Much detail about counting single bits
- Tutorial
I would like to give the Habr community an article in which I try to give a fairly complete description of approaches to the algorithms for counting single bits in variables ranging in size from 8 to 64 bits. These algorithms belong to the section of so-called “bit magic” or “bit alchemy”, which fascinates many programmers with its beauty and non-obviousness. I want to show that there is nothing complicated in the basics of this alchemy, and you can even develop your own methods for counting single bits by familiarizing yourself with the fundamental techniques that make up such algorithms.
Before we begin, I want to warn you right away that this article is not for beginners in programming. I need the reader to imagine the simplest bit operations in general terms (bitwise “and”, “or”, shift), have a good knowledge of the hexadecimal number system and use the imagination quite confidently, presenting in it not always short bit sequences. If possible, everything will be accompanied by pictures, but you understand, they only simplify, but do not replace, the complete presentation.
All the described techniques were implemented in C language and tested in two modes: 32 and 64 bits. Thus, for a better understanding of the article, it would be better for you to at least approximately understand the C language. Testing took place on the processor Core 2 Duo E8400 @ 3GHz on 64-bit Windows 7. Measurement of the net runtime of the programs was carried out using the utility runexe . All source codes of the described algorithms are available in the archive on the Yandex disk, their compilation is checked for the Visual C ++, Intel C ++, GCC and CLang compilers, so in principle, you should not have problems if someone wants to double-check the results at home. Linux users, I think, know better than me how to test the runtime of a program in their system, so I don’t give them any advice.
Among readers, there may be those who find it easier to watch the same thing on video. I recorded such a video (58 minutes), which in the presentation format sets out exactly the same thing that will be lower in the text, but it can be in a slightly different style, more dry and strict, while I tried to revive the text a little. Therefore, study the material in a way that is more convenient for anyone.
Algorithms generated by one or another set of alchemical methods will be described sequentially, each section will have a table comparing the operating time for variables of different sizes, and at the end there will be a summary table for all algorithms. All algorithms use aliases for unsigned numbers from 8 to 64 bits.
Obviously, bit alchemy is not used to shine at an interview, but to significantly speed up programs. Acceleration in relation to what? In relation to trivial tricks that may come to mind when there is no time to delve into the task in more detail. Such a technique is a naive approach to counting bits: we simply “bite off” one bit after another from the number and summarize them, repeating the procedure until the number becomes zero.
I see no reason to comment on anything in this trivial cycle. It is clear to the naked eye that if the most significant bit of the number n is 1, then the cycle will be forced to go through all the bits of the number before it reaches the most significant one.
Changing the type of the input parameter u8 to u16, u32 and u64 we get 4 different functions. Let's test each of them on a stream of 2 32 numbers submitted in a chaotic manner. It is clear that for u8 we have 256 different input data, but for consistency we still run 2 32 random numbers for all these and all subsequent functions, and always in the same order (for details, refer to the curriculum code from the archive )
The time in the table below is indicated in seconds. For testing, the program was run three times and the average time was selected. The error hardly exceeds 0.1 seconds. The first column reflects the compiler mode (32-bit source code or 64-bit), then 4 columns are responsible for 4 variants of input data.
As we can see, the speed of work quite naturally increases with the size of the input parameter. A little bit out of the general regularity is the option when the numbers are 64 bits in size, and the calculation is in x86 mode. It’s clear that the processor is forced to do four times the work when doubling the input parameter, and it’s even good that it can handle only three times slower.
The first benefit of this approach is that it is hard to make mistakes when implementing it, so a program written in this way can become a reference for testing more complex algorithms (this was exactly what was done in my case). The second benefit is versatility and relatively simple portability to numbers of any size.
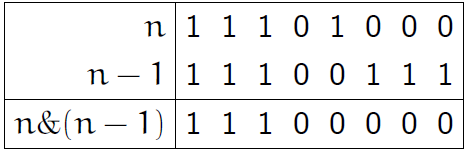
This alchemical technique is based on the idea of resetting the least significant bit. Having the number n, we can cast the spell n = n & (n-1), taking the least one from the number n. The picture below for n = 232 will clarify the situation for people who first learned about this trick.
The program code has not changed much.
Now the cycle will be executed exactly as many times as there are units in the number n. This does not eliminate the worst case when all bits in the number are single, but significantly reduces the average number of iterations. Will this approach greatly alleviate the suffering of the processor? Actually not very, but for 8 bits it will be even worse. Let me remind you that the summary table of results will be at the end, but here each section will have its own table.
Let's not rush to switch to “hard” spells, consider the last simple trick that can save even the most inexperienced magician. This solution to the problem does not apply directly to bit alchemy, however, for completeness, the picture should be considered without fail. We will create two tables with 256 and 65536 values, in which the answers for all possible 1-byte and 2-byte values are calculated in advance, respectively.
Now the program for 1 byte will look like this
To calculate the number of bits in larger numbers, they need to be divided into bytes. For example, for u32 there could be such a code:
Or such, if we use the pre-calculation table for 2 bytes:
Well, then you guessed it, for each option of the size of the input parameter n (except for 8 bits) there can be two options for pre-calculation, depending on which of the two tables we use. I think the reader understands why we can’t just get and get the BitsSetTableFFFFFFFF table, but there may well be problems where this will be justified.
Does pre-calculation work fast? It all depends on the size, see the tables below. The first for a single-byte pre-calculation, and the second for a double-byte.
An interesting point: for x64 mode, the pre-calculation for u64 is much faster, perhaps these are optimization features, although this does not appear in the second case.
Important note: this algorithm using pre-calculation is only beneficial if the following two conditions are met: (1) you have extra memory, (2)you need to calculate the number of single bits much more times than the size of the table itself, that is, you can “win back” the time spent pre-populating the table with some of the simple algorithms. Perhaps you can also keep in mind the exotic condition, which in practice is always fulfilled. You must ensure that accessing the memory itself is quick and does not slow down the operation of other system functions. The fact is that accessing the table may throw from the cache what was originally there and thus slow down some other piece of code. You are unlikely to find a jamb quickly, but hardly anyone will need such monstrous optimizations in practice when implementing ordinary programs.
