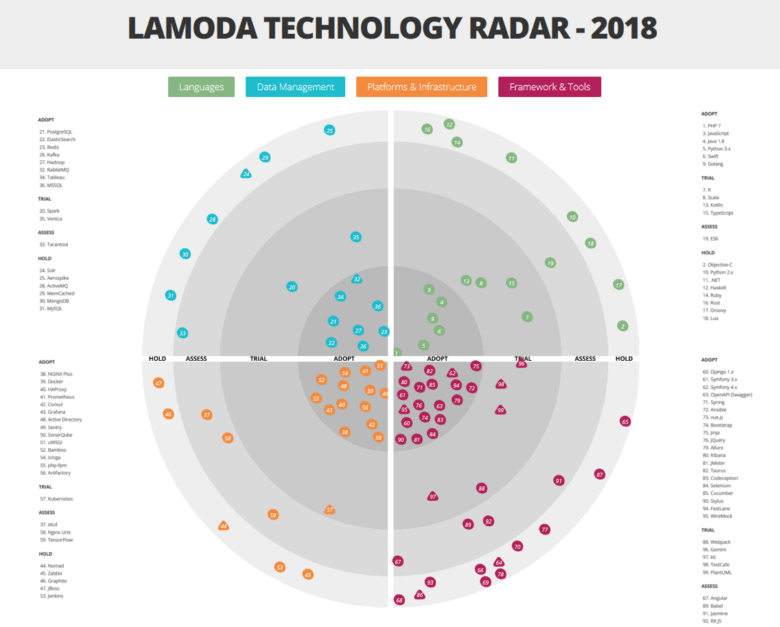
Radar technology: a list of languages, tools and platforms that have passed through the hands of Lamoda
In the comments to our previous article there were many questions about the technologies we use. In this article, I - Igor Mosyagin, R & D developer Lamoda - will talk about them. Under the cut you will find an exhaustive list of languages, tools, platforms and technologies that have passed through our hands. Front-end, back-end, database, message brokers, caches and monitoring, development and balancing - a detailed story about what we use today, and what we have refused.
My colleagues and I are ready to discuss in comments or on the company's stand at HighLoad ++ 2018.
Consider the radar large and detailed here.
As we have said, a huge number of different technologies and tools are involved in Lamoda. And this is not by chance. Otherwise, we can not cope with the load! We have a large automated warehouse. Our call-center is served by 500 employees, and the processes we have built up allow us to call the customer back within 5 minutes after placing the order. Our delivery service operates at 15-minute intervals. But besides our own systems, we have B2B integration with other online stores. With such a variety of tasks and the requirements of such a dynamic business as e-commerce, the growth of the technical stack is inevitable, because we want to solve every problem with the most appropriate technologies. Diversity is inevitable. On the main representatives of our stack, we describe below. But let's start with the mechanisms that allow us not to “get lost” in this diversity.
We are actively moving in the direction of microservice architecture. Most of the systems have already been built in accordance with this ideology - two years ago we went through a transitional stage with our problems and their solutions. But we will not dwell on the details of this process here - Andrei Evsyukov’s report “ Features of microservices on the example of an e-Com platform ” will tell much more about this .
In order not to aggravate technological diversity, we have introduced a “dictatorship of tried and tested practices,” according to which the creators of new chips are encouraged to use those technologies and tools that are already involved somewhere in the company. Most services communicate with each other through an API (we use our modification of the second version of the JSONRPC standard), but where business logic allows, we also use a data bus for interaction.
The use of other technologies is not prohibited. However, any new idea should be tested in a specially created architectural committee, which includes the leaders of the main directions.
Considering the next proposal, the committee either gives the go-ahead to the experiment, or offers some kind of replacement from the already existing stack. By the way, this decision largely depends on the current circumstances in the business. For example, if a team comes on the eve of the Black Friday sale and announces that it will be introducing into production a technology that the committee has never heard of before, it will most likely be refused. On the other hand, the same experiment can be given a green light if a new technology or tool is introduced in less critical business circumstances, and the implementation will begin with testing out of production.
The architecture committee is also responsible for maintaining the Technology radar, making the necessary changes once every 2-3 months. One of the purposes of this resource is to give the teams an idea of what kind of expertise is already in the company.
But let's move on to the most interesting - to the analysis of the sectors of our radar.
It is worth noting that we use a slightly non-standard interpretation of the categories of adoption of technology:
The first important language for us to stay in is PHP. Today, it solves only a part of the backend's tasks, and initially the entire backend worked on PHP. As business scaled on the front end, there was a noticeable lack of speed and performance - then we also used PHP 5, so Python came to replace it (first 2.x and then 3.x). However, PHP allows you to write rich business models, so this language remained in the back office for automating various operational processes, in particular, integration with third-party online stores or delivery services, as well as automating the content studio that makes out product cards. Now we are using PHP 7. In PHP, we have written many libraries for internal use: integration and wrappers over our infrastructure, integration layer between services, various reusable helpers. The first batch of libraries have already begun to make open source onour github.com , will soon reach the rest, the most "ripe". One of the first was the state machine, which, being present in almost all applications, ensures that all necessary actions are taken with the order before shipment.
