Algorithms for optimizing a trading robot: an effective way to trade a million retroactively
I read an authoritative book on trading strategies and wrote my trading robot. To my surprise, the robot does not bring millions, even trading virtually. The reason is obvious: a robot, like a racing car, needs to be “tuned”, to select parameters adapted to a specific market, a specific time period.
Since the robot has enough settings, iterating over all their possible combinations in search of the best, too time-consuming task. At one time, solving the optimization problem, I did not find a reasonable choice of the search algorithm for the quasi-optimal vector of the parameters of the trading robot. Therefore, I decided to independently compare several algorithms ...
Brief statement of the optimization problem
We have a trading algorithm. Input data - price history of the hourly interval for 1 year of observation. Output data - P - profit or loss, scalar value.
The trading algorithm has 4 configurable parameters:
- Mf is the period of the “fast” moving average ,
- Ms period of the “slow” moving average
- T - TakeProfit, the target profit level for each individual transaction,
- S - StopLoss, the target loss level for each individual transaction.
We assign a range and a fixed change step to each of the parameters , a total of 20 values for each of the parameters.
Thus, we can search for the maximum profit (P) for one parameter on one array of input data:
- varying one parameter, for example, P = f (Ms), producing up to 20 backtests ,
- varying two parameters, for example, P = f (Ms, T), producing up to 20 * 20 = 400 backtests,
- varying three parameters, for example, P = f (Mf, Ms, T), producing up to 20 * 20 * 20 = 8,000 backtests,
- varying each of the parameters, P = f (Mf, Ms, T, S) and producing up to 20 ^ 4 = 160,000 backtests.
For most trading algorithms, however, it takes several orders of magnitude more time to conduct a single test. Which leads us to the task of finding a quasi-optimal vector of parameters without the need to iterate over the whole set of possible combinations.
details about trade and trading robots
Trading on the stock exchange, betting at the Forex dealing center, crazy bets on “binary options”, speculation with cryptocurrencies - a kind of “diagnosis”, with several possible options for the development of the “disease”. A very common scenario is when a player, after playing “intuition”, comes to automatic trading. Don’t get me wrong, I don’t want to put the emphasis in such a way that “technologically and mathematically” rigorous trading robots are opposed to naive and helpless “manual” trading. For example, I myself am convinced that any of my attempts to extract profit from an efficient market (read from any transparent and liquid market) through speculation, whether discretionary or fully automated, are a priori doomed to failure. If, perhaps, not to allow the factor of random luck.
However, trading, and in particular, algo (rhythmic) trading, is a popular hobby for many. Some independently program trading robots, others go even further and create their own platforms for writing, debugging and backtesting trading strategies, while others download / buy a ready-made electronic “expert”. But even those who do not write trading algorithms on their own, should have an idea of how to handle this “black box” in order to profit from it in accordance with the author’s idea. In order not to be unfounded, I give my further observations using an example of a simple trading strategy:
A trading robot analyzes the dynamics of the value of gold, in dollars per troy ounce, and decides to “buy” or “sell” a certain amount of gold. For simplicity, we assume that the robot always trades in one troy ounce.
For example, at the time of purchase, the cost of a troy ounce of gold was 1075.00 USD . At the time of the subsequent sale (closing of the transaction), the price increased to 1079.00 USD. Profit on this transaction amounted to 4 USD.
If the robot “sold” gold at 1075.00 USD, and subsequently completed (closed) the transaction by “buying” gold back at a price of 1079 USD, the profit on the transaction will be negative - minus 4 USD. Actually, it does not matter for us how the robot sells gold, which it does not have, in order to later “buy back” it. A broker / dealing center allows a trader to “buy” and “sell” an asset in one way or another, earning (or, more often, losing), on the difference in rates.
With inputfor the robot, we decided - this is, in fact, the time series of prices (quotations) of gold. If you say that my example is too simple, not vital - I can assure you: most of the robots that circulate in the market (and indeed the traders too) in their trading are guided only by the price statistics of the goods they trade. In any case, in the problem of parametric optimization of a trading strategy, there is no fundamental difference between a robot trading on the basis of the price vector and a robot accessing a terabyte array of multi-sorted market analytics. The main thing is that both of these robots can (should be able to) be tested on historical data. Algorithms must be determined: that is, on the same input data (model time, if necessary, we can also take as a parameter),
However, trading, and in particular, algo (rhythmic) trading, is a popular hobby for many. Some independently program trading robots, others go even further and create their own platforms for writing, debugging and backtesting trading strategies, while others download / buy a ready-made electronic “expert”. But even those who do not write trading algorithms on their own, should have an idea of how to handle this “black box” in order to profit from it in accordance with the author’s idea. In order not to be unfounded, I give my further observations using an example of a simple trading strategy:
Simple trading robot
A trading robot analyzes the dynamics of the value of gold, in dollars per troy ounce, and decides to “buy” or “sell” a certain amount of gold. For simplicity, we assume that the robot always trades in one troy ounce.
