Designing PostgreSQL Document Oriented APIs: Complex Queries (Part 4)
- Transfer
Storing documents in Postgres is a bit simpler, now we have serious save procedures , the ability to run full-text searches , and some simple search and filtering procedures .
This is only half the story, of course. Rudimentary searches may serve the needs of the application, but they will never work in the long run when we need to ask deeper questions.
Document storage is a very big topic. How to store a document (and what to store), for me, is divided into three areas:
I am very drawn to the latter. I am an information storage device and when something happens, I want to know what / why / where to any limits.
Here's what I used to do to keep track of people buying something on TechPub. This is the format of the document that I was going to put into business, but did not reach this point (due to the sale on Plularsight).
This is a great document . I love great documents! This document is the exact result of all information movements during the checkout process:
I want this document to be an autonomous, self-contained object that does not need any other documents to be completed. In other words, I would like to be able to:
This document is completed on its own and it is wonderful!
OK, enough, let's write some reports.
When leading an analyst, it is important to remember two things:
It takes forever to execute huge queries on joined tables, and this ultimately leads to nothing. You should build reports on historical data that do not change (or change very little) over time. Denormalization helps with speed, and speed is your friend when building reports.
Given this, we must use the goodness of PostgreSQL to form our data into a sales fact table . "Actual" table - it's just a denormalized data set, which represents an event in your system - the smallest amount of digestible information on fact .
For us, this fact is a sale, and we want this event to look like this:

I use a sample Chinook databasewith some random sales data created with Faker .
Each of these records is a single event that I want to accumulate, and all the information about the dimension with which I want to combine them (time, supplier) is already included. I can add more (category, etc.), but for now this is enough.
These data are in tabular form, which means that we must extract them from the document shown above. The task is not easy, but much easier, because we use PostgreSQL:
This is a set of generalized table expressions (OTV), combined together in a functional way (more on this below). If you have never used OTV - they may look a little unusual ... until you take a closer look and understand that you simply combine things with names.
In the first request above, I pull out the sale id and call it invoice_id , and after that pull the timestamp and convert it to timestampz , Simple actions are inherently.
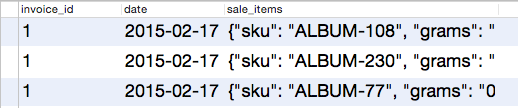
What gets interesting here is jsonb_array_elements, which pulls an array of objects from the document and creates a record for each of them. That is, if we had a single document in the database with three objects and launched the following query:
Instead of one record representing the sale, we would get 3:
Now that we have selected the objects, we need to separate them into separate columns. This is where the next trick with jsonb_to_record appears . We can immediately use this function, describing type values on the fly:
In this simple example, I convert jsonb to a table - I just need to tell PostgreSQL how to do it. This is exactly what we are doing in the second OTV (“event”) above. Also, we use date_part to convert dates.
This gives us an event table that we can save to the view if we:
You might think this query is terribly slow. In fact, it is quite fast. This is not some kind of level mark, or something like that - just a relative result to show you that this query is actually fast. I have 1000 test documents in the database, the execution of this query on all documents is returned in about a tenth of a second:

PostgreSQL. Cool stuff.
Now we are ready for some savings!
Then everything is simpler. You simply combine the data you want, and if you forget about something, you simply add it to your view and you do not have to worry about any table joins. Just data conversion that really happens fast.
Let's see the top five sellers:
This query returns data in 0.12 seconds. Fast enough for 1000 entries.
One of the things that I really like about RethinkDB is its own query language, ReQL. It is inspired by Haskell (according to the team) and it's all about composition (especially for me):
As can be seen above, we can approximate this using the OTVs combined together, each of which transforms the data in a specific way.
There is still much that I could write, but let's just sum it all up so that you can do everything that other document-oriented systems can do and even more. Postgres’s query capabilities are very large - there is a very small list of things that you cannot do and, as you have seen, the ability to convert your document into a spreadsheet helps a lot.
And this is the end of this small series of articles.
This is only half the story, of course. Rudimentary searches may serve the needs of the application, but they will never work in the long run when we need to ask deeper questions.
Source document
Document storage is a very big topic. How to store a document (and what to store), for me, is divided into three areas:
- Document / Domain Model. A look at all this from the developer's side, but if you are a fan of DDD (Domain Driven Design), then this plays a role.
- Real world. Accounts, purchases, orders - the business works on these things - let's think about it.
- Transactions, process results, event sources. In fact, when “something happens” with the application, you keep track of everything that happened while doing this and keep it.
I am very drawn to the latter. I am an information storage device and when something happens, I want to know what / why / where to any limits.
Here's what I used to do to keep track of people buying something on TechPub. This is the format of the document that I was going to put into business, but did not reach this point (due to the sale on Plularsight).
{
"id": 1,
"items": [
{
"sku": "ALBUM-108",
"grams": "0",
"price": 1317,
"taxes": [],
"vendor": "Iron Maiden",
"taxable": true,
"quantity": 1,
"discounts": [],
"gift_card": false,
"fulfillment": "download",
"requires_shipping": false
}
],
"notes": [],
"source": "Web",
"status": "complete",
"payment": {
//...
},
"customer": {
//...
},
"referral": {
//...
