Data migration in a bloody enterprise: what to analyze, so as not to overwhelm the project

A typical system integration project for us looks like this: the customer has a wagon system for customer accounting, the task is to assemble customer cards into a single database. And not only to collect, but also to clear from duplicates and garbage. To get a clean, structured, full customer cards.
For beginners I will explain that the migration proceeds according to the following scheme: sources → data conversion ( ETL or bus responds ) → receiver .
At one project, we lost three months simply because a third-party integrator team did not study the data in the source systems. The most annoying that this could have been avoided.
Worked like this:
- System integrators customize the ETL process.
- ETL converts the raw data and gives it to me.
- I am studying uploading and sending errors to integrators.
- The integrators fix the ETL and run the migration again.
The article will show how to analyze data with system integration. I studied the ETL uploads, it was very helpful. But on the source data the same techniques would speed up the work by a factor of two.
Tips will be useful to testers, enterprise-product implementers, system integrators, analysts. Receptions are universal for relational bases, and at full power they are revealed on volumes from a million customers.
But first, about one of the main myths of system integration.
Documentation and architect will help (actually not)
Integrators often do not study data before migration — they save time. Read the documentation, look at the structure, talk with the architect - and that's enough. After this, the integration is already planned.
It turns out badly. Only an analysis will show what is really going on in the database. If you do not get into the data with rolled up sleeves and a magnifying glass, the migration will go awry.
The documentation is lying. A typical enterprise system has been operating for 5–20 years. Over the years, changes in it have been documented by various departments and contractors. Each with its own bell tower. Therefore, there is no integrity in the documentation; nobody fully understands the logic and structure of data storage. Not to mention that the terms are always burning and there is not enough time for documentation.
The usual story: in the customer table there is a field "SNILS", on paper is very important. But when I look at the data, I see that the field is empty. As a result, the customer agrees that the target database will do without a field for SNILS, since there is still no data.
A special case of documentation is regulations and descriptions of business processes: how data gets into the database, under what circumstances, in what format. All this does not help either.
Business processes are flawless only on paper. Early in the morning, a nevyshvatsya operator Anatoly enters the bank's office in the outskirts of Vyksa. Under the window all night shouted, and in the morning Anatoly quarreled with the girl. He hates the whole world.
Nerves have not yet come in order, and Anatoly completely drives in the name of the new client in the field for the surname. He completely forgets about his birthday - the default "01/01/1900 g" remains in the form. Do not care about the regulations, when everything around is so annoying !!!
Chaos defeats business processes, very slim on paper.
The system architect does not know everything. The point is again in the honorable life of enterprise-systems. Over the years that they work, architects change. Even if you talk with the current one, the decisions of the previous ones will come up as surprises during the project.
And be sure: even a pleasant architect in all respects will keep his facies and crutches of the system secret.
Integration "by instrument", without data analysis - an error. I'll show you how we study data in HFLabs with system integration. In the last project, I analyzed only the uploads from ETL. But when the customer gives access to the source data, I check them by the same principles.
Field padding and null values
The simplest checks are for completeness of the tables as a whole and for completeness of individual fields. I start with them.
How many total rows in the table. The simplest query possible.
selectcount(*) from <table>;I get the first result.
| Individuals | amount |
|---|---|
| Total | 99 966 324 |
How many lines are filled for each field separately. I check all the columns in the table.
select <column_name>, count(*) as <column_name> cnt from <table>
where <column_name> is notnull;The first came across the field on his birthday, and he was immediately curious: for some reason, the data did not come at all.
| Individuals | amount |
|---|---|
| Total | 99 966 324 |
| DR | 0 |
I see that the source system birthdays in place. I go to integrators: guys, an error. It turned out that in the ETL process the decode function worked incorrectly. The code is corrected, in the next unload we check the changes.
I go further to the field with the TIN.
| Individuals | amount |
|---|---|
| Total | 99 966 324 |
| DR | 0 |
| TIN | 65,136 |
I check the source system, that's right: the INNs are similar to the actual ones, but there are almost none. So it's not about migration. It remains to find out whether the customer in the target database needs an almost empty field under the TIN.
