Fault Injection: your system is unreliable if you have not tried to break it
Hi, Habr! My name is Pavel Lipsky. I am an engineer, I work in the company Sberbank-Technology. My specialization is testing the fault tolerance and performance of backends of large distributed systems. Simply put, I break other people's programs. In this post I will talk about fault injection, a testing method that allows you to find problems in the system by creating artificial failures. To begin with, I came to this method, then we will talk about the method itself and how we use it.

The article will be examples in Java. If you do not program in Java - that's okay, it’s enough to understand the approach itself and the basic principles. Apache Ignite is used as a database, but the same approaches are applicable to any other DBMS. All examples can be downloaded from my GitHub .
I'll start with the story. In 2005, I worked at Rambler. By that time, the number of Rambler users was rapidly growing, and our two-tier architecture “server - database - server - applications” could no longer cope. We thought about how to solve performance problems and paid attention to the memcached technology.
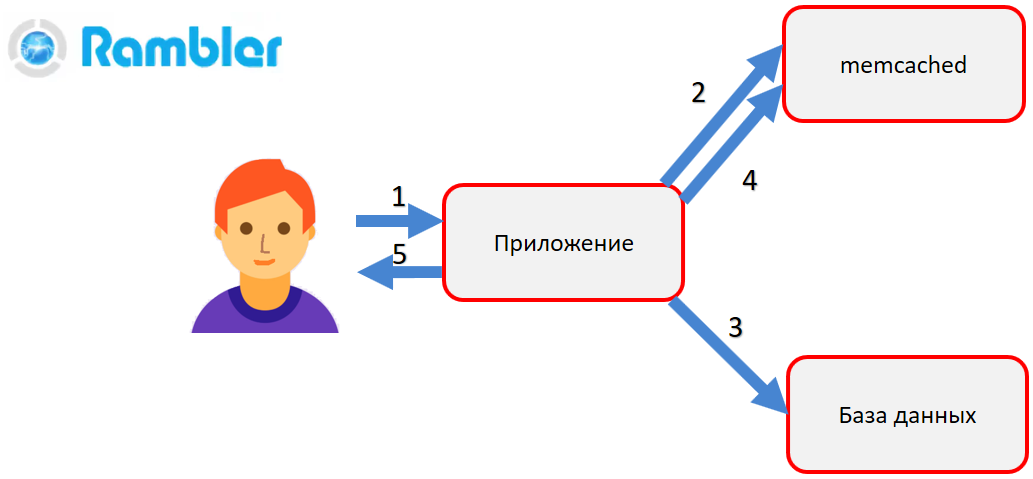
What is memcached? Memcached is a hash table in RAM with access to stored objects by key. For example, you need to get a user profile. The application is drawn to memcached (2). If there is an object in it, then it is immediately returned to the user. If there is no object, then the database is accessed (3), the object is formed and put into memcached (4). Then, during the next call, we no longer need to make a resource-intensive call to the database — we will get the finished object from the RAM - memcached.
Due to memcached, we noticeably unloaded the database, and our applications started working much faster. But as it turned out, it was too early to rejoice. Along with the increase in productivity, we have new problems.
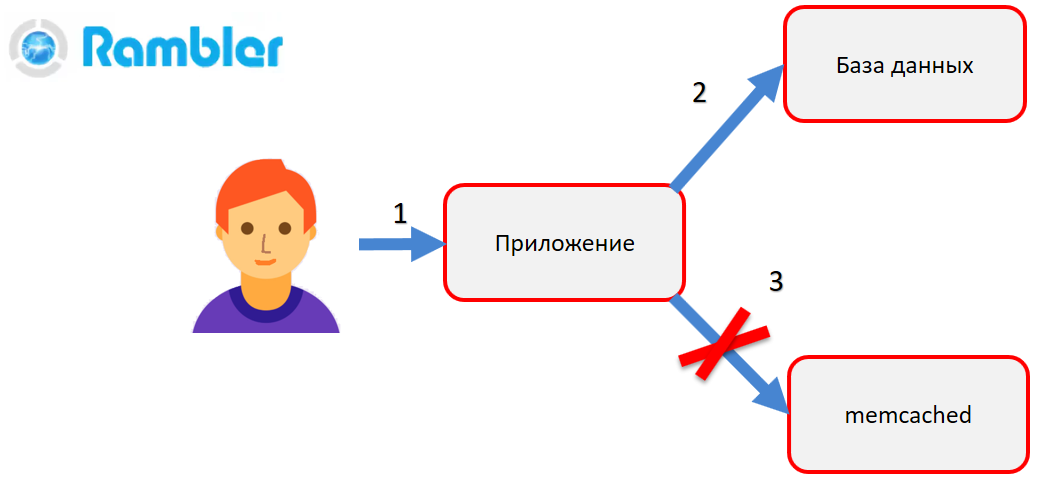
When you need to change the data, the application first makes a correction to the database (2), creates a new object and then tries to put it into memcached (3). That is, the old object must be replaced by a new one. Imagine that at that moment a terrible thing happens - the connection between the application and memcached is broken, the memcached server or even the application itself crashes. This means that the application could not update the data in memcached. As a result, the user goes to the site page (for example, his profile), sees the old data and does not understand why this happened.
