How does neural machine translation work?
- Transfer
Description of the processes of machine translation based on rules (Rule-Based), machine translation based on phrases (Phrase-Based) and neural translation

In this publication of our step-by-step series of articles, we will explain how neural machine translation works and compare it with other methods: rule-based translation technology and frame translation technology (PBMT, the most popular subset of which is statistical machine translation - SMT).
The results obtained by Neural Machine Translation are surprising in terms of decoding the neural network. It seems that the network actually “understands” the sentence when translating it. In this article, we will discuss the issue of the semantic approach that neural networks use for translation.
Let's start by looking at the working methods of all three technologies at different stages of the translation process, as well as the methods that are used in each case. Next, we will get acquainted with some examples and compare what each technology does in order to produce the most correct translation.
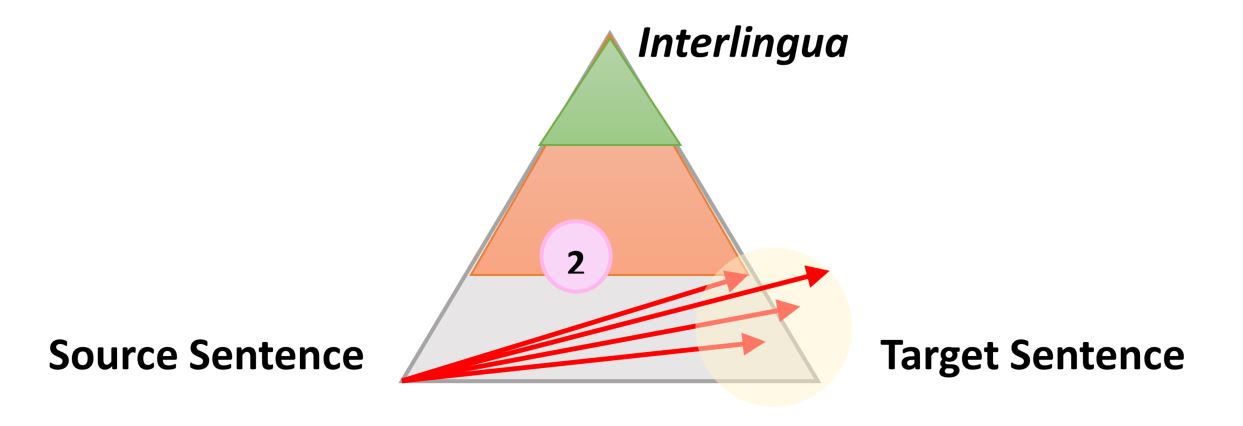
Very simple, but still useful information about the process of any type of automatic translation is the following triangle, which was formulated by the French researcher Bernard Vauquois in 1968:
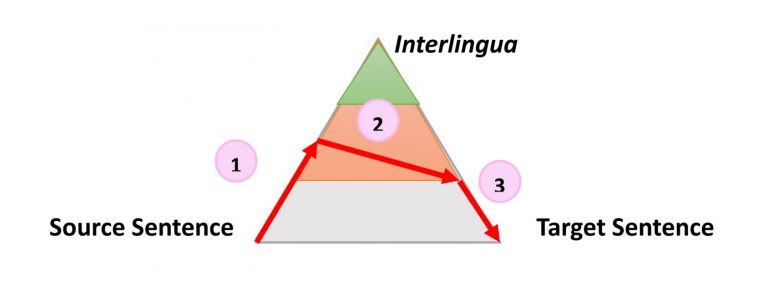
This triangle displays the process of converting the source sentence to the target in three different ways.
The left side of the triangle characterizes the source language, while as the right - the target. The difference in levels within the triangle represents the depth of the process of analyzing the original sentence, for example syntactic or semantic. Now we know that we cannot separately conduct syntactic or semantic analysis, but the theory is that we can delve into each direction. The first red arrow indicates the analysis of the sentence in the original language. From the sentence given to us, which is just a sequence of words, we can get an idea of the internal structure and degree of the possible depth of analysis.
For example, on one level we can determine the parts of speech of each word (noun, verb, etc.), and on the other - the interaction between them. For example, which word or phrase is subject.
