How to distinguish shampoo from champignons, and skewers from champagne ... Elasticsearch - search for products in store databases
Task
One of the main tasks of the application for storing and analyzing purchases is to search for identical or very close products in the database, where various assorted and incomprehensible product names obtained from checks are collected. There are two types of input request:
- A specific name with abbreviations that can only be understood by cashiers at a local supermarket, or by avid shoppers.
- A query in natural language entered by the user into the search string.
Requests of the first type, as a rule, come from the products in the check itself, when the user needs to find cheaper products. Our task is to select the most similar analogue of the goods from the check in other stores nearby. Here it is important to choose the most appropriate brand of product and, if possible, volume.
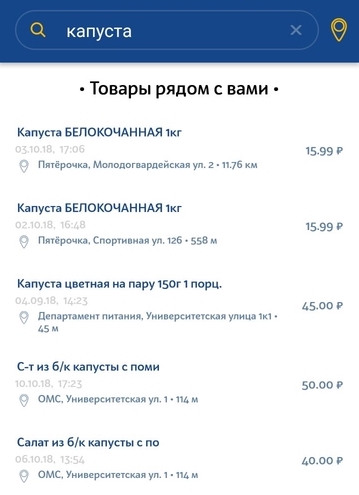
The second type of request is a simple user request to search for a specific product in the nearest store. The request can be a very general, non-uniquely describing product. There may be slight deviations from the request. For example, if a user is looking for milk at 3.2%, and in our database there is only milk at 2.5%, then we still want to show at least this result.
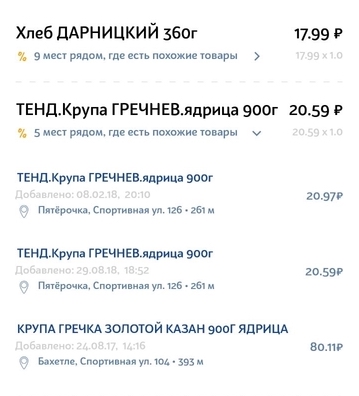
Features dataset - problems to solve
The information in the product check is far from perfect. There are many not always clear abbreviations, grammatical errors, misprints, various translites, Latin letters among the Cyrillic alphabet and character sets that make sense only for the internal organization in a particular store.
For example, a baby apple-banana puree with cottage cheese can easily be written on the check like this:

About technology
Elasticsearch is a fairly popular and affordable technology for implementing a search. This is a search engine with JSON REST API using Lucene and written in Java. The main advantages of Elastic are speed, scalability and fault tolerance. Similar engines are used for complex search in the database of documents. For example, search taking into account the morphology of the language or search by geo-coordinates.
Directions for Experiments and Improvements
To understand how you can improve your search, you need to parse the search system into its component customizable components. For our case, the structure of the system looks like this.
- The input string for the search passes through the analyzer, which in a certain way splits the string into tokens - search units that are searched among data that is also stored as tokens.
- Then there is a direct search for these tokens for each document in the existing database. After finding a token in a particular document (which is also represented in the database as a set of tokens), its relevance is calculated according to the selected Similarity model (we will call it the relevance model). This may be a simple TF / IDF (Term Frequency - Inverse Document Frequency), and there may be other more complex or specific models.
- In the next step, the number of points scored by each individual token is aggregated in a certain way. Aggregation parameters are specified by query semantics. An example of such aggregations can be additional weights for certain tokens (added value), conditions for the mandatory presence of a token, and so on. The result of this stage is Score - the final assessment of the relevance of a particular document from the database relative to the initial request.

Three separately configurable components can be distinguished from the search device, each of which can be distinguished with its own ways and means of improvement.
- Analyzers
- Similarity model
- Query-time improvements
Next, we consider each component separately and analyze the specific settings of parameters that helped improve the search in the case of product names.
Query-time improvements
To understand what we can improve in the query, we give an example of the initial query.
