A translator from a machine, or how to teach an MFP to translate documents
Hi% username%!
Recently, we, ABBYY LS , together with Xerox launched the Xerox Easy Translator Service - a service that allows you to get a machine translation of a document - for this you need to scan it using an MFP based on Xerox ConnectKey technology or take a photo with your phone’s camera. Through the same platform, you can order a professional translation.
How it works? Let's figure it out!

The user scans, photographs or downloads the finished file via the Web. The file is saved in the database, after which it begins to be parsed into segments - objects that store fragments of text (as a rule, these are sentences), and information about the layout of these fragments. Files in graphic formats are pre-recognized using ABBYY Recognition Server . Before sending a document for recognition, we ask the user what language the document is written in. An image can be recognized without this, however, indicating the language of the source document will allow you to recognize it faster and better.
In the process of integration with the Recognition Server, we needed to choose processing parameters for our document flow: the format for exporting the results, the ratio speed / quality of recognition suitable for us, and the type of document assembly.
We now use the “old man” .doc as the export format, since at the moment it most fully describes the Rich text and at the same time solves a number of problems associated with the layout of elements on the page during segmentation (hello, .docx!). Nevertheless, the transition to .docx is in the plans. The relationship between speed and quality caused the most controversy. On the one hand, the quality of recognition is the highest priority for machine translation of a document, since the whole process is automated, and there is no way to attract typesetting specialists. On the other hand, the main advantage of MT (machine translation) is its speed (especially in the scenario when the user is waiting for a printed translation near the MFP), but you have to pay for the speed with quality. Nevertheless, the choice was made in favor of quality.
The type of document assembly determines which elements of the source document will fall into the file with the result. You can limit the recognition result to plain text (this option does not suit us, since non-textual information important for understanding the context will be lost), you can save the formatting of this text (is it better, but what about important non-textual information?). Type editable copysaves text with formatting and non-text content, but without reference to pages. It would seem that the layout of the pages is broken - and this is a minus. But since the length of the words can vary significantly during translation (for example, the German translation of the word “friendship” is “Freundschaftsbezeigungen”), the absence of linking to the pages of the source file allows you to avoid situations where blocks with text “hit” other page elements, as well as when The text of the translation cannot be entered in the block sizes of the source text. Latest Exact Copy Optionsaves both text with formatting and non-text content. At the output, we have a document that is as close as possible to the original in terms of page layout. This option looks more solid from the point of view of formats that support pagination (pdf, djvu), but the translation may be “overboard”. As a result, we opted for Editable Copy .
The source code

example of Exact Copy

Example EditableCopy

Further, the recognized file goes through the already mentioned segmentation, and for segments comprising the first 1000 characters of the document, the language of the text is automatically detected. Despite the fact that we have already asked the user to specify the language of the document when downloading the file, we still carry out auto-detection, since when working through the API, setting the language is not necessary for graphic formats, and not at all when loading text-format documents. Knowing the language, we can calculate the statistics for the document: the number of pages, words, characters. After that, the service sends blocks of document segments through the machine translation API (MT-API) to one of several MT engines. Upon completion of the translation, the document is collected, and a notification is sent to the user.
Machine Translation Example:
Original Image