Over time, Python for the backend store also became insufficient. Now we prefer the more productive and lightweight Go.
Perhaps the transition to Go was an important change, because it allowed us to save a lot of hardware and human resources - the efficiency increased significantly. The first to do the first Go projects were RnD, they didn’t want to fight the technical limitations of Python. Then, in the mobile development team, people appeared who were well acquainted with him and promoted him to production. With their submission, we conducted tests and were more than satisfied with the result. In separate cases, after part of the project was rewritten from Python to Go, the cluster node load dropped significantly. For example, rewriting the discount calculation engine for the Python basket from Go made it possible to process 8 times more requests for the same hardware capacity, and the average API response time decreased 25 times. Those. Go turned out to be more efficient than Python (if you write on it correctly),
Since mobile development had to interact with dozens of internal APIs, a code generator was created that, according to the service API description (according to Swagger specification), a client on Go can generate. So, Go gradually began to correspond with existing services and tools, especially those that created a bottleneck for the load. In addition to simplifying the life of a mobile backend developer, we have simplified following internal agreements on how to develop an API, how to call methods, how to pass parameters, and the like. Such standardization has made the development and implementation of new services easier for all teams.
Today, Go is already used almost everywhere - in all real-time interactions with users - in the backend of the site and mobile applications, as well as the services with which they are associated. And where there is no need for fast processing and response, for example, in interaction tasks with the data warehouse, Python remained, since it has no equal for data processing tasks (although there is a Go penetration here).
As seen on the radar, we have Java in the asset. It is used in the warehouse automation system (WMS - Warehouse Management System), helping to collect orders faster. So far we have a fairly old stack and an old architecture model there — a monolith spinning on Wildfly 10 and 8 Java Hotspot, and there is also a remoting and Rich client on the Netbeans Application Platform(now this functionality is transferred to the web). Here, in our arsenal, we have standard storage facilities for the company and even our own monitoring. Unfortunately, we did not find a tool that can visualize well the work of the warehouse and important processes on it (when a section is overloaded, for example), and we made such a tool ourselves.
We use Python as the main language for machine learning: we build recommender systems and rank the catalog, correct typos in search queries, and also solve other tasks in conjunction with Spark on the Hadoop cluster (PySpark). Python helps us automate the calculation of internal metrics and AB testing.
Front-end desktop online store, as well as mobile sites written in JavaScript. Now the frontend is gradually moving to the ES6 specification, creating new projects in accordance with it. We use vue.js as the main framework, but we’ll dwell on it in the tools section.
Mobile application development is a separate unit in the company, which includes backend groups, as well as Android and iOS applications with their own technology stacks and tools, which, due to platform differences, are not always able to unify across the unit.
For two years now, all the new Android development has been going on at Kotlin, which allows us to write more concise and understandable code. Among the most commonly used features, our developers call: smartcast, sealed-classes, extension-functions, typesafe-builders (DSL), stdlib functionality.
iOS development is being done on Swift, which replaced Objective-C.
The range of tasks of Lamoda is not limited to developing “showcases” for different platforms, respectively, we have a number of languages that are used only within their systems, they work well there, but will not be implemented in other parts of the infrastructure:
Like many, most different databases are implemented on PostgreSQL - it is used everywhere where relational databases are needed, for example, to store a directory. Specialists in this technology are quite easy to find, and in addition, many different services are available.
Of course, PostgreSQL is not the only DBMS that can be found in our IT infrastructure. On some older systems, for example, MySQL is used, while WMS has a bit of MongoDB. However, for high loads and scaling (taking into account the rest of our technology stack), we do not use them for new projects. Overall, PostgreSQL is our everything.
Also on the radar is visible Aerospike. We used it quite actively, but then the product has changed the license agreement, so that "our" version was a bit curtailed. But now we looked at him again. Perhaps we will reconsider our attitude towards the instrument and will use it more actively. Now Aerospike is used in the event aggregation service for browsing pages and user experience with the basket as well as in the social-proof service (“5 people added this item to favorites this week”). Now we are making even more cool recommendations.
Apache Solr is used to search for data in production. In parallel, we also apply ElasticSearch. Both solutions are open source, but if earlier, when we only implemented search, Apache Solr already had the third or fourth version and was actively developing, and ElasticSearch did not even have the first stable release yet - it was too early to use it on production. Now the roles have changed - it is much easier to find solutions for ElasticSearch, and new people have just come to us who know how to prepare it well. However, Solr is sold in our company, and we will not move to another solution at least until Black Friday 2018.