For example, at the time of purchase, the cost of a troy ounce of gold was 1075.00 USD . At the time of the subsequent sale (closing of the transaction), the price increased to 1079.00 USD. Profit on this transaction amounted to 4 USD.
If the robot “sold” gold at 1075.00 USD, and subsequently completed (closed) the transaction by “buying” gold back at a price of 1079 USD, the profit on the transaction will be negative - minus 4 USD. Actually, it does not matter for us how the robot sells gold, which it does not have, in order to later “buy back” it. A broker / dealing center allows a trader to “buy” and “sell” an asset in one way or another, earning (or, more often, losing), on the difference in rates.
With inputfor the robot, we decided - this is, in fact, the time series of prices (quotations) of gold. If you say that my example is too simple, not vital - I can assure you: most of the robots that circulate in the market (and indeed the traders too) in their trading are guided only by the price statistics of the goods they trade. In any case, in the problem of parametric optimization of a trading strategy, there is no fundamental difference between a robot trading on the basis of the price vector and a robot accessing a terabyte array of multi-sorted market analytics. The main thing is that both of these robots can (should be able to) be tested on historical data. Algorithms must be determined: that is, on the same input data (model time, if necessary, we can also take as a parameter),
Более подробно о торговом роботе можно почитать в следующем спойлере:
алгоритм торговли робота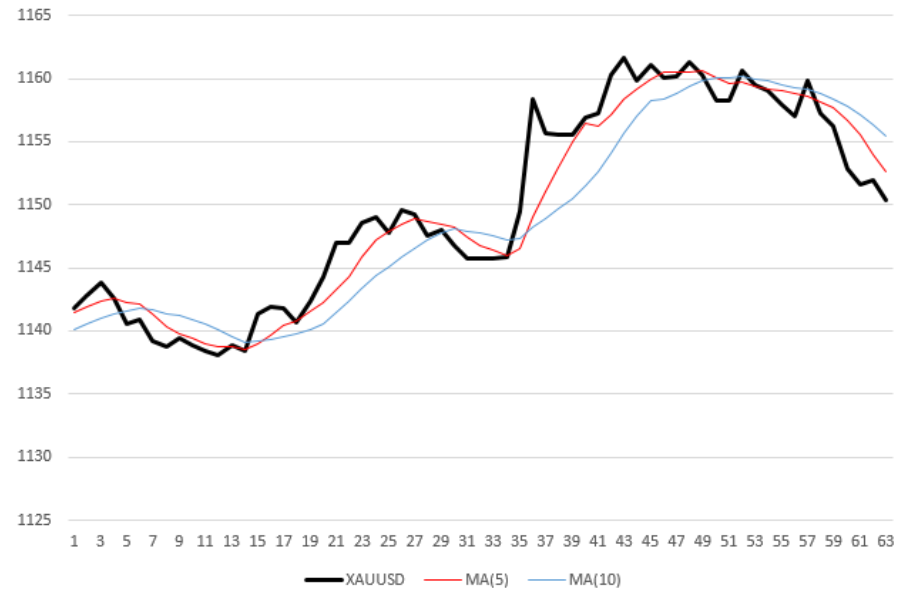
Черная (толстая) кривая на графике — часовые измерения цены XAUUSD. Две тонкие ломаные линии, красная и синяя — усредненные значения цены с периодами усреднения 5 и 10 соответственно. Иначе говоря, скользящие средние (Moving Average, MA) с периодами 5, 10. Например, для того, чтобы рассчитать ординату последней (правой) точки красной кривой, я взял среднее из последних 5 значений цены. Таким образом, каждая скользящая средняя не только “сглажена” относительно ценовой кривой, но и запаздывает относительно нее на половину своего периода.
The robot has a simple rule for making a buy / sell decision:
- as soon as a moving average with a short period (“fast” MA ) crosses a moving average with a long period (“slow” MA) from the bottom up, the robot buys an asset (gold).
As soon as the “fast” MA crosses the “slow” MA from top to bottom, the robot sells the asset. In the figure above, the robot will make 5 transactions: 3 sales at time stamps 7, 31 and 50 and two purchases (marks 16 and 36).
The robot is allowed to open an unlimited number of transactions. For example, at some point, the robot may have several pending purchases and sales at the same time.
The robot closes the deal as soon as:
Suppose StopLoss is 0.2%.
The deal is a “sale" of gold at a price of 1061.50.
