Training with reinforcements: parse on video games

At the AI Conference, Vladimir Ivanov will tell about the application of training with reinforcement vivanov879 , Sr. Deep learning engineer in Nvidia . The expert is engaged in machine learning in the testing department: “I analyze the data that we collect during the testing of video games and hardware. For this I use machine learning and computer vision. The main part of the work is image analysis, data cleaning before training, data marking and visualization of the solutions obtained. ”
In today's article, Vladimir explains why reinforced training is used in autonomous cars and tells how an agent is trained to act in a changing environment — using video game examples.
In the past few years, humanity has accumulated a huge amount of data. Some datasets spread in general and mark up manually. For example, dataset CIFAR, where each picture is signed, to which class it belongs.

Datasets appear, where it is necessary to assign a class not just to the picture as a whole, but to each pixel in the image. As, for example, in CityScapes.

What unites these tasks is the fact that the learning neural network only needs to remember the patterns in the data. Therefore, with sufficiently large amounts of data, and in the case of CIFAR it is 80 million images, the neural network is learning to generalize. As a result, she copes well with the classification of pictures that she has never seen before.
But acting within the framework of a teaching technique with a teacher that works for marking pictures, it is impossible to solve problems where we want not to predict the label, but to make decisions. As, for example, in the case of autonomous driving, where the task is to safely and reliably reach the end point of the route.
In the classification tasks, we used the teaching technique with the teacher - when each picture was assigned a certain class. And what if we do not have such a markup, but there is an agent and environment in which he can perform certain actions? For example, let it be a video game, and we can click on the control arrows.

