Parser OOXML (docx, xlsx, pptx) on Ruby: our errors and finds
We have laid out the parser of OOXML formats in Ruby in open-source. It is available on GitHub and RubyGems.org , is free and distributed under the AGPLv3 license. Everything is like the fashionable Ruby developers.

It's no secret that our parser is not the first OOXML parser in Ruby. We could take a third-party product, but decided not to. The solutions that we managed to find have a number of problems:
a) they have long been abandoned by developers;
b) they support only basic functionality;
c) they are usually distributed as three separate libraries. Often, the docx parser and the xlsx parser were made by different people, so their interfaces can differ dramatically. Agree, this is inconvenient.
We wrote it for ourselves and our tasks (testing document editors), but then we realized that perhaps he could help other Ruby developers, because he:
a) is actively developing;
b) supports all the functionality of our editors, and that is a lot. Here there can be read;
c) called the OOXML parser, as it works with docx, and xlsx, and pptx.
Let us dwell on item b) - functionality. Do we have all the possible features of the standard implemented? Nope. The ECMA-376 standard is four volumes and in total over 9000 pages (no). In fact, about 7 thousand. You can exhale.

In general, you yourself understand: not everything is implemented with us. But there is everything you need and more: paragraphs, tables, auto figures are recognized. There is support for complex things like
Spoiler - Why do we need parsers at all?
He was born in the testing department.
From the very beginning of automated testing, we adopted a single concept of functional tests.
Take the simplest test:
1. Create a new document.
2. We print the text and set its Bold property.
3. Check that the Bold is set.
The ONLYOFFICE editor is written in Canvas, that is, the text in the document is a picture. Checking the thickness of the font in the picture is extremely difficult. But you can apply Bold to any font!

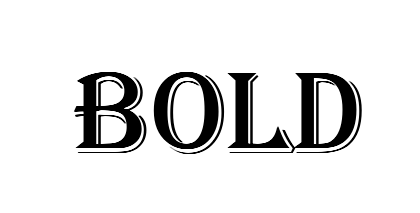
In some fonts (such as Arial Black), Bold may not appear at all visually. Agree that comparing images with imagemagick is not the best option.
Therefore, the test verification step was highlighted in a separate paragraph, namely:
4. Download the resulting file in docx format and verify that the Bold parameter is set for the text.
There are hundreds of such parameters. At the same time, none of the existing solutions supported anything but the simplest grabbing of text, tables, and a couple more things. So we decided to create our own library.
Wait, you ask, you are developing a document editor that can open all of these formats for editing! Why not use a ready-made solution from the editor and verify the tests through it?
Why not?
1. In the server side of the editors, the parser is written in C ++, and the entire process of automated testing is built on Ruby. On the move, it was not entirely clear how to tie this all together.
2. Now we have a version for Linux (and it’s the main one), but at the moment the integration of the entire infrastructure for testing began, the server part of the documents supported only Windows as a platform. At the same time, in testing, we always used Ubuntu and derivatives. To glue it all, I would have to come up with tricky schemes.
3. Is it possible to consider the server parser as a standard? Verify product results using the product itself? A dubious idea.
If you have ever tried to archive a docx file, you may have noticed that the compression ratio is very small. Why is that? It's simple: ooxml files are just an archived set of xml files. Their structure is quite trivial.
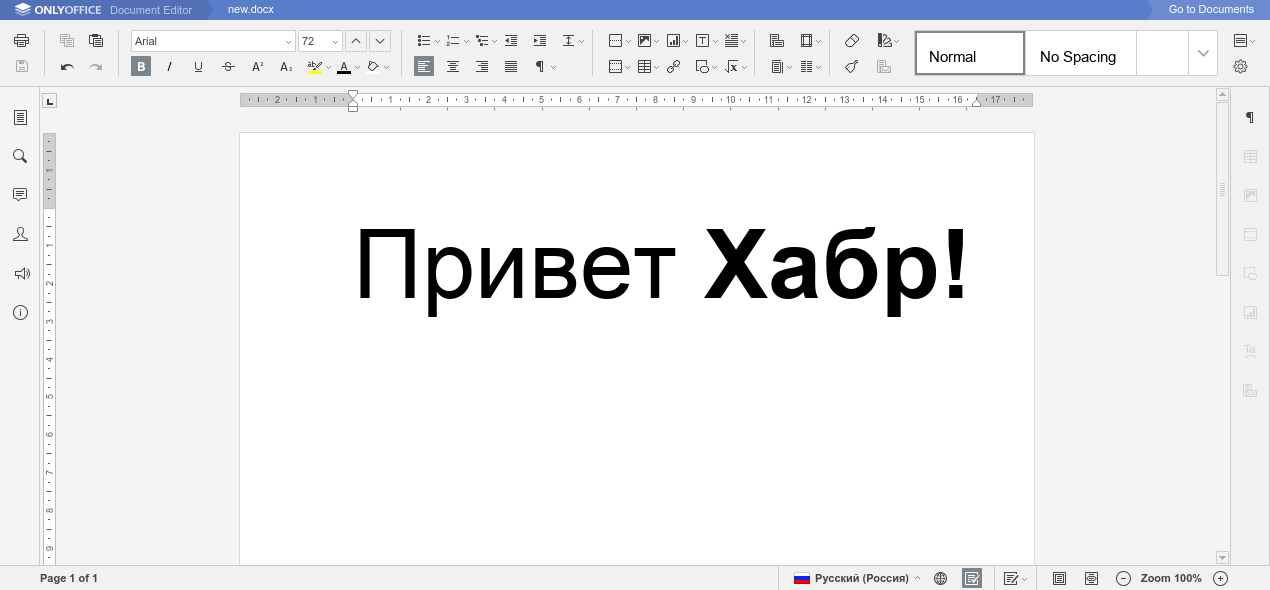
For example, create a simple greeting file in our ONLYOFFICE editor and download it in docx. Then unzip it as a zip file and see where the meat of this document, interesting to us, is stored.
