Quick Start: An Overview of the Basic Deep Learning Framework
Hello, Habr! We offer you a translation of the “Getting Started with Deep Learning” post by Matthew Rubashkin of Silicon Valley Data Science about the advantages and disadvantages of existing Deep Learning technologies and which framework to choose, taking into account the specific tasks and abilities of the team.
Here at SVDS, our R&D department studies a variety of Deep Learning technologies: from train image recognition to decoding human speech. Our goal was to build a continuous process of data processing, creating a model and assessing its quality. However, starting the study of affordable technologies, we were unable to find a suitable guide to launch a new Deep Learning project.
Nevertheless, it is worth paying tribute to the community of enthusiasts who are developing and improving Deep Learning technologies with open source code. Following their example, it is necessary to help others evaluate and choose these tools, share their own experiences. The table below shows the selection criteria for one or another Deep Learning framework:
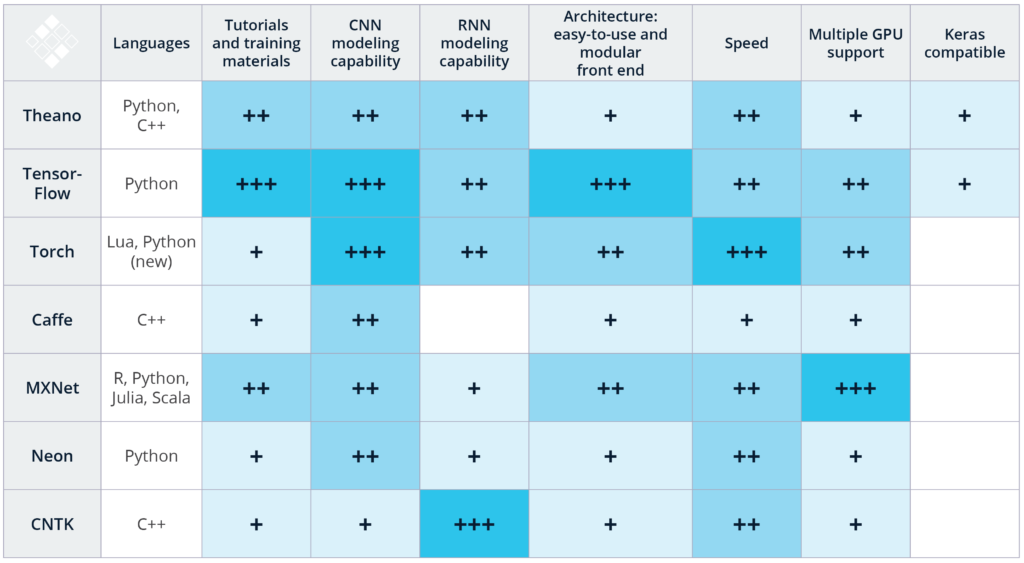
The resulting rating is based on a combination of our experience in applying the above technologies for image and speech recognition, as well as studying published comparative studies. It is worth noting that this list does not include all available Deep Learning tools, a larger number of which can be found here . In the coming months, our team is eager to test DeepLearning4j , Paddle , Chainer , Apache Signa , and Dynet .
Now let's move on to a more detailed description of our grading system:
Programming languages:Starting to work with Deep Learning, it is best to use the most convenient programming language for you. For example, Caffee (C ++) and Torch (Lua) have wrappers for their Python API, but using these tools is recommended only if you are fluent in C ++ or Lua, respectively. For comparison, TensorFlow and MXNet support many programming languages, which makes it possible to use this toolkit even if you are not a professional in C ++. Note: Unfortunately, we have not yet had the opportunity to test the new Python wrapper for Torch, PyTorch, released by Facebook AI Research (FAIR) in January 2017. This framework was created so that Python developers can improve the construction of neural networks in Torch.
