Effective development and maintenance of Ansible roles
Ansible is a system that solves various automation tasks, including configuration, backup and deployment of projects. It is pleasant to use the system for writing automation scripts from simple environments to large projects. In scripts, playbooks play an important role, and structured playbooks play roles.
Ansible is not a magic pill , and helps only at first. As the project grows, it becomes difficult to maintain an expanded number of roles. Helps solve the problem of the mechanism of continuous delivery for roles.
Just about this transcript of Alexander Kharkevich’s report at DevOps Conf Russia. In the report: development of Ansible-roles through CI, a mechanism for developing public roles and public roles with test runs in a private infrastructure. And there is no conclusion in the report.
About Speaker : Alexander Kharkevich ( kharkevich ) Senior Systems Engineer at EPAM Systems .
Let's start with a brief overview.
Ansible is a configuration management system. It is written in Python, Junja is template, and YAML is used as a DSL. Managed via Ansible Tower - WebUI for managing and monitoring system performance.
Ansible appeared in 2012, after 3 years, Red Hat bought the whole project, and two years later introduced AWX - Project Open Source-version of Ansible Tower.
Installation
To use Ansible, you need to do two simple things.
In the first stage, compile an inventory file in the case of a static infrastructure.

On the second - write a Playbook, which will lead the system in the expected state.

Often we have an overwhelming desire to write automation that can be reused. Automation is a good desire, and the guys from Ansible came up with a cool concept - a role.
Role
This is a structured entity that will bring the system into an expected state with the ability to reuse automation.
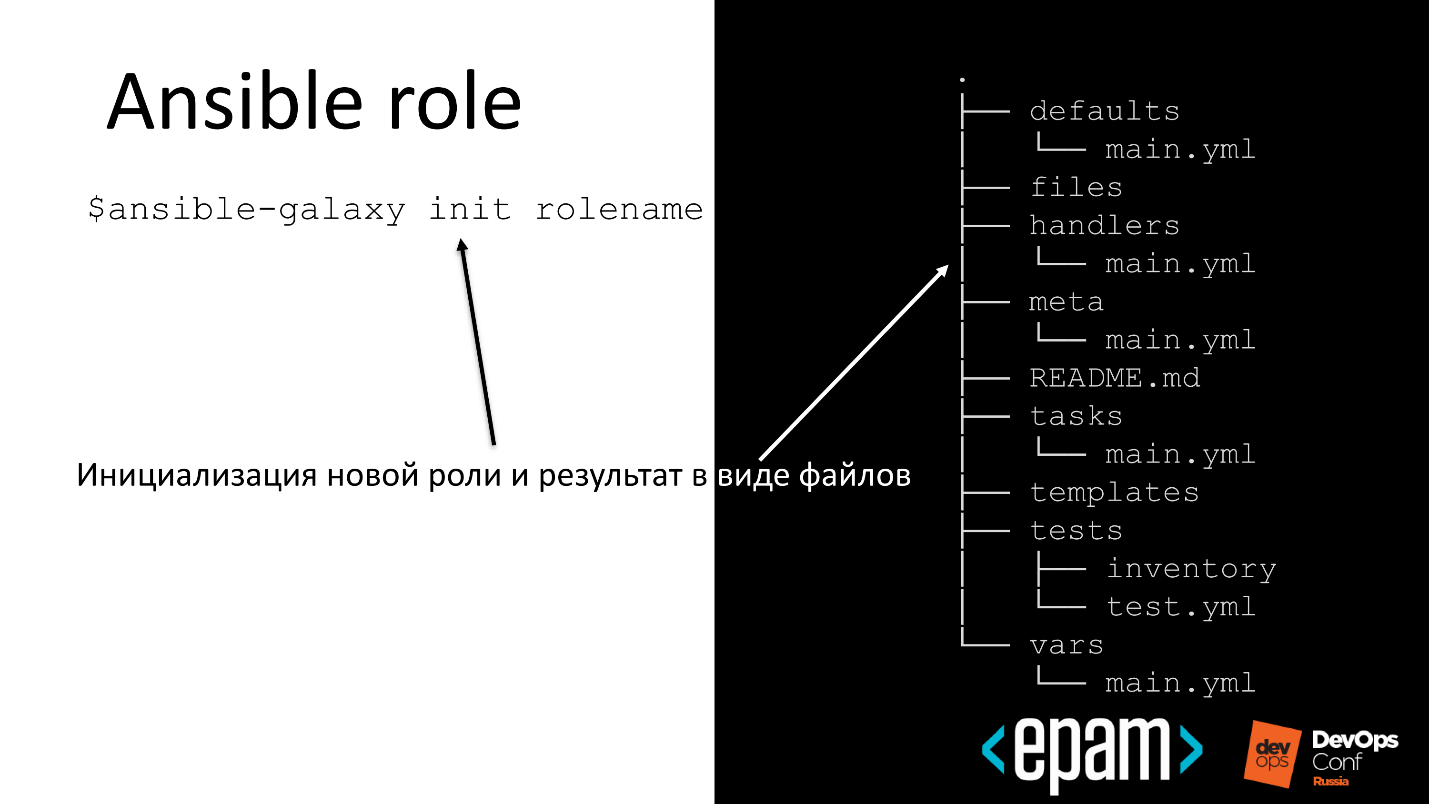
For example, we can write a role for Oracle Java: take a Playbook, put the role and apply it to the target system. At the exit, we get the installed Java.

How we presented work with roles
Since Ansible has such a wonderful thing as a role, we thought that now we would take and write many, many roles for all occasions, fumble, and we will reuse to reduce the amount of work.
We thought that we would write beautiful and clever roles ...

But life turned out to be more difficult.
As it turned out in reality
When more than one person works on writing a role or its improvement, everyone writes in one place and there are unpleasant surprises: the role does not behave in the way that was originally intended by the author.
Well, when it is applied to the end, but it does not always happen. Sometimes the role is successfully executed, but this affects the target system quite differently from the way it was originally intended.