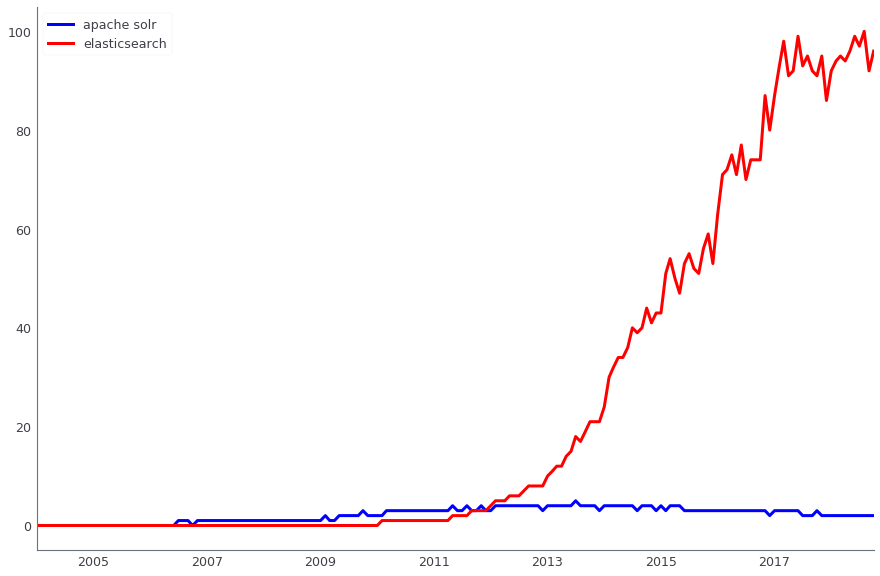
Comparison of the dynamics of the Apache Solr search queries (blue) and ElasticSearch (red), according to Google Trends
Data analysis takes place in several systems, in particular, we actively use Apache Hadoop. In parallel, for storing data marts (total volume of the order of 4 TB) is used columnar DBMS Vertica. Above these Storefronts financial, operational and commercial reporting is under construction. For many of our ETL tasks, we used Luigi earlier, but now we are switching to Apache Airflow. We also use Pentaho for the relational repository, in which there are about a thousand regular ETL tasks.
Part of the analysis and data preparation for other systems is carried out in Spark. In some places it is not only an analytics tool, but also part of our lambda architecture.
ERP systems play a major role in the IT infrastructure: Microsoft Dynamics AX and 1C. Microsoft SQL Server is used as a DBMS. And to create reports - its components, such as Analysis services and Reporting services.
For caching we use Redis. Previously, MemCached performed this task; it could not be used as key value storage with a periodic dump to disk, so we refused it.
As an event broker, we use two tools at once - Apache Kafka and RabbitMQ.
Apache Kafka is a tool that allows us to process tens of thousands of messages in various systems where you need to exchange messages. Separate Kafka clusters are deployed for some high-loaded parts of the system - for example, for user events or logging (we had a good report on Highload ++ 2017 for logging ). Kafka allows you to cope with 6000 thousands of bulk messages per second with minimal use of iron.
In internal systems, we use RabbitMQ for deferred actions.

Kubernetes is used for deployment, which replaces the Nomad + Consul bundle from Hashicorp. The previous stack worked very badly with the hardware upgrade. When our Ops-team changed the physical servers on which the nodes were spinning and the containers were stored, it periodically broke and fell, not wanting to rise. Stable version at that time did not work. Moreover, we did not use the latest one at that time - 0.5.6, which still needed to be updated. Upgrading to the latest beta required some effort. Therefore, it was decided to abandon him and go to the more popular Kubernetes.
Now Nomad and Consul are still used in QA, but in the future it should also move to Kubernetes.
To implement continuous delivery, Docker containers are used, to which we migrated two years ago. For our high-load services (baskets, catalog, website, order management system) it is important to quickly pick up a few additional containers of some service, so we have containers everywhere. And Docker is one of the most popular ways of containerization, so its presence on the radar is quite logical.
As a build server and continuous integration deployed Bamboo, used in conjunction with Jira and Bitbucket (standard stack).
Jenkins is also mentioned in the radar. We experimented with it, but not dragging it into new projects. This is an excellent tool, but it just doesn't fit into our stack due to the fact that we already have Bamboo.
Collected using Bamboo docker-containers are stored in a repository under the control of Artifactory.
We use NGINX Plus, but not in terms of balancing, since its metrics are not enough for our tasks. It cannot say, say, which request is most often routed or freezes. Therefore, HAProxy is used for load balancing. He can work quickly and efficiently in conjunction with nginx, without loading the processor and memory. In addition, we need the metrics here out of the box - HAproxy can show statistics on nodes, by the number of connections at the moment, by how busy the bandwidth is and much more.
