About named pipe performance in multiprocess applications
 In the article about the features of the new version of Visual Studio, one of the main innovations (from my point of view) turned out to be the separation of the previously monolithic process of the development environment (devenv.exe) into components that will work in separate processes. This has already been done for the version control system (moving from libgit to git.exe) and some plugins, and in the future, other parts of VS will be submitted to subprocesses. In this regard, the question arose in the comments: “But will it slow down the work, because the exchange of data between processes requires the use of IPC ( Inter Process Communications )?”
In the article about the features of the new version of Visual Studio, one of the main innovations (from my point of view) turned out to be the separation of the previously monolithic process of the development environment (devenv.exe) into components that will work in separate processes. This has already been done for the version control system (moving from libgit to git.exe) and some plugins, and in the future, other parts of VS will be submitted to subprocesses. In this regard, the question arose in the comments: “But will it slow down the work, because the exchange of data between processes requires the use of IPC ( Inter Process Communications )?” No, it will not. And that's why.
Speed
There are various technologies for organizing communication between processes in Windows: sockets, named pipes, shared memory, messaging. Since I don’t want to write a full-fledged benchmark of all the above, let's quickly look for something similar to Habré and find an article 6 years ago in which adontz compared the performance of sockets and named pipes. Results: sockets - 160 megabytes per second, named pipes - 755 megabytes per second. At the same time, you need to make corrections for iron 6 years ago and the .NET platform used for tests. Those. we can safely say that on modern hardware with a code, for example, in C, we get a few gigabytes per second. In this case, as promptedWikipedia, for example, the speed of DDR3 memory, for example, varies from 6400 to 19200 MB / s depending on the frequency - and these are ideal MB / s in vacuum, in practice, there will always be less.
Conclusion 1 : the speed of the pipes is only several times less than the maximum possible speed of RAM. Not a thousand times smaller, not by orders of magnitude, but only several times. Modern OSs do their job well.
Data volumes
Let's take the same 755 MB / s from the paragraph above, as the speed of named pipes. Is it a lot or a little? Well, if you, for example, wrote an application that would receive uncompressed FullHD video at a frame rate of 60 frames per second from a named channel and do something with it (encoded or streamed), then you would have had 355 MB / with. Those. even for such a very expensive operation, the speed of a named pipe would be enough with a margin of more than two times. What does Visual Studio operate in communicating with its components? Well, for example, the commands for git.exe and the data from his answer. These are a few kilobytes, in very rare cases - megabytes. Data exchange with plugins can hardly be accurately estimated (there are very different plugins). But in any case, not a single plugin that I saw requires hundreds of megabytes per second.
Conclusion 2 : taking into account the specifics of the data processed by Visual Studio (text, code, resources, pictures), the speed of named pipes is enough with multiple margins.
Latency
Well ok, you say, speed-speed, but there is also latency. After all, each operation will require some kind of overhead for synchronization. Yes, it will. And about this I recently published an article . People overestimate the overhead of locking and syncing. The trouble there is not in the locks themselves (they take nanoseconds), but in the fact that people write poor synchronous code, admit deadlocks, livelocks , races and damage to shared memory. Fortunately, in the case of named pipes, the API itself hints at the advantages of an asynchronous approach, and writing code that works correctly is not so difficult.
Conclusion 3 : while in the asynchronous / multi-threaded code there are no bugs - it works quite quickly, even with locks.
Practical example
Well, okay, you say, that's enough theory, you need practical proof! And we have it. This is one of the most popular desktop applications in the world - the Google Chrome browser. Created initially in the form of several interacting processes, Chrome immediately showed the advantages of this approach - one tab stopped hanging the rest, the death of the plug-in did not mean more browser crashes, the load in rendering content in one window no longer guaranteed brakes in another, etc. Chrome, if simplified, launches one main process, separate processes for rendering tabs, interacting with the GPU, plug-ins (in fact, the rules are a little trickier there, Chrome can optimize the number of child processes depending on different circumstances, but this is not very important now).