As soon as the price of gold rises to 1061.50 + 1061.50 * 0.2% / 100% = 1063.12%, the loss on the deal will obviously be 0.2% and the robot will close the deal automatically.
The robot makes all decisions about opening / closing a transaction at discrete points in time - at the end of each hour, after the publication of the next XAUUSD quote.
Yes, the robot is extremely simple. At the same time, it 100% meets the requirements for it:
Using the example of our simple robot, it can be seen that a complete enumeration of all possible vectors of robot settings is too expensive even for 4 variable parameters. An obvious alternative to exhaustive search is the choice of parameter vectors for a specific strategy. We consider only part of all possible combinations in search of the best one, in which the CF approaches the highest (or smallest, depending on which CF we choose and what result we achieve).
Черная (толстая) кривая на графике — часовые измерения цены XAUUSD. Две тонкие ломаные линии, красная и синяя — усредненные значения цены с периодами усреднения 5 и 10 соответственно. Иначе говоря, скользящие средние (Moving Average, MA) с периодами 5, 10. Например, для того, чтобы рассчитать ординату последней (правой) точки красной кривой, я взял среднее из последних 5 значений цены. Таким образом, каждая скользящая средняя не только “сглажена” относительно ценовой кривой, но и запаздывает относительно нее на половину своего периода.
Правило открытия сделки
The robot has a simple rule for making a buy / sell decision:
- as soon as a moving average with a short period (“fast” MA ) crosses a moving average with a long period (“slow” MA) from the bottom up, the robot buys an asset (gold).
As soon as the “fast” MA crosses the “slow” MA from top to bottom, the robot sells the asset. In the figure above, the robot will make 5 transactions: 3 sales at time stamps 7, 31 and 50 and two purchases (marks 16 and 36).
The robot is allowed to open an unlimited number of transactions. For example, at some point, the robot may have several pending purchases and sales at the same time.
Deal closing rule
The robot closes the deal as soon as:
- profit on the transaction exceeds the threshold specified in percent - TakeProfit,
- or loss on the transaction, in percent, exceeds the corresponding value - StopLoss.
Suppose StopLoss is 0.2%.
The deal is a “sale" of gold at a price of 1061.50.
As soon as the price of gold rises to 1061.50 + 1061.50 * 0.2% / 100% = 1063.12%, the loss on the deal will obviously be 0.2% and the robot will close the deal automatically.
The robot makes all decisions about opening / closing a transaction at discrete points in time - at the end of each hour, after the publication of the next XAUUSD quote.
Yes, the robot is extremely simple. At the same time, it 100% meets the requirements for it:
- the algorithm is deterministic: every time, simulating the work of the robot on the same price data, we will get the same result,
- has a sufficient number of adjustable parameters, namely: the period of “fast” and the period of “slow” moving average (natural numbers), TakeProfit and StopLoss - positive real numbers,
- a change in each of the 4 parameters, in the general case, has a nonlinear effect on the trading characteristics of the robot, in particular, on its profitability,
- profitability of a robot on price history is considered an elementary program code, and the calculation itself takes a split second for a vector of thousands of quotes,
- finally, which, however, is irrelevant, the robot, with all its simplicity, in reality will prove to be no worse (albeit probably not better) than the Grail sold by the author on the Internet for an immodest amount.
Quick search for a quasi-optimal set of input parameters
Using the example of our simple robot, it can be seen that a complete enumeration of all possible vectors of robot settings is too expensive even for 4 variable parameters. An obvious alternative to exhaustive search is the choice of parameter vectors for a specific strategy. We consider only part of all possible combinations in search of the best one, in which the CF approaches the highest (or smallest, depending on which CF we choose and what result we achieve).