To run synchronous Python applications, uWSGI is used. Php-fpm was used as a process manager on all PHP services.
We use Prometheus to collect metrics from our applications and host machines (virtual machines), as well as the Time series database for the application . We collect logs, for this we use the ELK stack, as the alert system we use Icinga, which is configured on both ELK and Prometheus. She sends alerts to mail and SMS. The same alert is received by the support service 6911 and decides on the engagement of duty engineers.
Prometheus is used almost everywhere, and for this we have libraries for all languages that allow using literally a couple of lines of code to connect its metrics to the project. For example, the library for PHP is laid out in Open Source ).
For visual display of monitoring results in the form of beautiful dashboards, Grafana is used. Basically, we collect all the dashboards from Prometheus, although sometimes other systems can serve as sources.
For trapping and automatic error aggregation, we use Sentry, which is integrated with Jira and makes it easy to start a task in the task tracker for each of the production problems. He knows how to grab a bug with some backtrace and additional information, so then it’s convenient to debug.
Statistics on the code created pull requests are collected using SonarQube.

During the development of the IT infrastructure of Lamoda, we experimented with almost three dozen different tools, so this category is the most “large-scale” on our radar. To date, actively used:
About the development of JavaScript I want to tell separately. We, like many, have a whole field of experiments. The site uses a samopisny framework for JavaScript. Within the framework of non-business-critical tasks, experiments with different frameworks were conducted - Angular, ReactJS, vue.js. In this “arms race”, it seems that vue.js is in the lead, which was originally used in the automation system of the content studio, and now it is gradually coming everywhere.
If you try to describe all this diversity in a nutshell, then we write in GO, PHP, Java, JavaScript, keep the bases in PostgreSQL, and deploy on Docker and Kubernetes.
Of course, the described state of the technological stack cannot be called final. We are constantly evolving, and as the load grows, classes of suitable solutions have to be changed, which in itself is an interesting task. At the same time, business logic becomes more complex, so we constantly have to look for new tools. If you want to discuss on the topic, why you chose this tool, and not the other, welcome to the comments.
My colleagues and I are ready to discuss in comments or on the company's stand at HighLoad ++ 2018.
Consider the radar large and detailed here.
As we have said, a huge number of different technologies and tools are involved in Lamoda. And this is not by chance. Otherwise, we can not cope with the load! We have a large automated warehouse. Our call-center is served by 500 employees, and the processes we have built up allow us to call the customer back within 5 minutes after placing the order. Our delivery service operates at 15-minute intervals. But besides our own systems, we have B2B integration with other online stores. With such a variety of tasks and the requirements of such a dynamic business as e-commerce, the growth of the technical stack is inevitable, because we want to solve every problem with the most appropriate technologies. Diversity is inevitable. On the main representatives of our stack, we describe below. But let's start with the mechanisms that allow us not to “get lost” in this diversity.
The main architecture
We are actively moving in the direction of microservice architecture. Most of the systems have already been built in accordance with this ideology - two years ago we went through a transitional stage with our problems and their solutions. But we will not dwell on the details of this process here - Andrei Evsyukov’s report “ Features of microservices on the example of an e-Com platform ” will tell much more about this .
In order not to aggravate technological diversity, we have introduced a “dictatorship of tried and tested practices,” according to which the creators of new chips are encouraged to use those technologies and tools that are already involved somewhere in the company. Most services communicate with each other through an API (we use our modification of the second version of the JSONRPC standard), but where business logic allows, we also use a data bus for interaction.
The use of other technologies is not prohibited. However, any new idea should be tested in a specially created architectural committee, which includes the leaders of the main directions.
Considering the next proposal, the committee either gives the go-ahead to the experiment, or offers some kind of replacement from the already existing stack. By the way, this decision largely depends on the current circumstances in the business. For example, if a team comes on the eve of the Black Friday sale and announces that it will be introducing into production a technology that the committee has never heard of before, it will most likely be refused. On the other hand, the same experiment can be given a green light if a new technology or tool is introduced in less critical business circumstances, and the implementation will begin with testing out of production.
The architecture committee is also responsible for maintaining the Technology radar, making the necessary changes once every 2-3 months. One of the purposes of this resource is to give the teams an idea of what kind of expertise is already in the company.
But let's move on to the most interesting - to the analysis of the sectors of our radar.
It is worth noting that we use a slightly non-standard interpretation of the categories of adoption of technology:
- ADOPT - technologies and tools that are implemented and actively used;
- TRIAL - technologies and tools that have already passed the testing phase and are preparing to work with production (or even already work there);
- ASSESS - test tools that are currently being evaluated and do not yet affect production. With their participation, only test projects are implemented;
- HOLD - we have expertise in this category, but the mentioned tools are used only with the support of existing systems - new projects are not launched on them.