Was it possible to detect this bug during functional testing or performance testing? I think that, most likely, we would not have found it. To search for such bugs there is a special type of testing - fault injection.
Usually during fault injection testing there are bugs, which are popularly called floating . They appear under load, when more than one user is working in the system, when abnormal situations occur - equipment fails, electricity is cut off, the network fails, etc.
A few years ago, Sberbank began building a new IT system. What for? Here are the statistics from the Central Bank website: The
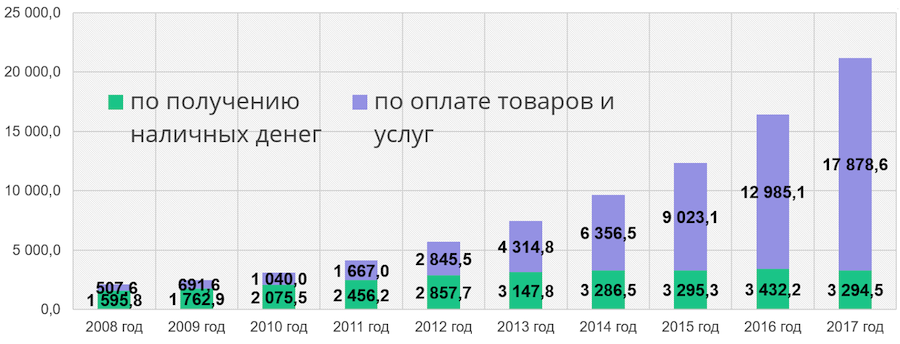
green part of the column is the number of cash withdrawals at ATMs, the blue part is the number of transactions for payment for goods and services. We see that the number of non-cash transactions is growing from year to year. In a few years, we will have to be able to handle the growing workload and continue to offer new services to customers. This is one of the reasons for creating a new IT system for Sberbank. In addition, we would like to reduce our dependence on Western technologies and expensive mainframes, which cost millions of dollars, and switch to open source technologies and a low-end server.
Initially, we laid the foundation for Apache Ignite technology at the heart of Sberbank. More precisely, we use the paid Gridgain plugin. The technology has a fairly rich functionality: combines the properties of a relational database (there is support for SQL queries), NoSQL, distributed processing and data storage in RAM. Moreover, when you restart the data that were in memory, will not be lost. Starting with version 2.1, Apache Ignite introduced Apache Ignite Persistent Data Store distributed disk storage with SQL support.
I will list some features of this technology:
The technology is relatively new, and therefore requires special attention.
The new IT system of Sberbank physically consists of many relatively small servers assembled into one cluster-cloud. All nodes are identical in structure, equal to each other, perform the function of storing and processing data.
Inside the cluster is divided into so-called cells. One cell is 8 nodes. Each data center has 4 nodes.
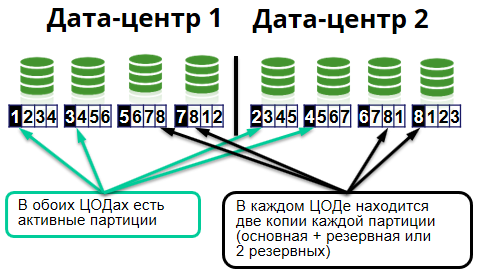
Since we use Apache Ignite, in-memory data grid, then, accordingly, all this is stored in server-distributed caches. And the caches, in turn, are divided into identical pieces - partitions. On the servers, they are presented as files. Partitions of the same cache can be stored on different servers. For each partition in the cluster there are primary (primary node) and backup nodes (backup node).
Primary nodes store primary partitions and process requests for them, replicate data to backup nodes, where backup partitions are stored.
While designing a new Sberbank architecture, we came to the conclusion that the system components can and will fail. Say, if you have a cluster of 1000 iron low-end servers, then from time to time you will have hardware failures. RAM strips, network cards and hard drives, etc. will fail. We will consider this behavior as completely normal behavior of the system. Such situations should be handled correctly and our clients should not notice them.
But it is not enough to design the system's stability to failure, it is necessary to test the systems during these failures. As the well-known distributed systems researcher Caitie McCaffrey of Microsoft Research says: “You will never know how the system behaves during an abnormal situation until you reproduce the failure.”
Let us examine a simple example, a banking application that simulates money transfers. The application will consist of two parts: the Apache Ignite server and the Apache Ignite client. The server part is a data storage.
The client application connects to the Apache Ignite server. Creates a cache, where the key is the account ID, and the value is the account object. A total of ten such objects will be stored in the cache. In this case, initially for each account we put 100 dollars (so that was what to transfer). Accordingly, the total balance of all accounts will be equal to $ 1,000.