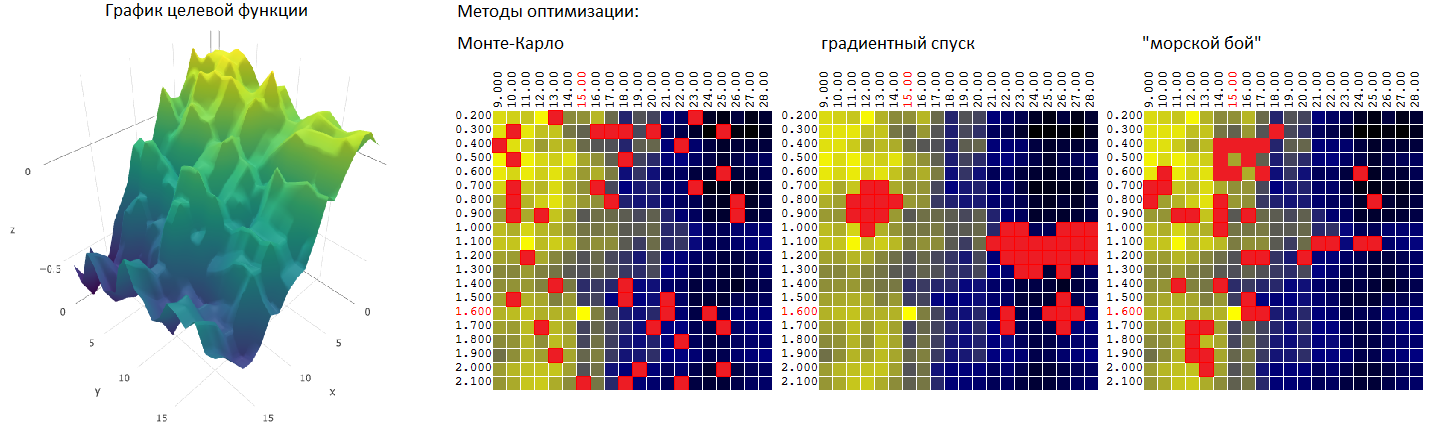
We will consider three search algorithms for the quasi- optimal value of the digital filter . For each algorithm, we set a limit of 40 tests (out of 400 possible combinations).
Monte Carlo Method
or a random selection of M uncorrelated vectors from among the possible number of sets equal to N. The method is probably the simplest possible. We will use it as a starting point for subsequent comparison with other optimization methods.
Example 1
the chart shows the dependence of the profit (P) of our trading robot trading EURUSD , obtained on the annual segment of the history of hourly price measurements, on the parameter value - the period of the “slow” moving average (M). All other parameters are fixed and are not optimized.
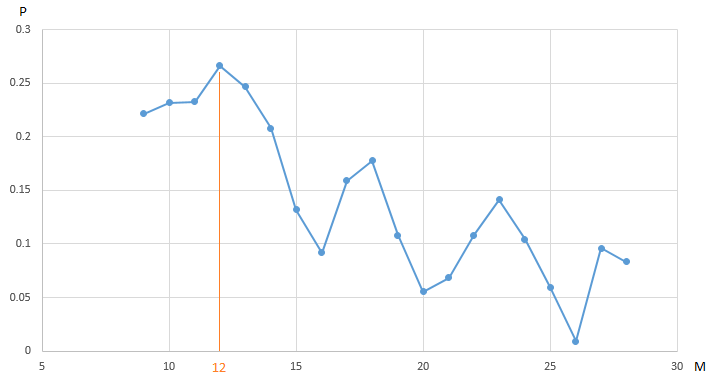
CF (profit) reaches a maximum of 0.27 at the point M = 12. In order to guarantee the maximum value of profit, we need to conduct 20 iterations of testing. An alternative is to conduct a smaller number of tests of a trading robot with a randomly selected value of the parameter M on the interval [9, 20]. For example, after 5 iterations (20% of the total number of tests, we found a quasi-optimal vector (vector, obviously, one-dimensional) of parameters: M = 18 with a value of CF (M) equal to 0.18:

The remaining values on the graph from our optimization algorithm were hidden by the “fog of war”.
Optimization of one of the four parameters of our trading robot, with fixed values of the remaining parameters, does not allow us to see the whole picture. Perhaps a maximum of 0.27 CF is not the best value of the indicator, if you vary the value of other parameters?

This is how the dependence of profit on the moving average period changes for various values of the TakeProfit parameter on the interval [0.2 ... 0.8].
Monte Carlo method: optimization of two parameters
Зависимость прибыли торгового робота от двух параметров графически можно изобразить в виде поверхности:

По двум осям отложены значения параметров T (TakeProfit) и M (период скользящей средней), третья ось — значение прибыли.
Для нашего торгового робота, проведя 400 тестов на интервале данных в один год (~6000 часовых котировок евро к доллару США), получим поверхность вида:

или, на плоскости, где значения ЦФ (прибыль, P) представлены цветом:

Выбирая произвольные точки на плоскости, в данном примере алгоритм не нашел оптимального значения, но подобрался довольно близко к нему:

Насколько эффективен метод Монте-Карло в поиске максимума ЦФ? Проведя 1 000 итераций поиска максимума ЦФ на исходных данных из примера выше, я получил следующую статистику:
- the average value of the maximum of the DF found during 1,000 optimization iterations (40 random vectors of parameters [M, T] out of 400 possible combinations) was 0.231 or 95.7% of the global maximum of the DF (0.279).
Obviously, in comparing the methods of parametric optimization of trading robots, one sample is not an indicator. But for now, this assessment is enough. We proceed to the next method - the gradient descent method .
Gradient descent method
Formally, as the name implies, the method is used to search for the minimum of the DF.
