Accelerate Home ESXi 6.5 with SSD Caching
Good afternoon!
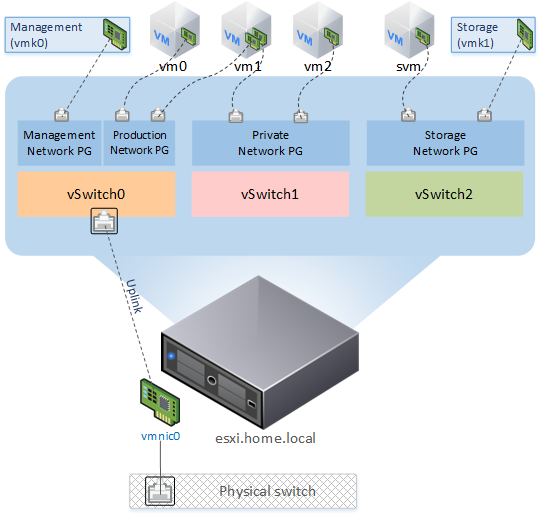
In this article I want to talk about how to slightly increase the performance of the ESXi host using SSD caching. At work and at home I use products from VMware, the home laboratory is built on the basis of Free ESXi 6.5. The host runs virtual machines both for home infrastructure and for testing some work projects (somehow I had to run the VDI infrastructure on it). Gradually, thick VM applications began to run up against the performance of the disk system, and everything did not fit on the SDD. As a solution, lvmcache was chosen. The logic diagram looks like this:

The basis of the whole scheme is CentOS 7 based svm VMs. RDM HDDs and a small VMDK disk from the SSD datastore are presented to her. Caching and data mirroring are implemented by software - mdadm and lvmcache. The VM disk space is mounted to the host as an NFS datastore. Part of the SSD datastore is reserved for VMs that require a powerful disk subsystem.
Computing node is assembled on desktop hardware:
MB: Gygabyte GA-Z68MX-UD2H-B3 (rev. 1.0)
HDD: 2 x Seagate Barracuda 750Gb, 7200 rpm
SSH: OCZ Vertex 3 240Gb
On the motherboard there are 2 RAID controllers:
- Intel Z68 SATA Controller
- Marvell 88SE9172 SATA Controller
I failed to get 88SE9172 in ESXi (There is a bug in the firmware of some Marvell adapters (at least 88SE91xx)), I decided to leave both controllers in ACHI mode.
RDM (Raw Device Mapping) technology allows a virtual machine to access a physical drive directly. Communication is provided through special “mapping file” files on a separate VMFS volume. RDM uses two compatibility modes:
- Virtual mode - works the same as in the case of a virtual disk file, allows you to take advantage of the virtual disk in VMFS (file locking mechanism, instant snapshots);
- Physical mode - provides direct access to the device for applications that require a lower level of control.
In virtual mode, read / write operations are sent to the physical device. The RDM device is presented in the guest OS as a virtual disk file, hardware characteristics are hidden.
In physical mode, almost all SCSI commands are transmitted to the device; in the guest OS, the device is presented as real.
By connecting disk drives to VMs using RDM, you can get rid of the VMFS layer, and in the physical compatibility mode their status can be monitored in the VM (using SMART technology). In addition, if something happens to the host, you can access the VM by mounting the HDD to the working system.
lvmcache provides transparent caching of data from slow HDD devices to fast SSD devices. LVM cache places the most frequently used blocks on a fast device. Turning caching on and off can be done without interrupting work.

When you try to read data, it becomes clear whether this data is in the cache. If the required data is not there, then reading occurs from the HDD, and along the way, the data is written to the cache (cache miss). Further reading of the data will come from the cache (cache hit).
- Write-through mode - when a write operation occurs, data is written both to the cache and to the HDD, a safer option, the probability of data loss during an accident is small;
- Write-back mode - when a write operation occurs, the data is written first to the cache, and then flushed to disk, there is a possibility of data loss during an accident. (A faster option, because the signal about the completion of the write operation is transmitted to the controlling OS after receiving data by the cache).
