HPE Intelligent Resilient Framework Virtualization Technology
Today, virtualization technology is widely used in ICT. It has long gone beyond server virtualization when several virtual machines are running on the same physical server. This approach, called 1: N virtualization, is applicable to the network: at the first stage of the development of network technologies, VPN or VRF technologies were used to isolate logical segments. At the next level of development, the possibility of hardware virtualization has appeared, when several images of the operating system are launched on the same physical switch. This approach allows you to create several independent devices that use such common resources as control modules (CPU, memory), chassis (factories, cooling) and the power supply system.
However, another option is possible: like combining several physical servers into one logical one, several physical network devices are combined into one easily manageable logical device. This approach is called N: 1 virtualization. Along with simpler administration, it helps to increase network reliability, increase port density and provides a number of other advantages, which we will discuss below.

Virtualization 1: N (several virtual switches work on the same platform) and N: 1 (several physical switches form one logical device).
Currently, several switch virtualization technologies are known that allow combining several physical switches into a single logical one, for example, Juniper Networks virtual chassis technology, Cisco Virtual Switching System (VSS) and HPE Intelligent Resilient Framework (IRF). The IRF technology developed at the time by H3C is the classic N: 1 virtualization.
In any case, virtualization of N: 1 switches creates a pool or device stack. To combine them, you can use either special dedicated interfaces or ordinary Ethernet ports 1/10/40 / 100G. In the latter case, the switches can be spaced a considerable distance: the logical switch is obtained geographically distributed. Sometimes switch virtualization technologies are called stacking, virtual stacking (as in the case of IRF) or clustering (for example, as in the technology of Huawei CSS / iStack).
The data plane is active on all devices that make up the logical switch, that is, they all provide packet transmission. The control plane, which is responsible for the logic of the switch, can be used on one device (master). It is responsible for processing network protocols (L2 / L3), ACLs, QoS, routing tables, etc.
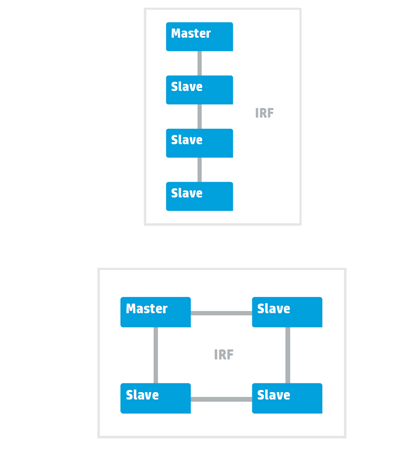
Two topologies: bus and ring.
Two topologies for connecting switches within the IRF are possible: bus and ring. The latter is recommended, as it is more fault tolerant. Consolidated switches begin to exchange packets to build a common stack topology. Next, based on the transfer of packets within the IRF stack.
Switch virtualization technologies can overcome the limitations of the traditional network architecture with the Spanning Tree Protocol (STP) - significant failure recovery time, inefficient use of bandwidth, difficulties in configuration, troubleshooting, etc.
To solve these problems in ring topologies, technologies such as Resilient Packet Ring (RPR), HPE Rapid Ring Protection Protocol (RRPP) and Ethernet Ring Protection Switching (ERPS). They provide a short recovery time (50 ms) in the event of a malfunction in the ring.
For networks built according to the classical “star” topology, these technologies are hardly applicable. One of the options for optimizing such networks was the use of N: 1 virtualization technologies. The use of HPE IRF-class technologies at the core / distribution level allows for high fault tolerance without complex protocol support.
At the access level, such technologies can not only overcome all the disadvantages of the traditional STP protocol, but also significantly reduce the total number of control points. Their advantages are obvious - there are no problems with STP, loops, port blocking, creating L2 domains, plus ease of administration.
Ring network structure
HPE IRF technology enables fault-tolerant convergence networks that are easy to manage and scale. The group of IRF switches that make up the virtual, logical switch (and this can be up to nine devices, depending on the model), has one IP address, which simplifies configuration and management.
One switch in the group is the main one, provides a control plane, updating forwarding and routing tables for other devices. That is, all control is carried out by the main switch, while its state is synchronized with slave devices.
