Mini AI Cup # 3: Writing a Top Bot

At the beginning of autumn, the contest for writing bots Mini AI Cup # 3 (aka Mad Cars) was completed, in which participants had to fight on typewriters. The participants argued a lot about what would work and what would not be, ideas from simple ifs to learning neural networks were expressed and tested, but the top places were taken by the guys with the so-called “simulation”. Let's try to figure out what it is, compare the solutions for the 1st, 3rd and 4th places and discuss other possible solutions.
Disclaimer
The article was written in collaboration with Alexey Dichkovsky (Commandos) and Vladimir Kiselev (Valdemar) .
For those who just want to read about the decisions of the winners, I advise you to immediately start from the point "Simulation".
Formulation of the problem
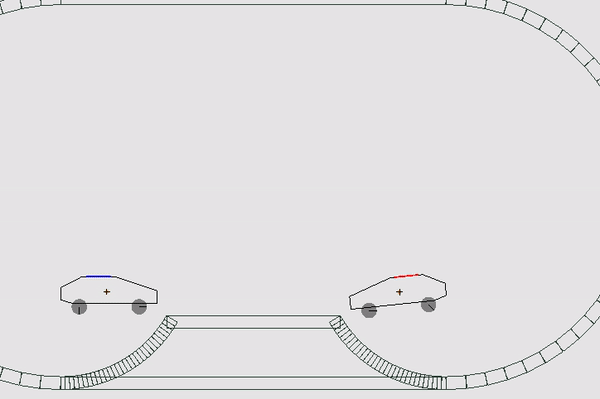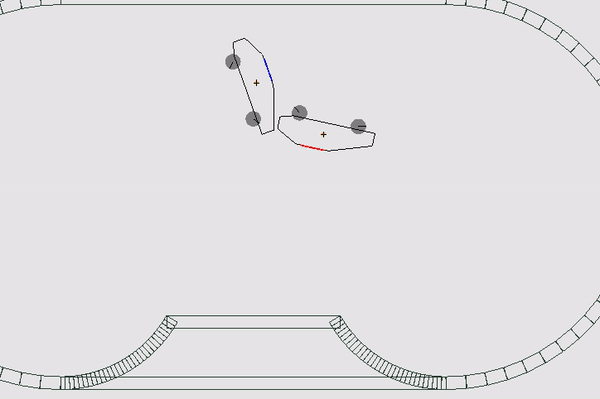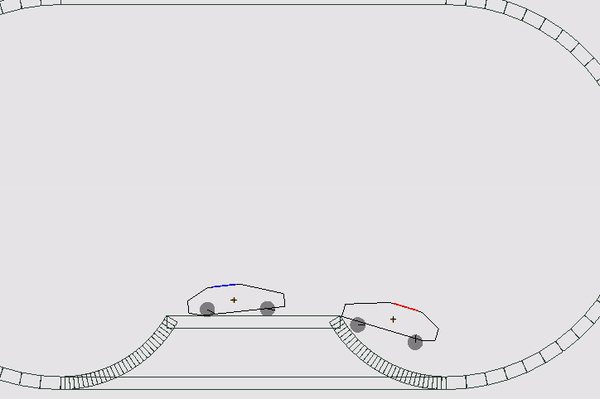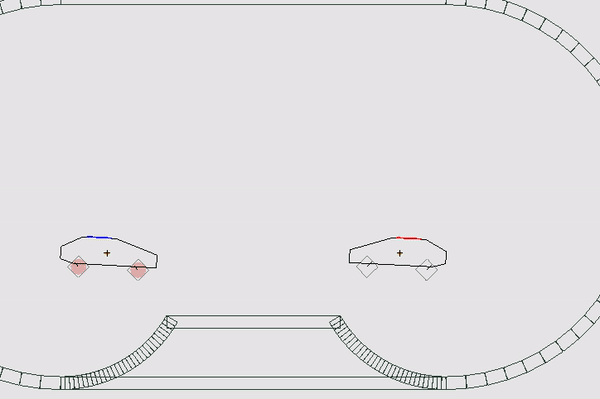
This time, the mechanics of the world looked a lot like the mobile game Drive Ahead: players were given a car with a button on it; the task is to push the button of the enemy faster than he does. If nobody wins over 600 game ticks, the card starts to sink into a pile of garbage, which can also press a button. In other words, you need to protect your button from enemies, the outside world and heaps of garbage (vitally, yes). Each player was given 5 lives, the game went from 5 to 9 rounds, until someone ended their lives. Each round was held on a random map and typewriters, the same for both participants. In total there were 6 different cards and 3 types of cars - a total of 18 different combinations.