Finally, let’s take more powerful potions from our alchemical regiment. With the help of multiplication and the remainder of dividing by a power of two without a unit, quite interesting things can be done. Let's start casting a spell with one byte. For convenience, we denote all bits of one byte in Latin letters from "a" to "h". Our number n will take the form:

Multiplication n '= n⋅0x010101 (so, through the prefix “0x”, I mean hexadecimal numbers) does nothing more than “replicate” one byte in triplicate:
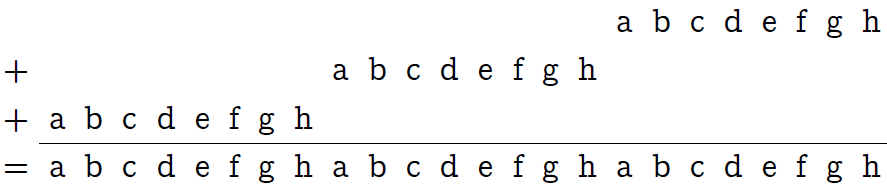
Now we will mentally divide our 24 bits into 8 blocks of 3 bits each (see the following picture, the first line of the plate). Then, using the bitwise “and” with the mask 0x249249 (the second line of the plate), zero the two high-order bits in each block.

The third row of the table explains the hexadecimal notation for the mask. The last line shows the result that we achieved: all bits of the original byte are contained each in its own three-bit block, but in a different order (the order is not important to us).
Now attention: we must add these 8 blocks - and get the sum of our bits!
It turns out that the remainder of dividing a certain number A by 2 k -1 just gives the sum of k-bit blocks of the number A, also taken modulo 2 k -1.
That is, from the number we received, we need to take the remainder of dividing by 2 3 -1 (seven) - and we get the sum of our 8 blocks modulo 7. The trouble is that the sum of bits can be 7 or 8, in this case the algorithm will return 0 and 1, respectively. But let's see: in what case can we get the answer 8? Only when n = 255. And in which case can we get 0? Only when n = 0. Therefore, if the algorithm after taking the remainder of 7 gives 0, then either we received n = 0 at the input, or among exactly 7 unit bits. Summing up this reasoning, we obtain the following code:
In the case where n has a size of 16 bits, you can split it into two parts of 8 bits. For example, like this:
For the case of 32-bit and 64-bit, such a partition does not even make sense even in theory, multiplication and the remainder of division with three branches will be too expensive if they are performed 4 or 8 times in a row. But I left for you empty spaces in the table below, so if you do not believe me, please fill them out yourself. There will most likely be results comparable to the CountBits1 procedure, if you have a similar processor (I'm not talking about the possibility of optimizations using SSE here, this will be a different matter).
This trick, of course, can be done without branching, but then we need to, when dividing the number into blocks, all numbers from 0 to 8 fit in a block, and this can be achieved only in the case of 4-bit blocks (and more). To perform the summation of 4-bit blocks, you need to select a factor that allows you to correctly "replicate" the number and take the remainder of the division by 2 4 -1 = 15 to add the resulting blocks. An experienced alchemist (who knows mathematics) can easily pick up such a factor: 0x08040201. Why is he chosen like this?

The fact is that we need all the bits of the original number to occupy the correct positions in their 4-bit blocks (picture above), and since 8 and 4 are not relatively prime numbers, the usual copying of 8 bits 4 times will not give the correct location bits. We will have to add one zero to our byte, that is, to replicate 9 bits, since 9 is mutually simple with 4. So we get a number that is 36 bits in size, but in which all the bits of the original byte are at the lower positions of 4-bit blocks. It remains only to take the bitwise “and” with the number 0x111111111 (the second line in the picture above) to reset the three most significant bits in each block. Then the blocks need to be folded.
With this approach, the program for calculating single bits in a byte will be extremely simple:
The disadvantage of the program is obvious: you need to go into 64-bit arithmetic with all the ensuing consequences. You can notice that in reality this program uses only 33 bits out of 64 (the upper 3 bits are reset), and in principle you can figure out how to transfer these calculations to 32-bit arithmetic, but stories about such optimizations are not included in the topic of this guides. Let's just study the techniques for now, and you have to optimize them yourself already for a specific task.
We will answer the question of what size the variable n can be, so that this trick works correctly for it. Since we take the remainder of dividing by 15, such a variable cannot have a size greater than 14 bits, otherwise we will have to apply branching, as we did before. But for 14 bits, reception works if you add one zero to 14 bits so that all the bits fall into position. Now I will assume that you, on the whole, have learned the essence of the reception and you can easily pick up a multiplier for replication and a mask for resetting unnecessary bits yourself. I will show you the finished result right away.
This program above shows what the code might look like if you had a variable of 14 bits unsigned. The same code will work with a variable of 15 bits, but under the condition that only 14 of them are at most equal to one, or if the case where n = 0x7FFF is examined separately. All this needs to be understood in order to write the correct code for a variable of type u16. The idea is to first “bite off” the least significant bit, count the bits in the remaining 15 bit number, and then add the “bitten” bit back.
For n 32 bits, you have to conjure already with a more serious face ... First, the answer fits in only 6 bits, but you can consider a separate case when n = 2 32 -1 and calmly do calculations in fields of 5 bits. This saves space and allows us to split the 32-bit field of n into 3 parts of 12 bits each (yes, the last field will not be complete). Since 12⋅5 = 60, we can duplicate one 12-bit field 5 times, choosing a factor, and then add 5-bit blocks, taking the remainder of dividing by 31. You need to do this 3 times for each field. Summing up the result, we get the following code:
Here, just as well, instead of three branches, it was possible to take 3 residues from division, but I chose the branch option, it will work better on my processor.
For n, the size of 64 bits, I was not able to come up with a suitable spell in which there would not be many multiplications and additions. It turned out either 6 or 7, and this is too much for such a task. Another option is to go into 128-bit arithmetic, and you don’t understand what kind of “rollback” it will turn out for us, an unprepared mage can be thrown to the wall :)
Let's take a better look at the time of work.
The obvious conclusion from this table is that 64-bit arithmetic is poorly perceived in 32-bit execution mode, although in general the algorithm is not bad. If we recall the speed of the pre-calculation algorithm in x64 mode for a single-byte table for the case u32 (24.79 s), we get that this algorithm is only 25% behind, and this is a reason for the competition embodied in the next section.
The disadvantage of the operation of taking the remainder is obvious to everyone. This is division, and division is a long time. Of course, modern compilers know alchemy and know how to replace division by multiplication with a shift, and to get the remainder, you need to subtract the quotient multiplied by the divisor from the dividend. However, it's still a long time! It turns out that in the ancient scrolls of code spellcasters one interesting way to optimize the previous algorithm has been preserved. We can summarize k-bit blocks not by taking the remainder of the division, but by another multiplication by the mask, with which we reset the extra bits in the blocks. Here's what it looks like for n 1 byte in size.
First, we duplicate the byte three times again and delete the two most significant bits of each 3-bit block using the formula 0x010101⋅n & 0x249249 already passed above.