You can read about the architecture of Chrome in theirdocumentation , but here’s a simplified picture:
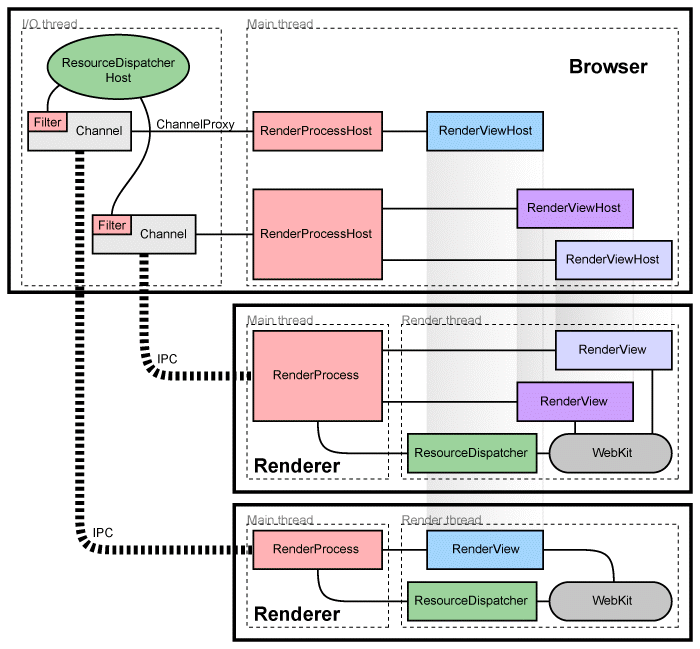
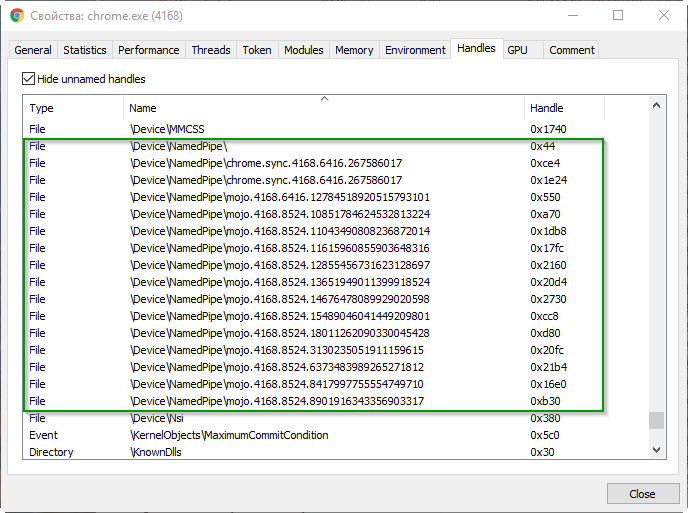
What is hidden in this picture under the line with the zebra and IPC inscription? But just named pipes are hiding. They can be seen, for example, using the Process Hacker application (Handles tab):
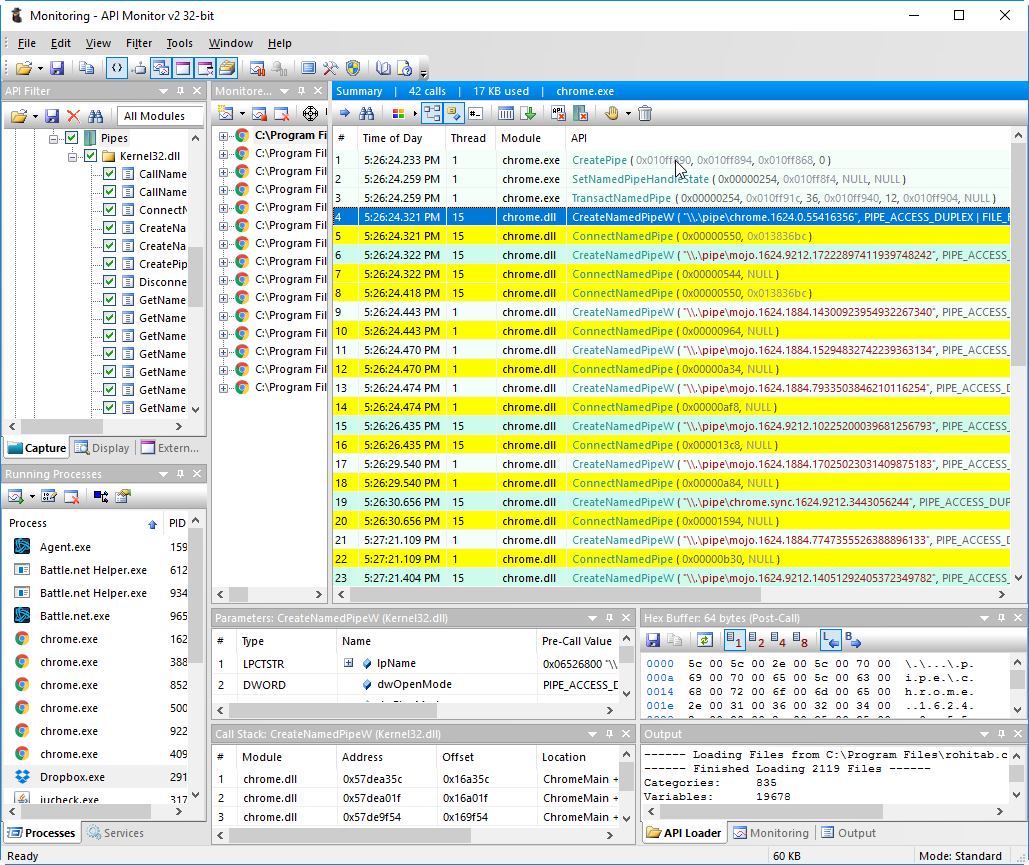
Well, or using Api Monitor :
How much named pipes slow down Chrome? You yourself know the answer to this question: not at all. Multiprocess architecture accelerates the browser, allowing you to better distribute the load between the cores, better control the performance of processes, more efficient use of memory. For example, let's