Each round is divided into tiki. A tick is one move, like in chess. The only difference is that both players walk at the same time. There are competitions where everyone moves in turns, or you can do the action only once in several moves and select units with a frame .
Each tick bot comes to a state of peace and given an opportunity to make 3 steps: ВЛЕВО, СТОП,ВПРАВО. These actions force the car to go in one of the directions, and if it does not touch the wheels of the earth, it gives a slight rotation to the whole body (a bit of arcade physics). After both opponents have chosen an action, a simulation of the game world starts, a new state is considered and sent to the players. In case someone pushed the button, the round ends and the next one starts. It's simple, but there are nuances.
More complete rules can be found here . A game finals see here .
General description of the solution
Most of the bots writing competitions are very similar: there are a finite number of ticks (there is approximately 1500 maximum for one round), there are a finite number of possible actions, you need to choose a sequence of actions to be better than your opponents. A little later, let us return to what it means to be better, but for now let's deal with how to deal with the main problem - a huge number of options: at the start we have one initial state, then each machine can move in three different ways that gives us 9 different combinations for two machines, by the 1500 move it will be already 9 ^ 1500 different combinations ... Which is a little more than we would like if we plan to have time to sort through them during the Universe existence.
This is where we come to what simulation is . This is not some kind of algorithm, but simply the re-creation of the rules of the game with sufficient or complete accuracy so that you can sort out the solutions. Of course, we will go through not all the solutions, but only a part of them. The search algorithm will be used for this - in the tree of the game states we are looking for the best for us. There are a lot of algorithms (from minimax to MCTS), each has its own nuances. It is best to familiarize yourself with what decisions were written by participants in past competitions in AI. This will give a basic understanding of the conditions under which the algorithms work, and under which not. There are many references for this in a special repository .
When choosing an algorithm should be considered:
- time limit for 1 tick (here I miscalculated strongly this year, but I was able to stay in 3rd place);
- number of players. For example, if there are three players, it will be difficult to use a minimax;
- simulation accuracy, because this may allow reuse of old calculations;
- "branching" of the state tree (is it possible to calculate all possible states at least 10 moves ahead);
- common sense - do not start writing MCTS if the competition lasts 4 hours.
In this competition, 1 tick was given about 10-13ms (2 minutes for the whole game). During this time, the bot had to read the data, make a decision and send a command to move. This was enough to simulate about 500-1000 moves. Enumerate all the states will not work. The simplest search algorithm can look like a comparison of three options for the movement: "50 ticks go left", "50 ticks go right", "50 ticks press stop". And no matter how simple it may sound, it is not very far from the decision of the winner.
Since we count only 50 moves ahead, which in most cases does not count to the end of the game, then we need the evaluation functionwhich will tell you how good and bad the state of the world is for us. Most often it is built on heuristics and understanding what is important for victory. For example, in the 2014 Russian AI Cup competition there were races, but it was possible to win the last one, if you get more bonus points. Hence, the evaluation function should stimulate the collection of points at the same time as fast movement on the highway. The estimate can be calculated only for the last simulation state (after 50 ticks) or as the sum of the estimates of intermediate states. Often, the estimate "fades out" in time, so that states that occur earlier are more affected. Since we can not predict the enemy for sure, and future options are less likely to happen, we will not rely heavily on them. Also, this technique causes the bot to quickly perform its tasks, rather than postpone everything until later.
Since we are going to predict the state of the world in response to our actions, then we need to somehow simulate the behavior of enemies. There is nothing difficult and there are a couple of common options:
- Stub or heuristics
Written simple logic of behavior, where the enemy simply does not do anything, or chooses actions based on simple heuristics (for example, you can use your first versions of the strategy or simply repeat the opponent’s previous move). - Use the same algorithm as for yourself
First we try to find the best actions for the enemy (against our best set of actions from the last move, or against the stub), and then we are looking for the best action for ourselves, using the behavior that we found for the enemy. Here the bot will try to resist cunning enemies. Such logic does not work well at the start of the competition, since Many bots are still very weak, and your decision will be too cautious with them. - Other
The same minimax sorts through all the players' moves at the same time, and he simply will not need heuristics.
If you implement all the above steps, you will most likely get a very good bot, especially if you manage to find a good evaluation function. But, looking through the fights, it is possible to notice that in certain situations he behaves strangely. Correcting the evaluation function for these situations can be difficult, or there is a high risk of breaking another logic. Here crutches and ifs come to the rescue. Yes, the last days of the competition often boil down to writing crutches and ifs to correct the flaws in some specific conditions. Personally, I don’t like this part very much, but I’ve noticed many times that crutches in the finals can affect the location of places in the top ten, which means one unwritten if can cost you a prize (my heart hurts when I write these words, I I also love beautiful algorithms and solutions).