Development
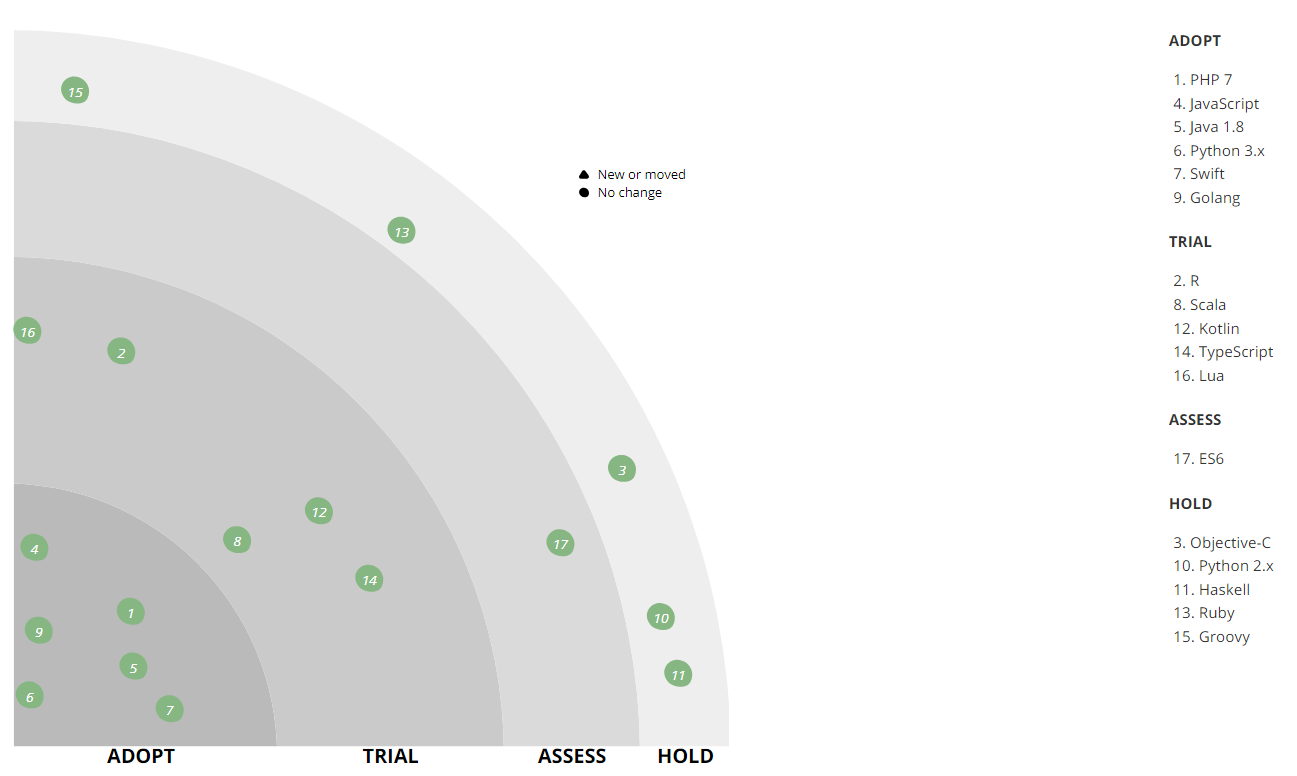
PHP - Python - Go
The first important language for us to stay in is PHP. Today, it solves only a part of the backend's tasks, and initially the entire backend worked on PHP. As business scaled on the front end, there was a noticeable lack of speed and performance - then we also used PHP 5, so Python came to replace it (first 2.x and then 3.x). However, PHP allows you to write rich business models, so this language remained in the back office for automating various operational processes, in particular, integration with third-party online stores or delivery services, as well as automating the content studio that makes out product cards. Now we are using PHP 7. In PHP, we have written many libraries for internal use: integration and wrappers over our infrastructure, integration layer between services, various reusable helpers. The first batch of libraries have already begun to make open source onour github.com , will soon reach the rest, the most "ripe". One of the first was the state machine, which, being present in almost all applications, ensures that all necessary actions are taken with the order before shipment.
Over time, Python for the backend store also became insufficient. Now we prefer the more productive and lightweight Go.
Perhaps the transition to Go was an important change, because it allowed us to save a lot of hardware and human resources - the efficiency increased significantly. The first to do the first Go projects were RnD, they didn’t want to fight the technical limitations of Python. Then, in the mobile development team, people appeared who were well acquainted with him and promoted him to production. With their submission, we conducted tests and were more than satisfied with the result. In separate cases, after part of the project was rewritten from Python to Go, the cluster node load dropped significantly. For example, rewriting the discount calculation engine for the Python basket from Go made it possible to process 8 times more requests for the same hardware capacity, and the average API response time decreased 25 times. Those. Go turned out to be more efficient than Python (if you write on it correctly),
Since mobile development had to interact with dozens of internal APIs, a code generator was created that, according to the service API description (according to Swagger specification), a client on Go can generate. So, Go gradually began to correspond with existing services and tools, especially those that created a bottleneck for the load. In addition to simplifying the life of a mobile backend developer, we have simplified following internal agreements on how to develop an API, how to call methods, how to pass parameters, and the like. Such standardization has made the development and implementation of new services easier for all teams.
