The most needed program in the world

What programs do people constantly use? If you think about this issue, it turns out that this list is not so big. Constantly used programs include: the operating system itself, file manager, text editor, browser, messenger. This is exactly the basic set that almost everyone uses on a computer. The requirements for such programs should be high: trouble-free operation, fast execution of all functions, clear and convenient interface.
We can say that the above set of programs is the most necessary programs that people use in the digital age. This list covers all the basic human user needs. Or not all? Is there another basic need that is not included in the above list of the most necessary programs? Is this need the most important one that a computer needs to automate? For me there is such a need, but she did not find a place in the list of the most used programs. What is this need?
Historical retrospective
Previously, a computer was considered a device for computing. Even household old computers focused on a very advanced user who used a computer for computing by writing his own small programs. For full work with the computer, the user had to know a programming language. The further rise of more advanced computer platforms occurred largely due to the appearance of the first versions of spreadsheets, which were also aimed at computing, but reduced the requirements for the user, without forcing him to be a programmer. In any case, this was the period when the purpose of the computer corresponded directly to its name. The computational module itself - the processor - was put at the forefront, because it was the appearance of the microprocessor that made the appearance of the computer itself possible.
However, the subsequent development did not focus on improving the performance of processors. All components of the computer developed, and, in particular, memory. The memory is operational, and the memory is permanent. At that moment, when it became clear that the computer is capable of storing and quickly delivering unprecedented amounts of data, it became possible to realize another long-standing human dream on the computer: the accumulation and quick extraction of data. Make a kind of unlimited memory, some place in which you can put information, and then quickly find and extract it. So began to develop databases and query languages.
Gradually, the world's largest database appeared - the Internet, with all its billions of sites: Wikipedia, libraries, forums and social networks. Search tools have changed dramatically, and an ordinary user cannot even have a personal search engine on the Internet - it is almost impossible, and not necessary.
The computer has tried on many roles for all the years of IT development. The computer is a very universal thing, and the digital universe is able to accommodate all the manifestations of human imagination. And it is good that so far the necessary minimum of programs has been formed that demonstrates the evolutionary path that humanity has gone through in its needs in the digital age. These needs, frankly, are strongly shifted to the field of consumption and transmission of content. Not to say that this is bad, but ...
Behind all this riot of technology, a very important dream of many people from antiquity to the present day, which is well implemented in the form of a personal computer, has moved a little to the side. This dream is to get a personal intellectual assistant with infinite memory, who would help a person, if not think, then remember and find the knowledge (and not data!) That a person has already managed to comprehend, or at least fluently saw from the corner of his eye, or knew that Something is needed in some library. This alone would help bring human development to a new qualitative level. Perhaps the ancient Greeks could say that we need to develop our own brains (when writing developed, many Greeks demonstrated the wonders of quoting from memory, neglecting records). However, a lot of time has passed, the world has changed, and now our civilization has rested in a restriction: in our time, the human brain does not cope with the amount of information that you need to know and remember. There is too much information. And this did not happen today, but at the time of the victorious march of the scientific and technological revolution.
History knows at least one conceptual project in which an attempt was made for the first time to solve the aforementioned problem at a new technological level. An American analog computer development engineer, Van Vivar Bush, suggested moving away from notebooks, records, files, libraries, and a crowd of personal secretaries to a device that could replace all of this. He proposed in the 40s of the last century the concept of the MEMEX device . Here is how it is described:
... an electromechanical device that allows you to create an autonomous knowledge base, equipped with associative links and notes, which can be transferred to other similar knowledge bases at any time. This device was supposed to most accurately simulate the associative processes of human thinking, in the absence of flaws, such as "forgetting" information.
The description of this device ultimately indirectly influenced the appearance of HTML hypertext markup, but now we are interested in just the class of programs that would in some way implement the idea of this concept. Attention should be paid to the words “autonomous knowledge base” - they are key for us. Are there any programs that fall under this definition? Of course have! These are personal information managers (PIM), mind-map solutions, some organizers and their various hybrids.
Search for the perfect helper
The peculiarity of choosing the ideal personal assistant is that such a program is selected for decades. And this requirement imposes great restrictions on potential candidates.
Due to my beliefs, when I looked for a suitable program, I focused primarily on cross-platform and open source code. The first requirement - cross-platform - is connected with the fact that I use Linux on home computers, and I am instructed to use Windows at work, and what platform I will have to work tomorrow - I don’t know for sure. But I know for sure that on every platform I need the same assistant. The openness of the code is associated with many factors, but the most important is the security in time and in the space of the code. Time safety is a firm belief that tomorrow the author of a proprietary program will not close his project or raise the price of a license. Security in code space is the certainty that a program will not merge stored personal data into places where there is nothing for this data to do.