Q: Is it possible to do without simulation at all?
A: Yes, you can use solutions on heuristics (decision trees, lots of ifs, etc.). There is a good article with AI architectures on heuristics.
Q: How much better is the use of simulation approaches on heuristics?
A: It all depends on the task. For example, here some combinations of cards and machines could be hard-coded with ifs and always win (or a draw). However, often the simulation finds solutions that are difficult to think of yourself, or it is difficult to implement heuristics. In this competition, when you turn over another machine, the solutions on the simulations put their wheels on the enemy's wheel, which turned off the flag "in the air", which means the enemy could not use body rotation and turn back on the wheels. But the decision did not reflect on the meaning of this; it simply found options where the enemy would quickly fall onto the roof and press its button.

Q: Neural networks and RL?
A: No matter how popular it is, in solutions of bots such solutions rarely show themselves well. Although neural networks do not need to be simulated, because they can simply produce an action based on the input parameters of the current state, they still need to somehow learn, and for this they often have to write a simulator to drive games by the thousands locally. Personally, I believe that they have the potential. Perhaps they can solve part of the problem, or use it in conditions of very limited response time.
Note
Regarding the finite number of possible actions, it is worth clarifying that sometimes it is allowed to "smoothly" adjust a parameter. For example, not just go ahead, but by some percentage of power. In this case, the “limbs” of the number of outputs is easy to achieve simply by using several values, for example, 0%, 25%, 50%, 75% and 100%. Most often just two are enough: "fully on" and "completely off."
Simulation
In this competition, the ready chipmunk physics engine was used . The expectations of the organizers were that he is old, time-tested and has many wrappers so that everyone can incorporate it into their decision ...
In the harsh reality, the engine produced different values each time, which made it difficult for it to restart to miscalculate the move options. The problem was solved “in the forehead” - my memory allocator was written in C and the piece of memory with the state of the world was copied entirely. Such an allocator put an end to the possibility of writing solutions in languages other than C ++ (in fact, it was possible, but very labor-intensive, and the allocator would still have to write in C). In addition, the accuracy of the prediction was influenced by the order of adding elements to the game world, which required a very accurate copy of the code used by the organizers for rendering games. But he was already in Python. The last nail in the coffin of other programming languages was that the engine is old and contains many optimizations that cannot be exactly recreated during the competition,
As a result, the engine, which was supposed to give all participants equal conditions for the simulation of moves, became the most difficult obstacle for this. Man overcame it. The first 7 leaderboard places were taken exclusively by the guys who made an accurate simulation, which may serve as some proof of its importance in such competitions.
With the exception of a couple of participants who were able to climb inside the chipmunk and optimize the copying of its state, the others had a simulation of approximately equal performance (which made the competition a bit more interesting, because you know that the struggle is for the solution algorithm, and not "who will count the moves more").
Algorithm of search and prediction of the enemy
From this point begins a separate description of the solutions. The description of the algorithms will be conducted on behalf of its author.
Vladimir Kiselev (Valdemar) 4 place
A random search (Monte Carlo) was used to search the solution space. The algorithm is as follows:
- Initialize the genome - a sequence of actions (left, right, stop) for 60 ticks - random data.
- We take the best genome found
- Randomly change one of the actions
- Using the evaluation function, we get a number - an indicator of how good the new genome is.
- If you have a better solution, then update the best solution.
- Repeat again with paragraph 2
My simulator gave out ~ 100k simulations of the world in 1 second, considering that there is an average of ~ 12ms per tick, we get 1200 actions per tick. That is, for 1 tick we manage to complete a full cycle about 20 times.
To find the optimal solution of such a number of iterations is clearly not enough. Therefore, the idea of “stretching” actions was implemented: instead of the genome of 60 moves, we will operate on a chain of 12 “stretched” moves - we believe that each action lasts 5 ticks in a row.
Plus: Improving the quality of mutations by reducing the length of the genome, a simulation can also be run every 5 ticks and check 100 genomes instead of 20 (to avoid falls over the time limit, eventually stopped at 70).