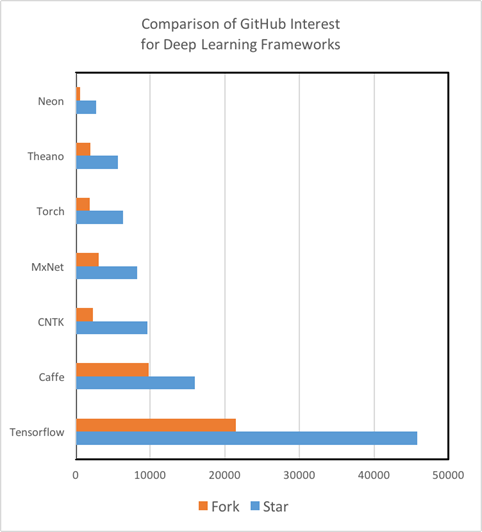
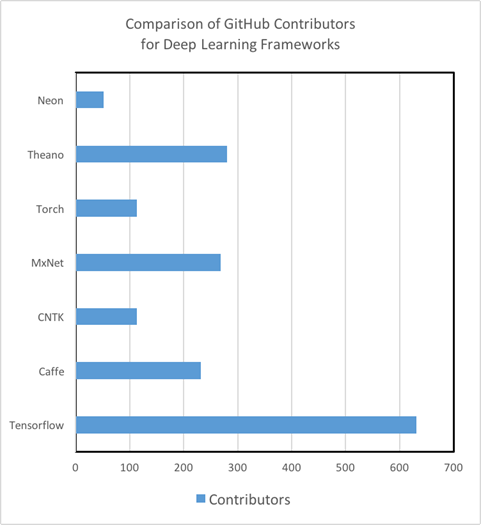
Study Guides:Regarding the quality and quantity of study guides and training materials, there are serious differences among the Deep Learning tools. So, Theano, TensorFlow, Torch and MXNet have excellent written tutorials that are easy to understand and use in practice. On the other hand, we could not find beginners' manuals with CNTK from Microsoft and Nervana Neon from Intel, quite advanced analysis tools. Moreover, we found out that the degree of involvement of the GitHub community is a reliable indicator not only of the future development of the toolkit, but also of the speed with which you can fix a bug or error in the code using StackOverflow or Git Issues. It is important to note that now TensorFlow is King Kong in the Deep Learning world in terms of the number of tutorials, materials for self-study,
CNN modeling capabilities: Convolutional neural networks are used for image recognition, recommender systems, and natural language processing (NLP). CNNs consist of a set of different layers that transform the input into estimates for a dependent variable with previously known classes. (For more information, read the overview of neural network architectures.from Eugenio Culurciello). CNN can also be used to solve regression problems, for example, calculating the steering angle of cars on autopilot. We evaluated the frameworks depending on the availability of certain capabilities for CNN modeling: the availability of embedded layers of neural networks, the availability of tools and functions for connecting these layers together. As a result of the analysis, the ease of building models using TensorFlow and its InceptionV3 , as well as the easy-to-use CNN temporary layout in Torch, distinguish these frameworks from the rest.
Features for RNN simulation:Recurrent Neural Networks (RNNs) are used for speech recognition, time series prediction, image capture and other tasks that require processing of sequential information. Due to the fact that embedded RNN models are not as common among CNN frameworks, when implementing a Deep Learning project, it is important to study other open-source projects using the technology that suits you. For example, Caffe has a minimal amount of RNN modeling capabilities, while Microsoft CNTK and Torch have rich sets of documentation and built-in models. Tensorflow also has some RNN stuff, and TFLearn and Keras include a large number of RNN examples using TensorFlow.
Architecture and easy-to use modular user interface: In order to create and train new models, the framework must have an easy-to-use, modular user interface. TensorFlow, Torch, and MXNet, for example, possess it, creating an intuitive development environment. By comparison, frameworks such as Caffe require considerable effort to create a new network layer. We also found that, in particular, TensorFlow is easily debugged not only during, but also after training, thanks to the TensorBoard GUI .
Speed: Torch and Nervana perform best in performance testingconvolutional neural networks. TensorFlow passed tests with comparable results, and Caffe and Theano were significantly behind the leaders. Microsoft CNTK, in turn, has shown itself to be the best at training recurrent neural networks (RNNs). The authors of another study , comparing Theano, Torch and TensorFlow, chose Theano as the winner in terms of RNN training.
