LLVM: do-it-yourself compiler. Introduction
Imagine that one fine day you came up with the idea of a processor of its own architecture, which was completely different, and you really wanted to implement this idea “in hardware”. Fortunately, nothing is impossible in this. A little verilogue, and here your idea is realized. You already have wonderful dreams about how Intel went bankrupt, Microsoft hastily rewrites Windows for your architecture, and the Linux community has already written a fresh version of the system for your microprocessor with very boring wallpapers.
However, for all this, one little thing is missing: the compiler!
Yes, I know that many do not consider having a compiler as something important, believing that everyone should program strictly in assembler. If you also think so, I will not argue with you, just do not read on.
If you want at least C language to be available for your original architecture, please, use cat.
The article will discuss the use of the LLVM compiler infrastructure to build custom solutions based on it.
The scope of LLVM is not limited to the development of compilers for new processors; the LLVM compiler infrastructure can also be used to develop compilers of new programming languages, new optimization algorithms, and specific tools for static analysis of program code (search for errors, collecting statistics, etc.).
For example, you can use some standard processor (e.g. ARM) in combination with a specialized coprocessor (e.g. matrix FPU), in which case you may need to modify the existing compiler for ARM so that it can generate code for your FPU.
Also, an interesting application of LLVM can be the generation of source texts in a high-level language ("translation" from one language to another). For example, you can write a code generator in Verilog by source code in C.

KDPV
Today, there are only two realistic ways to develop a compiler for your own architecture: using GCC or using LLVM. Other open source compiler projects either have not reached the level of development like GCC and LLVM, or are outdated and stopped developing, they do not have developed optimization algorithms, and may not provide full compatibility even with the C language standard, not to mention the support of others programming languages. Developing your own compiler “from scratch” is a very irrational way, because existing open source solutions already implement the compiler frontend with many very non-trivial optimization algorithms, which, moreover, have been well tested and have been used for a long time.
Which of these two open-source projects should I choose as the basis for my compiler? GCC (GNU Compiler Collection) is an older project, the first release of which took place in 1987, its author is Richard Stallman, a well-known figure in the open-source movement [4]. It supports many programming languages: C, C ++, Objective-C, Fortran, Java, Ada, Go. There are also frontends for many other programming languages that are not included in the main assembly. The GCC compiler supports a large number of processor architectures and operating systems, and is currently the most common compiler. GCC itself is written in C (in the comments, I was corrected that it has been mostly rewritten in C ++ already).
LLVM is much “younger”, its first release took place in 2003, it (more precisely, its Clang frontend) supports the C, C ++, Objective-C and Objective-C ++ programming languages, and also has front-ends for the Common Lisp, ActionScript, Ada languages , D, Fortran, OpenGL Shading Language, Go, Haskell, Java bytecode, Julia, Swift, Python, Ruby, Rust, Scala, C # and Lua. It was developed at the University of Illinois, in the USA, and is the main compiler for development under the OS X operating system. LLVM is written in C ++ (C ++ 11 for the latest releases) [5].

The relative “youth” of LLVM is not a flaw, it is mature enough to have no critical bugs, nor does it carry a huge burden of outdated architectural solutions like GCC. The modular structure of the compiler allows the use of the LLVM-GCC frontend, which provides full support for GCC standards, while the generation of the target platform code will be performed by LLC (LLVM backend). You can also use Clang, the original LLVM frontend.
LLVM is well documented and has a lot of code examples for it.
The LLVM compiler infrastructure consists of various tools; it makes no sense to consider all of them in the framework of this article. We restrict ourselves to the main tools that make up the compiler as such.
The LLVM compiler, like some other compilers, consists of a frontend, an optimizer (middleland), and a backend. Such a structure makes it possible to separate the development of a compiler for a new programming language, the development of optimization methods, and the development of a code generator for a specific processor (such compilers are called “retargetable”).
The link between them is the intermediate language LLVM, the assembler of the "virtual machine". The frontend (for example, Clang) converts the text of a program in a high-level language into text in an intermediate language, the optimizer (opt) performs various optimizations on it, and the backend (llc) generates the code of the target processor (in assembler or directly as a binary file). In addition, LLVM can operate in JIT (just-in-time) compilation mode when compilation takes place directly during program execution.
The intermediate representation of the program can be either in the form of a text file in the LLVM assembler language, or in the form of a binary format, “bitcode”. By default, clang generates the bitcode (.bc file), but for debugging and learning LLVM we will need to generate a text intermediate representation in LLVM assembler (it is also called IR code, from the words Intermediate Representation, intermediate representation).
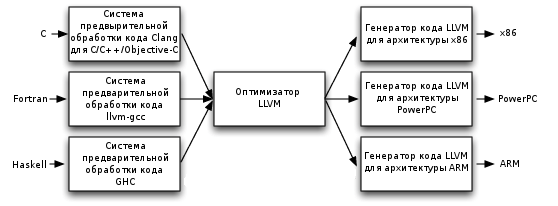
Fig. 1. Modular architecture of the compiler
In addition to the above programs, LLVM includes other utilities [6].