This kind of task is worth solving with the help of reinforcement training. In the general formulation of the problem, we want to learn how to perform the correct sequence of actions. It is fundamentally important that the agent has the opportunity to perform actions again and again, thus exploring the environment in which he is located. And instead of the correct answer, how to act in a given situation, he receives a reward for a correctly completed task. For example, in the case of an autonomous taxi, the driver will receive a bonus for each trip made.
Let's return to a simple example - to a video game. Take something unpretentious, for example, the Atari table tennis game.
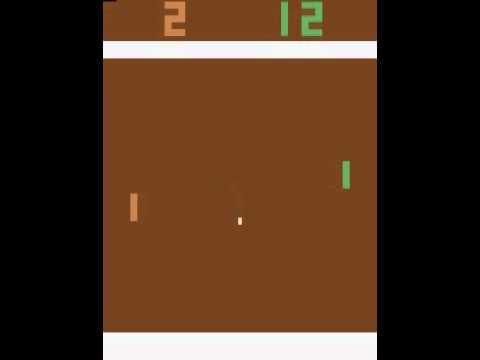
We will manage the small plate on the left. We will play against the computer-programmed rules of the player on the right. Since we work with the image, and neural networks cope most successfully with the extraction of information from images, let's submit a picture to the input of a three-layer neural network with a 3x3 core size. At the exit she will have to choose one of two actions: move the plank up or down.
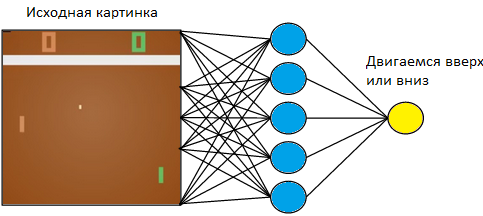
We train the neural network to perform actions that lead to victory. The technique of learning is as follows. We let the neural network play a few rounds of table tennis. Then we start to sort the games played. In those games where she won, we mark the pictures with the label “Up” where she raised the racket, and “Down” where she lowered it. In the lost games, we do the opposite. We mark those pictures, where she lowered the plate, labeled “Up”, and where she raised - “Down”. Thus, we reduce the task to the approach already known to us - learning with a teacher. We have a set of pictures with tags.
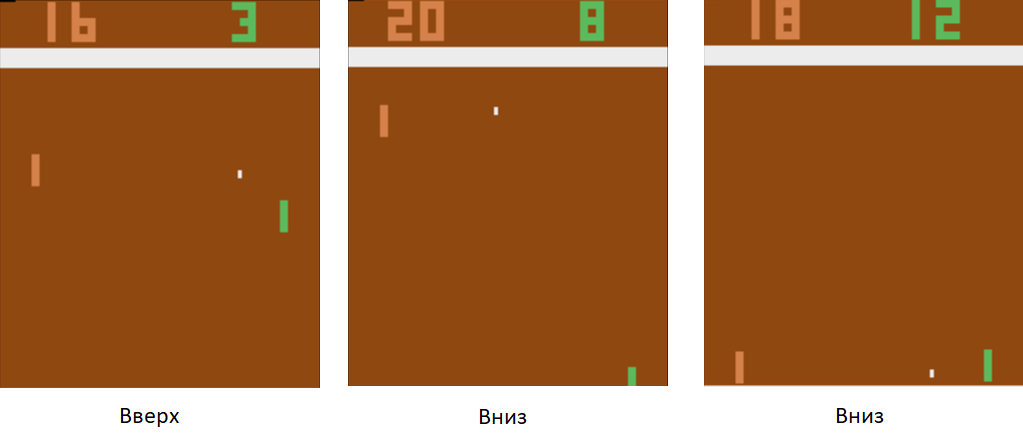
Using this training technique, in a couple of hours, our agent will learn how to beat the computer-programmed rules-based player.
How to be in the case of autonomous driving? The fact is that table tennis is a very simple game. And it can produce thousands of frames per second. Our network is now only 3 layers. Therefore, the learning process is lightning. The game generates a huge amount of data, and we instantly process them. In the case of autonomous driving data to collect much longer and more expensive. Cars are expensive, and from one car we will receive only 60 frames per second. In addition, the cost of error increases. In a video game, we could afford to play batch after batch at the very beginning of training. But we can not afford to spoil the car.
In this case, let's help the neural network at the very beginning of training. We will fix the camera on the car, put an experienced driver in it and record photos from the camera. For each picture we will sign the angle of the vehicle steering wheel. We will teach the neural network to copy the behavior of an experienced driver. Thus, we again reduced the task to the already well-known learning with the teacher.
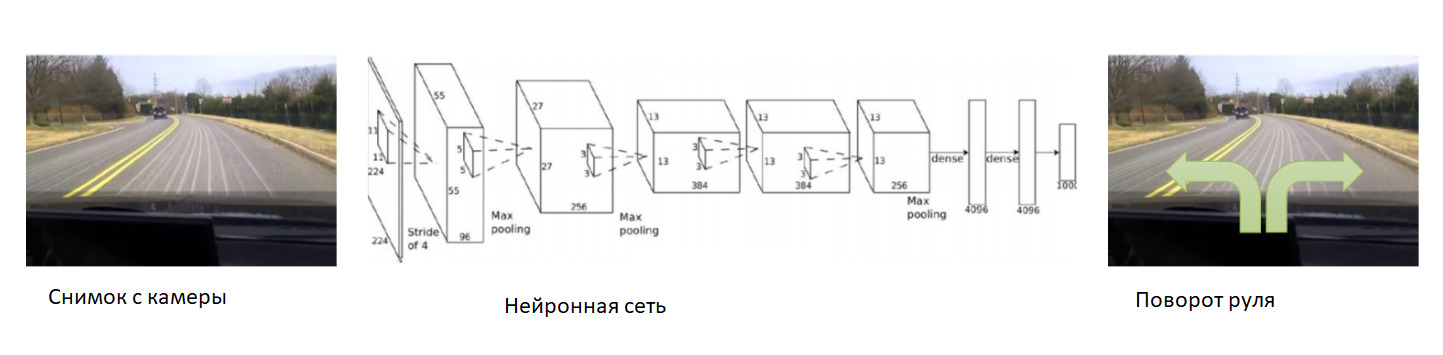
With a sufficiently large and diverse dataset, which will include different landscapes, seasons and weather conditions, the neural network will learn to accurately control the car.
However, there is a problem with the data. They are very long and expensive to collect. Let's use the simulator, which will be implemented all the physics of the movement of the car - for example, DeepDrive. We can learn in it, without fear of losing the car.

In this simulator, we have access to all indicators of the car and the surrounding world. In addition, all people, cars, their speeds and distances to them are marked up.

From the point of view of the engineer in this simulator, you can safely try new teaching techniques. What should the researcher do? For example, the student of different options for gradient descent in learning tasks with reinforcement. To test a simple hypothesis, you do not want to shoot a cannon on sparrows and launch an agent in a complex virtual world, and then wait for days for the simulation results. In this case, let's more efficiently use our computing power. Let the agents be simpler. Take, for example, a spider model on four legs. In the Mujoco simulator, it looks like this:

We assign him the task of running as fast as possible in a given direction — for example, to the right. The number of observed parameters for a spider is a 39-dimensional vector, which records the position and velocity of all its limbs. Unlike the neural network for table tennis, where there was only one neuron at the exit, here at the exit there are eight (since the spider has 8 joints in this model).
In such simple models one can test various hypotheses about the teaching technique. For example, let's compare the speed of learning to run, depending on the type of neural network. Let it be a single-layer neural network, a three-layer neural network, a convolutional network, and a recurrent network:
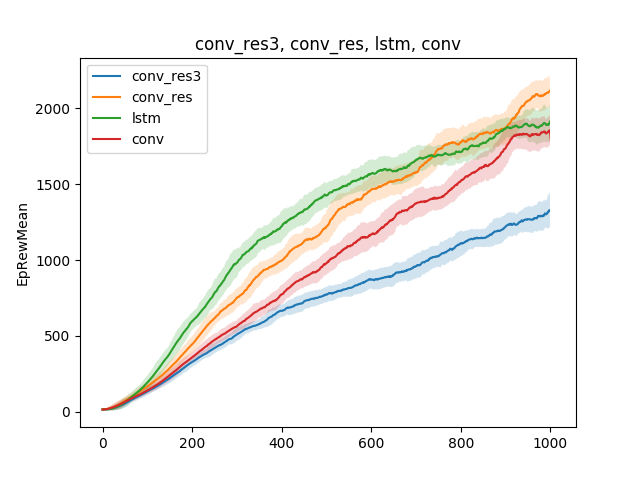
The conclusion can be drawn as follows: since the spider model and the task are rather simple, the results of the training are approximately the same for different models. A three-layer network is too complicated, and therefore learns worse.
Despite the fact that the simulator works with a simple spider model, depending on the task that is put before the spider, the training can last for days. In this case, let's animate several hundred spiders instead of one on the same surface and learn from the data that we will receive from all. So we will speed up the training several hundred times. Here is an example of the Flex engine.

The only thing that has changed in terms of neural network optimization is data collection. When we ran only one spider, we received data consistently. One run after another.

Now it may happen that some spiders are just starting the race, while others have been running for a long time.
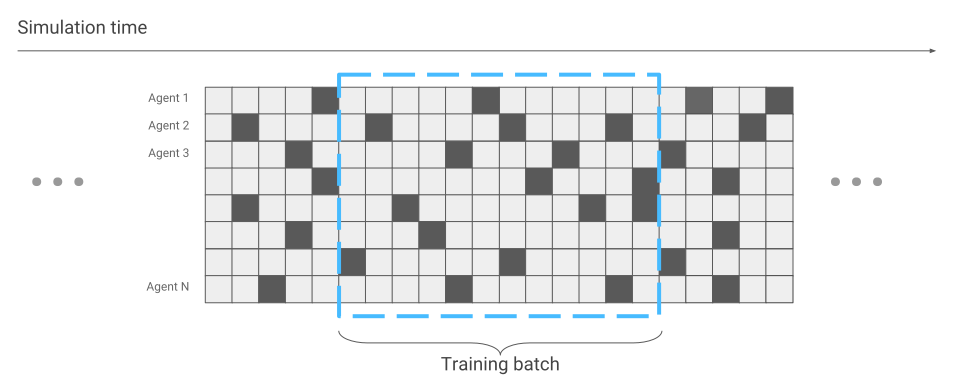
We will take this into account during the optimization of the neural network. Otherwise, everything remains the same. As a result, we receive acceleration in training hundreds of times, in terms of the number of spiders that are simultaneously on the screen.
Once we have an effective simulator, let's try to solve more complex tasks. For example, cross-country running.

Since the environment in this case has become more aggressive, let us change and complicate tasks during the training. It's hard to learn, but easy in battle. For example, every few minutes to change the terrain. In addition, let's give the agent more external influences. For example, let's throw balls into it and turn the wind on and off. Then the agent learns to run even on surfaces that he has never met. For example, climb the stairs.