{
"query": {
"multi_match": {
"query": "кетчуп хайнц 105г",
"type": "most_fields",
"fields": ["name"],
"minimum_should_match": "70%"
}
},
“size”: 100,
“min_score”: 15
}We use the most_fields query type, since we foresee the need for a combination of several analyzers for the “product name” field. This type of query allows you to combine search results for different attributes of an object containing the same text, analyzed in different ways. An alternative to this approach is the use of best_fields or cross_fields queries, but they are not suitable for our case, since the search among the various attributes of the object is calculated (eg: name and description). We are faced with the task of taking into account different aspects of one attribute - the name of the product.
What can be configured:
- Weighted combination of various analyzers.
Initially, all search elements have the same weight - and therefore, the same significance. This can be changed by adding the 'boost' parameter, which takes numeric values. If the parameter is greater than 1, the search element will have a greater impact on the results, respectively, less than 1 - less. - Separating analyzers into 'should' and 'must'.
Namely, certain analyzers must match, and some must be optional, that is, insufficient. In our case, an example of the benefits of such a separation could be a number analyzer. If the product name in the query and the product name in the database match only the number, then this is not a sufficient condition for their equivalence. We do not want to see such products as a result. At the same time, if the request is “cream 10%”, then we want all cream with 10% fat to have a big advantage over cream with 20% fat. - Parameter minimum_should_match. How many tokens must necessarily match in the request and the document from the database? This parameter works together with the type of our query (most_fields) and checks the minimum number of matching tokens for each of the fields (in our case, for each analyzer).
- The min_score parameter. Threshold, eliminating documents with insufficient points. The catch is that there is no known maximum rate. The resulting Score depends on the specific request and on the specific database of documents. Sometimes it can be 150 and sometimes 2, but both of these values will mean that the object from the database is relevant to the query. We cannot compare the speeds of the results of different queries.
- Constant.
After sufficient observation of the total scores for different queries, it is possible to identify an approximate limit, after which the results become unsuitable for most queries. This is the easiest, but also the most stupid solution that leads to poor-quality search. - Attempt to analyze the obtained rates for a specific query after the search with the minimum or zero min_score.
The idea is that after a certain point you can see a sharp jump in the direction of decreasing the skora. It remains only to determine this jump in order to stop in time. Such an approach would work well on such queries: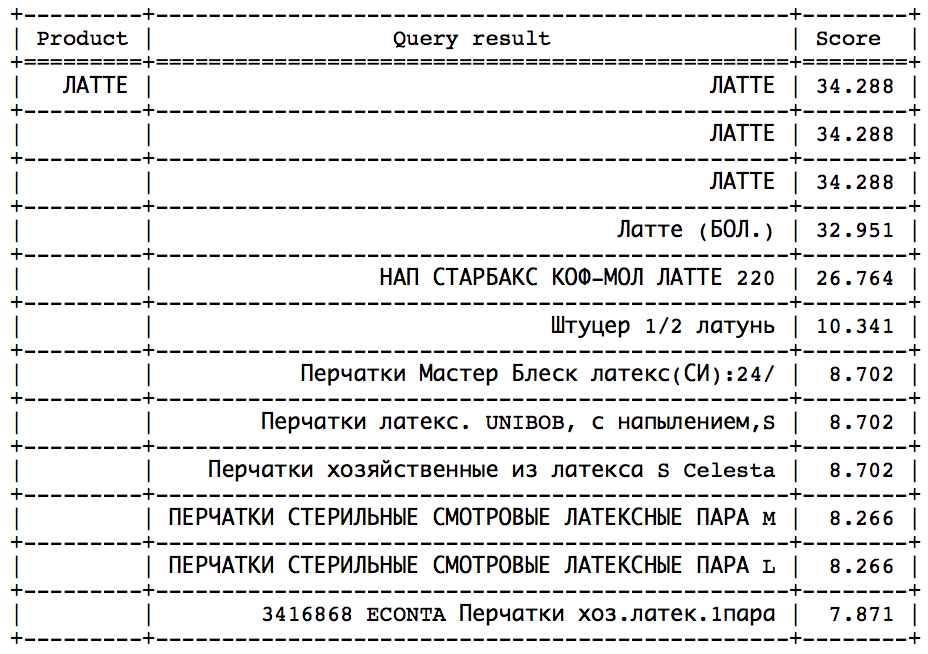
The jump can be found by statistical methods. But, unfortunately, not all requests have this jump present and are easy to define. - Calculate the ideal speed and set min_score as a certain percentage of the ideal, which can be done in two ways:
- From the detailed description of the calculations provided by Elastic itself when setting the parameter explain: true. This is a difficult task, requiring a comprehensive understanding of the query architecture and algorithms for computing used by Elastic.