So, let's write the simplest program in C.
And compile it: Some explanations: -c add.c - input file; -O0 - optimization level 0, no optimization; --target = xcore - the core of the xcore processor does not have any complex features when compiling into IR-code, therefore it is an ideal object for research. This kernel has a capacity of 32, and clang aligns all variables to the boundaries of 32-bit words; -emit-llvm -S - instruct clang to generate the llvm file in text form (in assembler LLVM); -o add_o0.ll - output file Let's look at the result: It looks pretty complicated, doesn't it? However, let's understand what is written here. So: target datalayout = "em: ep: 32: 32-i1: 8: 32-i8: 8: 32-i16: 16: 32-i64: 32-f64: 32-a: 0: 32-n32"
Description of bit depth of variables and the most basic features of architecture. e- little-endian architecture. For the big-endian, here would be the letter E. m: e - mangling, a naming convention. We don’t need it yet. p: 32: 32 - pointers have 32 bits and are aligned on the boundaries of 32-bit words. i1: 8: 32 - Boolean variables (i1) are expressed in 8-bit values and aligned on the boundaries of 32-bit words. Further, it is similar for integer variables i8 - i64 (from 8 to 64 bits, respectively), and f64 for real variables of double precision. a: 0: 32 - aggregate variables (i.e. arrays and structures) have 32 bit alignment, n32 - bit depth of numbers processed by the processor ALU (native integer width).
The name of the target (ie, the target processor) follows: target triple = “xcore”. Although the IR code is often referred to as “machine independent”, we actually see it is not. It reflects some features of the target architecture. This is one of the reasons why we should specify the target architecture not only for the backend, but also for the frontend.
The following is the function code for foo: The code is rather cumbersome, although the original function is very simple. Here is what he does. Just note that all variable names in LLVM have the prefix either% (for local variables) or @ for global. In this example, all variables are local. % 1 = alloca i32, align 4 - allocates 4 bytes on the stack for the variable, the pointer to this area is the pointer% 1.
store i32% x, i32 *% 1, align 4 - copies one of the function arguments (% x) to the selected area.
% 3 = load i32 *% 1, align 4 - Retrieves the value in the variable% 3. % 3 now stores a local copy of% x.
Does the same for the argument% y
% 5 = add nsw i32% 3,% 4 - adds local copies of% x and% y, puts the result in% 5. There is also an attribute nsw, but it is not important for us yet.
Returns the value% 5.
It can be seen from the above example that at a zero level of optimization, clang generates code, literally following the source code, creates local copies of all arguments and does not make any attempts to remove redundant commands. This may seem like a bad compiler property, but it’s actually a very useful feature when debugging programs and when debugging the code of the compiler itself.
Let's see what happens if you change the optimization level to O1: We see that not a single extra team is left. Now the program directly adds the function arguments and returns the result. There are higher levels of optimization, but in this particular case they will not give a better result, because The maximum level of optimization has already been achieved. The rest of the LLVM code (attributes, metadata), carries in itself the service information, which so far is not interesting to us.
The LLVM code structure is very simple. The program code consists of modules, the compiler processes one module at a time. The module has global declarations (variables, constants and declarations of function headers located in other modules) and functions. Functions have arguments and return types. Functions consist of base blocks. A base unit is an LLVM assembler instruction sequence that has one entry point and one exit point. The base block does not contain any branching and loops inside, it is executed strictly sequentially from beginning to end and must end with a terminating command (returning from a function or switching to another block).
And finally, the base unit consists of assembler instructions. The list of commands is given in the LLVM documentation [7].
So, once again: the base unit has one entry point, marked with a label, and must necessarily end with the unconditional jump command br or the return command ret. They may have a conditional branch command in front of them, in which case it should be immediately before the termination command. The base unit has a list of predecessors - base units from which control can come to it, and successors - base units to which it can transfer control. Based on this information, the CFG - Control Flow Graph, the flow chart of control, is the most important structure representing the program in the compiler.