Result

I want to note that, despite the fact that machine translation technology is still far inferior in quality to professional, it copes well with the task of quickly translating large amounts of information when an understanding of the general provisions of the document is required. Another frequency scenario is understanding the relevant pieces of the source text, which can then be translated more carefully. Nevertheless, we are taking steps to improve the quality of machine translation through the use of translation memory databases, which we will talk about below.
If the user needs a better translation, he can make an order for professional translators. In this case, the file path will be slightly different:
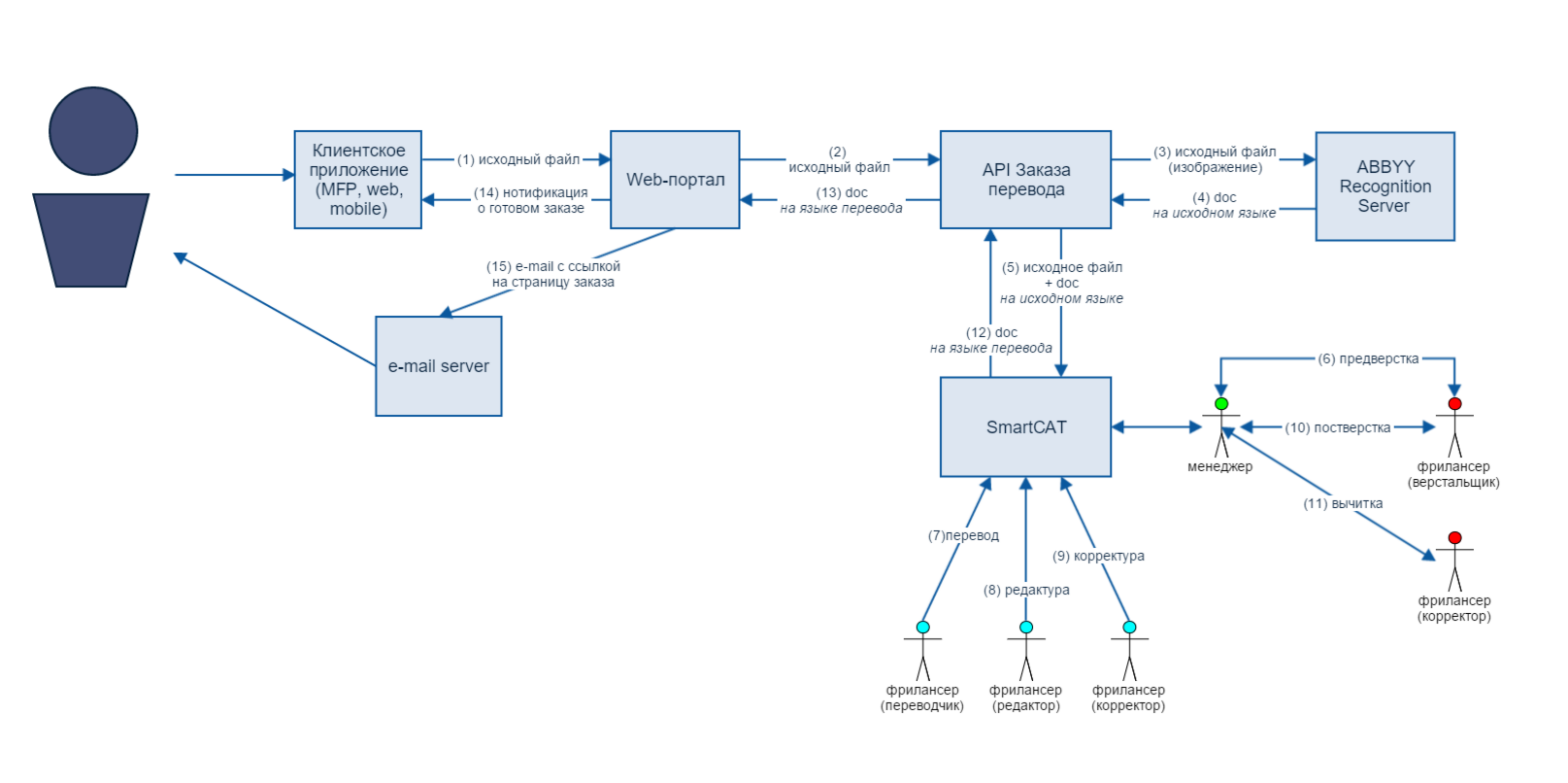
The text that was obtained as a result of recognition on the Recognition Server, together with the original document, is sent to SmartCAT- a platform for automating the translation process. The source file is needed so that non-textual content is available during translation, which may contain information that is important for maintaining the translation context. But before the document reaches the translator himself, the manager checks to see if he needs a preliminary layout, and, if necessary, attracts layout specialists. Only then performers are appointed. Directly in the editor, the translator has access to both the machine translation engines and the Translation Memory databases, which can reduce the time spent on the document. When the translation is completed, it is edited, subtracted and checked again by the manager. And now the translation is completed, and the user receives an email alert and a file with a high-class result.
Translation Example:
Original Image

Result

How is it all arranged inside? Good question!