Got to the client removal flag.
| Individuals | amount |
|---|---|
| Total | 99 966 324 |
| DR | 0 |
| TIN | 65,136 |
| Delete flag | 0 |
In the target system, the remote client flag is obligatory, this is a feature of the architecture. So, if the client has zero accounts in the receiving system, it must be closed through additional logic or not imported at all. Here as the customer decides.
Next - a sign with addresses. Usually in such tables something is wrong, because the addresses are complex, they are entered differently.
I check the completeness of the components of the address.
| Addresses | amount |
|---|---|
| Total | 254 803 976 |
| A country | 229,256,090 |
| Index | 46,834,777 |
| City | 6,474,841 |
| The outside | 894 040 |
| House | 20,903 |
As a result, the customer saw that ETL took the addresses from the old and irrelevant plate. It is in the base as a monument. And there is another table, new and good, the data must be taken from it.
During the analysis of occupancy, I alone put the fields that refer to reference books. The "IS NOT NULL" condition does not work with them: instead of "NULL" in the cell, it is usually "0". Therefore, reference fields are checked separately.
Changes in the field.So, I checked the total occupancy and occupancy of each field. Found problems, integrators fixed the ETL process and restarted the migration.
The second unload is driven through all the steps listed above. I record statistics in the same file to see the changes.
Fullness of all fields.
| Individuals | Unloading 1 | Unload 2 | Delta |
|---|---|---|---|
| Total | 99 966 324 | 94 847 160 | -5 119 164 |
- “Why are the records lost?”;
- “What data was screened out?”;
- “What data is left?”
It turns out that there is no problem: the “technical” clients were simply removed from the fresh download. They are in the database for tests, they are not living people. But with the same probability the data could disappear by mistake, it happens.
But the birthdays in the new unloading appeared, as I expected.
| Individuals | Unloading 1 | Unload 2 | Delta |
|---|---|---|---|
| Total | 99 966 324 | 94 847 160 | -5 119 164 |
| DR | 0 | 77,046,780 | 77,046,780 |
What to check in a nutshell.
- The total number of entries in the tables. Is this amount adequate to the expectations?
- The number of filled lines in each field.
- The ratio of the number of rows filled in each field to the number of rows in the table. If it is too small, it is a reason to think whether it is necessary to drag the field to the target base.
Repeat the first three steps for each upload. Follow the dynamics: where and why increased or decreased.
The length of the values in the string fields
I follow one of the basic rules of testing - I check the boundary values.
What values are too short. Among the shortest values is full of garbage, so it is interesting to dig.
select * from <table> wherelength (<column_name>) < 3;In this way I check the name, phone numbers, TIN, OKVED, site addresses. Nonsense like "A * 1", "0", "11", "-" and "..." emerge.
Is everything OK with maximum values? The end-to-end field is a marker that the data did not fit during the transfer, and they were cut off automatically. MySQL breaks off this famously and without warning. It seems that the migration went smoothly.
select * from <table_name> wherelength(<column_name>) = 65;In this way, I found in the field with the document type the string "Certificate of registration of an immigrant's application for recognition of his." I told the integrators, the length of the field corrected.
How values are distributed in length. In HFLabs, the table of the distribution of rows in length we call the "frequency".
selectlength(<column_name>), count(<column_name>) from <table> groupby length(<column_name>);Here I look for anomalies in the distribution of length. For example, here is a frequency for a table with postal addresses.
| Length | amount |
|---|---|
| 122 | 120 |
| 123 | 90 |
| 124 | 130 |
| 125 | 1100 |
| 126 | 70 |
What to check in a nutshell.
- The shortest values in string fields. Often strings with less than three characters are garbage.
- Values that "abut" along the width of the field. Often they are circumcised.
- Anomalies in the distribution of rows in length.
Popular Values
I divide into three categories the values that fall in the top popular:
- really common , as the name "Tatiana" or middle name "Vladimirovich." Here it must be remembered that, in general, “Tatyana” should not be 100 times more popular than “Anna”, and “Ismail” can hardly be more popular than “Yegor”;
- garbage , like ".", "1", "-" and the like;
- default on the input form, as "01/01/1900" for dates.