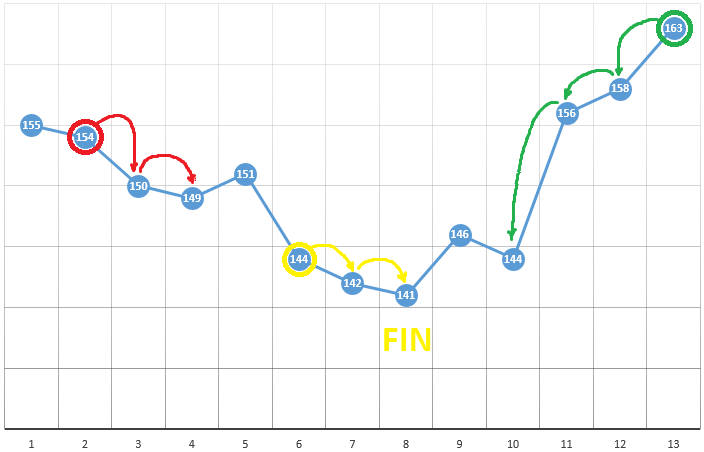
According to the method, we select the starting point with coordinates [x0, y0, z0, ...]. On the example of optimization of one parameter, this can be a randomly selected point:
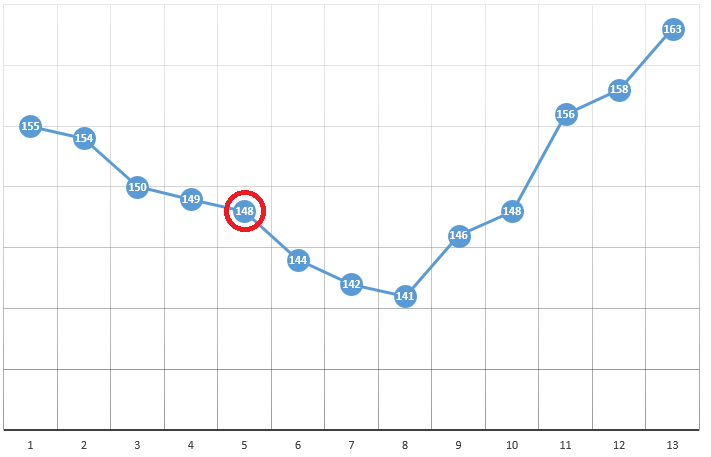
with coordinates [5] and a DF value of 148. Three simple steps follow:
- check CF values in the vicinity of the current position (149 and 144)
- move to the point with the smallest CF value
- if this is absent, a local extremum is found, the algorithm is completed

To optimize the DF as a function of two parameters, we use the same algorithm. If earlier we calculated the CF at two neighboring points
![$ [x_ {i-1}], [x_ {i + 1}] $](https://habrastorage.org/getpro/habr/formulas/73f/598/5da/73f5985da1cb6a42d9d5c3ba4eeb3afc.svg) , now we check 4 points:
, now we check 4 points: ![$ [x_ {i-1}, y_i], [x_ {i + 1}, y_i], [x_i, y_ {i-1}], [x_i, y_ {i + 1}]. $](https://habrastorage.org/getpro/habr/formulas/7fe/1d2/8f3/7fe1d28f361772bf6abec1870ebb0e0b.svg)
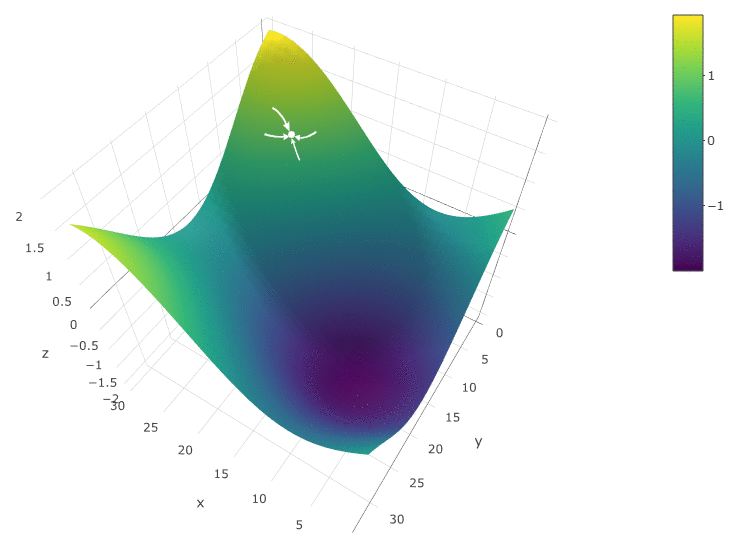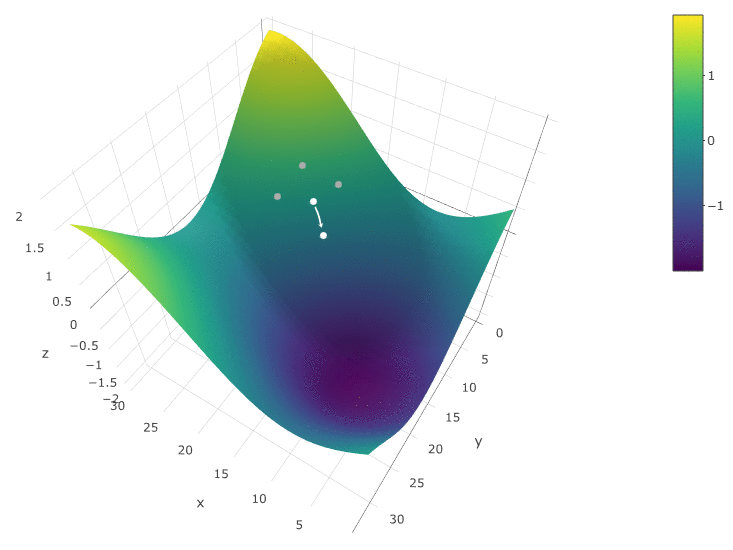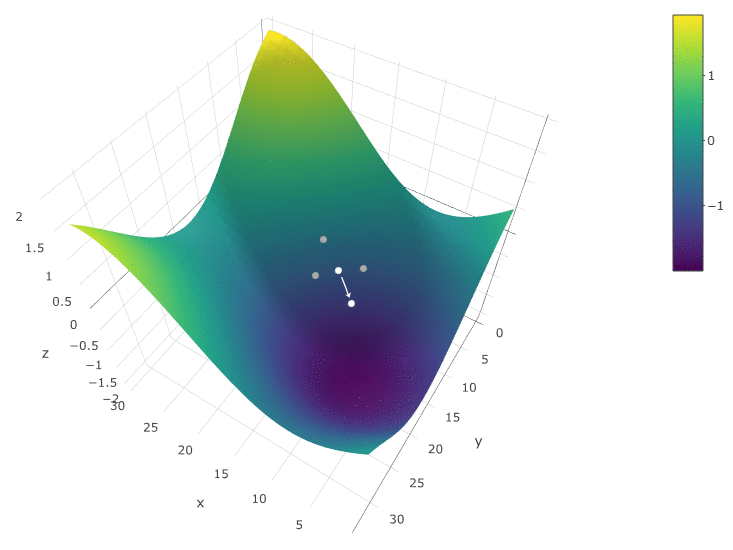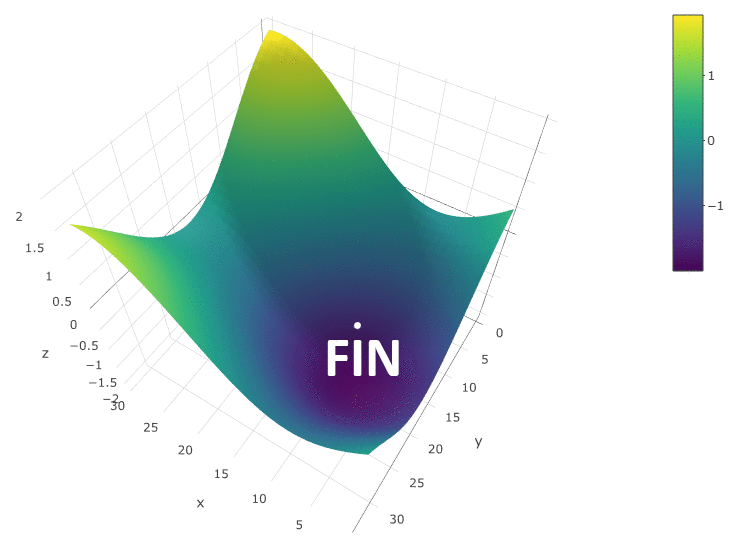
