Using Ansible, Terraform, Docker, Consul, Nomad in the Clouds (Alexey Vakhov, Uchi.ru)
This article is a transcript of the video report by Alexei Vakhov from Uchi.ru “Clouds in the Clouds”
Uchi.ru - an online platform for school education, more than 2 million schoolchildren regularly have interactive classes with us. All our projects are hosted completely in public clouds, 100% of applications run in containers, starting from the smallest, for internal use, and ending with large productions for 1k + requests per second. It so happened that we have 15 isolated docker clusters (not Kubernetes, sic!) In five cloud providers. Fifteen hundred user applications, the number of which is constantly growing.
I will tell very specific things: how we switched to containers, how we managed the infrastructure, problems we encountered, what worked and what didn't.
During the report, we will discuss:
- Technology motivation and business features
- Tools: Ansible, Terraform, Docker, Github Flow, Consul, Nomad, Prometheus, Shaman - web-interface for Nomad.
- Using Cluster Federation to Manage Distributed Infrastructure
- NoOps rollouts, test environments, application diagrams (almost all developers do their own changes)
- Entertaining stories from practice
Who cares, I ask under the cat.
My name is Alexey Vakhov. I work as a technical director in the company Uchi.ru. We are hosted in public clouds. We actively use Terraform, Ansible. Since then, we have completely switched to Docker. Very pleased. How satisfied, how satisfied we are, I will tell.

Company Uchi.ru engaged in the production of products for school education. We have a main platform on which children solve interactive tasks in various subjects in Russia, in Brazil, in the USA. We hold online competitions, contests, clubs, camps. Every year this activity grows.

From the engineering point of view, the classic web stack (Ruby, Python, NodeJS, Nginx, Redis, ELK, PostgreSQL). The main feature that many applications. Applications are hosted worldwide. Every day there are rollouts in production.
The second feature is that our schemes change very often. Ask to raise a new application, stop the old one, add cron for background jobs. Every 2 weeks there is a new Olympiad - this is a new application. All this needs to be accompanied, monitored, backed up. Therefore, the environment is superdynamic. Dynamism is our main difficulty.
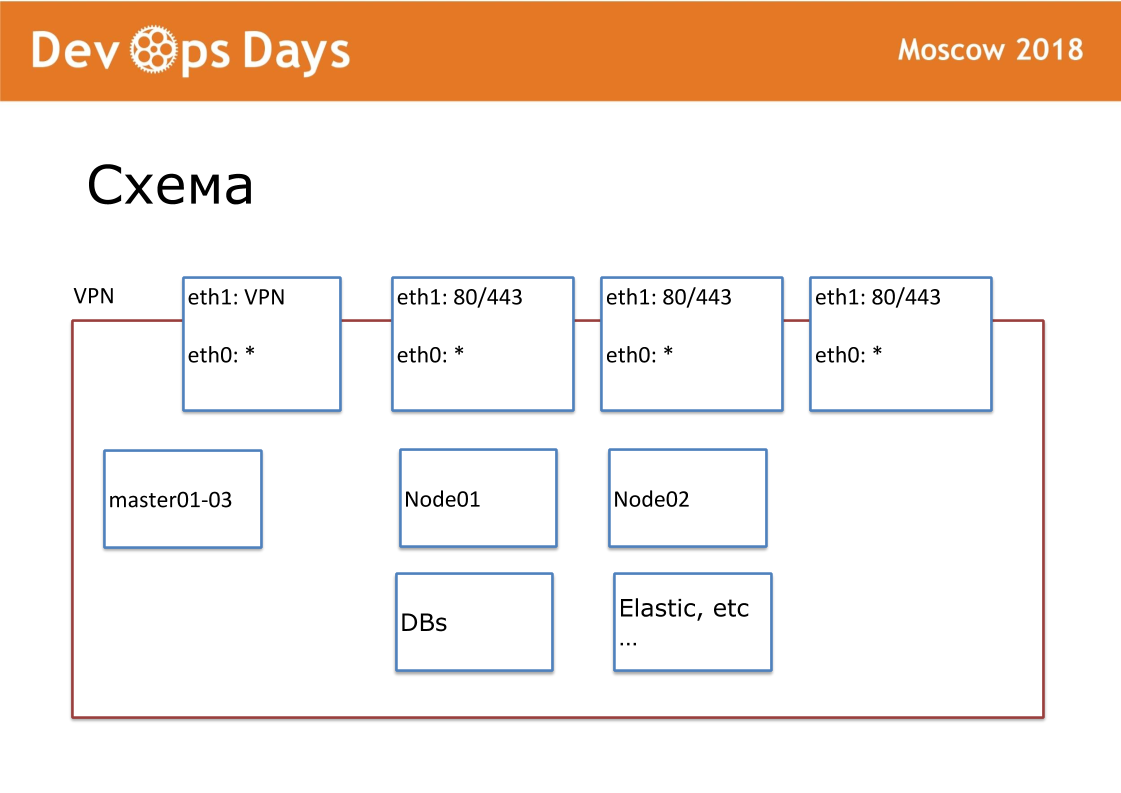
Our work unit is a playground. In terms of cloud providers, this is Project. Our site is a completely isolated entity with an API and private subnet. When we enter the country, we look for local cloud providers. Not everywhere is Google and Amazon. Sometimes there are no API to the cloud provider. Outside we publish VPN and HTTP, HTTPS on balancers. All other services communicate within the cloud.

