Arrays in PHP 7: Hash Tables
- Transfer
Hash tables are used everywhere, in every serious C-program. Essentially, they allow the programmer to store values in an “array” by indexing it with strings, while in C, only integer array keys are allowed. In a hash table, lowercase keys are first hashed and then reduced to the size of the table. Collisions can occur here, so an algorithm for resolving them is needed. There are several similar algorithms, and PHP uses a linked list strategy.
There are many great articles on the Web that highlight in detail the design of hash tables and their implementation. You can start with http://preshing.com/. But keep in mind, there are a myriad of hash table structure options, and none of them are perfect, each has trade-offs, despite optimizing processor cycles, memory usage, or a good scaling of the threaded environment. Some options are better when adding data, others when searching, etc. Choose an implementation depending on what is more important to you.
Hash tables in PHP 5 are discussed in detail in phpinternalsbook , which I wrote with Nikic , the author of a good article on hash tables in PHP 7 . Perhaps you also find it interesting. True, it was written before the release, so some things in it are slightly different.
Here we will take a closer look at how hash tables are arranged in PHP 7, how you can work with them from the point of view of the C language, and how to manage them using PHP tools (using structures called arrays). The source code is mostly available at zend_hash.c . Do not forget that we use hash tables everywhere (usually as dictionaries), therefore, you need to design them so that they are quickly processed by the processor and consume little memory. These structures are critical to the overall performance of PHP, since local arrays are not the only places where hash tables are used.
There are a number of provisions that we will consider in more detail below:
Consider the structure
Some fields are rarely used, and therefore we will not talk about them.
The size of this structure is 56 bytes (according to the LP64 model).
The most interesting data field is
As you may have noticed, the structure
Let's look at the picture, as there is a memory location:

As you can see, placed in a hash table of data is stored in adjacent memory section:
PHP must maintain the order of the elements when they are added to the array. If you apply the instruction to the array
This is an important point that imposed a number of restrictions on the implementation of hash tables. All data is placed in memory next to each other. In

Thanks to this approach, you can easily iterate the hash table: just iterate the array
Data is sorted and transferred to the next cell
A simplified view of adding items to a hash table using string keys:
When deleting a value, the array

Therefore, the iterative code needs to be rebuilt a bit so that it can process such "empty" cells:
Below we will consider what happens when the size of the hash table changes and how the array should be reorganized
Keys must be hashed and compressed, then converted from the compressed hashed value and indexed into
It must be remembered that we cannot index compressed values as is directly in
For example: if you add first with the key foo, and then with the key bar, the first will be hashed / compressed to key 5, and the second to key 3. If you store foo data in

So, we hash, and then compress the key so that it fits into the allotted boundaries
There is one caveat: the conversion table memory is prudently located behind the vector

Now our foo key is hashed in DJB33X and compressed modulo to the required size (
These cells are accessed by a negative shift from the starting position
Below you can clearly see how the buffer is divided into two parts:
When the macros are executed, we get:
Wonderful.
Now let’s see how collisions are resolved. As you recall, in a hash table, several keys when hashed and compressed may correspond to the same conversion index. So, having received the conversion index, we use it to extract the data back from
Note that a linked list is not memory-scattered like traditional linked lists. Instead of walking along several memory-mounted pointers received from the heap — and probably scattered across the address space — we read the entire vector from memory
In PHP 7, hash tables have very high data locality. In most cases, access occurs in 1 nanosecond, since the data is usually located in the processor cache of the first level.
Let's see how you can add elements to the hash, as well as resolve collisions:
Same thing with deleting:
Two-stage initialization provides certain advantages, allowing you to minimize the impact of an empty, just created hash table (a common case in PHP). When creating a table, we simultaneously create bucket cells in
Please note that here you can not use a bunch. The static const memory zone is quite enough, so it is much easier (
After adding the first element, we completely initialize the hash table. In other words, we create the last necessary transformation cells depending on the requested size (by default it starts with 8 cells). Placement in memory comes from a heap.
The macro
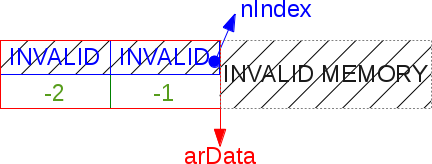
An example of a lazy-initialized (lazy-initialized) hash table: it has been created, but so far no hash has been placed in it.
If the hash table is full and you need to add new elements, you have to increase its size. This is a big advantage of hash tables compared to classic hard-limited arrays in C. With each increase, the size of the hash table doubles. I remind you that as the size of the table increases, we pre-allocate the C-array in memory
All this memory consists of UNDEF cells and waits for data to be placed in it.
For example, you have 1024 cells in a hash table, and you add a new element. The table grows to 2048 cells, of which 1023 are empty. 1023 * 32 bytes = approximately 32 Kb. This is one of the disadvantages of implementing hash tables in PHP.
It must be remembered that a hash table can consist entirely of one UNDEF cells. If you add and remove many elements, the table will be fragmented. But for the sake of preserving the order of the elements, we add everything new only at the end
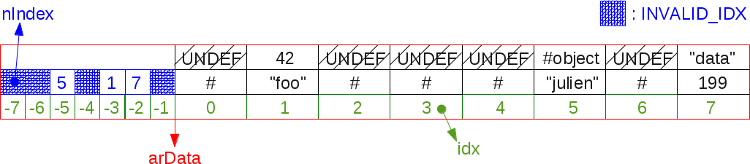
An example of a highly fragmented 8-cell hash table:
As you may recall, new values cannot be stored in UNDEF cells. In the above scheme, when iterating a hash table, we go from
By increasing the size, you can reduce the vector
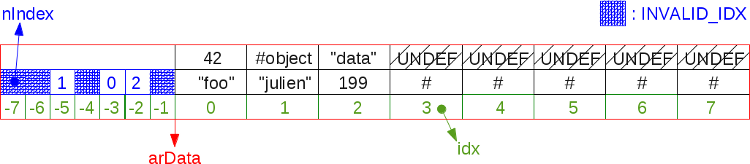
This illustration shows the previous fragmented hash table after compaction:
The algorithm scans
Well, now we know the main points of implementing a hash table in PHP 7. Let's now look at its public API.