For convenience, I designated each three-bit block with a capital Latin letter. Now we multiply the result by the same mask 0x249249. The mask contains a single bit in each 3rd position, so this multiplication is equivalent to adding the number of itself to itself 8 times, each time with a shift of 3 bits:
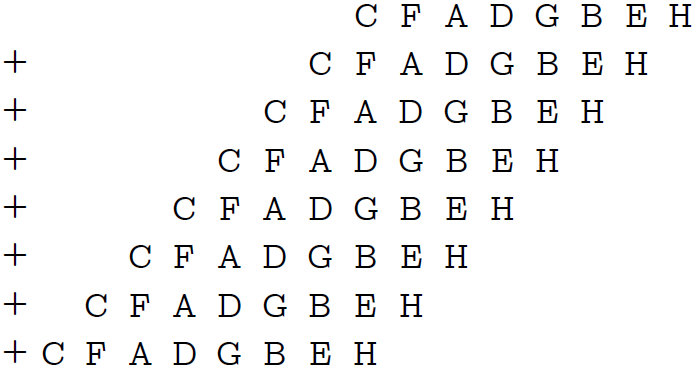
What do we see? Bits 21 to 23 give us the right amount! Moreover, overflow in any of the blocks on the right is impossible, since there will not be a number greater than 7 in any block. The only problem is that if our sum is 8, we will get 0, but this is not scary, because this is the only case can be considered separately.
In fact, we took the code from the previous section and replaced it by taking the remainder of dividing by 7 by multiplication, shift, and bitwise “And” at the end. However, instead of 3 branches, only one remains.
To compile a similar program for 16 bits, we need to take the code from the previous section, which shows how to do this by taking the remainder of the division by 15 and replace this procedure with multiplication. At the same time, it is easy to notice which conditions can be removed from the code.
For 32 bits, we do the same: we take the code from the previous section and, having drawn a little on paper, we understand what the shift will be if we replace the remainder with multiplication.
For 64-bit, I also could not come up with something that would not force my processor to act as a stove.
Pleasantly surprised by the results for x64 mode. As expected, we overtook the pre-calculation with a single-byte table for the u32 case. Is it even possible to overtake the pre-calculation? Good question :)
Perhaps this is the most common trick, which is very often repeated one after another by not quite experienced spellcasters, not understanding how it works exactly.
Let's start with 1 byte. A byte consists of 4 fields of 2 bits each, first add up the bits in these fields by saying something like:
Here is an explanatory picture for this operation (as before, we denote the bits of one byte with the first Latin letters):
One of the bitwise “And” leaves only the low-order bits of each two-bit block, the second leaves the high-order bits, but shifts them to positions corresponding to the low-order bits. As a result of the summation, we obtain the sum of adjacent bits in each two-bit block (the last line in the picture above).
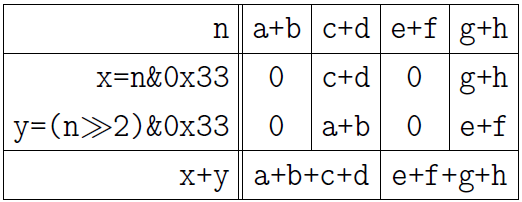
Now let's pair the numbers in two-bit fields, putting the result in 2 four-bit fields:
The following picture explains the result. I bring it now without further ado:
Finally, add two numbers in four-bit fields:
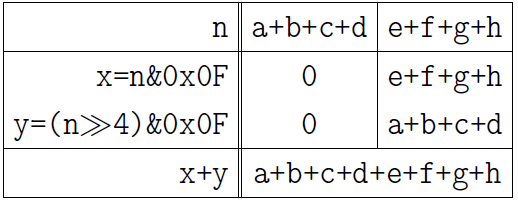
By analogy, you can extend the reception to any number of bits equal to the power of two. The number of spell lines is the binary logarithm of the number of bits. Having caught the idea, take a quick look at the 4 functions written below to make sure your understanding is correct.
This does not end parallel summation. The idea can be developed by observing that the same bitmask is used twice in each line, which seems to suggest “is it possible to somehow perform the bitwise“ And ”only once?”. It is possible, but not immediately. Here's what you can do if you take the code for u32 as an example (see comments).
As an exercise, I would like to offer to prove on my own why the following code will be an exact reflection of the previous one. For the first line, I give a hint, but do not look into it right away:
Similar optimization options are possible for other data types.
Two tables are listed below: one for normal parallel summation, and one for optimized.
In general, we see that the optimized algorithm works well, but loses to the usual one in x86 mode for u64.
We see that the best options for counting single bits are the parallel method (with optimization) and the replication method with multiplication to calculate the sum of blocks. We can combine both methods to get a combined algorithm.
The first thing to do is execute the first three lines of the parallel algorithm. This will give us the exact amount of bits in each byte of the number. For example, for u32, do the following:
Now our number n consists of 4 bytes, which should be considered as 4 numbers, the sum of which we are looking for:

We can find the sum of these 4 bytes if we multiply the number n by 0x01010101. You now well understand what such multiplication means, for the convenience of determining the position in which the answer will be, I quote the picture:

The answer is in 3-byte (if you count them from 0). Thus, the combined trick for u32 will look like this:
He is for u16:
He is for u64:
You can see the speed of this method immediately in the final table.
I suggest the reader to draw his own conclusions of interest by examining the two following tables. In them, I designated the name of the methods for which we implemented programs, and also marked with a rectangular frame those approaches that I consider to be the best in each particular case. Those who thought that the pre-calculation always wins will get a little surprise for the x64 mode.
The final comparison for x86 compilation mode.
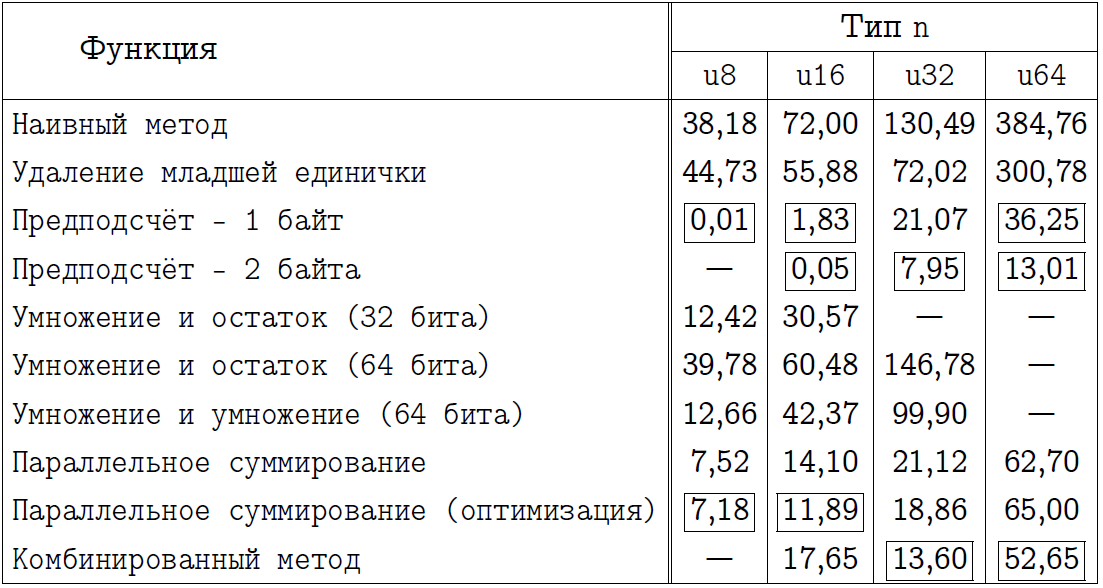
The final comparison for x64 compilation mode.
