Bash scripts, part 8: awk data processing language
- Transfer
Bash scripts: start of
Bash scripts, part 2: cycles
Bash scripts, part 3: parameters and command line keys
Bash scripts, part 4: input and output
Bash scripts, part 5: signals, background tasks, managing
Bash scripts scripts, part 6: functions and library development
Bash scripts, part 7: sed and word processing
Bash scripts, part 8: awk data processing language
Bash scripts, part 9: regular expressions
Bash scripts, part 10: practical examples
Bash scripts, part 11: expect and automation of interactive utilities

Last time we talked about the sed stream editor and looked at a lot of examples of text processing with its help. Sed can solve many problems, but it also has limitations. Sometimes you need a better tool for processing data, something like a programming language. As a matter of fact, such an instrument is awk. The awk utility, or rather GNU awk, in comparison with sed, takes data stream processing to a higher level. Thanks to awk, we have at our disposal a programming language, and not a rather modest set of commands given to the editor. Using the awk programming language, you can do the following:

- Declare variables to store data.
- Use arithmetic and string operators to work with data.
- Use structural elements and control structures of the language, such as the if-then operator and loops, which allows you to implement complex data processing algorithms.
- Create formatted reports.
If we talk only about the ability to create formatted reports that are convenient to read and analyze, this is very useful when working with log files that can contain millions of records. But awk is much more than a reporting tool.
Awk call features
The awk call scheme looks like this:
$ awk options program fileAwk perceives the data coming to it as a set of records. Entries are sets of fields. Simplified, if you do not take into account the awk configuration options and talk about some completely ordinary text, the lines of which are separated by newline characters, the record is a line. Field is a word in a string.
Consider the most commonly used awk command line switches:
-F fs- allows you to specify the separator character for the fields in the record.-f file- indicates the name of the file from which to read the awk script.-v var=value —allows you to declare a variable and set its default value that awk will use.-mf N- sets the maximum number of fields to process in the data file.-mr N —sets the maximum size of the record in the data file.-W keyword- Allows you to set the compatibility mode or alert level for awk.
The real power of awk lies in that part of the command to invoke it, which is marked above as
program. It points to an awk script file written by a programmer and designed to read data, process it, and output the results.Reading awk scripts from the command line
Awk scripts that can be written directly on the command line are executed as command texts enclosed in curly braces. In addition, since awk assumes that the script is a text string, it must be enclosed in single quotes:
$ awk '{print "Welcome to awk command tutorial"}'Run this command ... And nothing will happen. The point here is that when we called awk, we did not specify the data file. In a similar situation awk expects data from STDIN . Therefore, the execution of such a command does not lead to immediately observed effects, but this does not mean that awk does not work - it waits for input from
STDIN. If you now enter something into the console and click
Enter, awk will process the entered data using the script specified when it was run. Awk processes the text from the input stream line by line, in this it is similar to sed. In our case, awk does nothing with the data, it only, in response to each new line it receives, displays the text specified in the command print.
The first launch of awk, displaying the specified text on screen
Whatever we enter, the result in this case will be the same - text output.
In order to complete awk, you need to pass it the end-of-file character (EOF, End-of-File). You can do this using the keyboard shortcut
CTRL + D. It is not surprising if this first example did not seem particularly impressive to you. However, the most interesting is ahead.
Positional variables storing field data
One of awk’s main functions is the ability to manipulate data in text files. This is done by automatically assigning a variable to each element in the row. By default, awk assigns the following variables to each data field that it finds in a record:
$0 —represents the entire line of text (record).$1 —first field.$2 —second field.$n —nth field.
Fields are extracted from the text using the delimiter character. By default, these are whitespace characters like a space or a tab character.