There is nothing to talk about (well, in PHP 5 the API is much better). Just when using the API function, do not forget about three things:
Whatever your key, lowercase or integer, the main thing: the API should be aware that lowercase keys get hashes from
Sometimes a key can be a simple pair (char * / int). In this case, you need to use a different API, for example
Now about the data that you are going to store in the hash table. Again, it could be anything, the hash table will still put the data
The situation can be somewhat simplified if you have a pointer to the storage or memory area (data referenced by the pointer). Then the API will place this pointer or memory area in zval, and then zval itself will use the pointer as data.
Examples will help to understand the idea:
When retrieving the data, you will get either zval * or NULL. If a pointer is used as the value, the API can return as is:
As for the _new API like
Finally: as in PHP 5, the API
You can use many macros for iterations depending on what data you want to get in the loop: key, zval ... All these macros are based on
So, remember the critically important rule: we add data in
But in one case, such tables are useless: if the user uses only integer keys and only in ascending order. Then, when viewing
This optimization is called a “packed hashtable”:

As you can see, all keys are integer and placed simply in ascending order. When iterating
I must warn you: if you break the rule by, say, inserting a lowercase key (after hashing / compression), then the packed hash table must be converted to the classic one. With the creation of all the necessary transformation cells and the reorganization of bucket'ov.
A hash table is
To summarize: packed hash tables can optimize the use of both memory and processor.
Nevertheless, if you start using lowercase keys or violate the sort order of integer keys (say, insert 42 after 60), then the hash table will have to be converted to “classic”. You will spend a little processor resources on this (on large arrays - a bit more) and additional memory. To create a packed hash table, just say the API:
Keep in mind that this
Let's see how you can verify the hash table implementation details within custom code.
First, we will demonstrate the optimization of packed arrays (packed array):
As expected, memory consumption results:
When moving from a packed array to a classic hash, memory consumption increased by about 130 Kb (for an array with 25,000 elements).
Now we demonstrate the operation of the compression or enlargement algorithm:
Results:
When the table is full and we empty it, the consumed memory does not change (modulo noise). After applying
Now add something as the next item . Remember
Is compaction possible?
The answer seems obvious - yes, because we have solid UNDEF cells here. But actually not: we need to keep data in order because we use a packed arrayand we wouldn’t like it to turn into a classic until we completely hide it. If we add an element to an existing cell, we will break the sequence, which will start the compaction procedure, and not increase the size.
Memory usage:
See the difference? Now the algorithm did not increase our table from 32,768 to 65,538 cells, but compacted it. The table in memory still has 32,767 cells. And since the cell is
We can do the same with the classichash table just using lowercase keys. When we overfill it with one element, the table will be compacted, but not increased, because there is no need to maintain order. In any case, we are in "unpacked" mode, we just add one more value to the leftmost position (
Memory Results:
As expected. The array consumes about 2.5 MB. After applying
If one element is now added, then the internal size of the table will overflow, which will start the algorithm of compaction or increase. Since the array is not packed, it is not necessary to maintain the order of the elements, and the table will be compacted. The new value 42 is written in idx 0, the amount of memory does not change. The end of the story.
As you can see, in some rare cases, packed hash tables can even harm us, increasing in size instead of compaction. But will you really use such stupid code in real projects? This should not affect everyday programming, but if you need really high performance (frameworks, can you hear me?) And / or you want to optimize highly loaded batch scripts, then this can be a good solution. Instead of puzzling over the transition to pure C in solving such problems. If you do not have many thousands of elements, then memory consumption will be ridiculous. But in our examples there were “only” from 20 to 32 thousand elements, and the difference was measured in kilobytes and megabytes.
Immutable arrays are a feature of OPCache. Without enabling OPCache, you cannot take advantage of immutable arrays, i.e., read-only ones. If OPCache is activated, then it looks at the contents of each script and tries to copy many things into shared memory. In particular, constant AST nodes. Actually, a constant array is a constant AST node. For instance:
Here
In addition, OPCache turns arrays into immutable ones by setting the IS_ARRAY_IMMUTABLE and IS_TYPE_IMMUTABLE flags for them . When the engine meets IS_IMMUTABLE, he treats this data in a special way. If you convert an immutable array to a variable, then it will not be duplicated. Otherwise, a full copy of the array is created.
An example of the described optimization:
This script consumes about 400 MB of memory without OPCache, and with it about 35 MB. If OPCache is disabled, then in the script the engine creates a full copy of the 8-element array in each slot
Obviously, if you later change one of these arrays, say
In the internal hash tables, another, almost random optimization was made. As you may recall, PHP arrays are just a special case of Zend hash tables. Since you can manipulate them with PHP, you can imagine a way to use it. But hash tables are used throughout the engine. For example, any script may contain functions and / or classes. These two large schemes are stored in two hash tables. The compiler converts the script into the so-called OPArray and attaches the function table (it may be empty) and the class table (it may also be empty) to it. When PHP completes the current request, it clears this OPArray: destroys the function and class tables. But with OPCache enabled, both of these arrays also become IMMUTABLE, and as a result, the engine cannot destroy them. As soon as the next request appears, they will be immediately loaded from the shared memory and will request the exact same script.