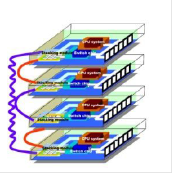
Switch Stack
In the event of a failure of the main IRF switch, a new one is instantly selected - service is not interrupted. If the link fails, one of the switches retains the role of the main one, the second switch enters the Recovery State and disables all ports except the IRF ports and the ports that are not disconnected (according to the configuration). After the link is restored, the switch, which was in the recovery state, will reboot and become a slave. A similar algorithm is used if two switches at once decide that they need to become active.
In the IRF domain, one of the switches can be disabled for maintenance or software updates — the so-called In-Service-Software-Upgrade (ISSU) procedure. This will not affect traffic.
IRF technology makes it possible to stack switches, receiving a total of up to 1024 Ethernet ports. For the interaction of devices in the IRF group, conventional Ethernet ports are used, in most cases - 10 Gb / s. An IRF channel is formed between the switches, and packets transmitted through it are provided with an additional header (IRF tag). The components of such a logical switch can be located in different racks of the data center or at different sites, remote from each other at a distance of up to 70 km.
IRF extends to the access, aggregation, and core levels of the network. Thanks to IRF, you can reduce the number of network layers by combining access and aggregation or aggregation functionality and the core. Boundary or aggregation switches interacting in a network with IRF-capable kernel switches see associated switches as a whole, so there is no need to use technologies such as STP.
The use of IRF provides several advantages over traditional networks. We have already talked about some of them. These benefits mainly cover three areas: simplicity, performance, and reliability.
Simplified network infrastructure
Network infrastructure is becoming simpler - not three-tier, but two-tier. It has fewer devices, interfaces, communications, and protocols that require configuration and management. A two-tier network requires less equipment and simplifies network administration in data centers and campus enterprise networks.
Centralized management and configuration
IRF does not require connecting to each device and controlling it individually. The main switch is used for configuration, and all settings apply to the devices associated with it. In this, this approach resembles SDN - software-configured networks.
So that network administrators can use not only the command line, but also a more convenient interface, the HPE Intelligent Management Center (IMC) has been developed. It allows you to manage the entire network in one console. The IMC network management system displays the network topology, manages configurations, devices, performance, and simplifies troubleshooting.
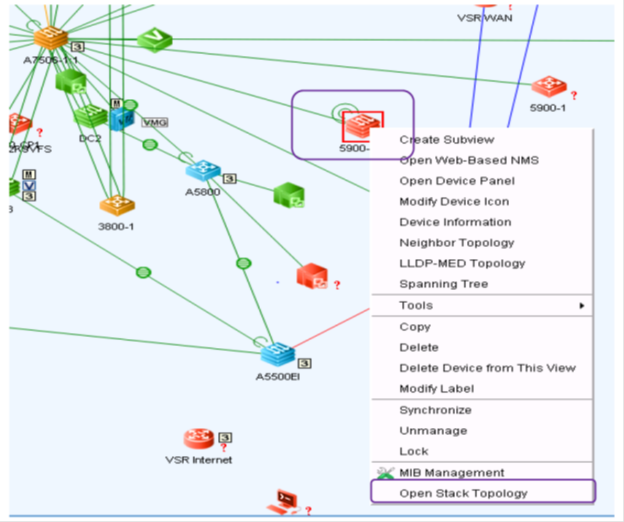
Network topology in the IMC interface
Reliability
Support in the IRF of the Link Aggregation Control Protocol (LACP) protocol allows the transfer of traffic between switches over several channels, and restoring the topology in case of a switch failure or link in the stack requires no more than 50 ms, while in case of STP it few seconds.
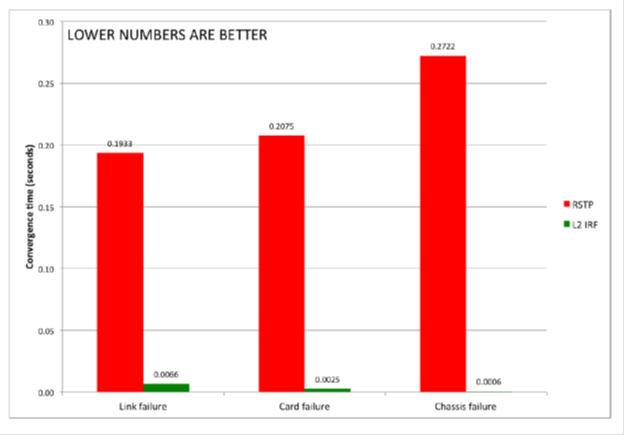
Comparison of convergence time in ms when using RSTP and IRF for channel failure, switch network card or chassis.