Consider a test example in C:
Let the source code in C have a loop:
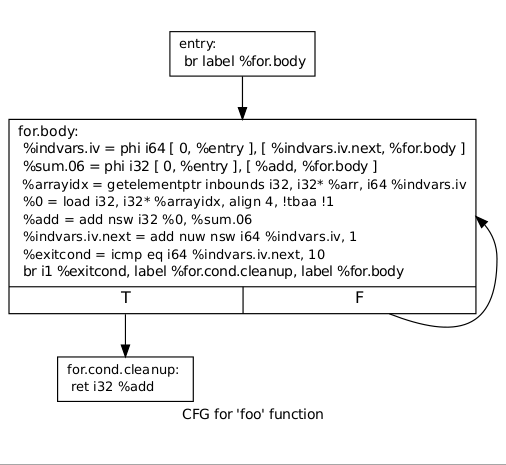
Its CFG looks like:
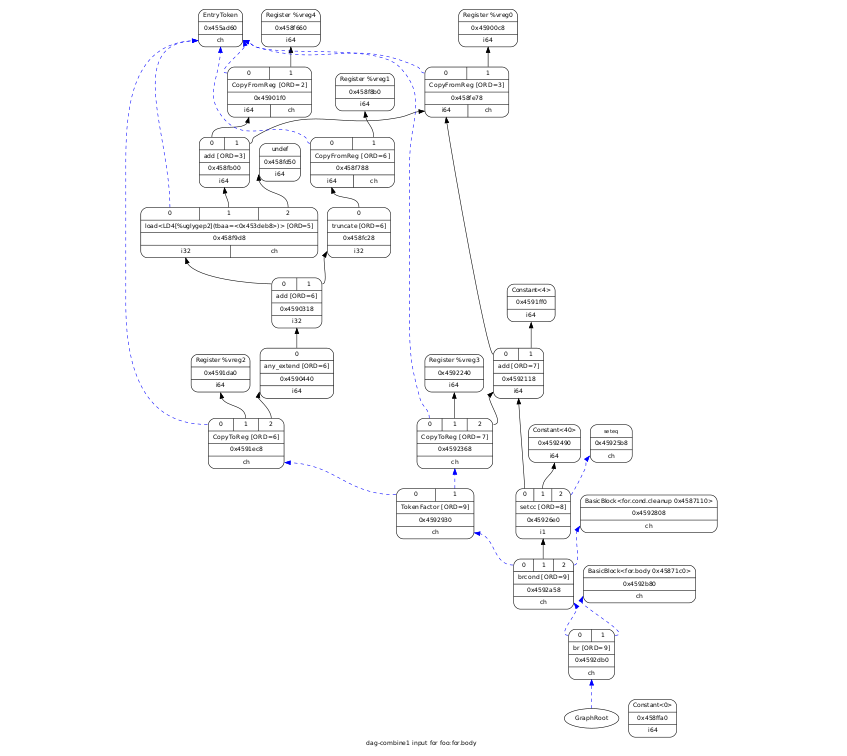
Another kind of graph in LLVM is the DAG - directed acyclic graph, a directed acyclic graph that is a basic unit.
It represents assembler commands and dependencies between them. The figure below shows the DAG of the base unit, representing the body of the loop in the example above, with the optimization level of -O1:
The key feature of the IR code that distinguishes it from high-level languages is that it is presented in the so-called SSA-form (Static Single Assignment form). This feature is very important for understanding when developing a compiler on the LLVM platform, so we will pay some attention to it. In short, in the SSA form, each variable is assigned a value exactly once and only at one point in the program. All algorithms for optimizing and converting IR code work only with this form.
However, how to convert a regular high-level language program into this form? Indeed, in ordinary programming languages, the value of a variable can be assigned several times in different places of the program, or, for example, in a loop.
To implement this program behavior, one of two methods is used. The first trick is to use pairs of load / store commands, as in the code above. The only assignment restriction applies only to LLVM named variables, and does not apply to memory locations referenced by pointers. That is, you can write to the memory cell an unlimited number of times with the store command, and the formal SSA rule will be respected, since the pointer to this cell does not change. This method is usually used with an optimization level of -O0, and we will not dwell on it in detail. The second trick uses φ-functions, another interesting concept of IR-code.
We will use the test case from the previous section.
Compile with the optimization level -O0: Here we see what was written above: the loop variable is just a memory cell referenced by the% i pointer.
Now let's try the optimization level O1: Here we see that the loop variable is% i.02 (variable names in LLVM can contain periods), and this is not a pointer, but a regular 32-bit variable, and the value is assigned using the phi i32 function [ 0,% 0], [% 5,% 1]. This means that the function will take the value 0 if the transition occurred from the base block% 0 (the first base block in the function), and the value of the variable% 5 if the transition occurred from the base block% 1 (i.e., from the output point of the same base block). Thus, the IR code generator got rid of two variable assignments, strictly following the formal SSA rules. Further it is seen that in a similar way the assignment to the variable% sum.01 takes place.
So, the meaning of the φ-function is that its value depends on which base unit the transition to it was made from. φ-functions can be found only at the beginning of the base unit. If there are several, they must follow continuously, starting with the first instruction of the base unit.
What will happen at the optimization level -O2? The optimizer has launched a loop. In general, the LLVM IR code optimizer is very intelligent; it can not only unroll loops, but also simplify non-trivial constructions, calculate constant values, even if they are not present in the code explicitly, and do other complex code transformations.
Real programs do not consist of one module. The traditional compiler compiles the modules individually, turning them into object files, and then passes them to the linker (linker), which combines them into one executable file. LLVM also allows you to do this.
But LLVM also has the ability to build IR code. The easiest way to consider this is with an example. Suppose there are two source modules: foo.c and bar.c:
If the program is compiled in the “traditional” way, then the optimizer will not be able to do almost anything with it: when compiling foo.c, the compiler does not know what is inside the bar function, and it can do the only obvious way to insert bar () calls.