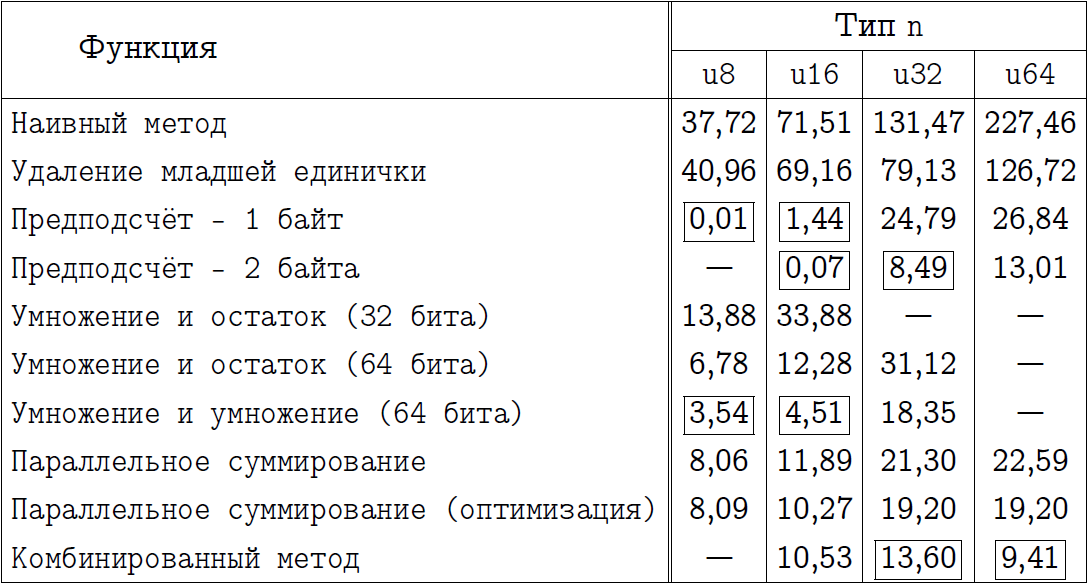
In no case do not consider the final table as evidence in favor of one or another approach. Believe that on your processor and with your compiler some numbers in such a table will be completely different. Unfortunately, we can never say for sure which of the algorithms will turn out to be better in any given case. A specific method needs to be sharpened for each task, and, unfortunately, a universal fast algorithm does not exist.
I have outlined the ideas that I know about myself, but these are just ideas whose specific implementations in different combinations can be very different. Combining these ideas in different ways, you can get a huge number of different algorithms for counting single bits, each of which may well turn out to be good in some case.
Thanks for attention. See you soon!
UPD : The POPCNT instruction from SSE4.2 is not included in the test list because I do not have a processor that supports SSE4.2.
Before we begin, I want to warn you right away that this article is not for beginners in programming. I need the reader to imagine the simplest bit operations in general terms (bitwise “and”, “or”, shift), have a good knowledge of the hexadecimal number system and use the imagination quite confidently, presenting in it not always short bit sequences. If possible, everything will be accompanied by pictures, but you understand, they only simplify, but do not replace, the complete presentation.
All the described techniques were implemented in C language and tested in two modes: 32 and 64 bits. Thus, for a better understanding of the article, it would be better for you to at least approximately understand the C language. Testing took place on the processor Core 2 Duo E8400 @ 3GHz on 64-bit Windows 7. Measurement of the net runtime of the programs was carried out using the utility runexe . All source codes of the described algorithms are available in the archive on the Yandex disk, their compilation is checked for the Visual C ++, Intel C ++, GCC and CLang compilers, so in principle, you should not have problems if someone wants to double-check the results at home. Linux users, I think, know better than me how to test the runtime of a program in their system, so I don’t give them any advice.
Among readers, there may be those who find it easier to watch the same thing on video. I recorded such a video (58 minutes), which in the presentation format sets out exactly the same thing that will be lower in the text, but it can be in a slightly different style, more dry and strict, while I tried to revive the text a little. Therefore, study the material in a way that is more convenient for anyone.
Watch the video
Algorithms generated by one or another set of alchemical methods will be described sequentially, each section will have a table comparing the operating time for variables of different sizes, and at the end there will be a summary table for all algorithms. All algorithms use aliases for unsigned numbers from 8 to 64 bits.
typedef unsigned char u8;
typedef unsigned short int u16;
typedef unsigned int u32;
typedef unsigned long long u64;
Naive approach
Obviously, bit alchemy is not used to shine at an interview, but to significantly speed up programs. Acceleration in relation to what? In relation to trivial tricks that may come to mind when there is no time to delve into the task in more detail. Such a technique is a naive approach to counting bits: we simply “bite off” one bit after another from the number and summarize them, repeating the procedure until the number becomes zero.
u8 CountOnes0 (u8 n) {
u8 res = 0;
while (n) {
res += n&1;
n >>= 1;
}
return res;
}
I see no reason to comment on anything in this trivial cycle. It is clear to the naked eye that if the most significant bit of the number n is 1, then the cycle will be forced to go through all the bits of the number before it reaches the most significant one.
