Parallel Algorithms for BigData Processing: Pitfalls and Challenges
This publication is based on a presentation by AlexSerbul at the Autumn BigData Conference .
Big data is a trendy and relevant topic. But many are still frightened by the excess of theoretical considerations and a certain lack of practical recommendations. In this post I want to partially fill this gap and talk about the use of parallel algorithms for processing big data using the example of clustering a product catalog of 10 million items.
Unfortunately, when you have a lot of data, you will have to “reinvent” the classic algorithm again so that it works in parallel using MapReduce. And that is a big problem.
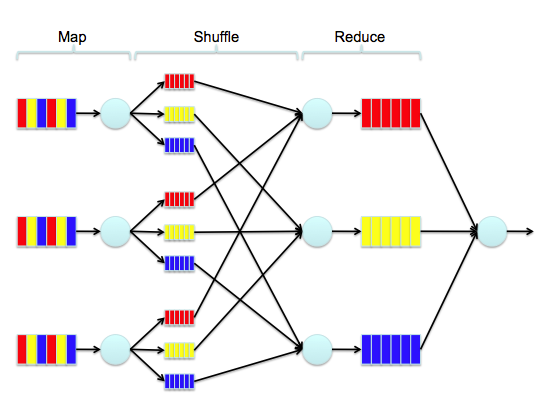
What is the way out? For the sake of saving time and money, you can of course try to find a library that will allow you to implement a parallel clustering algorithm. Of course, there is something on the Java platform: the dying Apache Mahout and the growing Apache Spark MLlib. Unfortunately, Mahout supports few algorithms under MapReduce - most of them are consistent.
The promising Spark MLlib mountains are also not rich in clustering algorithms. And with our volumes, things are even worse - this is what is proposed:
When you have 10-20 million entities for clustering, the above solutions will no longer help, you need hardcore. But first things first.
So, we need to cluster the catalog of 10 million items. Why is this needed? The fact is that our users can use the recommendation system in their online stores. And her work is based on the analysis of an aggregated catalog of goods of all sites working on our platform. Suppose, in one of the stores, the buyer was recommended to choose an ax to cut to mother-in-law (yes, this is a corporate blog, but without jokes about bigdata and math, you just can’t talk - everything is asleep). The system learns about it, analyzes it and, in another store, recommends the same buyer the button accordion to play and enjoy. That is, the first task solved by clustering is the transfer of interest.
The second task: to ensure the creation of the correct logical connections of goods to increase related sales. For example, if a user bought a camera, the system will recommend a battery and a memory card to it. That is, we need to collect similar products in clusters, and work in different stores already at the cluster level.
As noted above, our product database consists of catalogs of several tens of thousands of online stores operating on the 1C-Bitrix platform. Users enter text descriptions of different lengths there, someone adds brands of goods, models, manufacturers. It would be expensive, long and hard to create a consistent, accurate, unified system for collecting and classifying all products from tens of thousands of stores. And we wanted to find a way to quickly glue similar products together and significantly improve the quality of collaborative filtering. After all, if the system knows the buyer well, it does not matter what specific products and their brands he is interested in, the system will always find what to offer him.
First of all, it was necessary to choose a storage system suitable for working with "big" data. I will repeat a little, but it is useful for fixing the material. For ourselves, we identified four “camps” of databases:
Having dealt closely with the issue of clustering, we found out that there are not so many ready-made offers on the market.