Thus, IRF allows you to create more reliable "flat" network with fewer levels and devices. Compared to traditional network infrastructure, network latency is reduced, performance is increased, and complex protocols that increase reliability are no longer needed. Capital and operating costs are reduced.
To increase the reliability of the IRF factory, you can use the N + 1 configuration. In addition, the IRF domain allows the mobility of applications and virtual machines in the global network at the L2 level.
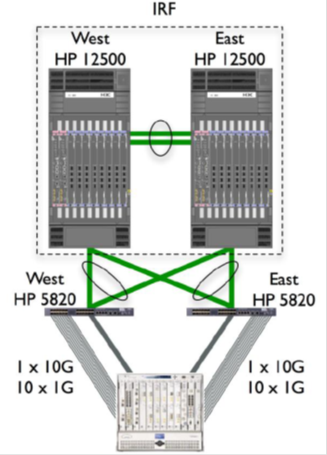
IRF configuration using LACP between the 12500 and 5820 switches. For the 5820 switch, the aggregated connection is one virtual link. This allows you to create interesting disaster-resilient solutions where IRF and aggregated links connect geographically distributed switches.
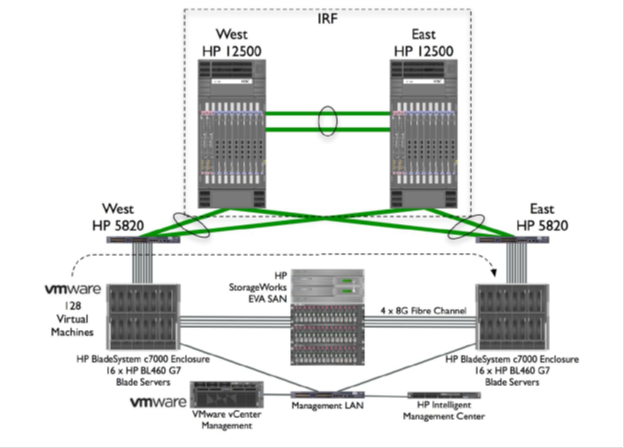
Testing the migration of 128 virtual machines (Vmware vMotion) in configurations using RSTP and IRF showed that in the latter case higher performance is achieved.
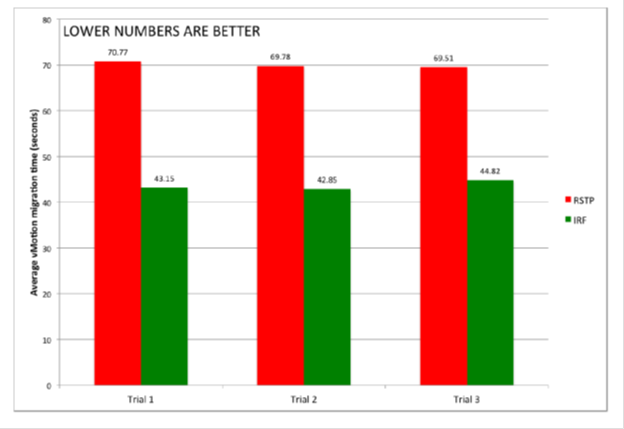
When using RSTP, the vMotion migration process took about 70 seconds in three tests , and in the case of IRF, only 43 seconds.
Performance
In the non-blocking IRF architecture, all links are active, and the throughput of the switching system is increased. The use of IRF in conjunction with LACP also allows aggregation of channels between servers and switches, increasing network bandwidth for critical applications.
In the IRF domain, network protocols function as a unit. This increases the efficiency of data processing, increases productivity, simplifies operations. For example, in the case of routing protocols, routes are defined in a single logical domain.
