Reverse engineering of visual short stories (part 2)
- Tutorial
 We continue our series of articles on how to get into the insides of game engines and pull out all kinds of contents from them. For those who have just joined us, I’ll briefly recall that we studied such a funny genre as visual short stories.
We continue our series of articles on how to get into the insides of game engines and pull out all kinds of contents from them. For those who have just joined us, I’ll briefly recall that we studied such a funny genre as visual short stories.
It has been a long time since we learned how to parse the archives of the visual novel engine Yuka , it is time to take on the most interesting of what we found there - in fact, the script. Looking ahead a bit, I’ll immediately warn you that the script, of course, is much more complicated matter than just an archive with files, so we can’t figure it out for one article, but today we’ll try to understand what parts it consists of and get access to text resources.
Перед тем, как погружаться в пучины бинарных дампов, давайте прикинем, как работают большинство движков визуальных новелл. Визуальная новелла сама по себе состоит из текста (реплик героев, диалогов, промежуточного повествования), графики и звуков. Для того, чтобы ее воспроизвести пользователю, явно нужно свести все это воедино с помощью какого-то управляющего воздействия. В теории можно было бы зашить это все прямо в exe-файл, но в 99% случаев (ладно, вру, в 100% виденных лично мной) так все-таки не делают, а хранят такие инструкции отдельно в виде отдельной программы-скрипта. Как правило, скрипт пишется на особенном языке программирования (специфичном для движка), который выглядит как-то так:
$ tarot = 0$ memory = 0
scene bg01_1 with dissolve
play music "bgm/8.mp3" fadein (2.0)
play ambience "amb/forest.mp3" fadein (3.0)
"Morning.""Not my favourite time of the day.""The morning is when you're not awake enough to do anything..."This is a fragment of the script source from one VN on Ren'Py - one of the most popular free / free engines. Leaving aside the scope of this article the question of how good Ren'Py is in itself, just for now let’s note what is usually included in the visual novel script and what we will need to find:
- text - it still either is not attributed to any character (ie the text "from the narrator" - as in our example), or is still pronounced by someone
- commands to show the graphics - background / sprite (
scene bg01_1), sometimes with some special effect (with dissolve) - commands to start playing music or sounds (
play music,play ambience), sometimes also with some additional parameters, most often lengths fade-in and fade-out (smooth increase in volume) - work with variables: setting (
$ tarot = 0, checking, branching) there are still commands:
- to play a speech delivered by the characters
- for management
- service stuff like comments, tags, macros
Of course, in the real world, often we will not have access to the source code of the script. People have already learned how to write compilers for about 50 years (as opposed to interpreters), so usually the script source is compiled into some binary code (byte code), which is then executed by a virtual machine inside the visual novel engine. Sometimes it’s lucky and for some popular engines there are legally or not very legally available tools - debuggers, compilers, decompilers, script validators, etc., but more often life is not so simple.
So, back to our visual novel, which we started exploring in a previous article - Koisuru Shimai no Rokujuso . We have already unpacked its archives and found inside and graphics, and sounds, and music, and, most importantly and incomprehensible so far - a bunch of files with the extension .yks. Presumably, they make up the short story script. By the way, there are many files:
YKS/ScriptStart.yks
YKS/trial/Yoyaku.yks
YKS/trial/trial_00100.yks
YKS/trial/trial_00200.yks
YKS/all/all_00010.yks
...
YKS/all/all_02320.yksOnly 103 files in YKS / all /. Let me remind you that we absolutely honestly downloaded and explored the trial version - but, apparently, the developers were a bit lazy and, apparently, the trial / script contains the trial version, and all / the full version.
In general, based on minimal experience, the builders of visual novel engine have 2 approaches: either everything is packed into one giant file, or there are many files and each of them has its own scene or event. It seems that the second. In addition, there is still a separate ScriptStart.yks - but as such it will most likely be of little interest to us: the fact is that developers often want to make the engine as versatile as possible and implement all sorts of user interfaces, menus-load-save-options, etc. .d. also by means of its scripting language. You can deal with this, but rather boring and fruitless: therefore, I propose to take the bull by the horns and start with the actual script of the game.