OPCache strictly once stores these tables in memory, preventing them from being destroyed. Destruction itself can take a lot of time, because it is recursive and involves the destruction of numerous pointers (the more classes and functions you have, the longer it is). Consequently, immutable hash tables also allow OPCache to speed up the closing procedure performed by the engine, the current PHP process will complete faster and the next request will proceed. All this improves the overall performance of PHP.
But don't let immutable arrays confuse you. For example, at the moment, such a scenario has no optimization:
Here two arrays are created in memory. And there is no process like that used for interned strings , when the engine tracks every part of the used string so that it can be used again if necessary. Immutable arrays are arrays filled with immutable types (no variables, no function calls, everything is solved at compile time) that are not duplicated in memory when moving from one place to another during PHP runtime. Also, these types are never destroyed in memory (from one request to another). In addition, immutable arrays are only used when the OPCache extension is activated.
There are many great articles on the Web that highlight in detail the design of hash tables and their implementation. You can start with http://preshing.com/. But keep in mind, there are a myriad of hash table structure options, and none of them are perfect, each has trade-offs, despite optimizing processor cycles, memory usage, or a good scaling of the threaded environment. Some options are better when adding data, others when searching, etc. Choose an implementation depending on what is more important to you.
Hash tables in PHP 5 are discussed in detail in phpinternalsbook , which I wrote with Nikic , the author of a good article on hash tables in PHP 7 . Perhaps you also find it interesting. True, it was written before the release, so some things in it are slightly different.
Here we will take a closer look at how hash tables are arranged in PHP 7, how you can work with them from the point of view of the C language, and how to manage them using PHP tools (using structures called arrays). The source code is mostly available at zend_hash.c . Do not forget that we use hash tables everywhere (usually as dictionaries), therefore, you need to design them so that they are quickly processed by the processor and consume little memory. These structures are critical to the overall performance of PHP, since local arrays are not the only places where hash tables are used.
Hash table design
There are a number of provisions that we will consider in more detail below:
- The key can be a string or an integer. In the first case, the structure is used
zend_string, in the second -zend_ulong. - A hash table must always remember the order in which its elements are added.
- The size of the hash table changes automatically. Depending on the circumstances, it independently decreases or increases.
- From the point of view of internal implementation, the size of the table is always equal to two in power. This is done to improve performance and align the placement of data in memory.
- All values in the hash table are stored in a structure
zval, nowhere else.Zval's can contain data of any type.
Consider the structure
HashTable:struct _zend_array {
zend_refcounted_h gc;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar reserve)
} v;
uint32_t flags; /* доступно 32 флага */
} u;
uint32_t nTableMask; /* маска — nTableSize */
Bucket *arData; /* полезное хранилище данных */
uint32_t nNumUsed; /* следующая доступная ячейка в arData */
uint32_t nNumOfElements; /* общее количество занятых элементов в arData */
uint32_t nTableSize; /* размер таблицы, всегда равен двойке в степени */
uint32_t nInternalPointer; /* используется для итерации */
zend_long nNextFreeElement; /* следующий доступный целочисленный ключ */
dtor_func_t pDestructor; /* деструктор данных */
};
Some fields are rarely used, and therefore we will not talk about them.
The size of this structure is 56 bytes (according to the LP64 model).
The most interesting data field is
arDataa kind of pointer to the memory area of the chain Bucket. Itself Bucketrepresents one cell in the array:typedef struct _Bucket {
zval val; /* значение */
zend_ulong h; /* хэш (или числовой индекс) */
zend_string *key; /* строковый ключ или NULL для числовых значений */
} Bucket;
As you may have noticed, the structure
Bucketwill be stored zval. Please note that this is not a pointer to zval, but the structure itself. This is because the PHP 7 zval's are no longer placed on the heap (unlike PHP 5), but the target value stored in zvalthe form of a pointer (for example, the PHP string) can be placed in PHP 7 . Let's look at the picture, as there is a memory location:
As you can see, placed in a hash table of data is stored in adjacent memory section:
arData.Adding items while maintaining order
PHP must maintain the order of the elements when they are added to the array. If you apply the instruction to the array
foreach, then you will receive the data exactly in the order in which they were placed in the array, regardless of their keys:$a = [9=>"foo", 2 => 42, []];
var_dump($a);
array(3) {
[9]=>
string(3) "foo"
[2]=>
int(42)
[10]=>
array(0) {
}
}
This is an important point that imposed a number of restrictions on the implementation of hash tables. All data is placed in memory next to each other. In
zval'ah they are stored packed in Bucket' s, which are located in the fields of the C-array arData. Like that:$a = [3=> 'foo', 8 => 'bar', 'baz' => []];
Thanks to this approach, you can easily iterate the hash table: just iterate the array
arData. In fact, this is a quick sequential scan of memory, consuming very few processor cache resources. All data from can be placed on one line arData, and access to each cell takes about 1 nanosecond. Please note: to increase the efficiency of the processor cache, it is arDataaligned according to the 64-bit model (optimizing alignment of 64-bit full instructions is also used). The hash table iteration code might look like this:size_t i;
