The logic of building universal work schedules
Employee work schedules are an integral part of any CRM system. But depending on the specifics of the client’s business, they can be very different. In the clinic, these are patient admission schedules, in telecom - customer connection schedules, at school - training schedules. They all differ in structure and substance. They have different caps, a different set of fields, different grids.
Our ERP Platform is focused on the rapid development of any niche configuration and we thought about how to do it all conveniently. First of all for myself. To our work on the development of graphics for a specific niche took no more than man-hours.
Before that, the graphics were some kind of thing developed in php. But god! Charles! Every time you need a new schedule for a niche solution, you need to copy this code, recycle. The individuality of the graphs did not allow something to change centrally. And in general, undermined the concept of our cloud platform in that the client can configure it independently.
As a result, we have formed the following requirements for work schedules
We believe that we have succeeded in quite gracefully realizing these requirements and in this article we will describe how this was done.
At the moment, I don’t know systems with graphs of similar universality (if you know, write in the comments, it’s interesting to see)
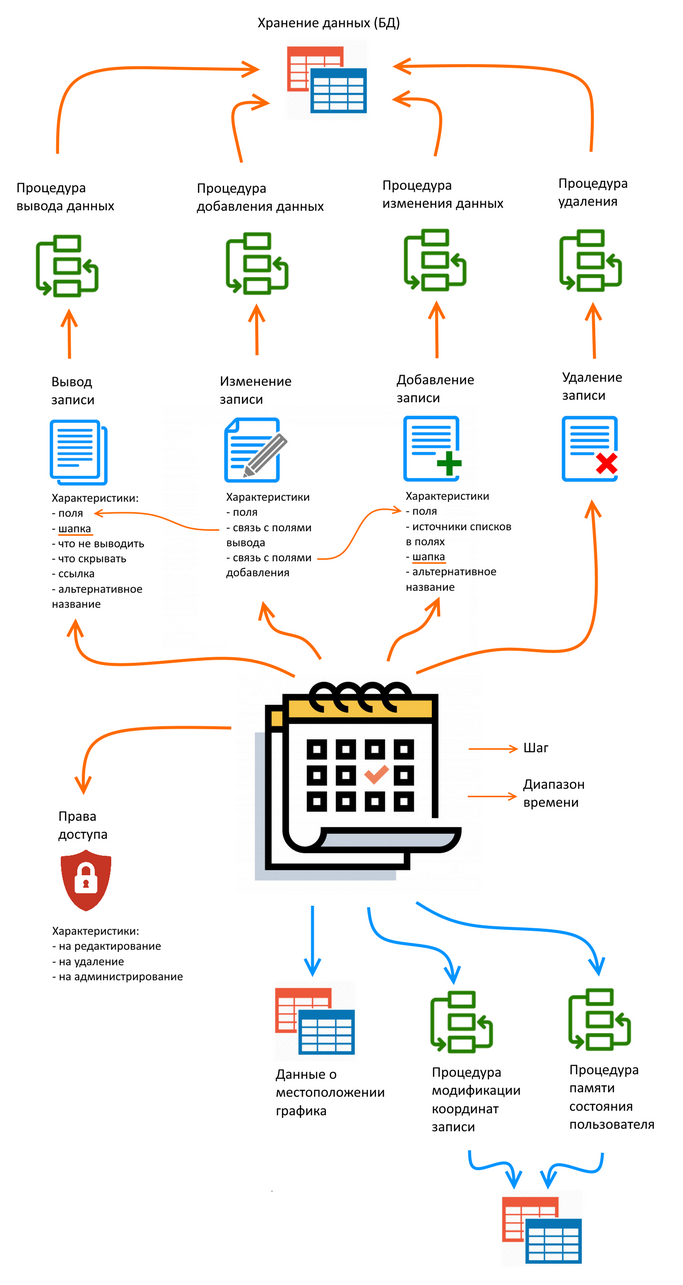
The general scheme for configuring the graph looks like this (do not judge strictly, you drew it yourself). Every element is needed, there is no excess.
All work begins with understanding what data set should be in the record and creating a table in the database under this schedule.

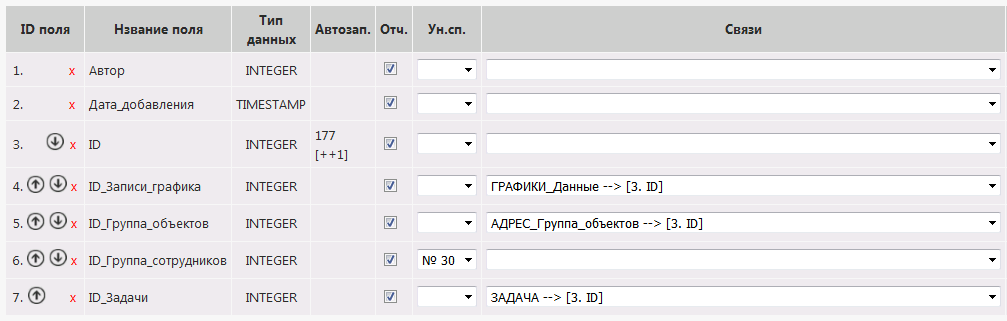
For example, for the schedule of work on the tasks in the telecom company, it is important to know when the work will be done, on what task, on what facility, and what group of engineers will do this work.