What can we say from a superficial visual inspection? Firstly, because Since the game runs on Windows, it’s quite possible to run it and see how it looks. We spend the nth amount of time, find a Windows machine, start it, see what happens immediately after clicking the start button for a new game:

It seems that the beginning of the story meets us. There is a background here (after a brief search in BG / there is a bg01_01.png file with this background), and there is text. We still need this text, so it’s worth re-typing it from the screen:
恋する姉妹の六重奏「セクステット」体験版Ver2をダウンロード頂きありがとうございます。Two points:
If there are problems with typing the Japanese text, I can recommend mastering three or four tricks that greatly simplify this matter and, with some patience, make it possible for those who have absolutely no idea what the squiggles are to type Japanese texts. We consider each icon individually:
- we check if this is a punctuation mark in such a table: 「...」 」()。 - if you are lucky, then copy; pay attention to the fact that both “commas”, “dots”, and brackets are specific here.
- if not, we look in this table: あ い う え お か き く け こ さ し す せ そ た ち つ て と な に ぬ ね の は ひ ふ へ ほ ま む め も や ゆ よ ら り を れ ろ ろ ろ ろ ろ ろ ろ
- then we look for something like this: ア イ ウ エ オ カ キ ク ケ コ サ シ ス セ ソ タ チ ツ テ ト ナ ニ ヌ ネ ノ ハ ヒ フ ヘ ホ マ ミ ム メ モ ヤ ユ ヨ ラ リ ル レ ロ ワ ワ ワ
- if it doesn’t help - for example, 恋 got caught - then this is kanji; then increase the font by 300-500% so that all the small details can be clearly seen and go to jisho.org in the "search by radicals" section ; there we look at the table of the constituent parts (radicals) and look for similar ones to what we see; for example 恋 - after a short meditation we find that he has a component below часть - we hold down the button with this component and we have only a couple of dozen icons of many thousands; look through their eyes and find in the issue in section "10" the fifth sign from the beginning - this will be the desired one 恋.
- I'm not sure if there will be Ver2 or Ver2 - note that these are not different fonts, but suddenly the so-called full-width characters - in Unicode they are somewhere in the U + FF01..U + FF5E region).
We will need the text for two things. Firstly, as a text, to understand what is happening (even if you don’t speak Japanese, you can insert it into the Google translator and understand that we are thanked here for downloading the trial version of this game => i.e. this is not a real start plot, and a certain introduction, "from the author"). Secondly, we can take this text or a piece of it, convert it to ShiftJIS (and most likely, as we found in the previous note, everything will be in this encoding) and look for it in the files. Take a piece from the end and prepare what we are looking for:
$ echo 'ダウンロード頂きありがとうございます'| iconv -t sjis | hd
00000000835f 83458393838d 815b 836892 b8 82 ab |._.E.....[.h....|0000001082 a082 e8 82 aa 82 c6 82 a4 82 b2 82 b4 82 a2 |................|0000002082 dc 82 b7 |....|We are looking for this line in all of our .yks files and, of course, cannot be found. Not so simple.
Let's do another digression: let's get acquainted with how the ShiftJIS encoding works. In Japanese, obviously, there are much more icons than in European: in ShiftJIS each of the icons is encoded with at least 1 byte, with a maximum of 2. As you can see from this plate , the values of bytes 00..7F are identical to ASCII, but bytes 81..9F and E0..EA mean that this is a two-byte combination, and for compatibility, again, with binary reading, the second byte will not have any value , but something between 40 and FF.
Microexcursion to the Japanese language: 3 groups of icons are used in the language:
- hiragana - it looks something like this: あ り が と う ご ざ い ま す - i.e. rounded simple writing forms; ~ 50 icons, but there are all sorts of variations like "large i = い, small i = ぃ"; 1 syllable = 1 character.
- katakana - it looks something like this: ダ ウ ン ロ ー ド - i.e. chopped-square, simple printing forms; the sounds are all about the same as hiragana, but used to record mostly borrowed words (ダ ウ ン ロ ー ド = da-un-lo: -do = download).
- kanji - it looks something like this: 体 験 版 - i.e. as a rule, complex square constructions from a heap of different parts and caps; it’s the hardest thing with them, that’s just a lot of them.
