How we sought a compromise between accuracy and completeness in a specific ML problem

I will talk about a practical example of how we formulated the requirements for a machine learning problem and chose a point on the accuracy / completeness curve. Developing a system for automatic content moderation, we faced the problem of choosing a compromise between accuracy and completeness, and solved it with the help of a simple but extremely useful experiment in collecting assessors and calculating their consistency.
At HeadHunter, we use machine learning to create custom services. ML is “fashionable, stylish, youth ...”, but, in the end, it is only one of the possible tools for solving business problems, and this tool must be used correctly.
Formulation of the problem
If you simplify it to the extreme, then the development of a service is an investment of the company's money. And the developed service should be profitable (perhaps indirectly - for example, increasing user loyalty). Developers of machine learning models, as you understand, evaluate the quality of their work in slightly different terms (for example, accuracy, ROC-AUC, and so on). Accordingly, it is necessary to somehow translate the requirements of the business, for example, into the requirements for the quality of models. This allows, inter alia, not to get carried away with the improvement of the model where “not necessary”. That is, from the point of view of accounting - less to invest, and from the point of view of product development - to do what is really useful to users. In one specific task, I’ll talk about how we set the quality requirements of the model in a fairly simple way.
One of the parts of our business is that we provide users-applicants with a set of services for creating electronic resumes, and users-employers with convenient (mostly paid) ways to work with these resumes. In this regard, it is extremely important for us to ensure a high quality resume base precisely from the point of view of perception by HR managers. For example, the database should not just not contain spam, but also always indicate the last place of work. Therefore, we have special moderators who check the quality of each resume. The number of new resumes is constantly growing (which, in itself, makes us very happy), but at the same time, the load on moderators is growing. We came up with a simple idea: historical data has been accumulated, let's train a model that can distinguish resumes that are acceptable for publication from resumes, requiring improvement. Just in case, I’ll explain that if a resume “needs improvement”, the user has limited possibilities for using this resume, he sees the reason for this and can fix everything.
I will not now describe the fascinating process of collecting source data and building a model. Perhaps those colleagues who did this will sooner or later share their experiences. Anyway, in the end we got a model with this quality:
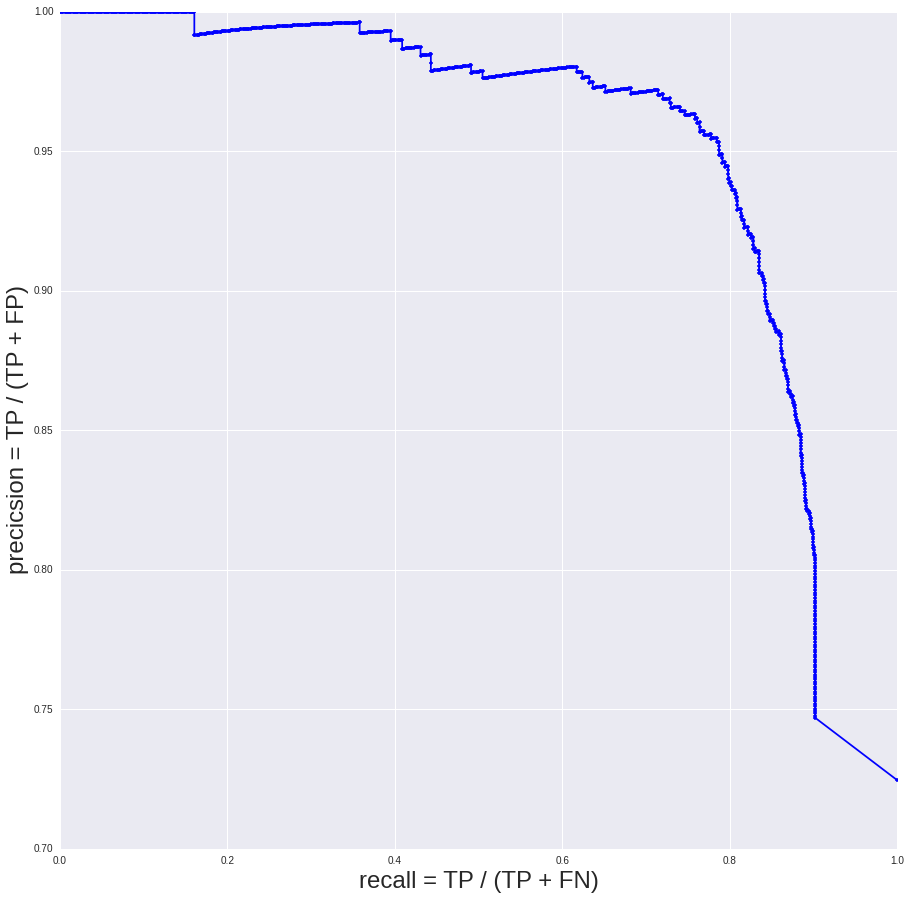
The vertical axis represents precision, or the proportion of resumes correctly accepted by the model. On the horizontal axis - the corresponding completeness (recall), or the proportion accepted by the model resumes from the total number of "eligible for publication" resumes. Everything that is not accepted by the model is accepted by people. A business has two opposite goals: a good base (the smallest proportion of “not good enough” resumes) and moderation costs (accepting as many resumes as possible automatically, and the lower the development cost, the better).