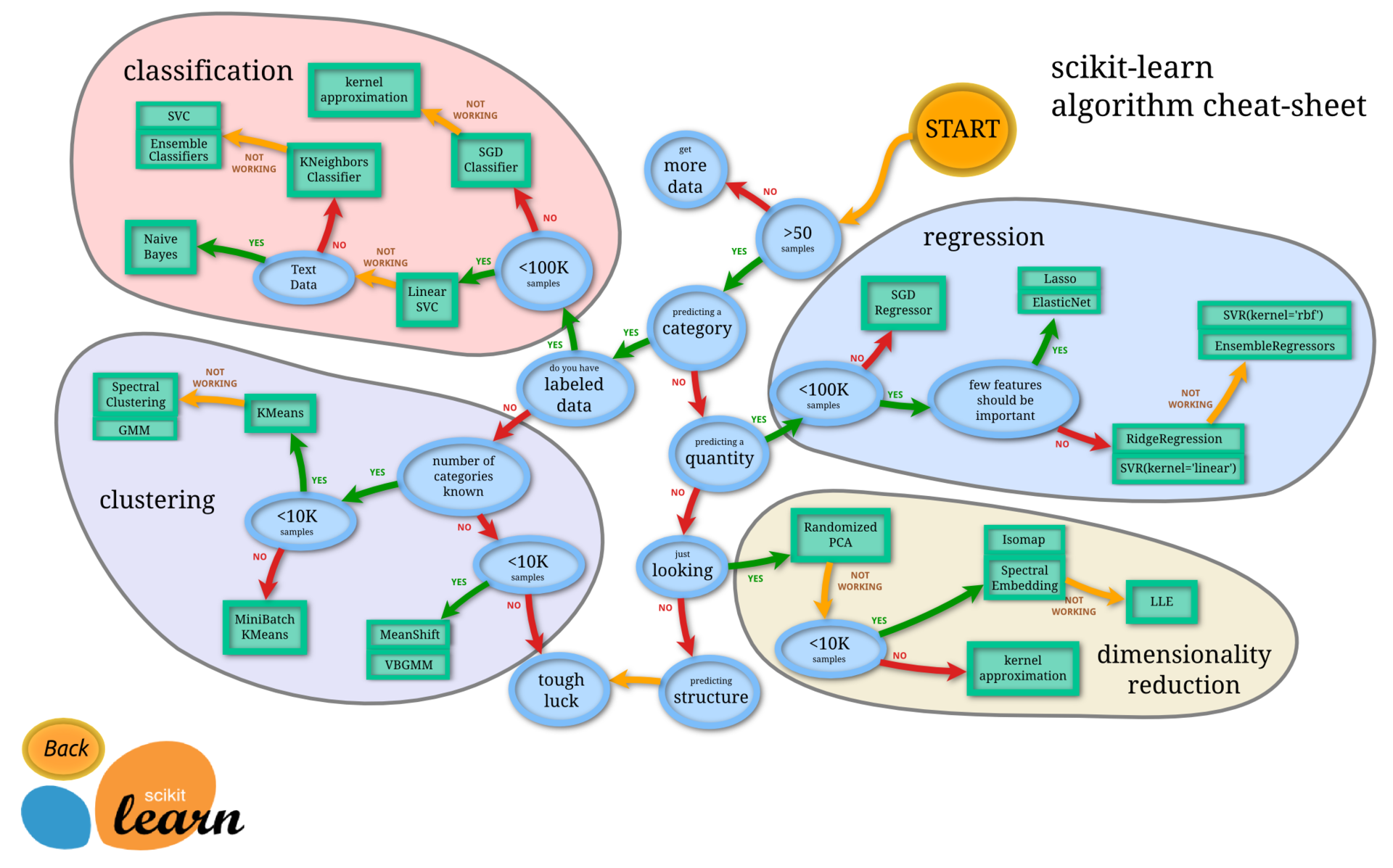
As a result, we settled on SparkMLlib, because there, as it seemed, there are reliable parallel clustering algorithms.
We first had to figure out how to combine text descriptions of goods (names and short descriptions) into clusters. Natural language word processing is a separate huge field of Computer Science, which includes both machine learning and Information retrieval
and linguistics and even (tadam!) Deep Learning.
When there are dozens, hundreds, thousands of data for clustering, almost any classical algorithm, even hierarchical clustering, is suitable. The problem is that the algorithmic complexity of hierarchical clustering is approximately O (N 3) That is, we must wait for “billions of years” until it works on our data volume, on a huge cluster. But it was impossible to be limited to processing only a certain sample. Therefore, hierarchical clustering in the forehead did not suit us.