Since we have learned so effectively to run in simulators, let's test reinforcement training techniques in competitive disciplines. For example, in shooters. The VizDoom platform offers a world in which you can shoot, collect weapons and replenish health. In this game we will also use a neural network. Only now she will have five outs: four to move and one to fire.
In order for the training to go effectively, let's approach this gradually. From simple to complex. At the entrance, the neural network receives an image, and before starting to do something conscious, it must learn to understand what the world around it consists of. By learning simple scenarios, she will learn to understand which objects inhabit the world and how you can interact with them. Let's start with a shooting gallery:
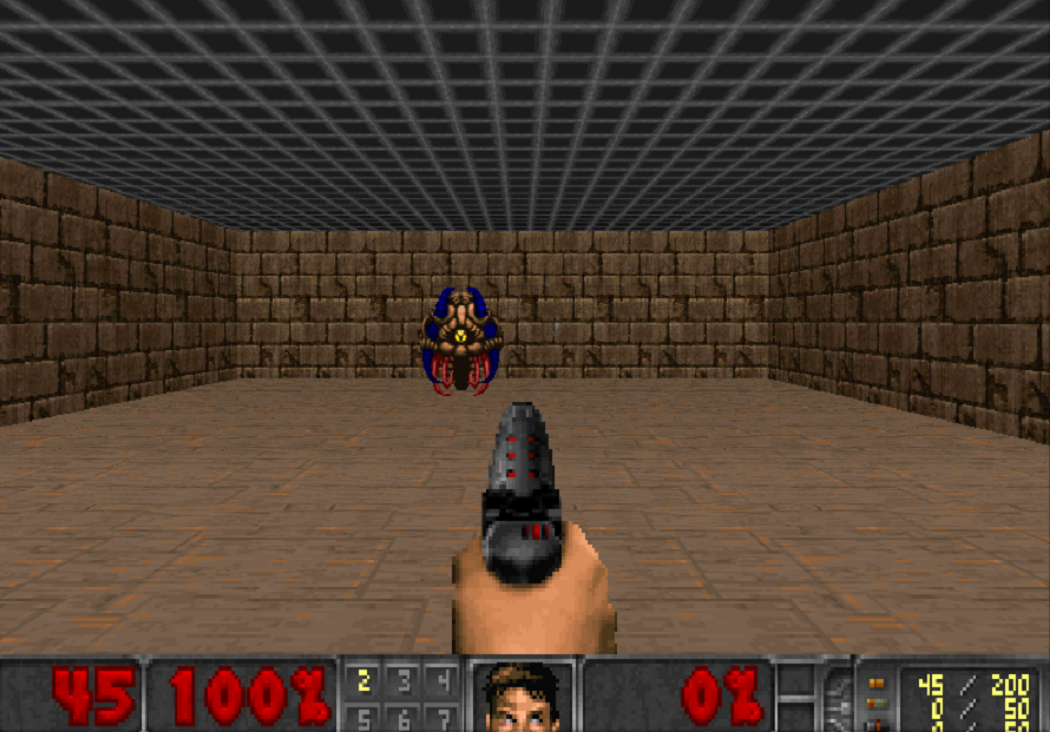
Having mastered this scenario, the agent will figure out that there are enemies, and they should be shot, because you get points for them. Then we will teach him in a scenario where health is constantly decreasing, and you need to replenish it.

Here he learns that he has health, and it needs to be replenished, because in case of death, the agent receives a negative reward. In addition, he will learn that if you move in the direction of the subject, it can be collected. In the first scenario, the agent could not move.
And in the final, third scenario, let's leave it to shoot with the game-programmed bots from the game so that he can hone his skills.

During training in this scenario, the correct selection of awards that an agent receives plays a very important role. For example, if you give a reward only for defeated rivals, the signal will be very rare: if there are few players around, then we will receive points every few minutes. So let's use a combination of awards that were before. The agent will receive a reward for every useful action, whether it is improving health, selecting cartridges or hitting an opponent.
As a result, an agent trained with well-chosen rewards turns out to be stronger than his more computationally demanding opponents. In 2016, such a system won the VizDoom competition with a margin of more than half the points scored from second place. The second place team also used the neural network, only with a large number of layers and additional information from the game engine during training. For example, information about whether there are enemies in the field of view of the agent.
We have examined approaches to solving problems where it is important to make decisions. But many problems with this approach will remain unresolved. For example, the quest game Montezuma Revenge.
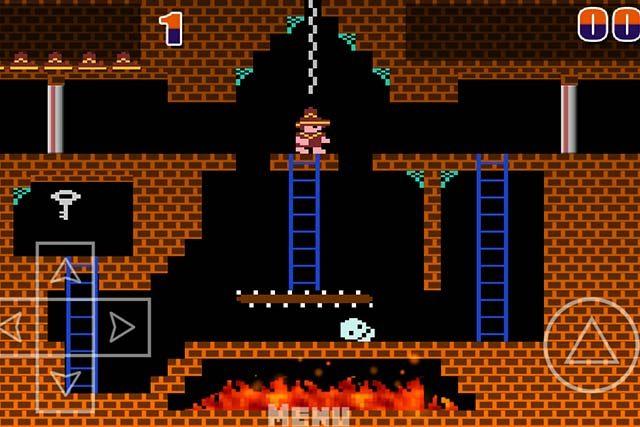
Here it is necessary to search for keys in order to open the doors to the next rooms. We rarely get keys, and we open rooms even less often. It is also important not to be distracted by foreign objects. If we teach the system the way we did in the previous tasks, and give rewards for the beaten enemies, it will simply start knocking out the rolling skull again and again and will not explore the map. About solving such problems, if interested, I can tell in a separate article.
You can listen to the speech of Vladimir Ivanov at the AI Conference on November 22 . Detailed program and tickets - on the official website of the event.
Read the interview with Vladimir here .