Fountain Codes
- Transfer
Today we’ll talk about fountain codes . They are also called “fixed speed codes”. Fountain code allows you to take, for example, a file, and convert it into an almost unlimited number of encoded blocks. With a subset of these blocks, you can restore the original file, provided that the size of this subset is slightly larger than the file size. In other words, such a code allows you to create a "fountain" from the encoded data. The recipient can restore the original data by collecting enough “drops” from the fountain, it doesn’t matter which “drops” he has, and which ones he missed.

A remarkable property of fountain codes is that their use allows you to send data via unreliable communication channels, for example, via the Internet, without relying on knowledge of the level of packet loss, and without requiring the recipient to contact the sender to recover missing pieces of data. It is easy to notice that such opportunities will prove to be very useful in many situations. Among them, for example, sending information via broadcast communication channels, as in video transmission systems on demand. The operation of the Bittorrent protocol and other similar ones, when file fragments are distributed among a large number of peers, belongs to the same category of tasks.
It might seem that fountain codes should be terribly complicated. But this is not so. There are different implementations of this algorithm, we suggest starting with the simplest one. This is the so-called Labi conversion code, in short it is usually called the LT code, from Luby Transform Code . When using this variant of fountain codes, blocks encode as follows:
As you can see, there is nothing complicated. But it should be noted that much in this scheme depends on the so-called distribution of degrees of code symbols, on how to choose the number of blocks that need to be combined. We will come back to this issue. From the description you can see that some of the encoded blocks are, in fact, created using only one block of source data, while the coding of most blocks involves several source blocks.
Here is another coding feature that is not quite obvious at first glance. It consists in the fact that as long as we let the recipient know exactly which blocks we are combining in order to obtain an output block, we do not need to explicitly transmit this list. If the sender and the recipient agree on a certain pseudo-random number generator, you can initialize the generator with a randomly selected number and use it to select the degree distribution and the set of source blocks. The initial number is simply sent along with the encoded block, and the recipient can use the same procedure to restore the list of source blocks that the sender used when encoding.
The decoding procedure is a little more complicated, although it is also quite simple.
Let's consider an example of decoding in order to better understand everything. Suppose we get five encoded blocks, each one byte long. Information was also obtained on which source blocks each of them was constructed from. These data can be represented in the form of a graph.
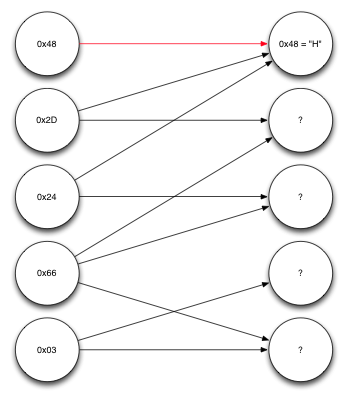
Graph representing the received data.
The nodes on the left are the received encoded blocks. The nodes on the right are the source blocks. The first of the received blocks, 0x48, as it turned out, was formed with the participation of only one source block, the first. Thus, we already know what this block was. Moving in the opposite direction by the arrows pointing to the first source block, we see that the second and third encoded blocks depend only on the first source block and on one another. And, since the first source block is already known, we can perform the XOR operation on the received blocks and the first source block and decode a few more blocks.
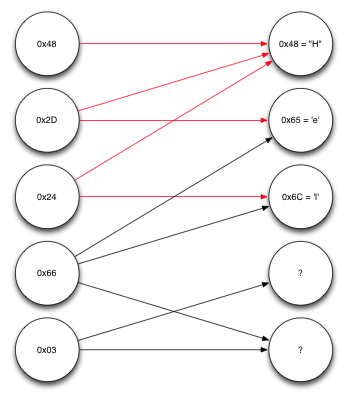
Continuing the decoding of the message.
Repeating the same procedure again, we can see that now we know enough to decode the fourth block, which depends on the second and third source blocks, each of which has already been decoded. Performing XOR operations on them allows you to find the fifth, that is, the last block in the source block list, as shown in the figure below.