Then we turned to the “bearded” K-means algorithm:
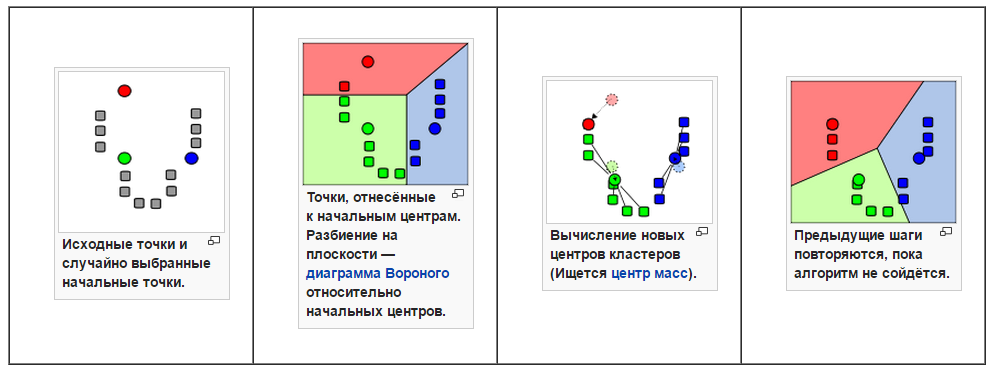
This is a very simple, well-studied and widespread algorithm. However, it works on big data very slowly: the algorithmic complexity is approximately O (nkdi). For n = 10,000,000 (quantity of goods), k = 1,000,000 (expected number of clusters), d = <1,000,000 (types of words, vector dimension), i = 100 (approximate number of iterations), O = 10 21 operations . For comparison, the age of the Earth is 1.4 * 10 17 seconds.
Although the C-means algorithm allows fuzzy clustering, it also works slowly on our volumes, as does spectral factorization. For the same reason, DBSCAN and probabilistic models did not suit us.
To carry out clustering, we decided at the first stage to turn the text into vectors. A vector is a certain point in multidimensional space, the clusters of which will be the desired clusters.
We needed to cluster product descriptions of 2-10 words. The simplest, classic solution to the forehead or eye - bag of words. Since we have a catalog, we can also define a dictionary. As a result, we have a corpus of approximately one million words. After stemming, there were about 500 thousand of them left. High-frequency and low-frequency words were discarded. Of course, you could use tf / idf, but decided not to complicate it.
What are the disadvantages of this approach? The resulting huge vector is then expensive to calculate, comparing its similarity with others. After all, what is clustering? This is the process of searching for similar vectors. And when they are 500 thousand in size, the search takes a lot of time, so you need to learn how to compress them. To do this, you can use Kernel hack, hashing words not in 500 thousand attributes, but in 100 thousand. A good, working tool, but conflicts can occur. We did not use it.
And finally, I’ll tell you about one more technology that we have discarded, but now we are seriously considering starting to use it. This is Word2Vec, a technique for statistical processing of text by compressing the dimension of text vectors by a two-layer neural network, developed by Google. In fact, this is a development of the good old eternal statistical N-gram text models, only skip-gram variation is used.
The first task, which is beautifully solved using Word2Vec: reducing dimension due to "matrix factorization" (specifically in quotation marks, because there are no matrices there, but the effect is very similar). That is, it turns out, for example, not 500 thousand attributes, but only 100. When there are words that are similar “in context”, the system considers them “synonyms” (of course, coffee and tea can combine). It turns out that the points of these similar words in multidimensional space begin to coincide, that is, words of similar meaning are clustered into a common cloud. Say, “coffee” and “tea” will be words that are close in meaning, because they are often found in context together. Thanks to the Word2Wec library, you can reduce the size of vectors, and they themselves turn out to be more meaningful.
This topic has been around for many years: Latent semantic indexing and its variations through PCA / SVD have been well studied, and the solution to the forehead by clustering columns or rows of the term2document matrix will, in fact, give a similar result - it only takes a very long time to do this.
It is very likely that we will still begin to use Word2Vec. By the way, its use also allows you to find typos and play with vector algebra of sentences and words.
As a result, after all the long searches for scientific publications, we wrote our own version of k-Means - Clustering by Bootstrap Averaging for Spark.