Minus: Stretching actions can lead to non-optimal solutions (for example, swinging on the bumper, instead of a stable rack)
It should be noted techniques that have significantly improved the quality of the algorithm:
- We carry out random initialization only on the first tick, all the rest of the time we reuse the best found solution with a shift of 1 turn (the action on the 2nd tick is shifted to the 1st, etc., the random action is added to the end). This greatly improves the quality of the search, because otherwise the algorithm “forgets” what it was going to do on the last tick and meaninglessly twitches in different directions.
- At the beginning of the turn, we make more intensive changes (changing the genome 2 or 3 times instead of one) in the hope of getting out of a local maximum (similarity of temperature in the method of simulating annealing).
The intensity was selected manually: the first 30 iterations make 3 mutations, the next 10 by 2, then by 1. - It is very important to predict the actions of the enemy. To the detriment of time to search for your own solution, we launch a random search by the enemy, for 20 iterations, then 50 for ourselves, using the information on the opponent’s optimal moves.
The best decision of the opponent is also reused on the next move with an offset. At the same time, during the search for the solution of the enemy, the genome from the last move is used as my intended actions.
During the competition, I actively used tools for local development, which allowed us to quickly find bugs and focus on the weak points of the strategy:
- local arena - the launch of many matches against the previous version;
- visualizer for debugging behavior;
- script for collecting statistics on matches from the site - allows you to understand on which maps and machines most often occur defeats.
mortido:
It’s risky to count every 5 ticks, especially if the enemy moves away from the options you predicted. On the other hand, in this game world for 5 ticks, not much happened.
Also, in my decision, I, nevertheless, added random combinations of each tick, but I won’t say exactly how this affected the decision.
Commandos:
Changing a couple of actions with such a number of simulations does not look very meaningful, because very little change happens in one action. But when stretching one action by 5 ticks, the meaning seems to be getting bigger.
I also do not like the idea itself - we take the best set and try to rule it somewhere in the beginning. It seems to me illogical that the change of the first tics will leave the subsequent ones at least relatively adequate.
Alexander Kiselev (mortido) 3 place
Armed with articles from the winners of other contests, I decided to use a genetic algorithm. It turned out, however, something similar to a random search or even imitation annealing, but more on that later.
Encode the solution with an array of 40 numbers, where -1, 0 and 1 correspond to the motion ВЛЕВО, СТОПand ВПРАВО.
At the beginning of each round, I considered how much time I had spent for the entire game, considered a new time limit based on how many more rounds there would be, and I considered each round a duration of 1200 ticks. So Initially, I tried to spend no more than 11ms per move, but I could “walk a little” at the end, if the previous rounds were faster than 1200 ticks.
Valdemar:
Interestingly, this chip has worsened my game. It turned out that it is always better to spend 20-30ms than first 11, and at the end 60
A third of this time I was looking for the best move of the enemy, the rest was spent on calculating my own decision. When searching for a move for an enemy, my behavior was modeled as the best from the last move, shifted by 1 tick. Those. as if I continue to act according to the plan made in the last tick, and he is trying to resist me.
The search for the solution itself was the same for both itself and the opponent:
- We take the decision from the last move and move it by 1 move (which we have already done)
- Throwing in the population of random solutions until we fill it all
- We simulate all the solutions and expose the fitness using the evaluation function. We remember the best.
- While there is time for calculations
- Hint, always add 1 mutation of the current best solution to the population, remember it if it is better
- As long as there is a place in the new population and the time for calculations has not been exceeded (you can get out on the floor of the populated population)
- We take two different individuals and leave with the best fitness - mom
- We take two different individuals and leave with the best fitness - dad (should not be the same as mom)
- We cross them
- Mutated if
RND < Вероятность Мутации - We simulate the decision and remember it if it is the best.
As a result, we will return a sequence of actions that is considered optimal. The first move in it is sent as a bot action. Unfortunately, in my plan there was a serious drawback, since the number of simulations that can be done for a tick was very small (including due to the long evaluation function), then on the competition server 4 the item was performed only 1 time, and for the enemy it wasn’t completely performed at all. This made the algorithm look more like a random search or simulated annealing (since we had time to mutate a solution from the last move). It was already too late to change something, and we managed to keep 3rd place.
The implementation of the crossing, mutation, and generation of initial random solutions is important, because depends on what decisions will be checked, and the full random is not as good as it might seem at first glance (it will work, but it will take much more options to sort through).
In the final version, the generation of random solutions occurred in segments, which excluded the solutions "jerking" in one place:
- A random team was selected.
- For the entire solution length (40 moves)
- Write the current command to the cell.
- With a probability of 10%, we change the current command to a random
A similar technology also involved a mutation — a random segment of the solution was replaced with a random command. Crossing occurred by choosing the point to which the decision was taken from 1 parent, and then from the 2nd.