Therefore, we form a table where there is all this info + service fields with the ID of the schedule entry. (PS: we can edit the tables directly in the cloud from the browser).
This is a simple case, but it can be much more complicated, where there are more fields or several tables.
That's all, the storage structure has been formed and now the graphics need to know how to work with it. Each entry can be added, displayed, changed and deleted.
Because the data set and storage structure can be arbitrary, then it is necessary to work with this structure through a stored procedure.
First you need to create a procedure. In our example, the case is simple, and you can create them in the configurator with one button using the “Create standard procedures” function. The system itself on this table will create procedures for making, modifying, deleting, and various conclusions.
For example, a fragment of an automatically created add procedure looks like this:
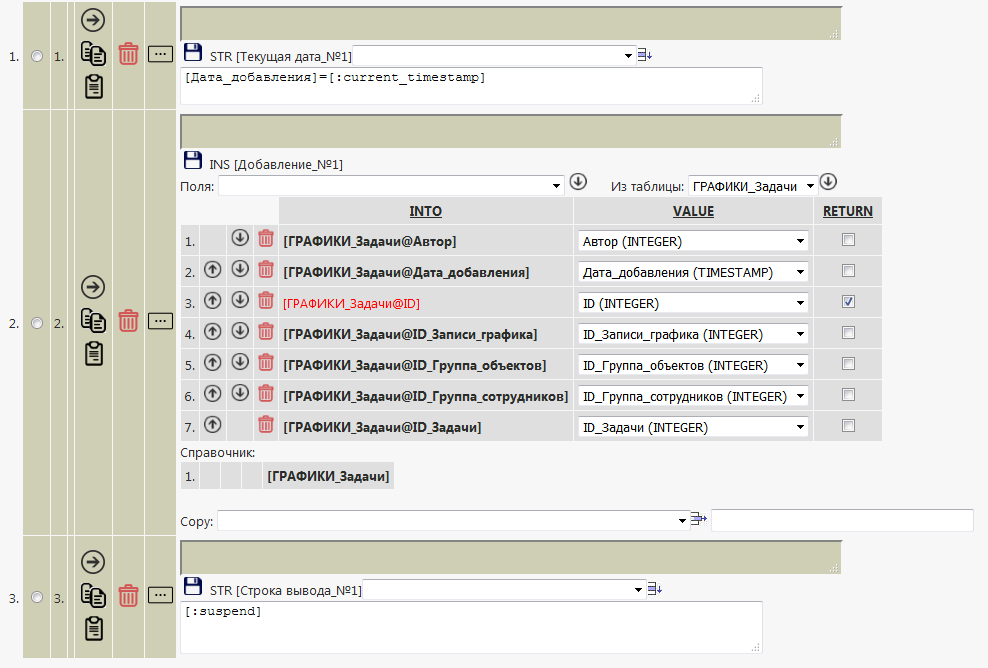
All procedures are edited directly from the web interface. The compilation logic is similar to PL-SQL.
The schedule in each action indicates which procedure is responsible for this action.
“Stitched” graphics settings
But still there are “stitched” settings that you can only customize, but not change the structure. This is simply not necessary.
- Date-time coordinates are an integral property of any record.
- The location of the schedule in the system. It is edited by means of the built-in interface editor and there is no need to do this from the graph itself.
- The memory of where the user was - no need to directly configure this property.

In the settings you can also set the Step (for example, the grid in 20 minutes, or in 30) and the working time range (for example, from 8 to 20).
The time range is needed to cut off unnecessary, for example, if all employees work an 8-hour standard working day, then it makes no sense to display the night hours.
Step - defines the schedule grid. For example, in one clinic there may be a doctor’s appointment schedule for 20 minutes, in another 15, in the third 30. This is all set up.
However, this does not mean that the recording can not be done outside the grid. You can make any records, but they will be displayed within the grid.
The step range can be set for 5, 10, 15, 30, 60 minutes.
Write a record
to create and specify a procedure. It is necessary for the schedule to understand how to work with it.

Cap
The most important thing is to specify the header of the chart. Which of the output fields of the procedure should be a header.
Consider the logic of building a class schedule in an educational organization. Suppose there is a teacher-group entry in the record.
