The first video codec on machine learning radically surpassed all existing codecs, including H.265 and VP9
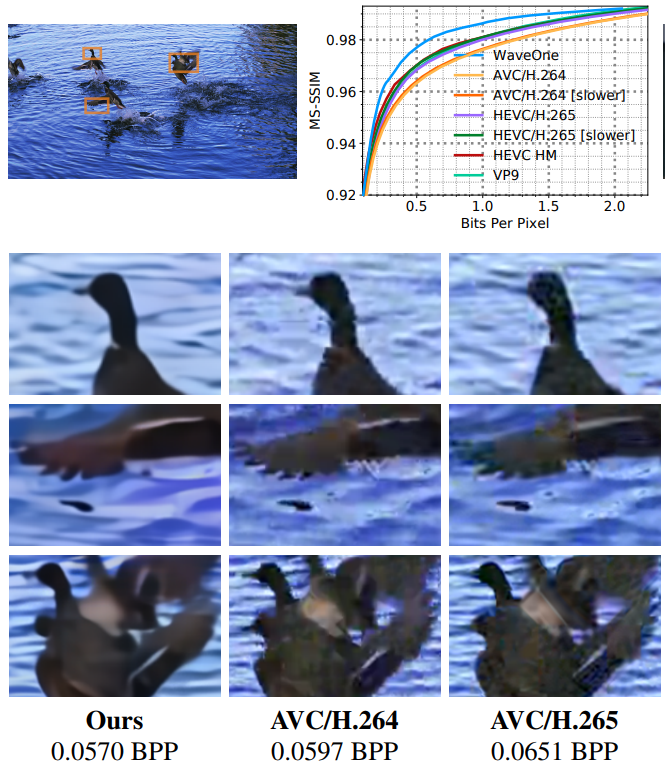
Examples of reconstruction of a fragment of video compressed by different codecs with approximately the same BPP value (bit per pixel). Comparative test results, see under the cat
Researchers from the company WaveOne claim that they are close to a revolution in the field of video compression. When processing high-resolution 1080p video, their new codec on machine learning compresses video by about 20% better than the most modern traditional video codecs, such as H.265 and VP9. And on the video "standard definition" (SD / VGA, 640 × 480) the difference reaches 60%.
The developers call the current methods of video compression, which are implemented in H.265 and VP9, “ancient” by the standards of modern technologies: “Over the past 20 years, the fundamentals of existing video compression algorithms have not changed significantly,” write the authors of the scientific paper in the introduction of their article. “Although they are very well designed and carefully tuned, they remain tightly programmed and, as such, cannot adapt to the growing demand and a more versatile range of video materials, including sharing in social media, object detection, streaming virtual reality broadcasting and so on.”
The use of machine learning should finally bring video compression technology into the 21st century. The new compression algorithm is far superior to existing video codecs. “As far as we know, this is the first machine learning method that showed such a result,” they say.
The basic idea of video compression is to remove the redundant data and replace it with a shorter description that allows you to play the video later. Most video compression occurs in two stages.
The first stage is compression of motion, when the codec searches for moving objects and tries to predict where they will be in the next frame. Then, instead of recording the pixels associated with this moving object, in each frame, the algorithm encodes only the shape of the object along with the direction of motion. Indeed, some algorithms look at future frames in order to determine motion even more accurately, although this obviously will not work for live broadcasts.
The second compression step removes other redundancies between one frame and the next. Thus, instead of recording the color of each pixel in a blue sky, the compression algorithm can determine the area of that color and indicate that it does not change over the next few frames. Therefore, these pixels remain the same color until they are told to change. This is called residual compression.
The new approach, which was presented by scientists, for the first time uses machine learning to improve both of these compression methods. So, while compressing motion, the machine learning methods of the team found new redundancies based on motion, which conventional codecs were never able to detect, much less use. For example, turning a person’s head from a frontal view to a profile always gives a similar result: “Traditional codecs will not be able to predict the profile of a face based on the frontal view,” write the authors of the scientific work. On the contrary, the new codec studies these types of space-time patterns and uses them to predict future frames.
Another problem is the allocation of available bandwidth between traffic and residual compression. In some scenes, the compression of movement is more important, while in others the residual compression provides the greatest gain. The best compromise between them is different from frame to frame.
Traditional algorithms process both processes separately. This means that there is no easy way to take advantage of one or the other and find a compromise.
The authors bypass this by compressing both signals simultaneously and, based on the complexity of the frame, determine how to distribute the bandwidth between the two signals in the most efficient way.
These and other improvements have allowed researchers to create a compression algorithm that far exceeds traditional codecs (see benchmarks below).