Under each site we have created our own Ansible repository. In the repository there are hosts.yml, playbook, roles and 3 secret folders, about which I will continue to talk. This is a terraform, provision, routing. We are fans of standardization. Our repository should always be called "site ansible-name." We standardize each file name, internal structure. This is very important for further automation.

Terraform a year and a half ago, set up, so we use it. Terraform without modules, without file structure (flat structure is used). Terraform file structure: 1 server - 1 file, network configuration and other settings. Using terraform, we describe servers, disks, domains, s3-buckets, networks, and so on. Terraform at the site fully prepares the iron.

Terraform creates a server, then ansibl rolls these servers. Due to the fact that we use the same version of the operating system everywhere, we all wrote the roles from scratch. Ansible roles for all operating systems that do not work anywhere are usually published on the Internet. We all took Ansible roles and left only what we need. Standardized Ansible Roles. We have 6 basic playbooks. When you run Ansible sets the standard list of software: OpenVPN, PostgreSQL, Nginx, Docker. Kubernetes we do not use.

We use Consul + Nomad. These are very simple programs. Run 2 programs written in Golang on each server. Consul is responsible for Service Discovery, health check, and key-value configuration storage. Nomad is responsible for scheduling, for rolling out. Nomad launches containers, provides rollouts, including rolling-update on health check, allows you to run sidecar-containers. Cluster is easy to expand or vice versa. Nomad supports distributed cron.
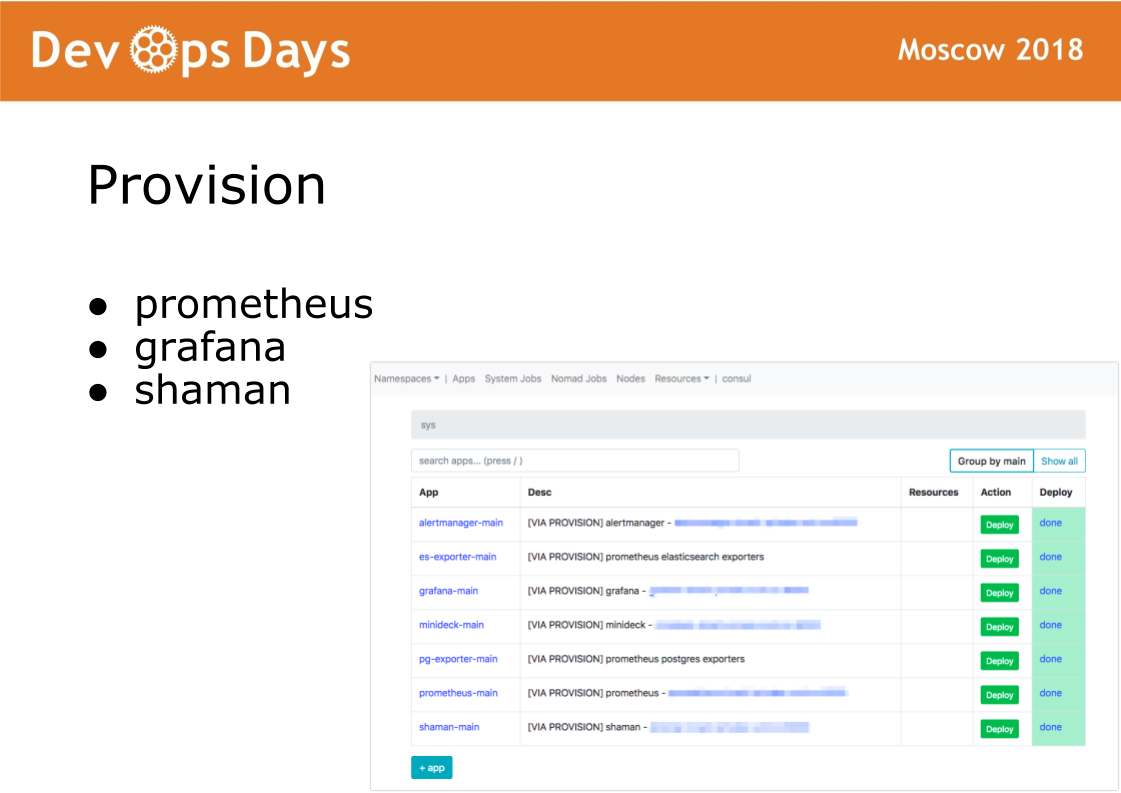
After we enter the site, Ansible executes a playbook located in the provision directory. A playbook in this directory is responsible for installing the software in the docker cluster that administrators use. Installed prometheus, grafana and secret software shaman.
Shaman is a web-dashboard for nomad. Nomad is low-level and I don’t really want to let developers to it. In shaman, we see a list of applications, developers issue a button for application deployment. Developers can change configurations: add containers, environment variables, start services.
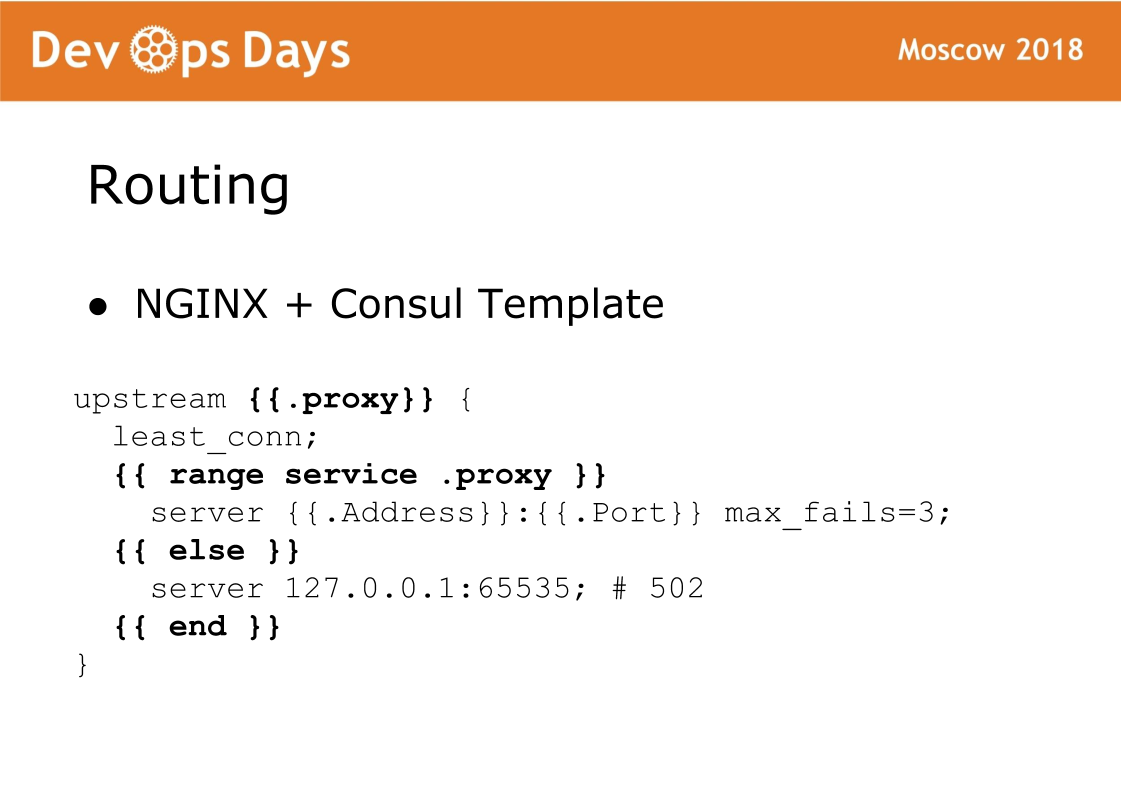
Finally, the final component of the site is routing. Routing is stored in our K / V storehouse of the consul, that is, there is a bunch between upstream, service, url and so on. On each balancer, the Consul template rotates, which generates the nginx config and reloads it. Very reliable thing, we never had a problem with it. The chip of such a scheme is that the traffic accepts the standard nginx and you can always see which config was generated and work as with the standard nginx.

