Storage Class Memory in the storage system - if you need even faster
 As you probably remember, HPE has long invested in the topic of new types of data storage (of course, The Machine ) and in optimizing access to storage (our membership in the Gen-Z consortium ).
As you probably remember, HPE has long invested in the topic of new types of data storage (of course, The Machine ) and in optimizing access to storage (our membership in the Gen-Z consortium ). The goal of this movement is to speed up the work of our customers' applications. Moreover, this movement is multilevel: while the completely new architecture of the computer systems The Machine (the so-called memory-centric architecture) is being forged, we understand that we need to accelerate now. Let's see what can be done today and what HPE will have tomorrow. Hint - we will talk about a strong acceleration of our 3PAR and Nimble storage systems using smart and budget caching on Storage Class Memory (SCM) in the form of Intel Optane.
First, we establish the boundaries of the problem under study. In this post, we are not interested in high performance computing with its own specifics and are not interested in tasks that require only intra-server fast storage. The latter are undoubtedly also a topic for Intel Optane and SCM in general, but such tasks are often specific, difficult to virtualize and, therefore, consolidate. We will talk about tasks and applications that get along well with external 3PAR, Nimble or MSA class storage systems (although we will not touch MSA either).
So, how can you improve the performance of a virtualized application that works with data on an external storage system:
- see what app is holding back now. Perhaps it’s not at all in the storage system, but in anticipation of the processor, in the internal logic of working with data, in suboptimally written queries;
- if there are large delays on the part of data waiting (IO), then first it is worth checking whether all recommendations for configuring the application-OS drivers (SCSI, HBA, etc.) are followed.
- possible deal in the SAN network (Ethernet, FC);
- Perhaps it's all the same in the storage system. Where in storage? In the controller's hardware (what's with the cache, what is the CPU usage), in the controller's OS and drivers, in the data bus, in the disks ...
Possible course of thought: Oh, sure - the wheels! Everything else is difficult and you do not want to touch, but with the disks we will try. What we have, a hybrid - well, it means you need all-flash. Do we have all-flash? And what is better? We look advertising respected brands:

Everything is clear, we take storage with "NVMe-disks". Wait, how much? And I need to buy a new storage system, I can not upgrade my current one? Well, it should be so ...

Is it possible in a different way after all? We at HPE believe that it is not only possible, but necessary. And that's why:

The fact is that most NVMe SSDs on the market right now are the same type of media, NAND-flash, only connected to the controller not by Serial Attached SCSI (SAS) protocol, but by the new NVMe protocol. The new protocol is no doubt beautiful, and here are some facts:
- 64,000 queues available with 64,000 streams each - IOPS above the roof
- controller directly in the CPU - lower CPU load
- each processor core sees each SSD directly - low latency
With a complete replacement of the SCSI protocol all the way from the application to the disks, it is possible to significantly reduce access latency. But what do marketers offer us today? "NVMe disks". Those. the whole chain up to the storage controller itself remains the same - SCSI. And then the controller simply repackages the SCSI in NVMe and so it communicates with the connected NAND SSD.
The result on the graph above is the minimum gain in delay. Although the gain on peak IOPS can really be very noticeable. The traditional analogy: do you need a car that can accelerate quickly for overtaking in 5 seconds, or a car that in ideal conditions can accelerate to 300 km / h in 10 minutes? Both options are good, but more often they choose the first one.
The reality is that the gain from NVMe NAND today is hardly noticeable for real applications, and in our opinion is not worth the difference in price and loss in available capacity compared to SAS SSD.
What HPE offers instead of simply replacing the “last mile” from SAS to NVMe is using brand new Intel Optane drives connected via NVMe as a read cache in the controllers of our 3PAR and Nimble storage systems.

(Both the adding machine and the admin in the photo are called Felix, but the difference is huge!)
Why we decided to go this way:
- so we can offer our customers to upgrade the already purchased storage systems (specifically 3PAR 9450, 20450, 20850 and Nimble AF60 and AF80 - all top all-flash)

- at the same time, in a very simple way (by adding an expansion card with Optane on board to each controller), we reduce the maximum delay by about 15 times, and the average delay - by 30-40% (IOPS also grow, but oh well). And most importantly, the delay does not jump from marketing " from 0.2 ms!" ad infinitum (marketing is not ours, just quoting), but it becomes much more stable:

(Delays based on HPE internal tests) - more specifically, what can be expected from such a decrease in the delay on the array for your favorite Oracle, for example: according to our internal tests, the IO wait is reduced by an average of 37%, and the execution of SQL selects is accelerated by 27%.
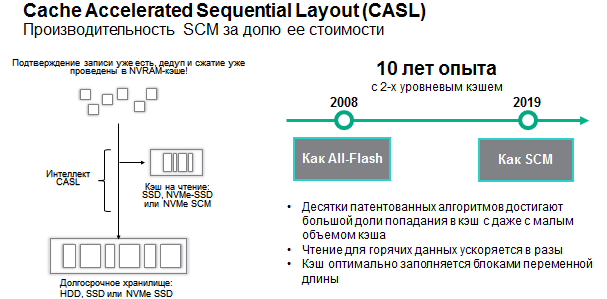
- Why is the cache read and not write? Because both in 3PAR and Nimble for many years, DRAM is used as a write cache (in the case of Nimble, non-volatile NVRAM). It, in turn, is many times faster than NVMe devices, and until the advent of Gen-Z or similar new protocols will remain so. Those. write speed through NVMe is not necessary.
- Why Intel Optane? Because it is the newest type of carrier, even if it is lagging behind the NAND in density, but an order of magnitude faster than the response. Plus, Optane has an almost inexhaustible resource for rewriting. In general, for loaded systems, the cost of a transaction on Optane is much lower than on NAND NVMe. And the cache is a layer very loaded from all directions. Hot data is copied to it from a slower layer (therefore a resource is needed), it is read from it if the data is not found in the controller's NVRAM cache (therefore, a fast response is needed so that going beyond the NVRAM cache does not look like a trip to the hypermarket compared to with going to the convenience store).
- why not put the NVMe-drives all the same? Be sure to put! For example, the Nimble chassis allows the installation of such disks right now (the backplane is ready for this), but we still do not sell such disks for Nimble, because it's early. SCM-cache now gives multiple performance gains for relative pennies. So let's use it while NVMe NAND still has a lot to get cheaper, the NVMe protocol itself is still evolving (multi-pathing appeared in the standard only in March 2018, and still lags far behind the stability of SCSI), and in general the NVMe ecosystem from application to disk still undeveloped (NVMe over fabric went to kindergarten, manufacturers argue about how it should look, drivers have minimal functionality so that they don’t rewrite too much when everything is fixed).
- Well, also because we love to cache everything. Here, for example, about Nimble:
By the way, are you familiar with HPE InfoSight ? With this tool you always know where to look for the delay. For example, like this:

(Those who have found a delay, please contact us.)
It's time to summarize: if you are a happy owner of 3PAR 9000 or 20,000, then you can order 3PAR 3D Cache based on Intel Optane right now. If you are looking at the array Nimble All-flash - take, because it is a reliable base to protect investments in the future. Start with SAS NAND SSD now, connect the All Flash Turbo-cache based on SCM later, then change the drives to NVMe.

For reference:
- here's a recent Nimble webinar: HPE Nimble Development: paranoid + data protection and other new features
- and here is a webinar about Intel Optane in the HPE portfolio: Optane number - we increase the power of your data center with Intel technologies .
- Post-based blog of the leader of the military wing Nimble: recoverymonkey.org/2018/11/30/hpe-memory-driven-architectures-extend-to-3par-and-nimble-storage .