Here you can make a heading for the Teachers, then the schedule will be formed as follows:
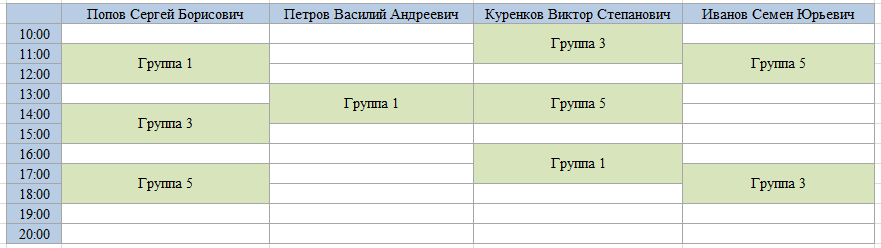
or you can by Groups, then this way:
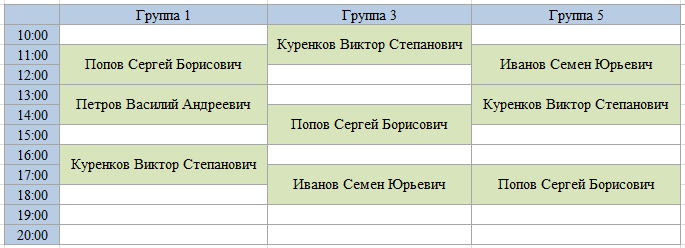
or you can even make 2 different schedules and display them, and so, as you like, the users will choose. The same data and the same procedures will be used. Changes in one chart will change in another.
But in general, the choice depends on the issues of expediency. The cap should be a fundamental little changing information. If you serve a fixed number of objects, then it should be them. If you have a fixed number of groups, then they are.
With a hat, you can create generally interesting things. For example, if you specify the task status as a header, then when the status in the task changes, the task record in the schedule will jump by itself to the corresponding status. Those. in fact almost kanban boards can be made here, etc. things. When we attach these records to the live information in the system through the procedures, it can also come to life in the charts. Very flexible mechanism.
Also, if you specify filtering conditions in the procedure, you can create these caps in the graph with arbitrary filters taken into account.
What not to display
You can also specify what to display in the record, and what is not. For example, in the procedure, some service identifiers for bundles can be displayed as results. This information that is not relevant to the user can be ignored in the output.
What to hide
And you can display, but turn under the cat. Information that is not very important, but sometimes needed. For example, who created this entry and when, may be needed only in case of some sorting out, but not in operational work.
Links
It is also very convenient when a field can be a link.
For example, if we make a schedule for tasks, why not click on its number to get into the task itself.
We have a standard link building mechanism in the configurator. You can make them there, and associate with the field in the graph. Everything is working.
Name
Of course, the field should somehow be called. By default, the system will take the name from the procedure field, but it is not always correct for perception. Therefore, sometimes you need to enter alternative names.
For example, all of the above we have is. Opposite to the fields of the specified procedure, check marks are placed.
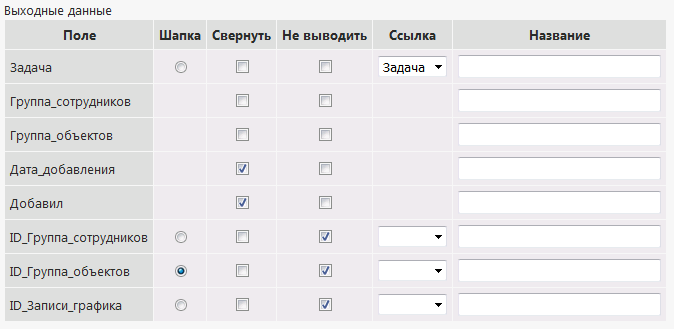
The output of the record will look like this:
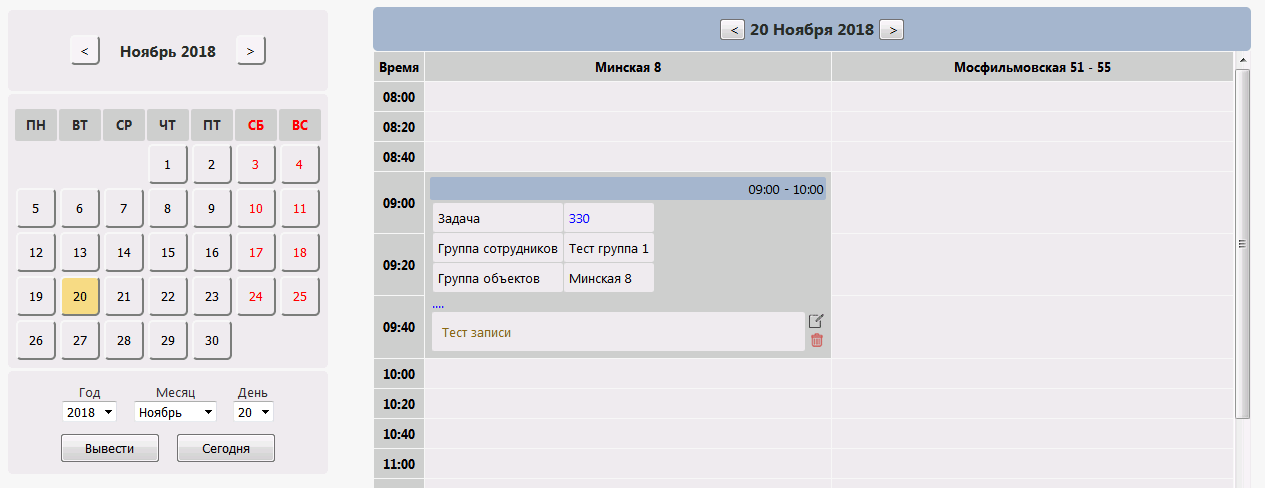
Adding a new record The
fields for adding a new record should be determined by the procedure for adding. Each input parameter of the procedure must be submitted information.
