Smart stubs for integration
Gone are the days when banking systems were large monolithic applications that were slowly updated to meet the requirements of the regulator. Now it is hundreds of interacting subsystems and thousands of modules that are constantly developing along with new business requirements and rapidly changing IT space. Hundreds of individual combat units — Agile teams — have been thrown into developing all of this.

Fancy it? Yes, breathtaking. Nevertheless, these are the usual workdays of the developers of the Unified Frontal System of Sberbank. Two hundred teams are simultaneously engaged in the development of the platform, daily solving complex and non-trivial tasks aimed at optimizing and synchronizing processes.
We can talk about synchronization and optimization for a long time, this topic deserves a separate book. In this article, we will cover only a small part - optimization of the development of integration interaction, share our experience and tell you how to integrate with hundreds of systems and not wait for anyone.
The question that concerns us in the first place is how do all teams, each of which depends on many other teams, manage to make their development efficiently, in compliance with all deadlines, and in order to get the expected result when docking with adjacent systems at the integration training ground?
And we found two answers to it: a single information space and the maximum automation of development and deployment.
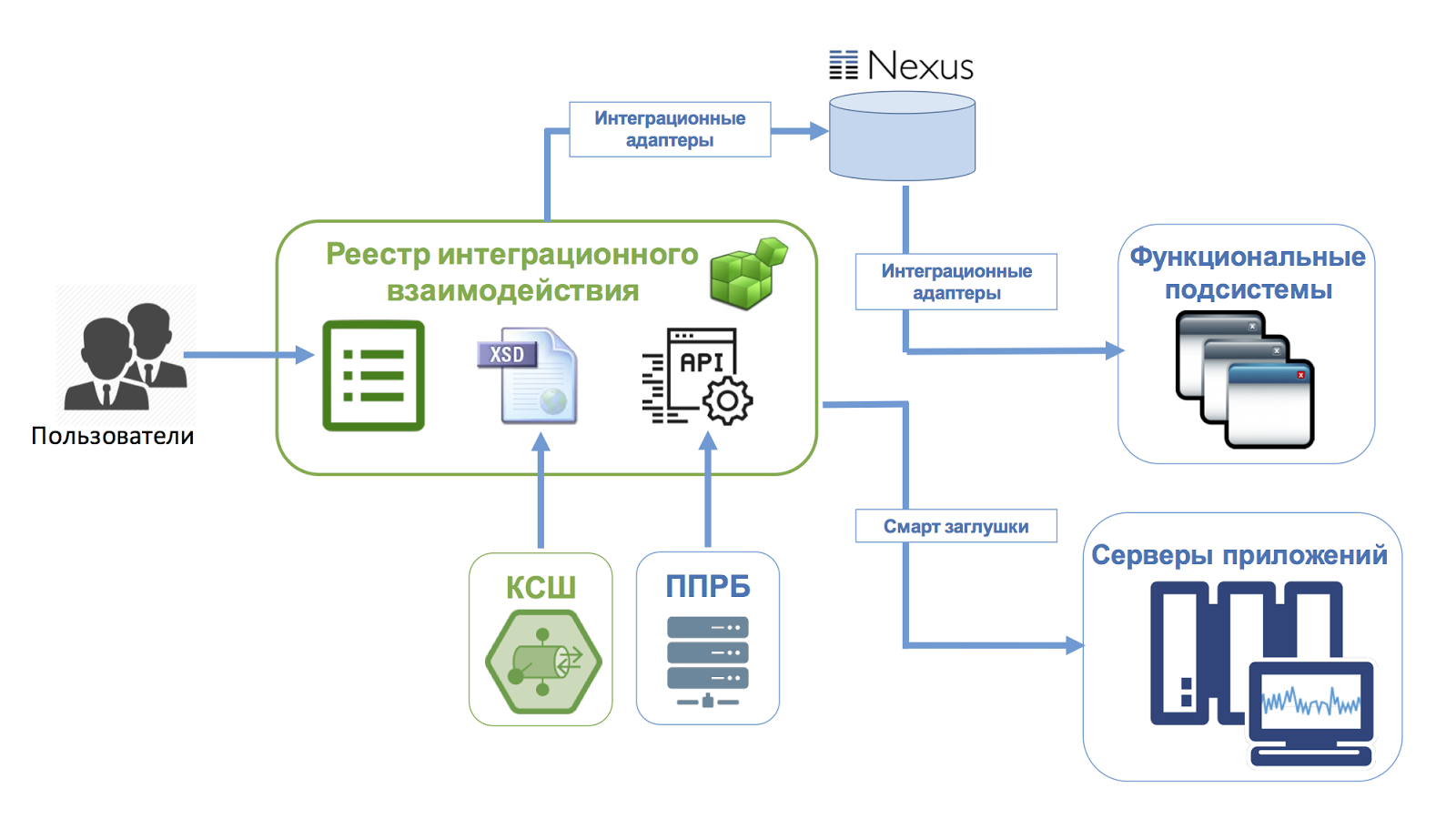
Now our integration center is the “Unified Register of Integration Interaction”. The registry contains information on all subsystems and services, details of integration interaction, attributive structure, description of data sources and usage register, formats, protocols and other characteristics necessary for an accurate and unambiguous description of each interaction. In addition, it is associated with similar registries of other bank systems. All this forms a single information space.
With a single information space it’s clear, what about automation? The more code is generated automatically, the lower the cost and the higher the quality of the final product. For the development of integration interaction, this is doubly important, since many individually developed systems must interact together and understand each other.