Did you get a good or bad model? Does it need to be improved? And if not, then what threshold (threshold), that is, what point on the curve to choose: what trade-off between accuracy and completeness suits the business? At first I answered this question with rather vague constructions in the spirit of “we want 98% accuracy, and 40% fullness, it would seem, is quite good.” The justification for such “product requirements”, of course, existed, but so unsteady that it was not worthy of being published. And the first version of the model came out in this form.
Experiment with assessors
Everyone is happy and happy, and then the question arises: let’s the automatic system accept even more resumes! Obviously, this can be achieved in two ways: to improve the model, or, for example, to choose another point on the above curve (to reduce accuracy for the sake of completeness). What have we done to formulate product requirements in a more conscious way?
We assumed that in fact people (moderators) may also be mistaken, and conducted an experiment. Four random moderators were asked to mark (independently of each other) the same sample of resumes on a test bench. At the same time, the working process was completely reproduced (the experiment was no different from a normal working day). In sampling, there was a trick. For each moderator, we took N random resumes already processed by him (that is, the total sample size was 4N).
So, for each resume, we have collected 4 independent decisions of the moderators (0 or 1), a solution to the model (a real number from 0 to 1), and an initial solution to one of these four moderators (again 0 or 1). The first thing you can do is to calculate the average "self-consistency" of the decisions of the moderators (it turned out about 90%). Further, you can more accurately assess the "quality" of the resume (the rating is "publish" or "do not publish"), for example, by the majority vote method. Our assumptions are as follows: we have an “initial rating from the moderator” and a “initial rating from the robot” plus three ratings from independent moderators. According to three estimates, there will always be a majority opinion (if there were four ratings, then by a 2: 2 vote, a solution could be chosen randomly). As a result, we can evaluate the accuracy of the “average moderator” - again, it turns out to be about 90%. We draw a point on our curve and see that the model will provide the same expected accuracy with a completeness of more than 80% (as a result, we began to automatically process 2 times as many resumes at minimal cost).
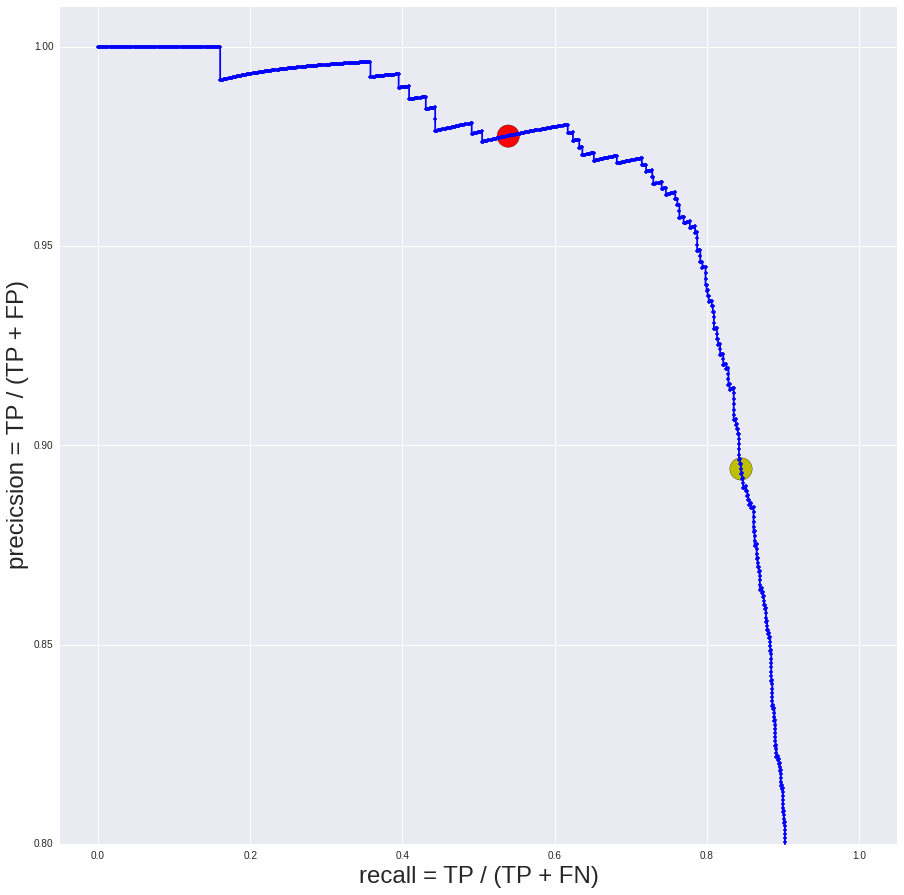
Conclusions and spoiler
In fact, while we were thinking about how to build the process of accepting the quality of the automatic moderation system, we came across several stones that I will try to describe next time. In the meantime, using a fairly simple example, I hope I have managed to illustrate the benefits of accessor markup and the simplicity of constructing such experiments, even if you don’t have Yandex.Tolki at hand, and how unexpected the results may be. In this particular case, we found out that 90% accuracy is quite enough to solve a business problem, that is, before improving the model, it is worth spending some time studying real business processes.
In conclusion, I would like to express my gratitude to Roman Poborchem p0b0rchy for the advice of our team during the work.
What to read:
- Ensuring quality in crowdsourced search relevance evaluation: The effects of training question distribution - an example of a similar problem statement
- Modeling Amazon Mechanical Turk - Amazon's Custom Grading System
- Maximum Likelihood Estimation of Observer Error-Rates Using the EM algorithm - iterative algorithms for predicting a true estimate (in particular, the authors name algorithm - Dawide-Skene algorithm)