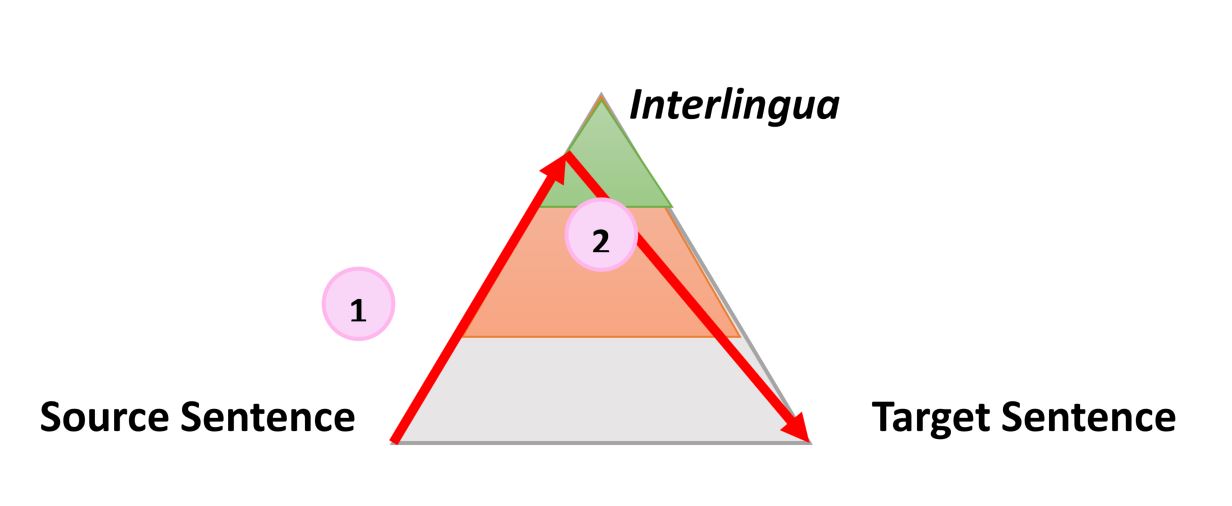
When the analysis is completed, the sentence is “transferred” by the second process with equal or lesser depth of analysis to the target language. Then the third process, called “generation”, forms the actual target sentence from this interpretation, that is, creates a sequence of words in the target language. The idea of using a triangle is that the higher (deeper) you analyze the original sentence, the easier the transfer phase goes. Ultimately, if we could transform the source language into some kind of universal “interlingualism” during this analysis, we would not need to carry out the transfer procedure at all. We would only need an analyzer and generator for each translated language into any other language (direct translation approx. Transl.)
This general idea explains the intermediate stages when the machine translates sentences step by step. More importantly, this model describes the nature of the actions during the translation. Let's illustrate how this idea works for three different technologies, using the sentence “The smart mouse plays violin” as an example. (The sentence chosen by the authors of the publication contains a small catch, since the word “Smart” in English, except for the most common meaning “smart” , has another 17 meanings in the dictionary as an adjective, for example, “agile” or “dexterous” approx.
Rule Based Machine Translation
Rule-based machine translation is the oldest approach and covers a wide variety of technologies. However, all of them are usually based on the following postulates:
- The process strictly follows the Wokua triangle, the analysis is very often overestimated, and the generation process is minimized;
- All three stages of translation use a database of rules and lexical elements to which these rules apply;
- Rules and lexical elements are uniquely defined, but can be changed by a linguist.
For example, the internal representation of our proposal may be as follows:
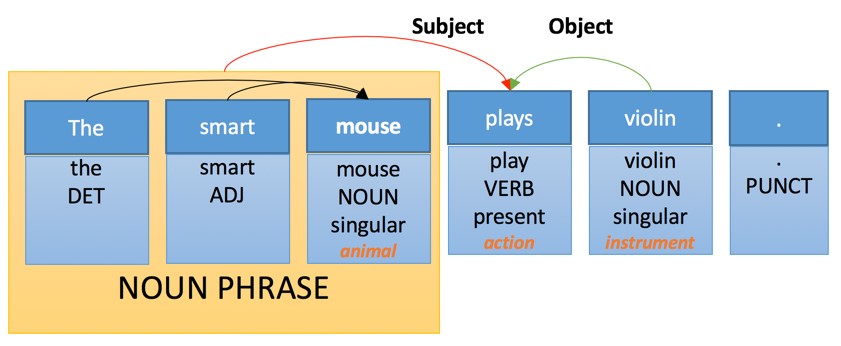
Here we see several simple levels of analysis:
- Targeting parts of speech. Each word is assigned its own "part of speech", which is a grammatical category.
- Morphological analysis: the word “plays” is recognized as a third-person distortion and represents the form of the verb “Play”.