As a result, terrible constructions arise, attempts to transfer bash to Ansible and serve it all under the sauce configuration management. We are faced with this phenomenon and sad.

Thinking, we discovered that in our configuration management there is some kind of code, which means that the practices that are applicable to code management in Systems Development Life Cycle, are applicable in Ansible.
We decided to implement the practice at our place and immediately went to look for suitable tools.
From the point of view of version control systems and continuous integration, there are a dozen solutions available, and a spreading zoo for testing.

From the point of view of release management in Ansible, there are not so many solutions: tagging in Git, or tagging in Git and uploading to Galaxy.
According to the testing tools, there are many approaches, everyone uses what they like. Popular solutions using KitchenCI, InSpec, Serverspec.
Our soul did not lie to take Ansible written in Python, and add tools from the world of Ruby to it. Therefore, having thrown out all non-native to the world of Python, we received the following picture.
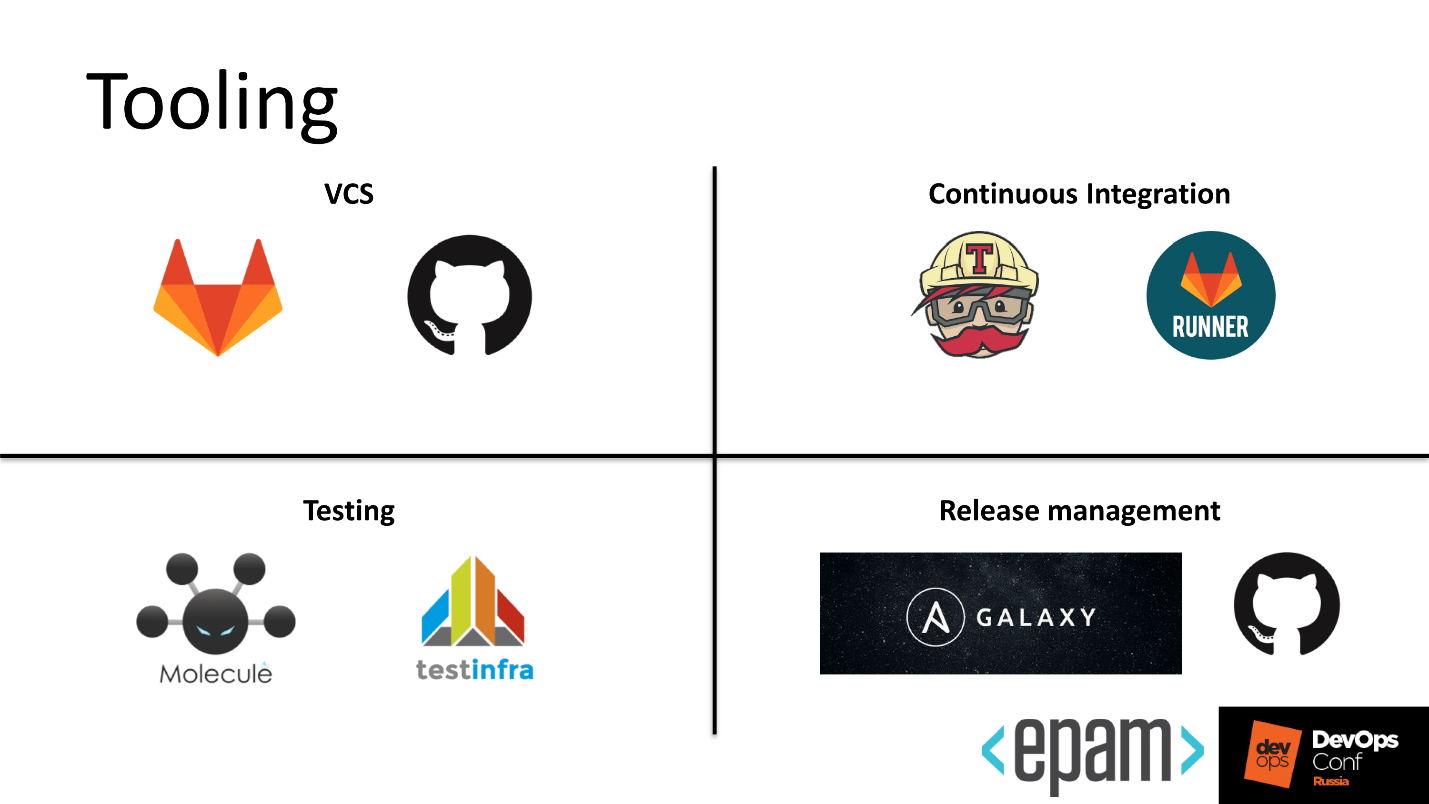
We use:
Our development cycle with these tools began to look more fun.
Molecule
This tool helps to fully test the ansible-role. For this, he has everything:

Test matrix
Consider the test matrix in steps. Total steps 11, but I will be brief.
№ 1. Lint
Run YAML lint and Ansible lint, and find something.
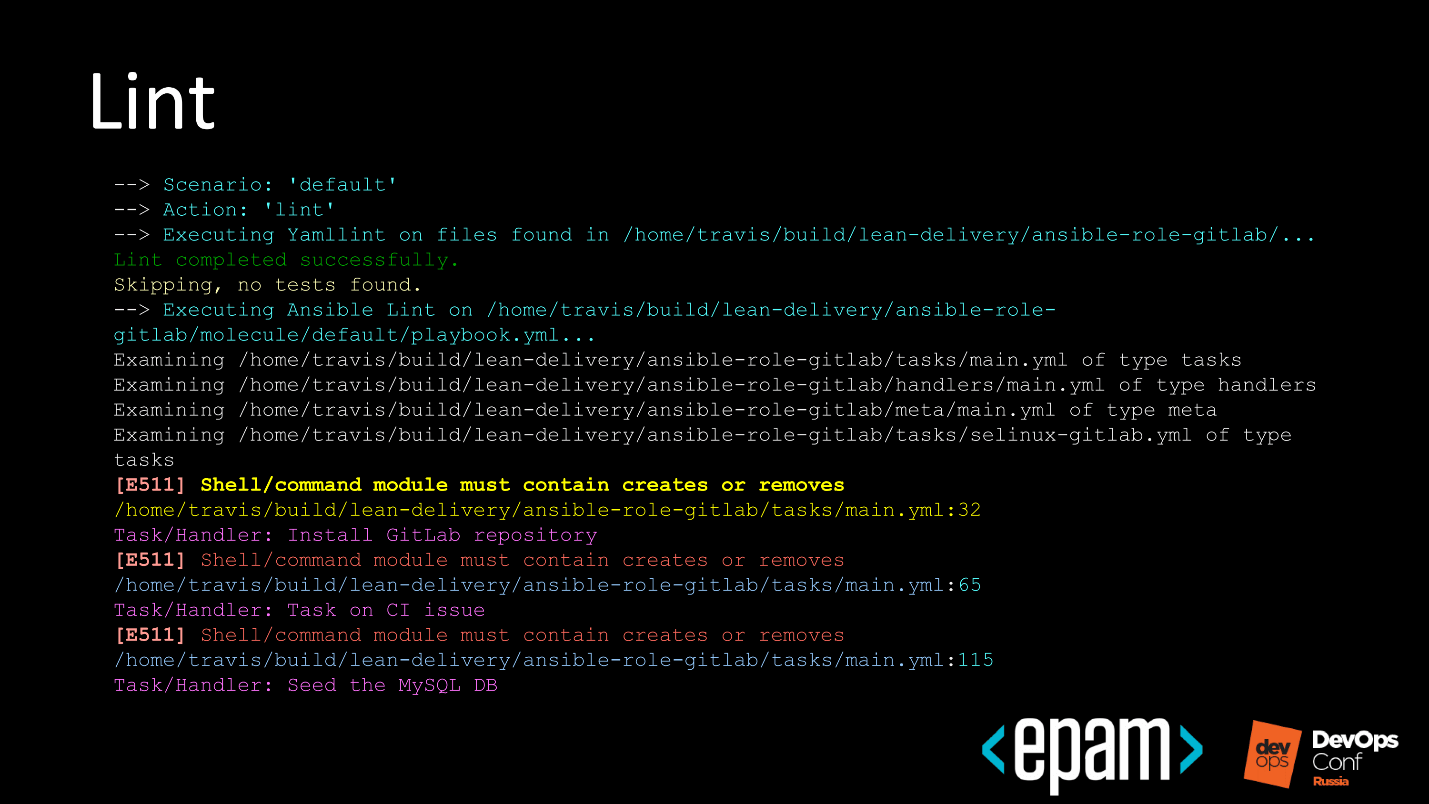
In the example above, lint swears that the shell should not just be called in Ansible, but fixed, binding to something.
Molecule gets rid of everything that remains after previous tests.
There are cases when a run has passed, a test range has developed and testing has ended. The stand should be cleaned at the end, but insuperable forces interfered and there was no cleaning. For such situations, Molecule banishes destroy and cleans the environment from residues.

№ 3. Dependency
Take the requirements.yml file and add our role dependencies to other roles. For example, referring to the fact that the role does not take off without Java installed on the system:
Molecule understands this and executes the script:

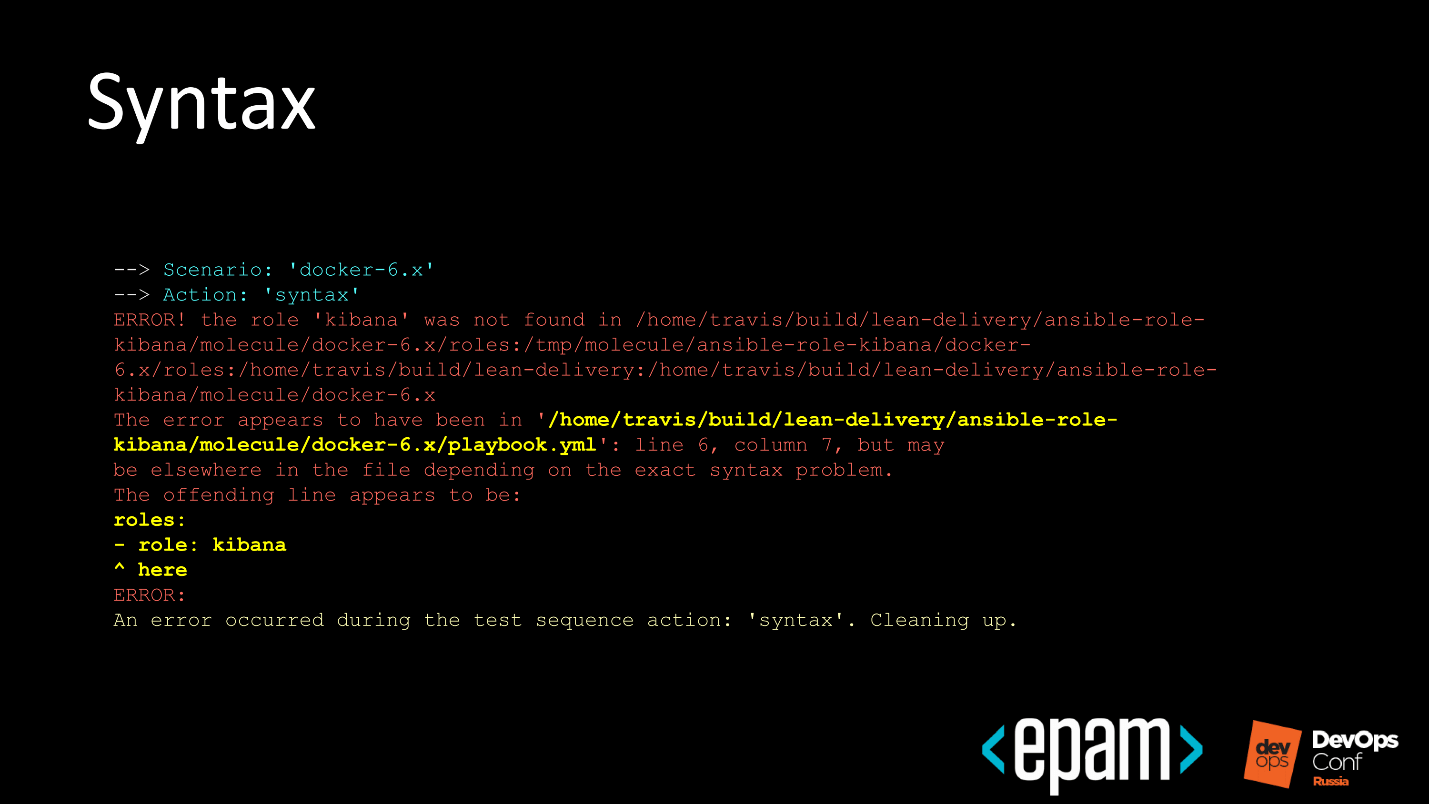
№ 4. Syntax
The next step is syntax checking. but not your role, but the test Playbook that you add to Molecule. At this step, there are also errors associated with the syntax.
The slide shows that the ansible role is called 'kibana', and in the test Playbook, the ansible-role-kibana is called. The system says: “Everything would be fine and you can create here, but I will not do that, because the names do not match!”
№ 5. Create
At this stage, we indicate the driver with which the test polygon is developed. You specify Google - it will lift test machines in Google Cloud.
We can write in the molecule.yml file what we want. Let's see how it looks on the example for Docker.