- By a little tricks. We receive a request, add a new product to our database with the same name, do a search and get the maximum speed. Since there will be a 100% match in the name, the resulting value will be perfect. It is this approach that we use in our system, since the concerns about the high cost of this operation in relation to time have not been confirmed.
- Constant.
- Change scoring algorithm, which is responsible for the total value of relevance. This may be taking into account the distance to the store (give more points to products that are closer), prices of goods (give more points to products with the most likely price) and so on.
Analyzers
The analyzer analyzes the input line in three stages and issues tokens at the output - search units:

First, changes occur at the character level of the string. This can be a replacement, delete or add characters to the string. Then the tokenizer comes into play, which is designed to divide the string into tokens. Standard tokenizer splits a string into tokens according to punctuation marks. The final step is to get the tokens filtered and processed.
Consider what variations of stages have become useful in our case.
Char filters
- According to the specifics of the Russian language, it would be useful to process such characters as nd and ё and replace them with and and e, respectively.
- Transliteration is the transmission of characters from one script by characters from another. In our case, this is the processing of names written in Latin or interspersed with both alphabets. Transliteration can be implemented using a plug-in ( ICU Analysis Plugin ) as a token filter (that is, it does not process the original string, but the final tokens). We decided to write our own transliteration, as we were not quite happy with the algorithm in the plugin. The idea is to first replace the four-character set entries (eg, "SHCH => y"), then the three-character, etc. The order in which the character filters are applied is important, since the result will depend on the order.