Today, Go is already used almost everywhere - in all real-time interactions with users - in the backend of the site and mobile applications, as well as the services with which they are associated. And where there is no need for fast processing and response, for example, in interaction tasks with the data warehouse, Python remained, since it has no equal for data processing tasks (although there is a Go penetration here).
As seen on the radar, we have Java in the asset. It is used in the warehouse automation system (WMS - Warehouse Management System), helping to collect orders faster. So far we have a fairly old stack and an old architecture model there — a monolith spinning on Wildfly 10 and 8 Java Hotspot, and there is also a remoting and Rich client on the Netbeans Application Platform(now this functionality is transferred to the web). Here, in our arsenal, we have standard storage facilities for the company and even our own monitoring. Unfortunately, we did not find a tool that can visualize well the work of the warehouse and important processes on it (when a section is overloaded, for example), and we made such a tool ourselves.
We use Python as the main language for machine learning: we build recommender systems and rank the catalog, correct typos in search queries, and also solve other tasks in conjunction with Spark on the Hadoop cluster (PySpark). Python helps us automate the calculation of internal metrics and AB testing.
Front-end and mobile development
Front-end desktop online store, as well as mobile sites written in JavaScript. Now the frontend is gradually moving to the ES6 specification, creating new projects in accordance with it. We use vue.js as the main framework, but we’ll dwell on it in the tools section.
Mobile application development is a separate unit in the company, which includes backend groups, as well as Android and iOS applications with their own technology stacks and tools, which, due to platform differences, are not always able to unify across the unit.
For two years now, all the new Android development has been going on at Kotlin, which allows us to write more concise and understandable code. Among the most commonly used features, our developers call: smartcast, sealed-classes, extension-functions, typesafe-builders (DSL), stdlib functionality.
iOS development is being done on Swift, which replaced Objective-C.
Special languages
The range of tasks of Lamoda is not limited to developing “showcases” for different platforms, respectively, we have a number of languages that are used only within their systems, they work well there, but will not be implemented in other parts of the infrastructure:
- R - used for data processing scripts and building reports within business intelligence (BI). He is not in the production and on new tasks it is no longer used, but we still have a number of such scripts. Solving problems using R, we realized that this language is not for high-load applications. In new tasks, we use Python and other technologies that are incompatible with R.
- Scala is used by the development office in Vilnius for the development of a call center automation system. Initially, this system was written in PHP, but in the transition to the microservice architecture, a number of components were copied to Scala. Also on it, the Data Engineering team writes the Spark job.
- to TypeScript we look narrowly. Delivery is already implemented with its help, and in the future we will use TypeScript + vue.js on the frontend.