We will see the following structure:
We begin to delve into the insides. In order.
[Content_Types] .xml - a list of mime types in the document. Coldly.
app.xml - document metadata, creator application, statistics. Already warm, the information is interesting, useful.
core.xml - metadata about the latest modifications.
document.xml - Ohh, that's a bingo. The content of our document is hidden in this file, we will consider it later.
fontTable.xml - table of fonts in the document. Useful.
document.xml.rels - a list of all files in the archive, this list will be very useful for us for complex documents with pictures and graphs.
settings.xml- From the name it’s clear that various document parameters are stored there, such as default zoom, number dividers and more.
styles.xml, theme1.xml and theme1.xml.rels are very bulky, very detailed files containing parameters for the styles and themes of the document. The ability to understand these documents is one of the key features of the product.
webSettings.xml - setting regarding the web version of the document. Not the most popular functionality for docx, omit it.
So, it turned out that in a simple document, it is word / document.xml that is interesting .

Simple xml. Fortunately, there are no problems with parsing xml on Ruby. Take Nokogiri and get a DOM tree. Well, then it’s a matter of technology, read the standard (if not laziness, the document is very large), or we’ll just understand where the necessary parameter is hidden in the document with the good old reverse engineering.
At the beginning of the work, we made a number of mistakes, which, as awareness increased, we corrected ourselves. The two most significant mistakes are described below - they are good in the past, and we are no longer ashamed. We hope that our experience will help others not to go over the same rake.
Huge files
So, we have a task to process three different document formats. How do we organize the code for this? Of course, three files of 4000 lines of code (in fact, even 4 files of 4000 lines of code, because there were also general methods for the formats).
The solution to the problem took the most time. I had to bring all this economy in a neat form (although a file with 300 lines sometimes still pops up), select methods in neat classes, etc. Now we have more than 200 source files instead of four. It’s easier to fix bugs.
Lack of tests
The logic was this: we are writing a parser to test our main product ONLYOFFICE Document Server, why do we need to test the parser itself?
NOT. NOT. NOT!!!
Scene from life:
- We need to fix something here, our color of the figure is incorrectly determined.
- Yes, now, there was a typo there, corrected one letter, committed it.
Bottom line:
Everything has fallen. Parser, editor, dollar exchange rate, Humpty Dumpty, self-esteem.
All that was needed was to create the `spec` folder, put a couple of hundred files there, check a bunch of parameters to sleep peacefully at night and know that the commit you made before leaving work would not break the verification of the option that is set in the menu 3rd level of nesting. As we call it "in the third star to the left."
But we not only squinted. We also had sound thoughts. The coolest ones:
Using RuboCop
RuboCop is a static code analyzer for Ruby, and we love it. Very very. And we always listen to his opinion. It helps to keep the code in good shape, avoid stupid mistakes and strictly monitor so that the code does not become dirtier and worse after the next commit (thanks to integration via overcommit ).
His work looks like this: after a hard working day, you forgot that variables in Ruby are usually capitalized and you try to commit code of the form
In this case, an error will occur:
You cannot commit this code without additional manipulations (`SKIP = RuboCop git commit -av`). This is a great defense against the fool.
Orientation to open-source projects
Almost from the very beginning of parser development, we focused on other open-source projects. Although we were not sure that our code would be laid out in open source, we were always ready for this. When the “Lay out” command arrived, we just clicked the “make public” button in GitHub, and that’s all, no additional combing and anything else.