As you probably guessed, the registry of integration interaction is needed not only for reference information. Based on the registry data, the automatic generation of integration components (integration layer) occurs. This saves teams from additional routine development, forms a single integration architecture and ensures coordination of interaction according to the announced contracts.
Yes, it’s really convenient, but that’s not all. The team brought all its integrations into the registry, received the generated integration layer and ... stop. The functionality of the modules developed by the team depends on related systems that are themselves in the development process. How to be? In addition, at the end of the sprint, the Product owner will want to see the result of the team. Perhaps, along with stakeholders, he wants to make some backlog adjustments. Agile, after all.
That's right, you need to drown out the missing integration interactions. And then all the teams rushed to write their stubs.
Time is sorely lacking, there is a great temptation to drown out the interaction, spending minimal effort. For example, add the return of the result directly to the code of the calling function. It’s not entirely honest, we agree, but you don’t have to spend time writing individual components, deploy and configure various message brokers. Yes, a lot will have to be changed at the next sprint, yes, there is no guarantee that adjacent systems will work similarly to this implementation, but there is no time - you need to complete the sprint, there is no time to optimize costs.
And here the Unified Register of Integration Interaction comes to the rescue. If it is already used to generate integration components, then what prevents it from immediately generating the corresponding stubs, automatically deploying them on a common infrastructure, accessible from the development and demo environment. And if you add to this a separate tool for creating test scripts, so that they can be written not only by developers, but also by testers or analysts who just work out all the interactions in detail and know the formats, attributes and use cases of each service well. And if we also further combine test scripts written by different teams into a common catalog, then we will get real “smart stubs”.