But if we compose the IR code, we get one module that after optimization with the -O2 level will look like this (for clarity, the module header and metadata are omitted): It is clear that no calls are made to the foo function, the compiler transferred it to it the contents of bar () completely, substituting the constant values of k along the way. Although the bar () function remains in the module, it will be excluded when compiling the executable file, provided that it is not called anywhere else in the program.
It should be noted that GCC also has the ability to link and optimize intermediate code (LTO, link-time optimization) [6].
Of course, optimization in LLVM is not limited to optimization of IR code. Inside the backend, various optimizations also take place at different stages of converting the IR code into a machine representation. LLVM performs some of these optimizations on its own, but the backend developer can (and should) develop his own optimization algorithms that will make full use of the features of the processor architecture.
The development of the compiler for the original processor architecture, this is mainly the development of the backend. Intervention in front-end algorithms, as a rule, is not necessary, or, in any case, requires very good reason. If you analyze the source code of Clang, you can see that most of the "special" algorithms fall on the x86 and PowerPC processors with their non-standard formats of real numbers. For most other processors, you need to specify only the sizes of the base types and endianness (big-endian or little-endian). Most often, you can simply find a similar (in terms of bit depth) processor among the many supported.
Code generation for the target platform takes place in the LLVM, LLC backend. LLC supports many different processors, and you can make a code generator for your own original processor based on it. This task is also simplified due to the fact that all source code, including modules for each supported architecture, is completely open and available for study.
The code generator for the target platform (target) is the most time-consuming task when developing a compiler based on LLVM infrastructure. I decided not to dwell on the features of the backend implementation here, since they significantly depend on the architecture of the target processor. However, if a respected Habr audience has an interest in this topic, I am ready to describe the key points in developing the backend in the next article.
In a short article, you can not consider in detail neither the LLVM architecture, nor the LLVM IR syntax, nor the backend development process. However, these issues are covered in detail in the documentation. The author rather tried to give a general idea about the infrastructure of LLVM compilers, emphasizing that this platform is modern, powerful, universal, and independent of either the input language or the target processor architecture, allowing you to implement both of them at the request of the developer.
In addition to the reviewed ones, LLVM also contains other utilities, however, their consideration is beyond the scope of the article.
LLVM allows you to implement a backend for any architecture (see note), including pipelined architectures, with extraordinary execution of commands, with various parallelization options, VLIW, for classic and stack architectures, in general, for any options.
Regardless of how non-standard solutions underlie the processor architecture, it is just a matter of writing more or less code.

Compilers
[1] Dragon Book
[2] Wirth N. Building
GCC Compilers
[3] gcc.gnu.org - GCC Project Site
[4] Richard M. Stallman and the GCC Developer Community. GNU Compiler Collection Internals
LLVM
[5] http://llvm.org/ - LLVM project site
[6] http://llvm.org/docs/GettingStarted.html Getting Started with the LLVM System
[7] http: // llvm .org / docs / LangRef.html LLVM Language Reference Manual
[8] http://llvm.org/docs/WritingAnLLVMBackend.html Writing An LLVM Backend
[9] http://llvm.org/docs/WritingAnLLVMPass.html Writing An LLVM Pass
[10] Chen Chung-Shu. Creating an LLVM Backend for the Cpu0 Architecture
[11] Mayur Pandey, Suyog Sarda. LLVM Cookbook
[12] Bruno Cardoso Lopes. Getting Started with LLVM Core Libraries
[13] Suyog Sarda, Mayur Pandey. LLVM Essentials
The author will be happy to answer your questions in the comments and in PM.
The request to report all typos noticed in PM. Thanks in advance.
However, for all this, one little thing is missing: the compiler!
Yes, I know that many do not consider having a compiler as something important, believing that everyone should program strictly in assembler. If you also think so, I will not argue with you, just do not read on.
If you want at least C language to be available for your original architecture, please, use cat.
The article will discuss the use of the LLVM compiler infrastructure to build custom solutions based on it.
The scope of LLVM is not limited to the development of compilers for new processors; the LLVM compiler infrastructure can also be used to develop compilers of new programming languages, new optimization algorithms, and specific tools for static analysis of program code (search for errors, collecting statistics, etc.).
For example, you can use some standard processor (e.g. ARM) in combination with a specialized coprocessor (e.g. matrix FPU), in which case you may need to modify the existing compiler for ARM so that it can generate code for your FPU.
Also, an interesting application of LLVM can be the generation of source texts in a high-level language ("translation" from one language to another). For example, you can write a code generator in Verilog by source code in C.
KDPV
Why LLVM?
Today, there are only two realistic ways to develop a compiler for your own architecture: using GCC or using LLVM. Other open source compiler projects either have not reached the level of development like GCC and LLVM, or are outdated and stopped developing, they do not have developed optimization algorithms, and may not provide full compatibility even with the C language standard, not to mention the support of others programming languages. Developing your own compiler “from scratch” is a very irrational way, because existing open source solutions already implement the compiler frontend with many very non-trivial optimization algorithms, which, moreover, have been well tested and have been used for a long time.