In essence, this is hierarchical k-Means, which does preliminary layer-by-layer sampling of data. It took a reasonable amount of time to process 10 million goods, hours, although it took a bunch of servers to use. But the result did not work, because Part of the text data could not be clustered - socks were glued with airplanes. The method worked, but very rude and inaccurate.
There was hope for the old, but now forgotten probabilistic methods for finding duplicates or "almost duplicates" - locality-sensitive hashing .
The method variant described here, required the use of vectors of the same size transformed from text, for further “scattering” them according to hash functions. And we took MinHash.
MinHash is a technology for compressing large-sized vectors into a small vector with preservation from mutual Jaccard-likeness. How does she work? We have a certain number of vectors or sets of sets, and we define a set of hash functions through which we run each vector / set.

Define, for example, 50 hash functions. Then we run each hash function by vector / set, determine the minimum value of the hash function, and get the number that is written to the N-position of the new compressed vector. We do it 50 times.
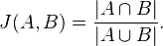
Pr [h min (A) = h min (B)] = J (A, B)
Thus, we solved the problem of compressing measurements and reducing vectors to a single number of measurements.
I completely forgot to tell you that we refused to vectorize texts forehead, because product names and brief descriptions created extremely discharged vectors suffering from the “curse of dimensionality”.
The names of the goods were usually about this type and size:
“Striped red terry
pants” “Red striped pants”
These two phrases differ in terms of the set of words, their quantity and location. In addition, people make typos when typing. Therefore, words cannot be compared even after stemming, because all texts will be mathematically dissimilar, although they are close in meaning.
In such a situation, the shingle algorithm (shingle, flakes, tiles) is often used . We present the text in the form of shingle, pieces.
{"Pants", "tany", "ana", "ny k", "s kra", "kras", ...}
And when comparing a lot of pieces, it turns out that two texts of different texts can suddenly find similarity with each other. We experimented with text processing for a long time, and in our experience, only in this way can short text descriptions be compared in our product catalog. This method is also used to identify similar articles, scientific papers, in order to detect plagiarism.
I repeat once again: we abandoned the very sparse text vectors, replaced each text with a set of set shingles, and then reduced them to a single size using MinHash.
As a result, we solved the problem of vectorizing the catalog as follows. Using the MinHash signature, we got small vectors from 100 to 500 (the size is chosen the same for all vectors). Now they need to be compared each with each in order to form clusters. On the forehead, as we already know, this is a very long time. And thanks to the LSH ( Locality-Sensitive Hashing ) algorithm, the problem was solved in one pass.
The idea is that similar objects, texts, vectors collide into one set of hash functions, into one bucket. And then it remains to go through them and collect similar elements. After clustering, we get a million bucket'ov, each of which will be a cluster.
Traditionally, several bands are used - sets of hash functions. But we simplified the task even more - we left only one band. Suppose the first 40 elements of a vector are taken and entered in a hash table. And then there are elements that have the same piece at first. That's all! For starters, great. If you need more accuracy, you can work with the bands group, but then in the final part of the algorithm it will take longer to collect mutually similar objects from them.
After the first iteration, we got good results: almost all duplicates and almost all similar products stuck together. Evaluated visually. And to further reduce the number of microclusters, we previously removed frequently occurring and rarely found words.
Now, in just two or three hours, on 8 spot-servers, 10 million goods are clustered in approximately one million clusters. In fact, in one pass, because band is only one. Having experimented with the settings, we got quite adequate clusters: yachts, cars, sausage, etc., without stupid things like “ax + plane”. And now this compressed cluster model is used to improve the accuracy of the personal recommendation system.
In collaborative algorithms, we began to work not with specific goods, but with clusters. A new product appeared, we found a cluster, put it there. And the reverse process - we recommend a cluster, then we select the most popular product from it and return it to the user. Using the cluster catalog improved the accuracy of recommendations by several times (we measure the recall of the current model a month earlier). And this is just due to the compression of data (names) and combining them in meaning. Therefore, I want to advise you - look for simple solutions to your problems associated with big data. Do not try to complicate things. I believe that you can always find a simple, effective solution that will solve 90% of the tasks in 10% of the effort! Good luck and success in working with big data!