Of course, an essential factor is the openness of the format of the stored data. Nothing should interfere with “fleeing from the format” if for some reason the initial choice of an assistant was unsuccessful. It would be very unpleasant to part with the accumulated knowledge base simply because it is stored in a proprietary format.
Note: why do I use the term “knowledge base” and not “database”? Because I would like to accumulate knowledge, not data. The question is what is the mechanism for turning data into knowledge. In the general case, we can say that data turns into knowledge after they are understood by a person. It is after this thought process that a person, looking at familiar records (data), can use them as knowledge.
As it turned out, there are not so many programs that meet the above criteria. And at first I even greatly lowered the bar of requirements, telling myself that in the extreme case there is Wine, and why be afraid of closed formats - others use it. And I went through a large number of projects in order to understand what exactly would suit me best.
From proprietary products, I reviewed linear and tree-like PIM managers, tried the mind-map solutions, felt the ability to record in organizers. None of what I tried approached me: there was always some unpleasant flaw that stopped me from further using the product. Good text editor, but linearity of entries instead of tree view. The presence of a tree, but a terrible editor. Attempts to make a limited set of record types that do not describe the whole variety of possible situations. Inability to receive data from office programs or from a browser window. Falls within five minutes with elementary actions. An ill-conceived interface, severe clutter of the workspace, overlapping elements on top of each other in Russian versions. It’s possible that things are better now, but eight years ago I was horrified that they offer people to buy for money. In fact, Microsoft OneNote and some Chinese combin with a bunch of functions and buttons that, surprisingly, all worked (perhaps it was TreeDBNotes) turned out to be more or less completed from the whole zoo. But seeing what destructive marketing Microsoft is involved in, I did not get involved with OneNote. And at that time, I could not purchase a Chinese combine because the payment was made either by a currency bank card or via PayPal, but I didn’t have either. But basically I was not going to pirate. I didn’t get involved with OneNote. And at that time, I could not purchase a Chinese combine because the payment was made either by a currency bank card or via PayPal, but I didn’t have either. But basically I was not going to pirate. I didn’t get involved with OneNote. And at that time, I could not purchase a Chinese combine because the payment was made either by a currency bank card or via PayPal, but I didn’t have either. But basically I was not going to pirate.
In the free software camp, I touched CherryTree, Zim, KOrganizer, KeepNote, even tried using Eclipse in a separate directory, creating a tree of subdirectories and opening text and HTML files in it. The problems turned out to be the same: major and minor flaws that prevent the full use of the program, or great inconvenience instead of working as in the case of Eclipse (it is not intended for such things, and it slows down, because Java). Even a more or less decent CherryTree, for example, could not curl up in a systray when clicking on the cross in the window title: it just finished the job. Under Linux, I somehow solved the problem, but on Windows it turned out to be unsolvable. At one time, I refused WinAmp when he suddenly forgot how to fold and continue to work when clicking on the cross. After all, a personal assistant is such a thing,
By the way, about the tree.The human brain is used to classifying everything. This is his strength. For example, such a complex thing as the classification of living beings from Aristotle and Theophrast to Robert Hook and Karl Linnaeus has a tree structure to this day. And although according to modern concepts, the origin of species is no longer a tree but a graph, and electronic encyclopedias in the structuring of information generally exclude tree-like appearance, which together indirectly suggests that the tree is unsuitable for describing all possible data groupings, I still think that the tree - this is a convenient compromise between simplicity of linearity (as in the first versions of Evernote) and complexity of the graph (as in Wikipedia). At a minimum, when constructing a tree, you can always single out one conditionally main feature by which information can be grouped. But the presence of a tree gives that support
The tree has many other useful properties: growing up without significant thickening, hierarchy, visibility. You can easily make a graph out of a tree: just add connections between branches.
Creating the perfect helper
In general, I found myself in a classic situation: if you want to get something good, do it yourself. At that moment, I was looking at the positive Qt framework, which was released in its 4th version. And I decided that there is nothing better than making my own manager who would satisfy me to the best of my own abilities. Even if the project doesn’t work, I can at least learn in practice a promising cross-platform framework.