- Semantic analysis: some words are assigned a semantic category. For example, “Violin" is a tool.
- Compound analysis: some words are grouped. “Smart mouse” is a noun.
- Dependency analysis: words and phrases are associated with “links”, through which the object and subject of action of the main verb “Plays” are identified.
The transfer of such a structure will be subject to the following lexical transformation rules:

Application of these rules will lead to the following interpretation in the target translation language:
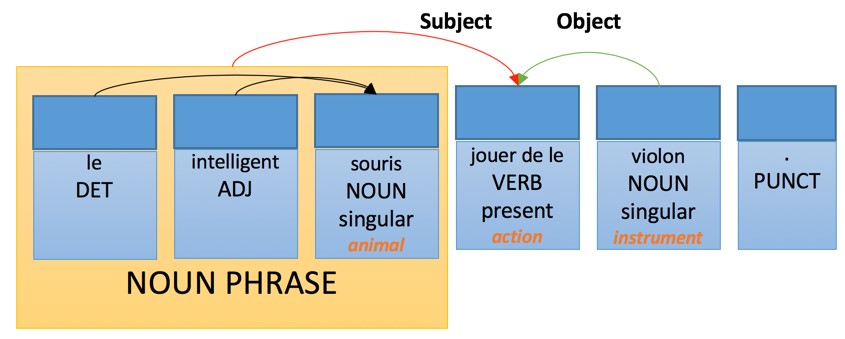
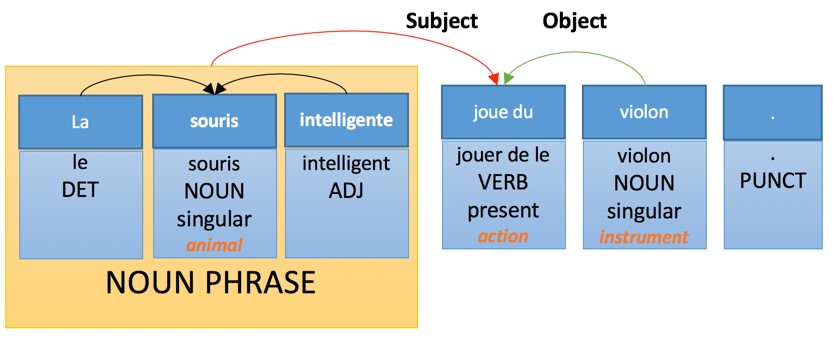
Whereas the generation rules in French will have the following form:
- An adjective expressed by a phrase follows a noun with a few exceptions.
- The defining word is consistent in number and gender with the noun that it modifies.
- The adjective is consistent in number and gender with the noun that it modifies.
- The verb is consistent with the subject.
Ideally, this analysis will generate the following translation version:
Phrase-based machine translation
Phrase-based machine translation is the simplest and most popular version of statistical machine translation. Today, it is still the main “workhorse" and is used in major online translation services.
Technically speaking, phrase-based machine translation does not follow the process formulated by Wokua. Not only that, in the process of this type of machine translation no analysis or generation is carried out, but, more importantly, the subordinate part is not deterministic. This means that the technology can generate several different translations of the same sentence from the same source, and the essence of the approach is to choose the best option.
This translation model is based on three basic methods:
- The use of a phrase table, which gives the translation options and the probability of their use in this sequence in the source language.
- A reordering table that indicates how words can be rearranged when translating from source to target language.
- A language model that shows the probability for each possible sequence of words in the target language.
Consequently, the following table will be built on the basis of the initial sentence (this is a simplified form, in reality there would be many more options associated with each word):
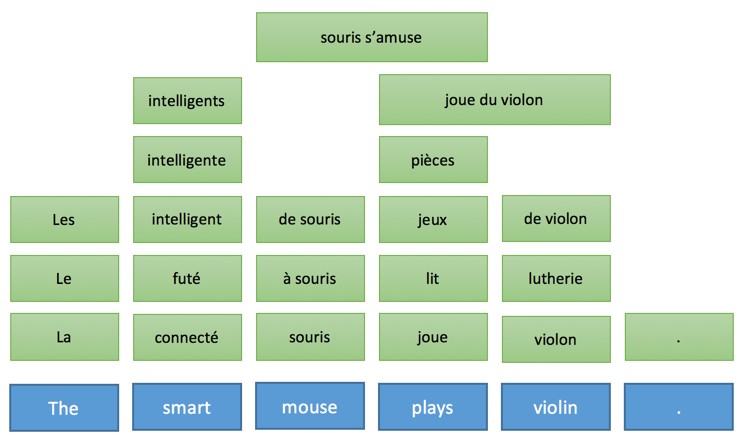
Next, from this table thousands of possible options for translating the sentence are generated, for example:
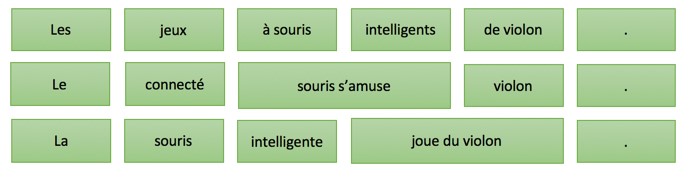
However, due to intelligent calculations of the probability and use of more perfect search algorithms, only the most likely translation options will be considered, and the best will be preserved as the final one.