Two cases out of three are problem markers, it is useful to look for them.
Popular values I look for in the fields of three types:
- Normal string fields.
- String field references. These are ordinary string fields, but the number of different values in them is of course regulated. In such fields store countries, cities, months, phone types.
- Classifier fields - they contain a link to an entry in a third-party classifier table.
Fields of each of these types I study a little differently.
For string fields, what are the top 100 popular values. If you want, you can take a little more, but all anomalies are usually placed in the first hundred values.
select * from (select <column_name>, count(*) cnt from <table> groupby <column_name>
orderby 2 desc) whererownum <= 100;I check the fields this way:
- Full name, as well as separate surnames, names and patronymic names;
- dates of birth and generally any dates;
- addresses Both the full address and its individual components, if they are stored in the database;
- telephones;
- series, number, type, place of issue of documents.
Almost always among the popular ones are test and default values, some kind of stubs.

It happens that the problem found is not a problem at all. Once I found a suspiciously popular phone number in the database. It turned out that customers indicated this number as a worker, and in the database there were simply many employees of the same organization.
Along the way, such an analysis will reveal hidden reference fields. According to logic, these fields are not supposed to be reference books, but in fact in the database they are. For example, I choose popular values from the “Position” field, and there are only five of them.
| Position |
|---|
| Director |
| Accountant |
| Specialist |
| Secretary |
| System Administrator |
For reference fields and classifiers, I check how popular all values are. For a start I understand which fields are reference books. Scripts can not do here, take the documentation and estimate. Typically, reference books are created for values whose number is of course and relatively small:
- country,
- languages,
- currency,
- months
- cities.
In an ideal world, the content of reference fields is clear and uniform. But our world is not like this, so I check it with a query.
select <column_name>, count(*) cnt from <table> groupby <column_name> orderby 2 desc;Usually in string-field directories such lies.
| Place of Birth | amount |
|---|---|
| Tajikistan | 467,599 |
| Tajikistan | 410 484 |
| Russia | 292,585 |
| TAJIKISTAN | 234,465 |
| Russia | 158,163 |
| RUSSIA | 76 367 |
- typos;
- spaces;
- different case.
Finding a mess, go to the integrators with examples on hand. Let them leave the garbage in the source, and eliminate the misunderstandings. Then in the target base for rigor it will be possible to turn reference strings into classifiers.
I check the popular values in the classifier fields to catch the lack of options. Faced with such cases.
| Floor | Phone type |
|---|---|
|
|
What to check in a nutshell.
- Which string fields are reference and which ones are not.
- For simple string fields, top popular values. Usually in the top trash and default data.
- For string reference fields - the distribution of all values in popularity. The sample will show discrepancies in the reference values.
- For classifiers - whether there are enough options in the database.
Consistency and cross-checking
From analyzing the data inside the tables I turn to the analysis of relationships.
Whether the data is bound to be bound. We call this parameter “consistency”. I take a subordinate table, for example, with telephones. To her in a pair - the parent table of customers. And I see how many client IDs in the subordinate table that are not in the parent.
selectcount(*) from ((select <ID1> from <table1>) minus (select <ID2> from <table2>));If the request gave the delta, it means no luck - there is unrelated data in the upload. So I check tables with phones, contracts, addresses, bills and so on. Once during the project, I found 23 million numbers that were just hanging in the air.
In the opposite direction it also works - I am looking for clients who for some reason do not have a single contract, address, telephone number. Sometimes this is normal - well, there is no address from the client, that such. Here you need to find out from the customer, the documentation is easily deceived.
Are there duplicate primary keys in different tables? Sometimes identical entities are stored in different tables. For example, heterosexual clients. (Nobody knows why, because the structure was claimed by Brezhnev.) And in the receiver, the table is the same, and when migrating, customer IDs will conflict.
I turn my head on and look at the structure of the base: where it is possible to crush similar entities. These can be customer tables, contact numbers, passports, and so on.