Decoded fifth source block
And finally, you can now decode the last of the remaining source blocks, which, in the end, will give the message that the sender wanted to transmit to the recipient.

Completely Decoded Message
It must be admitted that this example is artificial. Here we proceed from the assumption that only the blocks necessary for decoding the original message are received. In addition, among the blocks there is nothing superfluous, and the blocks themselves are arranged in a very convenient order. But this is only a demonstration of the principles of work of fountain codes. We are sure that, thanks to this example, you will be able to understand how the same procedures work with larger blocks and longer files.
Earlier it was said that how to select the number of source blocks that each of the encoded blocks should consist of, or the distribution of the degrees of code symbols, is very important. And, in fact, the way it is. Ideally, the algorithm should generate a small number of encoded blocks, for the creation of which only one source block is used. This is necessary so that the recipient can begin to decode the message. However, most encoded blocks should depend on a small number of other blocks. It's all about the right selection of distribution. A similar distribution, perfect for our purposes, exists. It is called the ideal soliton distribution .
Unfortunately, in practice this distribution is not so ideal. The fact is that random variations lead to the fact that some blocks of the source are not used, or to the fact that decoding is stopped when the decoder ends with known blocks. One of the variants of this distribution, called the robust soliton distribution, allows you to improve the performance of the algorithm by generating more blocks from a very small number of source blocks, as well as generating some blocks that are a combination of all or almost all of the source blocks. This is done to facilitate decoding of a number of the last blocks.
Here, in brief, how fountain codes work, and, in particular, LT codes. I must say that LT codes are the least effective of the known fountain codes, but they are also the easiest to understand.
Before we end this conversation, here's another thought. Fountain codes may look ideal for systems like Bittorrent, allowing sids to generate and distribute an almost unlimited number of blocks, more or less eliminating the “last block” problem in cases where there are few seeds, and ensuring that two randomly selected peers almost always have useful information which can be exchanged with each other. However, there is one important problem. The fact is that it is very difficult to verify the data received from peers.
Peer-to-peer protocols use secure hashing functions, such as SHA1, while the trusted side, the creator of the distribution, provides a list of valid hashes to all peers. Each feast, using this data, can check the downloaded fragments of the file. However, when using fountain codes, such a scheme of work is complicated. There is no way to calculate, for example, the SHA1 hash of the encoded fragment, even knowing the hashes of the individual fragments that took part in its formation. And we cannot trust other peers to calculate this hash for us, as they can simply deceive us. We can wait until we collect the entire file, and then, using the list of invalid fragments, we can try to find the incorrect encoded fragments, but this is difficult and unreliable. In addition, with this approach, errors can only be found in the final build of the file, that is - it is likely to take too much time. One of the possible alternatives is for the distribution creator to publish the public key and sign each generated block. Thus, we can check the encoded blocks, but there is a serious minus. The fact is that only the creator of the distribution can generate the correct blocks, which means that we immediately lose most of the advantages of using fountain codes. It seems that here we are at an impasse. However, there are alternatives, for example, a very ingenious scheme called homomorphic hashing. Although it is not perfect. but there is a serious minus. The fact is that only the creator of the distribution can generate the correct blocks, which means that we immediately lose most of the advantages of using fountain codes. It seems that here we are at an impasse. However, there are alternatives, for example, a very ingenious scheme called homomorphic hashing. Although it is not perfect. but there is a serious minus. The fact is that only the creator of the distribution can generate the correct blocks, which means that we immediately lose most of the advantages of using fountain codes. It seems that here we are at an impasse. However, there are alternatives, for example, a very ingenious scheme called homomorphic hashing. Although it is not perfect.
We talked about the basics of fountain codes. Varieties of this algorithm have found practical application in areas where its advantages unambiguously outweigh the shortcomings. If this topic interests you and you want to delve deeper into it, read this material on fountain codes. In addition, it will be useful to familiarize yourself with Raptor codes , which, complicating the LT codes a little, significantly improve their efficiency. Thanks to their use, it is possible to reduce the amount of transmitted data and the computational complexity of the algorithm.