Changing the type of the input parameter u8 to u16, u32 and u64 we get 4 different functions. Let's test each of them on a stream of 2 32 numbers submitted in a chaotic manner. It is clear that for u8 we have 256 different input data, but for consistency we still run 2 32 random numbers for all these and all subsequent functions, and always in the same order (for details, refer to the curriculum code from the archive )
The time in the table below is indicated in seconds. For testing, the program was run three times and the average time was selected. The error hardly exceeds 0.1 seconds. The first column reflects the compiler mode (32-bit source code or 64-bit), then 4 columns are responsible for 4 variants of input data.
| Mode | u8 | u16 | u32 | u64 |
|---|---|---|---|---|
| x86 | 38.18 | 72.00 | 130.49 | 384.76 |
| x64 | 37.72 | 71.51 | 131.47 | 227.46 |
As we can see, the speed of work quite naturally increases with the size of the input parameter. A little bit out of the general regularity is the option when the numbers are 64 bits in size, and the calculation is in x86 mode. It’s clear that the processor is forced to do four times the work when doubling the input parameter, and it’s even good that it can handle only three times slower.
The first benefit of this approach is that it is hard to make mistakes when implementing it, so a program written in this way can become a reference for testing more complex algorithms (this was exactly what was done in my case). The second benefit is versatility and relatively simple portability to numbers of any size.
The “bite” trick of the least significant bits
This alchemical technique is based on the idea of resetting the least significant bit. Having the number n, we can cast the spell n = n & (n-1), taking the least one from the number n. The picture below for n = 232 will clarify the situation for people who first learned about this trick.
The program code has not changed much.
u8 CountOnes1 (u8 n) {
u8 res = 0;
while (n) {
res ++;
n &= n-1; // Забираем младшую единичку.
}
return res;
}
Now the cycle will be executed exactly as many times as there are units in the number n. This does not eliminate the worst case when all bits in the number are single, but significantly reduces the average number of iterations. Will this approach greatly alleviate the suffering of the processor? Actually not very, but for 8 bits it will be even worse. Let me remind you that the summary table of results will be at the end, but here each section will have its own table.
| Mode | u8 | u16 | u32 | u64 |
|---|---|---|---|---|
| x86 | 44.73 | 55.88 | 72.02 | 300.78 |
| x64 | 40.96 | 69.16 | 79.13 | 126.72 |
Pre-calculation
Let's not rush to switch to “hard” spells, consider the last simple trick that can save even the most inexperienced magician. This solution to the problem does not apply directly to bit alchemy, however, for completeness, the picture should be considered without fail. We will create two tables with 256 and 65536 values, in which the answers for all possible 1-byte and 2-byte values are calculated in advance, respectively.
u8 BitsSetTableFF[256]; // Здесь все ответы для одного байта
u8 BitsSetTableFFFF[65536]; // Здесь все ответы для двух байт
Now the program for 1 byte will look like this
u8 CountOnes2_FF (u8 n) {
return BitsSetTableFF[n];
}
To calculate the number of bits in larger numbers, they need to be divided into bytes. For example, for u32 there could be such a code:
u8 CountOnes2_FF (u32 n) {
u8 *p = (u8*)&n;
n = BitsSetTableFF[p[0]]
+ BitsSetTableFF[p[1]]
+ BitsSetTableFF[p[2]]
+ BitsSetTableFF[p[3]];
return n;
}
Or such, if we use the pre-calculation table for 2 bytes:
u8 CountOnes2_FFFF (u32 n) {
u16 *p = (u16*)&n;
n = BitsSetTableFFFF[p[0]]
+ BitsSetTableFFFF[p[1]];
return n;
}
Well, then you guessed it, for each option of the size of the input parameter n (except for 8 bits) there can be two options for pre-calculation, depending on which of the two tables we use. I think the reader understands why we can’t just get and get the BitsSetTableFFFFFFFF table, but there may well be problems where this will be justified.
Does pre-calculation work fast? It all depends on the size, see the tables below. The first for a single-byte pre-calculation, and the second for a double-byte.
| Mode | u8 | u16 | u32 | u64 |
|---|---|---|---|---|
| x86 | 0.01 | 1.83 | 21.07 | 36.25 |
| x64 | 0.01 | 1.44 | 24.79 | 26.84 |
An interesting point: for x64 mode, the pre-calculation for u64 is much faster, perhaps these are optimization features, although this does not appear in the second case.
| Mode | u8 | u16 | u32 | u64 |
|---|---|---|---|---|
| x86 | --- | 0.05 | 7.95 | 13.01 |
| x64 | --- | 0,07 | 8.49 | 13.01 |
Important note: this algorithm using pre-calculation is only beneficial if the following two conditions are met: (1) you have extra memory, (2)you need to calculate the number of single bits much more times than the size of the table itself, that is, you can “win back” the time spent pre-populating the table with some of the simple algorithms. Perhaps you can also keep in mind the exotic condition, which in practice is always fulfilled. You must ensure that accessing the memory itself is quick and does not slow down the operation of other system functions. The fact is that accessing the table may throw from the cache what was originally there and thus slow down some other piece of code. You are unlikely to find a jamb quickly, but hardly anyone will need such monstrous optimizations in practice when implementing ordinary programs.
Multiplication and remainder of division
Finally, let’s take more powerful potions from our alchemical regiment. With the help of multiplication and the remainder of dividing by a power of two without a unit, quite interesting things can be done. Let's start casting a spell with one byte. For convenience, we denote all bits of one byte in Latin letters from "a" to "h". Our number n will take the form:
Multiplication n '= n⋅0x010101 (so, through the prefix “0x”, I mean hexadecimal numbers) does nothing more than “replicate” one byte in triplicate:
Now we will mentally divide our 24 bits into 8 blocks of 3 bits each (see the following picture, the first line of the plate). Then, using the bitwise “and” with the mask 0x249249 (the second line of the plate), zero the two high-order bits in each block.
The third row of the table explains the hexadecimal notation for the mask. The last line shows the result that we achieved: all bits of the original byte are contained each in its own three-bit block, but in a different order (the order is not important to us).
Now attention: we must add these 8 blocks - and get the sum of our bits!
It turns out that the remainder of dividing a certain number A by 2 k -1 just gives the sum of k-bit blocks of the number A, also taken modulo 2 k -1.
Proof
We divide the number A (in binary notation) into blocks of k bits each (if necessary, you can add the very last, oldest, block with zeros). Denote by A i the ith block. Now we write the value of the number A through the sum of these blocks multiplied by the corresponding power of two:
A = A 0 ⋅2 0⋅k + A 1 ⋅2 1⋅k + ... + A N-1 ⋅2 (N-1) ⋅k ,
where N is the number of blocks.
Now we calculate A mod (2 k -1).
A mod (2 k -1) = (A 0 ⋅2 0⋅k + A 1 ⋅2 1⋅k + ... + A N-1 ⋅2 (N-1) ⋅k) mod (2 k -1) = (A 0 + A 1 + ... + A N-1 ) mod (2 k -1).