Big data is a trendy and relevant topic. But many are still frightened by the excess of theoretical considerations and a certain lack of practical recommendations. In this post I want to partially fill this gap and talk about the use of parallel algorithms for processing big data using the example of clustering a product catalog of 10 million items.
Unfortunately, when you have a lot of data, you will have to “reinvent” the classic algorithm again so that it works in parallel using MapReduce. And that is a big problem.
What is the way out? For the sake of saving time and money, you can of course try to find a library that will allow you to implement a parallel clustering algorithm. Of course, there is something on the Java platform: the dying Apache Mahout and the growing Apache Spark MLlib. Unfortunately, Mahout supports few algorithms under MapReduce - most of them are consistent.
The promising Spark MLlib mountains are also not rich in clustering algorithms. And with our volumes, things are even worse - this is what is proposed:
- K-means
- Gaussian mixture
- Power iteration clustering (PIC)
- Latent Dirichlet allocation (LDA)
- Streaming k-means
When you have 10-20 million entities for clustering, the above solutions will no longer help, you need hardcore. But first things first.
So, we need to cluster the catalog of 10 million items. Why is this needed? The fact is that our users can use the recommendation system in their online stores. And her work is based on the analysis of an aggregated catalog of goods of all sites working on our platform. Suppose, in one of the stores, the buyer was recommended to choose an ax to cut to mother-in-law (yes, this is a corporate blog, but without jokes about bigdata and math, you just can’t talk - everything is asleep). The system learns about it, analyzes it and, in another store, recommends the same buyer the button accordion to play and enjoy. That is, the first task solved by clustering is the transfer of interest.
The second task: to ensure the creation of the correct logical connections of goods to increase related sales. For example, if a user bought a camera, the system will recommend a battery and a memory card to it. That is, we need to collect similar products in clusters, and work in different stores already at the cluster level.
As noted above, our product database consists of catalogs of several tens of thousands of online stores operating on the 1C-Bitrix platform. Users enter text descriptions of different lengths there, someone adds brands of goods, models, manufacturers. It would be expensive, long and hard to create a consistent, accurate, unified system for collecting and classifying all products from tens of thousands of stores. And we wanted to find a way to quickly glue similar products together and significantly improve the quality of collaborative filtering. After all, if the system knows the buyer well, it does not matter what specific products and their brands he is interested in, the system will always find what to offer him.
Tool selection
First of all, it was necessary to choose a storage system suitable for working with "big" data. I will repeat a little, but it is useful for fixing the material. For ourselves, we identified four “camps” of databases:
- MapReduce SQL: Hive, Pig, Spark SQL . Download one billion rows to the RDBMS and perform data aggregation - it will become clear that this class of storage systems is "not very" suitable for this task. Therefore, intuitively, you can try to use SQL through MapReduce (which Facebook once did). The obvious disadvantages here are the speed of execution of short queries.
- SQL on MPP (massive parallel processing): Impala, Presto, Amazon RedShift, Vertica . Representatives of this camp argue that SQL through MapReduce is a dead end, so you need to actually raise a driver on each node where the data is stored, which will quickly access this data. But many of these systems suffer from instability.
- NoSQL: Cassandra, HBase, Amazon DynamoDB . The third camp says: BigData is NoSQL. But we understand that NoSQL is, in fact, a set of “memcached servers” united in a ring structure, which can quickly execute a query such as “take a key by value and return a response”. They can also return a data set sorted in random access memory by key. That's almost all - forget about JOINS.
- Classic: MySQL, MS SQL, Oracle, etc . Monsters do not give up and claim that all of the above - garbage, grief from the mind, and relational databases work great with BigData. Someone offers fractal trees ( https://en.wikipedia.org/wiki/TokuDB ), others offer clusters. Monsters want to live too.
Having dealt closely with the issue of clustering, we found out that there are not so many ready-made offers on the market.
- Spark MLlib (Scala / Java / Python / R) - when there is a lot of data.