The method is definitely good when there is only one extremum in a DF in a test space. If there are several extrema, the search will have to be repeated several times in order to increase the likelihood of finding a global extremum:
In our example, we are looking for the maximum DF. To stay within the definition of the algorithm, we can assume that we are searching for a minimum of “minus DF”. All the same example, the profit of a trading robot as a function of the period of the moving average and the TakeProfit value, one iteration:
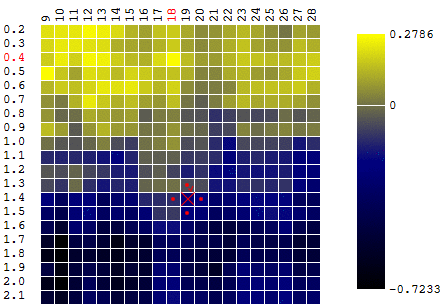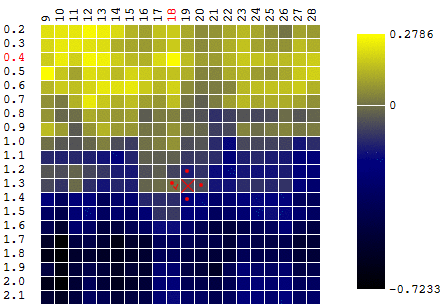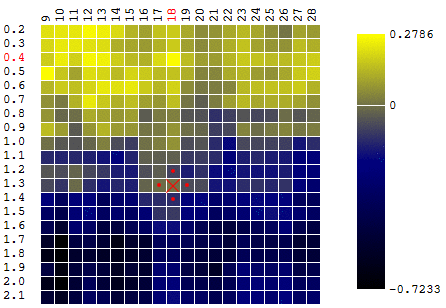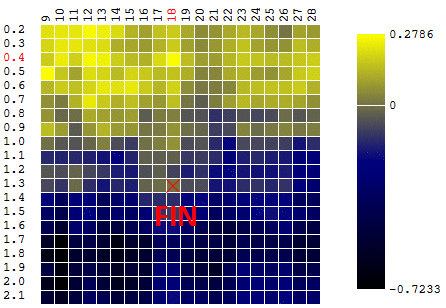
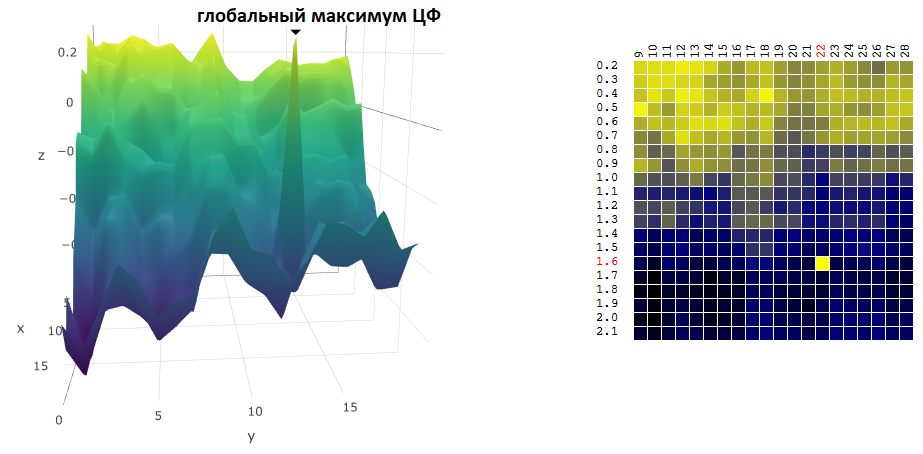
In this case, a local extremum was found that is far from the global maximum of the CF. An example of several iterations of the search for the extremum of the FS by the gradient descent method, the value of the FS is calculated 40 times (40 points out of 400 possible):

Now, we compare the efficiency of searching for the global maximum of the CF (profit) on our initial data using Monte Carlo and gradient descent algorithms. In each case, 40 tests are carried out (CF calculations). 1,000 optimization iterations were performed by each of the methods:
| Monte Carlo | gradient descent | |
|---|---|---|
| the average of the obtained quasi-optimal value of CF | 0.231 | 0.200 |
| the obtained value from the maximum of the CF | 95.7% | 92.1% |
As you can see from the table, in this example, the gradient descent method is worse at its task - to search for the global extremum of the digital asset - the maximum profit. But we are not in a hurry to discard it.
Parametric stability of the trading algorithm
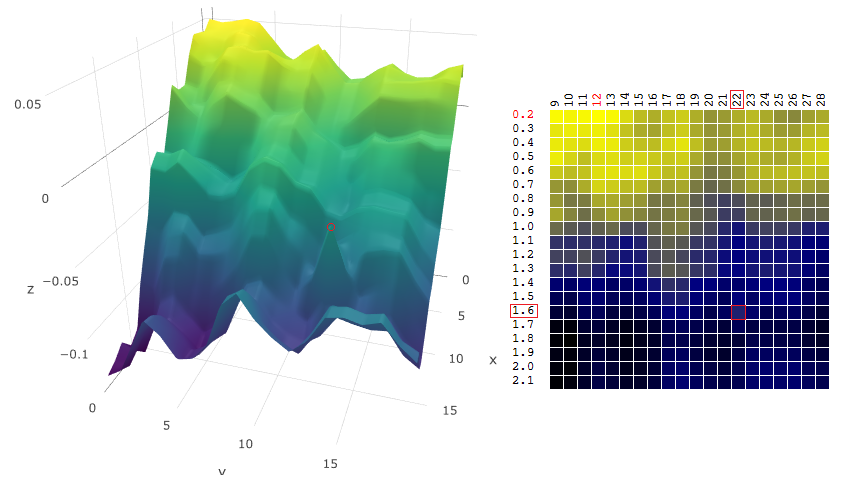
Finding the coordinates of the global maximum / minimum of a digital filter is often not an optimization goal. Suppose, on the chart, there is a “sharp” peak - a global maximum, the value of the DF in the vicinity of which is much lower than the peak value:
Suppose we chose the settings of the trading robot that correspond to the found DF maximum. Should we slightly change the value of at least one of the parameters - the period of the moving average and / or TakeProfit - the profitability of the robot will drop sharply (become negative). With regard to real trading, one can at least expect that the market in which our robot is to trade will be noticeably different from the period of history in which we optimized the trading algorithm.
