Papers, please. How a neural network helps us check customers and catch scammers
Before a client can make money transfers in ePayments, he will have to go through verification. He provides us with his personal data and uploads documents to confirm identity and address. And we check whether they meet the requirements of our regulator. The flow of applications for verification has become increasingly, it has become difficult for us to process such a stream of documents. We were afraid that the procedure would take a lot of time and exceed all reasonable terms for customers. Then we decided to make a deep learning verification system.

To issue electronic money, you need to get a license regulator. If you open a payment system, for example, in Russia, the Central Bank of the Russian Federation will become your regulator. ePayments is the English payment system, our regulator is the Financial Conduct Authority (FCA), a body accountable to the UK Ministry of Finance. FCA ensures that we comply with the Anti-money laundering policy (AML), which includes the Know Your Customer (KYC) procedure set.
According to KYC, we are committed to checking who our client is and whether he is not associated with socially dangerous groups. Therefore, we have two obligations:
Every year, KYC requirements are becoming stricter and more detailed. At the beginning of 2017, without verification, ePayments clients could still receive payment or make transfers. Now this is not possible until they confirm their identity.
A few years ago we coped on our own. The Russians sent a scan of certain pages of the passport to confirm their identity, to confirm the address - a scan of the lease agreement, a receipt for payment of utility bills. Remember the game Papers, please? In it, you, playing for a customs official, check documents on the increasingly complex requirements of the government. Our client department played it at work every day.

Clients are verified remotely, without a visit to the office. To make the procedure faster, we hired new employees, but this is a dead-end path. Then the thought appeared to entrust part of the work of the neural network. If it copes well with facial recognition, then it will cope with our tasks. From a business point of view, a quick verification system should be able to:
At the output, the system should indicate a certain level of trust in the client: high, medium or low. Focusing on such a gradation, we will quickly verify and not annoy customers with delays.
The task of this module is to make sure that the user sends a valid document and give an answer what exactly he downloaded: a passport of a citizen of Kazakhstan, a lease agreement or a receipt for paying for utilities.
The classifier receives input data:
At the exit, the classifier reports that he received (passport, driver's license, and so on) and how confident he is of the correct answer.

Now the solution works on the Wide Residual Network architecture. We came to her not immediately. The first version of the fast verification system was based on the architecture that VGG inspired us for. She had 2 obvious problems: a large number of parameters (about 130 million) and instability to the position of the document. The more parameters, the harder it is to train such a neural network - it does not generalize knowledge well. The document in the photo must be located in the center, otherwise the classifier would have to be trained on samples in which it is located in different parts of the photo. As a result, we abandoned VGG and decided to switch to another architecture.
Residual Network (ResNet) was cooler than VGG. Thanks to skip connections, you can create a large number of layers and achieve high accuracy. ResNet has only about 1 million parameters and was indifferent to the position of the document. No matter where it is in the image, the solution to this architecture coped with the classification.
While we were finalizing the solution with a file, a new modification of the architecture, the Wide Residual Network (WRN), was released. The main difference from ResNet is a step back in terms of depth. WRN has fewer layers, but more convolutional filters. Now it is the best neural network architecture for most tasks and our solution works on it.
Problem number 1. Classifier needed to be trained. We had to load a lot of Russian, Kazakh and Belarusian passports and driver's licenses. But, of course, you cannot take customer documents. There are samples in the network, but there are too few of them for successful neural network training.
Decision.Our technical department generated a sample of 8000+ samples of each type. We create a document template and propagate it on many random samples. Then we generate a random position of the document in space relative to the camera, taking into account its mathematical model and characteristics: focal length, resolution of the matrix, and so on. When generating an artificial photograph, a random image is selected from the finished data set as the background. After that, a document with perspective distortions is placed on the image randomly. On such a sample, our neural network was well trained and perfectly defined the document “in combat”. Results - at the end of the article.
Problem number 2.Banal restriction on computing resources and memory. It makes no sense to submit a deep neural network to the input of large images. And photos from modern smartphones are like that.
Decision. Before submission to the input, the photo is compressed to a size of approximately 300x300 pixels. In the image of such a resolution, it is possible to easily distinguish one identity document from another. To solve this problem, we can use the standard Wide ResNet architecture.
Problem number 3. The documents confirming the address of residence, all the more difficult. The lease agreement or bank statement can be distinguished only by the text on the sheet. After reducing the image size to the same 300x300 pixels, any of these documents looks the same - like an A4 sheet with illegible text.