Bucket p;
zval val;
for (i=0; i < ht->nTableSize; i++) {
p = ht->arData[i];
val = p.val;
/* можно что-нибудь сделать с val */
}
Data is sorted and transferred to the next cell
arData. To complete this procedure, just remember the next available cell in this array, stored in the field nNumUsed. Each time a new value is added, we put it ht->nNumUsed++. When the number of elements in nNumUsedreaches the number of elements in the hash table ( nNumOfElements), we run the compact or resize algorithm, which we will talk about below. A simplified view of adding items to a hash table using string keys:
idx = ht->nNumUsed++; /* берём номер следующей доступной ячейки */
ht->nNumOfElements++; /* инкрементируем количество элементов */
/* ... */
p = ht->arData + idx; /* получаем в этой ячейке bucket от arData */
p->key = key; /* устанавливаем ключ, перед которым собираемся вставить */
/* ... */
p->h = h = ZSTR_H(key); /* сохраняем в bucket хэш текущего ключа */
ZVAL_COPY_VALUE(&p->val, pData); /* копируем значение в значение bucket’а: операция добавления */
Erase Values
When deleting a value, the array
arDatadoes not decrease and does not regroup. Otherwise, the performance would have fallen catastrophically, since we would have to move the data in memory. Therefore, when deleting data from a hash table, the corresponding cell in is arDatasimply marked in a special way: zvalUNDEF. Therefore, the iterative code needs to be rebuilt a bit so that it can process such "empty" cells:
size_t i;
Bucket p;
zval val;
for (i=0; i < ht->nTableSize; i++) {
p = ht->arData[i];
val = p.val;
if (Z_TYPE(val) == IS_UNDEF) {
continue;
}
/* можно что-нибудь сделать с val */
}
Below we will consider what happens when the size of the hash table changes and how the array should be reorganized
arDataso that the “empty” cells disappear (compaction).Key Hashing
Keys must be hashed and compressed, then converted from the compressed hashed value and indexed into
arData. The key will be compressed even if it is integer. This is necessary so that it fits into the boundaries of the array. It must be remembered that we cannot index compressed values as is directly in
arData. After all, this will mean that the keys used for the index of the array directly correspond to the keys obtained from the hash, which violates one of the properties of hash tables in PHP: preserving the order of elements. For example: if you add first with the key foo, and then with the key bar, the first will be hashed / compressed to key 5, and the second to key 3. If you store foo data in
arData[5]and bar data в arData[3], then it turns out that bar data go todata foo. And during iteration, the arDataelements will not be transferred in the order in which they were added. So, we hash, and then compress the key so that it fits into the allotted boundaries
arData. But we do not use it as is, unlike PHP 5. You must first convert the key using the translation table. It simply compares one integer value obtained by hashing / compression and another integer value used for addressing within the array arData. There is one caveat: the conversion table memory is prudently located behind the vector
arData. This prevents the table from using a different memory area, because it is already located next toarDataand, therefore, remains in the same address space. This allows you to improve data locality. This is what the described scheme looks like in the case of an 8-element hash table (the smallest possible size): Now our foo key is hashed in DJB33X and compressed modulo to the required size (
nTableMask). The resulting value is an index that can be used to access transformation cellsarData (and not direct cells!). These cells are accessed by a negative shift from the starting position
arData. The two areas of memory were combined, so we can store data in memory sequentially.nTableMaskcorresponds to a negative value of the size of the table, so taking it as a module, we get a value from 0 to –7. Now you can access the memory. When placing the entire buffer in it, arDatawe calculate its size according to the formula: Размер таблицы * размер bucket’а + размер таблицы * размер(uint32) ячеек преобразования.Below you can clearly see how the buffer is divided into two parts:
#define HT_HASH_SIZE(nTableMask) (((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t))
#define HT_DATA_SIZE(nTableSize) ((size_t)(nTableSize) * sizeof(Bucket))
#define HT_SIZE_EX(nTableSize, nTableMask) (HT_DATA_SIZE((nTableSize)) + HT_HASH_SIZE((nTableMask)))
#define HT_SIZE(ht) HT_SIZE_EX((ht)->nTableSize, (ht)->nTableMask)
Bucket *arData;
arData = emalloc(HT_SIZE(ht)); /* теперь разместим это в памяти */
When the macros are executed, we get:
(((size_t)(((ht)->nTableSize)) * sizeof(Bucket)) + (((size_t)(uint32_t)-(int32_t)(((ht)->nTableMask))) * sizeof(uint32_t)))
Wonderful.
Collision Resolution
Now let’s see how collisions are resolved. As you recall, in a hash table, several keys when hashed and compressed may correspond to the same conversion index. So, having received the conversion index, we use it to extract the data back from
arDataand compare the hashes and keys, checking whether this is what is needed. If the data is incorrect, we go through the linked list using the field zval.u2.nextin which the next cell for entering data is displayed. Note that a linked list is not memory-scattered like traditional linked lists. Instead of walking along several memory-mounted pointers received from the heap — and probably scattered across the address space — we read the entire vector from memory
arData.And this is one of the main reasons for increasing the performance of hash tables in PHP 7, as well as the entire language. In PHP 7, hash tables have very high data locality. In most cases, access occurs in 1 nanosecond, since the data is usually located in the processor cache of the first level.