Which of these two open-source projects should I choose as the basis for my compiler? GCC (GNU Compiler Collection) is an older project, the first release of which took place in 1987, its author is Richard Stallman, a well-known figure in the open-source movement [4]. It supports many programming languages: C, C ++, Objective-C, Fortran, Java, Ada, Go. There are also frontends for many other programming languages that are not included in the main assembly. The GCC compiler supports a large number of processor architectures and operating systems, and is currently the most common compiler. GCC itself is written in C (in the comments, I was corrected that it has been mostly rewritten in C ++ already).
LLVM is much “younger”, its first release took place in 2003, it (more precisely, its Clang frontend) supports the C, C ++, Objective-C and Objective-C ++ programming languages, and also has front-ends for the Common Lisp, ActionScript, Ada languages , D, Fortran, OpenGL Shading Language, Go, Haskell, Java bytecode, Julia, Swift, Python, Ruby, Rust, Scala, C # and Lua. It was developed at the University of Illinois, in the USA, and is the main compiler for development under the OS X operating system. LLVM is written in C ++ (C ++ 11 for the latest releases) [5].
The relative “youth” of LLVM is not a flaw, it is mature enough to have no critical bugs, nor does it carry a huge burden of outdated architectural solutions like GCC. The modular structure of the compiler allows the use of the LLVM-GCC frontend, which provides full support for GCC standards, while the generation of the target platform code will be performed by LLC (LLVM backend). You can also use Clang, the original LLVM frontend.
LLVM is well documented and has a lot of code examples for it.
Modular Compiler Architecture
The LLVM compiler infrastructure consists of various tools; it makes no sense to consider all of them in the framework of this article. We restrict ourselves to the main tools that make up the compiler as such.
The LLVM compiler, like some other compilers, consists of a frontend, an optimizer (middleland), and a backend. Such a structure makes it possible to separate the development of a compiler for a new programming language, the development of optimization methods, and the development of a code generator for a specific processor (such compilers are called “retargetable”).
The link between them is the intermediate language LLVM, the assembler of the "virtual machine". The frontend (for example, Clang) converts the text of a program in a high-level language into text in an intermediate language, the optimizer (opt) performs various optimizations on it, and the backend (llc) generates the code of the target processor (in assembler or directly as a binary file). In addition, LLVM can operate in JIT (just-in-time) compilation mode when compilation takes place directly during program execution.
The intermediate representation of the program can be either in the form of a text file in the LLVM assembler language, or in the form of a binary format, “bitcode”. By default, clang generates the bitcode (.bc file), but for debugging and learning LLVM we will need to generate a text intermediate representation in LLVM assembler (it is also called IR code, from the words Intermediate Representation, intermediate representation).
Fig. 1. Modular architecture of the compiler
In addition to the above programs, LLVM includes other utilities [6].
So, let's write the simplest program in C.
int foo(int x, int y) {
return x + y;
}
And compile it: Some explanations: -c add.c - input file; -O0 - optimization level 0, no optimization; --target = xcore - the core of the xcore processor does not have any complex features when compiling into IR-code, therefore it is an ideal object for research. This kernel has a capacity of 32, and clang aligns all variables to the boundaries of 32-bit words; -emit-llvm -S - instruct clang to generate the llvm file in text form (in assembler LLVM); -o add_o0.ll - output file Let's look at the result: It looks pretty complicated, doesn't it? However, let's understand what is written here. So: target datalayout = "em: ep: 32: 32-i1: 8: 32-i8: 8: 32-i16: 16: 32-i64: 32-f64: 32-a: 0: 32-n32"
clang-3.5 -c add.c -O0 --target=xcore -emit-llvm -S -o add_o0.ll
; ModuleID = 'add.c'
target datalayout = "e-m:e-p:32:32-i1:8:32-i8:8:32-i16:16:32-i64:32-f64:32-a:0:32-n32"
target triple = "xcore"
; Function Attrs: nounwind
define i32 @foo(i32 %x, i32 %y) #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 %x, i32* %1, align 4
store i32 %y, i32* %2, align 4
%3 = load i32* %1, align 4
%4 = load i32* %2, align 4
%5 = add nsw i32 %3, %4
ret i32 %5
}
attributes #0 = { nounwind "less-precise-fpmad"="false" "no-frame-pointer-elim"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "stack-protector-buffer-size"="8" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.ident = !{!0}
!xcore.typestrings = !{!1}
!0 = metadata !{metadata !"Ubuntu clang version 3.5.0-4ubuntu2~trusty2 (tags/RELEASE_350/final) (based on LLVM 3.5.0)"}
!1 = metadata !{i32 (i32, i32)* @foo, metadata !"f{si}(si,si)"}
Description of bit depth of variables and the most basic features of architecture. e- little-endian architecture. For the big-endian, here would be the letter E. m: e - mangling, a naming convention. We don’t need it yet. p: 32: 32 - pointers have 32 bits and are aligned on the boundaries of 32-bit words. i1: 8: 32 - Boolean variables (i1) are expressed in 8-bit values and aligned on the boundaries of 32-bit words. Further, it is similar for integer variables i8 - i64 (from 8 to 64 bits, respectively), and f64 for real variables of double precision. a: 0: 32 - aggregate variables (i.e. arrays and structures) have 32 bit alignment, n32 - bit depth of numbers processed by the processor ALU (native integer width).