This is how dumping data from the cache (write-back) to disks looks like:
An SSD datastore is created on the host. I chose this scheme of using the available space: The virtual network looks as follows: A new vSwitch is created: VMkernel NIC connects to it through the port group: A group port is created to which the svm VM will be connected:
You must log in to the host via ssh and run the following commands:
Now these drives can be connected (Existing hard disk) to the new VM. CentOS 7 template, 1vCPU, 1024Gb RAM, 2 RDM disk, 61Gb ssd disk, 2 vNIC (VM Network group port, svm_Network) - during OS installation we use Device Type - LVM, RAID Level - RAID1
Setting up an NFS server is quite simple:
Prepare the cache and metadata volumes to enable caching of the cl_svm / data volume:
Notifications about changes in the state of the array:
At the end of the /etc/mdadm.conf file, you need to add parameters containing the address to which messages will be sent in case of problems with the array, and if necessary, specify the sender address: For the changes to take effect, you need to restart mdmonitor service:
Mail from VM is sent using ssmtp. Since I use RDM in virtual compatibility mode, the host itself will check the status of disks.
Preparing the host
Add the NFS datastore to ESXi: Configure VM autorun: This policy will allow the svm VM to start first, the hypervisor will mount the NFS datastore, after which the rest of the machines will turn on. Shutdown occurs in the reverse order. The VM start-up delay time was selected based on the results of the crash test, because with a small Start delay NFS value, the datastore did not have time to mount, and the host tried to start VMs that are not yet available. You can also play with the parameter . You can configure VM autostart more flexibly using the command line:
Minor optimization
Enable Jumbo Frames on the host: In Advanced Settings, set the following values: Enable Jumbo Frames on VM svm:
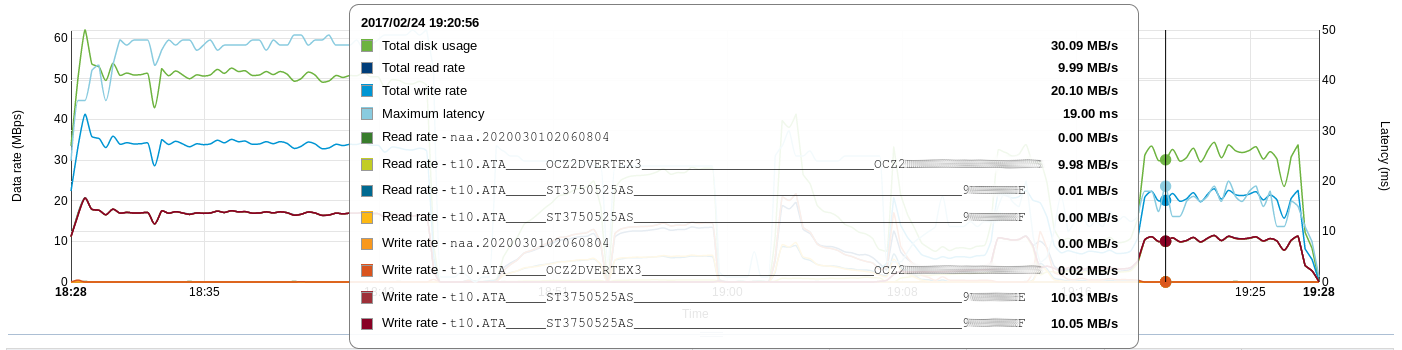
Performance was measured with a synthetic test (for comparison, I took readings from the cluster at work (at night)).
Used software on the test VM:
- CentOS 7.3.1611 OS (8 vCPU, 12Gb vRAM, 100Gb vHDD)
- fio v2.2.8
The results are presented in the tables (* during the tests noted the average CPU load on the svm VM):
The results that you can touch with your hands were obtained while running five VMs with Windows 7 and the office suite (MS Office 2013 Pro + Visio + Project) at startup. As the cache warms up, the VMs load faster, with the HDD practically not participating in the boot. At each start, I noted the time of full load of one of the five VMs and full load of all VMs.
The load time of a single VM was: In the form of a graph:

After the host was turned on and loaded, the svm VM booted up with the FS check (the data remained in the cache), the NFS datastore was mounted on the host, then the rest of the VMs were loaded, there were no problems and data loss.
I decided to turn off the power of the SATA drive. Unfortunately, hot swapping is not supported; you must crash the host. Immediately after a drive is disconnected, information appears in Events. It turned out to be an unpleasant moment that when a disk is lost, the hypervisor asks VM svm to answer the question - “You may be able to hot remove this virtual device from the virtual machine and continue after clicking Retry. Click Cancel to terminate this session ”- the machine is in a frize state. If you imagine that there was a temporary, insignificant problem with the disk (for example, the reason for the loop), then after fixing the problem and turning on the host, everything boots up normally.