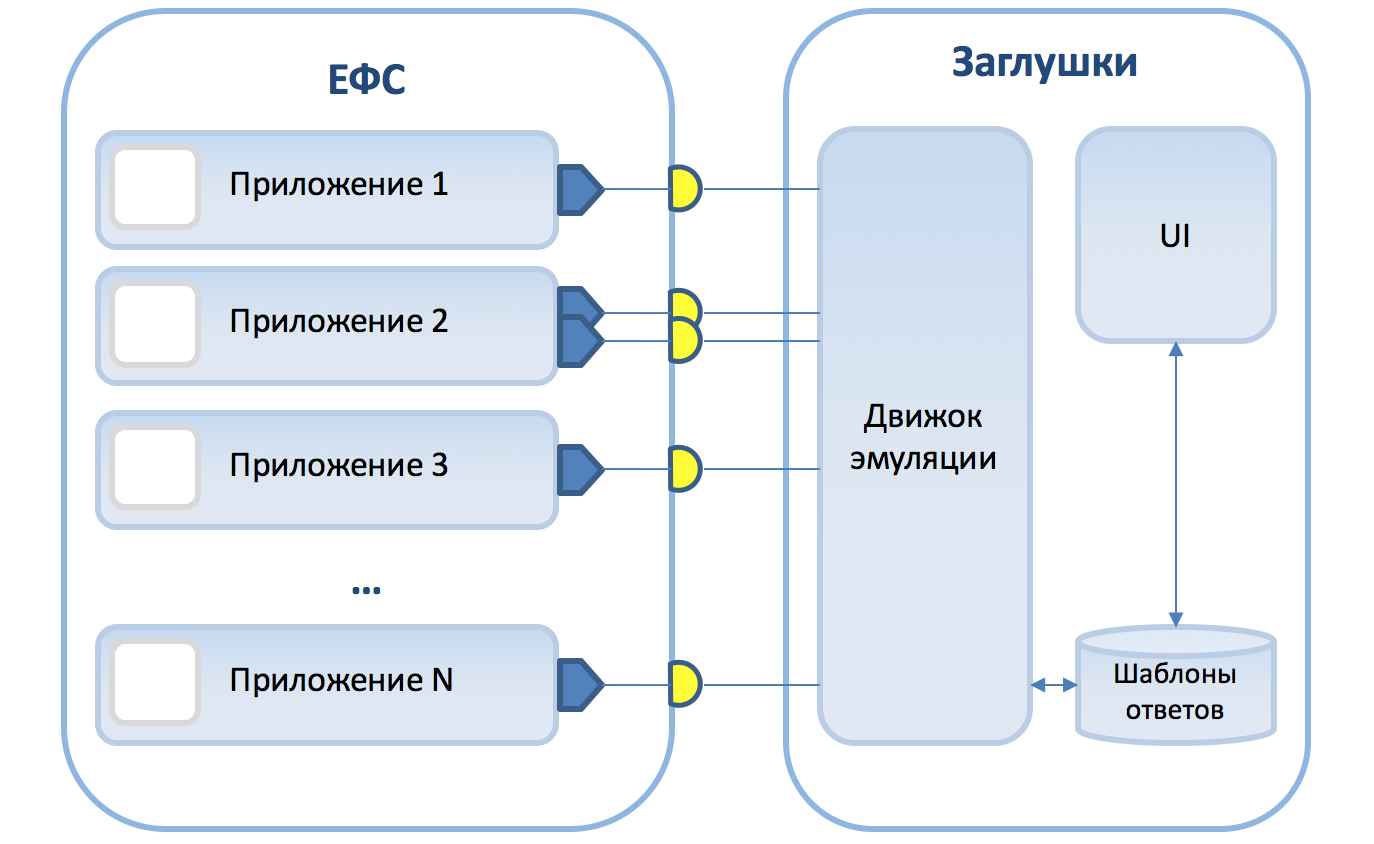
Our smart stubs now support the JMS messaging standard. This allows you to emulate most of the interactions of the Unified frontal system with adjacent systems. At the same time, four types of interaction are supported:
To select a response template, the conditions for incoming messages using XPath notation are used. Generation of answers according to the given templates occurs using FreeMarker. Validation of request / response by XSD scheme is supported. All requests and responses are logged into the database.
We mentioned above that the main developers of stubs and test scripts are testers and analysts. Analysts are directly involved in the study of integration interactions, describe the attributive structure of services, use cases and call sequences. Testers generate test scenarios based on user stories (User Story). With this in mind, all settings for stubs and writing test scripts are carried out through a convenient web interface, while programming skills are not required. Much attention is paid to working with message logs: filtering, viewing the list of calls and detailed information for each call. This functionality is necessary when analyzing the operation of stubs and for understanding the operation of test scripts.
