Meine Überwachung, or the tale of beautiful monitoring - the beginning
Now only the dead one who does not have it does not write about monitoring . We have monitoring in Tensor - this is our own metric collection system (although this is far from its only purpose), closely integrated with Zabbix.
If you are interested in how the monitoring of 5K servers is arranged in our company, what problems we had to face on the way to 1.5M metrics , 65K values per second and the current solution, and how did we get to such a life, welcome to cat.

A long time ago, back in the 90s, Tensor was developing not the current web services with millions of users, but the usual desktop application - a system for maintaining warehouse and accounting. It was a normal application, maximum with a network database, that worked on the hardware of the client. Accountants prepared reports in it, printed them and wore them with their “legs” into the tax.
Of all the “server” capacities, we ourselves then had nothing at all - a couple of servers from programmers to build the release and a server from the corporate database of the accounting system. Behind them, "half-eye" was watched by a couple of "admins", whose main occupation was the helpdesk of users.
Then we were able to save our client accountants from going to government agencies - our desktop application still helped them prepare reports, but sent them to the tax office itself - through our server using the mail protocol.
If someone believes that the “exchange of mail with the tax” is just a couple of mail servers, then this is not so. This adds a “slide” of proprietary software and hardware solutions to provide secure channels for each state agency - Federal Tax Service, PF, Rosstat, ... a lot of them. And each such decision has its own "troubles": requirements for the OS, hardware, service regulations ...
It is clear that this principle of operation required the growth of server capacities on our side, and the "pair of admins" ceased to be enough for all tasks. At this moment, we have outlined a specialization of “admins”, which has survived to this day, although there are already more than 70 of them:
At that moment, we realized that without some reasonable automation of monitoring all this “zoo” we would quickly get bogged down under a heap of problems.

Actually, all monitoring is needed only for one task - detecting anomalies / problems in the observed system. And the sooner - the better, ideally - even before the problem happens. And if it already happened, we should be able to analyze all the information taken and understand what led to it.
In fact, the entire monitoring development cycle looks like this:
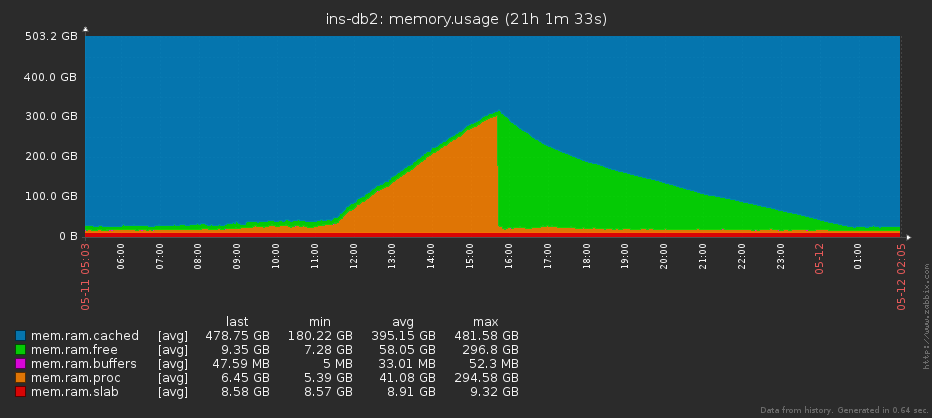
Well, for example, it happens that the server runs out of memory. Technically, the reasons can be different (“did not let go on time”, “the application is flowing”, “GC did not work,” ...), but the symptoms are almost always the same - gradually the amount of occupied memory becomes more and more.
Many people like to monitor "free memory", but this is not entirely correct, since with actively used pagecache it may practically not exist even under normal conditions. The image is clickable, it opens in the current tab of the web browser. Accordingly, if we analyze the dynamics of growth and the current state, then we will understand in time at what point it is time to stop hoping for “to resolve itself,” and it is time to raise the alarm.
At various stages, as the core of the monitoring system, we managed to try Nagios, Graphite and settled on Zabbix, which we have quite successfully used to this day to monitor several thousand servers. For several years, we have accumulated considerable experience in its operation, administration and tuning. And all this time he coped quite well with his tasks.