This is due to the fact that 2 i⋅k = 1 (mod (2 k -1)) for any non-negative integer i. (Here, however, it is important that the trick makes sense when k> 1, otherwise it is not entirely clear how we interpret module 1). So we got the sum of blocks modulo 2 k -1.
A = A 0 ⋅2 0⋅k + A 1 ⋅2 1⋅k + ... + A N-1 ⋅2 (N-1) ⋅k ,
where N is the number of blocks.
Now we calculate A mod (2 k -1).
A mod (2 k -1) = (A 0 ⋅2 0⋅k + A 1 ⋅2 1⋅k + ... + A N-1 ⋅2 (N-1) ⋅k) mod (2 k -1) = (A 0 + A 1 + ... + A N-1 ) mod (2 k -1).
This is due to the fact that 2 i⋅k = 1 (mod (2 k -1)) for any non-negative integer i. (Here, however, it is important that the trick makes sense when k> 1, otherwise it is not entirely clear how we interpret module 1). So we got the sum of blocks modulo 2 k -1.
That is, from the number we received, we need to take the remainder of dividing by 2 3 -1 (seven) - and we get the sum of our 8 blocks modulo 7. The trouble is that the sum of bits can be 7 or 8, in this case the algorithm will return 0 and 1, respectively. But let's see: in what case can we get the answer 8? Only when n = 255. And in which case can we get 0? Only when n = 0. Therefore, if the algorithm after taking the remainder of 7 gives 0, then either we received n = 0 at the input, or among exactly 7 unit bits. Summing up this reasoning, we obtain the following code:
u8 CountOnes3 (u8 n) {
if (n == 0) return 0; // Единственный случай, когда ответ 0.
if (n == 0xFF) return 8; // Единственный случай, когда ответ 8.
n = (0x010101*n & 0x249249) % 7; // Считаем число бит по модулю 7.
if (n == 0) return 7; // Гарантированно имеем 7 единичных битов.
return n; // Случай, когда в числе от 1 до 6 единичных битов.
}
In the case where n has a size of 16 bits, you can split it into two parts of 8 bits. For example, like this:
u8 CountOnes3 (u16 n) {
return CountOnes3 (u8(n&0xFF)) + CountOnes3 (u8(n>>8));
For the case of 32-bit and 64-bit, such a partition does not even make sense even in theory, multiplication and the remainder of division with three branches will be too expensive if they are performed 4 or 8 times in a row. But I left for you empty spaces in the table below, so if you do not believe me, please fill them out yourself. There will most likely be results comparable to the CountBits1 procedure, if you have a similar processor (I'm not talking about the possibility of optimizations using SSE here, this will be a different matter).
| Mode | u8 | u16 | u32 | u64 |
|---|---|---|---|---|
| x86 | 12,42 | 30.57 | --- | --- |
| x64 | 13.88 | 33.88 | --- | --- |
This trick, of course, can be done without branching, but then we need to, when dividing the number into blocks, all numbers from 0 to 8 fit in a block, and this can be achieved only in the case of 4-bit blocks (and more). To perform the summation of 4-bit blocks, you need to select a factor that allows you to correctly "replicate" the number and take the remainder of the division by 2 4 -1 = 15 to add the resulting blocks. An experienced alchemist (who knows mathematics) can easily pick up such a factor: 0x08040201. Why is he chosen like this?
The fact is that we need all the bits of the original number to occupy the correct positions in their 4-bit blocks (picture above), and since 8 and 4 are not relatively prime numbers, the usual copying of 8 bits 4 times will not give the correct location bits. We will have to add one zero to our byte, that is, to replicate 9 bits, since 9 is mutually simple with 4. So we get a number that is 36 bits in size, but in which all the bits of the original byte are at the lower positions of 4-bit blocks. It remains only to take the bitwise “and” with the number 0x111111111 (the second line in the picture above) to reset the three most significant bits in each block. Then the blocks need to be folded.
With this approach, the program for calculating single bits in a byte will be extremely simple:
u8 CountOnes3_x64 (u8 n) {
return ((u64)0x08040201*n & 0x111111111) % 15;
}
The disadvantage of the program is obvious: you need to go into 64-bit arithmetic with all the ensuing consequences. You can notice that in reality this program uses only 33 bits out of 64 (the upper 3 bits are reset), and in principle you can figure out how to transfer these calculations to 32-bit arithmetic, but stories about such optimizations are not included in the topic of this guides. Let's just study the techniques for now, and you have to optimize them yourself already for a specific task.
We will answer the question of what size the variable n can be, so that this trick works correctly for it. Since we take the remainder of dividing by 15, such a variable cannot have a size greater than 14 bits, otherwise we will have to apply branching, as we did before. But for 14 bits, reception works if you add one zero to 14 bits so that all the bits fall into position. Now I will assume that you, on the whole, have learned the essence of the reception and you can easily pick up a multiplier for replication and a mask for resetting unnecessary bits yourself. I will show you the finished result right away.
u8 CountOnes3_x64 (u14 n) { // Это не опечатка (и не должно работать)!
return (n*0x200040008001llu & 0x111111111111111llu) % 15;
}
This program above shows what the code might look like if you had a variable of 14 bits unsigned. The same code will work with a variable of 15 bits, but under the condition that only 14 of them are at most equal to one, or if the case where n = 0x7FFF is examined separately. All this needs to be understood in order to write the correct code for a variable of type u16. The idea is to first “bite off” the least significant bit, count the bits in the remaining 15 bit number, and then add the “bitten” bit back.
u8 CountOnes3_x64 (u16 n) {
u8 leastBit = n&1; // Берём младший бит.
n >>= 1; // Оставляем только 15 бит исходного числа.
if (n == 0) return leastBit; // Если получился 0, значит ответом будет младший бит.
if (n == 0x7FFF) return leastBit + 15; // Единственный случай, когда ответ 15+младший бит.
return leastBit + (n*0x200040008001llu & 0x111111111111111llu) % 15; // Ответ (максимум 14+младший бит).
}
For n 32 bits, you have to conjure already with a more serious face ... First, the answer fits in only 6 bits, but you can consider a separate case when n = 2 32 -1 and calmly do calculations in fields of 5 bits. This saves space and allows us to split the 32-bit field of n into 3 parts of 12 bits each (yes, the last field will not be complete). Since 12⋅5 = 60, we can duplicate one 12-bit field 5 times, choosing a factor, and then add 5-bit blocks, taking the remainder of dividing by 31. You need to do this 3 times for each field. Summing up the result, we get the following code:
u8 CountOnes3_x64 ( u32 n ) {
if (n == 0) return 0;
if (n + 1 == 0) return 32;
u64 res = (n&0xFFF)*0x1001001001001llu & 0x84210842108421llu;
res += ((n&0xFFF000)>>12)*0x1001001001001llu & 0x84210842108421llu;
res += (n>>24)*0x1001001001001llu & 0x84210842108421llu;
res %= 0x1F;
if (res == 0) return 31;
return res;
}
Here, just as well, instead of three branches, it was possible to take 3 residues from division, but I chose the branch option, it will work better on my processor.