I read a couple of books, sat down in programming, and made the first minimal version of the program. I called her MyTetra . She looked like this:
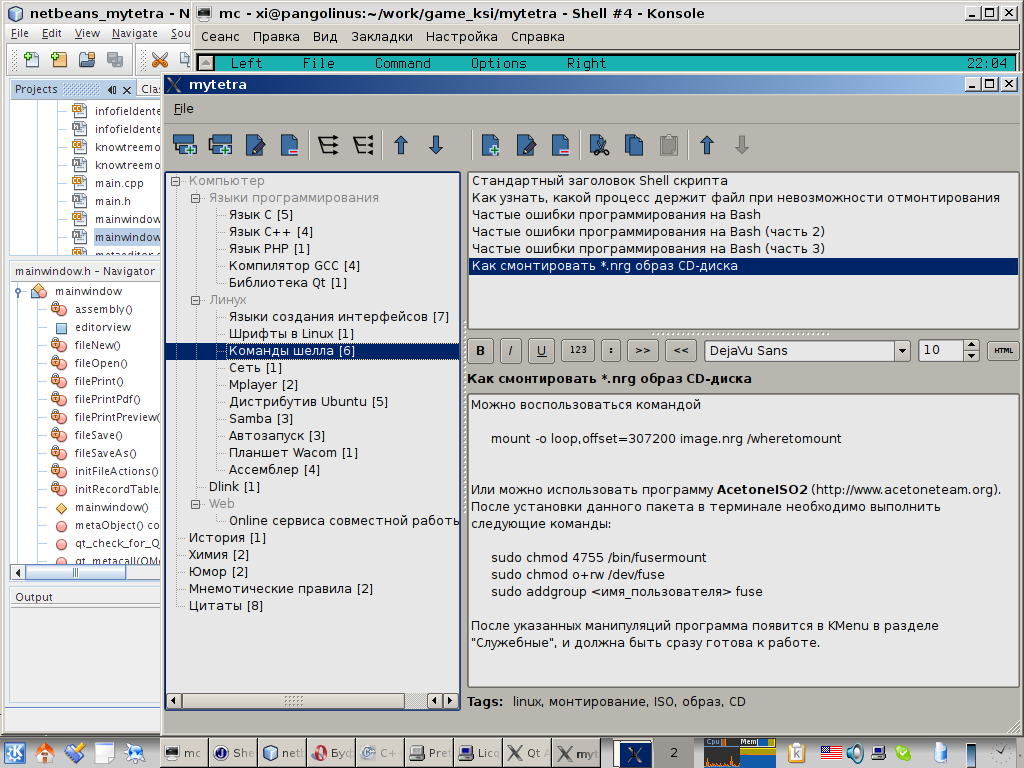
Initially, I sharpened those little things that I lacked in other managers: normal folding to tray, dividing the tree into entities "branch" and "record", counting the number of entries in the branches, copy-paste entries through the clipboard. There wasn’t even a search in the first version, but I started filling out the database with my notes in order to feel whether it was possible to keep the information in the tree, if I wouldn’t be bent on the fact that I needed different “slices” of the tree (I was passionately convinced of the need for an automatically reconfigurable tree one comrade), whether there will be a need for grouping according to various criteria. And he quickly realized that a tree performs its function of “basis” well, especially if you yourself have grown this tree.
I initially made the data storage format in a “natural” form, and I was not going to use any of my own binary formats. I also refused to store data in the database. All formats are open: the tree is stored in an XML file, formatted text in HTML, pictures in PNG, settings in INI. Initially, the structure was designed so that the data was neatly laid out in files, and succumb to differential synchronization through version control systems. The names of the stored files and directories are made platform independent: after all, the cross-platform program should work on any modern platform without alterations and side effects. All these are elementary things, but it turns out that developers of similar programs do not always understand them: for example, the author of OutWiker allows you to give directories Russian-language names - that is,
For entities “branch” and “record”, I determined the main actions that can be performed with them: create, edit, copy, paste, move, delete. And when this minimum worked and search appeared, I combed the code a bit and released the first public version.
What did I write to my program? First of all, I began to write down such information that I had forgotten all the time, and finding it in a simple form is very difficult. There are such things that you constantly climb into your notes. For example, in Linux, man pages are traditionally written in the form of “minimum necessary and sufficient”, therefore, it is very difficult to quickly understand the command line options of a program. For example, packaging options for the tar.gz archive: four badly pronounced letters that you always forget.
I also began to write down in detail the actions that I perform when setting up some kind of linux software. Often in Linux it is difficult not only to configure the program, but also difficult to install, not to mention run it. And for the program to start, it is necessary to do not five and not fifteen unobvious actions, but much more. By the end, if something happened, a person no longer remembers exactly what he was doing at the beginning. And if you wrote down - then there is no such problem.
I also recorded really good materials from the Internet or “squeezes” that I made based on them. It so happens that for a long time you can not figure out any issue. And suddenly you come across a text in which everything is explained in detail, easily and simply. It is a pity to lose such a text: it can disappear from the Internet, you can simply forget about it, having earned it. But if you throw it into your knowledge base, you can feel a sense of reassurance that this important information will not go anywhere, and will remain with you. Honestly, I don’t understand people who bookmark in the browser: it’s unpleasant to bookmark and know that at some point the information may disappear. Several times my prudence helped me out: interesting material disappeared from the Internet, but remained in my database.
And of course, I wrote down all the possible information on my household electronic devices, login passwords for admin pages and other Internet services, phone numbers and addresses of all kinds of organizations and acquaintances, other small things that are very important, but hard to remember.