In this approach, the target language model is extremely important and we can get an idea of the quality of the result by simply searching the Internet:

Search algorithms intuitively prefer to use sequences of words, which are the most likely translations of the original, given the table of order changes. This allows you to generate the correct sequence of words in the target language with high accuracy.
There is no explicit or implicit linguistic or semantic analysis in this approach. We were offered many options. Some of them are better, others are worse, but as far as we know, the main online translation services use this particular technology.
Neural Machine Translation
The approach to organizing a neural machine translation is fundamentally different from the previous one and, based on the Wokua triangle, it can be described as follows:
Neural machine translation has the following features:
- “Analysis” is called coding, and its result is a mysterious sequence of vectors.
- “Transfer” is called decoding and directly generates the target shape without any generation phase. This is not a strict limitation and there may be variations, but the underlying technology works just that.
The process itself is divided into two phases. In the first, each word of the original sentence passes through a “coder”, which generates what we call the “initial context”, relying on the current word and the previous context:
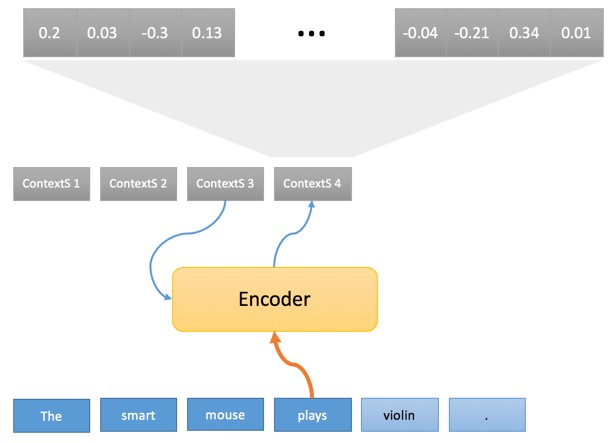
The sequence of the initial contexts (ContextS 1, ... ContextS 5) is an internal interpretation of the original sentence along the Wokua triangle and, as mentioned above, is a sequence of floating point numbers (usually 1000 floating point numbers associated with each source word). While we will not discuss how the encoder performs this conversion, we would like to note that the initial conversion of words in the “float” vector is especially interesting.
This is actually a technical unit, as in the case of the rules-based translation system, where each word is first compared with a dictionary, the first step of the encoder is to search for each source word inside the table.
Suppose you need to imagine different objects with variations in shape and color in two-dimensional space. In this case, the objects closest to each other should be similar. The following is an example:
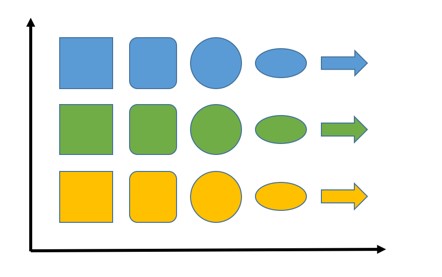
Shapes are represented on the abscissa axis and there we try to place objects of a different shape closest in this parameter (we will need to indicate what makes the shapes similar, but in the case of this example it seems intuitive). The ordinate is the color - green between yellow and blue (located so because green is the result of mixing yellow and blue, approx. Per.). If our figures had different sizes, we could add this third parameter as follows:
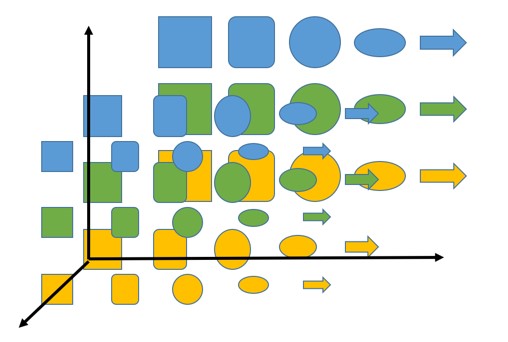
If we add more colors or shapes, we can also increase the number of dimensions so that any point can represent different objects and the distance between them, which reflects the degree of similarity.