Nevertheless, we probably stepped on all possible and impossible rakes. And this is the most rewarding experience.
So, the main problems that we encountered (attention! Hereinafter there is a lot of pain and suffering):
The maintenance service later found out about infrastructure problems, and the developers did not have a tool to analyze the effectiveness of their solutions. Ultimately, all this, one way or another, affected the effectiveness of our decisions.
 After realizing the fact that our monitoring is a collection of wrong architectural solutions (I don’t know if the absence of architecture can be considered an architectural solution), we decided that it was impossible to live like that anymore. And they began to think how to fix all the shortcomings described, but without radical solutions, such as replacing Zabbix with something else. Still, abandoning the accumulated experience and trying to eradicate long-term habits is probably not a good idea. Zabbix is a great tool if used properly.
After realizing the fact that our monitoring is a collection of wrong architectural solutions (I don’t know if the absence of architecture can be considered an architectural solution), we decided that it was impossible to live like that anymore. And they began to think how to fix all the shortcomings described, but without radical solutions, such as replacing Zabbix with something else. Still, abandoning the accumulated experience and trying to eradicate long-term habits is probably not a good idea. Zabbix is a great tool if used properly.
To begin with, we have determined for ourselves the following criteria that we would like to receive:
Since Zabbix operates as a monitoring object with a “host”, and we needed a “service” (for example, a specific one of several DBMS instances deployed on the same machine), we fixed certain rules for naming hosts, services, metrics and complex screens so that they do not "Broke" neither the logic of Zabbix, nor "human intelligibility":
For example: some-db.pgsql.5433: db.postgres . If the port is default, then it is not indicated for ease of perception. The image is clickable, it opens in the current tab of the web browser. We didn’t give a name to this system, but inside the company the working name “sbis3mon” was fixed, and some with a light hand called it “beautiful monitoring”. Why beautiful? We tried to make it not only functional, but also visual. The image is clickable, it opens in the current tab of the web browser. At the moment, we have already developed dozens of modules for monitoring various equipment and services used in the tensor:


The immediate plans also include monitoring MySQL, network equipment and telephony services (Asterisk).
We chose Node.js as the platform due to the developed ecosystem, asynchrony, ease of work with the network, ease of scaling (cluster module) and development speed.