Gradually, the base grew, and the program changed. At the moment, it looks like this (by the way, this is a screenshot from Linux, not Windows):
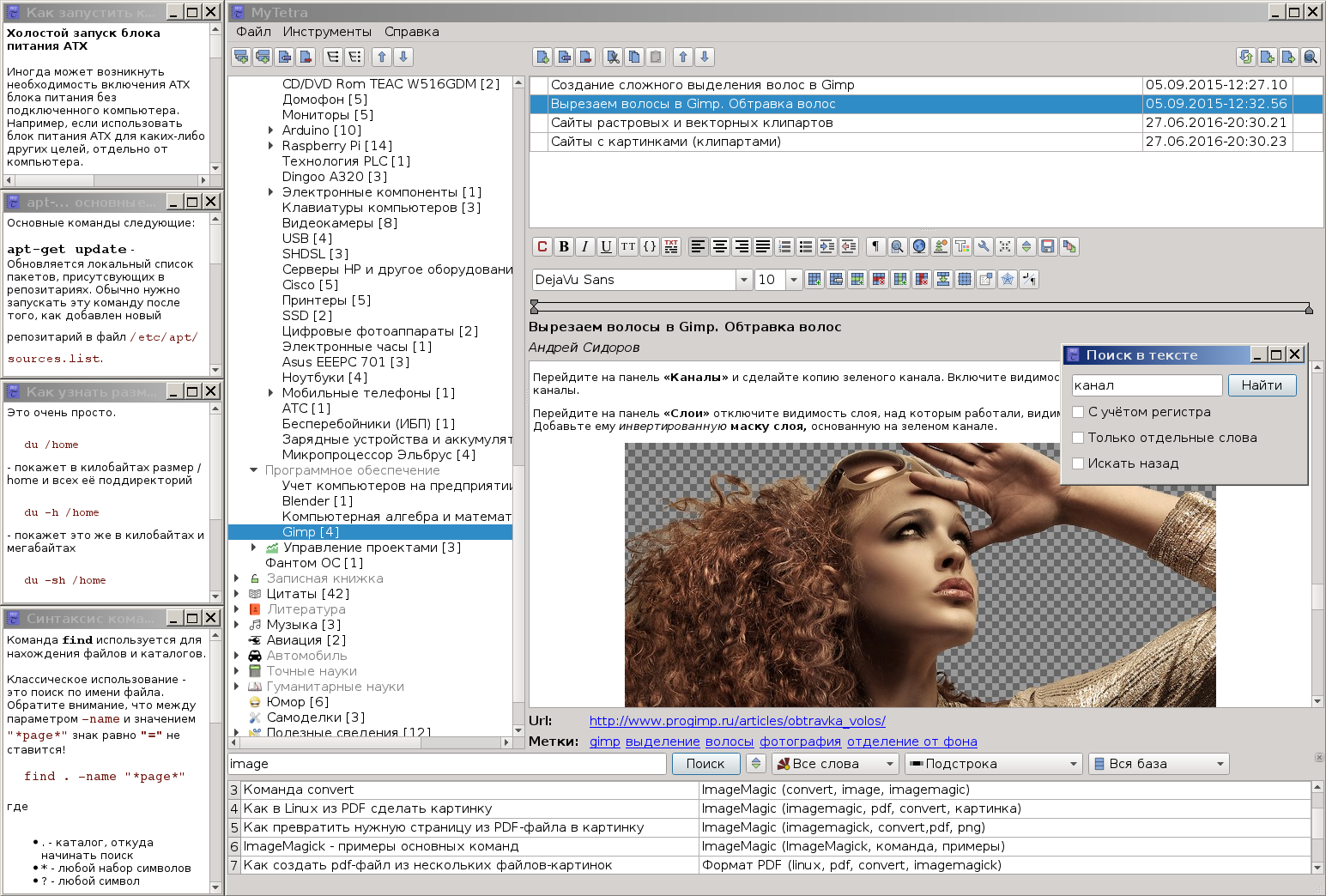
Yes, given that hosting of distributed version control systems, such as GitHub and BitBucket, as well as cloud storage like DropBox or Yandex.Disk, are now easily accessible, it would be a sin not to use them to store your knowledge bases in them for free. At the same time, the issue of backup and synchronization was solved. There was only one problem: the storage of private data. In the open, they cannot be uploaded to the hosting. Therefore, a small cryptographic library was developed, and on its basis encryption of the selected branches was made. That is, it became possible to safely store private data in plain sight. Why was the library made and not used the existing one? Because the manager is positioned as Qt-only. It should be easy to build with qmake & make on any platform where only Qt is available. and do not require any additional libraries. This principle makes it easy to get builds for all popular platforms: Linux, Windows, MacOs, FreeBSD, Android, and even for such exotic as MeeGo. However, versioning is provided for in the encryption format, and perhaps I will someday screw on OpenSSL when I figure out how to include it in the project for all of the above platforms.