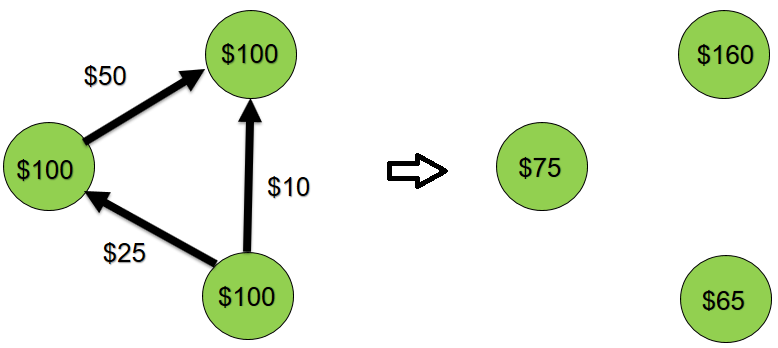
Then we make 100 random money transfers between these 10 accounts. For example, from account A to another account B is transferred 50 dollars. Schematically, this process can be depicted as follows:

The system is closed, transfers are made only inside, i.e. The total balance must remain equal to $ 1000.
Run the application.
We received the expected total balance value of $ 1000. Now let's complicate our application a bit - let's make it multi-tasking. In reality, several client applications can run simultaneously with the same account. We will launch two tasks that will simultaneously make money transfers between ten accounts.
The total balance is $ 1296. Customers are happy, the bank is suffering losses. Why did this happen?

Here we see how two tasks simultaneously change the state of account A. But the second task manages to record its changes before the first one does. Then the first task records its changes, and all changes made by the second task disappear immediately. This anomaly is called the problem of lost updates.
In order for the application to work as needed, it is necessary that our database supports ACID transactions and our code takes this into account.
Let's look at the ACID properties for our application to see why this is so important.

So, in the transferMoney method, we will make a money transfer within a transaction.
Run the application.
Hm Transactions did not help. Overall balance - $ 6951! What is the problem with this behavior of the application?
First, we chose the ATOMIC cache type, i.e. without ACID transaction support:
Secondly, the txStart method has two important parameters of the enum type, which it would be good to indicate: a blocking method (concurrency mode in Apache Ignite) and an isolation level. Depending on the values of these parameters, a transaction may read and write data in different ways. In Apache Ignite, these parameters are set as follows:
You can use PESSIMISTIC (pessimistic blocking) or OPTIMISTIC (optimistic blocking) as the value of the BLOCK METHOD parameter. They differ in the moment of imposing of blocking. When using PESSIMISTIC, the lock is imposed at the first reading / writing and is held until the transaction is committed. For example, when a transaction with a pessimistic blocking makes a transfer from account A to account B, other transactions can neither read nor write the values of these accounts until the transaction making the transfer is committed. It is clear that if other transactions want to access accounts A and B, they have to wait for the transaction to complete, which has a negative effect on the overall performance of the application. Optimistic locking does not restrict data access for other transactions, however, during the preparation phase of the transaction for commit (prepare phase, Apache Ignite uses the 2PC protocol), it will be checked whether the data was changed by other transactions? And if changes took place, then the transaction will be canceled. In terms of performance, OPTIMISTIC will work faster, but is more suitable for applications where there is no competitive work with data.
The INSULATION LEVEL parameter determines the degree of transaction isolation from each other. The ANSI / ISO SQL standard defines 4 types of isolation, and for each isolation level the same transaction scenario can lead to different results.
For many modern DBMSs (Microsoft SQL Server, PostgreSQL and Oracle), the default isolation level is READ_COMMITTED. For our example, this would be fatal, since it would not protect us from lost updates. The result will be the same as if we did not use transactions at all.

From the Apache Ignite transaction documentation , it follows that such combinations of blocking method and isolation level are suitable for us:
Hurray, received $ 1000, as expected. From the third attempt.
Now we will make our test more realistic - we will test under load. And add an additional server node. There are many tools for load testing, in Sberbank we use the HP Performance Center. This is quite a powerful tool, supports more than 50 protocols, is designed for large teams and costs a lot of money. I wrote my example on JMeter - it is free and solves our problem 100%. I wouldn’t like to rewrite Java code, so I’ll use the JSR223 sampler.
Let's create a JAR archive from the classes of our application and load it into a test plan. To create and fill the cache, run the class CreateCache. After initializing the cache, you can run the JMeter script.
All cool, got $ 1000.
Now we will be more destructive: during the operation of the cluster, we will abort one of the two server nodes. Through the utility Visor, which is included in the Gridgain distribution, we can monitor the Apache Ignite cluster and make different data samples. In the SQL Viewer tab, we execute a SQL query in order to get a total balance for all accounts.
What is the result? 553 dollars. Customers are terrified, the bank suffers a reputational loss. What did we do wrong this time?
It turns out that Apache Ignite has cache types:

We will frequently change our data, so we will select a partitioned cache and add an additional backup to it. That is, we will have two copies of the data - the main and backup.
Run the application. I remind you that before transfers we have $ 1000. We launch and, during operation, “extinguish” one of the nodes
In the Visor utility, we make a SQL query to get the total balance - $ 1000. Everything worked great!