For n, the size of 64 bits, I was not able to come up with a suitable spell in which there would not be many multiplications and additions. It turned out either 6 or 7, and this is too much for such a task. Another option is to go into 128-bit arithmetic, and you don’t understand what kind of “rollback” it will turn out for us, an unprepared mage can be thrown to the wall :)
Let's take a better look at the time of work.
| Mode | u8 | u16 | u32 | u64 |
|---|---|---|---|---|
| x86 | 39.78 | 60.48 | 146.78 | --- |
| x64 | 6.78 | 12.28 | 31.12 | --- |
The obvious conclusion from this table is that 64-bit arithmetic is poorly perceived in 32-bit execution mode, although in general the algorithm is not bad. If we recall the speed of the pre-calculation algorithm in x64 mode for a single-byte table for the case u32 (24.79 s), we get that this algorithm is only 25% behind, and this is a reason for the competition embodied in the next section.
Replacing the remainder with multiplication and shift
The disadvantage of the operation of taking the remainder is obvious to everyone. This is division, and division is a long time. Of course, modern compilers know alchemy and know how to replace division by multiplication with a shift, and to get the remainder, you need to subtract the quotient multiplied by the divisor from the dividend. However, it's still a long time! It turns out that in the ancient scrolls of code spellcasters one interesting way to optimize the previous algorithm has been preserved. We can summarize k-bit blocks not by taking the remainder of the division, but by another multiplication by the mask, with which we reset the extra bits in the blocks. Here's what it looks like for n 1 byte in size.
First, we duplicate the byte three times again and delete the two most significant bits of each 3-bit block using the formula 0x010101⋅n & 0x249249 already passed above.
For convenience, I designated each three-bit block with a capital Latin letter. Now we multiply the result by the same mask 0x249249. The mask contains a single bit in each 3rd position, so this multiplication is equivalent to adding the number of itself to itself 8 times, each time with a shift of 3 bits:
What do we see? Bits 21 to 23 give us the right amount! Moreover, overflow in any of the blocks on the right is impossible, since there will not be a number greater than 7 in any block. The only problem is that if our sum is 8, we will get 0, but this is not scary, because this is the only case can be considered separately.
u8 CountOnes3_x64_m (u8 n) {
if (n == 0xFF) return 8;
return ((u64(0x010101*n & 0x249249) * 0x249249) >> 21) & 0x7;
}
In fact, we took the code from the previous section and replaced it by taking the remainder of dividing by 7 by multiplication, shift, and bitwise “And” at the end. However, instead of 3 branches, only one remains.
To compile a similar program for 16 bits, we need to take the code from the previous section, which shows how to do this by taking the remainder of the division by 15 and replace this procedure with multiplication. At the same time, it is easy to notice which conditions can be removed from the code.
u8 CountOnes3_x64_m (u16 n) {
u8 leastBit = n&1; // Берём младший бит
n >>= 1; // Оставляем только 15 бит.
return leastBit
+ (( (n*0x200040008001llu & 0x111111111111111llu)*0x111111111111111llu
>> 56) & 0xF); // Ответ (максимум 15 + младший бит).
}
For 32 bits, we do the same: we take the code from the previous section and, having drawn a little on paper, we understand what the shift will be if we replace the remainder with multiplication.
u8 CountOnes3_x64_m ( u32 n ) {
if (n+1 == 0) return 32;
u64 res = (n&0xFFF)*0x1001001001001llu & 0x84210842108421llu;
res += ((n&0xFFF000)>>12)*0x1001001001001llu & 0x84210842108421llu;
res += (n>>24)*0x1001001001001llu & 0x84210842108421llu;
return (res*0x84210842108421llu >> 55) & 0x1F;
}
For 64-bit, I also could not come up with something that would not force my processor to act as a stove.
| Mode | u8 | u16 | u32 | u64 |
|---|---|---|---|---|
| x86 | 12.66 | 42.37 | 99.90 | --- |
| x64 | 3.54 | 4,51 | 18.35 | --- |
Pleasantly surprised by the results for x64 mode. As expected, we overtook the pre-calculation with a single-byte table for the u32 case. Is it even possible to overtake the pre-calculation? Good question :)
Parallel summation
Perhaps this is the most common trick, which is very often repeated one after another by not quite experienced spellcasters, not understanding how it works exactly.
Let's start with 1 byte. A byte consists of 4 fields of 2 bits each, first add up the bits in these fields by saying something like:
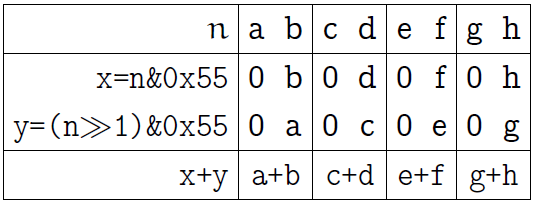
n = (n>>1)&0x55 + (n&0x55);
Here is an explanatory picture for this operation (as before, we denote the bits of one byte with the first Latin letters):
One of the bitwise “And” leaves only the low-order bits of each two-bit block, the second leaves the high-order bits, but shifts them to positions corresponding to the low-order bits. As a result of the summation, we obtain the sum of adjacent bits in each two-bit block (the last line in the picture above).
Now let's pair the numbers in two-bit fields, putting the result in 2 four-bit fields:
n = (n>>2)&0x33 + (n&0x33);
The following picture explains the result. I bring it now without further ado:
Finally, add two numbers in four-bit fields:
n = (n>>4)&0x0F + (n&0x0F);
By analogy, you can extend the reception to any number of bits equal to the power of two. The number of spell lines is the binary logarithm of the number of bits. Having caught the idea, take a quick look at the 4 functions written below to make sure your understanding is correct.