In addition to encryption, the program implemented custom synchronization, history navigation, a built-in preloader, attachments, a sortable list of records, and much more. After five years of open development, we got a PIM manager with the characteristics that were needed: open, cross-platform, easy and fast, able to work for months without shutting down, with a set of functionality that is necessary for convenient work on recording.
As a person who uses MyTetra every day, I currently have about 5,000 entries in it. The average increase is about 1000 records per year. For comparison: the author of the Evernote service Stepan Pachikov in one of his interviews mentioned 20,000 entries. However, he has a different concept: he collects everything in his system, using it as an “external” human memory. I collect the information I need, draw it up, tag it, that is, I work with the information with my hands. And over the past three years, such statistics have accumulated:
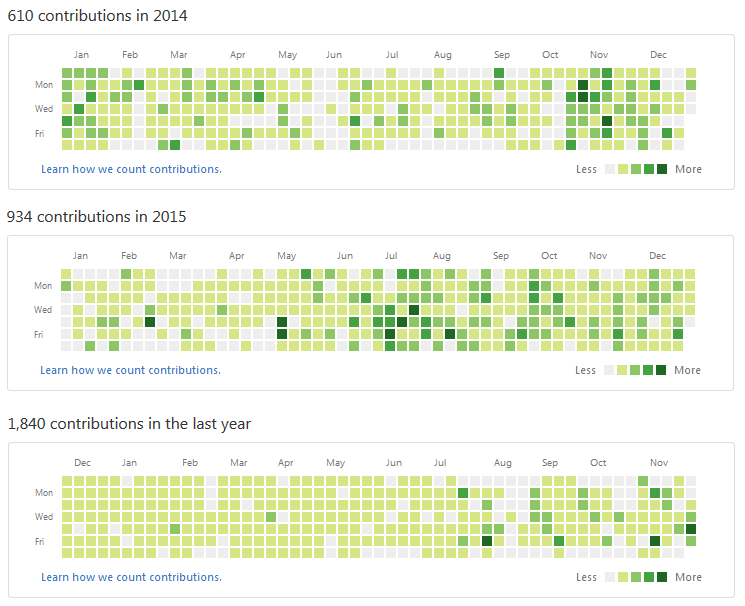
Not everyone can boast of such a Contributions Map on GitHub. And I don’t even notice how these statistics were collected, since MyTetra is my daily work tool.
MyTetra and the Internet
The personal record manager is, of course, good. Everyone can make their own small garden and secretly cut their knowledge base. How much personal data is in such a database, and how many that other people might need? From my own experience I’ll say that records that can be shared are about 2/3 of the total. This is taking into account the fact that in private recordings I have constant daily work, that is, their percentage is very large.
Once I was playing with visualization of my database through the GraphViz package. And to understand the scale of my open data, I made a couple of pictures. Here in the composite picture, the cloud is rotated 90 degrees, otherwise it would look too wide. About 3,000 open entries are displayed here. The full database would be ~ 2000 entries more.

Links to full-size pictures (Attention! Pictures are very large, the browser can go awry. It’s better to download them and view them as a viewer.):
Tree PNG 1.751 x 32.767 pix (7.2 Mb)
{kind=link}
Cloud PNG 31.279 x 5.289 pix (19.2 Mb)
{kind=link}
It's a pity that large arrays of knowledge are simple they lie on users' disks, and they don’t even have the opportunity to share them, even if they wanted to, because there is no corresponding infrastructure.
What is the reason for users to share their knowledge bases? Everyone decides for himself. Someone wants to "repay debts" to the information community, someone simply believes that on the ascent, everyone should share their knowledge. Someone needs to improve their karma. Someone wants to do this simply for altruistic reasons, and some of them are practical: it’s convenient to look into their open records from any place where there is Internet.