Multiple GPU support: Most Deep Learning algorithms require an incredible amount of FLOPS (floating point operations). For example, DeepSpeech, Baidu's pattern recognition model, requires 10 exaflops for training, and this is more than 10e18 calculations! Considering one of the leaders in the GPU market, NVIDIA`s Pascal TitanX can perform 11е9 flops per second, it will take more than a week to train a sufficiently large array of data. In order to reduce model creation time, it is necessary to use different GPUs on different systems. Fortunately, most of the above tools provide this feature. In particular, it is believed that MXNet has one of the most optimized engines for working with multiple graphics cards.
Keras Compatibility: Keras is a high-level library for quickly implementing Deep Learning algorithms, which is great for introducing analysts to the field. Keras currently supports 2 back-ends, TensorFlow and Theano, and will receive official support in the future.from TensorFlow. Moreover, the fact that the library, according to its author, will continue to act as a user interface that can be used with several back- ends, speaks in favor of Keras .
Thus, if you are interested in developing in the field of Deep Learning, I would recommend that you first assess the abilities and requirements of your team and project accordingly. For example, for image recognition by the Python development team, the best option would be to use TensorFlow, given its extensive documentation, high performance, and excellent design tools. On the other hand, to implement an RNN-based project with a team of professionals in Lua, the best option is Torch and its incredible speed, coupled with the ability to model recurrent networks.
Biography: Matthew Rubashkin, along with a solid background in optical physics and biomedical research, has experience in developing, managing databases and predictive analytics.
===
In our Deep Learning program , which launches for the second time on April 8, we use two libraries: Keras and Caffe. As noted, Keras is a higher-level library and allows rapid prototyping. This is a plus, since the program does not have to spend time learning how to work with the same TensorFlow, but immediately take and try different things in practice.
Caffe is also quite understandable to use, although not very convenient, but at the same time it can be used in production solutions. In the review, it is not marked as the fastest. If you follow the link to the initial speed analysis, then you can see a note: “it may seem that TensorFlow and Chainer are faster than Caffe, but in reality this may not be so, since these frameworks were tested on CuDNN, and Caffe on its default engine.”
Here at SVDS, our R&D department studies a variety of Deep Learning technologies: from train image recognition to decoding human speech. Our goal was to build a continuous process of data processing, creating a model and assessing its quality. However, starting the study of affordable technologies, we were unable to find a suitable guide to launch a new Deep Learning project.
Nevertheless, it is worth paying tribute to the community of enthusiasts who are developing and improving Deep Learning technologies with open source code. Following their example, it is necessary to help others evaluate and choose these tools, share their own experiences. The table below shows the selection criteria for one or another Deep Learning framework:
The resulting rating is based on a combination of our experience in applying the above technologies for image and speech recognition, as well as studying published comparative studies. It is worth noting that this list does not include all available Deep Learning tools, a larger number of which can be found here . In the coming months, our team is eager to test DeepLearning4j , Paddle , Chainer , Apache Signa , and Dynet .
Now let's move on to a more detailed description of our grading system:
Programming languages:Starting to work with Deep Learning, it is best to use the most convenient programming language for you. For example, Caffee (C ++) and Torch (Lua) have wrappers for their Python API, but using these tools is recommended only if you are fluent in C ++ or Lua, respectively. For comparison, TensorFlow and MXNet support many programming languages, which makes it possible to use this toolkit even if you are not a professional in C ++. Note: Unfortunately, we have not yet had the opportunity to test the new Python wrapper for Torch, PyTorch, released by Facebook AI Research (FAIR) in January 2017. This framework was created so that Python developers can improve the construction of neural networks in Torch.