But there is a trick. Fields can be not only text, but also lists.
Take our example for telecom, where there is a task, a group, an object. We will not force the user to search for object identifiers and drive them in. It is necessary that there was a pop-up list with the necessary information. And where can I get it?
To do this, the input field of the procedure should pull another procedure, which will give for example a list of actual tasks, or a list of necessary objects, etc. At the same time, it is impossible to simply indicate the fields of a table, since There may be complex filters. The same tasks may already be 10,000 in the system, stamped, but it is necessary to display a list of the 100 current ones now.
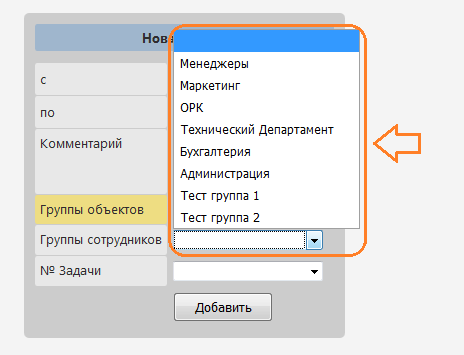
In general, a procedure that twitches across a field of another procedure.
Actually it just sounds scary. These things are well automated, procedures for standard directories are obtained with one button. Procedures for all sorts of lists of groups, tasks, applications, etc. long ago implemented to work all kinds of CRM modules. They just need to choose. If there is already a procedure with similar functionality, it is copied and edited.
You also need to specify which of the added fields will be a header. This is what we need in the editing system.
It looks like this for us:
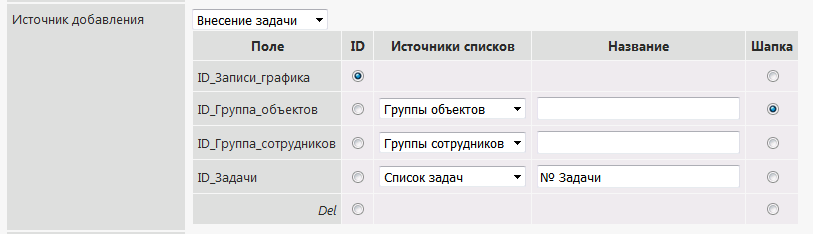
Editing a record
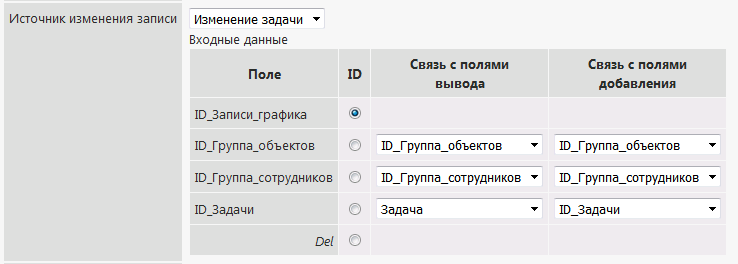
It’s still more interesting. It is not enough to display all the field lists as in the appendix. It is necessary to select the current positions (selected) in these lists. We are editing.
To do this, you must associate the creation fields with output fields. And in the case of a list field, it’s not just a bang from the output, but to know the identifier of this information.
Those. here it is necessary:
a) to specify the editing procedure
b) to associate its fields with the addition fields
c) to associate its fields with the data output fields of the record, in order to put the current data in the lists It is
not necessary to indicate any other features here, because we already have configured Output and Addition.
When the editing window is displayed, the system will automatically call the required procedure for each field, receive data, compare it with the data from the output of the record, insert the selected values in the lists, and insert the current values in simple fields.
It looks at us so
Deleting records
Removal is the easiest. Simply specify the deletion procedure with one input parameter: the ID of the schedule entry.
Event handling when adding / modifying / deleting records. Triggers. Cross Records.
Only add / modify entries in the graphs a little. Need to still manage events. This opens up unlimited room for configuration.
Managing events is actually very simple. We already have the tables in which the data of the schedule records are stored. On these tables, you can put any on the complexity of the triggers. Our cloud configurator makes it easy to do this.
