Neural networks in the detection of numbers

Car license plate recognition is still the best-selling computer vision solution. Hundreds, if not thousands, of products have been competing in this market for 20-25 years. This is partly why convolutional neural networks (CNNs) do not beat the previous algorithmic approaches in the market.
But the experience of recent years says that CNN algorithms make it possible to make reliable and flexible solutions. There is one more convenience: with this approach, you can always improve the reliability of a solution by an order of magnitude after a real implementation through retraining. In addition, such algorithms are perfectly implemented on GPUs (graphic modules), which are much more efficient in terms of energy consumption than conventional processors. And the Jetson TX platform from NVidiaso simple it consumes very little by the standards of modern calculators. Clear "energy superiority":

Of course, this superiority of Jetson TX1 over Intel Core i7 is exaggerated, because there are always side tasks: capturing images from the camera, working with memory, not all calculations are advisable to transfer to the GPU. And yet, it looks tempting.
It is easy to estimate the consumption budget for the complete system:

So, even for an autonomous solution powered by the sun and wind, you can install 3-4 cameras with IR sources and 2 Jetson.
It has become even more attractive! So, you need to do recognition on Jetson TX1, and do well.
Just say thanks to the NVidia team in Russia. Thanks to their help, everything worked out. The men gave us Jetson TX1 for experiments and promised to give us a test TX2 .
Number Search Algorithm
The search for the boundaries and angles of license plates in the pictures consisted of three stages, implemented by different trained CNNs.
Determining the position of a license plate number (center):

The output layer of the convolution network is the field of probabilities of finding the center of a number at a given point. The output is such beautiful “Gausses”. Of course, false positives are possible here. Moreover, thresholds are chosen in such a way as to minimize the likelihood of missing a number (increasing the number of false numbers).
Over the past couple of years, tens of thousands of different numbers have come to our freely accessible server. With such a base, it was possible to train a significantly more reliable detector than the previously used Haar.
Evaluation of the scale of the license

plate : Here along the way we filter out part of the false positives.
Search for the best transformation of “homography”, which brings the car number into a familiar form:
Here 2 more convolutional neural networks have worked: detecting the number boundaries, determining the most plausible hypothesis.
The result of the first:
And the second chooses the best homography:

As a result, a normalized image of the license plate is obtained, which must be further recognized. Below are a few examples of such normalized tablets (some of them are not readable even by the eye):

This multi-level approach has proven to be very reliable. At each stage, the probability of skipping is minimized, and the convolutional neural network at each next level is trained not only to perform its main function, but also to remove false positives. Thus, the inaccuracy of each CNN is compensated for in the next step.
In order to make it all work, we used 2 types of convolution networks:
1) A standard classification option, similar to VGG:

2) An architecture designed for segmentation, described in more detail in one of the previous articles .

Of course, these architectures had to be a little lightweight to work on the Jetson TX1. In addition, several tricks with loss functions and output layers helped to improve the generalization when training on a not-so-huge base that was available.
Number recognition text algorithm
Honestly, it seemed that the problems with text recognition have been thoroughly solved for several years by modern Deep Learning algorithms. But for some reason, no.
Here is a relatively recent overview of existing problems and solutions .
On Habré there was recently an article about using LSTM and CNN for recognizing text in a passport.
But the described approach requires manual marking of the entire base (the border between the characters). And we had a serious size base with a different layout for the layout (image + text):

After all, there was the same algorithm of the previous generation, which often quite successfully recognized the car number (sometimes making mistakes). So, it was necessary to come up with an approach that would allow us to train a neural network without involving information about the position of each symbol. This approach is even more valuable due to the fact that it is much easier to automatically increase the training sample. In a system in which errors are checked and corrected with the eyes (for example, to send a fine), an extension of the training sample is automatically generated. Yes, even if the correction is not carried out, retraining will help after the accumulation of recognized numbers.
Any convolutional network has a pre-programmed structure, which implies that the same kernels (convolutions) are applied to different positions of the image. Due to this, a significant reduction in the number of weights is achieved.
You can take a look at this property of convolution networks, and on the other hand, as AlexeyR suggests ( read here ). In short, the generalization problem is inextricably linked with the task of transforming input information into a context in which it is more often found or better described. Armed with this concept (or inspired), we will try to solve this seemingly simple task of recognizing text in an image with our markup (there is no position of signs, there is only a list of them).
Let’s build a small context-sensitive area of 36 mini-columns ( more ):

The picture shows only 10 transformations. Here is what the responses to each of the contexts should look like in the above picture.