Study Guides:Regarding the quality and quantity of study guides and training materials, there are serious differences among the Deep Learning tools. So, Theano, TensorFlow, Torch and MXNet have excellent written tutorials that are easy to understand and use in practice. On the other hand, we could not find beginners' manuals with CNTK from Microsoft and Nervana Neon from Intel, quite advanced analysis tools. Moreover, we found out that the degree of involvement of the GitHub community is a reliable indicator not only of the future development of the toolkit, but also of the speed with which you can fix a bug or error in the code using StackOverflow or Git Issues. It is important to note that now TensorFlow is King Kong in the Deep Learning world in terms of the number of tutorials, materials for self-study,
CNN modeling capabilities: Convolutional neural networks are used for image recognition, recommender systems, and natural language processing (NLP). CNNs consist of a set of different layers that transform the input into estimates for a dependent variable with previously known classes. (For more information, read the overview of neural network architectures.from Eugenio Culurciello). CNN can also be used to solve regression problems, for example, calculating the steering angle of cars on autopilot. We evaluated the frameworks depending on the availability of certain capabilities for CNN modeling: the availability of embedded layers of neural networks, the availability of tools and functions for connecting these layers together. As a result of the analysis, the ease of building models using TensorFlow and its InceptionV3 , as well as the easy-to-use CNN temporary layout in Torch, distinguish these frameworks from the rest.
Features for RNN simulation:Recurrent Neural Networks (RNNs) are used for speech recognition, time series prediction, image capture and other tasks that require processing of sequential information. Due to the fact that embedded RNN models are not as common among CNN frameworks, when implementing a Deep Learning project, it is important to study other open-source projects using the technology that suits you. For example, Caffe has a minimal amount of RNN modeling capabilities, while Microsoft CNTK and Torch have rich sets of documentation and built-in models. Tensorflow also has some RNN stuff, and TFLearn and Keras include a large number of RNN examples using TensorFlow.
Architecture and easy-to use modular user interface: In order to create and train new models, the framework must have an easy-to-use, modular user interface. TensorFlow, Torch, and MXNet, for example, possess it, creating an intuitive development environment. By comparison, frameworks such as Caffe require considerable effort to create a new network layer. We also found that, in particular, TensorFlow is easily debugged not only during, but also after training, thanks to the TensorBoard GUI .
Speed: Torch and Nervana perform best in performance testingconvolutional neural networks. TensorFlow passed tests with comparable results, and Caffe and Theano were significantly behind the leaders. Microsoft CNTK, in turn, has shown itself to be the best at training recurrent neural networks (RNNs). The authors of another study , comparing Theano, Torch and TensorFlow, chose Theano as the winner in terms of RNN training.
Multiple GPU support: Most Deep Learning algorithms require an incredible amount of FLOPS (floating point operations). For example, DeepSpeech, Baidu's pattern recognition model, requires 10 exaflops for training, and this is more than 10e18 calculations! Considering one of the leaders in the GPU market, NVIDIA`s Pascal TitanX can perform 11е9 flops per second, it will take more than a week to train a sufficiently large array of data. In order to reduce model creation time, it is necessary to use different GPUs on different systems. Fortunately, most of the above tools provide this feature. In particular, it is believed that MXNet has one of the most optimized engines for working with multiple graphics cards.
Keras Compatibility: Keras is a high-level library for quickly implementing Deep Learning algorithms, which is great for introducing analysts to the field. Keras currently supports 2 back-ends, TensorFlow and Theano, and will receive official support in the future.from TensorFlow. Moreover, the fact that the library, according to its author, will continue to act as a user interface that can be used with several back- ends, speaks in favor of Keras .
Thus, if you are interested in developing in the field of Deep Learning, I would recommend that you first assess the abilities and requirements of your team and project accordingly. For example, for image recognition by the Python development team, the best option would be to use TensorFlow, given its extensive documentation, high performance, and excellent design tools. On the other hand, to implement an RNN-based project with a team of professionals in Lua, the best option is Torch and its incredible speed, coupled with the ability to model recurrent networks.
Biography: Matthew Rubashkin, along with a solid background in optical physics and biomedical research, has experience in developing, managing databases and predictive analytics.
===
In our Deep Learning program , which launches for the second time on April 8, we use two libraries: Keras and Caffe. As noted, Keras is a higher-level library and allows rapid prototyping. This is a plus, since the program does not have to spend time learning how to work with the same TensorFlow, but immediately take and try different things in practice.
Caffe is also quite understandable to use, although not very convenient, but at the same time it can be used in production solutions. In the review, it is not marked as the fastest. If you follow the link to the initial speed analysis, then you can see a note: “it may seem that TensorFlow and Chainer are faster than Caffe, but in reality this may not be so, since these frameworks were tested on CuDNN, and Caffe on its default engine.”