Decision. To classify arbitrary documents, we made changes to the neural network architecture itself. An additional input layer of neurons appeared in it, which is connected with the output layer. The neurons of this input layer receive an input vector describing the previously recognized text using the Bag-of-Words model .
First, we trained the neural network to classify identity documents. We used the weights of the trained network to initialize another network with an additional layer for the classification of arbitrary documents. This solution had high accuracy, but text recognition took some time. The difference in processing speed by different modules and the accuracy of classification can be found in Table 2.
How to deceive the payment system that checks the documents? You can borrow someone else's passport and register with it. To make sure that the client registers himself, we ask you to take a selfie with your ID. And the recognition module should compare the face on the document and the face on the selfie and answer, it’s one person or two different.
How to compare 2 persons if you are a car and think like a car? Turn a photo into a set of parameters and compare their values. This is how neural networks recognize faces. They take an image and turn it into a 128-dimensional (for example) vector. When you submit another face image to the input and ask them to compare, the neural network will turn the second person into a vector and calculate the distance between them.
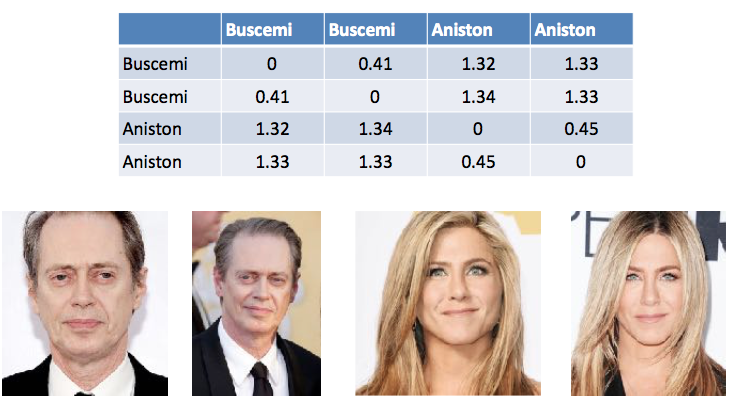
Table 1. An example of calculating the difference between vectors in face recognition. Steve Buscemi is different from himself in different photos at 0.44. And from Jennifer Aniston - an average of 1.33.
Of course, there are differences between how a person looks in life and on a passport. We also picked up the distance between the vectors and tested on real people to achieve results. In any case, now the final decision will be made by the person, and the comment from the system will be only a recommendation.
The documents have text fields that help the classifier understand what is in front of him. It will be convenient for the user if the text from the same passport is transferred automatically and you do not have to type manually, by whom and when it was issued. To do this, we made the following module - recognition and text extraction.
On some documents, for example, new RF passports there is a Machine-readable zone (MRZ). Using it, it is easy to shoot information - this is an easy-to-read black text on a white background that is easy to recognize. In addition, MRZ has a well-known format, thanks to which it is easier to obtain the necessary data.

If the task has documents with MRZ, then it becomes easier for us. The whole process lies in the field of computer vision. If this zone is not there, then after the recognition of the text you need to solve one interesting task - to understand, and what information have we recognized? For example, “05/15/1999” is the date of birth or the date of issue? At this stage, you can also make a mistake. MRZ is good because it is decoded unambiguously. We always know what information and in which part of the MRZ to look for. It is very convenient for us. But MRZ was not on the most popular document with which the network will work - the passport of the Russian Federation.
For text recognition, we needed a very effective solution. The text will have to be removed from the image made by the camera phone and not the most professional photographers. We tested Google Tesseract and several paid solutions. Nothing came up - either it worked poorly or it was unreasonably expensive. As a result, we began to develop our own solution. Now we finish testing it. The solution shows decent results - you can read about them below. We will tell about the photomontage verification module a little later when there will be accurate research results on test samples and on the “battle”.
The system is currently being tested on the verification application segment from Russia. The segment is determined by a random sample, the results are stored and reconciled with the decisions of the operator of the client department for a specific client.
Table 2. Accuracy of the classifier of documents (correct classification of the document in comparison with the operator's estimate).
One of the great advantages of machine learning is that the neural network really learns and makes fewer and fewer errors. Soon we will finish testing the segment and launch the verification system in a “combat” mode. 30% of applications for verification come to ePayments from Russia, Kazakhstan and Belarus. According to our estimates, the launch will help reduce the burden on the client department by 20–25%. In the future, the solution can be scaled to European countries.
We are looking for employees to work in an office in St. Petersburg. If you are interested in an international project with a large pool of ambitious tasks, we are waiting for you. We do not have enough people who are not afraid to implement them. Below you will find links to vacancies on hh.ru.