- Lua is used to configure nginx (via the nginx API), in other projects it is not and will not be.
- We are a fashion company and follow the mod on functional programming. For example, a sorting device emulator from one of our warehouses is written in Haskell.
Data management
DBMS, data search and analysis
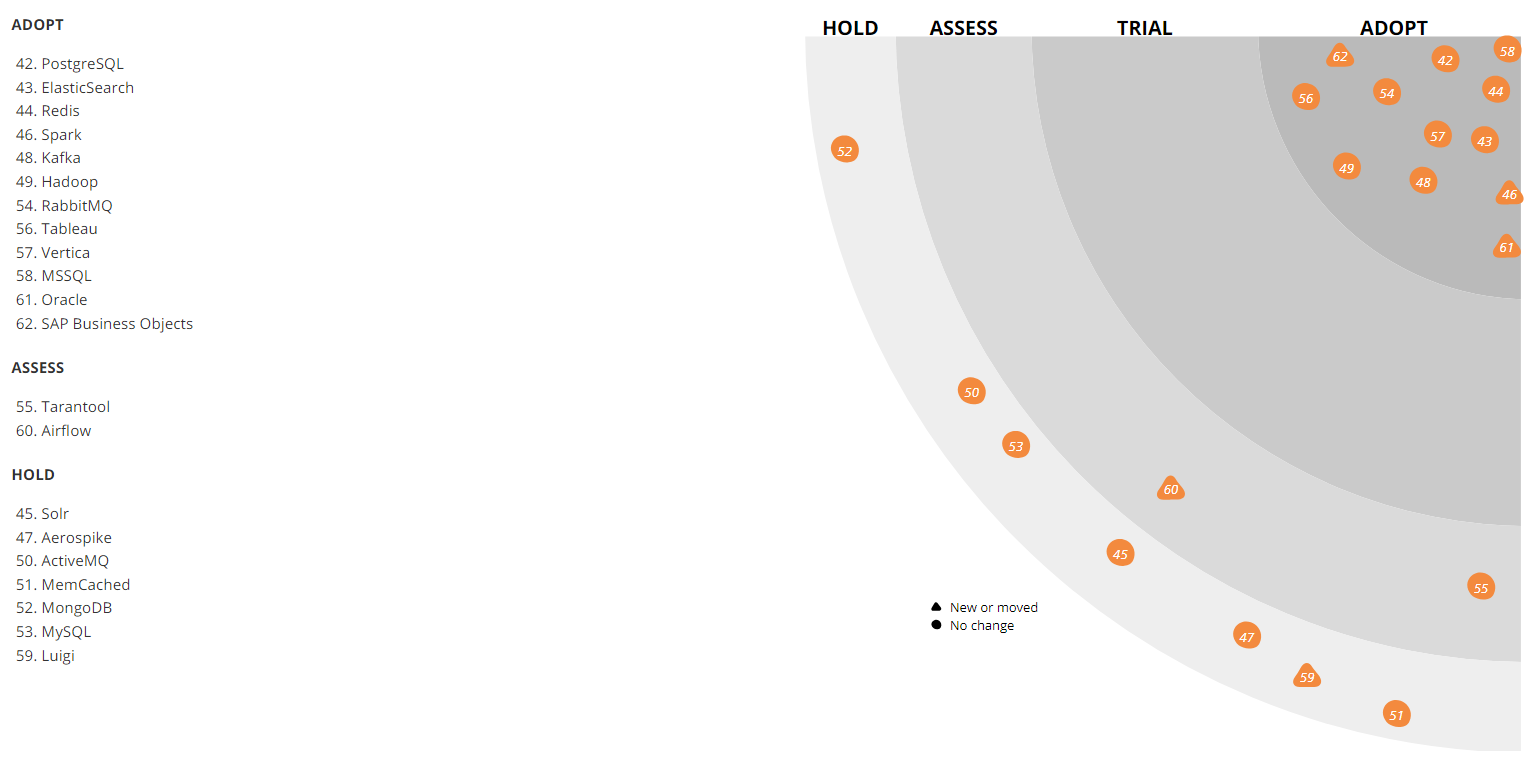
Like many, most different databases are implemented on PostgreSQL - it is used everywhere where relational databases are needed, for example, to store a directory. Specialists in this technology are quite easy to find, and in addition, many different services are available.
Of course, PostgreSQL is not the only DBMS that can be found in our IT infrastructure. On some older systems, for example, MySQL is used, while WMS has a bit of MongoDB. However, for high loads and scaling (taking into account the rest of our technology stack), we do not use them for new projects. Overall, PostgreSQL is our everything.
Also on the radar is visible Aerospike. We used it quite actively, but then the product has changed the license agreement, so that "our" version was a bit curtailed. But now we looked at him again. Perhaps we will reconsider our attitude towards the instrument and will use it more actively. Now Aerospike is used in the event aggregation service for browsing pages and user experience with the basket as well as in the social-proof service (“5 people added this item to favorites this week”). Now we are making even more cool recommendations.
Apache Solr is used to search for data in production. In parallel, we also apply ElasticSearch. Both solutions are open source, but if earlier, when we only implemented search, Apache Solr already had the third or fourth version and was actively developing, and ElasticSearch did not even have the first stable release yet - it was too early to use it on production. Now the roles have changed - it is much easier to find solutions for ElasticSearch, and new people have just come to us who know how to prepare it well. However, Solr is sold in our company, and we will not move to another solution at least until Black Friday 2018.
Comparison of the dynamics of the Apache Solr search queries (blue) and ElasticSearch (red), according to Google Trends
Data analysis takes place in several systems, in particular, we actively use Apache Hadoop. In parallel, for storing data marts (total volume of the order of 4 TB) is used columnar DBMS Vertica. Above these Storefronts financial, operational and commercial reporting is under construction. For many of our ETL tasks, we used Luigi earlier, but now we are switching to Apache Airflow. We also use Pentaho for the relational repository, in which there are about a thousand regular ETL tasks.
Part of the analysis and data preparation for other systems is carried out in Spark. In some places it is not only an analytics tool, but also part of our lambda architecture.
ERP systems play a major role in the IT infrastructure: Microsoft Dynamics AX and 1C. Microsoft SQL Server is used as a DBMS. And to create reports - its components, such as Analysis services and Reporting services.
Caching
For caching we use Redis. Previously, MemCached performed this task; it could not be used as key value storage with a periodic dump to disk, so we refused it.
Message Queues
As an event broker, we use two tools at once - Apache Kafka and RabbitMQ.