We also adopted the Continuous Delivery approach and began to attach wings to the aircraft on the fly. Thanks to frequent releases, we quickly received feedback and were able to adjust the direction of development. The system was built in front of our main users - the service department employees, while they continued to use the familiar monitoring shell. Gradually, we replaced the old monitoring methods with new ones until we completely got rid of them.
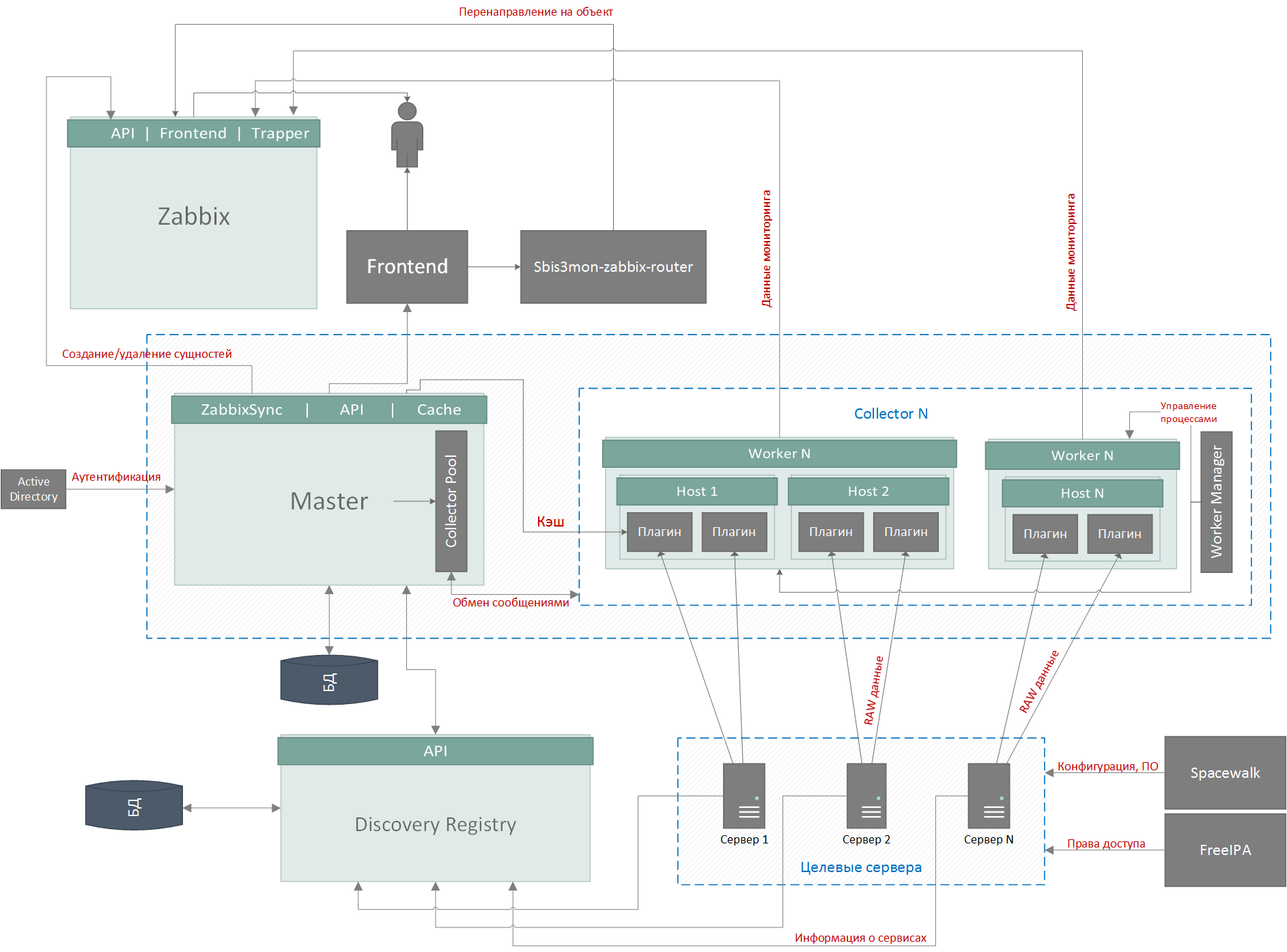
The system is based on microservice architecture and consists of 5 main parts:
As a DBMS we use PostgreSQL. But the base here is secondary and not very interesting - it stores the settings of hosts and services, discovered entities, links to Zabbix resources and audit logs, and no highload. The image is clickable, it opens in the current tab of the web browser. The most interesting thing is the services. They can work both on one server, and on different. The master and collectors have a common code base - the core. Depending on the startup parameters, the process becomes either a master or a collector. Features of the master process :
Collector Functions :
Now our several thousand hosts and tens of thousands of services on them are serviced by collectors living on only two servers , on 40 and 64 cores, with an average load of about 20-25% - that is, we can easily withstand the further growth of our server park in another 3- 4 times.
In the next part, we will describe in more detail about those solutions that allowed our monitoring to withstand the growth of workload and user requirements, while Tensor turned from a reporting operator into a real multiservice service provider with millions of online users.
Authors: vadim_ipatov (Vadim Ipatov) and kilor (Kirill Borovikov)
If you are interested in how the monitoring of 5K servers is arranged in our company, what problems we had to face on the way to 1.5M metrics , 65K values per second and the current solution, and how did we get to such a life, welcome to cat.
When the trees were big
A long time ago, back in the 90s, Tensor was developing not the current web services with millions of users, but the usual desktop application - a system for maintaining warehouse and accounting. It was a normal application, maximum with a network database, that worked on the hardware of the client. Accountants prepared reports in it, printed them and wore them with their “legs” into the tax.
Of all the “server” capacities, we ourselves then had nothing at all - a couple of servers from programmers to build the release and a server from the corporate database of the accounting system. Behind them, "half-eye" was watched by a couple of "admins", whose main occupation was the helpdesk of users.