Two years ago we were just starting to test the new IT system of Sberbank. Somehow we went to our support engineers and asked: what could possibly break? We were answered: everything can break, test everything! Of course, this answer did not suit us. We sat down together, analyzed the statistics of failures and realized that the most likely case we could encounter was a node failure.
Moreover, this can happen for completely different reasons. For example, it may fail an application, crash a JVM, crash the OS, or fail the hardware.
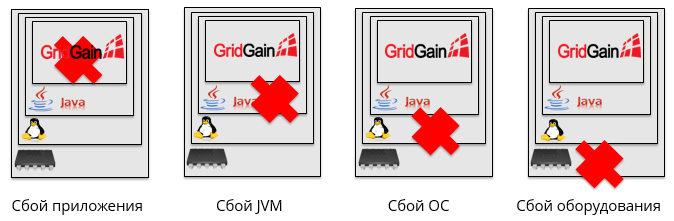
We divided all possible cases of failures into 4 groups:
They invented tests for them and called them reliability cases. A typical case of reliability consists of a description of the state of the system before the tests, the steps to reproduce the failure, and a description of the expected behavior during the failure.
This group includes such cases as:
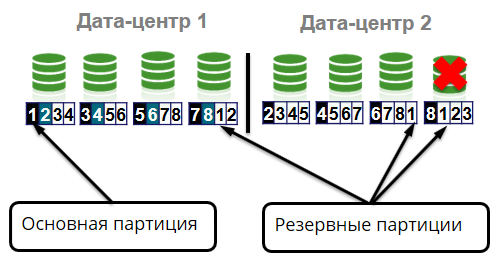
The cluster stores 4 identical copies of each partition: one main partition (primary) and three backup partitions (backup). Suppose, due to a hardware failure, a node is coming out of the cluster. In this case, the main partitions should move to the other surviving nodes.
What else can happen? Loss of rack in the cell.
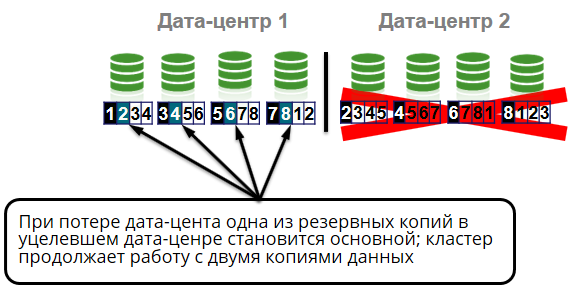
All cell nodes are in different racks. Those. rack output will not cause cluster failure or data loss. We will have three copies of the four. But even if we lose the whole data center, it will also not be a big problem for us, because we still have two copies of the data from four.
Part of the cases are performed directly in the data center with the participation of maintenance engineers. For example, shutting down the hard drive, turning off the power to the server or rack.
For testing cases related to network fragmentation, we use iptables. And with the help of the utility NetEm we emulate:
Another interesting network case we are testing is split-brain. This is when all cluster nodes are live, but due to network segmentation they cannot communicate with each other. The term came from medicine and means that the brain is divided into two hemispheres, each of which considers itself unique. The same can happen with a cluster.
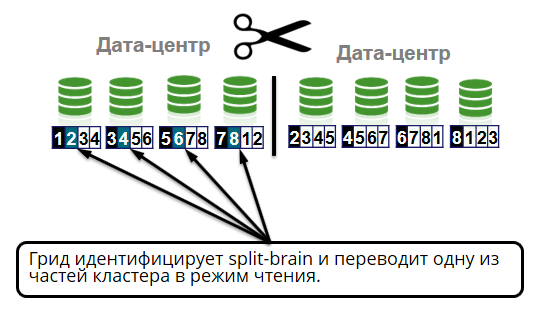
It happens that the connection between the data centers is lost. For example, last year, due to damage to the fiber optic cable by an excavator, the client of the banks “Tochka”, “Otkritie” and “Roketbank” did not perform operations over the Internet for several hours, the terminals did not accept cards and the ATMs did not work. About this accident, a lot has been written to Twitter.
In our case, the split-brain situation should be handled correctly. The grid identifies the split-brain - the division of the cluster into two parts. One of the halves is translated into read mode. This is half where there are more live nodes or there is a coordinator (the oldest node in the cluster).
These cases are associated with the failure of various subsystems:
Since most of the software is written in Java, we are subject to all the problems inherent in Java applications. Tests various garbage collector settings. We carry out tests with the fall of the java virtual machine.