This is a great merit of the same RuboCop: we often peeped at their code, thinking how best to organize a particular topic, for example Changelog, gem structure. In addition, all development, commits, a history of changes and other things were initially conducted in English.
Using the database of documents
When testing parsers, our previous achievements were useful to us - a large database with all sorts of strange, huge and incomprehensible files of three formats.
Once upon a time, at an early stage of development of ONLYOFFICE editors, we collected these files on the Internet - they checked the rendering of complex and non-standard documents. A few years later, the parser was run on the same document base. As a result, there were a lot of problems of different difficulty levels, and after spending a couple of weeks to resolve them, we got an excellent product.

So, everything is available, take it, add it to your Ruby application, parse docx, build statistics on them, analyze how your accounting for xlsx files works, find out which memesik hid your PM at the product presentation in the fourth slide. And all this is free.
You can also find problematic files and create issue on GitHub, we’ll resolve this. You can even edit yourself and send Pull Requests.
Why we did not use third-party parsers
It's no secret that our parser is not the first OOXML parser in Ruby. We could take a third-party product, but decided not to. The solutions that we managed to find have a number of problems:
a) they have long been abandoned by developers;
b) they support only basic functionality;
c) they are usually distributed as three separate libraries. Often, the docx parser and the xlsx parser were made by different people, so their interfaces can differ dramatically. Agree, this is inconvenient.
What is the difference between our parser
We wrote it for ourselves and our tasks (testing document editors), but then we realized that perhaps he could help other Ruby developers, because he:
a) is actively developing;
b) supports all the functionality of our editors, and that is a lot. Here there can be read;
c) called the OOXML parser, as it works with docx, and xlsx, and pptx.
Let us dwell on item b) - functionality. Do we have all the possible features of the standard implemented? Nope. The ECMA-376 standard is four volumes and in total over 9000 pages (no). In fact, about 7 thousand. You can exhale.
In general, you yourself understand: not everything is implemented with us. But there is everything you need and more: paragraphs, tables, auto figures are recognized. There is support for complex things like
- Color schemes;
- Styles of paragraphs and tables;
- Built-in charts;
- Properties of autofigures;
- Speakers;
- Lists.
Why did you need a parser
Spoiler - Why do we need parsers at all?
He was born in the testing department.
From the very beginning of automated testing, we adopted a single concept of functional tests.
Take the simplest test:
1. Create a new document.
2. We print the text and set its Bold property.
3. Check that the Bold is set.
The ONLYOFFICE editor is written in Canvas, that is, the text in the document is a picture. Checking the thickness of the font in the picture is extremely difficult. But you can apply Bold to any font!
In some fonts (such as Arial Black), Bold may not appear at all visually. Agree that comparing images with imagemagick is not the best option.
Therefore, the test verification step was highlighted in a separate paragraph, namely:
4. Download the resulting file in docx format and verify that the Bold parameter is set for the text.
There are hundreds of such parameters. At the same time, none of the existing solutions supported anything but the simplest grabbing of text, tables, and a couple more things. So we decided to create our own library.
Wait, you ask, you are developing a document editor that can open all of these formats for editing! Why not use a ready-made solution from the editor and verify the tests through it?
Why not?
1. In the server side of the editors, the parser is written in C ++, and the entire process of automated testing is built on Ruby. On the move, it was not entirely clear how to tie this all together.
2. Now we have a version for Linux (and it’s the main one), but at the moment the integration of the entire infrastructure for testing began, the server part of the documents supported only Windows as a platform. At the same time, in testing, we always used Ubuntu and derivatives. To glue it all, I would have to come up with tricky schemes.
3. Is it possible to consider the server parser as a standard? Verify product results using the product itself? A dubious idea.
How the parser works
If you have ever tried to archive a docx file, you may have noticed that the compression ratio is very small. Why is that? It's simple: ooxml files are just an archived set of xml files. Their structure is quite trivial.
For example, create a simple greeting file in our ONLYOFFICE editor and download it in docx. Then unzip it as a zip file and see where the meat of this document, interesting to us, is stored.
We will see the following structure:
#tree
├── [Content_Types].xml
├── docProps
│ ├── app.xml
│ └── core.xml
├── _rels
└── word
├── document.xml
├── fontTable.xml
├── _rels
│ └── document.xml.rels
├── settings.xml
├── styles.xml
├── theme
│ ├── _rels
│ │ └── theme1.xml.rels
│ └── theme1.xml
└── webSettings.xml
We begin to delve into the insides. In order.