For example, you need logs, who did what in the record. It's simple. A table is created for the logs, and a trigger is put on the chart table, which writes these modifications to the table with logs.
Also thanks to this cross-records are available. For example, when in our example the task is put in a group, you can define all the participants of this group and double them of this record in personal schedules. To put in personal charts in this case means to make an entry in the personal chart data table. It is also a graph in this system, only configured differently and moved to another location. This entry will appear in it.
Or you need to send a notification to group users. Or send a client a text message that they will come to work on such and such a task then. To do this, simply make the trigger, which make entries in the table of notifications or SMS.
Reports Graph
reports are also needed, and with such a structure they can be made.
For example, it took to make a report on how much time employees were on the road in the previous month. We go to the report configurator, select the desired table where the schedule records are stored, set the necessary filters and aggregation functions - and wahl, the report is ready.
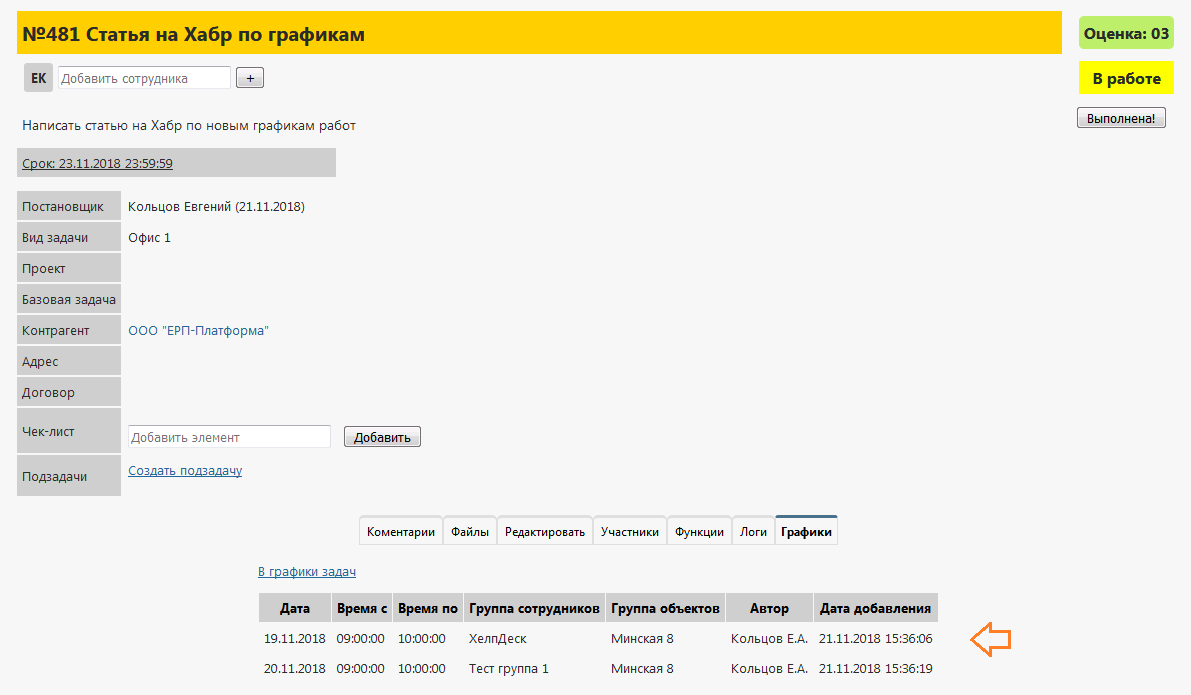
Other uses of chart data Graph
data can be used anywhere with an advanced system configurator. For example, in tasks we easily managed to make the Charts tab and in one simple procedure output information, for how long and who has this task for execution.
Lining time
They happen. And there is nothing worse looking than writing over each other and not giving to read the desired entry. This problem is also solved. System intersecting records automatically places nearby. In this case, only simple html is used, just the structure of the table is built in the way necessary for this. The system provides care at any depth, but more than 2 records are rare.
Of course, if time overlaps, most likely something is not so planned. A person cannot be in two places at the same time, but even such situations need to be displayed correctly.

Access and Security
Access is divided into 2 levels. System and Personal graphics. The system is defined as a whole by the Roles editor and the default permissions set in the interface configurator. For example, if a given cell of the page (or inherited above, tabs, pages, menus) is denied access to reading, then no users will see this graphic at the interface display level until users assign read access rights to this area in User Roles.
Next come the internal rights of the schedule. They can be
1) Editing
- only author
- only the group of the author (all employees included in the groups in which the author
is a member ) - only a division of the author (all employees included in the division of the author, according to staff)
2) Removal is similar.
- only author
- only group
- only division
What are internal rights for?
If this is a personal schedule, or there are some features, then it makes sense to put only the author.