Consider using these variables with a simple example. Namely, we will process the file that contains several lines (this file is shown in the figure below) using the following command:
$ awk '{print $1}' myfile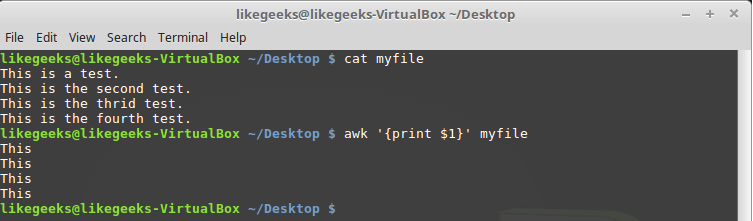
Output to the console of the first field of each line
Here we use a variable
$1that allows you to access the first field of each line and display it on the screen. Sometimes, in some files, something different from spaces or tabs is used as field separators. Above, we mentioned the awk key
-F, which allows you to specify the separator necessary for processing a specific file:$ awk -F: '{print $1}' /etc/passwd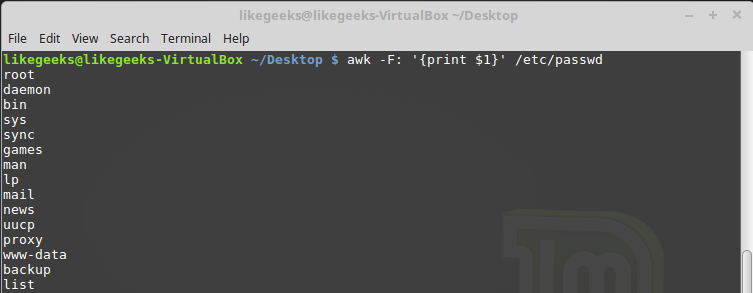
Specifying the delimiter character when awk is called
This command displays the first elements of the lines contained in the file
/etc/passwd. Since colons are used as delimiters in this file, it was this character that was passed to awk after the key -F.Using multiple commands
Calling awk with a single word processing command is a very limited approach. Awk allows you to process data using multi-line scripts. In order to send awk a multi-line command when calling it from the console, you need to separate its parts with a semicolon:
$ echo "My name is Tom" | awk '{$4="Adam"; print $0}'
Invoking awk from the command line with passing it a multi-line script
In this example, the first command writes the new value to a variable
$4, and the second displays the entire line.Reading awk script from file
Awk allows you to store scripts in files and reference them using the key
-f. Prepare a file testfilein which we write the following:{print $1 " has a home directory at " $6}We call awk, specifying this file as the source of the commands:
$ awk -F: -f testfile /etc/passwd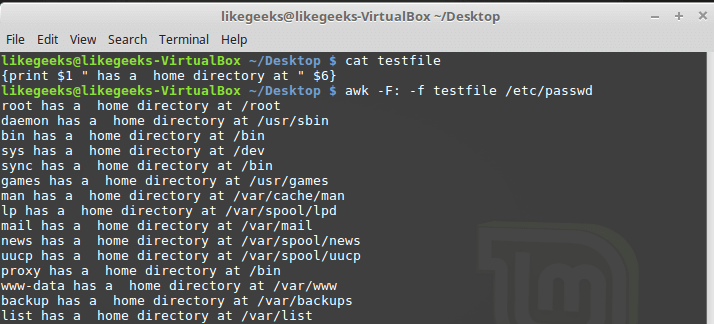
Calling awk with the script file.
Here we display the
/etc/passwdnames of the users who get into the variable $1and their home directories that get into the file $6. Please note that the script file is set using the key -f, and the field separator, a colon, in our case, using the key -F. The script file may contain many commands, while each of them is enough to write from a new line, it is not necessary to put a semicolon after each.
Here's what it might look like:
{
text = " has a home directory at "
print $1 text $6
}Here we store the text used in the output of data received from each line of the processed file in a variable, and use this variable in the command
print. If you reproduce the previous example by writing this code to a file testfile, the same will be displayed.Executing commands before processing data
Sometimes you need to perform some action before the script starts processing records from the input stream. For example, create a report header or something similar.