The most unpleasant situation is the failure of ssd. Access to data is in emergency mode. When replacing ssd, you must repeat the system setup procedure.
If a disaster is about to happen (according to the results of SMART), in order to replace it with a working one, you must perform the following procedure (on the svm VM):
In the VM settings, you need to "tear off" the dying vHDD, then replace the HDD with a new one.
Then prepare the RDM drive and add svm to the VM:
One of the disks is connected to the workstation, then you need to “collect” the RAID, disable the cache and access the data by mounting the LVM volume:
I also tried to boot the system directly from the disk, set up the network and connected the NFS datastore to another host - VMs are available.
As a result, I use lvmcache in write-through mode and a section for the cache size of 60Gb. Having sacrificed a little CPU and RAM resources of the host - instead of 210Gb very fast and 1.3Tb slow disk space, I got 680Gb fast and 158Gb very fast, with fault tolerance (but if the disk fails unexpectedly, you will have to participate in the process of accessing data).
In this article I want to talk about how to slightly increase the performance of the ESXi host using SSD caching. At work and at home I use products from VMware, the home laboratory is built on the basis of Free ESXi 6.5. The host runs virtual machines both for home infrastructure and for testing some work projects (somehow I had to run the VDI infrastructure on it). Gradually, thick VM applications began to run up against the performance of the disk system, and everything did not fit on the SDD. As a solution, lvmcache was chosen. The logic diagram looks like this:
The basis of the whole scheme is CentOS 7 based svm VMs. RDM HDDs and a small VMDK disk from the SSD datastore are presented to her. Caching and data mirroring are implemented by software - mdadm and lvmcache. The VM disk space is mounted to the host as an NFS datastore. Part of the SSD datastore is reserved for VMs that require a powerful disk subsystem.
Computing node is assembled on desktop hardware:
MB: Gygabyte GA-Z68MX-UD2H-B3 (rev. 1.0)
HDD: 2 x Seagate Barracuda 750Gb, 7200 rpm
SSH: OCZ Vertex 3 240Gb
On the motherboard there are 2 RAID controllers:
- Intel Z68 SATA Controller
- Marvell 88SE9172 SATA Controller
I failed to get 88SE9172 in ESXi (There is a bug in the firmware of some Marvell adapters (at least 88SE91xx)), I decided to leave both controllers in ACHI mode.
Rdm
RDM (Raw Device Mapping) technology allows a virtual machine to access a physical drive directly. Communication is provided through special “mapping file” files on a separate VMFS volume. RDM uses two compatibility modes:
- Virtual mode - works the same as in the case of a virtual disk file, allows you to take advantage of the virtual disk in VMFS (file locking mechanism, instant snapshots);
- Physical mode - provides direct access to the device for applications that require a lower level of control.
In virtual mode, read / write operations are sent to the physical device. The RDM device is presented in the guest OS as a virtual disk file, hardware characteristics are hidden.
In physical mode, almost all SCSI commands are transmitted to the device; in the guest OS, the device is presented as real.
By connecting disk drives to VMs using RDM, you can get rid of the VMFS layer, and in the physical compatibility mode their status can be monitored in the VM (using SMART technology). In addition, if something happens to the host, you can access the VM by mounting the HDD to the working system.
lvmcache
lvmcache provides transparent caching of data from slow HDD devices to fast SSD devices. LVM cache places the most frequently used blocks on a fast device. Turning caching on and off can be done without interrupting work.
When you try to read data, it becomes clear whether this data is in the cache. If the required data is not there, then reading occurs from the HDD, and along the way, the data is written to the cache (cache miss). Further reading of the data will come from the cache (cache hit).
Record
- Write-through mode - when a write operation occurs, data is written both to the cache and to the HDD, a safer option, the probability of data loss during an accident is small;
- Write-back mode - when a write operation occurs, the data is written first to the cache, and then flushed to disk, there is a possibility of data loss during an accident. (A faster option, because the signal about the completion of the write operation is transmitted to the controlling OS after receiving data by the cache).