- Replace the Latin c, surrounded by Cyrillic, with the Russian with. The need for this was revealed after analyzing the names in the database - very many names in Cyrillic included Latin c, which means Cyrillic c. When, as if the name is completely in Latin, then Latin c means Cyrillic k or c. Therefore, before transliterating, it is necessary to replace the character c.
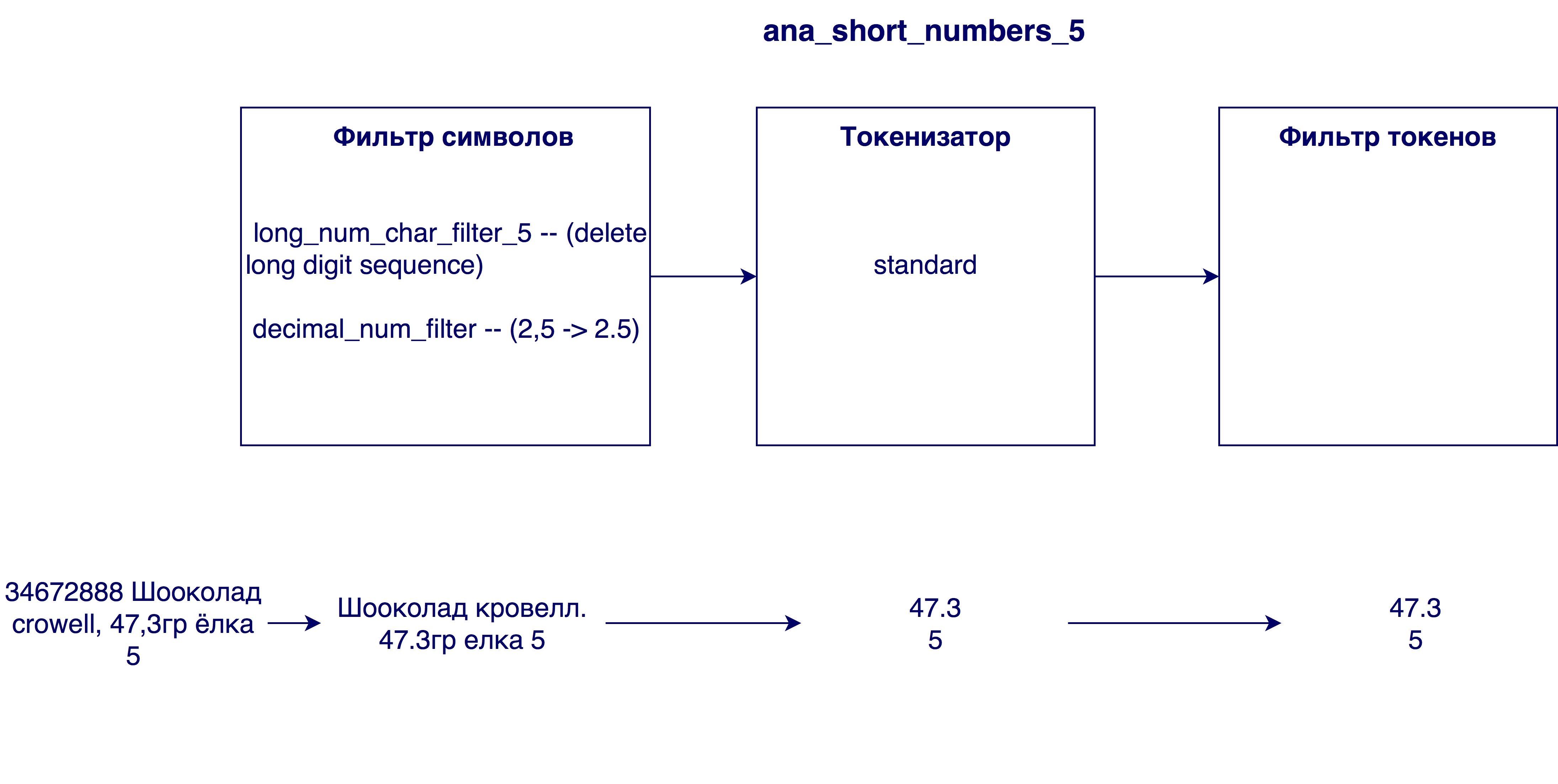
- Removing too large numbers from titles. Sometimes in the names of products there is an internal identification number (for example, 3387522 K.Ts. Sunflower oil. 0.9l oil), which does not carry any meaning in the general case.
- Replace commas with dots. Why do you need it? So that numerals, such as milk fat 3.2 and 3.2, are equivalent
Tokenizer
- Standard Tokenizer - splits lines according to the space and punctuation marks (eg, "Twix Extra 2” -> “Twix”, “Extra”, “2”)
- EdgeNGram tokenizer - breaks each word into tokens of a given length (usually a range of numbers), starting with the first character (for example, for N = [3, 6]: "tweaks extra 2" -> "twi", "tweak", “Twix”, “Ex”, “Ext”, “Extra”, “Extra”)
- Tokenizer for numbers - selects only numbers from a string by searching for a regular expression (eg, "Twix Extra 2 4.5" -> "2", "4.5")
Token filter
- Lowercase filter
- Stemming filter - performs a stemming algorithm for each token. Stemming is to determine the initial form of the word (eg, “rice” -> “rice”)
- Phonetic analysis. It is necessary in order to minimize the effect of typos and different ways of writing the same word on search results. The table presents the various algorithms available for phonetic analysis and the result of their work in problem cases. In the first case (Shampoo / champagne / champignon / champignons) success is determined by the generation of different encodings, in the others - the same.