You can use the keyword for this
BEGIN. Commands that follow BEGINwill be executed before data processing begins. In its simplest form, it looks like this:$ awk 'BEGIN {print "Hello World!"}'And here is a slightly more complex example:
$ awk 'BEGIN {print "The File Contents:"}
{print $0}' myfile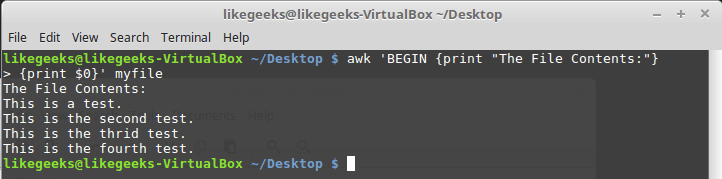
Executing commands before processing data
awk first executes a block
BEGIN, and then processing the data. Be careful with single quotes when using similar constructs on the command line. Note that both the block BEGINand the thread processing commands are one line in the awk view. The first single quote enclosing this string is before BEGIN. The second - after the closing curly brace of the data processing command.Execution of commands after the end of data processing
The keyword
ENDallows you to specify the commands that must be executed after the end of data processing:$ awk 'BEGIN {print "The File Contents:"}
{print $0}
END {print "End of File"}' myfile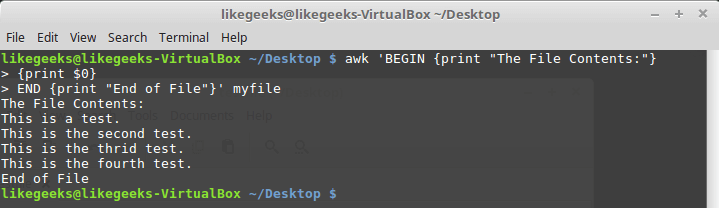
Results of the script, in which there are BEGIN and END blocks.
After completion of the output of the file contents, awk executes the block commands
END. This is a useful feature, with its help, for example, you can create a report footer. Now we will write a script of the following content and save it in a file myscript:BEGIN {
print "The latest list of users and shells"
print " UserName \t HomePath"
print "-------- \t -------"
FS=":"
}
{
print $1 " \t " $6
}
END {
print "The end"
}Here, in the block
BEGIN, a table report header is created. In the same section, we specify the delimiter character. After processing the file, thanks to the block END, the system will inform us that the work is finished. Run the script:
$ awk -f myscript /etc/passwd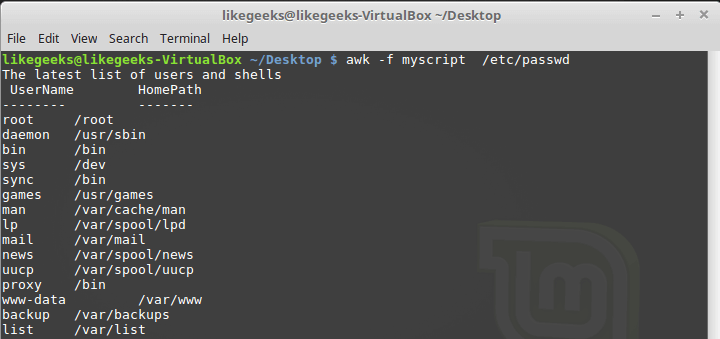
Processing the / etc / passwd file with an awk script
Everything we talked about above is just a small part of awk's features. Let's continue the development of this useful tool.
Built-in Variables: Setting Up Data Processing
The awk utility uses built-in variables that allow you to customize the data processing and give access to both the processed data and some information about them.
We have already discussed the positional variables -
$1, $2, $3that allow you to retrieve the field values, we worked with some other variables. In fact, there are quite a lot of them. Here are some of the most commonly used:FIELDWIDTHS —a list of numbers separated by spaces, defining the exact width of each data field, taking into account field separators.FS- a variable already familiar to you that allows you to specify a field separator character.RS —a variable that allows you to specify a separator character for entries.OFS —field separator in awk script output.ORS —awk script output delimiter.