The name of the target (ie, the target processor) follows: target triple = “xcore”. Although the IR code is often referred to as “machine independent”, we actually see it is not. It reflects some features of the target architecture. This is one of the reasons why we should specify the target architecture not only for the backend, but also for the frontend.
The following is the function code for foo: The code is rather cumbersome, although the original function is very simple. Here is what he does. Just note that all variable names in LLVM have the prefix either% (for local variables) or @ for global. In this example, all variables are local. % 1 = alloca i32, align 4 - allocates 4 bytes on the stack for the variable, the pointer to this area is the pointer% 1.
define i32 @foo(i32 %x, i32 %y) #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 %x, i32* %1, align 4
store i32 %y, i32* %2, align 4
%3 = load i32* %1, align 4
%4 = load i32* %2, align 4
%5 = add nsw i32 %3, %4
ret i32 %5
}
store i32% x, i32 *% 1, align 4 - copies one of the function arguments (% x) to the selected area.
% 3 = load i32 *% 1, align 4 - Retrieves the value in the variable% 3. % 3 now stores a local copy of% x.
Does the same for the argument% y
% 5 = add nsw i32% 3,% 4 - adds local copies of% x and% y, puts the result in% 5. There is also an attribute nsw, but it is not important for us yet.
Returns the value% 5.
It can be seen from the above example that at a zero level of optimization, clang generates code, literally following the source code, creates local copies of all arguments and does not make any attempts to remove redundant commands. This may seem like a bad compiler property, but it’s actually a very useful feature when debugging programs and when debugging the code of the compiler itself.
Let's see what happens if you change the optimization level to O1: We see that not a single extra team is left. Now the program directly adds the function arguments and returns the result. There are higher levels of optimization, but in this particular case they will not give a better result, because The maximum level of optimization has already been achieved. The rest of the LLVM code (attributes, metadata), carries in itself the service information, which so far is not interesting to us.
define i32 @foo(i32 %x, i32 %y) #0 {
%1 = add nsw i32 %y, %x
ret i32 %1
}
LLVM Code Structure
The LLVM code structure is very simple. The program code consists of modules, the compiler processes one module at a time. The module has global declarations (variables, constants and declarations of function headers located in other modules) and functions. Functions have arguments and return types. Functions consist of base blocks. A base unit is an LLVM assembler instruction sequence that has one entry point and one exit point. The base block does not contain any branching and loops inside, it is executed strictly sequentially from beginning to end and must end with a terminating command (returning from a function or switching to another block).
And finally, the base unit consists of assembler instructions. The list of commands is given in the LLVM documentation [7].
So, once again: the base unit has one entry point, marked with a label, and must necessarily end with the unconditional jump command br or the return command ret. They may have a conditional branch command in front of them, in which case it should be immediately before the termination command. The base unit has a list of predecessors - base units from which control can come to it, and successors - base units to which it can transfer control. Based on this information, the CFG - Control Flow Graph, the flow chart of control, is the most important structure representing the program in the compiler.
Consider a test example in C:
Let the source code in C have a loop:
//функция вычисляет сумму 10 элементов массива
int for_loop(int x[]) {
int sum = 0;
for(int i = 0; i < 10; ++i) {
sum += x[i];
}
return sum;
}
Its CFG looks like:
Another kind of graph in LLVM is the DAG - directed acyclic graph, a directed acyclic graph that is a basic unit.
It represents assembler commands and dependencies between them. The figure below shows the DAG of the base unit, representing the body of the loop in the example above, with the optimization level of -O1:
SSA form
The key feature of the IR code that distinguishes it from high-level languages is that it is presented in the so-called SSA-form (Static Single Assignment form). This feature is very important for understanding when developing a compiler on the LLVM platform, so we will pay some attention to it. In short, in the SSA form, each variable is assigned a value exactly once and only at one point in the program. All algorithms for optimizing and converting IR code work only with this form.
However, how to convert a regular high-level language program into this form? Indeed, in ordinary programming languages, the value of a variable can be assigned several times in different places of the program, or, for example, in a loop.
To implement this program behavior, one of two methods is used. The first trick is to use pairs of load / store commands, as in the code above. The only assignment restriction applies only to LLVM named variables, and does not apply to memory locations referenced by pointers. That is, you can write to the memory cell an unlimited number of times with the store command, and the formal SSA rule will be respected, since the pointer to this cell does not change. This method is usually used with an optimization level of -O0, and we will not dwell on it in detail. The second trick uses φ-functions, another interesting concept of IR-code.