The basic idea is that this also works when placing words. Instead of shapes, there are words, space is much larger - for example, we use 800 dimensions, but the idea is that words can be represented in these spaces with the same properties as shapes.
Consequently, words with common properties and attributes will be located close to each other. For example, one can imagine that the words of a certain part of speech are one dimension, the words based on gender (if any) are different, there may be a sign of positive or negative meaning and so on.
We do not know exactly how these investments are formed. In another article, we will analyze the investments in more detail, but the idea itself is as simple as organizing figures in space.
Back to the translation process. The second step has the following form:
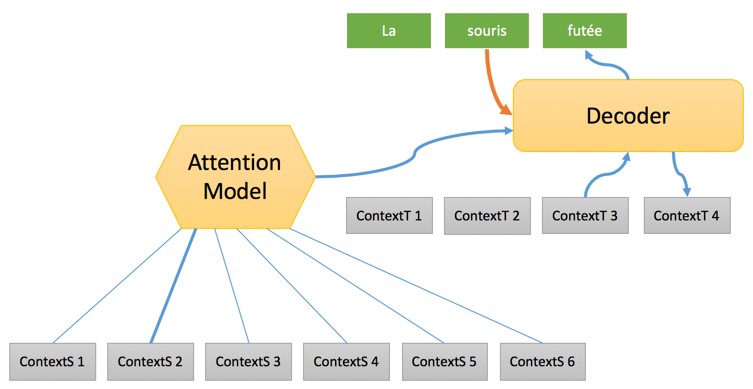
At this stage, a complete sequence is formed with emphasis on the “initial context”, after which target words are generated one by one using:
- “Target context”, formed in conjunction with the previous word and providing some information about the status of the translation process.
- The significance of the "contextual source", which is a mixture of various "source contexts" based on a specific model called the "Attention Model". What is this we will analyze in another article. In short, Attention Models select the source word for use in translation at any stage of the process.
- A previously given word using an embedding of words to convert it into a vector that will be processed by the decoder.
The translation is completed when the decoder reaches the stage of generating the actual last word in the sentence.
The whole process is undoubtedly very mysterious, and we will need several publications to consider the work of its individual parts. The main thing to keep in mind is that the operations of the neural machine translation process are arranged in the same sequence as in the case of machine translation based on the rules, however, the nature of the operations and processing of objects is completely different. And these differences begin with the conversion of words into vectors through their embedding in tables. Understanding this point is enough to realize what is happening in the following examples.