By default, the variable is
OFSconfigured to use a space. It can be set as needed for data output purposes:$ awk 'BEGIN{FS=":"; OFS="-"} {print $1,$6,$7}' /etc/passwd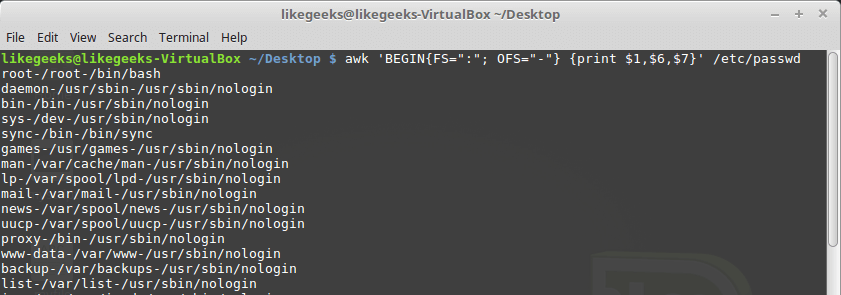
Setting the field separator for the output stream The
variable
FIELDWIDTHSallows you to read records without using the field separator character. In some cases, instead of using the field separator, the data within the records is located in constant-width columns. In such cases, it is necessary to set the variable
FIELDWIDTHSin such a way that its content matches the presentation of the data. When the variable is set,
FIELDWIDTHSawk will ignore the variable FSand find the data fields in accordance with the information about their width specified in FIELDWIDTHS. Suppose there is a file
testfilecontaining such data:1235.9652147.91
927-8.365217.27
36257.8157492.5It is known that the internal organization of this data corresponds to the 3-5-2-5 pattern, that is, the first field has a width of 3 characters, the second - 5, and so on. Here is a script that will parse such entries:
$ awk 'BEGIN{FIELDWIDTHS="3 5 2 5"}{print $1,$2,$3,$4}' testfile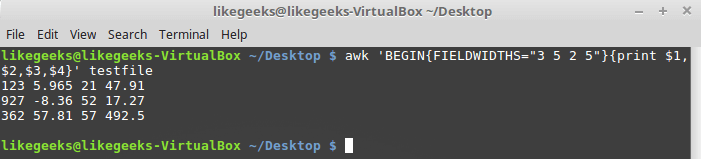
Using the FIELDWIDTHS Variable Let's
look at what the script displays. The data is parsed taking into account the value of the variable
FIELDWIDTHS, as a result, the numbers and other characters in the lines are divided in accordance with the specified field width. Variables
RSalso ORSdetermine the order in which records are processed. By default, RSand are ORSset to the line feed character. This means that awk treats each new line of text as a new record and displays each record on a new line. Sometimes it happens that the fields in the data stream are distributed over several lines. For example, suppose you have a file named
addresses:Person Name
123 High Street
(222) 466-1234
Another person
487 High Street
(523) 643-8754If you try to read this data, provided that
FSit is RSset to the default values, awk will consider each new line as a separate record and select the fields based on spaces. This is not what we need in this case. In order to solve this problem,
FSa linefeed character must be written in. This tells awk that each line in the data stream is a separate field. In addition, in this example, you will need to write an
RSempty string to the variable . Note that in the file, the data blocks for different people are separated by an empty line. As a result, awk will consider empty lines as record separators. Here's how to do it all:$ awk 'BEGIN{FS="\n"; RS=""} {print $1,$3}' addresses
Results of tuning RS and FS variables
As you can see, awk, thanks to such variable settings, treats lines from a file as fields, and empty lines become record separators.
Built-in Variables: Data and Environment Information
In addition to the built-in variables that we already talked about, there are others that provide information about the data and the environment in which awk works:
ARGC— количество аргументов командной строки.ARGV— массив с аргументами командной строки.ARGIND— индекс текущего обрабатываемого файла в массивеARGV.ENVIRON— ассоциативный массив с переменными окружения и их значениями.ERRNO— код системной ошибки, которая может возникнуть при чтении или закрытии входных файлов.FILENAME— имя входного файла с данными.FNR— номер текущей записи в файле данных.IGNORECASE— если эта переменная установлена в ненулевое значение, при обработке игнорируется регистр символов.NF— общее число полей данных в текущей записи.NR— общее число обработанных записей.