Let's see how you can add elements to the hash, as well as resolve collisions:
idx = ht->nNumUsed++; /* берём номер следующей доступной ячейки */
ht->nNumOfElements++; /* инкрементируем количество элементов */
/* ... */
p = ht->arData + idx; /* получаем от arData bucket в этой ячейке */
p->key = key; /* помечаем ключ для вставки */
/* ... */
p->h = h = ZSTR_H(key); /* сохраняем в bucket хэш текущего ключа */
ZVAL_COPY_VALUE(&p->val, pData); /* копируем значение в значение bucket’а: операция добавления */
nIndex = h | ht->nTableMask; /* получаем индекс таблицы преобразования */
Z_NEXT(p->val) = HT_HASH(ht, nIndex); /* помести следующего из нас как фактический элемент */
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx); /* помести нас в фактическую ячейку преобразования */
Same thing with deleting:
h = zend_string_hash_val(key); /* получаем хэш из строкового ключа */
nIndex = h | ht->nTableMask; /* получаем индекс таблицы преобразования */
idx = HT_HASH(ht, nIndex); /* получаем ячейку, соответствующую индексу преобразования */
while (idx != HT_INVALID_IDX) { /* если есть соответствующая ячейка */
p = HT_HASH_TO_BUCKET(ht, idx); /* получаем bucket из этой ячейки */
if ((p->key == key) || /* это правильный? Тот же указатель ключа? */
(p->h == h && /* ...или тот же хэш */
p->key && /* и ключ (на базе строкового ключа) */
ZSTR_LEN(p->key) == ZSTR_LEN(key) && /* и та же длина ключа */
memcmp(ZSTR_VAL(p->key), ZSTR_VAL(key), ZSTR_LEN(key)) == 0)) { /* и то же содержимое ключа? */
_zend_hash_del_el_ex(ht, idx, p, prev); /* вот они мы! Удаляй нас */
return SUCCESS;
}
prev = p;
idx = Z_NEXT(p->val); /* переместиться к следующей ячейке */
}
return FAILURE;
Conversion Cells and Hash Initialization
HT_INVALID_IDX- a special flag that we put in the conversion table. It means "this transformation does not lead anywhere, it is not necessary to continue." Two-stage initialization provides certain advantages, allowing you to minimize the impact of an empty, just created hash table (a common case in PHP). When creating a table, we simultaneously create bucket cells in
arDataand two transformation cells in which we place the flag HT_INVALID_IDX. Then we impose a mask that directs to the first transformation cell ( HT_INVALID_IDX, there is no data).#define HT_MIN_MASK ((uint32_t) -2)
#define HT_HASH_SIZE(nTableMask) (((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t))
#define HT_SET_DATA_ADDR(ht, ptr) do { (ht)->arData = (Bucket*)(((char*)(ptr)) + HT_HASH_SIZE((ht)->nTableMask)); } while (0)
static const uint32_t uninitialized_bucket[-HT_MIN_MASK] = {HT_INVALID_IDX, HT_INVALID_IDX};
/* hash lazy init */
ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC)
{
/* ... */
ht->nTableSize = zend_hash_check_size(nSize);
ht->nTableMask = HT_MIN_MASK;
HT_SET_DATA_ADDR(ht, &uninitialized_bucket);
ht->nNumUsed = 0;
ht->nNumOfElements = 0;
}
Please note that here you can not use a bunch. The static const memory zone is quite enough, so it is much easier (
uninitialized_bucket). After adding the first element, we completely initialize the hash table. In other words, we create the last necessary transformation cells depending on the requested size (by default it starts with 8 cells). Placement in memory comes from a heap.
(ht)->nTableMask = -(ht)->nTableSize;
HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_PERSISTENT));
memset(&HT_HASH(ht, (ht)->nTableMask), HT_INVALID_IDX, HT_HASH_SIZE((ht)->nTableMask))
The macro
HT_HASHallows you to access the transformation cells in that part of the buffer located in memory for which a negative offset is used. The table mask is always negative because the cells in the conversion table are indexed minus from the beginning of the buffer arData. Here, programming in C is revealed in all its glory: billions of cells are available to you, swim in this infinity, just don’t drown. An example of a lazy-initialized (lazy-initialized) hash table: it has been created, but so far no hash has been placed in it.
Hash Fragmentation, Enlargement, and Compaction
If the hash table is full and you need to add new elements, you have to increase its size. This is a big advantage of hash tables compared to classic hard-limited arrays in C. With each increase, the size of the hash table doubles. I remind you that as the size of the table increases, we pre-allocate the C-array in memory
arBucket, and put special UNDEF values in empty cells. As a result, we vigorously lose memory. Losses are calculated by the formula: (новый размер – старый размер) * размер BucketAll this memory consists of UNDEF cells and waits for data to be placed in it.
For example, you have 1024 cells in a hash table, and you add a new element. The table grows to 2048 cells, of which 1023 are empty. 1023 * 32 bytes = approximately 32 Kb. This is one of the disadvantages of implementing hash tables in PHP.
It must be remembered that a hash table can consist entirely of one UNDEF cells. If you add and remove many elements, the table will be fragmented. But for the sake of preserving the order of the elements, we add everything new only at the end
arData, and do not insert into the resulting spaces. Therefore, a situation may arise when we get to the end arData, although there are still UNDEF cells in it. An example of a highly fragmented 8-cell hash table:
As you may recall, new values cannot be stored in UNDEF cells. In the above scheme, when iterating a hash table, we go from
arData[0]to arData[7]. By increasing the size, you can reduce the vector
arDataand finally fill in the empty cells simply by redistributing the data. When a table is given a command to resize, it first tries to compact itself. Then it calculates whether it will have to increase again after compaction. And if it turns out that yes, then the table doubles. After this, the vector arDatabegins to occupy twice as much memory (realloc()). If it is not necessary to increase, then the data is simply redistributed in the cells already located in memory. Here we use an algorithm that we cannot use every time we delete elements, since it too often spends processor resources, and the exhaust is not so large. Do you remember the famous programmer's compromise between processor and memory?This illustration shows the previous fragmented hash table after compaction:
The algorithm scans
arDataand populates each UNDEF cell with data from the next nonUNDEF cell. Simplified, it looks like this:Bucket *p;
uint32_t nIndex, i;
HT_HASH_RESET(ht);
i = 0;
p = ht->arData;
do {
if (UNEXPECTED(Z_TYPE(p->val) == IS_UNDEF)) {
uint32_t j = i;
Bucket *q = p;
while (++i < ht->nNumUsed) {
p++;
if (EXPECTED(Z_TYPE_INFO(p->val) != IS_UNDEF)) {
ZVAL_COPY_VALUE(&q->val, &p->val);
q->h = p->h;
nIndex = q->h | ht->nTableMask;
q->key = p->key;
Z_NEXT(q->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(j);
if (UNEXPECTED(ht->nInternalPointer == i)) {
ht->nInternalPointer = j;
}
q++;
j++;
}
}
ht->nNumUsed = j;
break;
}
nIndex = p->h | ht->nTableMask;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(i);
p++;
} while (++i < ht->nNumUsed);
Hash Table API
Well, now we know the main points of implementing a hash table in PHP 7. Let's now look at its public API.