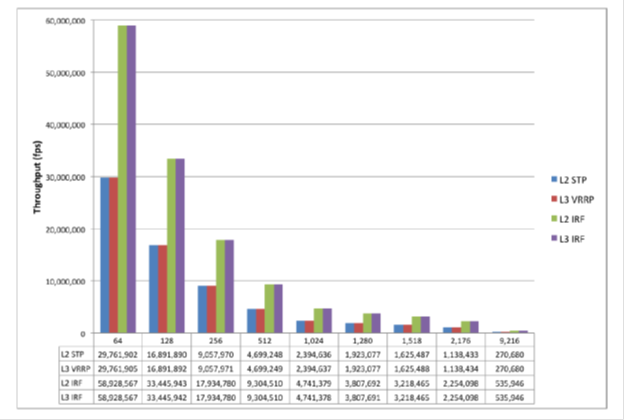
Comparison of performance in the case of using IRF and other mechanisms of fault tolerance L2 / L3.
Summarize. HPE IRF technology is:
IRF is supported on all HPE switches, starting from 3600 and ending with 12900E, as well as on the entire line of routers running Comware OS 7. This class of solutions can be used on campus networks (core, distribution, access), in data center networks (core, distribution , access), in routed branch networks, especially where redundancy of routers in branches is required.
As test results showIRF demonstrates advantages in areas such as network architecture, performance and reliability. Combining several switches and converting them into a single logical factory simplifies campus and data center networks, and accelerates VMware vMotion migration procedures. Thanks to the active / active design, the IRF network has twice as much bandwidth as the active / passive design. In addition, in L2 and L3 mode, the convergence time during failures is significantly reduced, network reliability is increased and application performance is increased.

These technologies are generally similar, but there are important differences. Like Cisco VSS, IRF technology provides for the aggregation of stack switch channels, uses LACP to negotiate the parameters of the resulting channel.
As with Cisco VSS, the state of the control plane is synchronized between the stack switches, and a failure of the main switch does not lead to a denial of service. However, the status of routing protocols is also synchronized in the IRF, and in the event of a failure and subsequent restoration of disconnection, L3 connections do not occur - in less than 50 ms the devices do not have time to detect a failure of one of the switches. Cisco has a special NSF technology for this purpose, in the case of IRF, a similar technology is used - Nonstop routing (NSR) or rgaceful restart (GR).
Switching traffic flows during aggregation - adding / removing physical channels - in IRF takes about 2 ms, while at Cisco this value is 200 ms. Such a short time allows dispensing with additional mechanisms.
Unlike Cisco VSS, IRF supports a wider range of switches, including relatively inexpensive devices. Using IRF, you can combine switches of only one model range. The exceptions are the 5800 and 5820 series switches, as well as the 5900 and 5920 switches.
Now let's briefly compare the HP IRF and Juniper VC technologies. They are similar to the following:
However, VC has several disadvantages. VC is the technology for the EX4200 switch, launched in 2008. Since then, there has been no significant investment in it. The company developed a completely different architecture - Qfabric.
With such limited funding, there was no significant innovation in EX products. For example, an EX4500 access switch with VC support used the same 128 Gb / s bus, which does not adequately respond to 10GbE traffic.
The EX8200 switch was well received by the market, but the EX8200 VC technology appeared some time later, and the internal Route Engines engines did not have enough power for the VC. The need to connect additional external controllers complicated the solution. In addition, only a few line cards support the chassis connection, mainly 8 SFP +.
In a configuration with two switches, if one of them fails, the second interprets this as a VC disconnect and goes into an inactive state according to the VC disconnect rules. The whole stack is crashing. This can be avoided by disabling gap detection, which admins often forget.
Some maintenance operations require connecting to the console and entering CLI commands. And the use of built-in dedicated VC ports limits the distance to 5 m. The EX4200 switch in the VC configuration supports only 64 LAGs.
Formally, since 2013 VC can also be used on MX series routers, but there are strong limitations. Only two chassis with two routing engines in each are supported. Mandatory Trio chipset. Enhanced Queuing DPC is not supported. Need a separate license. In addition, VC is not supported on MX5 / 10/20/40/80 hardware.
Meanwhile, the IRF has been further developed.