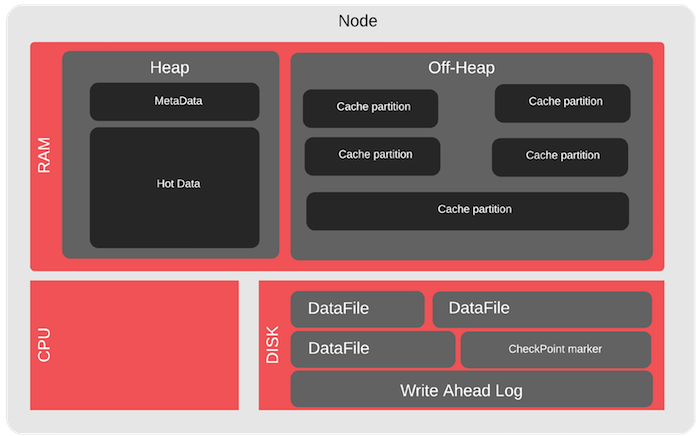
For the Apache Ignite cluster, there are special cases for off-heap - this is such a memory area that Apache Ignite controls. It is much more than java heap and is intended for storing data and indexes. Here you can, for example, test overflow. We overflow the off-heap and see how the cluster works in the case where some of the data did not fit into the RAM, i.e. read from disk.
These are cases that are not included in the first three groups. These include utilities that allow you to recover data in the event of a major crash or when migrating data to another cluster.
I recall a link to examples from my report. You can download the Apache Ignite distribution from the official site - Apache Ignite Downloads . And now I will share the utilities that we use at Sberbank, if you are suddenly interested in the topic.
Frameworks:
Configuration Management:
Linux utilities:
Load testing tools:
Both in the modern world and in Sberbank, all changes occur dynamically and it is difficult to predict which technologies will be used in the next couple of years. But I know for sure that we will use the Fault Injection method. The universal method is suitable for testing any technologies, it really works, it helps to catch a lot of bugs and make the products that we develop better.
The article will be examples in Java. If you do not program in Java - that's okay, it’s enough to understand the approach itself and the basic principles. Apache Ignite is used as a database, but the same approaches are applicable to any other DBMS. All examples can be downloaded from my GitHub .
Why do we need all this?
I'll start with the story. In 2005, I worked at Rambler. By that time, the number of Rambler users was rapidly growing, and our two-tier architecture “server - database - server - applications” could no longer cope. We thought about how to solve performance problems and paid attention to the memcached technology.
What is memcached? Memcached is a hash table in RAM with access to stored objects by key. For example, you need to get a user profile. The application is drawn to memcached (2). If there is an object in it, then it is immediately returned to the user. If there is no object, then the database is accessed (3), the object is formed and put into memcached (4). Then, during the next call, we no longer need to make a resource-intensive call to the database — we will get the finished object from the RAM - memcached.
Due to memcached, we noticeably unloaded the database, and our applications started working much faster. But as it turned out, it was too early to rejoice. Along with the increase in productivity, we have new problems.
When you need to change the data, the application first makes a correction to the database (2), creates a new object and then tries to put it into memcached (3). That is, the old object must be replaced by a new one. Imagine that at that moment a terrible thing happens - the connection between the application and memcached is broken, the memcached server or even the application itself crashes. This means that the application could not update the data in memcached. As a result, the user goes to the site page (for example, his profile), sees the old data and does not understand why this happened.
Was it possible to detect this bug during functional testing or performance testing? I think that, most likely, we would not have found it. To search for such bugs there is a special type of testing - fault injection.
Usually during fault injection testing there are bugs, which are popularly called floating . They appear under load, when more than one user is working in the system, when abnormal situations occur - equipment fails, electricity is cut off, the network fails, etc.
New IT system of Sberbank
A few years ago, Sberbank began building a new IT system. What for? Here are the statistics from the Central Bank website: The
green part of the column is the number of cash withdrawals at ATMs, the blue part is the number of transactions for payment for goods and services. We see that the number of non-cash transactions is growing from year to year. In a few years, we will have to be able to handle the growing workload and continue to offer new services to customers. This is one of the reasons for creating a new IT system for Sberbank. In addition, we would like to reduce our dependence on Western technologies and expensive mainframes, which cost millions of dollars, and switch to open source technologies and a low-end server.
Initially, we laid the foundation for Apache Ignite technology at the heart of Sberbank. More precisely, we use the paid Gridgain plugin. The technology has a fairly rich functionality: combines the properties of a relational database (there is support for SQL queries), NoSQL, distributed processing and data storage in RAM. Moreover, when you restart the data that were in memory, will not be lost. Starting with version 2.1, Apache Ignite introduced Apache Ignite Persistent Data Store distributed disk storage with SQL support.
I will list some features of this technology:
- Storage and processing of data in RAM
- Disk storage
- SQL support
- Distributed task execution
- Horizontal scaling
The technology is relatively new, and therefore requires special attention.
The new IT system of Sberbank physically consists of many relatively small servers assembled into one cluster-cloud. All nodes are identical in structure, equal to each other, perform the function of storing and processing data.
Inside the cluster is divided into so-called cells. One cell is 8 nodes. Each data center has 4 nodes.
Since we use Apache Ignite, in-memory data grid, then, accordingly, all this is stored in server-distributed caches. And the caches, in turn, are divided into identical pieces - partitions. On the servers, they are presented as files. Partitions of the same cache can be stored on different servers. For each partition in the cluster there are primary (primary node) and backup nodes (backup node).
Primary nodes store primary partitions and process requests for them, replicate data to backup nodes, where backup partitions are stored.