[Content_Types] .xml - a list of mime types in the document. Coldly.
app.xml - document metadata, creator application, statistics. Already warm, the information is interesting, useful.
core.xml - metadata about the latest modifications.
document.xml - Ohh, that's a bingo. The content of our document is hidden in this file, we will consider it later.
fontTable.xml - table of fonts in the document. Useful.
document.xml.rels - a list of all files in the archive, this list will be very useful for us for complex documents with pictures and graphs.
settings.xml- From the name it’s clear that various document parameters are stored there, such as default zoom, number dividers and more.
styles.xml, theme1.xml and theme1.xml.rels are very bulky, very detailed files containing parameters for the styles and themes of the document. The ability to understand these documents is one of the key features of the product.
webSettings.xml - setting regarding the web version of the document. Not the most popular functionality for docx, omit it.
So, it turned out that in a simple document, it is word / document.xml that is interesting .
Simple xml. Fortunately, there are no problems with parsing xml on Ruby. Take Nokogiri and get a DOM tree. Well, then it’s a matter of technology, read the standard (if not laziness, the document is very large), or we’ll just understand where the necessary parameter is hidden in the document with the good old reverse engineering.
How the parser was written
At the beginning of the work, we made a number of mistakes, which, as awareness increased, we corrected ourselves. The two most significant mistakes are described below - they are good in the past, and we are no longer ashamed. We hope that our experience will help others not to go over the same rake.
Huge files
So, we have a task to process three different document formats. How do we organize the code for this? Of course, three files of 4000 lines of code (in fact, even 4 files of 4000 lines of code, because there were also general methods for the formats).
The solution to the problem took the most time. I had to bring all this economy in a neat form (although a file with 300 lines sometimes still pops up), select methods in neat classes, etc. Now we have more than 200 source files instead of four. It’s easier to fix bugs.
Lack of tests
The logic was this: we are writing a parser to test our main product ONLYOFFICE Document Server, why do we need to test the parser itself?
NOT. NOT. NOT!!!
Scene from life:
- We need to fix something here, our color of the figure is incorrectly determined.
- Yes, now, there was a typo there, corrected one letter, committed it.
Bottom line:
Everything has fallen. Parser, editor, dollar exchange rate, Humpty Dumpty, self-esteem.
All that was needed was to create the `spec` folder, put a couple of hundred files there, check a bunch of parameters to sleep peacefully at night and know that the commit you made before leaving work would not break the verification of the option that is set in the menu 3rd level of nesting. As we call it "in the third star to the left."
But we not only squinted. We also had sound thoughts. The coolest ones:
Using RuboCop
RuboCop is a static code analyzer for Ruby, and we love it. Very very. And we always listen to his opinion. It helps to keep the code in good shape, avoid stupid mistakes and strictly monitor so that the code does not become dirtier and worse after the next commit (thanks to integration via overcommit ).
His work looks like this: after a hard working day, you forgot that variables in Ruby are usually capitalized and you try to commit code of the form
- path_to_zip_file = copy_file_and_rename_to_zip (path_to_file)
+ ZIP_file = copy_file_and_rename_to_zip (path_to_file)
In this case, an error will occur:
Analyze with RuboCop ........................................ [RuboCop] FAILED
Errors on modified lines:
ooxml_parser / lib / ooxml_parser / common_parser / parser.rb: 8: 7: E: dynamic constant assignment
You cannot commit this code without additional manipulations (`SKIP = RuboCop git commit -av`). This is a great defense against the fool.
Orientation to open-source projects
Almost from the very beginning of parser development, we focused on other open-source projects. Although we were not sure that our code would be laid out in open source, we were always ready for this. When the “Lay out” command arrived, we just clicked the “make public” button in GitHub, and that’s all, no additional combing and anything else.
This is a great merit of the same RuboCop: we often peeped at their code, thinking how best to organize a particular topic, for example Changelog, gem structure. In addition, all development, commits, a history of changes and other things were initially conducted in English.
Using the database of documents
When testing parsers, our previous achievements were useful to us - a large database with all sorts of strange, huge and incomprehensible files of three formats.
Once upon a time, at an early stage of development of ONLYOFFICE editors, we collected these files on the Internet - they checked the rendering of complex and non-standard documents. A few years later, the parser was run on the same document base. As a result, there were a lot of problems of different difficulty levels, and after spending a couple of weeks to resolve them, we got an excellent product.
Total
So, everything is available, take it, add it to your Ruby application, parse docx, build statistics on them, analyze how your accounting for xlsx files works, find out which memesik hid your PM at the product presentation in the fourth slide. And all this is free.
You can also find problematic files and create issue on GitHub, we’ll resolve this. You can even edit yourself and send Pull Requests.