Apache Kafka is a tool that allows us to process tens of thousands of messages in various systems where you need to exchange messages. Separate Kafka clusters are deployed for some high-loaded parts of the system - for example, for user events or logging (we had a good report on Highload ++ 2017 for logging ). Kafka allows you to cope with 6000 thousands of bulk messages per second with minimal use of iron.
In internal systems, we use RabbitMQ for deferred actions.
Platforms and infrastructure
Continuous delivery
Kubernetes is used for deployment, which replaces the Nomad + Consul bundle from Hashicorp. The previous stack worked very badly with the hardware upgrade. When our Ops-team changed the physical servers on which the nodes were spinning and the containers were stored, it periodically broke and fell, not wanting to rise. Stable version at that time did not work. Moreover, we did not use the latest one at that time - 0.5.6, which still needed to be updated. Upgrading to the latest beta required some effort. Therefore, it was decided to abandon him and go to the more popular Kubernetes.
Now Nomad and Consul are still used in QA, but in the future it should also move to Kubernetes.
To implement continuous delivery, Docker containers are used, to which we migrated two years ago. For our high-load services (baskets, catalog, website, order management system) it is important to quickly pick up a few additional containers of some service, so we have containers everywhere. And Docker is one of the most popular ways of containerization, so its presence on the radar is quite logical.
As a build server and continuous integration deployed Bamboo, used in conjunction with Jira and Bitbucket (standard stack).
Jenkins is also mentioned in the radar. We experimented with it, but not dragging it into new projects. This is an excellent tool, but it just doesn't fit into our stack due to the fact that we already have Bamboo.
Collected using Bamboo docker-containers are stored in a repository under the control of Artifactory.
Process Management and Balancing
We use NGINX Plus, but not in terms of balancing, since its metrics are not enough for our tasks. It cannot say, say, which request is most often routed or freezes. Therefore, HAProxy is used for load balancing. He can work quickly and efficiently in conjunction with nginx, without loading the processor and memory. In addition, we need the metrics here out of the box - HAproxy can show statistics on nodes, by the number of connections at the moment, by how busy the bandwidth is and much more.
To run synchronous Python applications, uWSGI is used. Php-fpm was used as a process manager on all PHP services.
Monitoring
We use Prometheus to collect metrics from our applications and host machines (virtual machines), as well as the Time series database for the application . We collect logs, for this we use the ELK stack, as the alert system we use Icinga, which is configured on both ELK and Prometheus. She sends alerts to mail and SMS. The same alert is received by the support service 6911 and decides on the engagement of duty engineers.
Prometheus is used almost everywhere, and for this we have libraries for all languages that allow using literally a couple of lines of code to connect its metrics to the project. For example, the library for PHP is laid out in Open Source ).
For visual display of monitoring results in the form of beautiful dashboards, Grafana is used. Basically, we collect all the dashboards from Prometheus, although sometimes other systems can serve as sources.
For trapping and automatic error aggregation, we use Sentry, which is integrated with Jira and makes it easy to start a task in the task tracker for each of the production problems. He knows how to grab a bug with some backtrace and additional information, so then it’s convenient to debug.
Statistics on the code created pull requests are collected using SonarQube.
Frameworks and tools
During the development of the IT infrastructure of Lamoda, we experimented with almost three dozen different tools, so this category is the most “large-scale” on our radar. To date, actively used:
- Symfony 3.x, and more recently - Symfony 4.x - for development in PHP;
- Django and Jinja template engine for Python development. By the way, Jinja is used, among other things, for configuration in Ansible;
- Flask - for internal services (along with Django), but in production we do not drag it;
- Spring is in Java development;
- Bootstrap - for a variety of internal tools in web development (admin panels, homemade dashboards, etc.);
- jQuery - for js development;
- OpenAPI (Swagger) - for documentation of all API-services, including which are used for Go code generation mentioned above;
- Webpack - for packaging JS and minimizing CSS;
- Selenium - for testing frontend;
- also used for testing are WireMock, JMeter, Allure and others;
- Ansible - for configuration management;
- Kibana - for visualizing search results in ElasticSearch.
About the development of JavaScript I want to tell separately. We, like many, have a whole field of experiments. The site uses a samopisny framework for JavaScript. Within the framework of non-business-critical tasks, experiments with different frameworks were conducted - Angular, ReactJS, vue.js. In this “arms race”, it seems that vue.js is in the lead, which was originally used in the automation system of the content studio, and now it is gradually coming everywhere.
The bottom line
If you try to describe all this diversity in a nutshell, then we write in GO, PHP, Java, JavaScript, keep the bases in PostgreSQL, and deploy on Docker and Kubernetes.
Of course, the described state of the technological stack cannot be called final. We are constantly evolving, and as the load grows, classes of suitable solutions have to be changed, which in itself is an interesting task. At the same time, business logic becomes more complex, so we constantly have to look for new tools. If you want to discuss on the topic, why you chose this tool, and not the other, welcome to the comments.