This is how dumping data from the cache (write-back) to disks looks like:
System Setup
An SSD datastore is created on the host. I chose this scheme of using the available space: The virtual network looks as follows: A new vSwitch is created: VMkernel NIC connects to it through the port group: A group port is created to which the svm VM will be connected:
220Gb — DATASTORE_SSD
149Gb — Отведено для особых ВМ
61Gb — Том для кэша и метаданных
10Gb — Host Swap CacheNetworking → Virtual Switches → Add standart virtual switch — указываем желаемое имя виртуального свитча (svm_vSwitch, в названиях я использую префикс svm_), остальное оставляем как есть.Networking → VMkernel NICs → Add VMkernel NIC
— Port group — New Port group
— New port group — Имя порт группы — svm_PG
— Virtual switch — svm_vSwitch
— IPv4 settings — Configuration — Static — указываем IP и маску сетиNetworking → Port Groups → Add port group — указываем имя (svm_Network) и свитч svm_vSwitchDisk preparation
You must log in to the host via ssh and run the following commands:
Отобразить пути всех подключенных дисков:
# ls -lh /vmfs/devices/disks/
lrwxrwxrwx 1 root root 72 Feb 22 20:24 vml.01000000002020202020202020202020203956504257434845535433373530 -> t10.ATA_____ST3750525AS_________________________________________9*E
lrwxrwxrwx 1 root root 72 Feb 22 20:24 vml.01000000002020202020202020202020203956504257434b46535433373530 -> t10.ATA_____ST3750525AS_________________________________________9*F
Перейти в директорию, где будут размещаться «mapping file»:
# cd /vmfs/volumes/DATASTORE_SSD/
Создаем RDM в режиме виртуальной совместимости:
# vmkfstools -r /vmfs/devices/disks/vml.01000000002020202020202020202020203956504257434845535433373530 9*E.vmdk
# vmkfstools -r /vmfs/devices/disks/vml.01000000002020202020202020202020203956504257434b46535433373530 9*F.vmdkVM preparation
Now these drives can be connected (Existing hard disk) to the new VM. CentOS 7 template, 1vCPU, 1024Gb RAM, 2 RDM disk, 61Gb ssd disk, 2 vNIC (VM Network group port, svm_Network) - during OS installation we use Device Type - LVM, RAID Level - RAID1
Setting up an NFS server is quite simple:
# yum install nfs-utils
# systemctl enable rpcbind
# systemctl enable nfs-server
# systemctl start rpcbind
# systemctl start nfs-server
# vi /etc/exports
/data 10.0.0.1(rw,sync,no_root_squash,no_subtree_check)
# exportfs -ar
# firewall-cmd --add-service=nfs --permanent
# firewall-cmd --add-service=rpc-bind --permanent
# firewall-cmd --add-service=mountd --permanent
# firewall-cmd --reloadPrepare the cache and metadata volumes to enable caching of the cl_svm / data volume:
Инициализация диска и расширение группы томов:
# pvcreate /dev/sdc
# vgextend cl_svm /dev/sdc
Создание тома с метаданными, в "man" написано, что этот том должен быть в 1000 раз меньше тома с кэшем:
# lvcreate -L 60M -n meta cl_svm /dev/sdc
Создание тома с кэшем:
# lvcreate -L 58,9G -n cache cl_svm /dev/sdc
Создание кэш-пула из томов:
# lvconvert --type cache-pool --cachemode writethrough --poolmetadata cl_svm/meta cl_svm/cache
Связываем подготовленный кэш-пул с томом данных:
# lvconvert --type cache --cachepool cl_svm/cache cl_svm/data
Статистику можно посмотреть в выводе:
# lvs -o cache_read_hits,cache_read_misses,cache_write_hits,cache_write_misses
CacheReadHits CacheReadMisses CacheWriteHits CacheWriteMisses
421076 282076 800554 1043571Notifications about changes in the state of the array:
At the end of the /etc/mdadm.conf file, you need to add parameters containing the address to which messages will be sent in case of problems with the array, and if necessary, specify the sender address: For the changes to take effect, you need to restart mdmonitor service:
MAILADDR alert@domain.ru
MAILFROM svm@domain.ru#systemctl restart mdmonitorMail from VM is sent using ssmtp. Since I use RDM in virtual compatibility mode, the host itself will check the status of disks.