But there are shift personnel and situations where the record needs to be edited, and the employee is not at work. What to do? It makes sense for such schedules to put editing by a group or division so that other shift workers can work with these records.
Also in the schedule can be specified Role, which has the right to administer. Employees with this Role will have rights to edit and delete, regardless of groups and divisions.
Here we have such a cool thing that makes life very simple when you can juzat it, of course. Just an inexperienced person may be difficult to understand. But we have such a schedule in an uncomplicated way, it is about a man-hour.
In addition, we still get the deepest configuration capabilities and the ability to interact with other elements of the system.
Our ERP Platform is focused on the rapid development of any niche configuration and we thought about how to do it all conveniently. First of all for myself. To our work on the development of graphics for a specific niche took no more than man-hours.
Before that, the graphics were some kind of thing developed in php. But god! Charles! Every time you need a new schedule for a niche solution, you need to copy this code, recycle. The individuality of the graphs did not allow something to change centrally. And in general, undermined the concept of our cloud platform in that the client can configure it independently.
As a result, we have formed the following requirements for work schedules
- Configurability
They must be fully configured from the web interface. - Variable pitch
They must have a variable grid pitch.
In one clinic, the doctor's reception grid may be 30 minutes per patient, and in the other 20, at the third hour - Arbitrary cap
graphics cap may be unique, i.e. it may be a set of doctors, facilities, teachers, teams, etc. In general, anything from the fact that the client has in the system. Even from what we can not assume. - In a graph record, an arbitrary set of fields.
A set of fields can be set arbitrarily, from any information that is in the system. And the records are arranged in accordance with the header. - CRUD
Graphics records must be CRUD (create, read, update, delete), despite arbitrary sets of fields. And not just this, but using procedures to organize complex interactions.Example: there is a schedule of tasks.
The schedule entry shows who performs, where the work is done, etc. + some data on the task (for example, its number and name).
Additional data on the schedule record is stored in one table, and task data in another.
When creating, the task number is indicated, who performs it and where. And the data will be displayed from two tables.
You can edit only the data of the schedule record, but not the task data.
The schedule entry should be deleted, but not the task.
We need to keep logs that someone did with this record. Because it can be removed and will not necessarily be visible in the graph, then somehow you need to get to the logs. It is more logical to lead them in the task itself, i.e. when creating, modifying, deleting, it should be written in a separate table and displayed in the task.
Such things can be solved only by stored procedures, so that simple and complex situations can be solved. - Fields can be lists.
Of course, fields should not be text only. They can be pop-up lists from some data in the system. - Fields can be links.
It is convenient when, for example, you can get into the task itself from the task schedule. - Hiding Fields
If there are many fields in a record, it makes sense to minimize some of them for convenience of perception. - Triggers
It is necessary to configure the system response to what is happening with the record. The most convenient way to do this is with triggers.For example, if a user needs to write some logs about actions on a record, or send notifications to employees, or even send an sms client or even do something that we cannot assume.
- Cross Records
Cross Records are records from different graphs combined into a single graph. Or the appearance of records in other graphs, when records appear in the current one.For example, there are such situations that the same teams perform work, for example, on applications and on tasks. Those. it will be convenient for them to have a general schedule where tasks from different schedules will be displayed.
Or you need a personal schedule of the employee, with records from all schedules where he participates.
Such tasks are a bit more complicated than typical ones, but they are completely solved with the help of triggers and data acquisition procedures. Those. by p.9 and p.5.
a) a trigger is created on the records of the required graphs, which create an entry in the user's personal graph in case the user is there (respectively, in the case of a change, they are deleted, in the case of deletion)
b) additional fields are created in the user graph, which will include the necessary data, as well as the procedures for outputting the records, which will pull up data from the tables of other graphs using these identifiers.
Such tasks can also be solved in the opposite way; when forming a personal schedule of a workplace, a more tricky procedure is made that will output data not only from personal tables, but from tables of other schedules where an employee is present in the data of the day. Such solutions based on this design are also possible. - Overlays of time
The system should correctly display the intersections of records in time, and not like most systems, where the records run over each other and there is not even the ability to read the lower layers.Like this, it's sad ...
- Reports
That according to the schedule it was possible to build reports. The storage system must be organized so that it can be hooked up in the report configurator.For example, it took to create a report on which of the staff spent much time traveling on tasks — voila! We go to the report configurator, there we select the table where the data of the records of the desired schedule are stored and make the report using the standard configurator according to the data from the schedule.
Embeddability The graph should be able to easily be embedded anywhere on any page - i.e. it must be a standard input element, the same as a text field, or a button.
Fortunately, we had experience in developing complex standard elements. In particular, we have a standard comment element, file application form, contact form, table. All of them are added with one click as usual elements and are configured without any problems.- Access and security
The access rights to the schedule as a whole should be regulated by the general system of rights, and within the schedule the access rights to the records should be governed by the schedule settings.For example, specify that only the author can edit his post, or his group, or division.