Thus, each site consists of 5 layers. With the help of a terraform, we set up the hardware. Ansible we perform basic server configuration, set up a docker cluster. Provision rolls system software. Routing directs traffic inside the site. Applications contains user applications and administrator applications.
We have been debugging these layers for quite a while so that they are as identical as possible. Provision routing match 100% between sites. Therefore, for developers, each site is exactly the same.
If IT professionals switch from project to project, then they end up in a completely typical environment. In ansible we could not make identical the settings of the firewall, VPN for different cloud providers. With the network, all cloud providers work differently. Terraform is different, because it contains specific constructions for each cloud provider.
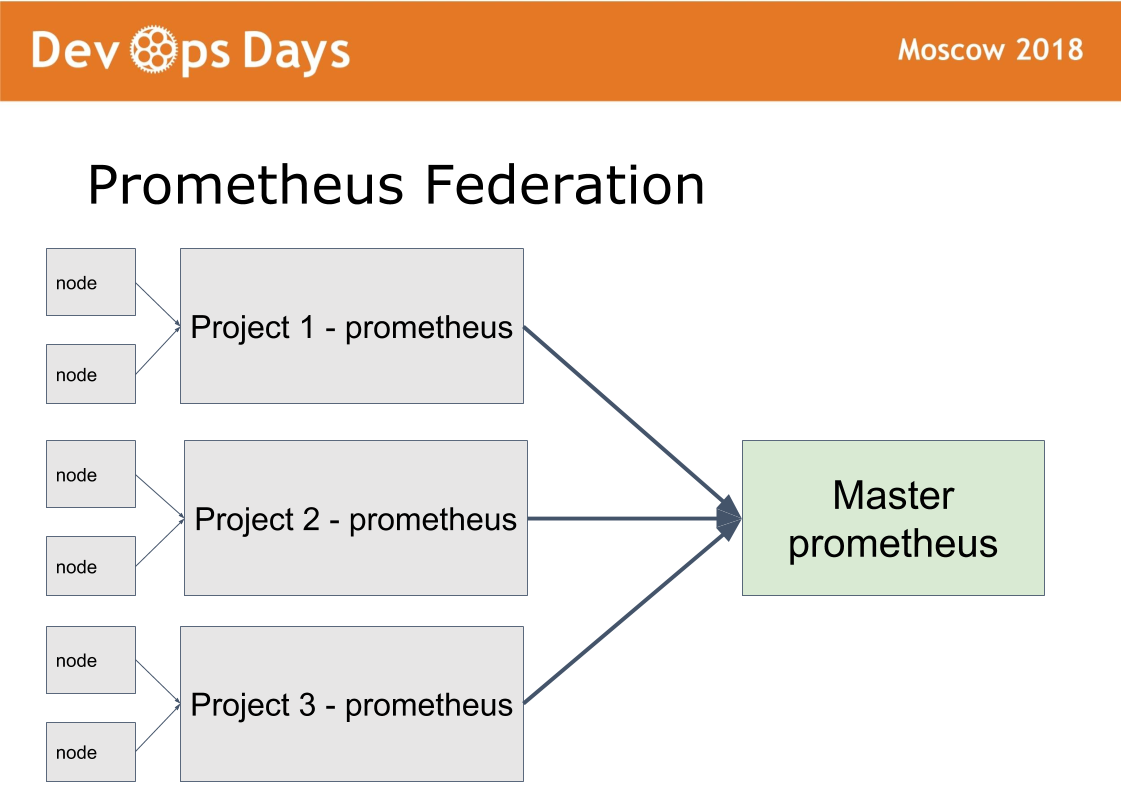
We have 14 production sites. The question arises: how to manage them? We made the 15th master platform, in which we let only admins. It works according to the federation scheme.
The idea was taken from prometheus. In prometheus there is a mode when in each site we install prometheus. Prometheus publish outside through HTTPS basic auth authorization. Prometheus master takes only the necessary metrics c removed prometheus. This makes it possible to compare application metrics in different clouds, to find the most downloaded or unloaded applications. Centralized notification (alerting) goes through the prometheus master for admins. Developers receive alerts from local prometheus.