Then we were able to save our client accountants from going to government agencies - our desktop application still helped them prepare reports, but sent them to the tax office itself - through our server using the mail protocol.
If someone believes that the “exchange of mail with the tax” is just a couple of mail servers, then this is not so. This adds a “slide” of proprietary software and hardware solutions to provide secure channels for each state agency - Federal Tax Service, PF, Rosstat, ... a lot of them. And each such decision has its own "troubles": requirements for the OS, hardware, service regulations ...
It is clear that this principle of operation required the growth of server capacities on our side, and the "pair of admins" ceased to be enough for all tasks. At this moment, we have outlined a specialization of “admins”, which has survived to this day, although there are already more than 70 of them:
- helpdesk - serve the work of local users in our offices;
- sysop - are responsible for the hardware, network and system software;
- devop - do all the work of application software (both ours and third-party) on this same hardware.
At that moment, we realized that without some reasonable automation of monitoring all this “zoo” we would quickly get bogged down under a heap of problems.
Back to the future
Actually, all monitoring is needed only for one task - detecting anomalies / problems in the observed system. And the sooner - the better, ideally - even before the problem happens. And if it already happened, we should be able to analyze all the information taken and understand what led to it.
In fact, the entire monitoring development cycle looks like this:
- We are looking for the causes of the problem;
- We understand what metrics can be used to predict the situation;
- we learn to remove, store and clearly show them;
- we implement “predictive” triggers that notify the attendant.
Well, for example, it happens that the server runs out of memory. Technically, the reasons can be different (“did not let go on time”, “the application is flowing”, “GC did not work,” ...), but the symptoms are almost always the same - gradually the amount of occupied memory becomes more and more.
Many people like to monitor "free memory", but this is not entirely correct, since with actively used pagecache it may practically not exist even under normal conditions. The image is clickable, it opens in the current tab of the web browser. Accordingly, if we analyze the dynamics of growth and the current state, then we will understand in time at what point it is time to stop hoping for “to resolve itself,” and it is time to raise the alarm.
Monitoring problems and monitoring problems
At various stages, as the core of the monitoring system, we managed to try Nagios, Graphite and settled on Zabbix, which we have quite successfully used to this day to monitor several thousand servers. For several years, we have accumulated considerable experience in its operation, administration and tuning. And all this time he coped quite well with his tasks.
Nevertheless, we probably stepped on all possible and impossible rakes. And this is the most rewarding experience.
So, the main problems that we encountered (attention! Hereinafter there is a lot of pain and suffering):
- "The seven nannies ..." - lack of uniform monitoring rules.
Remember, I spoke above about the specialization of "admins"? Gradually, they divided into different departments, and each developed its own rules for monitoring and responding to the same factors.
Well, for example, the database runs on the host and “eats” 100% CPU. The joy of the "ironworkers" is "well done, it won’t fail even under such a load!", And the "apprentices" have panic. - Not a single template ...
Most of those using Zabbix know about its powerful template system, but sometimes it comes across harsh reality.
Problems began to be added to different rules (and templates) for monitoring the same entities in different departments due to the insufficient ability to parameterize Zabbix itself.
For example, we have an excellent template with beautiful graphs for monitoring an 8-core server: The image is clickable, it opens in the current tab of the web browser. And ... it is no longer suitable for the 16-core one, you need a new one with new graphics, because the number of metrics is different. But we also have 64-core hosts ...
As a result, we had a whole bunch of templates for all occasions. Only for monitoring disks there were more than a dozen. There were no strict rules about which of them should connect to the host and in which cases.
The templates had no versioning except markups like “old” and “very_old”. They became attached and untied as the administrator ordered his heart. In some cases, the metrics were simply started manually, without templates. The result was a situation where different hosts were monitored differently. - Developers! Developers!
Hosts were added to monitoring manually. Despite the fact that the settings of the Zabbix agent were poured onto the servers using spacewalk, in some cases, to remove the metrics, it was necessary to log into the server via SSH and make some changes (put scripts, reinstall utilities, configure rights, etc.).