- Easy configuration
And of course, creating and configuring a new schedule should be done quickly and not cause any problems. In particular, for us, for a typical case (it is clear that it happens of course and very difficult), this work should take no more than man-hours.
We believe that we have succeeded in quite gracefully realizing these requirements and in this article we will describe how this was done.
At the moment, I don’t know systems with graphs of similar universality (if you know, write in the comments, it’s interesting to see)
The general scheme for configuring the graph looks like this (do not judge strictly, you drew it yourself). Every element is needed, there is no excess.
All work begins with understanding what data set should be in the record and creating a table in the database under this schedule.
For example, for the schedule of work on the tasks in the telecom company, it is important to know when the work will be done, on what task, on what facility, and what group of engineers will do this work.
Therefore, we form a table where there is all this info + service fields with the ID of the schedule entry. (PS: we can edit the tables directly in the cloud from the browser).
This is a simple case, but it can be much more complicated, where there are more fields or several tables.
That's all, the storage structure has been formed and now the graphics need to know how to work with it. Each entry can be added, displayed, changed and deleted.
Because the data set and storage structure can be arbitrary, then it is necessary to work with this structure through a stored procedure.
First you need to create a procedure. In our example, the case is simple, and you can create them in the configurator with one button using the “Create standard procedures” function. The system itself on this table will create procedures for making, modifying, deleting, and various conclusions.
For example, a fragment of an automatically created add procedure looks like this:
All procedures are edited directly from the web interface. The compilation logic is similar to PL-SQL.
If something is complicated, then these procedures can be edited depending on the storage structure and you can specify various conditions, loops, select, update, insert, etc. In general, draw any processing structure.
The schedule in each action indicates which procedure is responsible for this action.
“Stitched” graphics settings
But still there are “stitched” settings that you can only customize, but not change the structure. This is simply not necessary.
- Date-time coordinates are an integral property of any record.
- The location of the schedule in the system. It is edited by means of the built-in interface editor and there is no need to do this from the graph itself.
- The memory of where the user was - no need to directly configure this property.
In the settings you can also set the Step (for example, the grid in 20 minutes, or in 30) and the working time range (for example, from 8 to 20).
The time range is needed to cut off unnecessary, for example, if all employees work an 8-hour standard working day, then it makes no sense to display the night hours.
Step - defines the schedule grid. For example, in one clinic there may be a doctor’s appointment schedule for 20 minutes, in another 15, in the third 30. This is all set up.
However, this does not mean that the recording can not be done outside the grid. You can make any records, but they will be displayed within the grid.
The step range can be set for 5, 10, 15, 30, 60 minutes.
Write a record
to create and specify a procedure. It is necessary for the schedule to understand how to work with it.
Cap
The most important thing is to specify the header of the chart. Which of the output fields of the procedure should be a header.
Consider the logic of building a class schedule in an educational organization. Suppose there is a teacher-group entry in the record.
Here you can make a heading for the Teachers, then the schedule will be formed as follows:
or you can by Groups, then this way:
or you can even make 2 different schedules and display them, and so, as you like, the users will choose. The same data and the same procedures will be used. Changes in one chart will change in another.
But in general, the choice depends on the issues of expediency. The cap should be a fundamental little changing information. If you serve a fixed number of objects, then it should be them. If you have a fixed number of groups, then they are.
With a hat, you can create generally interesting things. For example, if you specify the task status as a header, then when the status in the task changes, the task record in the schedule will jump by itself to the corresponding status. Those. in fact almost kanban boards can be made here, etc. things. When we attach these records to the live information in the system through the procedures, it can also come to life in the charts. Very flexible mechanism.
Also, if you specify filtering conditions in the procedure, you can create these caps in the graph with arbitrary filters taken into account.
What not to display
You can also specify what to display in the record, and what is not. For example, in the procedure, some service identifiers for bundles can be displayed as results. This information that is not relevant to the user can be ignored in the output.
What to hide
And you can display, but turn under the cat. Information that is not very important, but sometimes needed. For example, who created this entry and when, may be needed only in case of some sorting out, but not in operational work.
Links
It is also very convenient when a field can be a link.
For example, if we make a schedule for tasks, why not click on its number to get into the task itself.
We have a standard link building mechanism in the configurator. You can make them there, and associate with the field in the graph. Everything is working.
Name
Of course, the field should somehow be called. By default, the system will take the name from the procedure field, but it is not always correct for perception. Therefore, sometimes you need to enter alternative names.
For example, all of the above we have is. Opposite to the fields of the specified procedure, check marks are placed.
The output of the record will look like this:
Adding a new record The
fields for adding a new record should be determined by the procedure for adding. Each input parameter of the procedure must be submitted information.
But there is a trick. Fields can be not only text, but also lists.