The same scheme is configured shaman. Administrators can deploy through the main site, configure it on any site through a single interface. A sufficiently large class of problems is solved without leaving this master site.

I'll tell you how we switched to docker. This process is very slow. We moved about 10 months. In the summer of 2017, we had 0 containers of production. In April 2018, we have documented and rolled out our latest application in production.

We are from the world of ruby on rails. There used to be 99% of Ruby on Rails applications. Rails rolls out through Capistrano. Technically, Capistrano works in the following way: the developer starts cap deploy, capistrano enters all application servers via ssh, picks up the latest version of the code, collects asset, migrates the database. Capistrano simulates a new version of the code and sends a USR2 signal to the web application. On this signal, the web server picks up a new code.
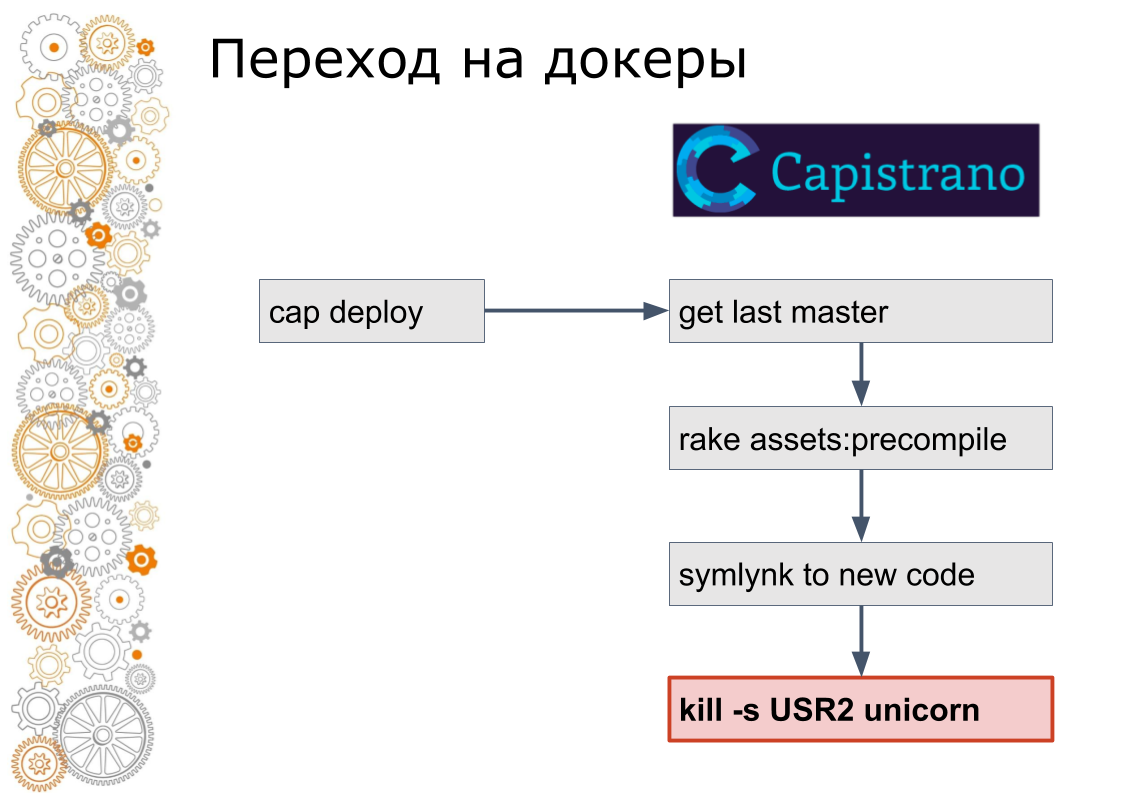
The last step in the docker is not done that way. In the docker you need to stop the old container, raise the new container. Then the question arises: how to switch traffic? In the cloudy world, service discovery is responsible for this.