While designing a new Sberbank architecture, we came to the conclusion that the system components can and will fail. Say, if you have a cluster of 1000 iron low-end servers, then from time to time you will have hardware failures. RAM strips, network cards and hard drives, etc. will fail. We will consider this behavior as completely normal behavior of the system. Such situations should be handled correctly and our clients should not notice them.
But it is not enough to design the system's stability to failure, it is necessary to test the systems during these failures. As the well-known distributed systems researcher Caitie McCaffrey of Microsoft Research says: “You will never know how the system behaves during an abnormal situation until you reproduce the failure.”
Lost updates
Let us examine a simple example, a banking application that simulates money transfers. The application will consist of two parts: the Apache Ignite server and the Apache Ignite client. The server part is a data storage.
The client application connects to the Apache Ignite server. Creates a cache, where the key is the account ID, and the value is the account object. A total of ten such objects will be stored in the cache. In this case, initially for each account we put 100 dollars (so that was what to transfer). Accordingly, the total balance of all accounts will be equal to $ 1,000.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME);
cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC);
try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) {
for (int i = 1; i <= ENTRIES_COUNT; i++)
cache.put(i, new Account(i, 100));
System.out.println("Accounts before transfers");
printAccounts(cache);
printTotalBalance(cache);
for (int i = 1; i <= 100; i++) {
int pairOfAccounts[] = getPairOfRandomAccounts();
transferMoney(cache, pairOfAccounts[0], pairOfAccounts[1]);
}
}
...
privatestaticvoidtransferMoney(IgniteCache<Integer, Account> cache, int fromAccountId, int toAccountId){
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
int amount = getRandomAmount(fromAccount.balance);
if (amount < 1) {
return;
}
fromAccount.withdraw(amount);
toAccount.deposit(amount);
cache.put(fromAccountId, fromAccount);
cache.put(toAccountId, toAccount);
}
Then we make 100 random money transfers between these 10 accounts. For example, from account A to another account B is transferred 50 dollars. Schematically, this process can be depicted as follows:
The system is closed, transfers are made only inside, i.e. The total balance must remain equal to $ 1000.
Run the application.
We received the expected total balance value of $ 1000. Now let's complicate our application a bit - let's make it multi-tasking. In reality, several client applications can run simultaneously with the same account. We will launch two tasks that will simultaneously make money transfers between ten accounts.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME);
cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC);
cfg.setCacheMode(CacheMode.PARTITIONED);
cfg.setIndexedTypes(Integer.class, Account.class);
try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) {
// Initializing the cache.
for (int i = 1; i <= ENTRIES_COUNT; i++)
cache.put(i, new Account(i, 100));
System.out.println("Accounts before transfers");
System.out.println();
printAccounts(cache);
printTotalBalance(cache);
IgniteRunnable run1 = new MyIgniteRunnable(cache, ignite,1);
IgniteRunnable run2 = new MyIgniteRunnable(cache, ignite,2);
List<IgniteRunnable> arr = Arrays.asList(run1, run2);
ignite.compute().run(arr);
}
...
privatevoidtransferMoney(int fromAccountId, int toAccountId){
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
int amount = getRandomAmount(fromAccount.balance);
if (amount < 1) {
return;
}
int fromAccountBalanceBeforeTransfer = fromAccount.balance;
int toAccountBalanceBeforeTransfer = toAccount.balance;
fromAccount.withdraw(amount);
toAccount.deposit(amount);
cache.put(fromAccountId, fromAccount);
cache.put(toAccountId, toAccount);
}
The total balance is $ 1296. Customers are happy, the bank is suffering losses. Why did this happen?
Here we see how two tasks simultaneously change the state of account A. But the second task manages to record its changes before the first one does. Then the first task records its changes, and all changes made by the second task disappear immediately. This anomaly is called the problem of lost updates.
In order for the application to work as needed, it is necessary that our database supports ACID transactions and our code takes this into account.
Let's look at the ACID properties for our application to see why this is so important.
- A - Atomicity, atomicity. Either all proposed changes will be made to the database, or nothing will be entered. That is, if between steps 3 and 6 we had a failure, the changes should not get into the database
- C - Consistency, integrity. After a transaction is completed, the database must remain in a consistent state. In our example, this means that the sum of A and B should always be the same, the total balance is $ 1000.
- I - Isolation, isolation. Transactions should not affect each other. If one transaction makes a transfer and the other receives the value of account A and B after step 3 and before step 6, she thinks that the system has less money than necessary. There are nuances that I’ll focus on later.
- D - Durability, stability. After the transaction has recorded changes in the database, these changes should not disappear as a result of failures.
So, in the transferMoney method, we will make a money transfer within a transaction.
privatevoidtransferMoney(int fromAccountId, int toAccountId){
try (Transaction tx = ignite.transactions().txStart()) {
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
int amount = getRandomAmount(fromAccount.balance);
if (amount < 1) {
return;
}
int fromAccountBalanceBeforeTransfer = fromAccount.balance;
int toAccountBalanceBeforeTransfer = toAccount.balance;
fromAccount.withdraw(amount);
toAccount.deposit(amount);
cache.put(fromAccountId, fromAccount);
cache.put(toAccountId, toAccount);
tx.commit();
} catch (Exception e){
e.printStackTrace();
}
}
Run the application.