Examples reconstruction fragment compressed with different codecs approximately the same value BPP shows a marked advantage codec WaveOne
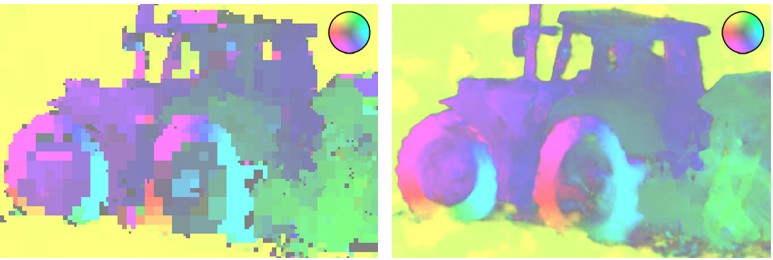
optic flow maps H.265 (left) and codec WaveOne (right) at the same bitrate
, however, a new approach is not without some drawbacks noted Edition MIT Technology Review. Perhaps the main disadvantage is low computational efficiency, that is, the time required for encoding and decoding video. On the Nvidia Tesla V100 platform and on the VGA-size video, the new decoder operates at an average speed of about 10 frames per second, and the encoder does at all at about 2 frames per second. Such speeds simply cannot be applied in live video broadcasts, and even when offline coding materials, the new encoder will have a very limited scope of use.
Moreover, decoder speed is not enough even for viewingvideo compressed by this codec on a regular personal computer. That is, to view these videos even in the minimum SD quality, at the moment, an entire computing cluster with several graphic accelerators is required. And to view the video in HD quality (1080p) you need a whole computer farm.
It remains to hope only in the future to increase the power of graphics processors and to improve the technology: “The current speed is not sufficient for deployment in real time, but it must be significantly improved in future work,” they write.
Benchmarks
All the leading HEVC / H.265, AVC / H.264, VP9 and HEVC HM 16.0 codecs in the reference implementation took part in the testing. For the first three, Ffmpeg was used, and for the latter, the official implementation. All codecs were as customized as possible by the knowledge of researchers. For example, H.264 / 5 with the option was used to remove the B-frames
bframes=0, a similar procedure was performed in the codec, -auto-alt-ref 0 -lag-in-frames 0and so on. To maximize performance against the MS-SSIM metric, of course, codecs were run with a flag -ssim.All codecs were tested on a standard base of videos in SD and HD formats, which are often used to evaluate video compression algorithms. For SD quality, a video library in VGA resolution from e Consumer Digital Video Library (CDVL) was used. It contains 34 videos with a total length of 15,650 frames. For HD, the Xiph 1080p dataset was used: 22 videos with a total length of 11,680 frames. All 1080p video clips were cropped in the center to a height of 1024 (in this approach, the researchers' neural network is capable of processing only measurements with dimensions that are multiples of 32 on each side).
Different test results are shown in the diagrams below:
- average MS-SSIM values for all videos in the set for each codec;
- comparing file sizes when averaging the MS-SSIM value for all codecs;