Therefore, when choosing the “optimal” settings of a trading robot, it’s worth getting an idea of how sensitive the robot is to changes in settings in the vicinity of the found extremum point of the DF.
Obviously, the gradient descent method, as a rule, gives us the values of TF in the vicinity of the extremum. The Monte Carlo method is more likely to hit squares.
In multiple instructions for testing automated trading strategies, after optimization is completed, it is recommended to check the target indicators of the robot in the vicinity of the found parameter vector. But these are additional tests. In addition, what if the profitability of the strategy drops with a slight change in settings? Obviously, you have to repeat the testing process.
An algorithm would be useful for us, which, at the same time as searching for the extremum of the CF, would allow us to evaluate the stability of the trading strategy to change settings in a narrow range with respect to the peaks found. For example, do not directly search for the maximum CF

and the weighted average value that takes into account the neighboring values of the objective function, where the weight is inversely proportional to the distance to the neighboring value (to optimize two parameters x, y and the objective function P):



In other words, when choosing a quasi-optimal vector of parameters, the algorithm will evaluate the “smoothed” objective function:
it
became
The method of "sea battle"
Trying to combine the advantages of both methods (Monte Carlo and the gradient descent method), I tried an algorithm similar to the algorithm of the game in the “sea battle”:
- first, I strike a few “blows" over the entire area
- then, in places of “hits” I open massive fire.
In other words, the first N tests are carried out on random uncorrelated vectors of input parameters. Of these, the M best results are selected. In the vicinity of these tests (plus - minutes 0..L to each of the coordinates) another K tests are carried out.
For our example (400 points, 40 tests in total) we have:
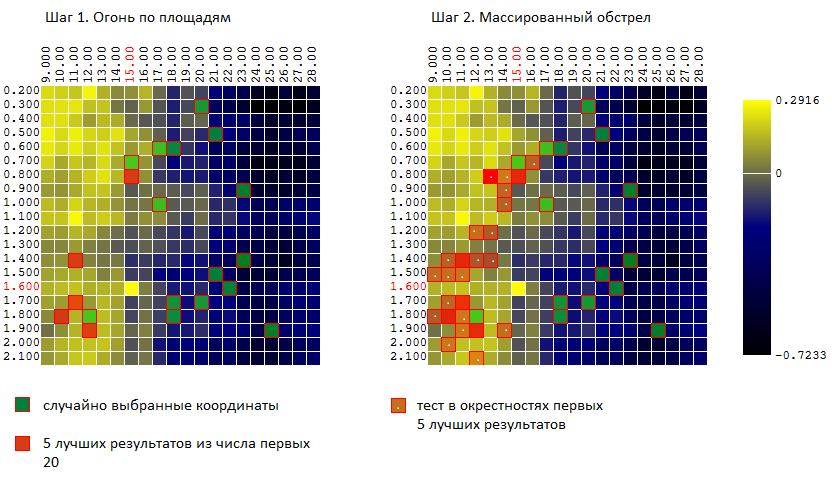
And again, we compare the effectiveness of now 3 optimization algorithms:
| Monte Carlo | gradient descent | “Sea battle” | |
|---|---|---|---|
| The average value of the found extremum of the CF as a percentage of the global value. 40 tests, 1,000 optimization iterations | 95.7% | 92.1% | 97.0% |
The result is encouraging. Of course, the comparison was carried out on one specific data sample: one trading algorithm on one time series of the value of the euro against the US dollar. But, before comparing the algorithms on more samples of the source data, I’m going to talk about another, unexpectedly (unjustifiably?) Popular algorithm for optimizing trading strategies - the genetic algorithm (GA) optimization. However, the article came out too voluminous, and the GA will have to be postponed to the next publication .