Now imagine that some of the adjacent systems are ready, some are being released in the current sprint, and something will be developed later. The centralized release of the integration layer allows you to control the configuration of adapters and stubs from a single Parameter Management System (CMS). The adapters are configured to work with real systems or stubs through the control system, and switching occurs in real time without restarting, and even more so without reassembling applications.
Given that smart stubs are provided by the service model, and teams do not need to deploy their own infrastructure (look for servers, install and configure something), new stubs can be created and started to be used in a few clicks. Agree, in the conditions of short deadlines it is a big help.
Simplifying the development of stubs is, of course, good. But is it possible to completely do without any costs? Oddly enough, but yes. The more plugs are developed, the higher the likelihood of their reuse. To simplify the search for implemented stubs, we have a separate registry. Before developing our own stub, we look in the registry for the master system and service for all test scripts already written for this interaction. And if the required plugs are already developed, then we just use them at no cost. If not, then either modify something in the current scenarios, or form new stubs. All separate testing areas can be used, it is very convenient, since it allows to avoid mutual influence:

The introduction of a single information space for the integration interaction of the ESF together with the automation of the development and deployment of the integration layer and smart plugs allowed to significantly reduce costs, improve the quality and consistency of integration interaction, and also provided the ability to conduct simultaneous development of many teams using a flexible (Agile) methodology.
Much has already been done, but judging by the requests of the teams and the formed roadmap, this is only the beginning. In the near future:
There are many tasks, and everything needs to be done yesterday. Therefore, joint development is encouraged. Each team can refine the functionality of smart stubs or registry. Having made the necessary refinement for himself, the team implements this for everyone else. The joint development of the toolkit can significantly accelerate the development of products and the timing of the implementation of the roadmap.
What do you think of this? If you are close and interested in the topic of integration, we will be happy to talk in the comments to the post.
Fancy it? Yes, breathtaking. Nevertheless, these are the usual workdays of the developers of the Unified Frontal System of Sberbank. Two hundred teams are simultaneously engaged in the development of the platform, daily solving complex and non-trivial tasks aimed at optimizing and synchronizing processes.
We can talk about synchronization and optimization for a long time, this topic deserves a separate book. In this article, we will cover only a small part - optimization of the development of integration interaction, share our experience and tell you how to integrate with hundreds of systems and not wait for anyone.
The question that concerns us in the first place is how do all teams, each of which depends on many other teams, manage to make their development efficiently, in compliance with all deadlines, and in order to get the expected result when docking with adjacent systems at the integration training ground?
And we found two answers to it: a single information space and the maximum automation of development and deployment.
Now our integration center is the “Unified Register of Integration Interaction”. The registry contains information on all subsystems and services, details of integration interaction, attributive structure, description of data sources and usage register, formats, protocols and other characteristics necessary for an accurate and unambiguous description of each interaction. In addition, it is associated with similar registries of other bank systems. All this forms a single information space.
With a single information space it’s clear, what about automation? The more code is generated automatically, the lower the cost and the higher the quality of the final product. For the development of integration interaction, this is doubly important, since many individually developed systems must interact together and understand each other.
As you probably guessed, the registry of integration interaction is needed not only for reference information. Based on the registry data, the automatic generation of integration components (integration layer) occurs. This saves teams from additional routine development, forms a single integration architecture and ensures coordination of interaction according to the announced contracts.
Yes, it’s really convenient, but that’s not all. The team brought all its integrations into the registry, received the generated integration layer and ... stop. The functionality of the modules developed by the team depends on related systems that are themselves in the development process. How to be? In addition, at the end of the sprint, the Product owner will want to see the result of the team. Perhaps, along with stakeholders, he wants to make some backlog adjustments. Agile, after all.
What to do?
That's right, you need to drown out the missing integration interactions. And then all the teams rushed to write their stubs.