Policy on regulators and their requirements
To issue electronic money, you need to get a license regulator. If you open a payment system, for example, in Russia, the Central Bank of the Russian Federation will become your regulator. ePayments is the English payment system, our regulator is the Financial Conduct Authority (FCA), a body accountable to the UK Ministry of Finance. FCA ensures that we comply with the Anti-money laundering policy (AML), which includes the Know Your Customer (KYC) procedure set.
According to KYC, we are committed to checking who our client is and whether he is not associated with socially dangerous groups. Therefore, we have two obligations:
- Identification and confirmation of customer identity.
- Verification of his data with various lists: terrorists, persons under sanctions, members of the government and many others.
Every year, KYC requirements are becoming stricter and more detailed. At the beginning of 2017, without verification, ePayments clients could still receive payment or make transfers. Now this is not possible until they confirm their identity.
Manual Verification
A few years ago we coped on our own. The Russians sent a scan of certain pages of the passport to confirm their identity, to confirm the address - a scan of the lease agreement, a receipt for payment of utility bills. Remember the game Papers, please? In it, you, playing for a customs official, check documents on the increasingly complex requirements of the government. Our client department played it at work every day.
Clients are verified remotely, without a visit to the office. To make the procedure faster, we hired new employees, but this is a dead-end path. Then the thought appeared to entrust part of the work of the neural network. If it copes well with facial recognition, then it will cope with our tasks. From a business point of view, a quick verification system should be able to:
- Categorize document. We are sent an ID and proof of address. The system must answer what it received at the entrance: a passport of a citizen of the Russian Federation, a lease agreement or something else.
- Compare the face in the photo and document. We ask clients to send selfies with an ID to make sure that they register themselves in the payment system.
- Extract text. Filling dozens of fields from a smartphone is not very convenient. Much easier if the application has done everything for you.
- Check image files for photo montage. We must not forget about fraudsters who want to get into the system fraudulently.
At the output, the system should indicate a certain level of trust in the client: high, medium or low. Focusing on such a gradation, we will quickly verify and not annoy customers with delays.
Document Classifier
The task of this module is to make sure that the user sends a valid document and give an answer what exactly he downloaded: a passport of a citizen of Kazakhstan, a lease agreement or a receipt for paying for utilities.
The classifier receives input data:
- Photo or scan document
- Country of residence
- Document type indicated by the client (ID or proof of residence)
- Extracted text (more on this below)
At the exit, the classifier reports that he received (passport, driver's license, and so on) and how confident he is of the correct answer.
Now the solution works on the Wide Residual Network architecture. We came to her not immediately. The first version of the fast verification system was based on the architecture that VGG inspired us for. She had 2 obvious problems: a large number of parameters (about 130 million) and instability to the position of the document. The more parameters, the harder it is to train such a neural network - it does not generalize knowledge well. The document in the photo must be located in the center, otherwise the classifier would have to be trained on samples in which it is located in different parts of the photo. As a result, we abandoned VGG and decided to switch to another architecture.
Residual Network (ResNet) was cooler than VGG. Thanks to skip connections, you can create a large number of layers and achieve high accuracy. ResNet has only about 1 million parameters and was indifferent to the position of the document. No matter where it is in the image, the solution to this architecture coped with the classification.
While we were finalizing the solution with a file, a new modification of the architecture, the Wide Residual Network (WRN), was released. The main difference from ResNet is a step back in terms of depth. WRN has fewer layers, but more convolutional filters. Now it is the best neural network architecture for most tasks and our solution works on it.
Some useful solutions.
Problem number 1. Classifier needed to be trained. We had to load a lot of Russian, Kazakh and Belarusian passports and driver's licenses. But, of course, you cannot take customer documents. There are samples in the network, but there are too few of them for successful neural network training.
Decision.Our technical department generated a sample of 8000+ samples of each type. We create a document template and propagate it on many random samples. Then we generate a random position of the document in space relative to the camera, taking into account its mathematical model and characteristics: focal length, resolution of the matrix, and so on. When generating an artificial photograph, a random image is selected from the finished data set as the background. After that, a document with perspective distortions is placed on the image randomly. On such a sample, our neural network was well trained and perfectly defined the document “in combat”. Results - at the end of the article.
Problem number 2.Banal restriction on computing resources and memory. It makes no sense to submit a deep neural network to the input of large images. And photos from modern smartphones are like that.