A remarkable property of fountain codes is that their use allows you to send data via unreliable communication channels, for example, via the Internet, without relying on knowledge of the level of packet loss, and without requiring the recipient to contact the sender to recover missing pieces of data. It is easy to notice that such opportunities will prove to be very useful in many situations. Among them, for example, sending information via broadcast communication channels, as in video transmission systems on demand. The operation of the Bittorrent protocol and other similar ones, when file fragments are distributed among a large number of peers, belongs to the same category of tasks.
Basic principles
It might seem that fountain codes should be terribly complicated. But this is not so. There are different implementations of this algorithm, we suggest starting with the simplest one. This is the so-called Labi conversion code, in short it is usually called the LT code, from Luby Transform Code . When using this variant of fountain codes, blocks encode as follows:
- Choose a random number d from the range 1 - k. The range corresponds to the number of blocks in the file. Below we will talk about how best to choose d.
- Randomly select d file blocks and combine them. In our case, the XOR operation is well suited.
- The block obtained in the previous step is transmitted along with information about which blocks it was created from.
As you can see, there is nothing complicated. But it should be noted that much in this scheme depends on the so-called distribution of degrees of code symbols, on how to choose the number of blocks that need to be combined. We will come back to this issue. From the description you can see that some of the encoded blocks are, in fact, created using only one block of source data, while the coding of most blocks involves several source blocks.
Here is another coding feature that is not quite obvious at first glance. It consists in the fact that as long as we let the recipient know exactly which blocks we are combining in order to obtain an output block, we do not need to explicitly transmit this list. If the sender and the recipient agree on a certain pseudo-random number generator, you can initialize the generator with a randomly selected number and use it to select the degree distribution and the set of source blocks. The initial number is simply sent along with the encoded block, and the recipient can use the same procedure to restore the list of source blocks that the sender used when encoding.
The decoding procedure is a little more complicated, although it is also quite simple.
- Restore the list of source blocks that were used to create the encoded block.
- For each source block from this list, if it has already been decoded, perform an XOR operation with the encoded block and remove it from the list of source blocks.
- If at least two source blocks remain in the list, add the encoded block to the temporary storage area.
- If only one source block remains in the list, this means that the next source block has been successfully decoded! You need to add it to the decoded file and go through the temporary storage list, repeating this procedure for any source blocks that contain the found block.
0x48 0x65 0x6C 0x6C 0x6F, world!
Let's consider an example of decoding in order to better understand everything. Suppose we get five encoded blocks, each one byte long. Information was also obtained on which source blocks each of them was constructed from. These data can be represented in the form of a graph.
Graph representing the received data.
The nodes on the left are the received encoded blocks. The nodes on the right are the source blocks. The first of the received blocks, 0x48, as it turned out, was formed with the participation of only one source block, the first. Thus, we already know what this block was. Moving in the opposite direction by the arrows pointing to the first source block, we see that the second and third encoded blocks depend only on the first source block and on one another. And, since the first source block is already known, we can perform the XOR operation on the received blocks and the first source block and decode a few more blocks.
Continuing the decoding of the message.
Repeating the same procedure again, we can see that now we know enough to decode the fourth block, which depends on the second and third source blocks, each of which has already been decoded. Performing XOR operations on them allows you to find the fifth, that is, the last block in the source block list, as shown in the figure below.
Decoded fifth source block
And finally, you can now decode the last of the remaining source blocks, which, in the end, will give the message that the sender wanted to transmit to the recipient.
Completely Decoded Message
It must be admitted that this example is artificial. Here we proceed from the assumption that only the blocks necessary for decoding the original message are received. In addition, among the blocks there is nothing superfluous, and the blocks themselves are arranged in a very convenient order. But this is only a demonstration of the principles of work of fountain codes. We are sure that, thanks to this example, you will be able to understand how the same procedures work with larger blocks and longer files.