The evolution of IRF has resulted in Enhanced IRF (eIRF) technology. It allows you to create more complex hierarchical, including kernel and access levels. Kernel-level switches (Controlling Bridges), primary and slave, take over the functions of managing the IRF stack, and switches, access levels are actually port extenders (Port Extenders). Their main role is traffic transfer. In total there can be up to 64 access level switches. All of these switches (CB + PE) represent a single logical switch.
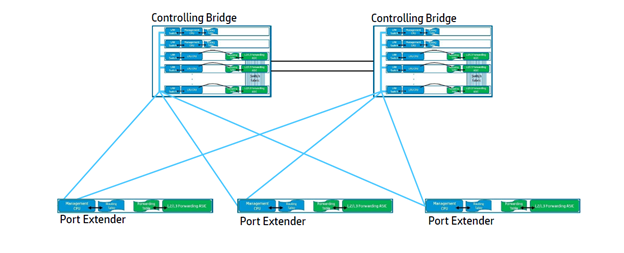
Kernel Switches (CB) and Port Extenders (PEs) with L2 / L3 Forwarding are a single logical unit. PE extenders actually act as switch line cards.
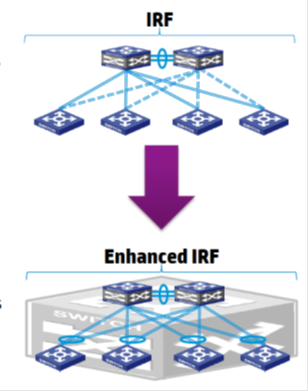
Unlike IRE, eIRF allows you to combine multiple physical devices at different levels
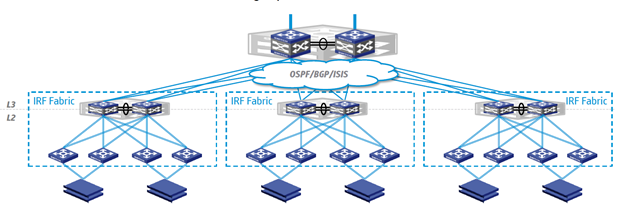
An example of building an eIRF-based network in a data center. Two switches of the factory IRF distribution level (above) are connected by redundant channels (uplinks) to the core of the network, the ToR switches (below) form the HA group. Each server in the rack is connected to two of these switches - port extenders.

An example of using eIRF on a campus network. Two IRF factory switches represent the core level, port expanders represent the access level switches. The latter form HA groups and service devices on floors of buildings. Each server connects to two switches.
Differences between IRF and eIRF
In conclusion, we list briefly what, in fact, gives us eIRF:
However, another option is possible: like combining several physical servers into one logical one, several physical network devices are combined into one easily manageable logical device. This approach is called N: 1 virtualization. Along with simpler administration, it helps to increase network reliability, increase port density and provides a number of other advantages, which we will discuss below.
Virtualization 1: N (several virtual switches work on the same platform) and N: 1 (several physical switches form one logical device).
What is switch virtualization?
Currently, several switch virtualization technologies are known that allow combining several physical switches into a single logical one, for example, Juniper Networks virtual chassis technology, Cisco Virtual Switching System (VSS) and HPE Intelligent Resilient Framework (IRF). The IRF technology developed at the time by H3C is the classic N: 1 virtualization.
In any case, virtualization of N: 1 switches creates a pool or device stack. To combine them, you can use either special dedicated interfaces or ordinary Ethernet ports 1/10/40 / 100G. In the latter case, the switches can be spaced a considerable distance: the logical switch is obtained geographically distributed. Sometimes switch virtualization technologies are called stacking, virtual stacking (as in the case of IRF) or clustering (for example, as in the technology of Huawei CSS / iStack).
The data plane is active on all devices that make up the logical switch, that is, they all provide packet transmission. The control plane, which is responsible for the logic of the switch, can be used on one device (master). It is responsible for processing network protocols (L2 / L3), ACLs, QoS, routing tables, etc.
Two topologies: bus and ring.
Two topologies for connecting switches within the IRF are possible: bus and ring. The latter is recommended, as it is more fault tolerant. Consolidated switches begin to exchange packets to build a common stack topology. Next, based on the transfer of packets within the IRF stack.
What is it for?