Similarity model
The relevance model is needed in order to determine to what extent the coincidence of one token affects the relevance of an object from the base in relation to the query. Suppose if in the request and the product from the database the token 'for' coincides, this is certainly not bad, but it says little about the compliance of the product with the request. Thus, the coincidence of different tokens carries different values. In order to take this into account and need a relevancy model. Elastic provides many different models. If you understand the truth in them, then you can choose a very specific and suitable model for a specific case. The choice can be based on the number of frequently used words (by the type of the same token 'for'), assessment of the importance of long tokens (longer means better? Worse? Doesn't matter?), What results we want to see at the end, etc. Examples of modelsOkapi BM25 (improved TF-IDF, default model), Divergence from randomness, Divergence from independence and so on. Each model also has customizable parameters. After several experiments with the model, the Okapi BM25 default model showed the best result, but with different parameters from the pre-set ones.
Use of categories
In the course of the search operation, a very important additional information about the product became available - its category. You can read more about how we implemented categorization in the article How I understood that I eat a lot of sweets, or the classification of goods by check in the appendix . Until then, we based our search only on the comparison of the names of goods, it is now possible to compare the category of the request and the goods in the database.
Possible options for using this information are a mandatory match on the category category (drawn up as a result filter), an additional advantage in the form of points to products with a matching category (as is the case with numbers) and sorting the results by category (first matching, then all the others). For our case, the last option worked best. This is due to the fact that our categorization algorithm is too good to use the second method, and not good enough to use the first one. We are confident enough in the algorithm and want to match the category was a big advantage. If additional points are added to the score (the second method), goods with the same category will go up in the list, but they will still lose to some goods that more coincided in name. However, the first method does not suit us either, since errors in categorization are still not excluded. Sometimes a request may contain insufficient information to correctly determine the category, or there are too few products in this category in the nearest radius of the user. In this case, we still want to show results with a different category, but still relevant to the product name.
The second method is also good because it does not “spoil” the speed of the products as a result of the search, and allows you to continue to use the calculated minimum rate without obstacles.
The specific implementation of sorting can be seen in the final query.
Final model
The selection of the final search model included the generation of various search engines, their evaluation and comparison. Most often, the comparison took place in one of the parameters. Suppose in one particular case we needed to calculate the best size for the edgeNgram tokenizer (that is, to select the most efficient range N). To do this, we generated the same search engines with only one difference in the size of this range. After that it was possible to identify the best value for this parameter.
The models were evaluated using the nDCG (normalized discounted cumulative gain) metric - a metric for assessing the quality of ranking. Predefined queries were sent to each search model, after which the nDCG metric was calculated using the search results obtained.
Analyzers that are included in the final model:



The default model (Okapi - BM25) with the parameter b = 0.5 was chosen as the relevance model. The default value is 0.75. This parameter shows to what extent the length of the product name normalizes the tf (term frequency) variable. A smaller number in our case works better, since a long name very often does not affect the significance of a single word. That is, the word “chocolate” in the title “chocolate with crushed hazelnuts in a package of 25pcs” does not lose its value because the name is rather long.