Variables
ARGCand ARGVallow you to work with the command line arguments. In this case, the script passed to awk does not fall into the array of arguments ARGV. Let's write a script like this:$ awk 'BEGIN{print ARGC,ARGV[1]}' myfileAfter starting it, you can find out that the total number of command line arguments is 2, and under the index 1 in the array the
ARGVname of the file being processed is written. In the array element with index 0 in this case there will be “awk”.
Working with command line parameters
A variable
ENVIRONis an associative array with environment variables. Let's test it:$ awk '
BEGIN{
print ENVIRON["HOME"]
print ENVIRON["PATH"]
}'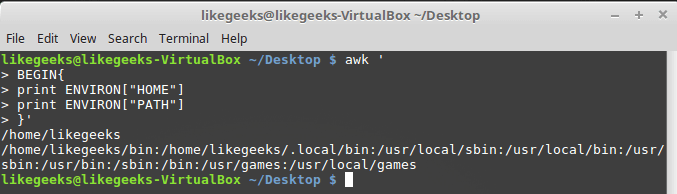
Working with environment variables Environment
variables can also be used without reference to
ENVIRON. You can do this, for example, like this:$ echo | awk -v home=$HOME '{print "My home is " home}'
Working with environment variables without using ENVIRON The
variable
NFallows you to access the last data field in the record without knowing its exact position:$ awk 'BEGIN{FS=":"; OFS=":"} {print $1,$NF}' /etc/passwd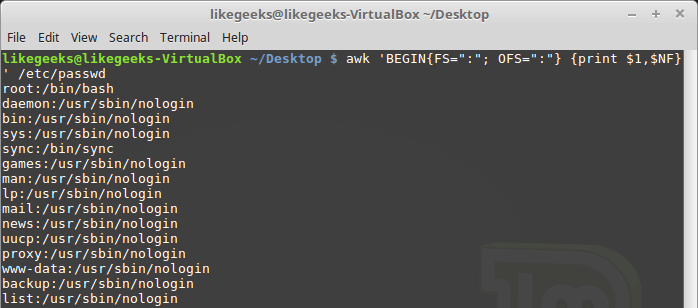
Example of using the variable NF
This variable contains the numerical index of the last data field in the record. You can access this field by placing a
NFsign in front of it $. Variables,
FNRand NRalthough they may seem similar, are actually different. So, the variable FNRstores the number of records processed in the current file. The variable NRstores the total number of processed records. Let's look at a couple of examples by passing awk the same file twice:$ awk 'BEGIN{FS=","}{print $1,"FNR="FNR}' myfile myfile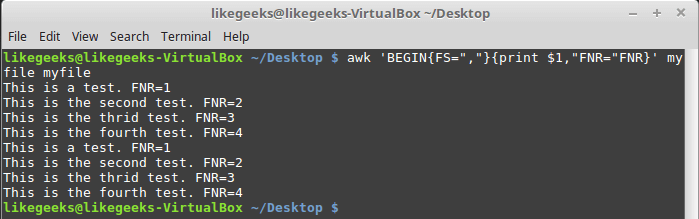
Examining the FNR variable
Transferring the same file twice is equivalent to transferring two different files. Please note that it is
FNRreset at the beginning of each file processing. Now let's take a look at how a variable behaves in a similar situation
NR:$ awk '
BEGIN {FS=","}
{print $1,"FNR="FNR,"NR="NR}
END{print "There were",NR,"records processed"}' myfile myfile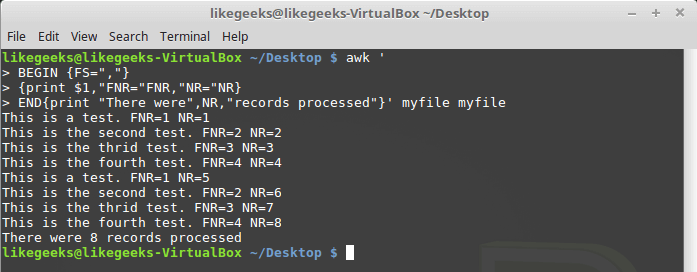
The difference between the NR and FNR variables.