Here it should be noted that far from the most efficient coding was used inside the mini-columns, but with the existing 22 concepts, this is not a big problem.
Convolutional networks are conceived so successfully that these contextual transformations are automatically obtained at the output of any convolutional layer, which means that there is no point in shifting the input images, it is enough to take the output of any convolutional layer, make several transformations already implemented by the layers in Caffe, and start learning SGD.
And as a result of the training, we will get a “slice” for 36 mini-columns:

We single out the local maxima and report the output of the combination: what they learned and in what context. And then we collect everything in order from left to right: A902YT190
This problem was solved using CAFFE and the convolution network architecture. But if we had to consider more complex and non-obvious transformations (scale, turns in space, perspective), then we would have to use more computing resources and create much more serious algorithms.
In addition, I had to sweat quite a bit over regions whose quality is poor. But this is such a big story that I do not want to include it in this already long article.
In this case, it is worth noting separately. If there are no regions, then any numbers with a monotone font are recognized by the same grid. It’s just enough to provide a reasonably large base of examples.
Applications
Of course, the most obvious is traffic control. But there are several more applications that we have met. We wanted to make a fairly universal algorithm. Therefore, I had to think about what kind of use cases are:
1)

Traffic control (application 1) - High resolution cameras: 3-8MP
- IR illuminator
- Predictable orientation and scale
- Possible manual adjustment after installation
- Up to 10-20 numbers per frame
2) Access control at the checkpoint (application 2)

- Low resolution cameras (0.3MP - 1MP)
- IR illuminator
- Predictable size and number area
- Possible manual adjustment after installation
- Only one number at a time in the frame
3) Hand-held photographs (application 3)

- High-resolution camera
- No IR illumination
Unpredictable room size and location. It turned out that the latter application is the most costly in computing resources. Mainly due to the fact that the scale of the number is poorly predicted. The simplest application is the second. There is no more than one number in the frame. The scale of the room varies within small limits. The first application is also quite successful and is located in the middle of computing needs. But with all these situations, Jetson TX1 successfully copes. Only the latter does not fit into the real-time scale, but takes about 1 second to calculate in an unoptimized code.
Frame calculation time budget on Jetson TX1
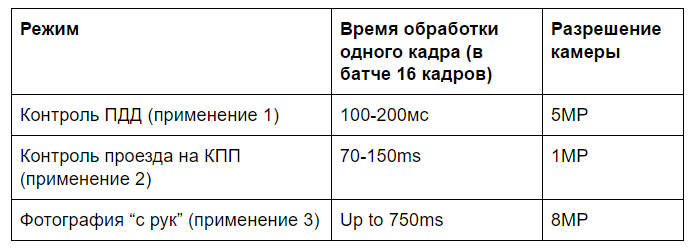
Performance tests are preliminary, optimization is still possible, especially for a specific application.
And, of course, when you perform the same algorithm on video cards of level 1080 / Titan, you can get almost a tenfold increase in speed. For the third application, this is already ~ 100ms per image.
Telegram Bot
The article on the hub is bad, which does not end with the story about writing the Telegram bot! Therefore, of course, we made one of these on Jetson TX1 so that you can take a picture and test the algorithm. The bot’s name is Recognitor.
This bot is now working on the Jetson TX1 demo board:

Jetson TX1 recognizes images at home (pay attention to the fan - it turns on every time a new image arrives).

It turned out that Telegram Bot is an excellent auxiliary tool when working with computer vision programs. So, for example, you can organize a manual check of the recognition results using it. The Telegram API provides an excellent feature set for this. ZlodeiBaal already used heretelegram bot .
It's simple: attach the image to the message (one! It seems the telegram allows you to send several, but only the last will be analyzed). An image with marked frames and a few lines with all likely-found numbers is returned. Each line also contains a percentage - this is the conditional probability that the number is really recognized. Less than 50% - something with the number is wrong (the part did not fit into the frame or it is not the number at all).
If you want to leave us a comment on a specific photo, then simply write it in text without attaching a picture. It will be saved in the log.txt file, which we will very likely read.
Do not forget that the algorithm is now running in test mode and only standard Ros.Gos. numbers or yellow taxi numbers are expected (no transit, trailers, etc.).
Training sample
We had about 25,000 images at our disposal. Most of the database is pictures from a phone with a random position and number scale:

Several thousand pictures were obtained from checkpoints:

About a thousand pictures are a standard view for traffic violation registration cameras.

Most of the database was based on the sample that we put in the public
domain a long time ago: yadi.sk/d/EAfnQ947criHW
yadi.sk/d/0H2AipxrcrXqy
yadi.sk/d/U41QZ8v7cpJ6R
Eventually
We assembled the entire stack of license plate recognition algorithms based on convolutional neural networks for the Jetson TX1 with sufficient speed to work with real-time video.
Recognition reliability has improved significantly compared to the previous algorithm . It’s hard to give specific numbers, because they vary greatly depending on the conditions of use. But the difference is clearly visible to the naked eye - Recognitor
Due to the fact that all the algorithms are retrainable, the applicability of the solution can be easily expanded. Up to changing recognition objects.