The final query looks like this:
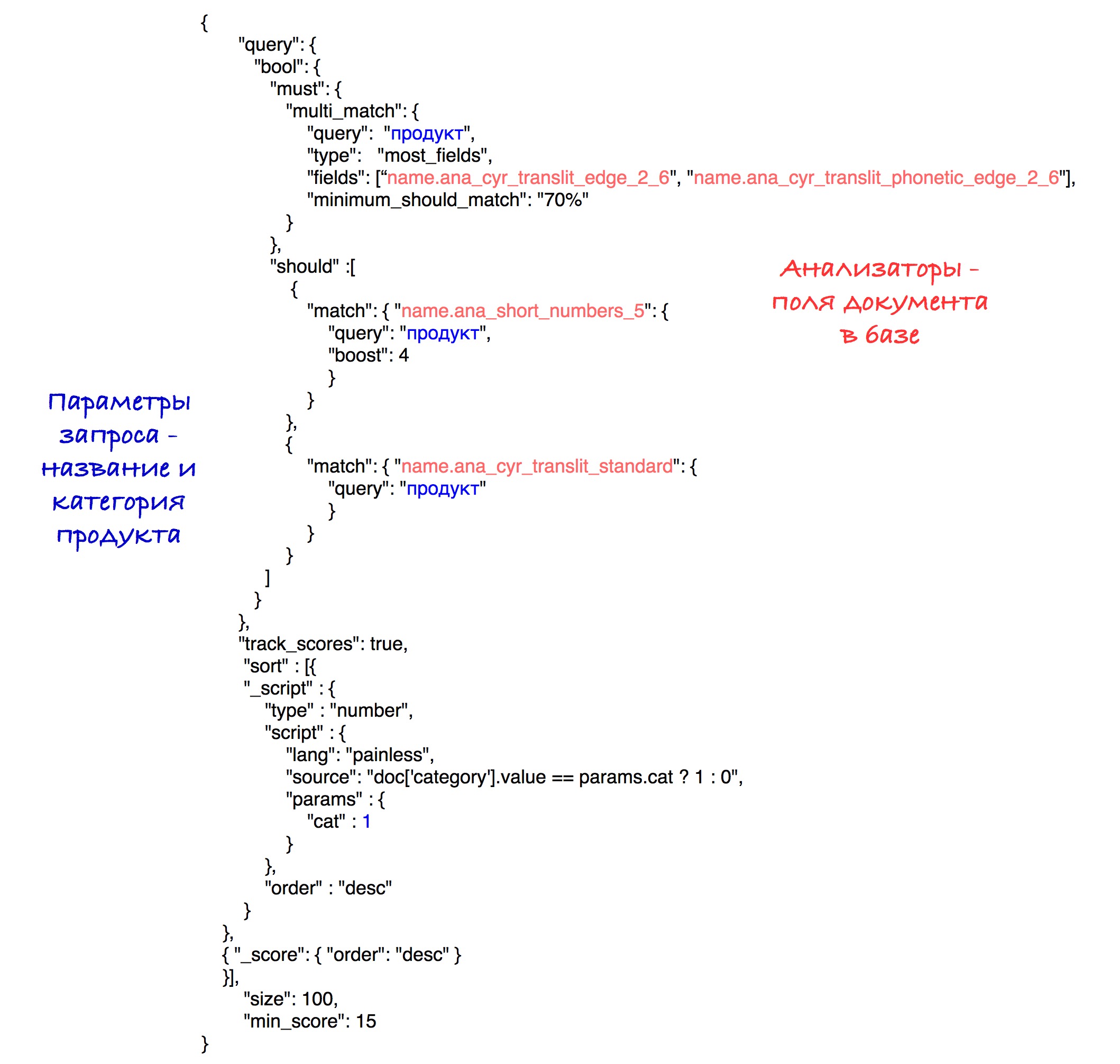
Experimentally, the best combination of analyzers and weights was identified.
As a result of sorting, products with a matching category go to the beginning of the results, and then all the others. Sorting by the number of points (soon) is stored within each subset.
For simplicity, this query specifies a threshold for a score of 15, although in our system we use the calculated parameter that was described earlier.
In future
There are thoughts to improve the search by solving one of the most embarrassing problems of our algorithm, which is the existence of a million and one different way to shorten a word of 5 letters. It can be solved by first processing the names in order to reveal the abbreviations. One of the solutions is an attempt to compare the abbreviated name from our database with one of the names from the database with the “correct” full names. This decision meets its own specific obstacles, but it seems a promising change.