},
"discounts": [],
"started_at": "2015-02-18T03:07:33.037Z",
"completed_at": "2015-02-18T03:07:33.037Z",
"billing_address": {
//...
},
"shipping_address": {
//...
},
"processor_response": {
//...
}
}
This is a great document . I love great documents! This document is the exact result of all information movements during the checkout process:
- Customer Addresses (for billing, for delivery)
- Billing information and what was purchased
- How did they get here and a brief information about what happened on their way (in the form of notes)
- Exact answer from the processor (which in itself is a large document)
I want this document to be an autonomous, self-contained object that does not need any other documents to be completed. In other words, I would like to be able to:
- Make an order
- Run some reports
- Notify the client about changes, implementation, etc.
- Take further action if necessary (cancellation, cancellation)
This document is completed on its own and it is wonderful!
OK, enough, let's write some reports.
Data generation. Actual table
When leading an analyst, it is important to remember two things:
- Never run it on a running system
- Denormalization is the norm
It takes forever to execute huge queries on joined tables, and this ultimately leads to nothing. You should build reports on historical data that do not change (or change very little) over time. Denormalization helps with speed, and speed is your friend when building reports.
Given this, we must use the goodness of PostgreSQL to form our data into a sales fact table . "Actual" table - it's just a denormalized data set, which represents an event in your system - the smallest amount of digestible information on fact .
For us, this fact is a sale, and we want this event to look like this:
I use a sample Chinook databasewith some random sales data created with Faker .
Each of these records is a single event that I want to accumulate, and all the information about the dimension with which I want to combine them (time, supplier) is already included. I can add more (category, etc.), but for now this is enough.
These data are in tabular form, which means that we must extract them from the document shown above. The task is not easy, but much easier, because we use PostgreSQL:
with items as (
select body -> 'id' as invoice_id,
(body ->> 'completed_at')::timestamptz as date,
jsonb_array_elements(body -> 'items') as sale_items
from sales
), fact as (
select invoice_id,
date_part('quarter', date) as quarter,
date_part('year', date) as year,
date_part('month', date) as month,
date_part('day', date) as day,
x.*
from items, jsonb_to_record(sale_items) as x(
sku varchar(50),
vendor varchar(255),
price int,
quantity int
)
)
select * from fact;
This is a set of generalized table expressions (OTV), combined together in a functional way (more on this below). If you have never used OTV - they may look a little unusual ... until you take a closer look and understand that you simply combine things with names.
In the first request above, I pull out the sale id and call it invoice_id , and after that pull the timestamp and convert it to timestampz , Simple actions are inherently.
What gets interesting here is jsonb_array_elements, which pulls an array of objects from the document and creates a record for each of them. That is, if we had a single document in the database with three objects and launched the following query:
select body -> 'id' as invoice_id,
(body ->> 'completed_at')::timestamptz as date,
jsonb_array_elements(body -> 'items') as sale_items
from sales
Instead of one record representing the sale, we would get 3:
Now that we have selected the objects, we need to separate them into separate columns. This is where the next trick with jsonb_to_record appears . We can immediately use this function, describing type values on the fly:
select * from jsonb_to_record(
'{"name" : "Rob", "occupation": "Hazard"}'
) as (
name varchar(50),
occupation varchar(255)
)
In this simple example, I convert jsonb to a table - I just need to tell PostgreSQL how to do it. This is exactly what we are doing in the second OTV (“event”) above. Also, we use date_part to convert dates.
This gives us an event table that we can save to the view if we:
create view sales_fact as
-- the query above
You might think this query is terribly slow. In fact, it is quite fast. This is not some kind of level mark, or something like that - just a relative result to show you that this query is actually fast. I have 1000 test documents in the database, the execution of this query on all documents is returned in about a tenth of a second:
PostgreSQL. Cool stuff.
Now we are ready for some savings!
Sales report
Then everything is simpler. You simply combine the data you want, and if you forget about something, you simply add it to your view and you do not have to worry about any table joins. Just data conversion that really happens fast.
Let's see the top five sellers:
select sku,
sum(quantity) as sales_count,
sum((price * quantity)/100)::money as sales_total
from sales_fact
group by sku
order by salesCount desc
limit 5
This query returns data in 0.12 seconds. Fast enough for 1000 entries.
OTV and functional requests
One of the things that I really like about RethinkDB is its own query language, ReQL. It is inspired by Haskell (according to the team) and it's all about composition (especially for me):
To understand ReQL, it helps to understand functional programming. Functional programming is part of a declarative paradigm in which the programmer seeks to describe the value that he wants to calculate, rather than describe the steps necessary to calculate this value. Database query languages tend to strive for a declarative ideal, which at the same time gives the query processor the greatest freedom in choosing the optimal execution plan. But while SQL achieves this using special keywords and specific declarative syntax, ReQL has the ability to express arbitrarily complex operations through a functional composition.
As can be seen above, we can approximate this using the OTVs combined together, each of which transforms the data in a specific way.
Conclusion
There is still much that I could write, but let's just sum it all up so that you can do everything that other document-oriented systems can do and even more. Postgres’s query capabilities are very large - there is a very small list of things that you cannot do and, as you have seen, the ability to convert your document into a spreadsheet helps a lot.
And this is the end of this small series of articles.