framework, it has a lot of things, but we are missing! There are not enough small features, such as:
- Automatic code reloading during development - does not support this Celery - restart.
- Metrics for Prometheus out of the box, but Dramatiq knows how.
- Support task lock - so that only one task is executed at a time. This can be done independently, but there is a convenient decorator in Dramatiq and Tasktiger, which guarantees that all other tasks will be blocked.
- Rate_limit for one task - not for the worker.
findings
Despite the fact that Celery is a framework that many people use in production, it consists of 3 libraries - Celery, Kombu and Billiard. All three of these libraries are being developed by the developers, and they can release one dependency and break your build.
Therefore, I hope that you have somehow figured out and made your assemblies deterministic.
In fact, the findings are not so sad. Celery copes with its tasks in our fintech project under our load. We have gained experience that I have shared with you, and you can apply our solutions or refine them and also overcome all of your difficulties.
Do not forget that monitoring should be the main part of your project.. Only with the help of monitoring you will be able to find out where is something wrong with you that needs to be corrected, added, corrected.
Contact speaker Oleg Churkin : Bahusss , facebook and github .
The next big Moscow Python Conf ++ will be held in Moscow on April 5th . This year we are experimentally trying to fit all the benefits in one day. There will be no less reports, we will allocate the whole stream to foreign developers of famous libraries and products. In addition, Friday is an ideal day for after-party, which, as you know, is an integral part of the conference about communication.
Join our professional Python conference - submit a report here , book a ticket here . In the meantime, preparations are underway, articles on Moscow Python Conf ++ 2018 will appear here.