Therefore, we added consul to each site. Consul was added because they used Terraform. We wrapped all the nginx configs in the consul template. Formally, the same thing, but we were already ready to dynamically control the traffic inside the sites.

Next, we wrote a ruby script that collected an image on one of the servers, pushed it into the registry, then went in ssh to each server, picked up new ones and stopped the old containers, registering them with the consul. The developers also continued to launch cap deployments, but the services were already working in docker.
I remember that there were two versions of the script, the second one turned out to be quite advanced, there was a rolling update when a small number of containers stopped, new ones were raised, the consul helfchieks waited and moved on.

Then they realized that this is a dead end way. The script has increased to 600 lines. The next step is manual scheduling, we replaced Nomad. Hiding from the developer details of the work. That is, they still called cap deploy, but inside was a completely different technology.
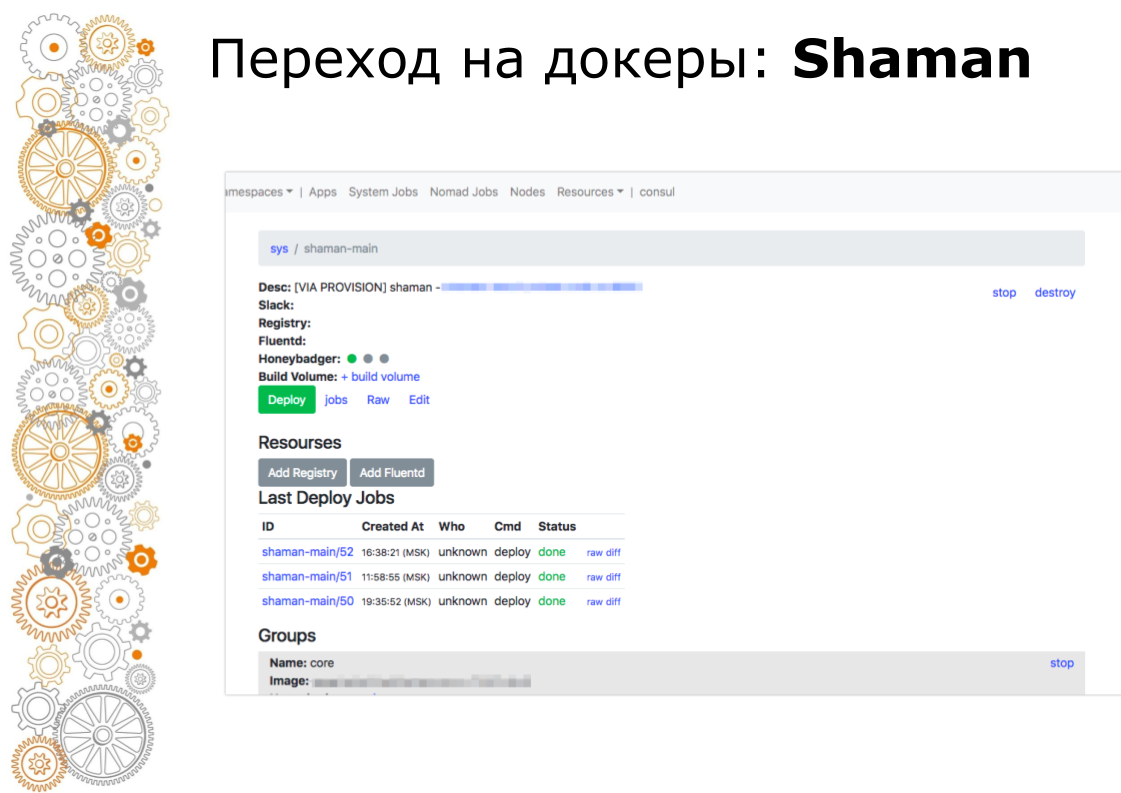
And in the end, we moved the deployment to the UI and took away access to the servers, leaving the green deployment button and management interface.
In principle, such a transition was certainly a long one, but we avoided a problem that I met quite a few times.
There is some kind of legacy stack, system or something like that. Khachinnaya already just in rags. The development of a new version begins. After a couple of months or a couple of years, depending on the size of the company, in the new version less than half of the required functionality was implemented, and the old version still ran into prered. And that new one also became very legacy. And it's time to start a new, third version from scratch. In general, this is an endless process.
Therefore, we always move the entire stack. In small steps, crooked, with crutches, but entirely. We can not update for example the docker engine on one site. It is necessary to update everywhere, since there is a desire.