I want to have two docker-images: one for RHEL-like, the second for Debian-like, to be sure that during the test run everything will be fine with both RHEL and Debian.
№ 6. Prepare
This is a pre-test preparation runtime step.
It seems to be all up, but sometimes you need to perform some additional settings. In the case of testing inside a raised Docker in Debian or Ubuntu, you need to install a second Python, which often happens.
№ 7. Converge
The stage of the first big run of the role to the Instance, to make sure that it reaches the end, is run out, and Ansible confirms that all is well.

№ 8. Idempotence
The idempotency test is simple and looks like this.

As a result, we understand that our role does not act destructively.
This stage caused pain to the guys I work with. They tried to work in ways to defeat idempotency testing. At Molecule, you can control the stages that it passes, and the first thing they did was turn off the idempotency test.

We caught trips and beat for it hands, but the engineers are smart and went deeper. The developers decided to say that this step in Ansible does not change anything.
Although in fact there will be some kind of team. Ansible directly takes and
will overwrite the file, but at the same time everything looks idempotent.

When this trick was also caught, the picture began to look like this.

Well - the script ran under the name default, and it is idempotent.
No. 9. Side_effect
In the next step, side effects are superimposed. It is not necessary to do this, but it is convenient when you test complex spreading roles that are dependent on each other.
For example, lift the ELK stack, then Elasticsearch in a cluster. At the side_effect stage, add test data and delete a couple of nodes from the cluster. The test site is ready for functional tests that occur in the next step.
№ 10. Verify
We are testing the infrastructure.

The above is an example of a very simple test. We check that we have the Docker Community Edition package in case of Ubuntu installed, it has the correct version, and the service is running.
At this stage, the launch of functional tests can all greatly complicate.
Probably the best example would be, in the case of the ELK stack, if we make a request to Elasticsearch on some test data, and since we know the test data, it will respond to us. We will not check that all installed components are assembled, but we will see that Elasticsearch is up, running and displaying exactly what is needed in the search.
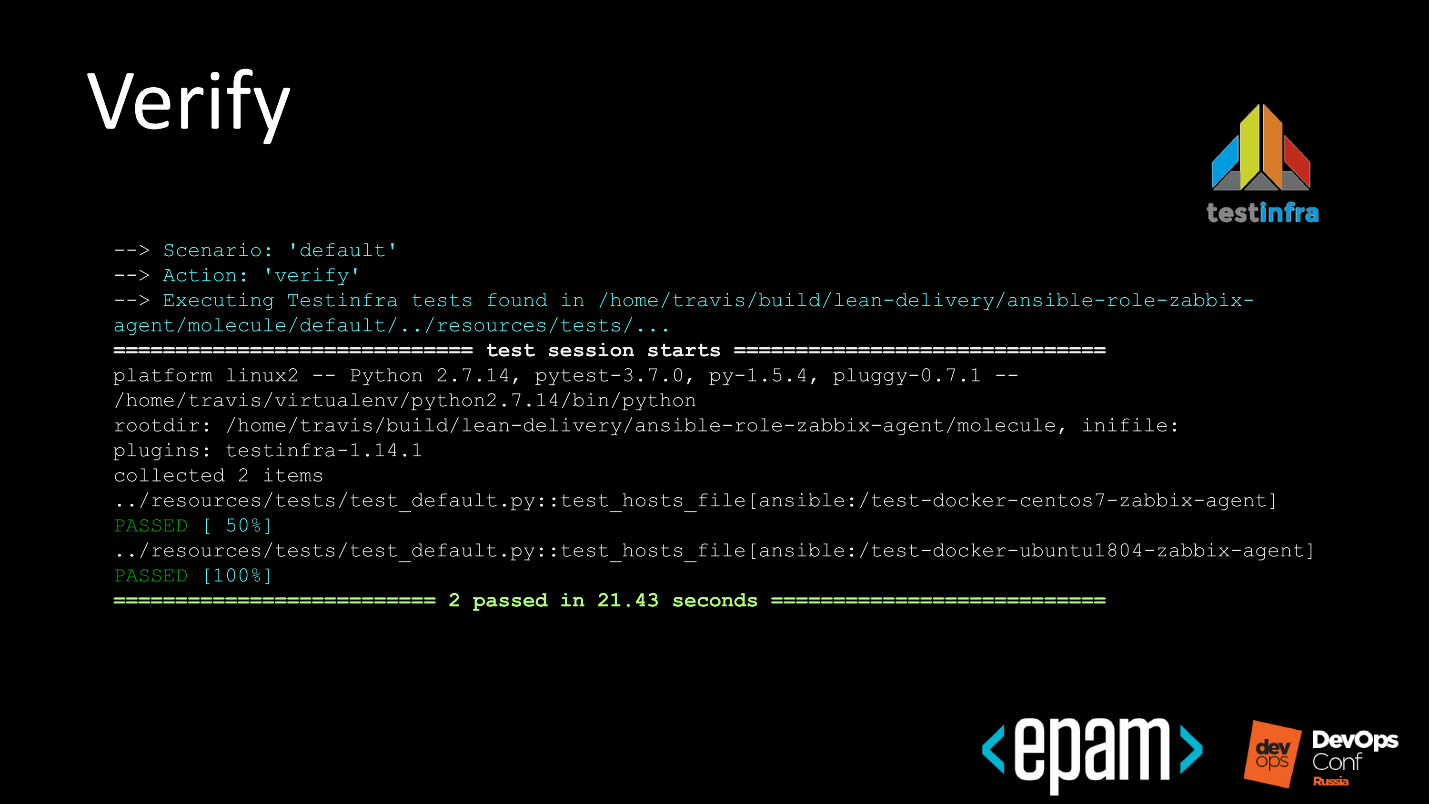
When functional tests run, it looks like it is beautiful, it is run up and down throughout the inventory, and the system informs us that everything is fine with us. Again, tests will run if we write them.
№ 11. Destroy
We conducted tests, a test report in some form is there and now we clean up all the garbage behind us.
Automation
Molecule is a great tool. Now the simplest thing is to connect a continuous integration system to it in order to enjoy automatic testing of our roles, which we did.