If the server configuration changed, then you had to remember to pick up the correct templates. But still it was necessary to drive macros with various settings into the host config, and then check that all this works. - Uncontrolled sclerosis
This problem, in part, follows from the two previous ones: many hosts simply were not added to the monitoring. And those that were there might not have the necessary settings in the config, metrics, triggers, graphs ... And even if everything was configured correctly, this still did not guarantee anything - the data might not be collected, for example, due to a mismatch between the script version and the OS .
And even if everyone gathered, the control triggers might just be accidentally disabled - after all, more than a dozen people had access to edit in Zabbix! - Overmonitoring
Zabbix is well able to collect specific values of certain metrics, but if you need to remove several of them from one object at once , problems arise.
For each sample for each of the many metrics, a request was generated by which a footcloth of various kinds of atop, iostat, grep, cut, awk, etc. was processed on the target server, and a single value was returned , then the connection was closed, and the next request was initiated.
It is clear that this is bad for performance both for the observed server and for Zabbix. But even worse is the lack of synchronism in the received data.
For example, if we measure the load of each of the CPU cores in turn, we get zeros and ... And we don’t understand anything about the load on the CPU as a whole, since at the time of each individual measurement it could appear on other cores. - Zabbix performance problems
At that stage, we still had not many metrics, and Zabbix nevertheless regularly tried to “lie down” - despite all the tuning and good hardware.
To collect metrics, we used passive zabbix agents and external scripts. To request data from agents from Zabbix, the specified fixed number of workers forked. While the worker is waiting for a response from the agent, he does not serve other requests. Thus, there were often situations when zabbix did not have time to service the queue and “holes” appeared on the charts - intervals with missing data.
Monitoring using external scripts also did not lead to anything good. A large number of simultaneously running various interpreters quickly led to space loading of the server. Monitoring at that time did not work, we were left “without eyes”. - Zabbix's limitations in terms of generating calculated indicators
It is difficult to create even the simplest calculated metrics, such as ratio = rx / tx - elementary, you can’t check the division by 0. If this happens, the metric will be disabled for a while.
The maintenance service later found out about infrastructure problems, and the developers did not have a tool to analyze the effectiveness of their solutions. Ultimately, all this, one way or another, affected the effectiveness of our decisions.
After realizing the fact that our monitoring is a collection of wrong architectural solutions (I don’t know if the absence of architecture can be considered an architectural solution), we decided that it was impossible to live like that anymore. And they began to think how to fix all the shortcomings described, but without radical solutions, such as replacing Zabbix with something else. Still, abandoning the accumulated experience and trying to eradicate long-term habits is probably not a good idea. Zabbix is a great tool if used properly.Evolution
To begin with, we have determined for ourselves the following criteria that we would like to receive:
- Uniformity . Monitoring should be carried out according to the same principles for all major systems and services used in the company. That is, if we are already removing some metrics for a 4-core server with 2 HDDs, then for a 16-core one with 8 HDDs, they should be removed the same way without additional modifications.
- Modularity . A common core with a minimum of service functions, which is expanded by connecting "application plug-ins" that implement monitoring of one or another type of objects.
The plugin includes:- detection of observable objects (for example, databases on a DBMS server);
- implementation of collection of target metrics;
- templates of generated triggers;
- templates for generated graphs and complex screens.
- Automation . A minimum of manual tuning, if something can be done automatically, it is better to do so.
- Efficiency . Minimum load on the target server. If a certain set of metrics can be obtained as the result of just one call, it should be so. If you regularly need to get some kind of “internal” metrics from the database, then you don’t have to torment it by reinstalling the connection, but just keep it.
zabbix-1: cat /proc/meminfo | grep 'MemFree' | awk '{print $2}' zabbix-2: cat /proc/meminfo | grep 'Shmem' | awk '{print $2}' sbis-mon: cat /proc/meminfo # все, дальше парсим на приемнике - Independence . If possible, agent-less monitoring. It is advisable not to install or configure anything on the server, do not use regular means. That is, yes, 'cat / proc / meminfo' is the right way.
- Monitoring as code . One of the basic concepts that allows you to describe the desired end state of monitoring using code, which gives the following advantages:
- Monitoring uses the capabilities of the version control system: all changes are transparent, it is known who changed what, and when, you can easily roll back to an arbitrary version at any time. The repository becomes a common tool for developers and maintenance services.