About perfect distribution
Earlier it was said that how to select the number of source blocks that each of the encoded blocks should consist of, or the distribution of the degrees of code symbols, is very important. And, in fact, the way it is. Ideally, the algorithm should generate a small number of encoded blocks, for the creation of which only one source block is used. This is necessary so that the recipient can begin to decode the message. However, most encoded blocks should depend on a small number of other blocks. It's all about the right selection of distribution. A similar distribution, perfect for our purposes, exists. It is called the ideal soliton distribution .
Unfortunately, in practice this distribution is not so ideal. The fact is that random variations lead to the fact that some blocks of the source are not used, or to the fact that decoding is stopped when the decoder ends with known blocks. One of the variants of this distribution, called the robust soliton distribution, allows you to improve the performance of the algorithm by generating more blocks from a very small number of source blocks, as well as generating some blocks that are a combination of all or almost all of the source blocks. This is done to facilitate decoding of a number of the last blocks.
Here, in brief, how fountain codes work, and, in particular, LT codes. I must say that LT codes are the least effective of the known fountain codes, but they are also the easiest to understand.
Peer-to-peer networks and the trust issue
Before we end this conversation, here's another thought. Fountain codes may look ideal for systems like Bittorrent, allowing sids to generate and distribute an almost unlimited number of blocks, more or less eliminating the “last block” problem in cases where there are few seeds, and ensuring that two randomly selected peers almost always have useful information which can be exchanged with each other. However, there is one important problem. The fact is that it is very difficult to verify the data received from peers.
Peer-to-peer protocols use secure hashing functions, such as SHA1, while the trusted side, the creator of the distribution, provides a list of valid hashes to all peers. Each feast, using this data, can check the downloaded fragments of the file. However, when using fountain codes, such a scheme of work is complicated. There is no way to calculate, for example, the SHA1 hash of the encoded fragment, even knowing the hashes of the individual fragments that took part in its formation. And we cannot trust other peers to calculate this hash for us, as they can simply deceive us. We can wait until we collect the entire file, and then, using the list of invalid fragments, we can try to find the incorrect encoded fragments, but this is difficult and unreliable. In addition, with this approach, errors can only be found in the final build of the file, that is - it is likely to take too much time. One of the possible alternatives is for the distribution creator to publish the public key and sign each generated block. Thus, we can check the encoded blocks, but there is a serious minus. The fact is that only the creator of the distribution can generate the correct blocks, which means that we immediately lose most of the advantages of using fountain codes. It seems that here we are at an impasse. However, there are alternatives, for example, a very ingenious scheme called homomorphic hashing. Although it is not perfect. but there is a serious minus. The fact is that only the creator of the distribution can generate the correct blocks, which means that we immediately lose most of the advantages of using fountain codes. It seems that here we are at an impasse. However, there are alternatives, for example, a very ingenious scheme called homomorphic hashing. Although it is not perfect. but there is a serious minus. The fact is that only the creator of the distribution can generate the correct blocks, which means that we immediately lose most of the advantages of using fountain codes. It seems that here we are at an impasse. However, there are alternatives, for example, a very ingenious scheme called homomorphic hashing. Although it is not perfect.
Conclusion
We talked about the basics of fountain codes. Varieties of this algorithm have found practical application in areas where its advantages unambiguously outweigh the shortcomings. If this topic interests you and you want to delve deeper into it, read this material on fountain codes. In addition, it will be useful to familiarize yourself with Raptor codes , which, complicating the LT codes a little, significantly improve their efficiency. Thanks to their use, it is possible to reduce the amount of transmitted data and the computational complexity of the algorithm.
Oh, and come to us to work? :)wunderfund.io is a young foundation that deals with high-frequency algorithmic trading . High-frequency trading is a continuous competition of the best programmers and mathematicians around the world. By joining us, you will become part of this fascinating battle.
We offer interesting and complex data analysis and low latency development tasks for enthusiastic researchers and programmers. A flexible schedule and no bureaucracy, decisions are quickly taken and implemented.
Join our team: wunderfund.io