There is nothing to talk about (well, in PHP 5 the API is much better). Just when using the API function, do not forget about three things:
- About your operation (adding, deleting, cleaning, destroying, etc.).
- About the type of your key (integer or lowercase).
- About the type of data you want to store.
Whatever your key, lowercase or integer, the main thing: the API should be aware that lowercase keys get hashes from
zend_string, and integer keys are immediately used as a hash. Therefore, you can meet zend_hash_add(ht, zend_string, data)or zend_hash_index_add(ht, long, data). Sometimes a key can be a simple pair (char * / int). In this case, you need to use a different API, for example
zend_hash_str_add(ht, char *, int, data). Remember that, be that as it may, the hash table will turn to zend_string, turning your string key into it and calculating its hash, spending some amount of processor resources. If you can use zend_string, use. Surely they have already calculated their hashes, so the API will just take them. For example, the PHP compiler calculates the hash of each part of the string used, aszend_string. OPCache stores a similar hash in shared memory. As the author of extensions, I recommend initializing all your literals in MINIT zend_string. Now about the data that you are going to store in the hash table. Again, it could be anything, the hash table will still put the data
zvalin each one Bucket. In PHP 7, zval's can store any kind of data. In general, the hash table API expects you to pack the data in zval, which the API perceives as a value. The situation can be somewhat simplified if you have a pointer to the storage or memory area (data referenced by the pointer). Then the API will place this pointer or memory area in zval, and then zval itself will use the pointer as data.
Examples will help to understand the idea:
zend_hash_str_add_mem(hashtable *, char *, size_t, void *)
zend_hash_index_del(hashtable *, zend_ulong)
zend_hash_update_ptr(hashtable *, zend_string *, void *)
zend_hash_index_add_empty_element(hashtable *, zend_ulong)
When retrieving the data, you will get either zval * or NULL. If a pointer is used as the value, the API can return as is:
zend_hash_index_find(hashtable *, zend_string *) : zval *
zend_hash_find_ptr(hashtable *, zend_string *) : void *
zend_hash_index_find(hashtable *, zend_ulong) : zval *
As for the _new API like
zend_hash_add_new(), it's better not to use it. It uses the engine for internal needs. This API forces the hash table to store data, even if it is already available in the hash (same key). As a result, you will have duplicates, which may not affect the work in the best way. So you can use this API only if you are completely sure that there is no data in the hash that you are going to add. Thus, you will avoid the need to look for them. Finally: as in PHP 5, the API
zend_symtable_api()takes care of converting the text writing of numbers directly to numeric:static zend_always_inline zval *zend_symtable_update(HashTable *ht, zend_string *key, zval *pData)
{
zend_ulong idx;
if (ZEND_HANDLE_NUMERIC(key, idx)) { /* handle numeric key */
return zend_hash_index_update(ht, idx, pData);
} else {
return zend_hash_update(ht, key, pData);
}
}
You can use many macros for iterations depending on what data you want to get in the loop: key, zval ... All these macros are based on
ZEND_HASH_FOREACH:#define ZEND_HASH_FOREACH(_ht, indirect) do { \
Bucket *_p = (_ht)->arData; \
Bucket *_end = _p + (_ht)->nNumUsed; \
for (; _p != _end; _p++) { \
zval *_z = &_p->val; \
if (indirect && Z_TYPE_P(_z) == IS_INDIRECT) { \
_z = Z_INDIRECT_P(_z); \
} \
if (UNEXPECTED(Z_TYPE_P(_z) == IS_UNDEF)) continue;
#define ZEND_HASH_FOREACH_END() \
} \
} while (0)
Packed Hash Table Optimization
So, remember the critically important rule: we add data in
arDataascending order, from zero to the end, and then form a vector arData. This allows you to easily and cheaply iterate the hash table: just iterate the C-array arData. Since a string or an out-of-order integer value can be used as a key of a hash table, we need a conversion table to be able to analyze the hash. But in one case, such tables are useless: if the user uses only integer keys and only in ascending order. Then, when viewing
arDatafrom beginning to end, we will receive the data in the same order in which they were placed. And since in this case the conversion table is useless, then it is possible not to place it in memory.This optimization is called a “packed hashtable”:
As you can see, all keys are integer and placed simply in ascending order. When iterating
arData[0]from the very beginning, we will get the elements in the correct order. So the conversion table has been reduced to just two cells, 2 * uint32 = 8 bytes. No more conversion cells are needed. It sounds strange, but with these two cells, the performance is higher than without them at all. I must warn you: if you break the rule by, say, inserting a lowercase key (after hashing / compression), then the packed hash table must be converted to the classic one. With the creation of all the necessary transformation cells and the reorganization of bucket'ov.