- Monitoring is fully tested in several stages: dev, QA, prod.
- Continuous integration.
Since Zabbix operates as a monitoring object with a “host”, and we needed a “service” (for example, a specific one of several DBMS instances deployed on the same machine), we fixed certain rules for naming hosts, services, metrics and complex screens so that they do not "Broke" neither the logic of Zabbix, nor "human intelligibility":
hostname[.service[.port]][:screen]For example: some-db.pgsql.5433: db.postgres . If the port is default, then it is not indicated for ease of perception. The image is clickable, it opens in the current tab of the web browser. We didn’t give a name to this system, but inside the company the working name “sbis3mon” was fixed, and some with a light hand called it “beautiful monitoring”. Why beautiful? We tried to make it not only functional, but also visual. The image is clickable, it opens in the current tab of the web browser. At the moment, we have already developed dozens of modules for monitoring various equipment and services used in the tensor:
- OS: Linux and Windows;
- ESXI hypervisor and its virtual machines;
- SHD: IBM DS, Storwize, Xiv, XtremIO, Openstack Swift;
- DBMS: PostgreSQL (and pgBouncer to it), MongoDB, Redis;
- Search Engine: ElasticSearch, Sphinx;
- Messaging: RabbitMQ;
- Web: Nginx and IIS, PHP-FPM, HAProxy;
- DNS: Named (BIND);
- as well as monitoring modules of our own services.
The immediate plans also include monitoring MySQL, network equipment and telephony services (Asterisk).
Metric Collection Architecture
We chose Node.js as the platform due to the developed ecosystem, asynchrony, ease of work with the network, ease of scaling (cluster module) and development speed.
We also adopted the Continuous Delivery approach and began to attach wings to the aircraft on the fly. Thanks to frequent releases, we quickly received feedback and were able to adjust the direction of development. The system was built in front of our main users - the service department employees, while they continued to use the familiar monitoring shell. Gradually, we replaced the old monitoring methods with new ones until we completely got rid of them.
The system is based on microservice architecture and consists of 5 main parts:
- master master process
- Db
- collectors - data collectors
- autodiscovery registry
- frontend
As a DBMS we use PostgreSQL. But the base here is secondary and not very interesting - it stores the settings of hosts and services, discovered entities, links to Zabbix resources and audit logs, and no highload. The image is clickable, it opens in the current tab of the web browser. The most interesting thing is the services. They can work both on one server, and on different. The master and collectors have a common code base - the core. Depending on the startup parameters, the process becomes either a master or a collector. Features of the master process :
- Managing the pool of collectors, the distribution of tasks between them, automatic load balancing; Now both collector servers are equally 25% CPU and LA = 15.
- Synchronization of entities with Zabbix and Discovery Registry, removal of "losses"
for example, instead of a "dead" HDD mounted a new one in a different way. - public API for frontend operation and integration with external services.
Collector Functions :
- Workflow Management (WorkerManager).
“Something here tasks have grown, it's time to raise another subsidiary process ...” - Task management (plugins).
“The PID process is 12345, you need to collect linux plugin metrics from the host with some-host! The process is PID 54321, you need to collect the metrics of the postgresql plugin from the host with some-db! ” - Data collection and aggregation by plugins.
“So, they expect 1 countdown from us for every 5 seconds ... For the last interval, we removed the following load indicators from the CPU: [60,50,40,30,20]. So, to save the correct values of min / max / avg, we will send [min = 20, avg = 40, max = 60]. ” - Grouping packages from child processes and sending data to Zabbix at the cluster.master level.
Now our several thousand hosts and tens of thousands of services on them are serviced by collectors living on only two servers , on 40 and 64 cores, with an average load of about 20-25% - that is, we can easily withstand the further growth of our server park in another 3- 4 times.
In the next part, we will describe in more detail about those solutions that allowed our monitoring to withstand the growth of workload and user requirements, while Tensor turned from a reporting operator into a real multiservice service provider with millions of online users.
Authors: vadim_ipatov (Vadim Ipatov) and kilor (Kirill Borovikov)