Decision. Before submission to the input, the photo is compressed to a size of approximately 300x300 pixels. In the image of such a resolution, it is possible to easily distinguish one identity document from another. To solve this problem, we can use the standard Wide ResNet architecture.
Problem number 3. The documents confirming the address of residence, all the more difficult. The lease agreement or bank statement can be distinguished only by the text on the sheet. After reducing the image size to the same 300x300 pixels, any of these documents looks the same - like an A4 sheet with illegible text.
Decision. To classify arbitrary documents, we made changes to the neural network architecture itself. An additional input layer of neurons appeared in it, which is connected with the output layer. The neurons of this input layer receive an input vector describing the previously recognized text using the Bag-of-Words model .
First, we trained the neural network to classify identity documents. We used the weights of the trained network to initialize another network with an additional layer for the classification of arbitrary documents. This solution had high accuracy, but text recognition took some time. The difference in processing speed by different modules and the accuracy of classification can be found in Table 2.
Face recognition
How to deceive the payment system that checks the documents? You can borrow someone else's passport and register with it. To make sure that the client registers himself, we ask you to take a selfie with your ID. And the recognition module should compare the face on the document and the face on the selfie and answer, it’s one person or two different.
How to compare 2 persons if you are a car and think like a car? Turn a photo into a set of parameters and compare their values. This is how neural networks recognize faces. They take an image and turn it into a 128-dimensional (for example) vector. When you submit another face image to the input and ask them to compare, the neural network will turn the second person into a vector and calculate the distance between them.
Table 1. An example of calculating the difference between vectors in face recognition. Steve Buscemi is different from himself in different photos at 0.44. And from Jennifer Aniston - an average of 1.33.
Of course, there are differences between how a person looks in life and on a passport. We also picked up the distance between the vectors and tested on real people to achieve results. In any case, now the final decision will be made by the person, and the comment from the system will be only a recommendation.
Text recognising
The documents have text fields that help the classifier understand what is in front of him. It will be convenient for the user if the text from the same passport is transferred automatically and you do not have to type manually, by whom and when it was issued. To do this, we made the following module - recognition and text extraction.
On some documents, for example, new RF passports there is a Machine-readable zone (MRZ). Using it, it is easy to shoot information - this is an easy-to-read black text on a white background that is easy to recognize. In addition, MRZ has a well-known format, thanks to which it is easier to obtain the necessary data.
If the task has documents with MRZ, then it becomes easier for us. The whole process lies in the field of computer vision. If this zone is not there, then after the recognition of the text you need to solve one interesting task - to understand, and what information have we recognized? For example, “05/15/1999” is the date of birth or the date of issue? At this stage, you can also make a mistake. MRZ is good because it is decoded unambiguously. We always know what information and in which part of the MRZ to look for. It is very convenient for us. But MRZ was not on the most popular document with which the network will work - the passport of the Russian Federation.
For text recognition, we needed a very effective solution. The text will have to be removed from the image made by the camera phone and not the most professional photographers. We tested Google Tesseract and several paid solutions. Nothing came up - either it worked poorly or it was unreasonably expensive. As a result, we began to develop our own solution. Now we finish testing it. The solution shows decent results - you can read about them below. We will tell about the photomontage verification module a little later when there will be accurate research results on test samples and on the “battle”.
Result
The system is currently being tested on the verification application segment from Russia. The segment is determined by a random sample, the results are stored and reconciled with the decisions of the operator of the client department for a specific client.
| A country | Classifier Type | Accuracy | Work time, with |
| Russia | Identification | 99.96% | 0.41 |
| Russia | Arbitrary document | 98.62% | 6.89 |
| Kazakhstan | Identification | 99.51% | 0.47 |
| Kazakhstan | Arbitrary document | 97.25% | 7.66 |
| Belorussia | Identification | 98.63% | 0.46 |
| Belorussia | Arbitrary document | 98.63% | 9.66 |
Table 2. Accuracy of the classifier of documents (correct classification of the document in comparison with the operator's estimate).
One of the great advantages of machine learning is that the neural network really learns and makes fewer and fewer errors. Soon we will finish testing the segment and launch the verification system in a “combat” mode. 30% of applications for verification come to ePayments from Russia, Kazakhstan and Belarus. According to our estimates, the launch will help reduce the burden on the client department by 20–25%. In the future, the solution can be scaled to European countries.
Looking for a job?
We are looking for employees to work in an office in St. Petersburg. If you are interested in an international project with a large pool of ambitious tasks, we are waiting for you. We do not have enough people who are not afraid to implement them. Below you will find links to vacancies on hh.ru.