- the effect of various components of the WaveOne codec on the quality of compression (the lower diagram)
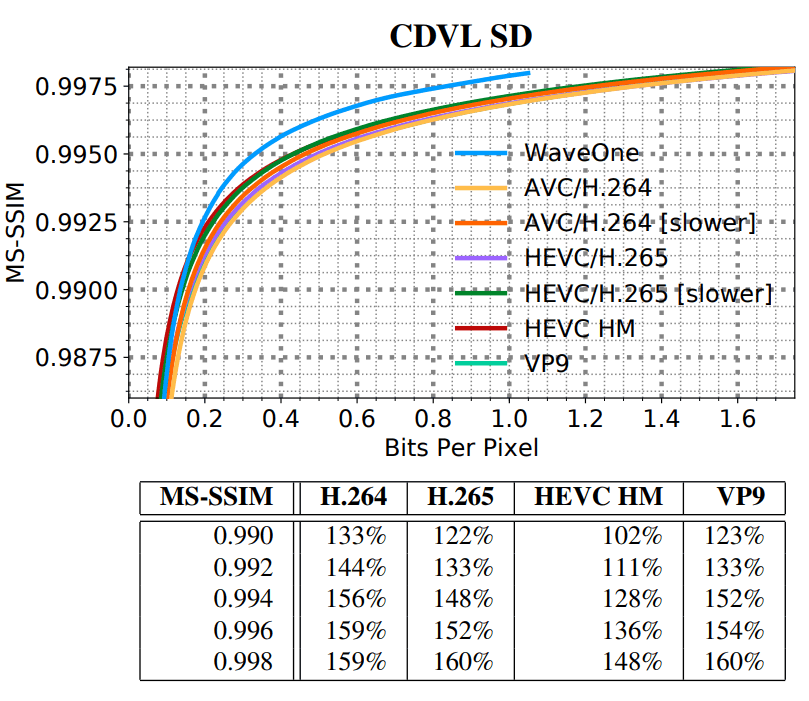
Test results on a set of low-resolution video clips (SD)
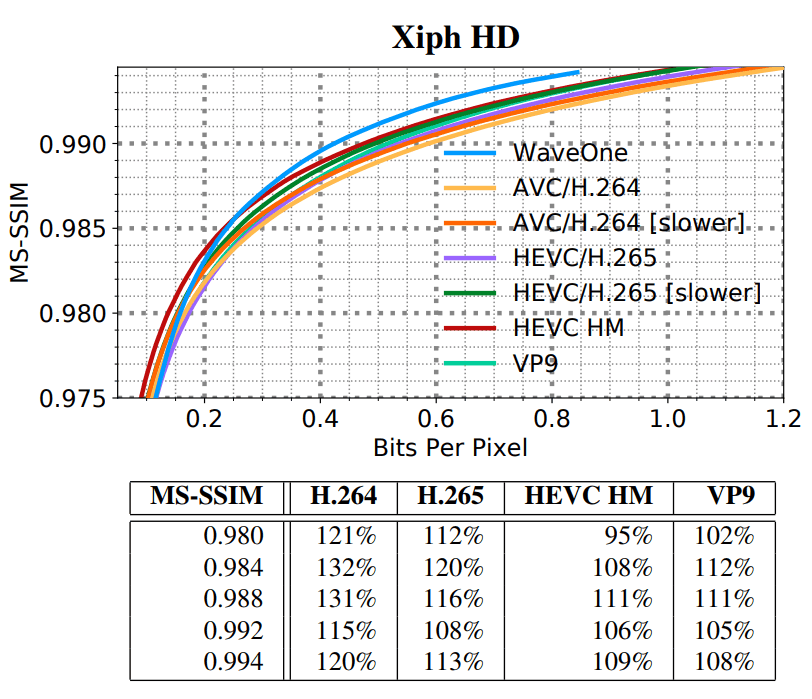
Test results on a set of high-resolution video clips (HD)
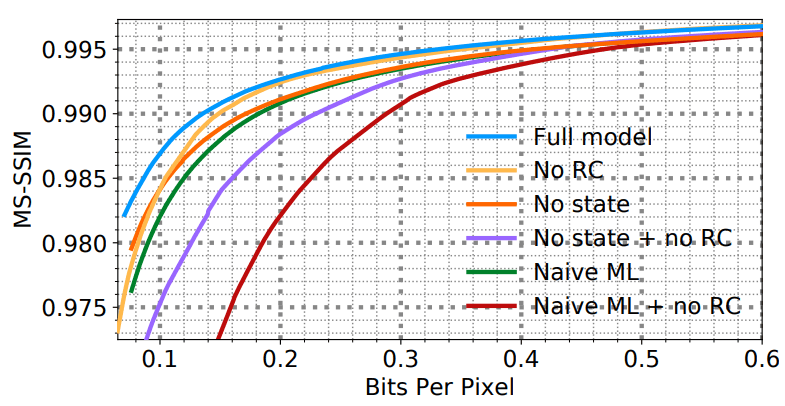
Effect of various components of the WaveOne codec on the quality of compression
You should not be surprised at such a high level of compression and cardinal superiority over traditional video codecs. This work is largely based on previous scientific articles, which describe various methods of compressing static images based on machine vision. All of them are far superior in terms of the level and quality of compression to traditional algorithms. For example, see G. Toderici, SM O'Malley, SJ Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar. Variable rate image compression with recurrent neural networks, 2015; G. Toderici, D. Vincent, N. Johnston, SJ Hwang, D. Minnen, J. Shor, M. Covell. Full resolution image compression with recurrent neural networks , 2016; J. Balle, V. Laparra, Simoncelli EP. End-to-end optimized image compression , 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, SJ Hwang, J. Shor, G. Toderici. Improved lossy image compression and adaptive bit rates for recurrent networks , 2017 and others. These papers show how trained neural networks reinvent many image compression techniques that were invented by humans and were previously manually written for use by traditional compression algorithms.
Progress in the field of ML-compression of static images inevitably led to the emergence of the first video codecs based on machine learning. With the increase in graphics accelerator performance, video codec implementation has become the first candidate. Until now, there was only one attempt to create a video codec on machine learning. It is described in C.-Y. Wu, N. Singhal, and P. Krahenbuhl. Video compression through image interpolation , which is published in ECCV (2018). That system first encodes keyframes, and then uses hierarchical interpolation of frames between them. It demonstrates coding efficiency similar to that of the traditional AVC / H.264 codec. As we see, now researchers have managed to significantly surpass this achievement.
Article“Learned Video Compression” was published on November 16, 2018 on the arXiv.org preprint site (arXiv: 1811.06981). The authors of the scientific work are Oren Rippel, Sanjay Nair, Carissa Lew, Steve Branson, Alexander G. Anderson, Lubomir Bourdev.
Best Comment Stas911 :
Altaisky: Article about video codec and not a single video. There was nothing to show?
Stas911: They still decode the first frame. Be patient.