u8 CountOnes4 (u8 n) {
n = ((n>>1) & 0x55) + (n & 0x55);
n = ((n>>2) & 0x33) + (n & 0x33);
n = ((n>>4) & 0x0F) + (n & 0x0F);
return n;
}
u8 CountOnes4 (u16 n) {
n = ((n>>1) & 0x5555) + (n & 0x5555);
n = ((n>>2) & 0x3333) + (n & 0x3333);
n = ((n>>4) & 0x0F0F) + (n & 0x0F0F);
n = ((n>>8) & 0x00FF) + (n & 0x00FF);
return n;
}
u8 CountOnes4 (u32 n) {
n = ((n>>1) & 0x55555555) + (n & 0x55555555);
n = ((n>>2) & 0x33333333) + (n & 0x33333333);
n = ((n>>4) & 0x0F0F0F0F) + (n & 0x0F0F0F0F);
n = ((n>>8) & 0x00FF00FF) + (n & 0x00FF00FF);
n = ((n>>16) & 0x0000FFFF) + (n & 0x0000FFFF);
return n;
}
u8 CountOnes4 (u64 n) {
n = ((n>>1) & 0x5555555555555555llu) + (n & 0x5555555555555555llu);
n = ((n>>2) & 0x3333333333333333llu) + (n & 0x3333333333333333llu);
n = ((n>>4) & 0x0F0F0F0F0F0F0F0Fllu) + (n & 0x0F0F0F0F0F0F0F0Fllu);
n = ((n>>8) & 0x00FF00FF00FF00FFllu) + (n & 0x00FF00FF00FF00FFllu);
n = ((n>>16) & 0x0000FFFF0000FFFFllu) + (n & 0x0000FFFF0000FFFFllu);
n = ((n>>32) & 0x00000000FFFFFFFFllu) + (n & 0x00000000FFFFFFFFllu);
return n;
}
This does not end parallel summation. The idea can be developed by observing that the same bitmask is used twice in each line, which seems to suggest “is it possible to somehow perform the bitwise“ And ”only once?”. It is possible, but not immediately. Here's what you can do if you take the code for u32 as an example (see comments).
u8 CountOnes4 (u32 n) {
n = ((n>>1) & 0x55555555) + (n & 0x55555555); // Можно заменить на разность
n = ((n>>2) & 0x33333333) + (n & 0x33333333); // Нельзя исправить
n = ((n>>4) & 0x0F0F0F0F) + (n & 0x0F0F0F0F); // Можно вынести & за скобку
n = ((n>>8) & 0x00FF00FF) + (n & 0x00FF00FF); // Можно вынести & за скобку
n = ((n>>16) & 0x0000FFFF) + (n & 0x0000FFFF); // Можно вообще убрать &
return n; // Неявное обрезание по 8-и младшим битам.
}
As an exercise, I would like to offer to prove on my own why the following code will be an exact reflection of the previous one. For the first line, I give a hint, but do not look into it right away:
hint
The two-bit block ab has the exact value 2a + b, so subtraction will make it equal to ...?
u8 CountOnes4_opt (u32 n) {
n -= (n>>1) & 0x55555555;
n = ((n>>2) & 0x33333333 ) + (n & 0x33333333);
n = ((n>>4) + n) & 0x0F0F0F0F;
n = ((n>>8) + n) & 0x00FF00FF;
n = ((n>>16) + n);
return n;
}
Similar optimization options are possible for other data types.
Two tables are listed below: one for normal parallel summation, and one for optimized.
| Mode | u8 | u16 | u32 | u64 |
|---|---|---|---|---|
| x86 | 7.52 | 14.10 | 21.12 | 62.70 |
| x64 | 8.06 | 11.89 | 21.30 | 22.59 |
| Mode | u8 | u16 | u32 | u64 |
|---|---|---|---|---|
| x86 | 7.18 | 11.89 | 18.86 | 65.00 |
| x64 | 8.09 | 10.27 | 19,20 | 19,20 |
In general, we see that the optimized algorithm works well, but loses to the usual one in x86 mode for u64.
Combined method
We see that the best options for counting single bits are the parallel method (with optimization) and the replication method with multiplication to calculate the sum of blocks. We can combine both methods to get a combined algorithm.
The first thing to do is execute the first three lines of the parallel algorithm. This will give us the exact amount of bits in each byte of the number. For example, for u32, do the following:
n -= (n>>1) & 0x55555555;
n = ((n>>2) & 0x33333333) + (n & 0x33333333);
n = (((n>>4) + n) & 0x0F0F0F0F );
Now our number n consists of 4 bytes, which should be considered as 4 numbers, the sum of which we are looking for:
We can find the sum of these 4 bytes if we multiply the number n by 0x01010101. You now well understand what such multiplication means, for the convenience of determining the position in which the answer will be, I quote the picture:
The answer is in 3-byte (if you count them from 0). Thus, the combined trick for u32 will look like this:
u8 CountOnes5 ( u32 n ) {
n -= (n>>1) & 0x55555555;
n = ((n>>2) & 0x33333333 ) + (n & 0x33333333);
n = ((((n>>4) + n) & 0x0F0F0F0F) * 0x01010101) >> 24;
return n; // Здесь происходит неявное обрезание по 8 младшим битам.
}
He is for u16:
u8 CountOnes5 (u16 n) {
n -= (n>>1) & 0x5555;
n = ((n>>2) & 0x3333) + (n & 0x3333);
n = ((((n>>4) + n) & 0x0F0F) * 0x0101) >> 8;
return n; // Здесь происходит неявное обрезание по 8 младшим битам.
}
He is for u64:
u8 CountOnes5 ( u64 n ) {
n -= (n>>1) & 0x5555555555555555llu;
n = ((n>>2) & 0x3333333333333333llu ) + (n & 0x3333333333333333llu);
n = ((((n>>4) + n) & 0x0F0F0F0F0F0F0F0Fllu)
* 0x0101010101010101) >> 56;
return n; // Здесь происходит неявное обрезание по 8 младшим битам.
}
You can see the speed of this method immediately in the final table.
Final comparison
I suggest the reader to draw his own conclusions of interest by examining the two following tables. In them, I designated the name of the methods for which we implemented programs, and also marked with a rectangular frame those approaches that I consider to be the best in each particular case. Those who thought that the pre-calculation always wins will get a little surprise for the x64 mode.
The final comparison for x86 compilation mode.
The final comparison for x64 compilation mode.
Comment
In no case do not consider the final table as evidence in favor of one or another approach. Believe that on your processor and with your compiler some numbers in such a table will be completely different. Unfortunately, we can never say for sure which of the algorithms will turn out to be better in any given case. A specific method needs to be sharpened for each task, and, unfortunately, a universal fast algorithm does not exist.
I have outlined the ideas that I know about myself, but these are just ideas whose specific implementations in different combinations can be very different. Combining these ideas in different ways, you can get a huge number of different algorithms for counting single bits, each of which may well turn out to be good in some case.
Thanks for attention. See you soon!
UPD : The POPCNT instruction from SSE4.2 is not included in the test list because I do not have a processor that supports SSE4.2.