If there are several tables with similar entities, I do a cross-check: I check the intersection of identifiers. Intersect - sticking patch. For example, we collect IDs for a single table using the “source table name + ID” scheme.
What to check in a nutshell.
- How many related tables unrelated data.
- Are there any potential primary key conflicts?
What else to check
Do not have Latin characters where they do not belong. For example, in surnames.
select <column_name> from <table> whereregexp_like(<column_name>, ’[A-Z]’, ’i’);So I catch a wonderful Latin letter "C", which coincides with the Cyrillic. The error is unpleasant, because by the name of the Latin "C" operator will never find a client.
Were there any extraneous characters in the string fields intended for numbers?
select <column_name> from <table> whereregexp_like(<column_name>, ‘[^0-9]’);Problems emerge in the fields with the passport number of the RF or TIN. Phones are the same, but there I allow plus, parentheses and hyphens. The request will also reveal the letter “O”, which is set instead of zero.
How data is adequate. You never know where the problem will come up, so I am always on my guard. Met such cases:
- 50 000 phones at the client "Sofia Vladimirovna" - is this normal? The answer is: not normal. The client is technical, he was hung up with "ownerless" phone numbers to make sms-mailings. Pull the client into the new database is not necessary;
- The TIN is filled, in fact in the column is "79853617764", "89109462345", "4956780966" and so on. What kind of phones, okay? Where is TIN? Answer: what kind of numbers - it is not known who put it - is unclear. No one uses them. The current TIN is stored in another field of another table, taken from there;
- the field “address in one line” does not correspond to the fields in which the address is stored in parts. Why are the addresses different? Answer: once the operators filled addresses in one line, and the external system parsed the addresses in separate fields. For segmentation. As time went on, people changed addresses. Operators regularly updated them, but only as a string: the address remains in parts old.
All you need is SQL and Excel
To analyze the data, expensive software is not needed. Enough good old Excel and knowledge of SQL.
I use Excel to build a long query. For example, I check the fields for fullness, and in the table they are 140. I will write with my hands before the carrot zagoveniya, therefore I collect the query with formulas in the excel-plate.
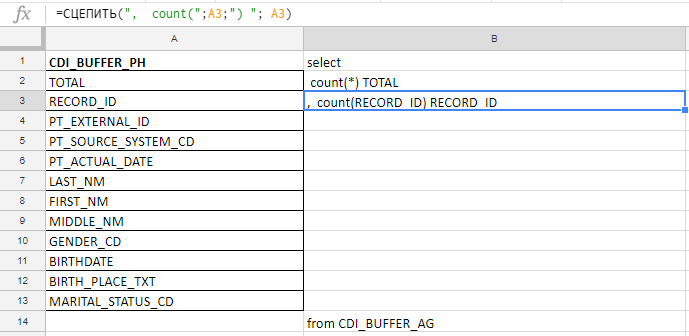
In the column "A" insert the field names, take them in the documentation or service tables. In the column “B” - the formula for gluing the request I
insert the names of the fields, write the first formula in the column “B”, pull the corner - and that's it.