Preparing the host
Add the NFS datastore to ESXi: Configure VM autorun: This policy will allow the svm VM to start first, the hypervisor will mount the NFS datastore, after which the rest of the machines will turn on. Shutdown occurs in the reverse order. The VM start-up delay time was selected based on the results of the crash test, because with a small Start delay NFS value, the datastore did not have time to mount, and the host tried to start VMs that are not yet available. You can also play with the parameter . You can configure VM autostart more flexibly using the command line:
Storage → Datastores → New Datastore → Mount NFS Datastore
Name: DATASTORE_NFS
NFS server: 10.0.0.2
NFS share: /dataHost → Manage → System → Autostart → Edit Settings
Enabled — Yes
Start delay — 180sec
Stop delay — 120sec
Stop action — Shut down
Wait for heartbeat — No
Virtual Machines → svm → Autostart → Increase Priority
(Автозапуск не сработал, пришлось удалить ВМ из Inventory и добавить заново)NFS.HeartbeatFrequencyПосмотреть параметры автозапуска для ВМ:
# vim-cmd hostsvc/autostartmanager/get_autostartseq
Изменить значения автостарта для ВМ (синтаксис):
# update_autostartentry VMId StartAction StartDelay StartOrder StopAction StopDelay WaitForHeartbeat
Пример:
# vim-cmd hostsvc/autostartmanager/update_autostartentry 3 "powerOn" "120" "1" "guestShutdown" "60" "systemDefault"Minor optimization
Enable Jumbo Frames on the host: In Advanced Settings, set the following values: Enable Jumbo Frames on VM svm:
Jumbo Frames: Networking → Virtual Switches → svm_vSwitch указать MTU 9000;
Networking → Vmkernel NICs → vmk1 указать MTU 9000NFS.HeartbeatFrequency = 12
NFS.HeartbeatTimeout = 5
NFS.HeartbeatMaxFailures = 10
Net.TcpipHeapSize = 32 (было 0)
Net.TcpipHeapMax = 512
NFS.MaxVolumes = 256
NFS.MaxQueueDepth = 64 (было 4294967295)# ifconfig ens224 mtu 9000 up
# echo MTU=9000 >> /etc/sysconfig/network-scripts/ifcfg-ens224Performance
Performance was measured with a synthetic test (for comparison, I took readings from the cluster at work (at night)).
Used software on the test VM:
- CentOS 7.3.1611 OS (8 vCPU, 12Gb vRAM, 100Gb vHDD)
- fio v2.2.8
Последовательность команд запуска теста:
# dd if=/dev/zero of=/dev/sdb bs=2M oflag=direct
# fio -readonly -name=rr -rw=randread -bs=4k -runtime=300 -iodepth=1 -filename=/dev/sdb -ioengine=libaio -direct=1
# fio -readonly -name=rr -rw=randread -bs=4k -runtime=300 -iodepth=24 -filename=/dev/sdb -ioengine=libaio -direct=1
# fio -name=rw -rw=randwrite -bs=4k -runtime=300 -iodepth=1 -filename=/dev/sdb -ioengine=libaio -direct=1
# fio -name=rw -rw=randwrite -bs=4k -runtime=300 -iodepth=24 -filename=/dev/sdb -ioengine=libaio -direct=1The results are presented in the tables (* during the tests noted the average CPU load on the svm VM):
| Disk type | FIO depth 1 (iops) | FIO depth 24 (iops) | ||
|---|---|---|---|---|
| randread | randwrite | randread | randwrite | |
| HDD | 77 | 99 | 169 | 100 |
| SSD | 5639 | 17039 | 40868 | 53670 |
| SSD Cache | FIO depth 1 (iops) | FIO depth 24 (iops) | CPU / Ready *% | ||
|---|---|---|---|---|---|
| randread | randwrite | randread | randwrite | ||
| Off | 103 | 97 | 279 | 102 | 2.7 / 0.15 |
| On | 1390 | 722 | 6474 | 576 | 15 / 0.1 |
| Disk type | FIO depth 1 (iops) | FIO depth 24 (iops) | ||
|---|---|---|---|---|
| randread | randwrite | randread | randwrite | |
| 900Gb 10k (6D + 2P) | 122 | 1085 | 2114 | 1107 |
| 4Tb 7.2k (8D + 2P) | 68 | 489 | 1643 | 480 |
The results that you can touch with your hands were obtained while running five VMs with Windows 7 and the office suite (MS Office 2013 Pro + Visio + Project) at startup. As the cache warms up, the VMs load faster, with the HDD practically not participating in the boot. At each start, I noted the time of full load of one of the five VMs and full load of all VMs.