In general, in addition to the record accumulation program itself, I decided to create a service that allows me to display my records on the Internet. Initially, I made a JavaScript application that can feed the URL of the MyTetra database index file, accessible via HTTP (S). And this application opens the MyTetra database in a WEB interface reminiscent of the MyTetra Qt interface. I called this application MyTetra Web Client . This case looks like this:
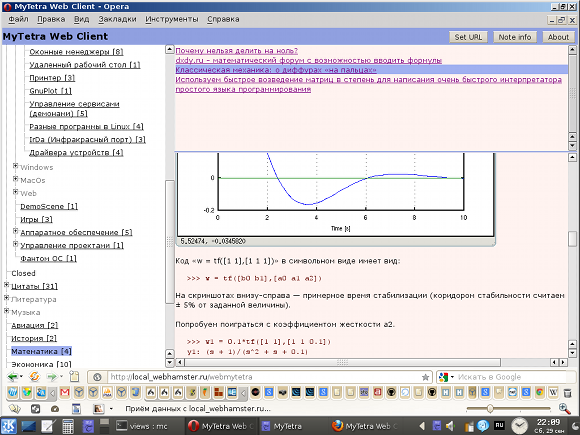
This client was written in 2012, and since then I have not developed it. This is a very simple shell in which not even a search has been done for the name of the records and tags. Just a demonstration that the MyTetra database can be seen in a browser directly on the Internet, if you store data in the open GitHub or BitBucket repositories. The client works now, and you can see a demonstration of his work like this:
- Copy the following URL to the clipboard: https://raw.github.com/xintrea/mytetra_syncro/master/mytetra.xml
- Follow the Web Client link , and paste this URL in the dialog that appears. (Sometimes GitHub does not respond due to the large number of requests from the IP of my site, so if nothing is shown, you can click the “Set URL” button in the upper right again)
If there is another MyTetra database stored somewhere in open HTTP (S) access - GitHub, BitBucket, the shared DropBox directory, then you can also see it, just specify the URL of the mytetra.xml file. No registration is required - everything just works. If the database has private encrypted branches, then they simply do not appear: there is no point in showing people what is impossible to read.
However, this web client has one drawback: in fact, it is just a JavaScript page, and the data displayed on it is not indexed by search engines. What is the use of knowledge bases if no one knows about them?
So I made a second project called MyTetra Share. The motto of the project: "Share knowledge!". This service dynamically converts the MyTetra knowledge base into a set of HTML pages that can be viewed over the Internet. On the official page of the project, 8 user bases are listed that you can immediately view. The principle is the same as for MyTetra Web Client: if the database is stored in open repositories, you can create a special URL to open the contents of the knowledge base in HTML form. If the search engine indexes such a URL, then it will go further and index the entire contents of the open database. As I said, there are now 8 such databases ( an example of one database ), and they are indexed by search engines. MyTetra Share looks like this. The tree itself:
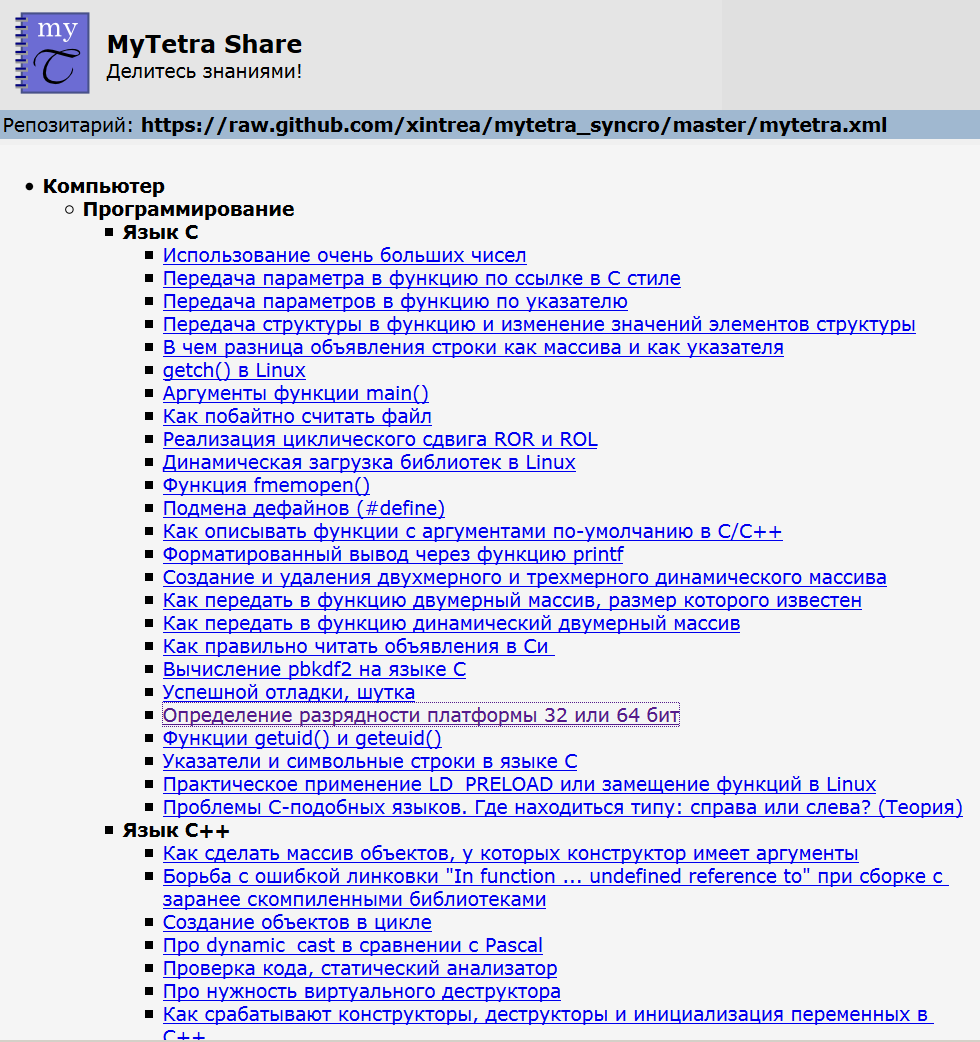
And the entry:

This project turned out to be more popular, and with the help of it I was even able to monetize the contents of my homepage and MyTetra Share service: text ads can be seen on some pages. These funds are enough to pay for hosting, domain name and pay for a mobile phone. It would be possible to earn more, but I immediately put a hard filter on all kinds of audio drugs, slot machines, vibrators, microloans, on sorcerers and psychics. Unfortunately, even in text advertising, the main profits come from obscurantism and debauchery. I’m focusing on aligning the digital universe in a more proper direction, so such things are not allowed on my site.