Hm Transactions did not help. Overall balance - $ 6951! What is the problem with this behavior of the application?
First, we chose the ATOMIC cache type, i.e. without ACID transaction support:
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME);
cfg.setAtomicityMode(CacheAtomicityMode.АTOMIC);Secondly, the txStart method has two important parameters of the enum type, which it would be good to indicate: a blocking method (concurrency mode in Apache Ignite) and an isolation level. Depending on the values of these parameters, a transaction may read and write data in different ways. In Apache Ignite, these parameters are set as follows:
try (Transaction tx = ignite.transactions().txStart(МЕТОД БЛОКИРОВКИ, УРОВЕНЬ ИЗОЛЯЦИИ)) {
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
...
tx.commit();
}
You can use PESSIMISTIC (pessimistic blocking) or OPTIMISTIC (optimistic blocking) as the value of the BLOCK METHOD parameter. They differ in the moment of imposing of blocking. When using PESSIMISTIC, the lock is imposed at the first reading / writing and is held until the transaction is committed. For example, when a transaction with a pessimistic blocking makes a transfer from account A to account B, other transactions can neither read nor write the values of these accounts until the transaction making the transfer is committed. It is clear that if other transactions want to access accounts A and B, they have to wait for the transaction to complete, which has a negative effect on the overall performance of the application. Optimistic locking does not restrict data access for other transactions, however, during the preparation phase of the transaction for commit (prepare phase, Apache Ignite uses the 2PC protocol), it will be checked whether the data was changed by other transactions? And if changes took place, then the transaction will be canceled. In terms of performance, OPTIMISTIC will work faster, but is more suitable for applications where there is no competitive work with data.
The INSULATION LEVEL parameter determines the degree of transaction isolation from each other. The ANSI / ISO SQL standard defines 4 types of isolation, and for each isolation level the same transaction scenario can lead to different results.
- READ_UNCOMMITED - the lowest level of isolation. Transactions can see "dirty" uncommitted data.
- READ_COMMITTED - when a transaction sees inside itself only private data
- REPEATABLE_READ - means that if a read is performed within a transaction, this read must be repeatable.
- SERIALIZABLE - this level assumes the maximum degree of transaction isolation - as if there are no other users in the system. The result of the work of concurrently running transactions will be as if they were executed in turn (orderly). But together with a high degree of isolation, we get a decrease in performance. Therefore, we must carefully approach the choice of this level of isolation.
For many modern DBMSs (Microsoft SQL Server, PostgreSQL and Oracle), the default isolation level is READ_COMMITTED. For our example, this would be fatal, since it would not protect us from lost updates. The result will be the same as if we did not use transactions at all.
From the Apache Ignite transaction documentation , it follows that such combinations of blocking method and isolation level are suitable for us:
- PESSIMISTIC REPEATABLE_READ - a lock is imposed when you first read or write data and is held until it is complete.
- PESSIMISTIC SERIALIZABLE - works in the same way as PESSIMISTIC REPEATABLE_READ
- OPTIMISTIC SERIALIZABLE - the version of the data obtained after the first reading is remembered, and if this version is different during the preparation phase for fixing (the data was changed by another transaction), then the transaction will be canceled. Let's try this option.
privatevoidtransferMoney(int fromAccountId, int toAccountId){
try (Transaction tx = ignite.transactions().txStart(OPTIMISTIC, SERIALIZABLE)) {
Account fromAccount = cache.get(fromAccountId);
Account toAccount = cache.get(toAccountId);
int amount = getRandomAmount(fromAccount.balance);
if (amount < 1) {
return;
}
int fromAccountBalanceBeforeTransfer = fromAccount.balance;
int toAccountBalanceBeforeTransfer = toAccount.balance;
fromAccount.withdraw(amount);
toAccount.deposit(amount);
cache.put(fromAccountId, fromAccount);
cache.put(toAccountId, toAccount);
tx.commit();
} catch (Exception e){
e.printStackTrace();
}
}Hurray, received $ 1000, as expected. From the third attempt.
We test under load
Now we will make our test more realistic - we will test under load. And add an additional server node. There are many tools for load testing, in Sberbank we use the HP Performance Center. This is quite a powerful tool, supports more than 50 protocols, is designed for large teams and costs a lot of money. I wrote my example on JMeter - it is free and solves our problem 100%. I wouldn’t like to rewrite Java code, so I’ll use the JSR223 sampler.
Let's create a JAR archive from the classes of our application and load it into a test plan. To create and fill the cache, run the class CreateCache. After initializing the cache, you can run the JMeter script.
All cool, got $ 1000.
Emergency stop of the cluster node
Now we will be more destructive: during the operation of the cluster, we will abort one of the two server nodes. Through the utility Visor, which is included in the Gridgain distribution, we can monitor the Apache Ignite cluster and make different data samples. In the SQL Viewer tab, we execute a SQL query in order to get a total balance for all accounts.