SSA code: load / store
We will use the test case from the previous section.
Compile with the optimization level -O0: Here we see what was written above: the loop variable is just a memory cell referenced by the% i pointer.
define i32 @for_loop(i32* %x) #0 {
%1 = alloca i32*, align 4
%sum = alloca i32, align 4
%i = alloca i32, align 4
store i32* %x, i32** %1, align 4
store i32 0, i32* %sum, align 4
store i32 0, i32* %i, align 4
br label %2
; :2 ; preds = %12, %0
%3 = load i32* %i, align 4
%4 = icmp slt i32 %3, 10
br i1 %4, label %5, label %15
; :5 ; preds = %2
%6 = load i32* %i, align 4
%7 = load i32** %1, align 4
%8 = getelementptr inbounds i32* %7, i32 %6
%9 = load i32* %8, align 4
%10 = load i32* %sum, align 4
%11 = add nsw i32 %10, %9
store i32 %11, i32* %sum, align 4
br label %12
; :12 ; preds = %5
%13 = load i32* %i, align 4
%14 = add nsw i32 %13, 1
store i32 %14, i32* %i, align 4
br label %2
; :15 ; preds = %2
%16 = load i32* %sum, align 4
ret i32 %16
}
SSA code: φ functions
Now let's try the optimization level O1: Here we see that the loop variable is% i.02 (variable names in LLVM can contain periods), and this is not a pointer, but a regular 32-bit variable, and the value is assigned using the phi i32 function [ 0,% 0], [% 5,% 1]. This means that the function will take the value 0 if the transition occurred from the base block% 0 (the first base block in the function), and the value of the variable% 5 if the transition occurred from the base block% 1 (i.e., from the output point of the same base block). Thus, the IR code generator got rid of two variable assignments, strictly following the formal SSA rules. Further it is seen that in a similar way the assignment to the variable% sum.01 takes place.
define i32 @for_loop(i32* nocapture readonly %x) #0 {
br label %1
; :1 ; preds = %1, %0
%i.02 = phi i32 [ 0, %0 ], [ %5, %1 ]
%sum.01 = phi i32 [ 0, %0 ], [ %4, %1 ]
%2 = getelementptr inbounds i32* %x, i32 %i.02
%3 = load i32* %2, align 4, !tbaa !2
%4 = add nsw i32 %3, %sum.01
%5 = add nsw i32 %i.02, 1
%exitcond = icmp eq i32 %5, 10
br i1 %exitcond, label %6, label %1
; :6 ; preds = %1
ret i32 %4
}
So, the meaning of the φ-function is that its value depends on which base unit the transition to it was made from. φ-functions can be found only at the beginning of the base unit. If there are several, they must follow continuously, starting with the first instruction of the base unit.
Moar optimization!
What will happen at the optimization level -O2? The optimizer has launched a loop. In general, the LLVM IR code optimizer is very intelligent; it can not only unroll loops, but also simplify non-trivial constructions, calculate constant values, even if they are not present in the code explicitly, and do other complex code transformations.
define i32 @for_loop(i32* nocapture readonly %x) #0 {
%1 = load i32* %x, align 4, !tbaa !2
%2 = getelementptr inbounds i32* %x, i32 1
%3 = load i32* %2, align 4, !tbaa !2
%4 = add nsw i32 %3, %1
%5 = getelementptr inbounds i32* %x, i32 2
%6 = load i32* %5, align 4, !tbaa !2
%7 = add nsw i32 %6, %4
%8 = getelementptr inbounds i32* %x, i32 3
%9 = load i32* %8, align 4, !tbaa !2
%10 = add nsw i32 %9, %7
%11 = getelementptr inbounds i32* %x, i32 4
%12 = load i32* %11, align 4, !tbaa !2
%13 = add nsw i32 %12, %10
%14 = getelementptr inbounds i32* %x, i32 5
%15 = load i32* %14, align 4, !tbaa !2
%16 = add nsw i32 %15, %13
%17 = getelementptr inbounds i32* %x, i32 6
%18 = load i32* %17, align 4, !tbaa !2
%19 = add nsw i32 %18, %16
%20 = getelementptr inbounds i32* %x, i32 7
%21 = load i32* %20, align 4, !tbaa !2
%22 = add nsw i32 %21, %19
%23 = getelementptr inbounds i32* %x, i32 8
%24 = load i32* %23, align 4, !tbaa !2
%25 = add nsw i32 %24, %22
%26 = getelementptr inbounds i32* %x, i32 9
%27 = load i32* %26, align 4, !tbaa !2
%28 = add nsw i32 %27, %25
ret i32 %28
}
IR Code Layout
Real programs do not consist of one module. The traditional compiler compiles the modules individually, turning them into object files, and then passes them to the linker (linker), which combines them into one executable file. LLVM also allows you to do this.