Switch virtualization technologies can overcome the limitations of the traditional network architecture with the Spanning Tree Protocol (STP) - significant failure recovery time, inefficient use of bandwidth, difficulties in configuration, troubleshooting, etc.
To solve these problems in ring topologies, technologies such as Resilient Packet Ring (RPR), HPE Rapid Ring Protection Protocol (RRPP) and Ethernet Ring Protection Switching (ERPS). They provide a short recovery time (50 ms) in the event of a malfunction in the ring.
For networks built according to the classical “star” topology, these technologies are hardly applicable. One of the options for optimizing such networks was the use of N: 1 virtualization technologies. The use of HPE IRF-class technologies at the core / distribution level allows for high fault tolerance without complex protocol support.
At the access level, such technologies can not only overcome all the disadvantages of the traditional STP protocol, but also significantly reduce the total number of control points. Their advantages are obvious - there are no problems with STP, loops, port blocking, creating L2 domains, plus ease of administration.
Ring network structure
IRF Features
HPE IRF technology enables fault-tolerant convergence networks that are easy to manage and scale. The group of IRF switches that make up the virtual, logical switch (and this can be up to nine devices, depending on the model), has one IP address, which simplifies configuration and management.
One switch in the group is the main one, provides a control plane, updating forwarding and routing tables for other devices. That is, all control is carried out by the main switch, while its state is synchronized with slave devices.
Switch Stack
In the event of a failure of the main IRF switch, a new one is instantly selected - service is not interrupted. If the link fails, one of the switches retains the role of the main one, the second switch enters the Recovery State and disables all ports except the IRF ports and the ports that are not disconnected (according to the configuration). After the link is restored, the switch, which was in the recovery state, will reboot and become a slave. A similar algorithm is used if two switches at once decide that they need to become active.
In the IRF domain, one of the switches can be disabled for maintenance or software updates — the so-called In-Service-Software-Upgrade (ISSU) procedure. This will not affect traffic.
IRF technology makes it possible to stack switches, receiving a total of up to 1024 Ethernet ports. For the interaction of devices in the IRF group, conventional Ethernet ports are used, in most cases - 10 Gb / s. An IRF channel is formed between the switches, and packets transmitted through it are provided with an additional header (IRF tag). The components of such a logical switch can be located in different racks of the data center or at different sites, remote from each other at a distance of up to 70 km.
IRF extends to the access, aggregation, and core levels of the network. Thanks to IRF, you can reduce the number of network layers by combining access and aggregation or aggregation functionality and the core. Boundary or aggregation switches interacting in a network with IRF-capable kernel switches see associated switches as a whole, so there is no need to use technologies such as STP.
IRF Benefits
The use of IRF provides several advantages over traditional networks. We have already talked about some of them. These benefits mainly cover three areas: simplicity, performance, and reliability.
Simplified network infrastructure
Network infrastructure is becoming simpler - not three-tier, but two-tier. It has fewer devices, interfaces, communications, and protocols that require configuration and management. A two-tier network requires less equipment and simplifies network administration in data centers and campus enterprise networks.
Centralized management and configuration
IRF does not require connecting to each device and controlling it individually. The main switch is used for configuration, and all settings apply to the devices associated with it. In this, this approach resembles SDN - software-configured networks.
So that network administrators can use not only the command line, but also a more convenient interface, the HPE Intelligent Management Center (IMC) has been developed. It allows you to manage the entire network in one console. The IMC network management system displays the network topology, manages configurations, devices, performance, and simplifies troubleshooting.
Network topology in the IMC interface
Reliability
Support in the IRF of the Link Aggregation Control Protocol (LACP) protocol allows the transfer of traffic between switches over several channels, and restoring the topology in case of a switch failure or link in the stack requires no more than 50 ms, while in case of STP it few seconds.
Comparison of convergence time in ms when using RSTP and IRF for channel failure, switch network card or chassis.
Thus, IRF allows you to create more reliable "flat" network with fewer levels and devices. Compared to traditional network infrastructure, network latency is reduced, performance is increased, and complex protocols that increase reliability are no longer needed. Capital and operating costs are reduced.
To increase the reliability of the IRF factory, you can use the N + 1 configuration. In addition, the IRF domain allows the mobility of applications and virtual machines in the global network at the L2 level.