ZEND_API void ZEND_FASTCALL zend_hash_packed_to_hash(HashTable *ht)
{
void *new_data, *old_data = HT_GET_DATA_ADDR(ht);
Bucket *old_buckets = ht->arData;
ht->u.flags &= ~HASH_FLAG_PACKED;
new_data = pemalloc(HT_SIZE_EX(ht->nTableSize, -ht->nTableSize), (ht)->u.flags & HASH_FLAG_PERSISTENT);
ht->nTableMask = -ht->nTableSize;
HT_SET_DATA_ADDR(ht, new_data);
memcpy(ht->arData, old_buckets, sizeof(Bucket) * ht->nNumUsed);
pefree(old_data, (ht)->u.flags & HASH_FLAG_PERSISTENT);
zend_hash_rehash(ht);
}
A hash table is
u.flagsused to determine if the main hash table is packed. If so, then its behavior will be different from the behavior of a traditional hash table, it will not need conversion cells. In the source code, you can find a lot of places when packed and classic hashes go along different branches of the code. For instance:static zend_always_inline zval *_zend_hash_index_add_or_update_i(HashTable *ht, zend_ulong h, zval *pData, uint32_t flag ZEND_FILE_LINE_DC)
{
uint32_t nIndex;
uint32_t idx;
Bucket *p;
/* ... */
if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) {
CHECK_INIT(ht, h < ht->nTableSize);
if (h < ht->nTableSize) {
p = ht->arData + h;
goto add_to_packed;
}
goto add_to_hash;
} else if (ht->u.flags & HASH_FLAG_PACKED) {
/* ... */
} else if (EXPECTED(h < ht->nTableSize)) {
p = ht->arData + h;
} else if ((h >> 1) < ht->nTableSize &&
(ht->nTableSize >> 1) < ht->nNumOfElements) {
zend_hash_packed_grow(ht);
p = ht->arData + h;
} else {
goto convert_to_hash;
}
/* ... */
To summarize: packed hash tables can optimize the use of both memory and processor.
- Memory: the difference in the byte consumption compared to classic:
(размер_таблицы - 2) * размер(uint32). If you have thousands of cells, then the bill goes to kilobytes. - Processor: with each operation, we do not need to check the conversion cells and perform the conversion. This saves several processor instructions for each operation, which translates into milliseconds when working with an actively used array.
Nevertheless, if you start using lowercase keys or violate the sort order of integer keys (say, insert 42 after 60), then the hash table will have to be converted to “classic”. You will spend a little processor resources on this (on large arrays - a bit more) and additional memory. To create a packed hash table, just say the API:
void ZEND_FASTCALL zend_hash_real_init(HashTable *ht, zend_bool packed)
Keep in mind that this
zend_hash_real_init()is a complete initialization step, not a lazy one ( zend_hash_init()). Usually, if initialization is "lazy", then the hash table is initially packed. And when appropriate circumstances arise, it is converted into a classic hash.Arrays in PHP
Let's see how you can verify the hash table implementation details within custom code.
Hash table memory and optimized packed arrays
First, we will demonstrate the optimization of packed arrays (packed array):
function m()
{
printf("%d\n", memory_get_usage());
}
$a = range(1,20000); /* range() создаёт упакованный массив */
m();
for($i=0; $i<5000; $i++) {
/* Продолжаем добавлять ключи в порядке возрастания,
* поэтому контракт упакованного массива всё ещё действителен:
* мы остаёмся в «упакованном» режиме */
$a[] = $i;
}
m();
/* Мы неожиданно нарушили контракт упакованного массива и заставили
* хэш-таблицу превратиться в «классическую», потратив больше
* памяти на ячейки преобразования */
$a['foo'] = 'bar';
m();
As expected, memory consumption results:
1406744
1406776
1533752
When moving from a packed array to a classic hash, memory consumption increased by about 130 Kb (for an array with 25,000 elements).
Now we demonstrate the operation of the compression or enlargement algorithm:
function m()
{
printf("%d\n", memory_get_usage());
}
/* Размер хэш-таблицы соответствует двойке в степени. Давайте создадим
* массив из 32 768 ячеек (2^15). Используем упакованный массив */
for ($i=0; $i<32768; $i++) {
$a[$i] = $i;
}
m();
/* Теперь очистим его */
for ($i=0; $i<32768; $i++) {
unset($a[$i]);
}
m();
/* Добавим один элемент. Размер хэш-таблицы превысит предел,
* что запустит работу алгоритма уплотнения или увеличения */
$a[] = 42;
m();
Results:
1406864
1406896
1533872
When the table is full and we empty it, the consumed memory does not change (modulo noise). After applying
unset()to each value, our table will have arData32,768 cells filled with UNDEF-zvals. Now add something as the next item . Remember
nNumUsed, which is used for addressing arDataand increasing with each addition? Now it will overflow the size of the table, and it will be necessary to decide whether to compact it or increase the size. Is compaction possible?
The answer seems obvious - yes, because we have solid UNDEF cells here. But actually not: we need to keep data in order because we use a packed arrayand we wouldn’t like it to turn into a classic until we completely hide it. If we add an element to an existing cell, we will break the sequence, which will start the compaction procedure, and not increase the size.
/* Код тот же, что и выше, но: */
/* здесь мы добавляем ещё один элемент к известному индексу (idx).