I liked that we use all the time available to us to find the best solution. And it’s not scary if the solution is not the best - we can improve it on the next tick, because optimization turns out "smeared" in time. We also always try to predict how the enemy will ruin our lives and resist it. Of course, the fact that part of the idea did not work due to the time limit spoils the rainbow picture. Now I would not implement this idea in such conditions, but would be inclined to the option of a random search or simulate annealing
Valdemar:
Genetics from the 1st generation looks more like a random search, I think, using your randomization methods without crossing would increase productivity and produce the best result.
Commandos:
About the time limit - with our number of simulations, I would not even think about genetics.
And I still don’t like cyclicity very much - I chose the best for the enemy, then I chose the best for myself. It seems on the next move from the enemy, countermeasures will be found, as well as countermeasures against countermeasures ... But this is only relevant if we have a lot more time to calculate. We can accidentally get “solutions that jingle in one place.” Although in our case it was good to find at least something.
Alexey Dichkovsky (Commandos) 1st place
For myself, I went through only two actions (a two-level search tree), which repeated n and m ticks, respectively. That is, only 3 ^ 2 = 9 combinations. In total, the rendering depth was m + n and in the final version it was 40 ticks.
Solution example:
|----------- n раз -----------|---------- m раз --------|
| ВЛЕВО ВЛЕВО ... ВЛЕВО ВЛЕВО | СТОП СТОП ... СТОП СТОП |For each branch of his actions, he simulated three variants of the opponent's actions: the opponent either always goes to the right, or to the left, or stands. I chose the worst outcome for myself (by analogy with a minimax).
A collection of combinations of n and m was also made , and for each next move the next pair was taken from the collection. Thanks to this, every move was searched for new variants, which gave a great boost to the strategy.
The algorithm at each step of the game worked as follows:
- We get the estimate for the set of actions that was found on the previous tick (at the very first step of the round, this is minus infinity, without additional checks):
- We take the set of actions recognized as the best in the previous step, remove the first tick that has passed since that moment.
- For ease of comparison, estimates need to be made so that the length coincides with the length of the solutions that we will iterate. For this you need to add one tick to the chain of my actions on the right. I decided instead of just adding one tick to sort through all the options for my actions for the last two ticks. After this stage, the set of actions looked like the chosen best one on the previous tick, in which the first and last moves were discarded, and two new ones were added to the end, which were obtained by full brute force.
- This set of actions was evaluated in three variants of the enemy's behavior. The worst score was remembered; according to the results of the assessment, the enemy’s behaviors were sorted (in the future, the worst option for us was first checked in the tree).
- We build a tree of checks on the following value n and m from the collection. Verification of the opponent’s actions proceeds in the order obtained at the end of claim 1, from worst to best for me; the sheet remembers the minimum of the ratings for this set of actions. If this minimum at some stage (most often after the first check) turns out to be less than the worst estimate for the basic set of actions - the current set of actions cannot be exactly the best, subsequent simulations are not carried out with it;
- After all the simulations we look at the maximum value of the evaluation function in the leaves of the search tree. If it is more than the estimate of the base set - replace the base set with the new one found. Most often there remained the one that was found at the previous step (and slightly improved by additional search of the last two ticks).
Valdemar:
Surprised that the search of possible directions with a depth of 2 gave such a good result. Apparently the devil is in the details. The idea of a forest of trees with different parameters is very interesting, I have not seen anything similar before.
mortido:
Great! Climbing different options, it looks like a good distribution of time for calculations. Looks easy to implement. I'm not sure that the depth of 2 is enough in other competitions, where over 40-60 ticks you can perform a more complex action plan. I also like that for each of his moves up to 3 different moves of the opponent are checked.
n + m == const?
In the end, yes. When n + m != const, even the estimate neatly normalized by the number of moves did not lead to anything good. At danger, the bot chose a tree shorter, which is logical. And because of this, it turned out worse.
Evaluation function
Vladimir Kiselev (Valdemar) 4 place
Immediately it should be said that normalization was actively used in my evaluation. The values obtained from the simulator (machine tilt angle, speed, distance, etc.) were transferred to the range [0..1].
This made it possible to conveniently assemble various indicators and achieve fine-tuning of behavior. For example, scenarios such as were implemented: try to go faster, but only if the angle of inclination is not too large.
I don’t try to judge how much this chip influenced the success of the strategy as a whole, but one can say for sure that it helped during the debugging: the composite components of the evaluative were displayed in the log, which allowed to quickly understand why the bot behaves in a certain way.
