Frontera: Web Crawl Framework and Current Issues
Hello everyone, I am developing Frontera , the first ever open source framework for large-scale Internet crawl made in Python. Using Frontera, you can easily make a robot that can pump out content at a speed of thousands of pages per second, while following your crawl strategy and using a regular relational database or KV storage to store the link database and queue.
The development of Frontera is funded by Scrapinghub Ltd., has fully open source code (located on GitHub, BSD 3-clause license) and a modular architecture. We try to make the development process as transparent and open as possible.
In this article I am going to talk about the problems that we encountered when developing Frontera and operating robots based on it.
The device of the distributed robot based on Frontera looks like this:
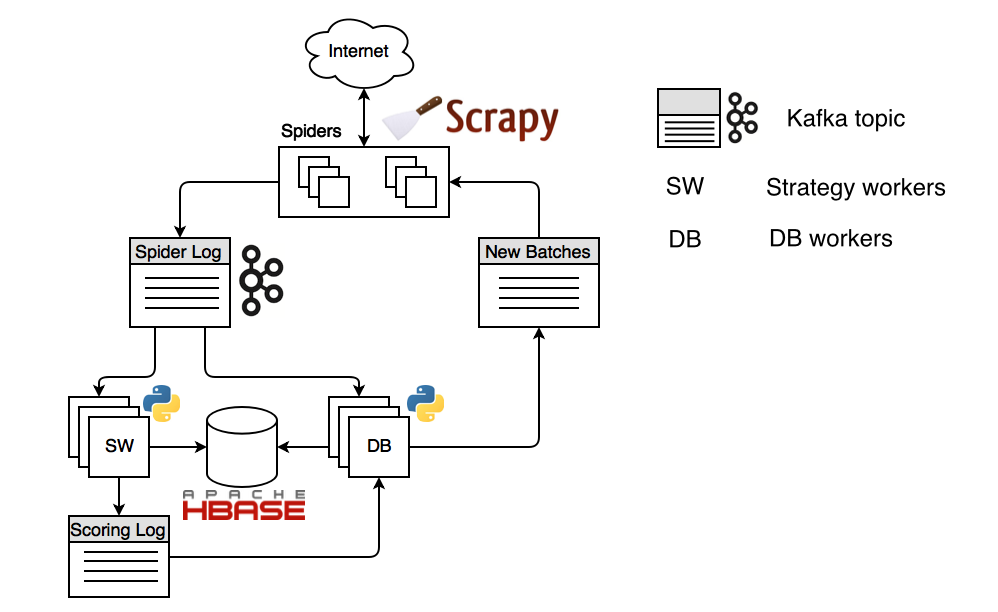
The picture shows the configuration with the Apache HBase storage and the Apache Kafka data bus. The process starts from a crawl strategy (SW) worker who plans the URLs from which to start the crawl. These URLs fall into the scoring log, the kafka topic (dedicated message channel), are consumed by the database worker and are also planned to the new batches topic, from where they are sent to the spiders based on Scrapy. The Scrapy spider resolves the DNS name, maintains a pool of open connections, receives content and sends it to the "spider log" topic. From where the content is consumed again by the strategy worker, and depending on the logic encoded in the crawl strategy, he plans new URLs.
If anyone is interested, here is a video of my report onhow we went around the Spanish Internet using Frontera .
At the moment, we are faced with the fact that people who are trying to deploy a robot at home are very difficult to configure distributed components. Unfortunately, the deployment of Frontera on a cluster requires an understanding of its architecture, reading documentation, properly configuring a data bus and storage for it. All this is very time consuming and by no means for beginners. Therefore, we want to automate the deployment on the cluster. We chose Kubernetes and Dockerto achieve these goals. A big plus of Kubernetes is that it is supported by many cloud providers (AWS, Rackspace, GCE, etc.) i.e. using it, you can deploy Frontera without even having a Kubernetes cluster configured.
Another problem is that Frontera is like a water system for a nuclear power plant. There are consumers and manufacturers in it. It is very important for them to control such characteristics as flow rate and productivity in different places of the system. It should be recalled here that Frontera is an online system. Classic Robots ( Apache Nutch), on the contrary, work in batch mode: first, a portion is planned, then downloaded, then parsed and planned again. Simultaneous parsing and planning are not provided in such systems. Thus, we are faced with the problem of synchronizing the speed of various components. It’s quite difficult to design a robot that bypasses pages with constant performance with a large number of threads, while storing them in a repository and planning new ones. The response speed of web servers varies, the size and number of pages on the site, the number of links, all this makes it impossible to accurately adjust the components for performance. As a solution to this problem, we want to make a web interface based on Django. It will display the main parameters, and if it turns out to prompt what steps to take to the robot operator.
I have already mentioned modular architecture. Like any open source project, we strive for a variety of technologies that we support. So now we are preparing support for distributed Redis in Pull Request, there have already been two attempts to make support for Apache Cassandra, well, we would like to support RabbitMQ as a data bus.
We plan to at least partially solve all these problems within the framework of Google Summer Of Code 2017. If you find something interesting and you are a student, then let us know at [email protected] and submit an application through the GSoC form . Submission of applications begins on March 20 and will last until April 3. The full GSoC 2017 schedule is here .