As elsewhere, there are several features.
Some of the roles that we write to automate something are good, but we cannot test the system with Travis, because the roles deploy products that we cannot share for general licensing reasons.
For example, you have automation of deployment of the Oracle base. If you put the database installer in a file, then company lawyers will come to you and will swear hard. In order for everyone to live in peace and not swear, we decided to do the following.
In fact, the role lies publicly, the data too, and we are not deceiving anyone - we are running real tests with real tools.
Let's take a step-by-step look at how this looks in Travis.
Travis

Steps:
Public CI
Public CI looks elementary.
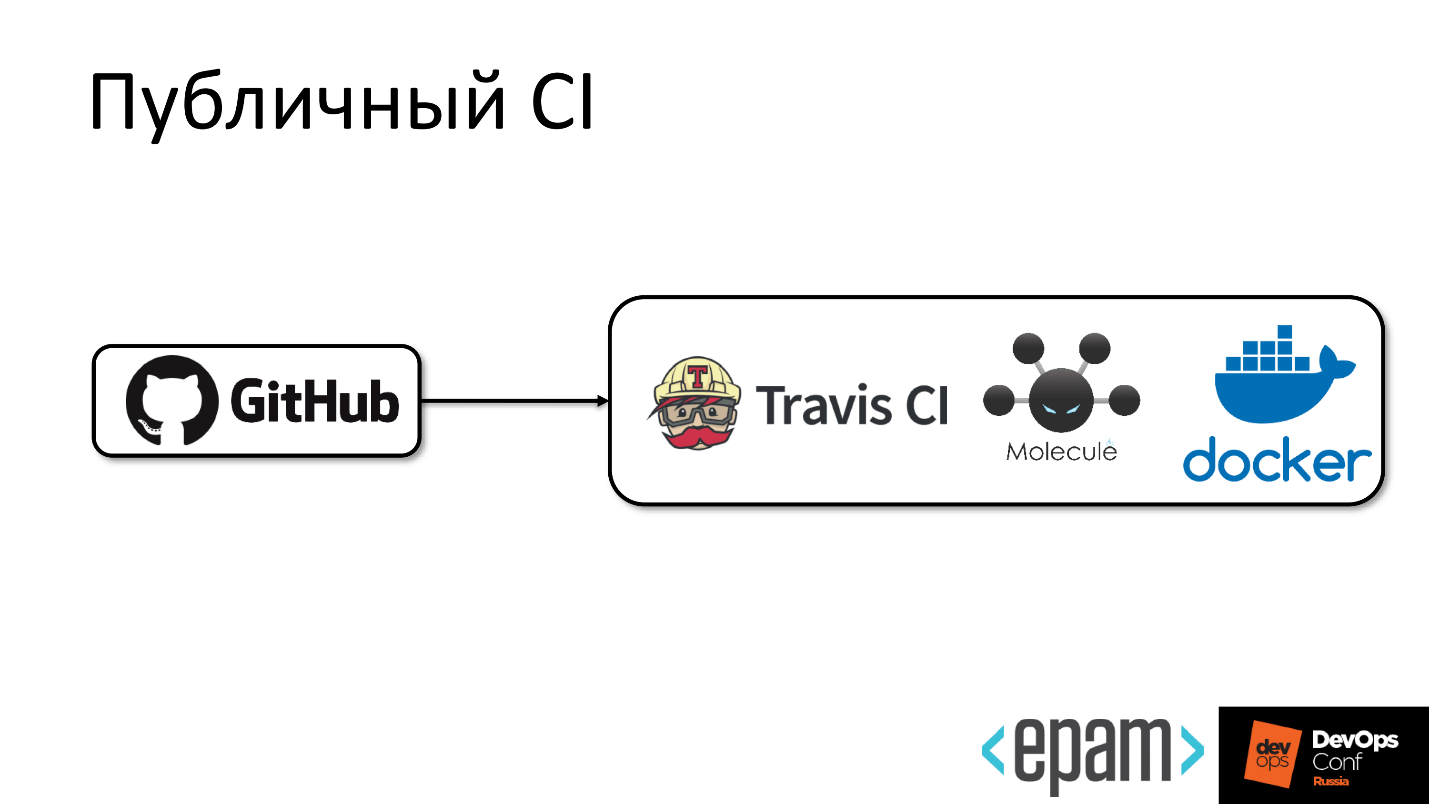
From GitHub is an arrow to Travis, inside of which Molecule and Docker live.
Private CI
For the private part of GitLab, everything is the same.