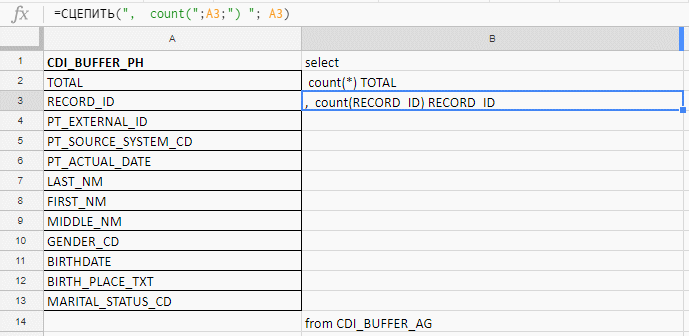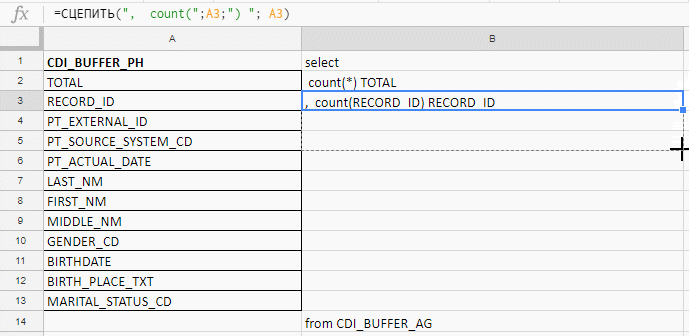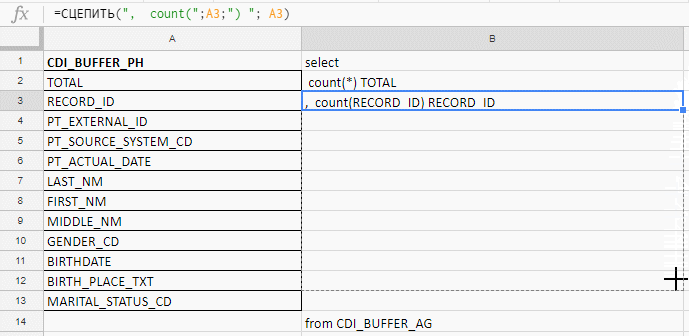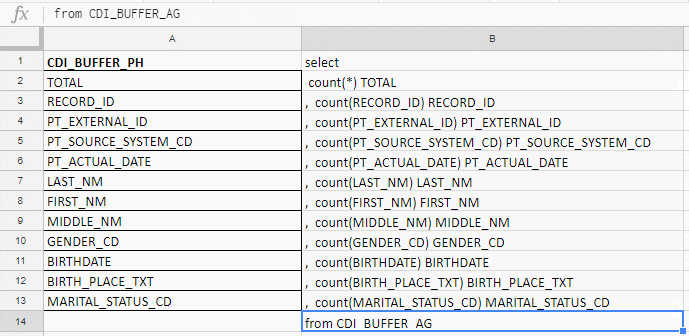
It works in Excel, Google Docs, and Excel Online (available on Yandex.Disk)
. Data analysis saves time wagons and saves the nerves of managers. It’s easier to meet the deadline. If the project is large, analytics will save millions of rubles and reputation.
Not numbers, but conclusions
She formulated a rule for herself: do not show bare numbers to the customer, you still cannot achieve the effect. My task is to analyze the data and draw conclusions, and attach the numbers as evidence. Conclusions are primary, numbers are secondary.
What I collect for the report:
- problem formulations in the form of a hypothesis or a question : “The TIN is 0.07% complete. How do you use this data, how relevant are they, how to interpret them? Is the INN just in one table? ” You can not blame: "Your TIN is not filled at all." In response, you will receive only aggression;
- examples of problems. These are the signs that so much in the article;
- Options for how to do it: “It may be worth removing the TIN from the target base so as not to produce empty fields.”
I do not have the right to decide what to take from the source database and how to change the data during the migration. Therefore, with the report I go to the customer or integrators, and we figure out how to proceed further.
Sometimes the customer, having seen the problem, replies: “Do not worry, do not pay attention. Let's buy an extra terabyte of memory, and that's all. It's cheaper than optimizing. ” You cannot agree to this: if you take everything in, there will be no quality in the receiver. Migrate all the same littered redundant data.
Therefore, we gently but steadily ask: "Tell us how you will use these data in the target system." Not "why are needed", namely "how will you use." Answers "we will think up then" or "it just in case" do not suit. Sooner or later, the customer understands what data you can do without.
The main thing - to find and resolve all issues, until the system is not launched in the prod. On live to change the architecture and data model - go crazy.
With basic analytics on it all, study the data!
HFLabs is looking for an analyst-trainee with a salary of 50 000 ₽. We will teach the right person everything I told in the article, and other tricks.
The vacancy is suitable for technicians who want to change their profile or have not yet decided which field to work in. If interested, send your responses to the jobs page on hh.ru .