Of course, there are also performance issues. At the moment, Scrapinghub is working in pilot mode on a massive page download service based on Frontera. The client provides us with a set of domains to which he would like to receive content, and we download them and put them in S3 storage. Payment for the downloaded volume. In such conditions, we try to download as many pages as possible per unit of time. When trying to scale Fronter to 60 spiders, we were confused with the fact that HBase (via the Thrift interface) degrades when all found links are written to it. We call this data a reference base, but we need it in order to know when and what we downloaded, what response we received, etc. On a cluster of 7 server regions, our number of requests reaches 40-50K per second, and with such volumes, the response time increases significantly. Recording performance drops dramatically. You can solve this problem in different ways: for example, save it in a separate fast log, and then write it in HBase using batch methods, or contact HBase directly bypassing Thrift through your own Java client.
We are also constantly working to improve reliability. Too large a downloaded document or sudden network problems should not cause the components to stop. However, this sometimes happens. To diagnose such cases, we made a signal processor OS SIGUSR1, which saves the current stack of the process to the log. Several times it helped us a lot to figure out what the problem was.
We plan to further improve Frontera, and we hope that the community of active developers will grow.
The development of Frontera is funded by Scrapinghub Ltd., has fully open source code (located on GitHub, BSD 3-clause license) and a modular architecture. We try to make the development process as transparent and open as possible.
In this article I am going to talk about the problems that we encountered when developing Frontera and operating robots based on it.
The device of the distributed robot based on Frontera looks like this:
The picture shows the configuration with the Apache HBase storage and the Apache Kafka data bus. The process starts from a crawl strategy (SW) worker who plans the URLs from which to start the crawl. These URLs fall into the scoring log, the kafka topic (dedicated message channel), are consumed by the database worker and are also planned to the new batches topic, from where they are sent to the spiders based on Scrapy. The Scrapy spider resolves the DNS name, maintains a pool of open connections, receives content and sends it to the "spider log" topic. From where the content is consumed again by the strategy worker, and depending on the logic encoded in the crawl strategy, he plans new URLs.
If anyone is interested, here is a video of my report onhow we went around the Spanish Internet using Frontera .
At the moment, we are faced with the fact that people who are trying to deploy a robot at home are very difficult to configure distributed components. Unfortunately, the deployment of Frontera on a cluster requires an understanding of its architecture, reading documentation, properly configuring a data bus and storage for it. All this is very time consuming and by no means for beginners. Therefore, we want to automate the deployment on the cluster. We chose Kubernetes and Dockerto achieve these goals. A big plus of Kubernetes is that it is supported by many cloud providers (AWS, Rackspace, GCE, etc.) i.e. using it, you can deploy Frontera without even having a Kubernetes cluster configured.
Another problem is that Frontera is like a water system for a nuclear power plant. There are consumers and manufacturers in it. It is very important for them to control such characteristics as flow rate and productivity in different places of the system. It should be recalled here that Frontera is an online system. Classic Robots ( Apache Nutch), on the contrary, work in batch mode: first, a portion is planned, then downloaded, then parsed and planned again. Simultaneous parsing and planning are not provided in such systems. Thus, we are faced with the problem of synchronizing the speed of various components. It’s quite difficult to design a robot that bypasses pages with constant performance with a large number of threads, while storing them in a repository and planning new ones. The response speed of web servers varies, the size and number of pages on the site, the number of links, all this makes it impossible to accurately adjust the components for performance. As a solution to this problem, we want to make a web interface based on Django. It will display the main parameters, and if it turns out to prompt what steps to take to the robot operator.
I have already mentioned modular architecture. Like any open source project, we strive for a variety of technologies that we support. So now we are preparing support for distributed Redis in Pull Request, there have already been two attempts to make support for Apache Cassandra, well, we would like to support RabbitMQ as a data bus.
We plan to at least partially solve all these problems within the framework of Google Summer Of Code 2017. If you find something interesting and you are a student, then let us know at [email protected] and submit an application through the GSoC form . Submission of applications begins on March 20 and will last until April 3. The full GSoC 2017 schedule is here .
Of course, there are also performance issues. At the moment, Scrapinghub is working in pilot mode on a massive page download service based on Frontera. The client provides us with a set of domains to which he would like to receive content, and we download them and put them in S3 storage. Payment for the downloaded volume. In such conditions, we try to download as many pages as possible per unit of time. When trying to scale Fronter to 60 spiders, we were confused with the fact that HBase (via the Thrift interface) degrades when all found links are written to it. We call this data a reference base, but we need it in order to know when and what we downloaded, what response we received, etc. On a cluster of 7 server regions, our number of requests reaches 40-50K per second, and with such volumes, the response time increases significantly. Recording performance drops dramatically. You can solve this problem in different ways: for example, save it in a separate fast log, and then write it in HBase using batch methods, or contact HBase directly bypassing Thrift through your own Java client.
We are also constantly working to improve reliability. Too large a downloaded document or sudden network problems should not cause the components to stop. However, this sometimes happens. To diagnose such cases, we made a signal processor OS SIGUSR1, which saves the current stack of the process to the log. Several times it helped us a lot to figure out what the problem was.
We plan to further improve Frontera, and we hope that the community of active developers will grow.