As you can see,
FNRas in the previous example, it is reset at the beginning of each file processing, but NR, when moving to the next file, it saves the value.User variables
Like any other programming language, awk allows a programmer to declare variables. Variable names can include letters, numbers, underscores. However, they cannot begin with a number. You can declare a variable, assign a value to it and use it in the code as follows:
$ awk '
BEGIN{
test="This is a test"
print test
}'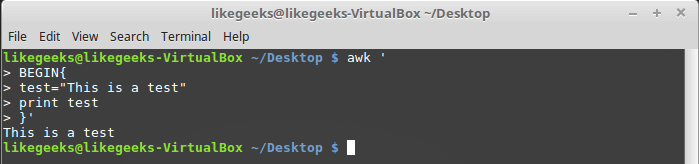
Work with a custom variable
Conditional operator
Awk supports the standard conditional statement format in many programming languages
if-then-else. The one-line version of the operator is a keyword iffollowed by the expression to be checked in brackets, and then the command to be executed if the expression is true. For example, there is a file with the name
testfile:10
15
6
33
45We will write a script that displays numbers from this file, large 20:
$ awk '{if ($1 > 20) print $1}' testfile
Single-line if statement
If you need to execute
ifseveral statements in a block , you need to enclose them in braces:$ awk '{
if ($1 > 20)
{
x = $1 * 2
print x
}
}' testfile
Executing several commands in an if block
As already mentioned, the awk conditional statement may contain a block
else:$ awk '{
if ($1 > 20)
{
x = $1 * 2
print x
} else
{
x = $1 / 2
print x
}}' testfile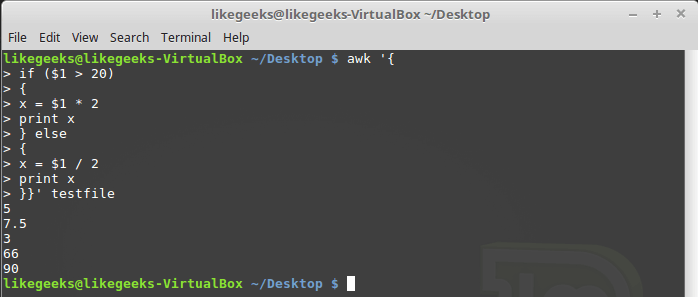
Conditional statement with else block
A branch
elsecan be part of a one-line record of a conditional statement, including only one line with a command. In this case, after the branch if, immediately before else, you must put a semicolon:$ awk '{if ($1 > 20) print $1 * 2; else print $1 / 2}' testfile
A conditional statement containing if and else branches written on the same line
While loop
The loop
whileallows you to iterate over data sets by checking the condition that stops the loop. Here is the file
myfilewhose processing we want to organize with a loop:124 127 130
112 142 135
175 158 245Let's write a script like this:
$ awk '{
total = 0
i = 1
while (i < 4)
{
total += $i
i++
}
avg = total / 3
print "Average:",avg
}' testfile
Processing data in a while loop
The loop iterates
whileover the fields of each record, accumulating their sum in a variable totaland increasing 1 counter variable in each iteration i. When it ireaches 4, the condition at the entrance to the cycle will be false and the cycle will end, after which the remaining commands will be executed - calculation of the average value for the numeric fields of the current record and output of the found value. In loops,
whileyou can use the breakand commands continue. The first allows you to prematurely complete the cycle and begin to execute the commands located after it. The second allows, without completing the current iteration, to move on to the next. Here's how the command works
break:$ awk '{
total = 0
i = 1
while (i < 4)
{
total += $i
if (i == 2)
break
i++
}
avg = total / 2
print "The average of the first two elements is:",avg
}' testfile
Break command in while loop
For loop
Loops
forare used in many programming languages. Supports them and awk. We solve the problem of calculating the average value of number fields using this cycle:$ awk '{
total = 0
for (i = 1; i < 4; i++)
{
total += $i
}
avg = total / 3
print "Average:",avg
}' testfile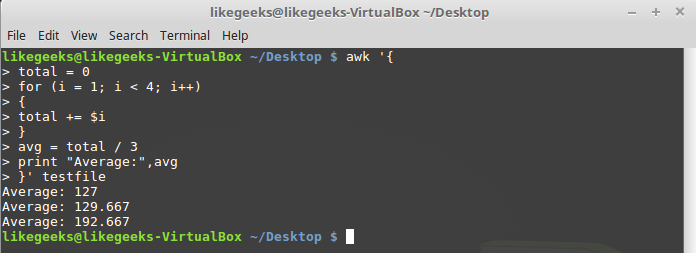
The for loop The
initial value of the counter variable and the rule for changing it in each iteration, as well as the condition for terminating the loop, are set at the beginning of the loop, in parentheses. As a result, we do not need, unlike the case with a cycle
while, to increment the counter ourselves.Formatted data output
The
printfawk command allows you to output formatted data. It makes it possible to customize the appearance of the output data through the use of templates that can contain text data and formatting specifiers. The formatting specifier is a special character that defines the type of output data and how it should be output. Awk uses formatting specifiers as pointers to where data is inserted from variables passed in
printf. The first qualifier corresponds to the first variable, the second qualifier to the second, and so on.