In the private perimeter, we have a runner running, and the picture looks more fun.
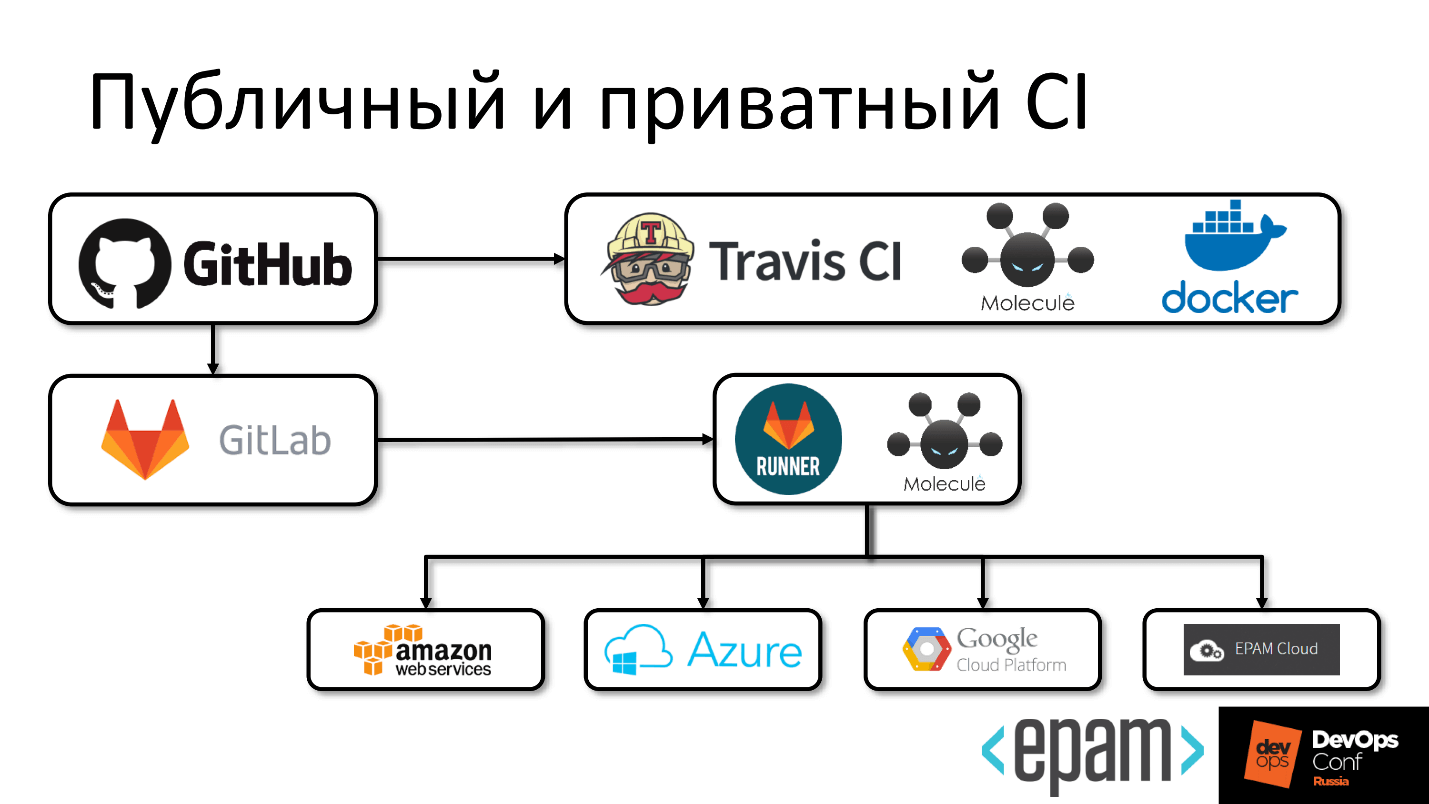
The code gets from GitHub to GitLab, somewhere a private runner is running that can pull external services, for example, run something on Amazon.
A small retreat. Running and deploying a test environment in Amazon doesn't want to be transferred, because keys are needed. To invent mechanisms to put them in public, but at the same time not to become another startup platform for mining is not a trivial task. Therefore, we did not solve it, but took the runner to private, so as not to mine the Amazon bitcoins.
Even here, we were a bit lazy and did the following. We have our own private cloud in EPAM and it is hybrid. This means that many public clouds are accessible from an internal cloud, as are regions. You can not write a thousand tests, but play around with the regions and say: “Now, conduct a test using this test scenario for the AWS, EPAM Cloud, Azure region”.
Ansible galaxy
We reached the final, our role is green, beautiful, we will publish it in the Galaxy.
This is a simple operation:
There is one feature - if you do not mark a role, do not tag, do not assign a version to it, then in Galaxy it will always be without a version. As soon as another developer wants to install it for himself through Ansible Galaxy install, he will take away the role that lies in the master branch, or in another branch by default. By default the branch is not always stable, which is inconvenient.
Templates
I share a little trick: in order not to copy-paste each time when writing a new role, we decided to create templates and a separate repository in which we put the template in order to quickly write roles from scratch.
The template has default settings for Ansible lint and GitHub issue_template. Everything is freely available, so the issue_template is in a nice form so that we can also make a pull request or bug reports nicely. In the same repository we add templates for Gitignore, Gitlab-ci and license.