- scikit-learn.org (Python) - when there is little data.
- R - causes conflicting feelings due to the terrible curvature of the implementation (entrust programming to mathematicians and statisticians), but there are many ready-made solutions, and recent integration with Spark is very pleasing.
As a result, we settled on SparkMLlib, because there, as it seemed, there are reliable parallel clustering algorithms.
Clustering Algorithm Search
We first had to figure out how to combine text descriptions of goods (names and short descriptions) into clusters. Natural language word processing is a separate huge field of Computer Science, which includes both machine learning and Information retrieval
and linguistics and even (tadam!) Deep Learning.
When there are dozens, hundreds, thousands of data for clustering, almost any classical algorithm, even hierarchical clustering, is suitable. The problem is that the algorithmic complexity of hierarchical clustering is approximately O (N 3) That is, we must wait for “billions of years” until it works on our data volume, on a huge cluster. But it was impossible to be limited to processing only a certain sample. Therefore, hierarchical clustering in the forehead did not suit us.
Then we turned to the “bearded” K-means algorithm:
This is a very simple, well-studied and widespread algorithm. However, it works on big data very slowly: the algorithmic complexity is approximately O (nkdi). For n = 10,000,000 (quantity of goods), k = 1,000,000 (expected number of clusters), d = <1,000,000 (types of words, vector dimension), i = 100 (approximate number of iterations), O = 10 21 operations . For comparison, the age of the Earth is 1.4 * 10 17 seconds.
Although the C-means algorithm allows fuzzy clustering, it also works slowly on our volumes, as does spectral factorization. For the same reason, DBSCAN and probabilistic models did not suit us.
To carry out clustering, we decided at the first stage to turn the text into vectors. A vector is a certain point in multidimensional space, the clusters of which will be the desired clusters.
We needed to cluster product descriptions of 2-10 words. The simplest, classic solution to the forehead or eye - bag of words. Since we have a catalog, we can also define a dictionary. As a result, we have a corpus of approximately one million words. After stemming, there were about 500 thousand of them left. High-frequency and low-frequency words were discarded. Of course, you could use tf / idf, but decided not to complicate it.
What are the disadvantages of this approach? The resulting huge vector is then expensive to calculate, comparing its similarity with others. After all, what is clustering? This is the process of searching for similar vectors. And when they are 500 thousand in size, the search takes a lot of time, so you need to learn how to compress them. To do this, you can use Kernel hack, hashing words not in 500 thousand attributes, but in 100 thousand. A good, working tool, but conflicts can occur. We did not use it.
And finally, I’ll tell you about one more technology that we have discarded, but now we are seriously considering starting to use it. This is Word2Vec, a technique for statistical processing of text by compressing the dimension of text vectors by a two-layer neural network, developed by Google. In fact, this is a development of the good old eternal statistical N-gram text models, only skip-gram variation is used.
The first task, which is beautifully solved using Word2Vec: reducing dimension due to "matrix factorization" (specifically in quotation marks, because there are no matrices there, but the effect is very similar). That is, it turns out, for example, not 500 thousand attributes, but only 100. When there are words that are similar “in context”, the system considers them “synonyms” (of course, coffee and tea can combine). It turns out that the points of these similar words in multidimensional space begin to coincide, that is, words of similar meaning are clustered into a common cloud. Say, “coffee” and “tea” will be words that are close in meaning, because they are often found in context together. Thanks to the Word2Wec library, you can reduce the size of vectors, and they themselves turn out to be more meaningful.
This topic has been around for many years: Latent semantic indexing and its variations through PCA / SVD have been well studied, and the solution to the forehead by clustering columns or rows of the term2document matrix will, in fact, give a similar result - it only takes a very long time to do this.
It is very likely that we will still begin to use Word2Vec. By the way, its use also allows you to find typos and play with vector algebra of sentences and words.
“I will build my lunapark! ..”
As a result, after all the long searches for scientific publications, we wrote our own version of k-Means - Clustering by Bootstrap Averaging for Spark.