* Размер хэша переполнится, запустится алгоритм уплотнения или увеличения */
$a[3] = 42;
m();
Memory usage:
1406864
1406896
1406896
See the difference? Now the algorithm did not increase our table from 32,768 to 65,538 cells, but compacted it. The table in memory still has 32,767 cells. And since the cell is
Bucket, inside which is located zval, whose size is equal long(in our case 42), the memory does not change. After all, zval already includes the size long. :) Therefore, now we can reuse these 32,768 cells by placing integer, boolean, floating point values in them. And if we use strings, objects, other arrays, etc. as values, then additional memory will be allocated, a pointer to which will be stored in previously stored UNDEF-zval's in our “hot” array. We can do the same with the classichash table just using lowercase keys. When we overfill it with one element, the table will be compacted, but not increased, because there is no need to maintain order. In any case, we are in "unpacked" mode, we just add one more value to the leftmost position (
idx 0), and all subsequent ones are UNDEF-zval.function m()
{
printf("%d\n", memory_get_usage());
}
/* Размер хэш-таблицы соответствует двойке в степени. Давайте создадим
* массив из 32 768 ячеек (2^15). Здесь мы НЕ используем упакованный массив */
for ($i=0; $i<32768; $i++) {
/* возьмём строковый ключ, чтобы у нас был классический хэш */
$a[' ' . $i] = $i;
}
m();
/* теперь очистим его */
for ($i=0; $i<32768; $i++) {
unset($a[' ' . $i]);
}
m();
/* здесь мы добавляем ещё один элемент к известному индексу.
* Размер хэша переполнится, запустится алгоритм уплотнения или увеличения */
$a[] = 42;
m();
Memory Results:
2582480
1533936
1533936
As expected. The array consumes about 2.5 MB. After applying
unset()to all values, memory consumption decreases, we free the keys. We have 32,768 keys zend_string, and after their release, the array begins to consume 1.5 MB. If one element is now added, then the internal size of the table will overflow, which will start the algorithm of compaction or increase. Since the array is not packed, it is not necessary to maintain the order of the elements, and the table will be compacted. The new value 42 is written in idx 0, the amount of memory does not change. The end of the story.
As you can see, in some rare cases, packed hash tables can even harm us, increasing in size instead of compaction. But will you really use such stupid code in real projects? This should not affect everyday programming, but if you need really high performance (frameworks, can you hear me?) And / or you want to optimize highly loaded batch scripts, then this can be a good solution. Instead of puzzling over the transition to pure C in solving such problems. If you do not have many thousands of elements, then memory consumption will be ridiculous. But in our examples there were “only” from 20 to 32 thousand elements, and the difference was measured in kilobytes and megabytes.
Immutable arrays
Immutable arrays are a feature of OPCache. Without enabling OPCache, you cannot take advantage of immutable arrays, i.e., read-only ones. If OPCache is activated, then it looks at the contents of each script and tries to copy many things into shared memory. In particular, constant AST nodes. Actually, a constant array is a constant AST node. For instance:
$a = ['foo', 1, 'bar'];
Here
$ais a constant AST node. The compiler determines that it is an array filled with constants, and turns it into a constant node. Next, OPCache scans all the scripts in the AST node, copies their address associated with the process (heap address) to the shared memory segment, and then frees this address. You can find more information about OPCache in an overview of this extension . In addition, OPCache turns arrays into immutable ones by setting the IS_ARRAY_IMMUTABLE and IS_TYPE_IMMUTABLE flags for them . When the engine meets IS_IMMUTABLE, he treats this data in a special way. If you convert an immutable array to a variable, then it will not be duplicated. Otherwise, a full copy of the array is created.
An example of the described optimization:
$ar = [];
for ($i = 0; $i < 1000000; ++$i) {
$ar[] = [1, 2, 3, 4, 5, 6, 7, 8];
}
This script consumes about 400 MB of memory without OPCache, and with it about 35 MB. If OPCache is disabled, then in the script the engine creates a full copy of the 8-element array in each slot
$ar. As a result, one million 8-slot arrays are stored in memory. And if you enable OPCache, it will mark the 8-slot array as IS_IMMUTABLE and when you run the script, $aronly the array pointer will be copied to the slots , which prevents full duplication in each cycle. Obviously, if you later change one of these arrays, say
$ar[42][3] = 'foo';, then the 8-slot array in $ar[42]will be fully duplicated by the copy-write mechanism.In the internal hash tables, another, almost random optimization was made. As you may recall, PHP arrays are just a special case of Zend hash tables. Since you can manipulate them with PHP, you can imagine a way to use it. But hash tables are used throughout the engine. For example, any script may contain functions and / or classes. These two large schemes are stored in two hash tables. The compiler converts the script into the so-called OPArray and attaches the function table (it may be empty) and the class table (it may also be empty) to it. When PHP completes the current request, it clears this OPArray: destroys the function and class tables. But with OPCache enabled, both of these arrays also become IMMUTABLE, and as a result, the engine cannot destroy them. As soon as the next request appears, they will be immediately loaded from the shared memory and will request the exact same script.
OPCache strictly once stores these tables in memory, preventing them from being destroyed. Destruction itself can take a lot of time, because it is recursive and involves the destruction of numerous pointers (the more classes and functions you have, the longer it is). Consequently, immutable hash tables also allow OPCache to speed up the closing procedure performed by the engine, the current PHP process will complete faster and the next request will proceed. All this improves the overall performance of PHP.
But don't let immutable arrays confuse you. For example, at the moment, such a scenario has no optimization:
$a = [1];
$b = [1];
Here two arrays are created in memory. And there is no process like that used for interned strings , when the engine tracks every part of the used string so that it can be used again if necessary. Immutable arrays are arrays filled with immutable types (no variables, no function calls, everything is solved at compile time) that are not duplicated in memory when moving from one place to another during PHP runtime. Also, these types are never destroyed in memory (from one request to another). In addition, immutable arrays are only used when the OPCache extension is activated.