Do you like puff cakes? We love, and the infrastructure of our application can be represented as such a cake:

Each piece is made up of dll assemblies that implement a specific feature, for example, FileManagement - file management. Libraries are also divided into layers: Contracts, Web API, Data Storage, Task Processing. During the separation, the CQRS principle was implemented - command-query responsibility segregation, according to which the method should be either a command that performs some action or a query that returns data, but not simultaneously. In other words, asking a question should not change the answer ( wiki ).
Contracts
The contract assembly stores the interfaces through which the application modules interact, as well as the commands and requests that the described feature operates on. These assemblies are used by other layers of the same set of functionality (for example, file management is FileManagement.Api and FileManagement.Processing) and other features (order management uses file management).
Web API
Everything is simple here - the API method called by the consumer initiates the execution of commands, requests, or their combinations, and gives the result to the user.
Data storage
Data storage. The assembly subscribes to the execution of commands and requests of certain types and performs the modification or reading of data. We use MongoDB for these purposes, but since working with data is carried out through commands and queries, the rest (not Data Storage) assemblies can only guess about the documentary essence of the database.
Task Processing
Performing lengthy operations. Like the data storage assembly, this assembly subscribes to the call of certain commands, however, the real time of the start of processing such a command is regulated by the scheduler. Such commands are called tasks. Parsing a file into segments is one such task.
The tree of the whole project looks like this:

Such a division into layers and features allows you to flexibly increase the functionality of ourcakeapplications, adding more and more tasty useful features.
And that's all for today, until we meet again.
Recently, we, ABBYY LS , together with Xerox launched the Xerox Easy Translator Service - a service that allows you to get a machine translation of a document - for this you need to scan it using an MFP based on Xerox ConnectKey technology or take a photo with your phone’s camera. Through the same platform, you can order a professional translation.
How it works? Let's figure it out!
Machine translate
The user scans, photographs or downloads the finished file via the Web. The file is saved in the database, after which it begins to be parsed into segments - objects that store fragments of text (as a rule, these are sentences), and information about the layout of these fragments. Files in graphic formats are pre-recognized using ABBYY Recognition Server . Before sending a document for recognition, we ask the user what language the document is written in. An image can be recognized without this, however, indicating the language of the source document will allow you to recognize it faster and better.
In the process of integration with the Recognition Server, we needed to choose processing parameters for our document flow: the format for exporting the results, the ratio speed / quality of recognition suitable for us, and the type of document assembly.
We now use the “old man” .doc as the export format, since at the moment it most fully describes the Rich text and at the same time solves a number of problems associated with the layout of elements on the page during segmentation (hello, .docx!). Nevertheless, the transition to .docx is in the plans. The relationship between speed and quality caused the most controversy. On the one hand, the quality of recognition is the highest priority for machine translation of a document, since the whole process is automated, and there is no way to attract typesetting specialists. On the other hand, the main advantage of MT (machine translation) is its speed (especially in the scenario when the user is waiting for a printed translation near the MFP), but you have to pay for the speed with quality. Nevertheless, the choice was made in favor of quality.
The type of document assembly determines which elements of the source document will fall into the file with the result. You can limit the recognition result to plain text (this option does not suit us, since non-textual information important for understanding the context will be lost), you can save the formatting of this text (is it better, but what about important non-textual information?). Type editable copysaves text with formatting and non-text content, but without reference to pages. It would seem that the layout of the pages is broken - and this is a minus. But since the length of the words can vary significantly during translation (for example, the German translation of the word “friendship” is “Freundschaftsbezeigungen”), the absence of linking to the pages of the source file allows you to avoid situations where blocks with text “hit” other page elements, as well as when The text of the translation cannot be entered in the block sizes of the source text. Latest Exact Copy Optionsaves both text with formatting and non-text content. At the output, we have a document that is as close as possible to the original in terms of page layout. This option looks more solid from the point of view of formats that support pagination (pdf, djvu), but the translation may be “overboard”. As a result, we opted for Editable Copy .
The source code
example of Exact Copy
Example EditableCopy
Further, the recognized file goes through the already mentioned segmentation, and for segments comprising the first 1000 characters of the document, the language of the text is automatically detected. Despite the fact that we have already asked the user to specify the language of the document when downloading the file, we still carry out auto-detection, since when working through the API, setting the language is not necessary for graphic formats, and not at all when loading text-format documents. Knowing the language, we can calculate the statistics for the document: the number of pages, words, characters. After that, the service sends blocks of document segments through the machine translation API (MT-API) to one of several MT engines. Upon completion of the translation, the document is collected, and a notification is sent to the user.
Machine Translation Example:
Original Image
Result
I want to note that, despite the fact that machine translation technology is still far inferior in quality to professional, it copes well with the task of quickly translating large amounts of information when an understanding of the general provisions of the document is required. Another frequency scenario is understanding the relevant pieces of the source text, which can then be translated more carefully. Nevertheless, we are taking steps to improve the quality of machine translation through the use of translation memory databases, which we will talk about below.
Professional Translation
If the user needs a better translation, he can make an order for professional translators. In this case, the file path will be slightly different:
The text that was obtained as a result of recognition on the Recognition Server, together with the original document, is sent to SmartCAT- a platform for automating the translation process. The source file is needed so that non-textual content is available during translation, which may contain information that is important for maintaining the translation context. But before the document reaches the translator himself, the manager checks to see if he needs a preliminary layout, and, if necessary, attracts layout specialists. Only then performers are appointed. Directly in the editor, the translator has access to both the machine translation engines and the Translation Memory databases, which can reduce the time spent on the document. When the translation is completed, it is edited, subtracted and checked again by the manager. And now the translation is completed, and the user receives an email alert and a file with a high-class result.
Translation Example:
Original Image
Result
How is it all arranged inside? Good question!
Cake is not a lie!
Do you like puff cakes? We love, and the infrastructure of our application can be represented as such a cake:
Each piece is made up of dll assemblies that implement a specific feature, for example, FileManagement - file management. Libraries are also divided into layers: Contracts, Web API, Data Storage, Task Processing. During the separation, the CQRS principle was implemented - command-query responsibility segregation, according to which the method should be either a command that performs some action or a query that returns data, but not simultaneously. In other words, asking a question should not change the answer ( wiki ).
Contracts
The contract assembly stores the interfaces through which the application modules interact, as well as the commands and requests that the described feature operates on. These assemblies are used by other layers of the same set of functionality (for example, file management is FileManagement.Api and FileManagement.Processing) and other features (order management uses file management).
Web API
Everything is simple here - the API method called by the consumer initiates the execution of commands, requests, or their combinations, and gives the result to the user.
Data storage
Data storage. The assembly subscribes to the execution of commands and requests of certain types and performs the modification or reading of data. We use MongoDB for these purposes, but since working with data is carried out through commands and queries, the rest (not Data Storage) assemblies can only guess about the documentary essence of the database.
Task Processing
Performing lengthy operations. Like the data storage assembly, this assembly subscribes to the call of certain commands, however, the real time of the start of processing such a command is regulated by the scheduler. Such commands are called tasks. Parsing a file into segments is one such task.
The tree of the whole project looks like this:
Such a division into layers and features allows you to flexibly increase the functionality of our
And that's all for today, until we meet again.