Formatting specifiers are written as follows:
%[modifier]control-letterHere is some of them:
c- perceives the number passed to it as an ASCII character code and displays this character.d- Outputs a decimal integer.i- the same asd.e- displays the number in exponential form.f- displays a floating point number.g- displays the number either in exponential notation or in floating point format, depending on how it turns out shorter.o- displays the octal representation of the number.s- displays a text string.
Here's how to format the output with
printf:$ awk 'BEGIN{
x = 100 * 100
printf "The result is: %e\n", x
}'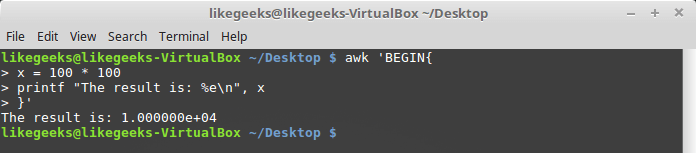
Formatting the output with printf
Here, as an example, we output the number in the exponential notation. We believe this is enough for you to understand the basic idea on which to work with
printf.Built-in math functions
When working with awk, the programmer has built-in functions . In particular, these are mathematical and string functions, functions for working with time. Here, for example, is a list of mathematical functions that you can use when developing awk scripts:
cos(x)- cosinex(xexpressed in radians).sin(x)- sinex.exp(x)Is an exponential function.int(x)- returns the integer part of the argument.log(x)- natural logarithm.rand()- returns a random floating-point number in the range 0 - 1.sqrt(x)- the square root ofx.
Here's how to use these features:
$ awk 'BEGIN{x=exp(5); print x}'
Work with math functions
String functions
Awk supports many string functions . All of them are arranged more or less in the same way. Here is an example function
toupper:$ awk 'BEGIN{x = "likegeeks"; print toupper(x)}'
Using the string function toupper
This function converts the characters stored in the string variable passed to it to uppercase.
Custom functions
If necessary, you can create your own awk functions. Such functions can be used in the same way as built-in functions:
$ awk '
function myprint()
{
printf "The user %s has home path at %s\n", $1,$6
}
BEGIN{FS=":"}
{
myprint()
}' /etc/passwd
Using our own function
In the example, we use the function we defined
myprint, which displays data.Summary
Today we covered the basics of awk. This is a powerful data processing tool, the scale of which is comparable to a separate programming language.
You could not help noticing that much of what we are talking about is not so difficult to understand, and knowing the basics, you can already automate something, but if you dig a little deeper, delve into the documentation ... For example, The GNU Awk User's Guide. The only thing that impresses with this guide is that it has its history since 1989 (the first version of awk, by the way, appeared in 1977). However, now you know about awk enough not to get lost in the official documentation and get to know it as close as you want. Next time, by the way, we'll talk about regular expressions. Without them, it is impossible to engage in serious text processing in bash scripts using sed and awk. Dear readers! We are sure that many of you periodically use awk. Tell us how it helps you in your work.