But LLVM also has the ability to build IR code. The easiest way to consider this is with an example. Suppose there are two source modules: foo.c and bar.c:
//bar.h
#ifndef BAR_H
#define BAR_H
int bar(int x, int k);
#endif
//bar.c
int bar(int x, int k) {
return x * x * k;
}
//foo.c
#include "bar.h"
int foo(int x, int y) {
return bar(x, 2) + bar(y, 3);
}
If the program is compiled in the “traditional” way, then the optimizer will not be able to do almost anything with it: when compiling foo.c, the compiler does not know what is inside the bar function, and it can do the only obvious way to insert bar () calls.
But if we compose the IR code, we get one module that after optimization with the -O2 level will look like this (for clarity, the module header and metadata are omitted): It is clear that no calls are made to the foo function, the compiler transferred it to it the contents of bar () completely, substituting the constant values of k along the way. Although the bar () function remains in the module, it will be excluded when compiling the executable file, provided that it is not called anywhere else in the program.
define i32 @foo(i32 %x, i32 %y) #0 {
%1 = shl i32 %x, 1
%2 = mul i32 %1, %x
%3 = mul i32 %y, 3
%4 = mul i32 %3, %y
%5 = add nsw i32 %4, %2
ret i32 %5
}
; Function Attrs: nounwind readnone
define i32 @bar(i32 %x, i32 %k) #0 {
%1 = mul nsw i32 %x, %x
%2 = mul nsw i32 %1, %k
ret i32 %2
}
It should be noted that GCC also has the ability to link and optimize intermediate code (LTO, link-time optimization) [6].
Of course, optimization in LLVM is not limited to optimization of IR code. Inside the backend, various optimizations also take place at different stages of converting the IR code into a machine representation. LLVM performs some of these optimizations on its own, but the backend developer can (and should) develop his own optimization algorithms that will make full use of the features of the processor architecture.
Target platform code generation
The development of the compiler for the original processor architecture, this is mainly the development of the backend. Intervention in front-end algorithms, as a rule, is not necessary, or, in any case, requires very good reason. If you analyze the source code of Clang, you can see that most of the "special" algorithms fall on the x86 and PowerPC processors with their non-standard formats of real numbers. For most other processors, you need to specify only the sizes of the base types and endianness (big-endian or little-endian). Most often, you can simply find a similar (in terms of bit depth) processor among the many supported.
Code generation for the target platform takes place in the LLVM, LLC backend. LLC supports many different processors, and you can make a code generator for your own original processor based on it. This task is also simplified due to the fact that all source code, including modules for each supported architecture, is completely open and available for study.
The code generator for the target platform (target) is the most time-consuming task when developing a compiler based on LLVM infrastructure. I decided not to dwell on the features of the backend implementation here, since they significantly depend on the architecture of the target processor. However, if a respected Habr audience has an interest in this topic, I am ready to describe the key points in developing the backend in the next article.
Conclusion
In a short article, you can not consider in detail neither the LLVM architecture, nor the LLVM IR syntax, nor the backend development process. However, these issues are covered in detail in the documentation. The author rather tried to give a general idea about the infrastructure of LLVM compilers, emphasizing that this platform is modern, powerful, universal, and independent of either the input language or the target processor architecture, allowing you to implement both of them at the request of the developer.
In addition to the reviewed ones, LLVM also contains other utilities, however, their consideration is beyond the scope of the article.
LLVM allows you to implement a backend for any architecture (see note), including pipelined architectures, with extraordinary execution of commands, with various parallelization options, VLIW, for classic and stack architectures, in general, for any options.
Regardless of how non-standard solutions underlie the processor architecture, it is just a matter of writing more or less code.
note
for anyone within reason. It is hardly possible to implement the C language compiler for a 4-bit architecture, as the language standard explicitly requires a bit depth of at least 8.
Literature
Compilers
[1] Dragon Book
[2] Wirth N. Building
GCC Compilers
[3] gcc.gnu.org - GCC Project Site
[4] Richard M. Stallman and the GCC Developer Community. GNU Compiler Collection Internals
LLVM
[5] http://llvm.org/ - LLVM project site
[6] http://llvm.org/docs/GettingStarted.html Getting Started with the LLVM System
[7] http: // llvm .org / docs / LangRef.html LLVM Language Reference Manual
[8] http://llvm.org/docs/WritingAnLLVMBackend.html Writing An LLVM Backend
[9] http://llvm.org/docs/WritingAnLLVMPass.html Writing An LLVM Pass
[10] Chen Chung-Shu. Creating an LLVM Backend for the Cpu0 Architecture
[11] Mayur Pandey, Suyog Sarda. LLVM Cookbook
[12] Bruno Cardoso Lopes. Getting Started with LLVM Core Libraries
[13] Suyog Sarda, Mayur Pandey. LLVM Essentials
The author will be happy to answer your questions in the comments and in PM.
The request to report all typos noticed in PM. Thanks in advance.