Take our example for telecom, where there is a task, a group, an object. We will not force the user to search for object identifiers and drive them in. It is necessary that there was a pop-up list with the necessary information. And where can I get it?
To do this, the input field of the procedure should pull another procedure, which will give for example a list of actual tasks, or a list of necessary objects, etc. At the same time, it is impossible to simply indicate the fields of a table, since There may be complex filters. The same tasks may already be 10,000 in the system, stamped, but it is necessary to display a list of the 100 current ones now.
In general, a procedure that twitches across a field of another procedure.
Actually it just sounds scary. These things are well automated, procedures for standard directories are obtained with one button. Procedures for all sorts of lists of groups, tasks, applications, etc. long ago implemented to work all kinds of CRM modules. They just need to choose. If there is already a procedure with similar functionality, it is copied and edited.
You also need to specify which of the added fields will be a header. This is what we need in the editing system.
It looks like this for us:
Editing a record
It’s still more interesting. It is not enough to display all the field lists as in the appendix. It is necessary to select the current positions (selected) in these lists. We are editing.
To do this, you must associate the creation fields with output fields. And in the case of a list field, it’s not just a bang from the output, but to know the identifier of this information.
Those. here it is necessary:
a) to specify the editing procedure
b) to associate its fields with the addition fields
c) to associate its fields with the data output fields of the record, in order to put the current data in the lists It is
not necessary to indicate any other features here, because we already have configured Output and Addition.
When the editing window is displayed, the system will automatically call the required procedure for each field, receive data, compare it with the data from the output of the record, insert the selected values in the lists, and insert the current values in simple fields.
It looks at us so
Deleting records
Removal is the easiest. Simply specify the deletion procedure with one input parameter: the ID of the schedule entry.
Event handling when adding / modifying / deleting records. Triggers. Cross Records.
Only add / modify entries in the graphs a little. Need to still manage events. This opens up unlimited room for configuration.
Managing events is actually very simple. We already have the tables in which the data of the schedule records are stored. On these tables, you can put any on the complexity of the triggers. Our cloud configurator makes it easy to do this.
For example, you need logs, who did what in the record. It's simple. A table is created for the logs, and a trigger is put on the chart table, which writes these modifications to the table with logs.
Also thanks to this cross-records are available. For example, when in our example the task is put in a group, you can define all the participants of this group and double them of this record in personal schedules. To put in personal charts in this case means to make an entry in the personal chart data table. It is also a graph in this system, only configured differently and moved to another location. This entry will appear in it.
Or you need to send a notification to group users. Or send a client a text message that they will come to work on such and such a task then. To do this, simply make the trigger, which make entries in the table of notifications or SMS.
Reports Graph
reports are also needed, and with such a structure they can be made.
For example, it took to make a report on how much time employees were on the road in the previous month. We go to the report configurator, select the desired table where the schedule records are stored, set the necessary filters and aggregation functions - and wahl, the report is ready.
Other uses of chart data Graph
data can be used anywhere with an advanced system configurator. For example, in tasks we easily managed to make the Charts tab and in one simple procedure output information, for how long and who has this task for execution.
Lining time
They happen. And there is nothing worse looking than writing over each other and not giving to read the desired entry. This problem is also solved. System intersecting records automatically places nearby. In this case, only simple html is used, just the structure of the table is built in the way necessary for this. The system provides care at any depth, but more than 2 records are rare.
Of course, if time overlaps, most likely something is not so planned. A person cannot be in two places at the same time, but even such situations need to be displayed correctly.
Access and Security
Access is divided into 2 levels. System and Personal graphics. The system is defined as a whole by the Roles editor and the default permissions set in the interface configurator. For example, if a given cell of the page (or inherited above, tabs, pages, menus) is denied access to reading, then no users will see this graphic at the interface display level until users assign read access rights to this area in User Roles.
Next come the internal rights of the schedule. They can be
1) Editing
- only author
- only the group of the author (all employees included in the groups in which the author
is a member ) - only a division of the author (all employees included in the division of the author, according to staff)
PS: the working group and staff may differ from us. For example, in one division there may be several working groups, or employees from different divisions may be in the same group. The same employee can be simultaneously in different groups. All this system takes into account.
2) Removal is similar.
- only author
- only group
- only division
What are internal rights for?
If this is a personal schedule, or there are some features, then it makes sense to put only the author.
But there are shift personnel and situations where the record needs to be edited, and the employee is not at work. What to do? It makes sense for such schedules to put editing by a group or division so that other shift workers can work with these records.
Also in the schedule can be specified Role, which has the right to administer. Employees with this Role will have rights to edit and delete, regardless of groups and divisions.
Here we have such a cool thing that makes life very simple when you can juzat it, of course. Just an inexperienced person may be difficult to understand. But we have such a schedule in an uncomplicated way, it is about a man-hour.
In addition, we still get the deepest configuration capabilities and the ability to interact with other elements of the system.