Reporting system: how to get 50 million reports and save Zen

The more complex the software product, the more it interacts with third-party systems (often no less complex), the higher the likelihood of malfunctions. Testing helps to find most bugs before rolling out a release, but sometimes something can slip through . And in order to quickly receive detailed information about the fact of a failure and related conditions, a reporting system is widely used in our products. We want to talk about its device today.
{kind=link}
Usually applications crash due to bugs or unpredictable user actions. To understand the cause of the crash, you need to collect different information: in what environment the application works, what the user did. In general, data that can help us solve the problem. For this, a system is used to send reports on the operation of the application and on the facts of failures.

In addition to investigating the causes of failures, we use reports to analyze user behavior. To do this, we approximately every three months initiate anonymous collection of statistics on the use of our applications. We look at what functions are used most often and in what situations, whether users have difficulties. This helps us adjust our product development plans. Take for example Parallels Desktop. We are interested in how many users run one virtual machine, two, four, and so on. If most of them have one VM, then it is obvious that it makes no sense to optimize the interface for using several virtual machines, and so on.
Implementation Details
Reports are sent both automatically when the application crashes, and on the initiative of users. They include application logs, crash dumps, memory dumps, machine configuration information, and sometimes some other service information. All this is packed into a tar.gz file, the size of which ranges from units to hundreds of megabytes, and is sent to our server. Here the file is subjected to primary processing, service information is added to it - the sender's IP address and timestamp - and then the file is uploaded to MongoDB.
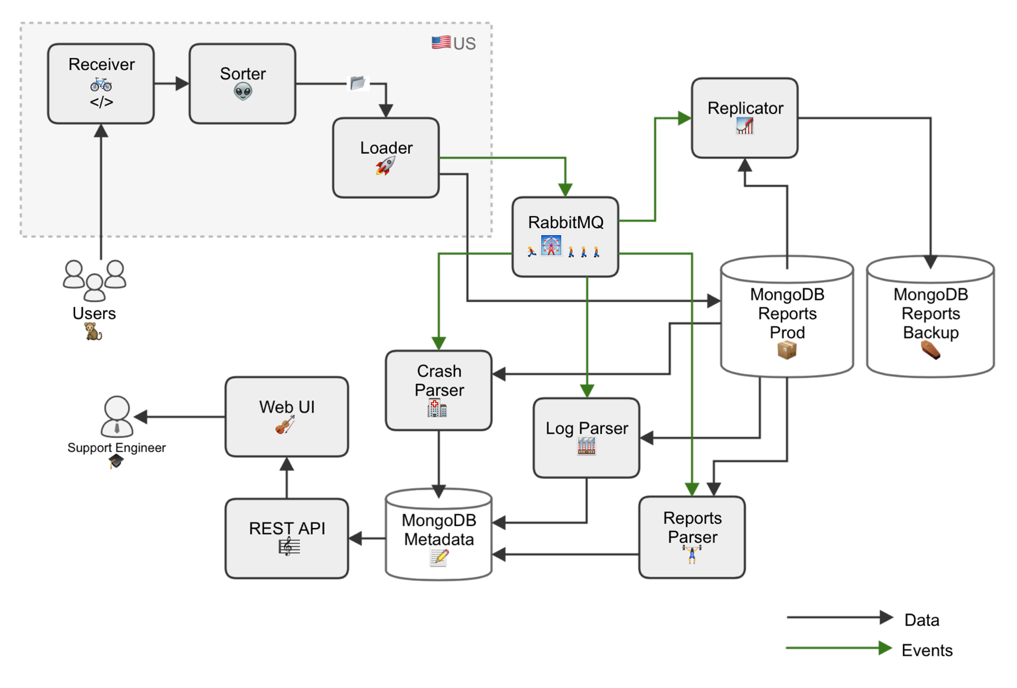
Then there are two options for the development of events:
• Developers can manually analyze XML files, logs and configuration in order to understand what environment the application works in and what the user did
• The report can be automatically classified and included in the general statistics
The classification is done this way: parsers written in Python receive from RabbitMQ the ID of the reports uploaded to MongoDB, extract state-trace from them, and according to some rules they assign a text label - a signature. Parsers extract the necessary data from XML files and add them as separate documents with indexed fields.
We also have special parsers, each of which processes specific types of crash reports. They go through each report and see if there are files of interest to them. For example, one parser searches only for Mac reports, another searches only for Windows, and so on. Then they build the signature in the same way. Reporting components are deployed using Chef .
General statistics on real-time reports are displayed on a special web page where you can sort data by signatures and individual fields. For example, according to Mac OS, guest OS and product version. This helps to quickly understand what problem needs to be solved in the first place, if the number of some signatures suddenly starts to grow sharply, for example, after the next update.
Server park
On average, we process about 400,000 reports per month, 100 gigabytes. Over 10 years, we have accumulated more than 50 million diverse reports. The servers that receive reports are located in the United States, because most of our users are located there. But data storage, processing and analysis are carried out in Russia. Sometimes it used to happen that reports arrived faster than we had time to process and transmit across the ocean. Now we have already tested and started to implement a system that uses queues and microservices for parsing. The number of microservices can be changed depending on the current load, so the only bandwidth can become the only limitation.
How many servers serve our reporting system:

If necessary, any of the subsystems can be scaled to adapt to the growing load.

Reports are not only a source of detailed information about failures, but also an “early warning” system. Often, users do not contact support immediately, but only having encountered a problem several times. But thanks to automatic reports, we will quickly see an increase in the number of failures and immediately begin to solve the problem. Often we will fix a bug even before a wave of calls goes in support.