Translation examples for comparison
Let's look at some translation examples and discuss how and why some of the proposed options do not work with different technologies. We have selected several polysemic (i.e. polysemantic, approx. Transl.) Verbs of the English language and study their translation into French.

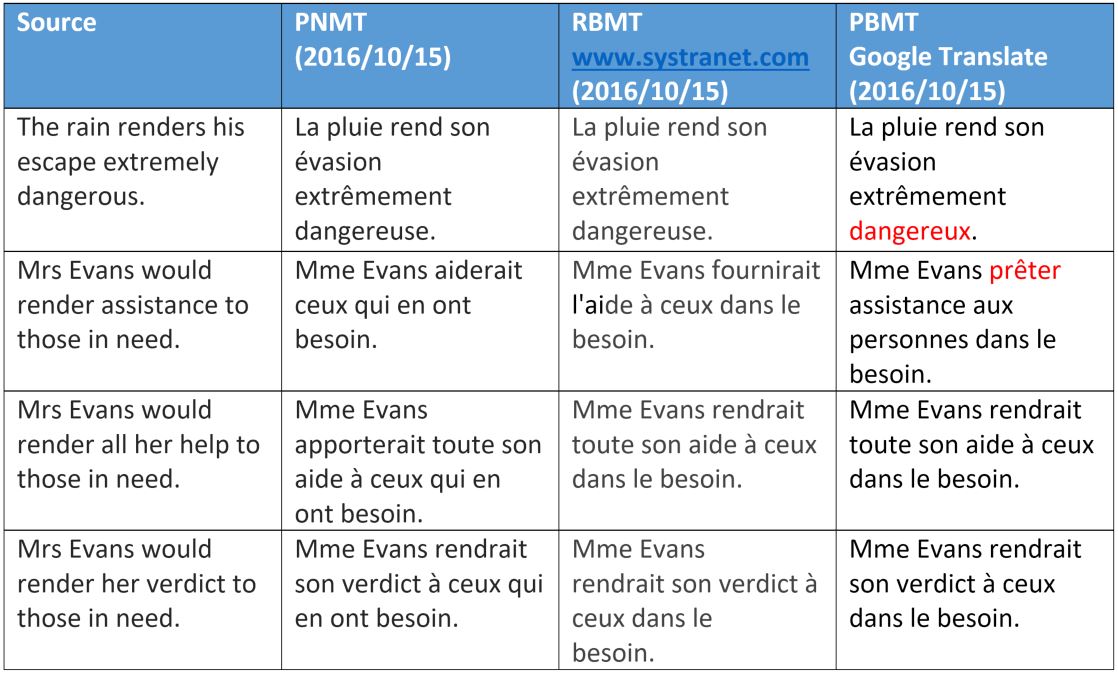
We see that machine translation based on phrases interprets “render” as meaning - with the exception of the very idiomatic version of “assisting”. This can be easily explained. The choice of value depends either on checking the syntactic meaning of the sentence structure or on the semantic category of the object.
For neural machine translation, it can be seen that the words “help” and “assistance” are processed correctly, which shows some superiority, as well as the obvious ability of this method to receive syntax data at a large distance between words, which we will examine in more detail in another publication.

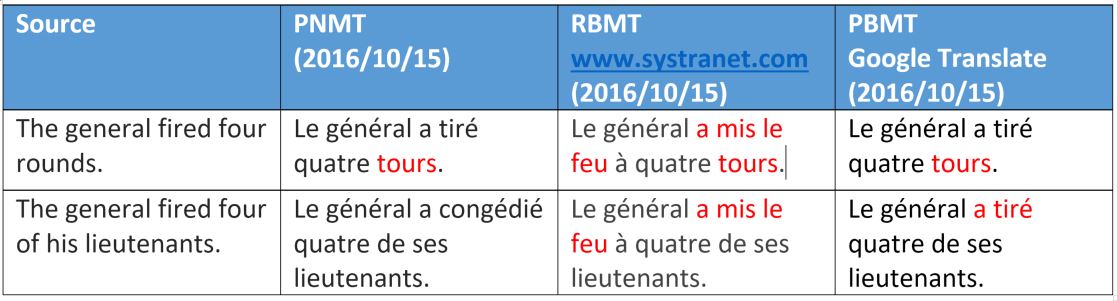
This example again shows that neural machine translation has semantic differences with two other methods (mainly they relate to animation, denotes the word of a person or not).
However, we note that the word “rounds” was incorrectly translated, which in this context has the meaning of the word “bullet”. We will explain this type of interpretation in another article on training neural networks. As for the rule-based translation, he recognized only the third meaning of the word “rounds”, which is applied to missiles, not bullets.

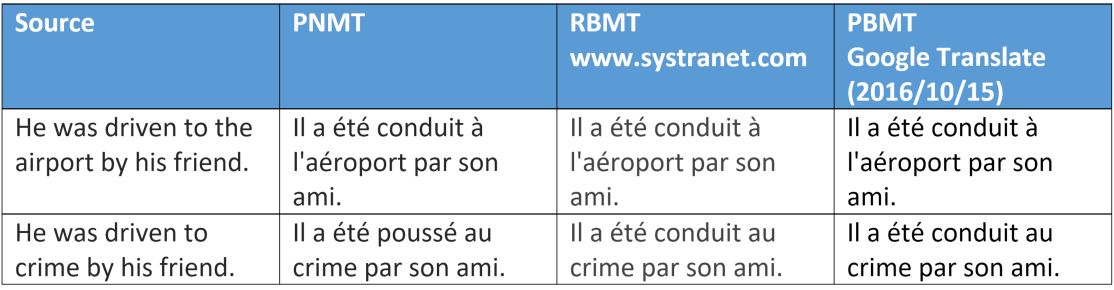
The above is another interesting example of how the semantic variations of the verb during the neural translation interact with the object in the case of the unambiguous use of the word proposed for translation (crime or destination).
Other variants with the word “crime” showed the same result ...
Translators working on the basis of words and phrases were also not mistaken, because they used the same verbs acceptable in both contexts.