estimate how much data Chrome drives through its named pipes when playing one minute of a video from Youtube. To do this, you can use the good IO Ninja utility (normally the data stream by pipe, to their shame, does not show either Wireshark, API Monitor, or Sysinternals utilities - a shame!):
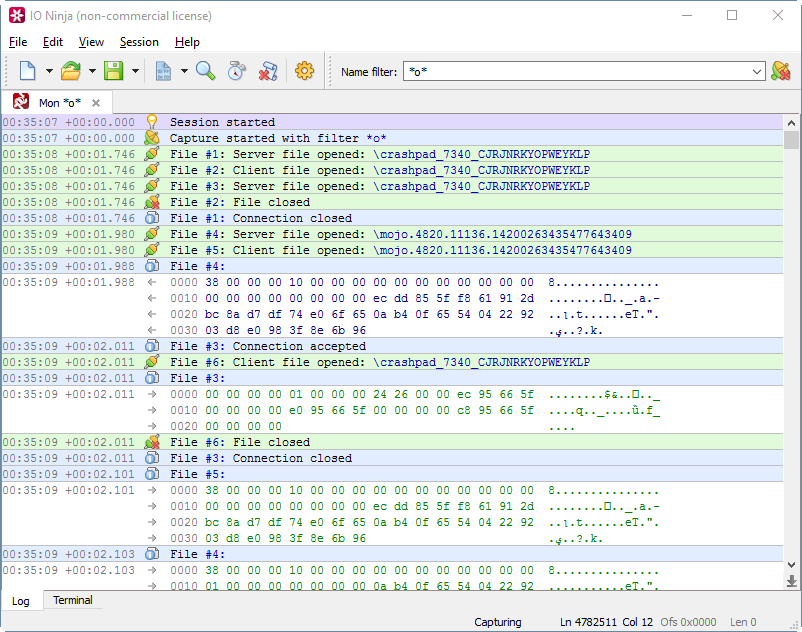
Measurement showed that in 1 minute of playing Youtube-video Chrome transfers 76 MB of data through named pipes. In this case, 79715 pieces occurred of separate read / write operations. As you can see, even such a serious program as Chrome, even on such a strong site as Youtube, did not confuse named channels. So Visual Studio has every chance to benefit from dividing the monolithic IDE into subprocesses.