IRF configuration using LACP between the 12500 and 5820 switches. For the 5820 switch, the aggregated connection is one virtual link. This allows you to create interesting disaster-resilient solutions where IRF and aggregated links connect geographically distributed switches.
Testing the migration of 128 virtual machines (Vmware vMotion) in configurations using RSTP and IRF showed that in the latter case higher performance is achieved.
When using RSTP, the vMotion migration process took about 70 seconds in three tests , and in the case of IRF, only 43 seconds.
Performance
In the non-blocking IRF architecture, all links are active, and the throughput of the switching system is increased. The use of IRF in conjunction with LACP also allows aggregation of channels between servers and switches, increasing network bandwidth for critical applications.
In the IRF domain, network protocols function as a unit. This increases the efficiency of data processing, increases productivity, simplifies operations. For example, in the case of routing protocols, routes are defined in a single logical domain.
Comparison of performance in the case of using IRF and other mechanisms of fault tolerance L2 / L3.
Summarize. HPE IRF technology is:
- A single point of control and settings for all devices on the stack, regardless of which device the console is connected to.
- Simplification of network topology by reducing the number of devices with an independent control plane.
- Cost reduction by using a stack instead of expensive chassis devices.
- Good scalability (up to 9 switches with fixed ports and up to four chassis).
- High fault tolerance.
- Support for the full range of IRF features and technologies.
- Automatic software update on switches in the stack, ISSU support.
IRF is supported on all HPE switches, starting from 3600 and ending with 12900E, as well as on the entire line of routers running Comware OS 7. This class of solutions can be used on campus networks (core, distribution, access), in data center networks (core, distribution , access), in routed branch networks, especially where redundancy of routers in branches is required.
As test results showIRF demonstrates advantages in areas such as network architecture, performance and reliability. Combining several switches and converting them into a single logical factory simplifies campus and data center networks, and accelerates VMware vMotion migration procedures. Thanks to the active / active design, the IRF network has twice as much bandwidth as the active / passive design. In addition, in L2 and L3 mode, the convergence time during failures is significantly reduced, network reliability is increased and application performance is increased.
HPE IRF Switches
IRF and VSS
These technologies are generally similar, but there are important differences. Like Cisco VSS, IRF technology provides for the aggregation of stack switch channels, uses LACP to negotiate the parameters of the resulting channel.
As with Cisco VSS, the state of the control plane is synchronized between the stack switches, and a failure of the main switch does not lead to a denial of service. However, the status of routing protocols is also synchronized in the IRF, and in the event of a failure and subsequent restoration of disconnection, L3 connections do not occur - in less than 50 ms the devices do not have time to detect a failure of one of the switches. Cisco has a special NSF technology for this purpose, in the case of IRF, a similar technology is used - Nonstop routing (NSR) or rgaceful restart (GR).
Switching traffic flows during aggregation - adding / removing physical channels - in IRF takes about 2 ms, while at Cisco this value is 200 ms. Such a short time allows dispensing with additional mechanisms.
Unlike Cisco VSS, IRF supports a wider range of switches, including relatively inexpensive devices. Using IRF, you can combine switches of only one model range. The exceptions are the 5800 and 5820 series switches, as well as the 5900 and 5920 switches.
| VSS vs IRF | Cisco vss | HPE IRF |
| Where supported | 4500X, 4500E, 6500E, 6800 | 3100, 3600, 5120, etc. |
| The number of devices that can be combined | 2 | 9 |
| Switch from state save | Yes (SSO / NSF) | Yes |
| Switching speed in case of failure of the main switch | 200-400 ms | 50 ms |
| Bus for combining switches | VSL channel, Ethernet ports | IRF channel, Ethernet ports |
| Dual Active Switch Situation Detection Technologies | ePAgP, Fast Hello, IP BFD | LACP, BFD, ARP, ND |
| Prevention of network problems in the event of a break in the VSL / IRF channel | Port blocking | Port blocking |
| Building hierarchical topologies | Instant access | eIRF |
IRF and VC
Now let's briefly compare the HP IRF and Juniper VC technologies. They are similar to the following:
- Both eliminate the need for STP and VRRP.