Plus there are also punctuation marks, plus or minus are the same as in European languages: dot 。, comma 、, ellipsis …, quotation marks 「」, exclamation and question marks, etc. But there are usually no gaps. The trick is that the text constantly alternates with “important” words that are recorded by kanji and particles that are recorded by hiragana, as a result of which this mixture can be sorted out at least somehow. For example, take the name of the game 恋 す る 姉妹 の 六 重奏:
- 恋 - kanji
- す る - hiragana
- 姉妹 - kanji
- の - hiragana
- 六 重奏 - kanji
What does this give us in the bottom line? Very simple: frequency table. We take a ready-made script of the first visual novel in Japanese that came to hand, quickly look at the boundaries of the ranges of all three groups in Unicode and run this script on it (sorry for the pun):
stats = {}
$stdin.each_char { |c|
t = case c.ord
when0x3041..0x309Fthen:hiraganawhen0x30A0..0x30FFthen:katakanawhen0x4E00..0x9FCCthen:kanjiend
stats[t] ||= 0
stats[t] += 1
}
p statsand we get something like the output:
{nil=>72384, :kanji=>5731, :hiragana=>15377, :katakana=>2241}those. the typical text will be ~ 25% kanji, 65% hiragana and 10% katakana.
It seems time to uncover the tools and dive headlong into the work. Let me remind you briefly that we use the new open source tool Kaitai Struct to analyze binary files with an incomprehensible structure - it allows you to describe templates in the markup language, which you can then apply to files and quickly visualize their contents arranged in shelves in a tree, and in As a mega-bonus, then - compile the template directly into the source in virtually any popular programming language (since the writing of the previous article, Kaitai Struct began to support not only Java, JavaScript, Python and Ruby, but also C ++, C #, Perl and PHP). That is, if you look at all kinds of lists of top languages - Top 10 is completely covered, from top 20, if you don’t take domain-specific things, Delphi, Visual Basic (although I have little idea that anyone would do reverse engineering on the ancient Visual Basic, not .NET), Swift and Go
We studied the basic syntax of Kaitai Struct templates in the first part of the article, so whoever missed / forgot what it was about is the time to familiarize yourself with it / refresh it in memory .
So, we quickly look at dumps of 3-4 files and understand that such a template is suitable for us as a starting point:
meta:
id: yks
application: YukaEngine
endian: le
seq:
- id: magic
contents: ["YKS001", 1, 0]
- id: magic2
contents: [0x30, 0, 0, 0, 0, 0, 0, 0, 0x30, 0, 0, 0]
- id: unknown1
type: u4
- id: unknown2
type: u4
- id: unknown3
type: u4
- id: unknown4
type: u4
- id: unknown5
type: u4
- id: unknown6
type: u4
- id: unknown7
type: u4You can immediately draw analogies with the YKC format. Because there at the beginning there was a description of the "header", starting with its length, then with a high probability the fixed 0x30 found everywhere in magic2 is the length of the original header, so I propose to read everything down to 0x30 at once. It turns out 7 numbers, now it will try to guess what it is.
For Yoyaku.yks (the file itself is 27741 bytes):
[.] @unknown1 = 1845
[.] @unknown2 = 7428
[.] @unknown3 = 795
[.] @unknown4 = 20148
[.] @unknown5 = 7593
[.] @unknown6 = 25
[.] @unknown7 = 0For trial_00100.yks (file 91267 bytes):
[.] @unknown1 = 6433
[.] @unknown2 = 25780
[.] @unknown3 = 2376
[.] @unknown4 = 63796
[.] @unknown5 = 27471
[.] @unknown6 = 5
[.] @unknown7 = 0And, for comparison, some file from all, for example, all_00010.yks (12968 bytes):
[.] @unknown1 = 933
[.] @unknown2 = 3780
[.] @unknown3 = 353
[.] @unknown4 = 9428
[.] @unknown5 = 3540
[.] @unknown6 = 1
[.] @unknown7 = 0What is visible? Firstly, it’s all epic like offsets or sizes in a file, because with a file size of 91K, numbers float in the region of 25-63K, and with a size of 12K, in the region of 3-9K. On closer inspection, the offsets and sizes are most likely only unknown2, unknown4, unknown5 - they are divided into 4 and quite large. Secondly, unknown7 always seems to be 0. Thirdly, unknown6 seems to be setting something very piecewise. This may be, for example, the size of the reserved memory of the virtual machine for variables, the number of changing scenes / sprites / backgrounds, or something else.