By default, we publish under the Apache 2.0 license. If you want to visit us and reuse the templates, you can take everything, create a closed repository and not explain anything to anyone. Thanks Apache.
We have several options for tests, so that you can quickly kick everything and start.
Total
There will be no conclusion, instead there are links to my GitHub , my Galaxy profile , GitHub Lean Delivery and Ansible Galaxy . On the links you can see how everything works. All examples are freely available.
Ansible is not a magic pill , and helps only at first. As the project grows, it becomes difficult to maintain an expanded number of roles. Helps solve the problem of the mechanism of continuous delivery for roles.
Just about this transcript of Alexander Kharkevich’s report at DevOps Conf Russia. In the report: development of Ansible-roles through CI, a mechanism for developing public roles and public roles with test runs in a private infrastructure. And there is no conclusion in the report.
About Speaker : Alexander Kharkevich ( kharkevich ) Senior Systems Engineer at EPAM Systems .
Let's start with a brief overview.
About Ansible
Ansible is a configuration management system. It is written in Python, Junja is template, and YAML is used as a DSL. Managed via Ansible Tower - WebUI for managing and monitoring system performance.
Ansible appeared in 2012, after 3 years, Red Hat bought the whole project, and two years later introduced AWX - Project Open Source-version of Ansible Tower.
Installation
To use Ansible, you need to do two simple things.
In the first stage, compile an inventory file in the case of a static infrastructure.
On the second - write a Playbook, which will lead the system in the expected state.
Often we have an overwhelming desire to write automation that can be reused. Automation is a good desire, and the guys from Ansible came up with a cool concept - a role.
Role
This is a structured entity that will bring the system into an expected state with the ability to reuse automation.
For example, we can write a role for Oracle Java: take a Playbook, put the role and apply it to the target system. At the exit, we get the installed Java.
How we presented work with roles
Since Ansible has such a wonderful thing as a role, we thought that now we would take and write many, many roles for all occasions, fumble, and we will reuse to reduce the amount of work.
We thought that we would write beautiful and clever roles ...
But life turned out to be more difficult.
As it turned out in reality
When more than one person works on writing a role or its improvement, everyone writes in one place and there are unpleasant surprises: the role does not behave in the way that was originally intended by the author.
Well, when it is applied to the end, but it does not always happen. Sometimes the role is successfully executed, but this affects the target system quite differently from the way it was originally intended.
As a result, terrible constructions arise, attempts to transfer bash to Ansible and serve it all under the sauce configuration management. We are faced with this phenomenon and sad.
Thinking, we discovered that in our configuration management there is some kind of code, which means that the practices that are applicable to code management in Systems Development Life Cycle, are applicable in Ansible.
- Collect the best practices.
- Apply static analysis, lints.
- To test
- Zarelit, start in Release management.
We decided to implement the practice at our place and immediately went to look for suitable tools.
Instruments
From the point of view of version control systems and continuous integration, there are a dozen solutions available, and a spreading zoo for testing.
From the point of view of release management in Ansible, there are not so many solutions: tagging in Git, or tagging in Git and uploading to Galaxy.
According to the testing tools, there are many approaches, everyone uses what they like. Popular solutions using KitchenCI, InSpec, Serverspec.
Our soul did not lie to take Ansible written in Python, and add tools from the world of Ruby to it. Therefore, having thrown out all non-native to the world of Python, we received the following picture.
We use:
- For configuration management, GitHub and GitLab. GitLab is looking right at the same time on GitHub. Why did so, I will tell later.
- For CI, we took Travis for the public part and GitLab Runner for the private part.
- We test Molecule.
- Release in GitHub and add to Ansible Galaxy.
Our development cycle with these tools began to look more fun.
Molecule
This tool helps to fully test the ansible-role. For this, he has everything:
- Integration with YAML lint and Ansible lint for checking roles for compliance with our requirements.
- Test infrastructure for a functional test run.
- Molecule drivers is where Molecule rolls out our test bench. Everything is supported: Azure, Delegated, Docker, EC2, GCE, LXC, LXD, Openstack, Vagrant.
- There is also a useful and simple thing - delegation. This means that Molecule is not responsible for deploying the test bench and the developer must write a Playbook to raise the test bench. If you have a superprivate cloud, then delegate the creation and deletion of test machines, and Molecule itself will add everything inside.
Test matrix
Consider the test matrix in steps. Total steps 11, but I will be brief.
№ 1. Lint
Run YAML lint and Ansible lint, and find something.
In the example above, lint swears that the shell should not just be called in Ansible, but fixed, binding to something.
No. 2. Destroy
Molecule gets rid of everything that remains after previous tests.
There are cases when a run has passed, a test range has developed and testing has ended. The stand should be cleaned at the end, but insuperable forces interfered and there was no cleaning. For such situations, Molecule banishes destroy and cleans the environment from residues.
№ 3. Dependency
Take the requirements.yml file and add our role dependencies to other roles. For example, referring to the fact that the role does not take off without Java installed on the system:
---
- src: lean_delivery.java
version: 1.4
Molecule understands this and executes the script:
- coming down to galaxy or git;
- figure out what you need to solve dependencies;
- coming off the Galaxy again;
- downloads;
- will expand.
№ 4. Syntax
The next step is syntax checking. but not your role, but the test Playbook that you add to Molecule. At this step, there are also errors associated with the syntax.
The slide shows that the ansible role is called 'kibana', and in the test Playbook, the ansible-role-kibana is called. The system says: “Everything would be fine and you can create here, but I will not do that, because the names do not match!”
№ 5. Create
At this stage, we indicate the driver with which the test polygon is developed. You specify Google - it will lift test machines in Google Cloud.
We can write in the molecule.yml file what we want. Let's see how it looks on the example for Docker.
- I specify the docker images to be pulled up.
- I specify how to group them in order to form an inventory file.
I want to have two docker-images: one for RHEL-like, the second for Debian-like, to be sure that during the test run everything will be fine with both RHEL and Debian.
№ 6. Prepare
This is a pre-test preparation runtime step.
It seems to be all up, but sometimes you need to perform some additional settings. In the case of testing inside a raised Docker in Debian or Ubuntu, you need to install a second Python, which often happens.
№ 7. Converge
The stage of the first big run of the role to the Instance, to make sure that it reaches the end, is run out, and Ansible confirms that all is well.