- HP IRF and Juniper VC use concepts such as primary switch, backup device, and stack components.
- Like the IRF, Juniper VC is supported in a single series of switches. True, some HPE devices can stack with other models, for example 5800/5820 with 5900/5920. Separate Juniper devices also form a VC with other models, such as the EX4200 / EX4500 / EX4550.
- HP IRF and Juniper VC support remote IRF / VC connections.
However, VC has several disadvantages. VC is the technology for the EX4200 switch, launched in 2008. Since then, there has been no significant investment in it. The company developed a completely different architecture - Qfabric.
With such limited funding, there was no significant innovation in EX products. For example, an EX4500 access switch with VC support used the same 128 Gb / s bus, which does not adequately respond to 10GbE traffic.
The EX8200 switch was well received by the market, but the EX8200 VC technology appeared some time later, and the internal Route Engines engines did not have enough power for the VC. The need to connect additional external controllers complicated the solution. In addition, only a few line cards support the chassis connection, mainly 8 SFP +.
In a configuration with two switches, if one of them fails, the second interprets this as a VC disconnect and goes into an inactive state according to the VC disconnect rules. The whole stack is crashing. This can be avoided by disabling gap detection, which admins often forget.
Some maintenance operations require connecting to the console and entering CLI commands. And the use of built-in dedicated VC ports limits the distance to 5 m. The EX4200 switch in the VC configuration supports only 64 LAGs.
Formally, since 2013 VC can also be used on MX series routers, but there are strong limitations. Only two chassis with two routing engines in each are supported. Mandatory Trio chipset. Enhanced Queuing DPC is not supported. Need a separate license. In addition, VC is not supported on MX5 / 10/20/40/80 hardware.
Meanwhile, the IRF has been further developed.
Enhanced IRF
The evolution of IRF has resulted in Enhanced IRF (eIRF) technology. It allows you to create more complex hierarchical, including kernel and access levels. Kernel-level switches (Controlling Bridges), primary and slave, take over the functions of managing the IRF stack, and switches, access levels are actually port extenders (Port Extenders). Their main role is traffic transfer. In total there can be up to 64 access level switches. All of these switches (CB + PE) represent a single logical switch.
Kernel Switches (CB) and Port Extenders (PEs) with L2 / L3 Forwarding are a single logical unit. PE extenders actually act as switch line cards.
Unlike IRE, eIRF allows you to combine multiple physical devices at different levels
An example of building an eIRF-based network in a data center. Two switches of the factory IRF distribution level (above) are connected by redundant channels (uplinks) to the core of the network, the ToR switches (below) form the HA group. Each server in the rack is connected to two of these switches - port extenders.
An example of using eIRF on a campus network. Two IRF factory switches represent the core level, port expanders represent the access level switches. The latter form HA groups and service devices on floors of buildings. Each server connects to two switches.
Differences between IRF and eIRF
| IRF | Enhanced IRF | |
| Hierarchy | Horizontal, devices of one type and one model | Vertical, multiple devices allowed |
| number | 2-4 devices of the senior class or 4-9 junior | 30 ~ 64 |
| Number of Managed Nodes | 1 / 4-1 / 9 | 1 / 30-1 / 64 + |
| Horizontal cables | A large number of access levels, complicated installation and maintenance | No horizontal cables, simple cable management |
| Traffic model | Traditional | SDN prototype. Simplified migration to SDN |
In conclusion, we list briefly what, in fact, gives us eIRF:
- Simplified operations : centralized management and automated installation, actually plug & play.
- Improved scalability and a more powerful virtual factory : Enhanced IRF supports two chassis switches in its core, these are very powerful platforms.
- Simple implementation : 5700 switches as L2 devices in Port Extender mode when connected to the Controlling Bridge automatically become part of the Enhanced IRF factory.
- Scalable server-side access : 1GbE and 10GbE support.
- Redundancy: active / active, the server connects to two Port Extender switches.
- Guaranteed bandwidth : Controlling Bridge and Port Extender switches can operate in L2 or L3 mode using the entire band at full speed.
- Ready for the Future : The equipment is ready to use OpenFlow / SDN. And this is very important, given the latest trends in the construction of data transmission networks.