| No. | Datastore | First start | Second launch | Third launch | |||
|---|---|---|---|---|---|---|---|
| First VM boot time | Download time of all VMs | First VM boot time | Download time of all VMs | First VM boot time | Download time of all VMs | ||
| 1 | HDD VMFS6 | 4min 8sec | 6min 28sec | 3 min. 56sec | 6min 23sec | 3 min. 40sec | 5 minutes. 50sec |
| 2 | NFS (SSD Cache Off) | 2 minutes. 20sec | 3 min. 2sec | 2 minutes. 34sec | 3 min. 2sec | 2 minutes. 34sec | 2 minutes. 57sec |
| 3 | NFS (SSD Cache On) | 2 minutes. 33sec | 2 minutes. 50sec | 1 minute. 23sec | 1 minute. 51sec | 1 minute. 0sec | 1 minute. 13sec |
The load time of a single VM was: In the form of a graph:
— HDD VMFS6 - 50 секунд
— NFS с выключенным кэшем - 35 секунд
— NFS с включенным и нагретым кэшем - 26 секундCrush test
Power off
After the host was turned on and loaded, the svm VM booted up with the FS check (the data remained in the cache), the NFS datastore was mounted on the host, then the rest of the VMs were loaded, there were no problems and data loss.
HDD failure (imitation)
I decided to turn off the power of the SATA drive. Unfortunately, hot swapping is not supported; you must crash the host. Immediately after a drive is disconnected, information appears in Events. It turned out to be an unpleasant moment that when a disk is lost, the hypervisor asks VM svm to answer the question - “You may be able to hot remove this virtual device from the virtual machine and continue after clicking Retry. Click Cancel to terminate this session ”- the machine is in a frize state. If you imagine that there was a temporary, insignificant problem with the disk (for example, the reason for the loop), then after fixing the problem and turning on the host, everything boots up normally.
SSD Failure
The most unpleasant situation is the failure of ssd. Access to data is in emergency mode. When replacing ssd, you must repeat the system setup procedure.
Maintenance (Disk Replacement)
If a disaster is about to happen (according to the results of SMART), in order to replace it with a working one, you must perform the following procedure (on the svm VM):
Посмотреть общее состояние массива:
# cat /proc/mdstat
или для каждого устройства:
# mdadm --detail /dev/md126 /dev/md126
Пометить разделы неисправными:
# mdadm --manage /dev/md127 --fail /dev/sda1
# mdadm --manage /dev/md126 --fail /dev/sda2
Удалить сбойные разделы из массива:
# mdadm --manage /dev/md127 --remove /dev/sda1
# mdadm --manage /dev/md126 --remove /dev/sda2In the VM settings, you need to "tear off" the dying vHDD, then replace the HDD with a new one.
Then prepare the RDM drive and add svm to the VM:
Перечитать список устройств, где X — номер SCSI шины Virtual Device Node в настройках vHDD:
# echo "- - -" > /sys/class/scsi_host/hostX/scan
С помощью sfdisk скопировать структуру разделов:
# sfdisk -d /dev/sdb | sfdisk /dev/sdc
Добавить получившиеся разделы в массив, установить загрузчик и дождаться окончания синхронизации:
# mdadm --manage /dev/md127 --add /dev/sdc1
# mdadm --manage /dev/md126 --add /dev/sdc2
# grub2-install /dev/sdcEmergency Data Access
One of the disks is connected to the workstation, then you need to “collect” the RAID, disable the cache and access the data by mounting the LVM volume:
# mdadm --assemble --scan
# lvremove cl_svm/cache
# lvchanange -ay /dev/cl_svm/data
# mount /dev/cl_svm/data /mnt/dataI also tried to boot the system directly from the disk, set up the network and connected the NFS datastore to another host - VMs are available.
Summary
As a result, I use lvmcache in write-through mode and a section for the cache size of 60Gb. Having sacrificed a little CPU and RAM resources of the host - instead of 210Gb very fast and 1.3Tb slow disk space, I got 680Gb fast and 158Gb very fast, with fault tolerance (but if the disk fails unexpectedly, you will have to participate in the process of accessing data).