In essence, this is hierarchical k-Means, which does preliminary layer-by-layer sampling of data. It took a reasonable amount of time to process 10 million goods, hours, although it took a bunch of servers to use. But the result did not work, because Part of the text data could not be clustered - socks were glued with airplanes. The method worked, but very rude and inaccurate.
There was hope for the old, but now forgotten probabilistic methods for finding duplicates or "almost duplicates" - locality-sensitive hashing .
The method variant described here, required the use of vectors of the same size transformed from text, for further “scattering” them according to hash functions. And we took MinHash.
MinHash is a technology for compressing large-sized vectors into a small vector with preservation from mutual Jaccard-likeness. How does she work? We have a certain number of vectors or sets of sets, and we define a set of hash functions through which we run each vector / set.
Define, for example, 50 hash functions. Then we run each hash function by vector / set, determine the minimum value of the hash function, and get the number that is written to the N-position of the new compressed vector. We do it 50 times.
Pr [h min (A) = h min (B)] = J (A, B)
Thus, we solved the problem of compressing measurements and reducing vectors to a single number of measurements.
Text shingling
I completely forgot to tell you that we refused to vectorize texts forehead, because product names and brief descriptions created extremely discharged vectors suffering from the “curse of dimensionality”.
The names of the goods were usually about this type and size:
“Striped red terry
pants” “Red striped pants”
These two phrases differ in terms of the set of words, their quantity and location. In addition, people make typos when typing. Therefore, words cannot be compared even after stemming, because all texts will be mathematically dissimilar, although they are close in meaning.
In such a situation, the shingle algorithm (shingle, flakes, tiles) is often used . We present the text in the form of shingle, pieces.
{"Pants", "tany", "ana", "ny k", "s kra", "kras", ...}
And when comparing a lot of pieces, it turns out that two texts of different texts can suddenly find similarity with each other. We experimented with text processing for a long time, and in our experience, only in this way can short text descriptions be compared in our product catalog. This method is also used to identify similar articles, scientific papers, in order to detect plagiarism.
I repeat once again: we abandoned the very sparse text vectors, replaced each text with a set of set shingles, and then reduced them to a single size using MinHash.
Vectorization
As a result, we solved the problem of vectorizing the catalog as follows. Using the MinHash signature, we got small vectors from 100 to 500 (the size is chosen the same for all vectors). Now they need to be compared each with each in order to form clusters. On the forehead, as we already know, this is a very long time. And thanks to the LSH ( Locality-Sensitive Hashing ) algorithm, the problem was solved in one pass.
The idea is that similar objects, texts, vectors collide into one set of hash functions, into one bucket. And then it remains to go through them and collect similar elements. After clustering, we get a million bucket'ov, each of which will be a cluster.
Clustering
Traditionally, several bands are used - sets of hash functions. But we simplified the task even more - we left only one band. Suppose the first 40 elements of a vector are taken and entered in a hash table. And then there are elements that have the same piece at first. That's all! For starters, great. If you need more accuracy, you can work with the bands group, but then in the final part of the algorithm it will take longer to collect mutually similar objects from them.
After the first iteration, we got good results: almost all duplicates and almost all similar products stuck together. Evaluated visually. And to further reduce the number of microclusters, we previously removed frequently occurring and rarely found words.
Now, in just two or three hours, on 8 spot-servers, 10 million goods are clustered in approximately one million clusters. In fact, in one pass, because band is only one. Having experimented with the settings, we got quite adequate clusters: yachts, cars, sausage, etc., without stupid things like “ax + plane”. And now this compressed cluster model is used to improve the accuracy of the personal recommendation system.
Summary
In collaborative algorithms, we began to work not with specific goods, but with clusters. A new product appeared, we found a cluster, put it there. And the reverse process - we recommend a cluster, then we select the most popular product from it and return it to the user. Using the cluster catalog improved the accuracy of recommendations by several times (we measure the recall of the current model a month earlier). And this is just due to the compression of data (names) and combining them in meaning. Therefore, I want to advise you - look for simple solutions to your problems associated with big data. Do not try to complicate things. I believe that you can always find a simple, effective solution that will solve 90% of the tasks in 10% of the effort! Good luck and success in working with big data!