Time is sorely lacking, there is a great temptation to drown out the interaction, spending minimal effort. For example, add the return of the result directly to the code of the calling function. It’s not entirely honest, we agree, but you don’t have to spend time writing individual components, deploy and configure various message brokers. Yes, a lot will have to be changed at the next sprint, yes, there is no guarantee that adjacent systems will work similarly to this implementation, but there is no time - you need to complete the sprint, there is no time to optimize costs.
And here the Unified Register of Integration Interaction comes to the rescue. If it is already used to generate integration components, then what prevents it from immediately generating the corresponding stubs, automatically deploying them on a common infrastructure, accessible from the development and demo environment. And if you add to this a separate tool for creating test scripts, so that they can be written not only by developers, but also by testers or analysts who just work out all the interactions in detail and know the formats, attributes and use cases of each service well. And if we also further combine test scripts written by different teams into a common catalog, then we will get real “smart stubs”.
Smart Stub ESF
Our smart stubs now support the JMS messaging standard. This allows you to emulate most of the interactions of the Unified frontal system with adjacent systems. At the same time, four types of interaction are supported:
- ESF request / response external speaker;
- ESF request / without response from external speakers (notification);
- request from external speaker / no response from ESF (notification);
- request from external speaker / with response from ESF.
To select a response template, the conditions for incoming messages using XPath notation are used. Generation of answers according to the given templates occurs using FreeMarker. Validation of request / response by XSD scheme is supported. All requests and responses are logged into the database.
We mentioned above that the main developers of stubs and test scripts are testers and analysts. Analysts are directly involved in the study of integration interactions, describe the attributive structure of services, use cases and call sequences. Testers generate test scenarios based on user stories (User Story). With this in mind, all settings for stubs and writing test scripts are carried out through a convenient web interface, while programming skills are not required. Much attention is paid to working with message logs: filtering, viewing the list of calls and detailed information for each call. This functionality is necessary when analyzing the operation of stubs and for understanding the operation of test scripts.
Now imagine that some of the adjacent systems are ready, some are being released in the current sprint, and something will be developed later. The centralized release of the integration layer allows you to control the configuration of adapters and stubs from a single Parameter Management System (CMS). The adapters are configured to work with real systems or stubs through the control system, and switching occurs in real time without restarting, and even more so without reassembling applications.
Given that smart stubs are provided by the service model, and teams do not need to deploy their own infrastructure (look for servers, install and configure something), new stubs can be created and started to be used in a few clicks. Agree, in the conditions of short deadlines it is a big help.
Simplifying the development of stubs is, of course, good. But is it possible to completely do without any costs? Oddly enough, but yes. The more plugs are developed, the higher the likelihood of their reuse. To simplify the search for implemented stubs, we have a separate registry. Before developing our own stub, we look in the registry for the master system and service for all test scripts already written for this interaction. And if the required plugs are already developed, then we just use them at no cost. If not, then either modify something in the current scenarios, or form new stubs. All separate testing areas can be used, it is very convenient, since it allows to avoid mutual influence:
And finally
The introduction of a single information space for the integration interaction of the ESF together with the automation of the development and deployment of the integration layer and smart plugs allowed to significantly reduce costs, improve the quality and consistency of integration interaction, and also provided the ability to conduct simultaneous development of many teams using a flexible (Agile) methodology.
Much has already been done, but judging by the requests of the teams and the formed roadmap, this is only the beginning. In the near future:
- Extension of supported protocols and formats: http, kafka, json.
- Support for complex test scenarios involving multiple calls, and saving intermediate results in the context of a single test scenario.
- Ability to call external services and record real answers for subsequent use in stubs.
- Plugin support for enhanced emulation capabilities.
There are many tasks, and everything needs to be done yesterday. Therefore, joint development is encouraged. Each team can refine the functionality of smart stubs or registry. Having made the necessary refinement for himself, the team implements this for everyone else. The joint development of the toolkit can significantly accelerate the development of products and the timing of the implementation of the roadmap.
What do you think of this? If you are close and interested in the topic of integration, we will be happy to talk in the comments to the post.