Thanks to the placement of well-tagged information, the MyTetra Share project generated a citation index for the site of 100 TICs, and provided about 3000 visitors per day. For the Pet project, this is not a good indicator, given that I did not engage in any promotion.
About unfulfilled hopes
What hopes did I have for this gigantic and long-term project? The most important thing that I wanted from the project was the formation of at least a small, but constant development team, so that it would be possible to develop not as a single programmer, but in close communication with my own kind. The second hope was that I could figure out the C ++ language, and finally feel the ease of programming on it. Unfortunately, neither one nor the other happened.
Periodically, people appeared who made small edits and bug fixes in the project. And I am very grateful to them. Sometimes they did something for the project themselves, without asking, sometimes I myself turned to the community of ENT and Toaster, and there were people who helped solve a specific problem. But these are all isolated cases, the whole project has to be pulled by yourself.
As for the C ++ language, it turned out to be much more complicated and ambiguous than I could have expected ten years ago when I started to use it heavily. Unfortunately, my work is not related to programming: where I live, you won’t earn such a thing. In my environment there are no acquaintances who at least knew the difference between the “ones” and the “pluses”, only a couple of PHP encoders. And so it turns out that if there is no personal communication with the mouth and ears with the board and felt-tip pen at hand, then there is no development. There is no one to discuss difficult things with so that there is no misunderstanding and they fit well in the head. Perhaps the books that I highly recommended would help me:
- Nicholas A. Salter, Scott J. Kleper, “C ++ for Professionals”
- Bruce Eckel, “C ++ Philosophy” (1st volume)
- Bruce Eckel, “C ++ Philosophy. Practical Programming ”(2nd volume)
but I can’t find them in paper form anywhere. I can’t get deep reading from the screen. The maximum that I can read is fiction from a book reader. But I don’t perceive technical. Perhaps because book readers are one “sheet”, and I need to quickly jump back and forth in search of different places, but book readers do not allow this, they are too slow and uncomfortable.
I tried to improve my understanding of C ++ by looking at lectures from distance learning courses. The most sane thing I have found is the courses of Eugene Linsky on lektorium.tv. But all the same, lectures on the Internet cannot be attributed to studies: you won’t ask the video for things that you did not understand during the lecture. So there’s little sense in such “training”.
In general, for me, C ++ remained a mystery. I use a very small part of the language - procedures and OOP, painfully write patterns, if you can not do without them. Every time I cry from the syntax of pointers and addresses. I use inheritance with caution, although I understand that the strength of the language is in it. I look with horror at multiple inheritance and at casting object types. Qt smoothes out all these problems a bit, but it disguises them more than it solves. The apotheosis of my understanding of the language was the news on ENT, which was quickly cut out, here is a small part:
What changes does the initiative group of the C ++ standard offer to make the C ++ language a beautiful, powerful and popular tool for modern development? Of the most notable improvements:
- Inclusion in the standard of conceptors that implement the aspect-oriented paradigm of inherited code;
- Multi-vector scheduling of dynamic polymorphism to translate the polymorphic interface into runtime;
- Native support for kappa functors, and mapping them to sets of Booleans with a covariant structure, which solves the problem of metadata singularity;
- Recursive constructors that reload function objects for friendly generic classes;
- Advanced pointer arithmetic to support addressing of fragments of inherited virtual data structures in the assembly specifier;
- Transformation of mutable objects through access operators to class fields through barking generators.
To make it clear, I wrote this news on April 1 , and it just says a mishmash of terms. I have a similar perception of the language. The funny thing is that the rubbish described above almost did not bother anyone - the people actively discussed the actions of the ISO committee and faded over the name C ++ !! ..