So, in the evaluation were taken into account:
- tilt angle of the machine - the range was normalized from 70 to 180 degrees (hereinafter, the values that are not included in the range are cut to the corresponding boundary).
For the usual buggy, an extra bonus was also given if the enemy is tilted and airborne. - distances between the centers of machines in the range 0..500
- angular velocity - range [2pi, pi / 4] was displayed in [0, 1]
- proximity to the button - the formula takes into account the distance, the angle between the point and the center of the button (to encourage targeting to the center), the angle of the car (the bonus is not given if we are approaching from the bottom, because the button still does not press)
- The definition of a ram is a case when we drive in the direction of the enemy, he is turned to our bottom, and our hood is aimed at a point just below its front wheel.
The bonus is especially good for ordinary buggies, it allows you to determine when we can turn the enemy over. - speed - to a certain extent, encourage movement. Allows you to not stand still and generally play more actively.
- the difference between the minimum Y coordinate of the buttons is relevant when approaching the deadline.
- a big penalty if we lost and a big bonus for winning
The angle of inclination, proximity to the button and the ram were considered 2 times for me and the enemy and gave either a bonus or a penalty, respectively.
All components multiplied by different factors depending on the type of machine.
In the case of a regular buggy, a couple of cards were counted manually:
- on the “island” only acceleration towards the enemy was allowed, otherwise the probability of falling from the platform
- on the “island of the pit” was given a huge bonus for being on the launch pad, as statistics showed that descending into the pit often leads to defeat.
mortido:
Faster than me, because I made many requests to the engine, but they were very slow.
Commandos:
In general, the essence is similar to mine, the difference in details and the number of crutches. Maybe in some places better.
Alexander Kiselev (mortido) 3 place
I took most of the parameters for the evaluation function using requests to the chipmunk physics engine. These queries allowed finding different distances to the nearest objects or intersections of the object and the beam. Although the engine optimized them using its internal structures and caches, a large number of calls to it ultimately slowed down the simulation. Many components of the evaluation function had to be eliminated before the final.
Initially, I did one evaluation function, and only after writing a script to collect battle statistics, I divided it into 3 parts and head code added some fixes.
Here are some of the components that I was able to recall at the moment (I don’t think that an exact indication is fundamentally important, the main idea is the main idea):
- penalty for death. It is the largest and after it the simulation does not go any further, it is just assumed that we die in each subsequent tick (so the bot will try to postpone death for later, so that the total penalty is less);
- bonus for killing the enemy, the simulation goes on - it helps with misses on the button of the enemy when his movement is incorrectly predicted; the main reason for such blunders is that we use only 1 enemy behavior;
- speed bonus;
- the height difference between the lower points of the button (the closer to the match deadline, the stronger);
- the distance from the button to any obstacle (me with a “+” sign, an opponent with a “-” sign);
-distance from the button to the enemy (me with a “+” sign, an opponent with a “-” sign); a slightly controversial parameter, it allowed the machine to be positioned so that its button was kept safe, but this often reared the car and turned it over;
rays under 30 degrees from the button plane to look at the distance from them to the map, it helped a little not to roll over (but this is not accurate); - the rest of the hacks, mainly for protection against upheavals and correct positioning.
It is worth noting that when adding components one decayed in time, while others had a higher ratio closer to the end (for example, it is more profitable to be higher in the last tick and to descend slightly to accelerate now than to eagerly rise in the current)
Valdemar:
The idea of giving a larger ratio closer to the end is rather fragile. You can get into a situation where the bot will think “now I’ll stand, but through a tick I will start to accelerate to get a bigger bonus” and so several ticks in a row until the situation suddenly changes (the opponent made an unpredictable move, etc.) and the situation becomes much worse.
That was, he stood up to the last, so that, right on the thread from death, he began to take off. There were difficulties with that.
Commandos:
It’s not very clear why continue the simulation if the enemy is “dead” ... Maybe this is a crutch for the bus deadline? The idea of raising the bonus for the height of the machine at the end of the simulation could be tried, maybe it would “take off”.
Alexey Dichkovsky (Commandos) 1st place
The main evaluation function was done under SquaredWheelsBuggy, as under the most interesting with tz. games are a machine with which a variety of situations can occur. The evaluation function for a simple Buggy differed only in that it added a bonus for touching the opponent's wheel so that the enemy could not influence his angular speed (and often in such a situation just fell helplessly onto the roof / button).