What is the result? 553 dollars. Customers are terrified, the bank suffers a reputational loss. What did we do wrong this time?
It turns out that Apache Ignite has cache types:
- partitioned - one or several backup copies are stored within the cluster
- Replicated caches - all partitions (all cache pieces) are stored within one server. Such caches are suitable primarily for reference books - something that rarely changes and is often read.
- local - all on one site
We will frequently change our data, so we will select a partitioned cache and add an additional backup to it. That is, we will have two copies of the data - the main and backup.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME);
cfg.setAtomicityMode(CacheAtomicityMode.TRANSACTIONAL);
cfg.setCacheMode(CacheMode.PARTITIONED);
cfg.setBackups(1);Run the application. I remind you that before transfers we have $ 1000. We launch and, during operation, “extinguish” one of the nodes
In the Visor utility, we make a SQL query to get the total balance - $ 1000. Everything worked great!
Reliability cases
Two years ago we were just starting to test the new IT system of Sberbank. Somehow we went to our support engineers and asked: what could possibly break? We were answered: everything can break, test everything! Of course, this answer did not suit us. We sat down together, analyzed the statistics of failures and realized that the most likely case we could encounter was a node failure.
Moreover, this can happen for completely different reasons. For example, it may fail an application, crash a JVM, crash the OS, or fail the hardware.
We divided all possible cases of failures into 4 groups:
- Equipment
- Network
- Software
- Other
They invented tests for them and called them reliability cases. A typical case of reliability consists of a description of the state of the system before the tests, the steps to reproduce the failure, and a description of the expected behavior during the failure.
Reliability cases: equipment
This group includes such cases as:
- Power failure
- Complete loss of access to the hard disk
- Failure of one hard disk access path
- CPU, RAM, disk, network load
The cluster stores 4 identical copies of each partition: one main partition (primary) and three backup partitions (backup). Suppose, due to a hardware failure, a node is coming out of the cluster. In this case, the main partitions should move to the other surviving nodes.
What else can happen? Loss of rack in the cell.
All cell nodes are in different racks. Those. rack output will not cause cluster failure or data loss. We will have three copies of the four. But even if we lose the whole data center, it will also not be a big problem for us, because we still have two copies of the data from four.
Part of the cases are performed directly in the data center with the participation of maintenance engineers. For example, shutting down the hard drive, turning off the power to the server or rack.
Reliability Cases: Network
For testing cases related to network fragmentation, we use iptables. And with the help of the utility NetEm we emulate:
- network delays with different distribution functions
- packet loss
- repeat packets
- reordering of packets
- packet distortion
Another interesting network case we are testing is split-brain. This is when all cluster nodes are live, but due to network segmentation they cannot communicate with each other. The term came from medicine and means that the brain is divided into two hemispheres, each of which considers itself unique. The same can happen with a cluster.
It happens that the connection between the data centers is lost. For example, last year, due to damage to the fiber optic cable by an excavator, the client of the banks “Tochka”, “Otkritie” and “Roketbank” did not perform operations over the Internet for several hours, the terminals did not accept cards and the ATMs did not work. About this accident, a lot has been written to Twitter.
In our case, the split-brain situation should be handled correctly. The grid identifies the split-brain - the division of the cluster into two parts. One of the halves is translated into read mode. This is half where there are more live nodes or there is a coordinator (the oldest node in the cluster).
Reliability Cases: Software
These cases are associated with the failure of various subsystems:
- DPL ORM - data access module, type Hibernate ORM
- Intermodular transport - messaging between modules (microservices)
- Logging system
- Access granting system
- Apache Ignite Cluster
- ...
Since most of the software is written in Java, we are subject to all the problems inherent in Java applications. Tests various garbage collector settings. We carry out tests with the fall of the java virtual machine.
For the Apache Ignite cluster, there are special cases for off-heap - this is such a memory area that Apache Ignite controls. It is much more than java heap and is intended for storing data and indexes. Here you can, for example, test overflow. We overflow the off-heap and see how the cluster works in the case where some of the data did not fit into the RAM, i.e. read from disk.
Other cases
These are cases that are not included in the first three groups. These include utilities that allow you to recover data in the event of a major crash or when migrating data to another cluster.
- The utility for creating snapshots (backup) of data is testing full and incremental snapshots.
- Recovery to a specific point in time is the PITR (Point in-time recovery) mechanism.
Utilities for fault injection
I recall a link to examples from my report. You can download the Apache Ignite distribution from the official site - Apache Ignite Downloads . And now I will share the utilities that we use at Sberbank, if you are suddenly interested in the topic.
Frameworks:
Configuration Management:
Linux utilities:
- NetEm (tc)
- stress-ng
- Iperf
- kill -9
- iptables
Load testing tools:
Both in the modern world and in Sberbank, all changes occur dynamically and it is difficult to predict which technologies will be used in the next couple of years. But I know for sure that we will use the Fault Injection method. The universal method is suitable for testing any technologies, it really works, it helps to catch a lot of bugs and make the products that we develop better.