Immediately after 0x30, even with the naked eye, in a human hex editor, a table of increasing (or almost always increasing numbers) is visible. This is hardly the bytecode itself: the bytecode is characterized by just the constant repetition of the same sequences. This is also most likely some offsets - for example, it can be offsets that define the beginning of commands in bytecode, or some beginning-ends of lines of variable length, or something else. We have 7 unknown values, this is not so much - let's go through it and see if one of them looks like:
- either the length of this section
- either by the absolute offset of the end of this section = the beginning of a new
- either by the number of 4-byte integers in the plot
Almost the very first attempt fits very well: unknown1 turns out to be the number of elements in this section, and unknown2 turns out to be a pointer to the beginning of the next section. And thus, it seems that in practice unknown2 = 0x30 + unknown1 * 4. We add the description right away, at the same time moving the header to the explicitly selected header type, and we start calling the opened sections sect1..sectX:
seq:
- id: header
type: header
- id: sect1
size: header.sect2_ofs - 0x30type: sect1
types:
header:
seq:
- id: magic
contents: ["YKS001", 1, 0]
- id: magic2
contents: [0x30, 0, 0, 0, 0, 0, 0, 0, 0x30, 0, 0, 0]
- id: sect1_qty
type: u4
- id: sect2_ofs
type: u4
- id: unknown3
type: u4
- id: unknown4
type: u4
- id: unknown5
type: u4
- id: unknown6
type: u4
- id: unknown7
type: u4
sect1:
seq:
- id: entries
type: u4
repeat: expr
repeat-expr: _root.header.sect1_qtyAs a result, trial_00100 starts to look like this:
[-] @header
[.] @magic = 594b533030310100
[.] @magic2 = 300000000000000030000000
[.] @sect1_qty = 6433
[.] @sect2_ofs = 25780
[.] @unknown3 = 2376
[.] @unknown4 = 63796
[.] @unknown5 = 27471
[.] @unknown6 = 5
[.] @unknown7 = 0
[-] @sect1
[-] @entries (6433 = 0x1921 entries)
[.] 0 = 6
[.] 1 = 7
[.] 2 = 3
[.] 3 = 3
[.] 4 = 4
...
[.] 6425 = 2371
[.] 6426 = 2372
[.] 6427 = 34
[.] 6428 = 1
[.] 6429 = 2373
[.] 6430 = 2374
[.] 6431 = 1
[.] 6432 = 2375In fact, it is now noticeable that these are not just increasing values - this may well be a bytecode. In this file, noticeable increasing numbers seem to go from 0 or 1 and eventually increase to 2375. Suddenly, unknown3 = 2376 is very similar to the number of these values. Those. the bytecode refers to another table in which there are 2376 different values (apparently, from 0 to 2375 inclusive). What could it be?
We look at the next section, looking at what happens on the screen 3-4 forward:

In my opinion, it is more or less obvious that these are records of 16 bytes (1 line) long, and again they have something strikingly similar to obviously constantly unevenly increasing offsets or indices. Will there be 2376 such records? We check by renaming unknown3 to sect2_qty and adding a trivial slice to collect sect2 from 16-byte records:
- id: sect2
size: 16repeat: expr
repeat-expr: header.sect2_qtyand, it seems, bingo, this is it and very precisely:

It can be clearly seen with the naked eye that these very slender 16-byte records really end exactly after sect2_qty pieces and then something completely different begins. What do we see here? These are clearly not long 4-byte numbers, almost all non-zero. Some obviously periodic structure is also not traced, at least at first glance. An abundance of 0xaa. A lot of 0x28 alternating through time. We look at the end of the file, trying to find some other sections - it seems not, at the end about the same texture:
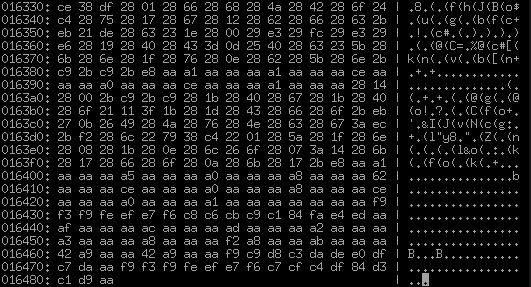
That is, this is the third and last section of the file, there will be nothing more in it. And what have we not seen? Text and lines. Apparently, this is what they are, but clearly somehow encoded. Squeezed? No, not like that. Such a number of repeating 0x28 and 0xaa would not be. Yes, and repeating 0x28 in all kinds of 28 08 28 1b 28 0e 28 6c 26 6f 28 07 3a 14 28 6blooks terribly suspicious. For comparison, let us remember what it looks like in ShiftJIS average Japanese text: 82 a0 82 e8 82 aa 82 c6 82 a4 82 b2 82 b4 82 a2. The hypothesis immediately arises that this is the simplest wildcard cipher, where each byte is always converted to the same other byte. What can it be, how to get from 0x82 => 0x28? Humanity actually came up with not so many options:
- addition / subtraction - add (or subtract the same thing) to each byte the same number, overflow just ignore
- rol / ror - a cyclic shift by a certain number of bits, in the most stupid version, a shift of exactly 4 bits is made to the right or left, swaps 2 hexadecimal digits
- exclusive "or" (xor) - perform an xor operation with some other fixed byte with each byte; one of the most stupid, banal, somehow acting and therefore popular ways
In general, there is even "heavy" artillery in the form of programs such as XORSearch , which try to guess such transformations by brute force, but here it is still more commonplace and I manage to guess the second time. The abundance of 0xaa suggests that there are many zeros that XOR with 0xaa, which gives 0xaa. And suddenly 0x82 ^ 0xaa is exactly 0x28. 0xaa is generally one of the most commonplace assumptions that should be checked for good in the first place, because 0xaa = 0b10101010, i.e. xor stupidly flips every second bit with it.
Fortunately, Kaitai Struct has built-in support for such transformations, activated through process:. Just write like this:
- id: sect3
size-eos: trueprocess: xor(0xaa)after which we will finally be able to observe the rich inner world of string constants of our trust scripts:
000000: 696600 c8 000000476c 6f62616c 466c 61 | if.....GlobalFla
000010: 67003d00 ff ff 0000010000003d007b 00 | g.=.........=.{.
000020: 0d00000057696e 646f774e 616d655365 | ....WindowNameSe
000030: 740097 f6 82 b7 82 e9 8e 6f968582 cc 985a | t........o.....Z
000040: 8f649174288366836f8362834f29817c | .d.t(.f.o.b.O).|
000050: 46696c 65203a 20747269616c 685f6d61 | File : trialh_ma
000060: 79752e 796b 73007d0009000000447261 | yu.yks.}.....Dra
000070: 7753746f700047726170686963486964 | wStop.GraphicHid
000080: 65000a 0000005472616e 736974696f6e | e.....Transition
000090: 0002000000640000000a 0000000b 0000 | .....d..........
0000a0: 00477261706869634c 6f616400000000 | .GraphicLoad....Fortunately, among other things, there is a cloud of ASCII lines, which greatly simplifies life. At first glance, it seems that these are just C-style lines terminated with zeros, but upon closer inspection, it turns out that this is not entirely true. There are lines and any incomprehensible interspersing of constants, for example:, ff ff 00 00 01 00 00 00or 02 00 00 00 64 00 00 00 0a 00 00 00 0b 00 00 00, which, despite the presence of one printed ASCII character in the center ( d= 0x64), are most likely not lines. In addition, the most valuable thing - here they are - these same lines in Japanese in ShiftJIS with 82.
To summarize, we succeeded:
- sect1, consisting of 4-byte integers (presumably this is bytecode), partially referring to 16-byte entries in sect2 with these numbers
- sect2, consisting of 16-byte records with increasing numbers inside (presumably some offsets)
- sect3, which consists mainly of null-terminated lines in ShiftJIS, but not quite (presumably - string resources and all sorts of other constants referenced bytecode)
On this small victory, I think we will complete our today's research, since the article once again turns out indecently large. To some extent - if, for example, the task is to translate a visual novel - the achievements today are already enough to tear out texts and give them to translators. We take sect3, find in it everything that looks like SJIS, carefully discard everything else - voila:
恋する姉妹の六重奏(デバッグ)-File : trialh_mayu.yks
まゆ
「きゃっ……!!」
教育的指導を兼ねて、お望み通りメチャクチャにしてやろうじゃないか!!
「あっ……お、おにぃっ……」
自分から誘っておきながら、不安そうな表情を浮かべるまゆ。
そんなまゆを、ソファーに押しつけて……胸を露出させ、股間が丸見えになる体勢を強いる。
「んぁっ……」Thanks to everyone who read to this place. Next time we get to the bytecode itself and try to understand how sect1 and sect2 work. See you!