Roll out. All docker instructions are rolling out 10 nginx containers or 10 redis containers into docker. This is a bad example, because the images have already been collected, the images are easy. We packed our rails applications into docker. The size of docker images was 2-3 gigabytes. They do not roll out so quickly.
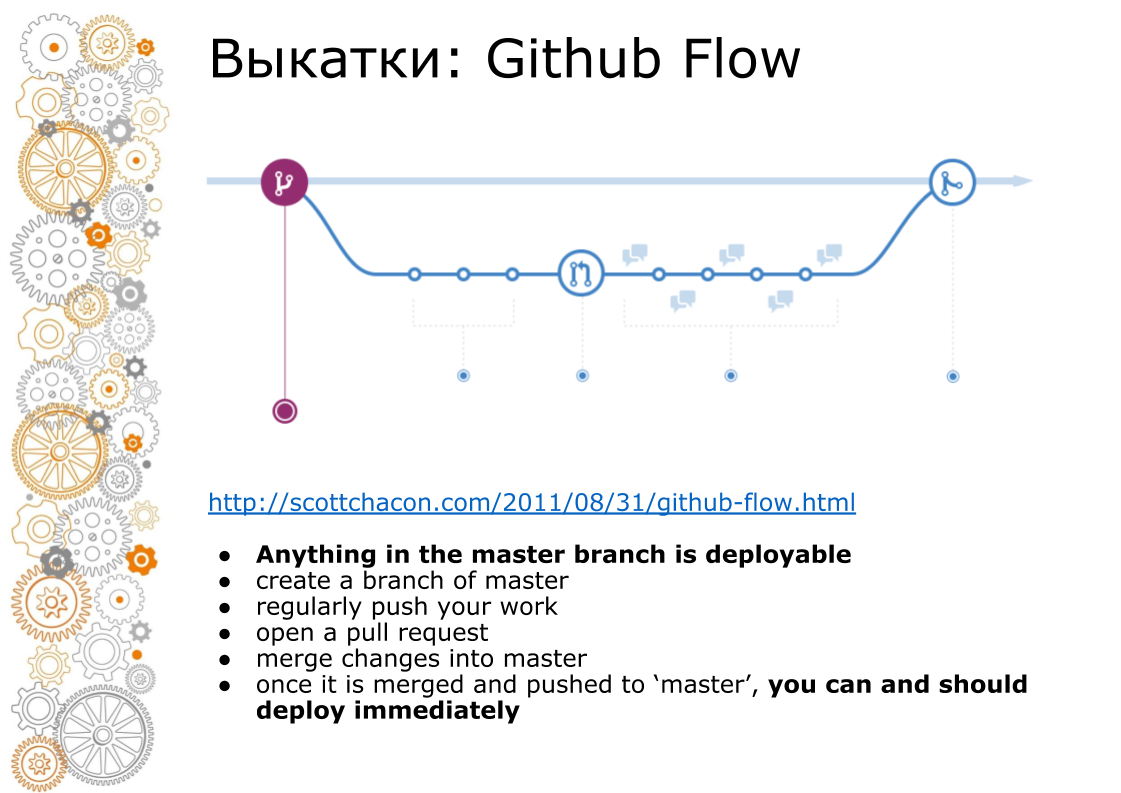
The second problem came from the hipster web. Hipster web is always Github Flow. In 2011, there was a landmark post that Github Flow rules, so the whole web rolls. What does this look like? The master branch is always production. When adding a new functionality, we make a branch. When doing a merge, we do code-review, we run tests, raises the staging environment. Business looks staging environment. At time X, if everything is successful, then we merge the branch to master and roll it out into production.
It worked perfectly on capistrano, because it was created for that. Docker always sells us pipeline. Collected container. The container can be transferred to the developer, tester, transferred to production. But at the moment of merge in the master code is different. All docker images that were collected from the feature-branch are not collected from the master.

How are we done? We collect image, we put it in local docker registry. And after that we do the rest of the operations: migrations, deploy in production.

To quickly assemble this image, we use Docker-in-Docker. On the Internet, everyone writes that this is an anti-pattern, it kreshitsya. We had nothing like this. How many already working with him never had any problems. We forward the / var / lib / docker directory to the main server using Persistent volume. All intermediate images are on the main server. Build a new image within a few minutes.