- Molecule refers to Ansible.
- Ansible deploit to the test site.
- Runs through.
- It's okay!
№ 8. Idempotence
The idempotency test is simple and looks like this.
- The first time the role runs through the previous step.
- Ansible reports how many changes there were.
- Re-launches the same role.
- It checks that the system was brought to the expected state, but there are no changes during the second rental.
As a result, we understand that our role does not act destructively.
This stage caused pain to the guys I work with. They tried to work in ways to defeat idempotency testing. At Molecule, you can control the stages that it passes, and the first thing they did was turn off the idempotency test.
We caught trips and beat for it hands, but the engineers are smart and went deeper. The developers decided to say that this step in Ansible does not change anything.
Although in fact there will be some kind of team. Ansible directly takes and
will overwrite the file, but at the same time everything looks idempotent.
When this trick was also caught, the picture began to look like this.
Well - the script ran under the name default, and it is idempotent.
No. 9. Side_effect
In the next step, side effects are superimposed. It is not necessary to do this, but it is convenient when you test complex spreading roles that are dependent on each other.
For example, lift the ELK stack, then Elasticsearch in a cluster. At the side_effect stage, add test data and delete a couple of nodes from the cluster. The test site is ready for functional tests that occur in the next step.
№ 10. Verify
We are testing the infrastructure.
The above is an example of a very simple test. We check that we have the Docker Community Edition package in case of Ubuntu installed, it has the correct version, and the service is running.
At this stage, the launch of functional tests can all greatly complicate.
Probably the best example would be, in the case of the ELK stack, if we make a request to Elasticsearch on some test data, and since we know the test data, it will respond to us. We will not check that all installed components are assembled, but we will see that Elasticsearch is up, running and displaying exactly what is needed in the search.
When functional tests run, it looks like it is beautiful, it is run up and down throughout the inventory, and the system informs us that everything is fine with us. Again, tests will run if we write them.
№ 11. Destroy
We conducted tests, a test report in some form is there and now we clean up all the garbage behind us.
Automation
Molecule is a great tool. Now the simplest thing is to connect a continuous integration system to it in order to enjoy automatic testing of our roles, which we did.
As elsewhere, there are several features.
Some of the roles that we write to automate something are good, but we cannot test the system with Travis, because the roles deploy products that we cannot share for general licensing reasons.
For example, you have automation of deployment of the Oracle base. If you put the database installer in a file, then company lawyers will come to you and will swear hard. In order for everyone to live in peace and not swear, we decided to do the following.
- GitLab, in one of the latest releases, learned how to make CI for third-party repositories.
- The role lies in the public GitHub, the same public GitLab.com is connected to it, in which we indicated: “Dear GitLab, collect us the CI for the external repository”.
- Private runners are screwed to GitLab, in a closed perimeter, and they already have access to the binary, which they can deploy.
In fact, the role lies publicly, the data too, and we are not deceiving anyone - we are running real tests with real tools.
Let's take a step-by-step look at how this looks in Travis.
Travis
Steps:
- In the first step, the 8th line, we inform Travis that we do not just want to run it, but also use the Docker service so that the Docker is available inside Travis.
- Next, the 10th line, we take away our lint rules. We not only use the default Ansible lint rules, but also write our own.
- On line 15, we first call lint to save time running the test matrix. If something is not written according to the rules, and lint does not find it, then go to the beginning and leave a report. A developer who commits, repairs his commit or discards changes. When he fixes, let him come, and we will continue the test further.
Public CI
Public CI looks elementary.
From GitHub is an arrow to Travis, inside of which Molecule and Docker live.
Private CI
For the private part of GitLab, everything is the same.
In the private perimeter, we have a runner running, and the picture looks more fun.
The code gets from GitHub to GitLab, somewhere a private runner is running that can pull external services, for example, run something on Amazon.
A small retreat. Running and deploying a test environment in Amazon doesn't want to be transferred, because keys are needed. To invent mechanisms to put them in public, but at the same time not to become another startup platform for mining is not a trivial task. Therefore, we did not solve it, but took the runner to private, so as not to mine the Amazon bitcoins.
Even here, we were a bit lazy and did the following. We have our own private cloud in EPAM and it is hybrid. This means that many public clouds are accessible from an internal cloud, as are regions. You can not write a thousand tests, but play around with the regions and say: “Now, conduct a test using this test scenario for the AWS, EPAM Cloud, Azure region”.
Ansible galaxy
We reached the final, our role is green, beautiful, we will publish it in the Galaxy.
This is a simple operation:
- Call webhook, which is in Travis.
- At the same time, Travis is triggered, CI will run again.
- Call webhook.
- The new version will successfully grow in the Galaxy.
There is one feature - if you do not mark a role, do not tag, do not assign a version to it, then in Galaxy it will always be without a version. As soon as another developer wants to install it for himself through Ansible Galaxy install, he will take away the role that lies in the master branch, or in another branch by default. By default the branch is not always stable, which is inconvenient.
If you publish something in Galaxy, do not forget to tag it, so that there are versions, and everything is cool.
Templates
I share a little trick: in order not to copy-paste each time when writing a new role, we decided to create templates and a separate repository in which we put the template in order to quickly write roles from scratch.
The template has default settings for Ansible lint and GitHub issue_template. Everything is freely available, so the issue_template is in a nice form so that we can also make a pull request or bug reports nicely. In the same repository we add templates for Gitignore, Gitlab-ci and license.
By default, we publish under the Apache 2.0 license. If you want to visit us and reuse the templates, you can take everything, create a closed repository and not explain anything to anyone. Thanks Apache.
We have several options for tests, so that you can quickly kick everything and start.
Total
There will be no conclusion, instead there are links to my GitHub , my Galaxy profile , GitHub Lean Delivery and Ansible Galaxy . On the links you can see how everything works. All examples are freely available.
The next DevOps conference will be held in May.
While we are waiting for the event, subscribe to the YouTube channel and newsletter . The channel will be updated with the records of the best reports, and in the newsletter there will be collections of useful materials, decryption and DevOps news.
Subscribe, it will be interesting :)