How can you help the project
I don’t even dream about the fact that there will be people who besides me are constantly engaged in the project code. Over the entire development period of the project, there were several people who lasted a little longer than people doing single edits. But their enthusiasm quickly fades away when it comes to the realization that before coding, it is necessary to coordinate the changes. Perhaps someday a miracle will happen, and I will have permanent partners.
Therefore, the real help to the MyTetra project can be only one thing: you need to start using it. If you set up synchronization and start using MyTetra Share, then you will get an amazing thing: you accumulate your knowledge base and automatically share knowledge with the entire Internet, simply using this self-organizing tool. You can use MyTetra Share quietly for yourself, and so that the link to the database appears on the project page, you can inform the author of MyTetra about this desire. A separate article has been written on how to set up synchronization via the Internet .
It is important to understand: if you use free tariffs for CVS hosting like GitHub or BitBucket, then at the beginning of use you accept the hosting rules that your data is open to everyone under various OpenSource licenses. Accordingly, your data may appear on MyTetra Share pages simply by posting it on such open hosting services, without your participation. This is the harsh truth of the OpenSource world, and it is good!
At the official forum, you can express your wishes for the necessary improvements to the program. Although I have my own vision of program functions, reasoned improvements find their reflection in the code.
In order for the project to develop further, as a creator, I need to see that the project is in demand. No objective means are provided for determining the number of program installations: people don’t like it when a program begins to merge some information, even if it previously asked permission to do so. Therefore, the only measure of demand can be correspondence on the forum, the number of email messages and the presence of activity in MyTetra Share.
If the number of databases in MyTetra Share doubles compared to the current one, I will begin work on creating a separate site for the MyTetra project. It is planned to create sections of news, source codes, Wiki, screenshots, post a forum on the new site, transfer MyTetra Share and MyTetra Web Client services there. Perhaps the presence of the site and the English version of the pages will take the project to a new level.
Speaking of English. English-speaking users are constantly contacting me, and I understand that MyTetra has some interest in the English-speaking world. Two official pages - MyTetra and MyTetra Web Client pagehave English versions in crooked English (I translate a lot from, but I can’t translate into). In a good way, they need to be combed and brought in line with Russian-language versions. They also require translation of the page according to MyTetra Share, on data synchronization via the Internet, according to the data storage format (links are given at the end of this post). In addition, it would be nice to get, if not an audio track, then at least English subtitles for review videos (also at the end of the post). I can’t do all this, but maybe someone with a good knowledge of the language will take up such work.
About MyTetra Forks
The author is very pleased that a few months ago, the Chinese developer Beimprovised (real name Hugh Young) forked MyTetra called MyTetra WebEngine . For several months, he frantically commits huge pieces of code on GitHub, which makes him genuinely surprised at its performance. The presence of this fork suggests that the code of the MyTetra program was clear enough and simple so that another developer, even a native speaker of another language, could pick up the project and start making a new product based on it.
Hugh Young has his own vision for the project, and his fork has gone very far from the original MyTetra. But recently, he expressed regret that the paths of the projects have diverged, and he does not have any innovations that appeared in the latest version of MyTetra, and it is problematic to use the new code, because he greatly changed the internal structure of the project.
In any case, the presence of a fork makes me very happy as an author. This means that my efforts to write a project were not in vain.
Conclusion
About the MyTetra program, I wrote several materials that allow you to understand the possibilities inherent in it:
- MyTetra - a program for collecting meaningful information
- MyTetra Share
- MyTetra Web Client
- MyTetra v.1.28 - detailed review
- MyTetra v.1.30 - detailed review
- MyTetra v.1.42 - detailed review
- How to set up synchronization via MyTetra via the Internet
- MyTetra: data storage format
- MyTetra sources on GitHub
There is a good ideological article by a man under the pseudonym Igor Blogrator (unfortunately, I am not familiar with him), in the second part of which MyTetra is considered:
- In search of the mythical Memex. No. 1
- In search of the mythical Memex. Number 2
- In search of the mythical Memex. No. 3
Also, due to the fact that the other day I released the latest version 1.42, I made a video review of the program in 3 parts, a video review was posted on YouTube:
- Video review MyTetra v.1.42. Part 1. Overview of the main features of MyTetra
- Video review MyTetra v.1.42. Part 2. MyTetra settings
- Video review MyTetra v.1.42. Part 3. Innovations in MyTetra v.1.42
In these videos, all aspects of working with the program are described in detail (therefore, the videos are long for 20-40 minutes), and the basic methods of work are considered. MyTetra is not only a note manager, it is a tool that helps organize your own workflow. For example, in MyTetra, you can keep a to-do list and create small reports for yourself. This technique is described in the first part.
According to the new version of MyTetra 1.42 (an anniversary issue for the 5th anniversary of the opening of the source), a news article is published that describes changes and innovations, there is information on installing and updating the program.
I hope the Habrahabr community will like the program, and the ideas embodied in it.