For each application we make a local internal docker registry and our own build volume. Because docker saves all the layers on the disk and is difficult to clean. Now we know the disk utilization of every local docker registry. We know how much disk it requires. You can receive alerts through a centralized Grafana and clean. While we clean their hands. But we will automate it.

One more thing. Docker-image collected. Now this image needs to be decomposed into servers. When copying a large docker image, the network does not cope. In the cloud we have 1 Gbit / s. A global plug-in occurs in the cloud. Now we deploy a docker image on 4 heavy production servers. The graph shows the disk worked on 1 pack of servers. Then the second pack of servers is deployed. Bottom can be seen recycling channel. Approximately 1 Gbit / s we almost pull out. More there is not particularly particularly accelerated.

My favorite production is South Africa. There is a very expensive and slow iron. Four times more expensive than in Russia. There is very bad internet. Internet modem level, but not buggy. There we roll out applications in 40 minutes, taking into account tyunig caches, timeout settings.

The last problem that worried me before the docker contacted was the load. In fact, the load is the same as without a docker with an identical iron. The only nuance we rested just one point. If from the Docker engine to collect logs via the built-in fluentd driver, then at a load of about 1000 rps the internal buffer fluentd started to litter and requests begin to slow down. We carried out logging in sidecar containers. In nomad, this is called log-shipper. Near the large container of the application hangs a small container. The only task for him to take logs and send it to a centralized repository.

What were the problems / solutions / challenges. I tried to analyze what the task was. The features of our problems are:
- many independent applications
- constant changes to the infrastructure map
- Github flow and large docker images

Our solutions
- Federation of docker clusters. In terms of handling hard. But docker is good in terms of rolling out business functionality in production. We work with personal data and we have certification in each country. In an isolated area, such certification is easy to pass. During certification, all questions arise: where are you hosted, how is your cloud provider, where do you store personal data, where do you back up, who has access to the data. When everything is isolated, the circle of suspects is much easier to describe and follow all this much easier.
- Orchestration. It is clear that kubernetes. He is everywhere. But I want to say that Consul + Nomad is quite a production solution.
- Build images. Quickly collect images in Docker-in-Docker.
- When using Docker, it is also possible to hold a load of 1000 rps.
Development direction vector
Now one of the big problems is the desynchronization of software versions on the platforms. Previously, we set up the server by hand. Then we became devops engineers. Now configure the server using ansible. Now we have total unification, standardization. Introduce the usual thinking in the head. We can not fix PostgreSQL hands on the server. If you need some kind of fine tuning on exactly 1 server, then we think how to extend this setting everywhere. If not standardized, then there will be a zoo settings.
I am delighted and very glad that we get out of the box for free a really very pleasant infrastructure.

You can add me on facebook. If we do something new good, I'll write about it.
Questions:
What is the advantage of Consul Template over Ansible Template, for example, for setting firewall rules and other things?
Answer: Now we have traffic from external balancers going straight to the containers. There is no one intermediate layer. A config is created there that forwards the IP addresses and ports of the cluster. We also have all the balancing settings in K / V in Consul. We have an idea to give routing settings to developers through a secure interface so that they don’t break anything.
Question: Regarding the homogeneity of all sites. Are there really no requests from business or from developers that need to roll out something non-standard on this site? For example, tarantool with cassandra.
Answer: It happens, but it is a very big rarity. This we make out an internal separate artifact. There is such a problem, but it is rare.
Question: The solution to the delivery problem is to use the private docker registry in each site and from there you can quickly get docker images.
Answer: All the same, the deployment will rest on the network, since we decompose the docker image on there 15 servers simultaneously. We run into the net. Inside the network 1 Gbit / s.
Question: Are such a huge number of docker containers based on roughly the same technology stack?
Answer: Ruby, Python, NodeJS.
Question: How often do you test or check your docker images for updates? How do you solve update problems, for example, when glibc, openssl needs to be fixed in all docker?
Answer: If you find such an error, vulnerability, then we sit down for a week and fix it. If you need to roll out, then we can roll out the whole cloud (all applications) from scratch through the federation. We can click through all the green buttons for application deployment and go away to drink tea.
Question: Are you going to release your shaman in opensource?
Answer: Andrew here (pointing at a person from the audience) promises us to lay out a shaman in the fall. But there you need to add support for kubernetes. Opensource should always be better.