Briefly:
- penalty for death;
- penalty per corner relative to the ground; if we have great speed and move upwards - the coefficient with which this fine worked varied from 1 to 0; so with a quick climb, the angle of the machine was not taken into account;
- penalty per corner relative to the opponent. I didn’t really want to be a button to the opponent; this angle was also considered with a shift in the position of the opponent by 10 ticks forward at current speeds (therefore, the machine finished setting the useless angle a little earlier in the hope of protecting itself from the opponent);
- penalty for the proximity of the wheels and some control points of the opponent to my button (its own optimized implementation without a request to the game engine, did not take into account the squareness of the wheels);
- bonus for the speed of the machine (believed that it was better to run around the map in the hope of an opponent's mistake);
- a small penalty for the distance to the opponent - slightly more often moved to the opponent than from him;
- penalty / bonus for height difference with an opponent; basically, the center of mass was considered to be the starting point, for a bus in a newer implementation - the lower point of the button; The new implementation of the estimated for the bus differed weakly and did not play on all the cards.
Points 1-5 were considered mirror for me and the opponent, with a different sign. In clause 2, the “climb factor” was not taken into account for the opponent.
Valdemar:
I think many have come to this, who at least a couple of days sat on the appraisal. All the magic in the search algorithm and the coefficients with which all these points are summed up.
mortido:
An interesting idea with an angle to the enemy, given his position after 10 ticks.
Crutches and IFs
Vladimir Kiselev (Valdemar) 4 place
Periodic collection of statistics on matches showed that certain cards on buses and buggies are always played on if-strategies. I began to pay attention to this approximately 3 days before the start of the finals, by that time the ideas for improving the evaluation had already ended, and the proximity of the top prize did not allow to give up and go for a rest. Therefore, heuristics were added next to the random search algorithm, which took control in certain machine-map combinations.
An important point: at the beginning of each tick, a check was made that said how “safe” to include heuristics - if the enemy quickly approaches us, or does something incomprehensible, or for unknown reasons, our car was in an unexpected position (for example, it flies down, although it must stand) - control takes the simulation.
At the mercy of ipham were given:
- Rack on the bumper for the bus. Because the stretching of the actions gave a slight swinging, which sometimes led to defeat from the deadline.
- Movement in the rack for the bus - it is important for the card with the pit, by oscillations with different amplitudes it was possible to ride on the bumper and at least guarantee a draw on this card.
- Hardcode initial ticks. Actually for the buggy on the “island with the pit” map and for the bus on most maps.
With the help of the visualizer, actions were calculated that allowed the strategies on the ifes to take an optimal position, after which these actions were shamelessly copied to themselves.
This approach is fragile and works only if the enemy does not approach and push, but the simulation was turned on for this case, so the sum worked well enough.
During operation, the heuristics were greatly helped by a simulator that provided additional information: speed and angular velocity. After the contest, it turned out that where I used this data, the participants in if used trigonometry and cunning calculations.
mortido:
Quiet tough hardcore grieved me when I first found out about it. Now this idea does not seem so bad in this competition.
Commandos: The
harsh reality of ifs. Plugging holes where it flows from a solution covering most situations ... I still tried to put more scripts on the evaluation function, but it took time, and the result was strange in places.
Alexander Kiselev (mortido) 3 place
This was written with great pain in the heart and attempts to disguise crutches in every possible way under some kind of logic.
First, 3 evaluation functions were separated. Each for their cars. Two of them were almost identical and differed by coefficients. For the “Loaf”, which was more profitable not to fight and just climb higher and stand in a defensive posture, its own function was written. There were even potential fields for a couple of cards that allowed her to drive up to a height, or jump on a mound.
I did not use hard ticker hardcode moves for cards, where I could copy the “best” solution from others. I poured this dirty trick into the evaluation function. Where, depending on the card, typewriter and tick, there could be slightly different tasks, for example, to minimize the distance of the front wheels to a particular point. And then the genetic algorithm tried to solve this problem. It worked much worse than hardcode, and it was almost impossible to set up and debug, because Random introduced many problems.
In disputes after the competition, where I scolded very hard ticks, I expressed that I could put up with them if these ticks were found locally by the same search algorithm, only with a huge margin of computation time. After I checked this option ... The genetic algorithm could not even find close good moves. In general, if something can be done simply and it works, it is necessary to do it, as a matter of principle, it often only hinders (but I am also for a healthy share of curiosity, in order to check other options).
Valdemar: It’s
interesting about potential fields, I didn’t even think about using them. The idea of adding an analogue of a tick-based hardcode to the search seems to be completely wrong. If we are talking about the principles and aesthetic “beauty” of the solution, then this approach is even worse than obvious ifs. And the fact that the genetic algorithm could not find good moves is not at all surprising - the participants with heuristics spent several days or even weeks searching for these moves.
I think you could still collect the opponent's moves from the replays of the games where you lost and add them + their mutations as a starting population. True, it sounds like a lot of time and code spent.
Commandos:
In this case ... If you want something to be done, do it yourself, and don't ask the appraisal to do it the way you want. Although I also killed a lot of time to do what I wanted through an appraisal, but in the end it was not very meaningful and the ticked hardcode would be simpler and more reliable.
Alexey Dichkovsky (Commandos) 1st place
I started hardcoding two weeks before the end of the competition. And the hardcode accumulated a huge amount (more than in any other competition that I wrote earlier). Basically, the entire hardcode was in the selection of coefficients (and additional components) for the card / machine combinations.
For example, on the pill carcass map for both buggies, the speed bonus greatly increased if I was at the bottom when the deadline was approaching, and I also added points for finding closer to the center of the upper crossbar (as well as the bonus for pushing away from the rival center). A very similar bonus was on the island map, where all that was required of us was to turn or push the enemy.
Also of the well-worked hardcodes was riding on the rear bumper on the island hole for buggy map. For this typewriter / map combination, the normal rating function was turned off until my strategy decided that the opponent went on the attack (is too close). If such a situation took place, the standard evaluation function was included. Also similar, and also not ideal implementation was on the same map, but for the bus. And for SquaredWheelBuggy, this card was fined for speeding up too high. Sometimes physics worked in such a way that the buggy just flew off into space, the evaluation function found it and believed that it would be better. The speed is big, we are higher than the opponent ... But until the moment when we die anyway, there was not enough simulation distance to calculate.
On one map (Pill map, Bus), the start was generally done with a tick-based hardcode and did not show up until the very last day of the competition in order to avoid copying, which was not difficult to do in this competition (according to the result, I have 100% wins on this combination of card / machine).
Also, the bus was successfully scripted for the pill hubble map. The script could work as correctly , and not very (in all examples, the first round), but I really liked it. Well, the statistics speak in his favor.
For the same buses, in total, there were two different evaluation functions on different maps - it was too lazy to test for all and tested only where corrections were required ...
The described moments do not cover the entire width of the cochylization, but allow us to understand its depth. But basically it is still the replacement of weights for different parts of the evaluation function and the addition of components that depend on a particular map. The benefit of the support of such crutches was built into the architecture initially (although it was slightly corrected after the fact).
Valdemar:
The specificity of the game is such that the hardcode action on some cards allows you to play perfectly - at least to achieve a draw with a couple of conditions. Hardcode looks awful, but at the same time incredibly effective.
mortido:
Well I patched the holes in the strategy while I was trying to write an “ideal” evaluation function.
Emotions
Valdemar:
The start of the contest was pretty boring. Creating a simulator required a lot of effort and experienced participants began to express opinions that we would not see anything interesting. Then the evenings began (and even a few nights) of constant improvements and it became much more fun.
I participate in such competitions for the sake of emotions and the pleasure of communication in the circle of the same fans of game AI. These “fanatics” who, after a working day at the computer, come home and modify the bot to the detriment of housework and, sometimes, sleep :) The
impressions are great, thanks to mailru for organizing such contests.
mortido:
Competitions of bots always bring a lot of emotions for me: when you watch how your bot starts to beat everyone and you just watch half the night fights, and then in the morning cool guys come and break his face ... I like the moments where your strategy starts to find solutions to which you I would not have thought of it (for example, like here with a wheel and a coup). Or when you throw a replay where your bot killed 3 teammates, and you pretend that it was an accident ... although it was a slightly different competition.
Commandos:
Strangely enough, I spent this competition, started crutches too early. And, perhaps, a little bit wrong. Although on the other hand ... crutches here a lot of weather and it became. But in the end, it affected the evaluation function - it was not very thoughtful, for which I almost paid.
Integration with chipmank killed - meticulous copying of the engine from the python in C ++. This time it was half the success. After writing the simulator for a long time I could not decide which side to approach to writing the bot. Then I saw in the top 1 mortidoand went to break his bot faceand decided to write at least something.
so
Hopefully, the article turned out to be interesting and we managed to reveal the similarity and variety of solutions. During the description of solutions, the authors had a lot of controversy and discussion on the optimality of certain approaches. Some of the discussions were added to the article, but if you have any questions, you can ask them here or in the off-line chat of the competition.
Special thanks to Dmitry and Mail.Ru Group for organizing the competition.
Bonus
Sources Valdemar
Sources mortido
Depository articles on the topic